
8 PROCEDIMIENTOS DE COMPARACIÓN MÚLTIPLE
Cuando el resultado de un ANOVA es significativo, lo único que puede afirmarse es que no todas las medias poblacionales de los grupos comparados son iguales entre sí. No obstante, en esta primera instancia no es posible conocer las particularidades de las diferencias, excepto si el experimento consta únicamente de dos tratamientos.
Cuando se tienen más de dos tratamientos, se requieren procedimientos adicionales que permitan precisar las conclusiones. Para ello, se emplean procedimientos de comparación múltiple (PCM), también conocidos tradicionalmente como pruebas post hoc.
¿Post hoc?
En sentido estricto, esta denominación se refiere a las pruebas realizadas a posteriori —tras observar los resultados significativos del ANOVA—, en contraposición con las que el investigador hubiera planeado a priori —antes de conocer los resultados—.
Esta distinción, sin embargo, puede resultar problemática en la práctica contemporánea, pues sugiere que la naturaleza de un procedimiento depende del momento en que se formula la comparación.
Los PCM están diseñados para contrastar simultáneamente varias hipótesis acerca de las medias de las poblaciones involucradas en un experimento.
A pesar de que se encuentran entre las herramientas de mayor uso en investigación experimental, la opinión de los estadísticos alrededor de estos procedimientos dista de ser unánime. La miríada de propuestas constituye un primer indicio de ello. La instauración de un encuentro bienal dedicado exclusivamente a los PCM1 muestra que se trata de un campo en constante desarrollo y que está lejos de considerarse cerrado.
En esta sección se discuten inicialmente tres elementos transversales a los PCM clásicos:
La definición y el control de diferentes tasas de error que surgen por la evaluación simultánea de múltiples hipótesis.
El uso de contrastes o combinaciones lineales de medias que representan comparaciones entre grupos de tratamientos.
La realización del proceso inferencial mediante intervalos de confianza simultánea.
Seguidamente, se presentan los PCM clásicos de uso más frecuente, dejando constancia una vez más de que son muchísimos los procedimientos existentes para este fin.
¿¡Y Duncan!?
Merece un comentario especial la Nueva Prueba de Rangos Múltiples de Duncan o simplemente Prueba de Duncan (1955), que por muchos años fue una de las más usadas, especialmente en el área agraria.
En el presente texto no se incluye esta prueba, siguiendo la recomendación de autores como Day y Quinn (1989), Rafter, Abell y Braselton (2002) y Ozcaya y Ercan (2012), quienes desaconsejan su uso, debido a que no controla la tasa de error por familia.
Luego, se describen algunos métodos basados en el ajuste del valor p y otros más basados en el control de la tasa de falsos descubrimientos.
A continuación, se presenta un método de comparación de cada uno de los tratamientos contra la media general.
Finalmente se evalúan algunos métodos para comparación de medias en situación de heterocedasticidad bajo distintos esquemas inferenciales.
8.1 Tasas de error
En el contexto de los experimentos diseñados —cuando se tienen \(k\) tratamientos, con \(k>2\)— surge la posibilidad de plantear y responder múltiples preguntas sobre las medias de los tratamientos, mediante el contraste de múltiples hipótesis.
Así, para un experimento con cuatro tratamientos, como el del ejemplo 7.1, pueden realizarse todas las posibles comparaciones entre pares de medias (pairwise comparisons), contrastando los seis juegos de hipótesis siguientes:
\[
\mu_{\text{A}} \text{ vs. }\mu_{\text{B}}:\quad H_0:\mu_{\text{A}} =\mu_{\text{B}},\quad H_a:\mu_{\text{A}} \ne\mu_{\text{B}}
\] \[
\mu_{\text{A}} \text{ vs. }\mu_{\text{C}}:\quad H_0:\mu_{\text{A}} =\mu_{\text{C}},\quad H_a:\mu_{\text{A}} \ne\mu_{\text{C}}
\] \[
\mu_{\text{A}} \text{ vs. }\mu_{\text{D}}:\quad H_0:\mu_{\text{A}} =\mu_{\text{D}},\quad H_a:\mu_{\text{A}} \ne\mu_{\text{D}}
\] \[
\mu_{\text{B}} \text{ vs. }\mu_{\text{C}}:\quad H_0:\mu_{\text{B}} =\mu_{\text{C}},\quad H_a:\mu_{\text{B}} \ne\mu_{\text{C}}
\] \[
\mu_{\text{B}} \text{ vs. }\mu_{\text{D}}:\quad H_0:\mu_{\text{B}} =\mu_{\text{D}},\quad H_a:\mu_{\text{B}} \ne\mu_{\text{D}}
\] \[
\mu_{\text{C}} \text{ vs. }\mu_{\text{D}}:\quad H_0:\mu_{\text{C}} =\mu_{\text{D}},\quad H_a:\mu_{\text{C}} \ne\mu_{\text{D}}
\]
Al decidir sobre cualquier juego de hipótesis existe la probabilidad de errar, bien sea rechazando una hipótesis nula que es cierta (error tipo I) o dejando de rechazar una hipótesis nula falsa (error tipo II) (cf. tabla 3.4).
Al contrastar simultáneamente múltiples juegos de hipótesis, surge un concepto adicional:
¿Tipo I o II?
Aunque en escenarios en los que contrastan múltiples juegos de hipótesis siguen estando presentes las probabilidades de error tipo I y II, las conceptualizaciones se construyen alrededor del error tipo I, dado que es el que el usuario puede controlar directamente.
Luego, la definición 8.1 se refiere a la tasa de error tipo I por familia.
Para diferenciar la tasa de error por familia del tradicional error tipo I que surge al contrastar un único juego de hipótesis, resulta conveniente la siguiente definición:
En concreto…
La tasa de error por comparación es el riesgo de error tipo I de una comparación particular. Es la probabilidad a la que se ha hecho referencia en los capítulos precedentes. En el presente contexto se denota \(\alpha_\text{c}.\)
La tasa de error por familia es el riesgo de cometer error tipo I en al menos una de las comparaciones que conforman una familia. Se denota \(\alpha_\text{f}\) o TEF (FWER: Familywise Error Rate). Cuando no existe riesgo de ambigüedad se denota simplemente por \(\alpha.\)
¿¡Familia!?
En el contexto de experimentos con un solo factor —como los que se desarrollan en el capítulo 7—, se consideran habitualmente todas las comparaciones entre los tratamientos. En tal sentido, a menudo se habla indistintamente de tasa de error por familia o tasa de error por experimento.
No obstante, en experimentos con más de un factor —como los que se desarrollan en el capítulo 10— pueden surgir múltiples familias dentro de un mismo experimento.
Cuando se realizan múltiples comparaciones, se incrementa la posibilidad de detectar diferencias que en realidad no existen (error tipo I), como consecuencia del número de pruebas evaluadas. Los PCM buscan superar este inconveniente, mediante la aplicación de ajustes o correcciones.
En general, la TEF depende de la tasa de error por comparación y del número de comparaciones. Mientras mayor sea el número de tratamientos de un experimento, mayor es el número de posibles comparaciones entre estos y —si no se realizara ningún tipo de corrección— mayor sería también la TEF.
El número de comparaciones por pares que pueden realizarse en un experimento conformado por \(k\) tratamientos está determinado por las combinaciones de \(k\) en 2, así:
\[
\begin{align}
\binom{k}{2}&=\dfrac{k!}{2!(k-2)!}\\[1.4em]
&=\frac{k(k-1)(k-2)!}{2!(k-2)!}\\[1.4em]
&=\frac{k(k-1)}{2}
\end{align}
\]
Para ilustrar cuál sería la TEF si no se usara ningún tipo de corrección y las comparaciones por pares fueran independientes, considérese inicialmente la probabilidad de cometer un error tipo I en una comparación específica. Esta es la tasa de error por comparación fijada por el usuario: \(\alpha_\text{c}.\)
La probabilidad de no cometer error tipo I al realizar una comparación es el complemento \((1-\alpha_\text{c}).\)
Al realizar \(m\) comparaciones independientes, la probabilidad de no cometer error tipo I en ninguna de ellas es \((1-\alpha_\text{c})^m.\)
La probabilidad de cometer al menos un error tipo I cuando se realizan \(m\) comparaciones independientes es \(1-(1-\alpha_\text{c})^m.\)
Luego, si en un experimento se realizaran \(m\) comparaciones independientes, cada una de ellas con una tasa de error por comparación \(\alpha_\text{c}\) y no se aplicara ningún tipo de corrección, la TEF estaría dada por:
\[
\text{TEF}\equiv \alpha_\text{f}\equiv\alpha=1-(1-\alpha_\text{c})^m
\]
La tabla 8.1 muestra las TEF para experimentos con \(k\) en el rango entre 2 y 10, si las comparaciones por pares fueran independientes y no se aplicara ningún tipo de corrección.
| Número de tratamientos | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| Número de comparaciones | 1 | 3 | 6 | 10 | 15 | 21 | 28 | 36 | 45 |
| Tasa de error por familia | 0.05 | 0.143 | 0.265 | 0.401 | 0.537 | 0.659 | 0.762 | 0.842 | 0.901 |
Aunque las TEF reales son menores que las presentadas en la tabla 8.1, por la falta de independencia entre las comparaciones por pares, estas seguirán siendo mayores que las tasas de error por comparación. El único caso en el que la TEF es igual a la tasa de error por comparación es aquel en el que se comparan dos medias, no requiriéndose, por tanto, ningún tipo de corrección.
En general, mediante los PCM se aplican ajustes para el control de la TEF. Desde luego, esto afecta las tasas de error por comparación, llevándolas a niveles muy bajos, con la consiguiente disminución de la potencia de las pruebas.
Aunque esta es una estrategia ampliamente aceptada, ello no significa que exista consenso sobre la validez de la misma, siendo destacables las posiciones contrarias de autores como Cox (1965), O’Brien (1983) y Saville (1990), quienes conceden mayor importancia a la tasa de error por comparación y a la potencia de las pruebas individuales.
8.2 Contrastes de medias
Aunque pueden plantearse infinitas combinaciones lineales de medias que satisfagan la condición necesaria para ser contrastes (que la suma de los coeficientes \(c_i\) sea cero), resultan de interés práctico aquellos contrastes que expresan la comparación entre dos grupos de medias.
Los contrastes constituyen la forma más general de comparación de medias. Mediante los contrastes se comparan grupos de medias, en lugar de medias individuales.
Considérese un experimento con cinco tratamientos e igual número de réplicas, con medias poblacionales \(\mu_1,\) \(\mu_2,\) \(\mu_3,\) \(\mu_4\) y \(\mu_5.\) La comparación entre las medias de los tratamientos 1 y 3 y las de los tratamientos 2, 4 y 5 puede expresarse mediante la siguiente hipótesis:
\[
\begin{align}
H_0&:\frac{\mu_1+\mu_3}{2}=\frac{\mu_2+\mu_4+\mu_5}{3}\\[1.4em]
H_0&:3\mu_1+3\mu_3=2\mu_2+2\mu_4+2\mu_5\\[1.4em]
H_0&:3\mu_1+3\mu_3-2\mu_2-2\mu_4-2\mu_5=0\\[1.4em]
\end{align}
\]
La combinación lineal \(\xi=3\mu_1-2\mu_2+3\mu_3-2\mu_4-2\mu_5\) es el contraste que representa la comparación entre las medias del grupo de tratamientos 1, 3 y las del grupo 2, 4, 5.
La comparación entre los dos grupos puede expresarse de manera simplificada, así:
\[
H_0:\xi=0 \text{ vs. } H_a:\xi\ne0
\]
Al plantear un contraste no es necesario que los grupos comparados estén conformados por el mismo número de medias, como tampoco es necesario que todas las medias participen en el contraste, pudiendo asignárseles coeficiente cero a las medias que no participan.
El contraste para comparar la media del tratamiento 1 contra las medias de los tratamientos 3, 4 y 5 se escribe así:
\[
\begin{align}
\xi =& 3\mu_1+0\mu_2-\mu_3-\mu_4-\mu_5\\[1.4em]
=& 3\mu_1-\mu_3-\mu_4-\mu_5
\end{align}
\]
La comparación entre pares de medias es un contraste particular en el que el primer grupo está conformado por una sola media y el segundo grupo también.
El contraste para comparar la media del tratamiento 2 contra la media del tratamiento 5 se escribe así:
\[
\begin{align}
\xi=&0\mu_1+1\mu_2+0\mu_3+0\mu_4-1\mu_5\\[1.4em]
=&\mu_2-\mu_5
\end{align}
\]
¡También son contrastes!
Los contrastes constituyen la forma más general de comparación de medias.
Las comparaciones por pares son contrastes particulares.
La posibilidad de comparar grupos de medias introduce un elemento adicional que debe considerarse en los PCM. En un experimento con \(k\) tratamientos, el número de comparaciones no está limitado a las \(\frac{k(k − 1)}{2}\) comparaciones entre pares de medias, sino que pueden realizarse comparaciones adicionales entre grupos de medias.
Advertencia 8.1: ¿¡Contrastes ortogonales!?
Como una forma de limitar el número de comparaciones entre grupos de medias, suele recomendarse considerar únicamente conjuntos de contrastes ortogonales o independientes, lo que impone una cota máxima de \(k−1\) comparaciones.
En experimentos con igual número de réplicas, dos contrastes son ortogonales o independientes si la suma de los productos cruzados de sus correspondientes coeficientes es cero.
\[
\text{Sean }\xi_1: c_1\mu_1+c_2\mu_2+\dotsb+c_k\mu_k\quad\text{y}\quad\xi_2: c_1'\mu_1+c_2'\mu_2+\dotsb+c_k'\mu_k
\] \[
\xi_1 \text{ y } \xi_2 \text{ son ortogonales o independientes si y solo si } \sum\limits_{i=1}^k c_ic_i'=0
\]
Existen varias razones para desaconsejar esta práctica:
La restricción de ortogonalidad puede llevar a que el usuario desestime comparaciones de interés.
En la búsqueda del conjunto de los \(k-1\) contrastes ortogonales pueden surgir comparaciones que no sean de interés práctico.
Existen procedimientos de comparación múltiple que permiten realizar cualquier número de comparaciones, manteniendo controlada la TEF.
En consecuencia, se recomienda considerar todos los contrastes que sean de interés, sin importar si representan o no un conjunto de contrastes ortogonales.
¡Úselos!
En la práctica investigativa, la comparación entre grupos de medias o por contrastes es una herramienta mucho menos conocida y utilizada que la comparación entre pares de medias.
Son muy pocos los estudios en los que se utilizan comparaciones entre dos grupos de medias, sin considerar, desde luego, las comparaciones por pares, como casos particulares de los contrastes.
En tal sentido, más que advertir sobre el riesgo de realizar demasiados contrastes —que es un riesgo controlable—, debería estimularse el uso de esta herramienta en los casos en los que pudiera aportar información relevante.
Los contrastes deben plantearse a priori, de manera tal que exista algún aspecto diferenciador entre los grupos, a la vez que los tratamientos que conformen cada grupo tengan algo en común, que le dé sentido a la media conjunta de tales tratamientos y a la interpretación de la diferencia entre las medias conjuntas de los grupos.
En un experimento para control de plagas, podría ser pertinente realizar un contraste entre biopesticidas y pesticidas químicos.
En un experimento de evaluación de variedades, un contrate entre grupos de diferentes orígenes o grupos de diferentes hábitos de crecimiento podría suministrar información valiosa.
8.2.1 Contrastes entre tratamientos con diferente número de réplicas
Cuando no todos los tratamientos tienen el mismo número de réplicas, los coeficientes para los contraste se obtienen planteando el juego de hipótesis a partir de medias ponderadas dentro de cada grupo.
Para ilustrarlo, supóngase las siguientes réplicas para un experimento con 5 tratamientos:
| Tratamiento | Réplicas |
|---|---|
| Tto1 | 5 |
| Tto2 | 7 |
| Tto3 | 3 |
| Tto4 | 5 |
| Tto5 | 4 |
La hipótesis nula correspondiente a la comparación entre el grupo de tratamientos 1, 2 y 3 y el grupo de tratamientos 4 y 5 se expresa así:
\[
\begin{align}
H_0&:\frac{5\mu_1+7\mu_2+3\mu_3}{15}=\frac{5\mu_4+4\mu_5}{9}\\[1.4em]
H_0&:\frac{5\mu_1+7\mu_2+3\mu_3}{15}-\frac{5\mu_4+4\mu_5}{9}=0&\\[1.4em]
H_0&:\frac{5}{15}\mu_1+\frac{7}{15}\mu_2+\frac{3}{15}\mu_3-\frac{5}{9}\mu_4-\frac{4}{9}\mu_5=0
\end{align}
\]
Luego, los coeficientes del correspondiente contraste, son:
\(c_1=\frac{5}{15},\) \(c_2=\frac{7}{15},\) \(c_3=\frac{3}{15},\) \(c_4=-\frac{5}{9}\) y \(c_5=-\frac{4}{9}.\)
8.3 Intervalos de confianza simultánea
Los intervalos de confianza y las pruebas de hipótesis son las dos caras de la moneda de un mismo proceso inferencial, por la relación uno a uno que existe entre pruebas de hipótesis de dos colas e intervalos de confianza (cf. nota 4.1, sección 4.5 y numeral 8 del decálogo sobre pruebas de hipótesis). En consecuencia, los PCM también puede abordarse mediante intervalos de confianza simultánea, ya sea para diferencias de medias (comparaciones por pares) o para contrastes.
En este contexto es particularmente relevante observar si el intervalo de confianza contiene el cero. Un intervalo de confianza para \(\mu_1−\mu_2\) que contenga al cero indica que no hay diferencia estadísticamente significativa entre \(\mu_1\) y \(\mu_2.\) Las diferencias estadísticamente significativas se verán reflejadas por intervalos con ambos límites negativos o ambos positivos. Un intervalo de confianza para \(\mu_1−\mu_2\) en el que ambos límites sean positivos indica que \(\mu_1\) supera significativamente a \(\mu_2,\) mientras que un intervalo de confianza para \(\mu_1−\mu_2\) con límites negativos indica que \(\mu_2\) supera significativamente a \(\mu_1\) (cf. nota 5.1).
Al comparar grupos de medias mediante contrastes, la interpretación de los correspondientes intervalos de confianza es análoga a la presentada anteriormente, pero en lugar de comparar \(\mu_1\) contra \(\mu_2,\) se compara el grupo de medias que entran con signo positivo en el contraste contra el grupo de medias que entran con signo negativo.
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia \(\mu_1−\mu_2\) se interpreta de la forma habitual: “Se tiene una confianza del \(100(1−\alpha)\,\%\) en que \(\mu_1\) supera a \(\mu_2\) en una cantidad que está entre el límite inferior y el límite superior” (cf. nota 5.1).
No obstante, por la misma razón por la que la TEF se infla con relación a la tasa de error por comparación cuando se realizan múltiples pruebas de hipótesis, la confianza global del conjunto de intervalos es menor que las confianzas individuales, requiriéndose, por tanto, un ajuste o corrección para la confianza global del conjunto de intervalos.
Cuando se cuenta con un conjunto de intervalos para diferencias de medias (o diferencias de grupos de medias), cuya confianza global sea \(100(1−\alpha)\,\%,\) se dice que “se tiene una confianza del \(100(1−\alpha)\,\%\) en que todas las diferencias de medias se encuentran dentro de los límites de sus correspondientes intervalos”.
La probabilidad de que al menos uno de los intervalos no contenga la diferencia real es \(\alpha.\)
Así, si se realizara una corrección tal que diera lugar a una confianza global del 95 % para el conjunto de intervalos de confianza que conforman un experimento, se tendría una confianza del 95 % en que tales intervalos incluyeran las diferencias reales entre las medias o, en otras palabras, la probabilidad de que al menos una de las diferencias reales estuviera por fuera de su intervalo sería 0.05.
La confianza simultánea es la contraparte conceptual, en términos de intervalos, de la TEF. En el marco de los PCM clásicos, solamente los procedimientos que controlan la TEF pueden llevar asociados intervalos de confianza simultánea.
¿Intervalos de confianza simultáneos o intervalos de confianza simultánea?
Entre angloparlantes, la denominación simultaneous confidence intervals es suficiente. No obstante, al proponer una traducción es importante preguntarse a cuál sustantivo hace referencia la simultaneidad: a los intervalos o a la confianza.
El aspecto central de este concepto tiene que ver con el hecho de que pueda asignársele una confianza global o simultánea al conjunto de intervalos; no al hecho de obtener todos los intervalos al mismo tiempo.
Luego, una traducción acorde con este espíritu sería intervalos de confianza simultánea.
Al referirse a los procedimientos que generan estos intervalos, Hochberg y Tamhane (1987) los denominan simultaneous confidence procedures. Cuando se refieren a un procedimiento particular, lo denominan a simultaneous confidence procedure. Esto ratifica que la simultaneidad se refiere a la confianza no a los intervalos ni a los procedimientos que los generan.
En consecuencia, aunque la traducción “intervalos de confianza simultáneos” es la más extendida en español, preferimos utilizar intervalos de confianza simultánea por recoger mejor el espíritu de la simultaneidad.
8.4 Prueba de la diferencia mínima significativa
La prueba de la diferencia mínima significativa-DMS (Least Significant Difference-LSD), propuesta por Fisher en 1935, constituyó una de las primeras alternativa para la comparación de medias.
Al tratarse de una reescritura de la prueba de \(t\) presentada en la sección 5.2.1, en este contexto, también se le denomina prueba de \(t\).
En el contexto del ANOVA, la comparación de dos medias se plantea mediante el siguiente juego de hipótesis:
\[
H_0: \mu_1=\mu_2\Leftrightarrow\mu_1-\mu_2=0
\] \[
H_a: \mu_1\ne\mu_2\Leftrightarrow\mu_1-\mu_2\ne0
\]
Puesto que una de las condiciones del ANOVA es la homogeneidad de varianzas (cf. sección 6.3), sería posible contrastar estas hipótesis usando la prueba de \(t\) para comparación de medias de dos poblaciones normales con varianzas homogéneas (cf. sección 5.2.1).
El estadístico de prueba usado para dicha comparación es (cf. expresión 5.5):
\[
t_\text{c}=\frac{\overline{X}_1-\overline{X}_2}
{\sqrt{S_\text{p}^2\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)}}
\overset {H_0}\thicksim t_{\left(n_1+n_2-2\right)},
\]
donde la varianza combinada se calcula así (cf. expresión 5.3):
\[
S_\text{p}^2=\dfrac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2}
\]
En el contexto del ANOVA, el equivalente de la varianza combinada es el \(\text{CME},\) que corresponde a la media ponderada por los grados de libertad de las varianzas dentro de tratamientos (cf. secciones 6.1.9 y 6.2.5):
\[
\text{CME}=\frac{(r_1-1)S_1^2+(r_2-1)S_2^2+\dotsb+(r_k-1)S_k^2}
{n-k}
\]
Por consiguiente, adaptando la nomenclatura, el estadístico de prueba puede escribirse así:
\[
t_\text{c}=\frac{\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}}
{\sqrt{\text{CME}\left(\dfrac{1}{r_1}+\dfrac{1}{r_2}\right)}}
\overset {H_0}\thicksim t_{\left(n-k\right)}
\]
Para una prueba de dos colas, como la planteada, el criterio de rechazo es el siguiente (cf. tabla 5.3 y figura 5.6):
\[
\text{rechaza } H_0\text{ si }|t_\text{c}|\ge t_{\alpha/2(n-k)}
\]
Remplazando el símbolo del estadístico de prueba por su expresión se tiene:
\[
\text{si }\left|\dfrac{\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}}
{\sqrt{\text{CME}\left(\dfrac{1}{r_1}+\dfrac{1}{r_2}\right)}}\right|
\ge t_{\alpha/2(n-k)}\Rightarrow \text{rechaza } H_0 \text{ con un nivel }\alpha
\]
Hasta este punto, lo que se tiene es una prueba de \(t\) igual a la presentada en la sección 5.2.1, no difiriendo más que en la notación.
Este criterio se reescribe de una forma que permite su posterior simplificación y que resulta más interpretable y generalizable:
\[
\text{si }\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|\ge
t_{\alpha/2(n-k)}{\sqrt{\text{CME}\left(\frac{1}{r_1}+\frac{1}{r_2}\right)}}
\Rightarrow \text{rechaza } H_0
\]
Cuando los tratamientos comparados tienen el mismo número de réplicas, la anterior expresión se simplifica así:
\[
\text{si }\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|\ge
t_{\alpha/2(n-k)}\sqrt{\dfrac{2\text{CME}}{r}}
\Rightarrow \text{rechaza } H_0
\]
Bajo los supuestos del ANOVA, las medias muestrales son variables aleatorias independientes y normalmente distribuidas con media \(\mu_i\) y varianza \(\frac{σ^2}{r}:\)
\[
\overline{Y}_{i\bullet}\thicksim N\left(\mu_i,\;\frac{σ^2}{r}\right),\quad i=1, 2, \dotsc, k
\]
La diferencia entre dos medias muestrales es a su vez una variable aleatoria normal:
\[
\left(\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right)\thicksim N\left(\mu_1-\mu_2,\;\frac{2σ^2}{r}\right)
\]
El estimador de la desviación estándar de la diferencia de medias se denomina error estándar de la diferencia de medias. Este se denota y calcula así:
\[
S_{\overline{Y}_{1}-\overline{Y}_{2}} =\sqrt{\dfrac{2\text{CME}}{r}}
\]
Luego, el criterio de comparación de medias puede escribirse de manera compacta así:
\[
\text{si }\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|\ge
t_{\alpha/2(\text{gle})}S_{\overline{Y}_{1}-\overline{Y}_{2}}
\Rightarrow \text{rechaza } H_0 \text{ con un nivel }\alpha
\]
A la expresión del lado derecho de la desigualdad se le denomina diferencia mínima significativa (DMS), puesto que es la diferencia mínima que debe existir entre dos medias muestrales para poder declarar significancia con un nivel \(\alpha.\) De ahí surge el nombre de la prueba.
El criterio de comparación de dos medias mediante la prueba de la diferencia mínima significativa se expresa así:
\[
\text{si }\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|\ge
\text{DMS}
\Rightarrow \text{rechaza } H_0 \text{ con un nivel de significancia }\alpha
\]
Nota 8.1: ¿Cómo se afecta la potencia?
La DMS es la mínima diferencia que debe observarse entre dos medias muestrales para declarar con un nivel de significancia \(\alpha\) que las correspondientes medias poblacionales difieren.
Mientras menor sea la DMS, más probable será declarar diferencias significativas, es decir, mayor será la potencia de las pruebas.
En consecuencia, la potencia de las pruebas está determinada por los diferentes elementos que conforman la DMS: \(\alpha,\) \(\text{gle},\) \(\text{CME}\) y \(r:\)
\[
\text{DMS}=t_{\alpha/2(\text{gle})}\sqrt{\dfrac{2\text{CME}}{r}}
\]
A continuación se detalla el efecto de cada uno de estos componentes. En todos los casos es posible realizar una interpretación aritmética directa —considerando su posición en la expresión— así como una interpretación intuitiva —teniendo en cuenta su papel en la prueba—:
1. Efecto de \(\alpha.\) La figura 8.1, correspondiente a la parte derecha de una distribución \(t_{(8)},\) muestra que mientras menor sea \(\alpha,\) mayor será su correspondiente valor crítico2, lo que incrementa la DMS y reduce la potencia.
La relación inversa entre las probabilidades de error tipo I y tipo II, para una muestra fija en términos de tamaño y variabilidad, es una característica propia de todas las pruebas de hipótesis. Esta relación se explora en detalle en la sección 3.9.2.2.
2. Efecto de los grados de libertad del error. La figura 8.2, correspondiente a la parte derecha de dos distribuciones \(t\) con diferente número de grados de libertad, muestra que, mientras mayor sea el número de grados de libertad del error, menor será su correspondiente valor crítico, lo que da lugar a un menor valor de la DMS y, por tanto, a una mayor potencia.

En términos de la forma de la distribución, esto se explica por el incremento de la condición leptocúrtica de la distribución \(t\) a medida que sus grados de libertad disminuyen. Mientras más pesadas sean las colas de la distribución (más área en las colas), más se desplazará el correspondiente valor crítico hacia la derecha.
En términos de la prueba, la disminución en la potencia se explica por la mayor incertidumbre que acompaña los procesos inferenciales cuando la estimación del error experimental está basada en un menor número de elementos independientes.
Los grados de libertad del error constituyen el elemento central de la ecuación de los recursos propuesta por Mead, Gilmour y Mead (2012) (cf. sección 7.3.1), que sirve como guía para elegir el número de réplicas en un ensayo.
3. Cuadrado medio del error. El \(\text{CME}\), al aparecer en el numerador de la DMS, se relaciona directamente con esta. Mientras menor sea el \(\text{CME},\) menor será la DMS y, por ende, mayor la potencia.
Lógicamente, mientras menor sea la variabilidad entre unidades experimentales asociadas a un mismo tratamiento, la prueba será más sensible y podrá declarar diferencias significativas a partir de diferencias menores.
4. Número de réplicas. Por su parte, el número de réplicas, al aparecer en el denominador de la DMS, se relaciona inversamente con esta. A mayor número de réplicas, menor será la DMS y, por tanto, mayor la potencia.
Esto es consistente con la prescripción de incrementar el tamaño de muestra (número de réplicas en el presente contexto) para aumentar la potencia.
La tabla 8.2 resume el efecto de los diferentes componentes de la DMS en su magnitud y, por tanto, en la potencia de las pruebas. Las relaciones que allí se presentan son válidas para todos los procedimientos de comparación múltiple.
| Componente de la DMS | Efecto en la DMS | Efecto en la potencia |
|---|---|---|
| \(\downarrow\;\alpha\) | \(\uparrow\;\) DMS | \(\downarrow\; (1-\beta)\) |
| \(\uparrow\;\text{gle}\) | \(\downarrow\;\) DMS | \(\uparrow\; (1-\beta)\) |
| \(\downarrow\;\text{CME}\) | \(\downarrow\;\) DMS | \(\uparrow\; (1-\beta)\) |
| \(\uparrow\;r\) | \(\downarrow\;\) DMS | \(\uparrow\; (1-\beta)\) |
A continuación, se ilustra el proceso de aplicación de la prueba DMS, para realizar las seis posibles comparaciones entre los pares de medias del ejemplo 7.1, con un nivel de significancia \(\alpha=0.05.\)
\[
\begin{align}
\text{DMS}&=t_{\alpha/2(\text{gle})}\sqrt{\dfrac{2\text{CME}}{r}}\\[1.4em]
&=t_{0.025(8)}\sqrt{\dfrac{2\times 0.025}{3}}\\[1.4em]
&=2.3060 \times 0.1291\\[1.4em]
&=0.2977
\end{align}
\]
En cada comparación, si la diferencia absoluta entre un par de medias muestrales es mayor o igual que la DMS (0.2977), se rechaza la correspondiente hipótesis nula con un nivel de significancia del 5 %. Las medias muestrales aparecen en la última columna de la tabla 7.1.
\[
\begin{align}
\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{B} \bullet}\right|=
\left|4.1-3.2\right|=0.9>0.2977\quad*\\[0.5em]
\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|4.1-3.8\right|=0.3>0.2977\quad*\\[0.7em]
\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|4.1-3.9\right|=0.2<0.2977\quad\text{ns}\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|3.2-3.8\right|=0.6>0.2977\quad*\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|3.2-3.9\right|=0.7>0.2977\quad*\\[0.7em]
\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{C}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|3.8-3.9\right|=0.1<0.2977\quad\text{ns}
\end{align}
\]
En cada una de las comparaciones anteriores se contrasta un juego de hipótesis sobre las correspondientes medias poblacionales. Así, la primera comparación permite decidir sobre el juego de hipótesis:
\[
H_0: \mu_{\text{A}}=\mu_{\text{B}}
\] \[
H_a: \mu_{\text{A}}\ne\mu_{\text{B}}
\]
Este juego de hipótesis se representa de manera compacta mediante la expresión \(\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}\).
Aunque esta señalización no suele aparecer en los resultados de las pruebas —en las que usualmente se presentan solo las medias muestrales, omitiendo toda referencia a las medias poblacionales— es importante tenerla presente, a fin de evitar interpretaciones erróneas.
El hecho de que en los resultados se presente únicamente las medias muestrales puede llevar a pensar que son estas las que se comparan. Esto, desde luego, carece de interés. Las medias muestrales casi siempre son diferentes. Es totalmente irrelevante responder si 4.1 difiere de 3.9 (desde luego, difieren); lo que interesa averiguar es si la diferencia entre dichas medias muestrales es de una magnitud tal que permita afirmar con baja probabilidad de error que las correspondientes medias poblacionales son diferentes.
Los procesos inferenciales que se realizan mediante la DMS son equivalentes a los ilustrados en la sección 5.2, donde se utilizan medias muestrales para inferir sobre medias poblacionales.
En los casos en los que la diferencia entre las medias muestrales es mayor o igual que 0.2977, se rechaza la hipótesis nula al 5 %, lo cual se denota mediante un asterisco; en los demás casos, puede usarse la etiqueta \(\text{ns}\) o no usar ninguna marca.
Así, por ejemplo, puede afirmarse, con una probabilidad de error máxima de 0.05 que \(\mu_{\text{A}}\) es diferente de \(\mu_{\text{B}},\) mientras que no es posible afirmar con una probabilidad máxima de error de 0.05 que exista diferencia entre \(\mu_{\text{A}}\) y \(\mu_{\text{D}}.\)
Lo anterior, desde luego, deberá expresarse y discutirse acorde con cada contexto. Para el ejemplo 7.1 podría afirmarse con una probabilidad máxima de error de 0.05 que el pH medio de la pulpa de guanábana, empacada con el sistema \(\text{A}\) difiere del pH medio de la pulpa de guanábana empacada con el sistema \(\text{B},\) mientras que no es posible afirmar con una probabilidad máxima de error de 0.05 que el pH medio de la pulpa de guanábana, empacada con el sistema \(\text{A}\) difiera del pH medio bajo el sistema \(\text{D}.\)
Los resultados de los contrastes suelen agruparse —usando un código de letras— en una tabla en la que se organizan las medias, ya sea de manera ascendente o descendente. La elección entre uno u otro orden responde a criterios de presentación. Con frecuencia se utiliza el orden descendente para destacar los tratamientos con mayores promedios.
Se asigna una letra común a los tratamientos cuyas medias no difieren significativamente. Por el contrario, los tratamientos cuyas medias difieren significativamente no tendrán ninguna letra común3.
La tabla 8.3 muestra dicho resumen o agrupación para las medias de los tratamientos del ejemplo 7.1.
| Tratamiento | \(\overline{Y}_{i\bullet}\) | Grupos |
|---|---|---|
| \(\text{A}\) | 4.1 | a |
| \(\text{D}\) | 3.9 | ab |
| \(\text{C}\) | 3.8 | b |
| \(\text{B}\) | 3.2 | c |
La tabla 8.3 debe acompañarse de la siguiente leyenda:
Las medias de los tratamientos con alguna letra común no difieren al 5 %, según la prueba DMS.
¡Atención a la leyenda!
Es necesario tener precaución con la forma en la que se escribe la leyenda acompañante de este tipo de tablas.
Es muy común ver leyendas como la siguiente:
Las medias de los tratamientos con letras distintas difieren al 5 %, según la prueba DMS.
Aunque aparentemente se trata de la misma leyenda, expresada de manera diferente, no lo es y lo que allí se indica es incorrecto.
Con base en lo que se dice en esta última leyenda se concluiría que, dado que el tratamiento \(\text{A}\) y el tratamiento \(\text{D}\) van acompañados de letras diferentes (a y b), los pH medios de tales tratamientos difieren significativamente.
Desde luego, ni es esta la conclusión correcta ni era esto lo que se pretendía expresar.
La tabla 8.3 permite captar rápidamente el orden de los valores de pH. También se observa que no hay diferencia significativa entre el pH medio de los tratamientos \(\text{A}\) y \(\text{D}\) (comparten la letra a), ni entre el pH medio de los tratamientos \(\text{D}\) y \(\text{C}\) (comparten la letra b). Entre los demás pares de tratamientos, la DMS permite declarar diferencia significativa al 5 %.
La tabla 8.3 también permite visualizar rápidamente que el pH medio del tratamiento \(\text{B}\) es significativamente menor que el de todos los demás tratamientos.
Los resultados agrupados en los que hay tratamientos con más de una letra pueden generar desconcierto, al considerarse que reflejan una violación al principio de transitividad, el cual establece que si \(\text{A}=\text{B}\) y \(\text{B}=\text{C}\), entonces \(\text{A}=\text{C}.\)
La información condensada en la tabla 8.3 conlleva la aceptación de que \(\mu_{\text{A}}\) no es diferente de \(\mu_{\text{D}}\). Asimismo, se acepta que \(\mu_{\text{D}}\) no es diferente de \(\mu_{\text{C}}.\) Sin embargo, se rechaza que \(\mu_{\text{A}}\) sea igual a \(\mu_{\text{C}}.\)
Suele hablarse de grupos homogéneos en referencia a grupos de medias con una letra común, es decir, un grupo de medias entre las cuales no existe diferencia estadísticamente significativa.
En el presente ejemplo, los tratamientos \(\text{A}\) y \(\text{D}\) conforman un grupo homogéneo, mientras que los tratamientos \(\text{D}\) y \(\text{C}\) conforman otro grupo homogéneo.
Las letras indicadoras que aparecen en la última columna de la tabla 8.3 señalan la membresía de un tratamiento a un grupo determinado, pudiendo suceder que un tratamiento pertenezca a varios grupos simultáneamente, lo cual puede representarse mediante un diagrama de grupos homogéneos traslapantes (figura 8.3).

En la figura 8.3 se ilustra que \(\mu_{\text{D}}\) forma parte del mismo grupo que \(\mu_{\text{C}}\) y también comparte grupo con \(\mu_{\text{A}}\). Sin embargo, \(\mu_{\text{C}}\) no comparte grupo con \(\mu_{\text{A}}.\)
El paquete agricolae para R incluye funciones para realizar los PCM más populares. La función LSD.test implementa la prueba de la diferencia mínima significativa.
Las funciones de agricolae que se utilizan para la realización de diferentes PCM comparten una serie de argumentos comunes:
y: Objeto de la claseaovolmcon el modelo ajustado del ANOVA.trt: Nombre de los tratamientos. Debe especificarse entre comillas.group: Variable lógica que indica si los resultados deben presentarse de manera resumida en formato de grupos homogéneos, como el de la tabla 8.3. Por defecto,group = TRUE.console: Variable lógica que indica si los resultados deben presentarse en consola. Por defecto,console = FALSE.
El siguiente fragmento de código ilustra el uso de la función LSD.test, incluyendo en las tres primeras líneas los pasos preliminares necesarios, como se ilustró en el desarrollo del ejemplo 7.1. El objeto anova que se genera en la línea 3 es el que se utiliza como argumento principal de la función LSD.test en la línea 5:
Antes de analizar los resultados, vale la pena realizar algunos comentarios sobre la sintaxis de las funciones de este paquete.
Aunque existen otras maneras de alimentar la información del modelo en la función, la más práctica es la expuesta en el fragmento anterior, es decir, la que consiste en ajustar previamente el ANOVA, cuyos resultados se utilizan como primer argumento, lo que permite extraer de allí casi toda la información necesaria para la realización de la prueba.
Todas las funciones que forman parte de este paquete trabajan por defecto con un nivel de significancia del 5 % (alpha = 0.05).
Salvo que los resultados únicamente constituyan un paso intermedio de un proceso posterior, lo usual es querer visualizarlos en consola. Dado que el valor por defecto del argumento console es FALSE, se hace necesario especificar console = TRUE para que estos se muestren en la consola.
Los resultados son los siguientes:
Study: anova ~ "tto"
LSD t Test for pH
Mean Square Error: 0.025
tto, means and individual ( 95 %) CI
pH std r se LCL UCL Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.889492 4.310508 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 2.989492 3.410508 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.589492 4.010508 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.689492 4.110508 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of t: 2.306004
least Significant Difference: 0.2977039
Treatments with the same letter are not significantly different.
pH groups
A 4.1 a
D 3.9 ab
C 3.8 b
B 3.2 cEn la primera parte aparece información de carácter general:
- Mean Square Error: \(\text{CME}=0.025\)
- Alpha: \(\alpha=0.05\)
- DF Error: \(\text{gle}=8\)
- Critical value of t: \(t_{0.025(8)}=2.306004\)
- Least Significant Difference: \(\text{DMS}=0.2977039\)
También en la primera parte se presenta información descriptiva para cada uno de los tratamientos (media, desviación estándar, número de réplicas, entre otros). Esta información puede ser útil para caracterizar los datos, aunque no es central en el contexto de los PCM.
Asimismo, se presentan intervalos de confianza individuales para cada tratamiento, cuya interpretación en este contexto requiere especial precaución.
¡Cuidado con los intervalos individuales!
En el contexto del ANOVA, bajo el supuesto de homogeneidad de varianzas, los procesos inferenciales se fundamentan en el estimador conjunto de la varianza (\(\text{CME}\)), no en estimaciones individuales.
En la salida de la función LSD.test se presentan intervalos de confianza para la media de cada tratamiento, construidos a partir del error estándar individual, lo que rompe el marco conceptual del ANOVA basado en una varianza común.
Por tal motivo, estos intervalos no deben considerarse —ni siquiera como guía— para la comparación de tratamientos.
En la parte final aparece el resumen de grupos homogéneos como el que se mostró en la tabla 8.3.
Asimismo, los resultados de la función LSD.test pueden usarse como argumento de la función plot para generar un gráfico que permite visualizar la posición de la media de cada tratamiento, su variabilidad, en términos del recorrido, y las letras usadas para definir los diferentes grupos, tal y como lo ilustra el siguiente fragmento de código:
out.LSD <- LSD.test(anova, "tto")
plot(out.LSD)
box()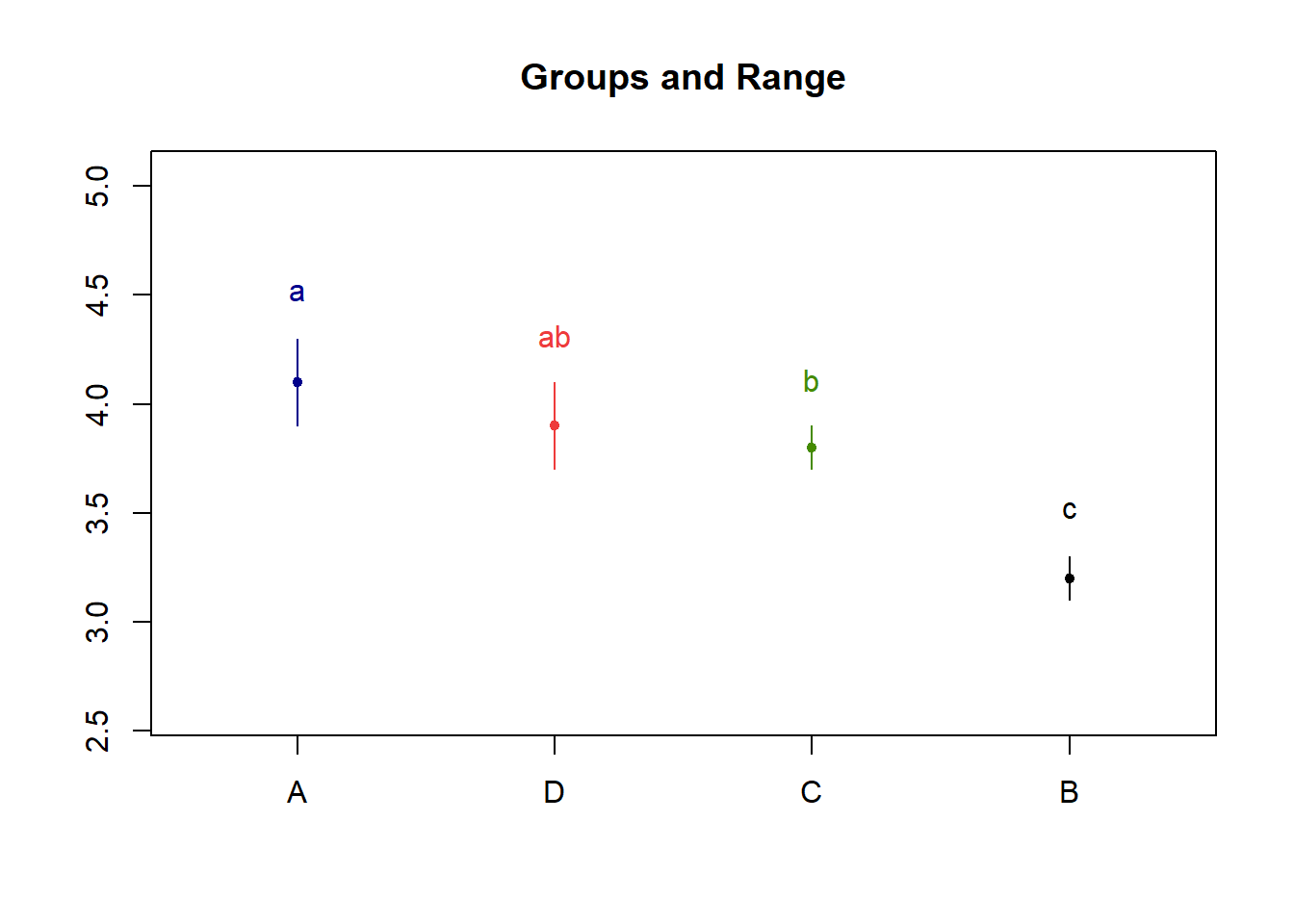
Teniendo en cuenta que la DMS no es más que una reexpresión de la prueba de \(t,\) puede obtenerse el valor p asociado con esta prueba, de acuerdo con lo indicado en la sección 5.2.1.1 (cf. tabla 5.3 y figura 5.6).
Para comparar, por ejemplo, las medias de los tratamientos 1 y 2, el estadístico de prueba es:
\[
t_\text{c}=\frac{\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}}
{\sqrt{\dfrac{2\,\text{CME}}{r}}}
\overset {H_0}\thicksim t_{\left(\text{gle}\right)}
\]
Por consiguiente, el valor p se calcula así:
\[
2\, P\left(t_\text{(gle)}>|t_\text{c}|\right)
\]
Para el ejemplo 7.1 se obtiene la siguiente expresión general del estadístico de prueba:
\[
\begin{align}
t_\text{c}&=\frac{\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}}
{\sqrt{\dfrac{2\,\text{CME}}{r}}}\\[1.4em]
&=\frac{\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}}
{\sqrt{\dfrac{2\times 0.025}{3}}}\\[1.4em]
&=\frac{\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}}
{0.129099}\\[1.4em]
\end{align}
\]
La tabla 8.4 muestra el estadístico de prueba para los diferentes contrastes entre pares de medias y sus correspondientes valores p.
| Comparación | \(t_\text{c}\) | Valor p |
|---|---|---|
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}\) | 6.971394 | 0.000116 |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}\) | 2.323798 | 0.048630 |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}\) | 1.549199 | 0.159927 |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}\) | −4.647596 | 0.001650 |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}\) | −5.422195 | 0.000629 |
| \(\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}\) | −0.774599 | 0.460855 |
La comparación de los valores p con el nivel de significancia elegido \((\alpha=0.05)\) produce las mismas conclusiones que la comparación de la diferencia de medias muestrales con la DMS.
Nótese que solamente las comparaciones \(\mu_\text{B}\text{ vs. } \mu_\text{C}\) y \(\mu_\text{C}\text{ vs. } \mu_\text{D}\) tienen asociados valores p mayores que 0.05, coincidiendo con diferencias entre medias muestrales menores que la DMS y, por tanto, con la ausencia de diferencias significativas al 5 %.
8.4.1 Intervalos de Confianza DMS
En adición a las pruebas de hipótesis, también es posible generar intervalos de confianza para las diferencias de medias, usando la metodología descrita en sección 5.2.1.2, bastando con adaptar la notación.
Así, un intervalo de confianza del 95 % para la diferencia entre \(\mu_1\) y \(\mu_2\) está dado por:
\[
\begin{align}
\text{IC}_{95\%}:&\left(\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right)\pm t_{0.025(\text{gle})}
\sqrt{\dfrac{2\,\text{CME}}{r}}\\[1.4em]
=&\left(\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right)\pm \text{DMS}
\end{align}
\]
Nótese que para la construcción del intervalo no se trabaja con la diferencia absoluta entre las medias, sino que se tiene en cuenta el sentido de la diferencia.
Aunque un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_1−\mu_2\) brinda la misma información que un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_2−\mu_1\) (cf. tip 5.1), para su interpretación, debe tenerse presente a qué diferencia particular le corresponde un intervalo dado.
A continuación, se presentan los seis posibles intervalos de confianza del 95 % para las diferencias de medias del ejemplo 7.1.
\[
\begin{align}
\mu_{\text{A}}-\mu_{\text{B}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{B} \bullet}\right)
\pm \text{DMS}=0.9 \pm 0.2977&:&[0.6023,\,1.1977]\:&*\\[0.5em]
\mu_{\text{A}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DMS}=0.3\pm 0.2977&:&[0.0023,\,0.5977]&*\\[0.7em]
\mu_{\text{A}}-\mu_{\text{D}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{D} \bullet}\right)
\pm \text{DMS}=0.2\pm 0.2977&:&[-0.0977,\,0.4977]&\text{ns}\\[0.7em]
\mu_{\text{B}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DMS}=-0.6\pm 0.2977&:&[-0.8977,\,-0.3023]&*\\[0.7em]
\mu_{\text{B}}-\mu_{\text{D}}&: \left(\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{D} \bullet}\right)
\pm \text{DMS}=-0.7\pm 0.2977&:&[-0.9977,\,-0.4023]&*\\[0.7em]
\mu_{\text{C}}-\mu_{\text{D}}&: \left(\overline{Y}_{\text{C}\bullet}-\overline{Y}_{\text{D} \bullet}\right)
\pm \text{DMS}=-0.1\pm 0.2977&:&[-0.3977,\,0.1977]&\text{ns}
\end{align}
\]
La significancia se determina a través del intervalo de confianza, verificando si contiene el cero (cf. sección 8.3). Además de la coincidencia de resultados —en términos de significancia— entre pruebas de hipótesis e intervalos de confianza, los intervalos de confianza aportan información sobre el sentido y la magnitud de las diferencias.
Así, por ejemplo, al comparar \(\mu_\text{A}\) y \(\mu_\text{B}\) mediante el juego de hipótesis, se concluye con una probabilidad máxima de error de 0.05 que \(\mu_\text{A}\) es diferente de \(\mu_\text{B}.\) Mediante el intervalo de confianza para \(\mu_\text{A}-\mu_\text{B},\) adicionalmente puede afirmarse con una confianza del 95 % que el pH medio del tratamiento \(\text{A}\) supera el pH medio del tratamiento \(\text{B}\) en una cantidad que está entre 0.6023 y 1.1977.
¿¡Y, entonces!?
Es innegable que las pruebas de hipótesis gozan de mayor popularidad que los intervalos de confianza.
Esto puede deberse en parte al desconocimiento de los intervalos de confianza como alternativa inferencial en el contexto de los PCM, pero también a la capacidad de resumen y facilidad interpretativa que brindan los esquemas agrupados como el de la tabla 8.3.
Así, por ejemplo, para un experimento con \(k=10\), el resultado basado en intervalos consta de 45 líneas, mientras que su correspondiente resumen como grupos homogéneos se presenta en 10 líneas.
Asimismo, vale la pena anotar que no todos los PCM permiten generar intervalos de confianza (cf. sección 8.10).
Los intervalos de confianza muestran de manera completa toda la información de cada una de las comparaciones. La tabla de grupos homogéneos la resume.
¡Una relación interesante!
El intervalo de confianza para la diferencia de medias puede escribirse en términos de la DMS:
\[
\text{IC}_{95\%}: \left(\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right)\pm \text{DMS}
\]
Esta expresión destaca cómo la relación entre la DMS y la diferencia de medias muestrales determina la significancia de una comparación:
Si \(\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|\ge\text{DMS},\) la diferencia es significativa y —puesto que la DMS representa el semirradio del intervalo de confianza del \(100(1−\alpha)\,\%\)— el intervalo de confianza no contiene el cero.
Si \(\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|<\text{DMS},\) la diferencia no es significativa y el intervalo de confianza del \(100(1−\alpha)\,\%\) contiene el cero.
En otras palabras, la comparación mediante la DMS y la evaluación del intervalo de confianza son criterios completamente equivalentes.
Para obtener en R los intervalos de confianza para las diferencias de medias, con base en la prueba DMS, se usa la función LSD.test, incluyendo la opción group = FALSE.
LSD.test(anova, "tto", group = FALSE, console = TRUE)
Study: anova ~ "tto"
LSD t Test for pH
Mean Square Error: 0.025
tto, means and individual ( 95 %) CI
pH std r se LCL UCL Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.889492 4.310508 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 2.989492 3.410508 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.589492 4.010508 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.689492 4.110508 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of t: 2.306004
Comparison between treatments means
difference pvalue signif. LCL UCL
A - B 0.9 0.0001 *** 0.602296146 1.1977039
A - C 0.3 0.0486 * 0.002296146 0.5977039
A - D 0.2 0.1599 -0.097703854 0.4977039
B - C -0.6 0.0016 ** -0.897703854 -0.3022961
B - D -0.7 0.0006 *** -0.997703854 -0.4022961
C - D -0.1 0.4609 -0.397703854 0.1977039De nuevo, la parte relevante de los resultados aparece al final, debajo del encabezado Comparison between treatments means. Esta salida incluye los valores p de las pruebas de hipótesis de cada una de las comparaciones por pares (cf. tabla 8.4) y los intervalos de confianza del 95 % (por defecto alpha = 0.05) para las diferencias de medias, donde LCL (lower confidence limit) corresponde al límite inferior y UCL (upper confidence limit) al superior.
group
El argumento group determina la manera en la que se presentan los resultados de los PCM generados por las funciones de agricolae:
8.4.2 Contrastes DMS
Un contraste es una combinación lineal de medias que permite comparar dos grupos de tratamientos (cf. sección 8.2).
A partir de un contraste puede formularse un juego de hipótesis para comparar las medias de los dos grupos, así:
\[
H_0:\xi=0,\quad H_a:\xi\ne0
\]
La prueba DMS permite evaluar este juego de hipótesis, comparando el valor estimado del contraste con un valor de referencia.
El estimador de un contraste está dado por una combinación lineal equivalente de las medias muestrales:
\[
\widehat\xi=\sum\limits_{i=1}^k c_i\widehat\mu_i=\sum\limits_{i=1}^k c_i\overline{Y}_{i\bullet}
\]
De manera análoga a la utilizada para obtener el error estándar de la diferencia de medias, se calcula el error estándar del contraste estimado:
\[
S_\widehat\xi=\sqrt{\text{CME}\sum\limits_{i=1}^k{\frac{c_i^2}{r_i}}}
\]
Nótese que para el caso particular de un contraste en el que cada grupo esté conformado por una media, esto es, para la comparación entre un par de medias, se tendrá un coeficiente \(+1,\) otro coeficiente \(−1\) y el resto de coeficientes \(0.\) En tal caso, el error estándar del contraste estimado coincide con el error estándar de la diferencia de medias.
¿¡Cómo así!?
Supóngase un contraste para comparar la primera y la segunda media de un grupo de tratamientos:
\[
\begin{align}
S_\widehat\xi=&\sqrt{\text{CME}\left(\frac{(+1)^2}{r_1}+\frac{(-1)^2}{r_2}+\frac{(0)^2}{r_3}+\dotsb+\frac{(0)^2}{r_k}\right)}\\[1.4em]
=&\sqrt{\text{CME}\left(\frac{1}{r_1}+\frac{1}{r_2}\right)}\\[1.4em]
\end{align}
\]
La diferencia mínima significativa para el contraste está dada por:
\[
\begin{align}
\text{DMS}_{\xi}&=t_{\alpha/2(\text{gle})}S_{\widehat\xi}\\[1.4em]
&=t_{\alpha/2(\text{gle})}\sqrt{\text{CME}\sum\limits_{i=1}^k\dfrac{c_i^2}{r_i}}\\[1.4em]
\end{align}
\]
El criterio de rechazo se expresa así:
\[
\text{si }\left|\widehat\xi\right|\ge\text{DMS}_\xi
\Rightarrow \text{rechaza } H_0 \text{ con un nivel de significancia }\alpha
\]
En su forma completa, este criterio se escribe así:
\[
\text{si }\left|\sum\limits_{i=1}^k c_i\overline{Y}_{i\bullet}\right|\ge t_{\alpha/2(\text{gle})}\sqrt{\text{CME}\sum\limits_{i=1}^k\dfrac{c_i^2}{r_i}}
\Rightarrow \text{rechaza } H_0 \text{ con un nivel }\alpha
\]
Obsérvese que cada contraste se evalúa con una DMS particular, acorde con sus coeficientes y, por consiguiente, con su error estándar.
El hecho de que todas las comparaciones por pares se evalúen con una única DMS se debe a que todas pueden expresarse como contrastes con un coeficiente \(+1,\) otro \(−1\) y el resto \(0,\) lo que da lugar a un error estándar común.
Supóngase que en el ejemplo 7.1, los tratamientos \(\text{A}\) y \(\text{D}\) son sistemas de empaque con atmósfera modificada, mientras que el tratamiento \(\text{C}\) es un sistema de empaque al vacío. Esta característica diferencial le da sentido a una comparación entre estos dos grupos.
El correspondiente contraste se expresa así:
\[
\xi= +0.5\mu_\text{A}+0\mu_\text{B}-1\mu_\text{C}+0.5\mu_\text{D}\Rightarrow 0.5\mu_\text{A}-1\mu_\text{C}+0.5\mu_\text{D}
\]
El estimador del contraste para la comparación planteada \((\text{A},\text{D}\text{ vs. }\text{C})\) es:
\[
\begin{align}
\widehat\xi=& 0.5\overline{Y}_\text{A}-1\overline{Y}_\text{C}+0.5\overline{Y}_\text{D}\\[1.4em]
=&0.5\times 4.1-1\times 3.8+0.5\times3.9=0.2\\[1.4em]
\end{align}
\]
Para un nivel de significancia de 0.05, el valor crítico superior de \(t\) es:
\[
t_{\alpha/2(\text{gle})}=t_{0.025(8)}=2.306004
\]
El error estándar del contraste estimado se calcula así:
\[
\begin{align}
S_\widehat\xi=&\sqrt{\text{CME}\sum\limits_{i=1}^k \frac{c_i^2}{r_i}}\\[1.4em]
=&\sqrt{0.025\dfrac{(0.5)^2+(-1)^2+(0.5)^2}{3} }=0.1118034
\end{align}
\]
Por tanto, la DMS para el contraste es:
\[
\begin{align}
\text{DMS}_{\xi}&=t_{\alpha/2(\text{gle})}S_{\widehat\xi}\\[1.4em]
&=t_{\alpha/2(\text{gle})}\sqrt{\text{CME}\sum\limits_{i=1}^k\dfrac{c_i^2}{r_i}}\\[1.4em]
&=2.306004\times0.1118034=0.2578
\end{align}
\]
Puesto que el valor absoluto del contraste estimado es menor que la DMS para el correspondiente contraste \((0.2 < 0.2578),\) no se rechaza la hipótesis nula con un nivel de significancia del 5 %. Esto indica que no puede concluirse, con baja probabilidad de error, que el pH medio de la pulpa de guanábana en los sistemas de empaque basados en atmósfera modificada (tratamientos \(\text{A}\) y \(\text{D}\)) difiera del pH medio de la pulpa de guanábana en el sistema de empaque al vacío (tratamiento \(\text{C}\)).
Este resultado ilustra cómo las comparaciones grupales incorporan otros matices y enfoques en lo referente a la comparación de medias.
Para el presente ejemplo, aunque puede afirmarse, con baja probabilidad de error, que el pH medio de la pulpa de guanábana difiere entre uno de los sistemas de empaque con atmósfera modificada (tratamiento \(\text{A}\)) y el sistema de empaque al vacío (tratamiento \(\text{C}\)), no es posible generalizar para afirmar con baja probabilidad de error que el pH medio de la pulpa de guanábana difiere entre los sistemas de empaque basados en atmósfera modificada y el sistema de empaque al vacío.
De manera análoga a como se calculó el valor p para las comparaciones por pares, puede calcularse el valor p para el contraste.
El estadístico de prueba para el contraste se define así:
\[
\begin{align}
t_\text{c}=\dfrac{\widehat\xi}{\sqrt{\text{CME}\sum\limits_{i=1}^k\dfrac{c_i^2}{r_i}}}\overset{H_0}\thicksim t_{\text{(gle)}}\\[1.4em]
t_\text{c}=\dfrac{0.2}{0.1118034}=1.78885
\end{align}
\]
Valor p: 2 * pt(1.78885, 8, lower.tail = FALSE) = 0.111435.
En consecuencia, no se rechaza la hipótesis nula con un nivel de significancia del 5 %.
Es posible obtener un intervalo de confianza del \(100(1−\alpha)\,\%\) para el contraste, con base en la siguiente expresión:
\[
\begin{align}
\text{IC}_{100(1−\alpha)\,\%}&:\quad\widehat\xi\pm\text{DMS}_\xi\\[1.4em]
&:\quad\widehat\xi\pm t_{\alpha/2\text{(gle)}}\sqrt{\text{CME}\sum\limits_{i=1}^k\frac{c_i^2}{r_i}}\\[1.4em]
\end{align}
\]
Un intervalo de confianza del 95 % para el contraste planteado \((\mu_{\text{A}, \text{D}}-\mu_{\text{C}})\) está dado por:
\[
0.2\pm 0.2578:\quad[-0.0578,\;0.4578]
\]
Este resultado es coherente con el obtenido anteriormente: puesto que el intervalo de confianza del 95 % para la diferencia de medias de los dos grupos contiene el cero, no se rechaza la hipótesis nula al 5 %.
Para realizar contrastes en R, es fundamental asegurarse de que el orden que se tiene en mente para la asignación de los coeficientes a los tratamientos coincida con el orden interno que R asigna a los tratamientos. Si no fuera así, se estaría evaluando un contraste diferente al deseado.
En general, R ordena los tratamientos alfabéticamente. Si algunos tratamientos tienen nombres numéricos y otros alfanuméricos, los números van antes que las letras, pero los tratamientos con nombre numérico no se ordenan según su valor numérico, sino como cadenas de caracteres.
Así, un factor cuyos niveles fueran a, 3, 25 y 100, tendría el siguiente orden interno:
[1] "100" "25" "3" "a" No obstante, si en el caso anterior el nombre del último tratamiento iniciara con un espacio, se tendría el siguiente ordenamiento:
[1] " a" "100" "25" "3" Cuando todos los nombres son estrictamente numéricos, sí se tiene en cuenta el valor numérico para la ordenación, así:
[1] "3" "4" "25" "100"
¡Verifique el orden!
En vista de que hay muchas posibilidades de errar en la definición de los coeficientes, se recomienda verificar el orden interno que R ha asignado a los tratamientos antes de evaluar cualquier contraste.
Esta verificación puede realizarse mediante la función levels{base}:
levels(data$tto)[1] "A" "B" "C" "D"Para evaluar en R el contraste propuesto anteriormente \((\mu_{\text{A}, \text{D}}-\mu_{\text{C}}),\) se usa la función glht{multcomp}, con el vector de coeficientes del contraste en el argumento linfct.
La línea 1 ajusta el modelo sin intercepto. Para ello se agrega - 1 en la parte derecha del modelo. Este modelo se emplea como primer argumento de la función glht.
La línea 2 define el vector de coeficientes acorde con el orden interno de los tratamientos: \(c_1=0.5, c_2=0, c_3=-1, c_4=0.5\). Mediante la función t (transposición), este vector se convierte en una matriz fila, lo que permite asignarle un nombre al contraste.
La línea 3 le asigna un nombre a la fila de la matriz de coeficientes, el cual se usa en las salidas como identificador del contraste.
La línea 4 ejecuta la prueba del contraste.
anova.c <- aov(pH ~ tto - 1, data = data)
k <- t(c(0.5, 0, -1, 0.5))
rownames(k) <- "A y D vs. C"
summary(multcomp::glht(anova.c, linfct = k))
Simultaneous Tests for General Linear Hypotheses
Fit: aov(formula = pH ~ tto - 1, data = data)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
A y D vs. C == 0 0.2000 0.1118 1.789 0.111
(Adjusted p values reported -- single-step method)
¡¿Y la TEF?!
En la sección 8.1 se presentó el concepto de tasa de error por familia (TEF), y se ilustró la manera en la que esta se infla al realizar más de una comparación.
Este es el problema fundamental de los PCM: se requiere incorporar un mecanismo que controle esta situación, manteniendo la TEF en un nivel que no exceda el definido por el usuario.
¿Cuál es el mecanismo que permite controlar la inflación de la TEF en la DMS?
En la literatura clásica se describe una variante de la prueba DMS, denominada DMS protegida o DMS protegida de Fisher4, que consiste en realizar las comparaciones entre medias únicamente si el ANOVA resulta significativo. Se supone que la significancia del ANOVA brinda protección contra la inflación de la TEF.
Acorde con Hochberg y Tamhane (1987), este procedimiento brinda protección únicamente en sentido débil, es decir, cuando la hipótesis nula global del ANOVA es cierta, pero no bajo otras condiciones.
Esto conduce a una situación paradójica: si todas las medias son iguales, que es el caso en el que la prueba protege contra la inflación de la TEF, lo esperable es que el ANOVA no resulte significativo y, en consecuencia, no se realicen comparaciones por pares.
En el escenario de la hipótesis alternativa, el ANOVA probablemente será significativo y se tendría interés en realizar comparaciones por pares; sin embargo, en tal caso no se dispone de protección contra la inflación de la TEF.
La realidad es que, ya sea que se realice la DMS “protegida” o la DMS sin considerar el resultado del ANOVA, esta prueba no proporciona un adecuado control de la TEF en el sentido general requerido en los PCM.
En tal sentido, resulta cuestionable incluso catalogar la DMS como un PCM.
Asimismo, los intervalos construidos con base en la DMS (cf. sección 8.4.1) no conforman un conjunto de intervalos de confianza simultánea con una confianza global del \(100(1−\alpha)\,\%\); simplemente se tienen seis intervalos con confianzas individuales del \(100(1−\alpha)\,\%\).
En consecuencia, la DMS no debe utilizarse como PCM… al menos no en la forma básica expuesta en esta sección. Sin embargo, es posible ajustarla para pasar de una “protección” meramente aparente a un verdadero control de la TEF, mediante las estrategias que se exponen en las secciones 8.9, 8.10, 8.11 y 8.12.
8.5 Prueba de Tukey
Esta prueba —también conocida como Diferencia Significativa Honesta (DSH) (Honestly Significant Difference–HSD) o Diferencia Significativa Honesta de Tukey— fue propuesta por John W. Tukey en 19535.
Acorde con Benjamini y Braun (2002), Tukey tiene todos los méritos para ser considerado uno de los pioneros en el campo de las comparaciones múltiples, habiendo moldeado en gran parte los procedimientos de inferencia simultánea, no solo en lo que a su desarrollo matemático se refiere, sino también desde su filosofía y aplicaciones prácticas.
En su artículo La filosofía de las comparaciones múltiples, Tukey se enfoca en analizar y responder varias preguntas trascendentales: ¿qué queremos que hagan las comparaciones múltiples?, ¿por qué queremos que hagan eso? y ¿cómo pueden presentarse los resultados? (Tukey, 1991).
¡La prueba de Tukey sí controla la TEF!
La prueba DSH de Tukey permite realizar las \(k(k-1)/2\) posibles comparaciones entre pares de medias manteniendo controlada la TEF.
Esta prueba se basa en la distribución de la variable aleatoria \(q\), denominada recorrido estudentizado. En este texto se utiliza el término recorrido estudentizado (traducción de studentized range), manteniendo la distinción adoptada previamente entre recorrido (range) y rango (rank). (cf. advertencia 2.1)
¿recorrido estudentizado?
El recorrido estudentizado es una función probabilística continua, similar a la normal, la ji cuadrado, la \(t\) o la \(F\), aunque menos conocida que estas por no tener un ámbito de aplicación tan amplio en el contexto inferencial.
Aunque no fue Tukey quien desarrolló esta distribución, sí fue quien la popularizó, mediante su inclusión en la prueba de la diferencia significativa honesta.
Se trata de una función asimétrica a la derecha, cuyo soporte son los reales positivos. Su forma depende de sus parámetros \(k\) —que representa el número de medias que se comparan— y \(\text{gle}\) —que representa los grados de libertad del error—.
La figura 8.4, correspondiente a tres miembros de la familia con \(\text{gle}=8,\) muestra el efecto del parámetro \(k\) sobre la forma de la distribución y, por tanto, sobre el valor crítico de \(q.\)
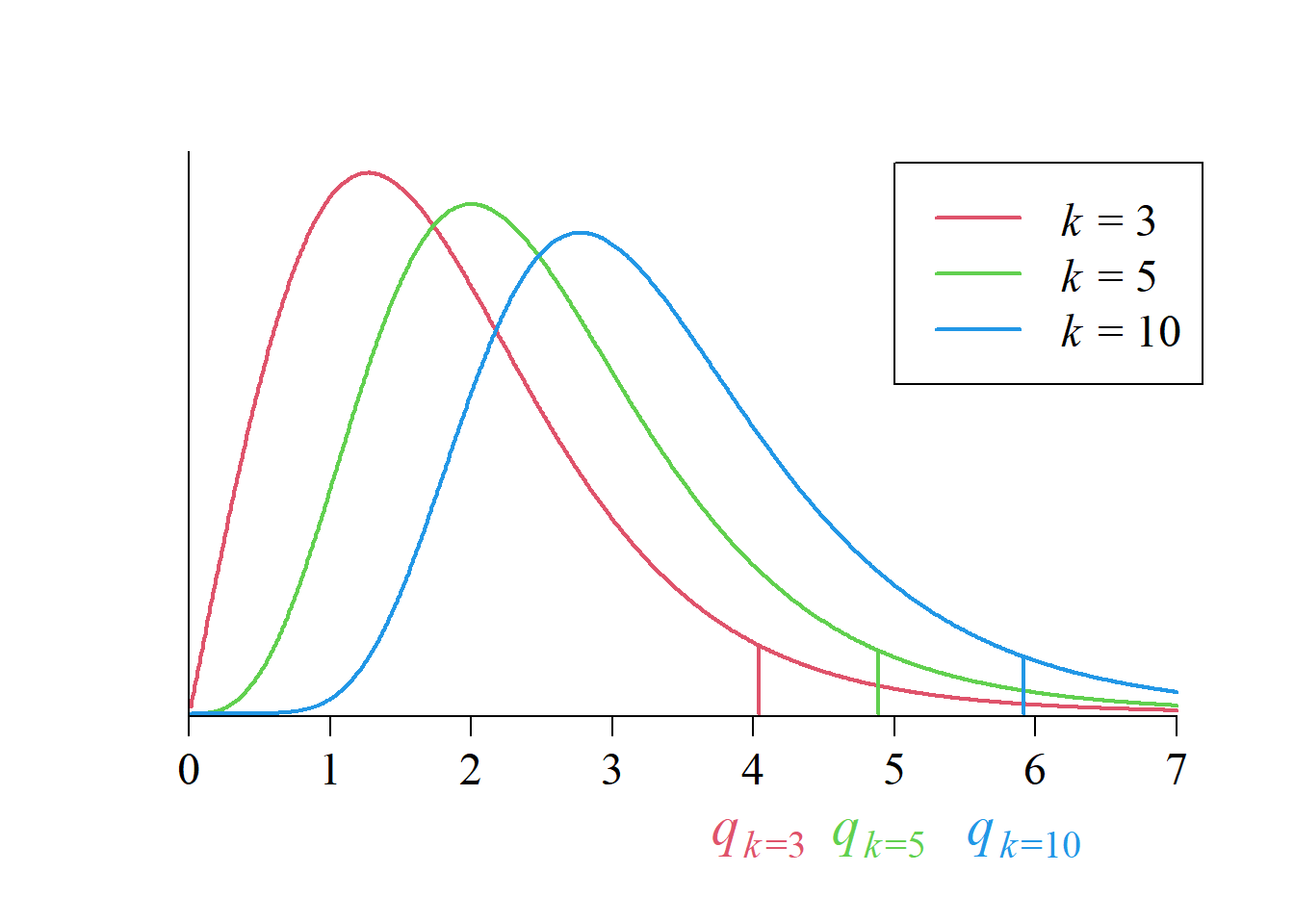
A mayor \(k,\) mayor será el número de posibles comparaciones por pares y, en consecuencia, mayor será la inflación potencial de la TEF, requiriéndose, por tanto, un mayor control sobre esta.
La figura 8.4 ilustra que dicho control se ejerce mediante un incremento en el valor crítico de \(q.\)
Aunque el parámetro de la distribución es \(k,\) el valor crítico resultante controla la TEF asociada a las \(k(k-1)/2\) posibles comparaciones por pares.
Este comportamiento refleja que la prueba de Tukey incorpora de manera implícita el número total de comparaciones en la determinación del valor crítico, en lugar de ajustar cada comparación de manera individual.
En el caso particular en que \(k=2\), siendo \(k(k-1)/2=1,\) no existe inflación de la TEF y, por tanto, no se requiere ajuste alguno. En este escenario, la prueba de Tukey coincide con la DMS.
De hecho, todos los procedimientos de comparación múltiple coinciden cuando \(k=2.\)
La variable aleatoria \(q\) se define como la razón entre la diferencia de la mayor y la menor de las medias muestrales y el estimador de la desviación estándar común de cada media muestral, denominado error estándar.
El error estándar se denota y calcula de la siguiente manera:
\[
S_{\overline{Y}}=\sqrt{\frac{\text{CME}}{r}}
\]
A partir de \(q,\) se define una diferencia significativa honesta (DSH), que debe ser igualada o superada por el valor absoluto de la diferencia entre dos medias muestrales para que la correspondiente comparación se declare significativa.
El criterio de rechazo de la prueba de Tukey se expresa de forma análoga al de la DMS, así:
\[
\text{si }\left|\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right|\ge\text{DSH}\Rightarrow \text{ rechaza } H_0
\]
Este criterio es formalmente idéntico al de la prueba de la DMS, siendo la DSH el único elemento que difiere.
La DSH se define como el producto entre el valor crítico superior del recorrido estudentizado y el error estándar.
Cuando los tratamientos tienen el mismo número de réplicas, la DSH viene dada por:
\[
\text{DSH}=q_{\alpha(k,\,\text{gle})}\sqrt{\dfrac{\text{CME}}{r}}
\]
Nota 8.2: ¿Tukey-Kramer?
Durante mucho tiempo, la prueba de Tukey se presentó en el formato para igual número de réplicas, acompañada de diferentes alternativas para adaptarla a la comparación de grupos con diferente número de réplicas.
Kramer (1956) propuso la siguiente adaptación para el cálculo del error estándar cuando los tratamientos no están basados en el mismo número de réplicas:
\[
S_{\overline{Y}}=\sqrt{\dfrac{\text{CME}}{2}\left(\dfrac{1}{r_1}+\dfrac{1}{r_2} \right)}
\]
Esto equivale a calcular el error estándar empleando la media armónica de las réplicas de los dos tratamientos comparados.
A la prueba basada en esta adaptación suele llamársele prueba de Tukey-Kramer. No obstante, Dunnett (1980a) hace notar que esta adaptación ya había sido propuesta por Tukey en 19536. Consecuentemente, autores como Abdi y Williams (2010) obvian toda referencia a Kramer.
Dunnett (1980a), quien evaluó mediante simulación varias propuestas para comparar medias cuando se tienen varianzas homogéneas y diferente número de réplicas, concluye en favor de la denominada prueba de Tukey-Kramer, por proporcionar intervalos de confianza conservadores.
Este autor desaconseja métodos alternativos, tales como el uso de la media armónica global de todas las réplicas. Hayter (1984) demuestra matemáticamente que la prueba de Tukey-Kramer es conservadora en todos los casos.
A continuación se ilustra la comparación por pares de las medias del ejemplo 7.1, usando un nivel de significancia \(\alpha = 0.05,\) que corresponde al nivel al cual se controla la TEF.
En este caso, dado que todos los tratamientos tienen igual número de réplicas, se obtiene una DSH común con base en la siguiente expresión:
\[
\text{DSH}=q_{\alpha(k,\,\text{gle})}\sqrt{\dfrac{\text{CME}}{r}}
\]
El valor crítico del recorrido estudentizado con \(k\) grupos y \(\text{gle},\) que tradicionalmente se obtenía en tablas, puede hallarse en R, mediante la función qtukey{stats}, en la cual p es el nivel de significancia, nmeans el número de tratamientos, df los grados de libertad del error y lower.tail = FALSE indica que se obtiene el valor crítico superior:
\(q_{\alpha(k,\,\text{gle})}=q_{0.05(4,\,8)}:\)
qtukey(p = 0.05, nmeans = 4, df = 8, lower.tail = FALSE)[1] 4.52881Obsérvese que, a diferencia del valor crítico de \(t\) en la DMS, el valor crítico de \(q\) depende del número de tratamientos, \(k,\) lo que permite controlar la TEF.
El error estándar viene dado por:
\[
S_{\overline{Y}}=\sqrt{\frac{\text{CME}}{r}}=\sqrt{\frac{0.025}{3}}=0.09129
\]
Luego, la DSH viene dada por:
\[
\text{DSH}=q_{\alpha(k,\,\text{gle})}\sqrt{\dfrac{\text{CME}}{r}}=4.52881\times0.09129=0.4134
\]
Se presentan a continuación los seis posibles contrastes entre pares de medias, cuyo resultado se resume en la tabla 8.5.
\[
\begin{align}
\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{B} \bullet}\right|=
\left|4.1-3.2\right|=0.9>0.4134\quad*\\[0.5em]
\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|4.1-3.8\right|=0.3<0.4134\quad\text{ns}\\[0.7em]
\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|4.1-3.9\right|=0.2<0.4134\quad\text{ns}\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|3.2-3.8\right|=0.6>0.4134\quad*\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|3.2-3.9\right|=0.7>0.4134\quad*\\[0.7em]
\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{C}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|3.8-3.9\right|=0.1<0.4134\quad\text{ns}
\end{align}
\]
| Tratamiento | \(\overline{Y}_{i\bullet}\) | Grupos |
|---|---|---|
| \(\text{A}\) | 4.1 | a |
| \(\text{D}\) | 3.9 | a |
| \(\text{C}\) | 3.8 | a |
| \(\text{B}\) | 3.2 | c |
Para el presente ejemplo, los resultados de la prueba de Tukey difieren de los de la prueba DMS (cf. tabla 8.3). En particular, la diferencia entre \(\mu_{\text{A}}\) y \(\mu_{\text{C}}\), que resulta significativa bajo la DMS, deja de serlo bajo la prueba de Tukey. Esto se debe a que el control que la prueba de Tukey ejerce sobre la TEF se logra a costa de ser más exigente o conservadora que la prueba DMS en las comparaciones individuales.
Esto quiere decir que, si bien la prueba de Tukey ejerce un mejor control sobre la probabilidad de error tipo I, tiene una menor potencia que la DMS.
¿Y, entonces?
El hecho de que la prueba de la DSH exhiba una menor potencia que la DMS en las comparaciones individuales podría hacer dudar sobre su idoneidad.
No obstante, el aspecto esencial en los procedimientos de comparación múltiple es el control de la TEF, lo que descalifica a la prueba de la DMS en estos escenarios.
La disminución de la potencia en las comparaciones individuales es el precio que paga la prueba de la DSH por el control de la TEF.
En R, la prueba de Tukey puede realizarse mediante la función HSD.test{agricolae}, siendo posible asimismo usar un fragmento de código análogo al código 8.1 para generar un gráfico con el recorrido de los tratamientos y las letras de significancia.
HSD.test(anova, "tto", console = TRUE)
Study: anova ~ "tto"
HSD Test for pH
Mean Square Error: 0.025
tto, means
pH std r se Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of Studentized Range: 4.52881
Minimun Significant Difference: 0.4134219
Treatments with the same letter are not significantly different.
pH groups
A 4.1 a
D 3.9 a
C 3.8 a
B 3.2 b
¿¡Minimum Significant Difference!?
La leyenda Minimum Significant Difference que aparece en los resultados —antes del valor 0.4134219— puede generar confusión, al sugerir que se está aplicando la DMS en lugar de la DSH. Sin embargo, este no es el caso.
Las funciones de agricolae siempre utilizan esta leyenda de manera genérica, para referirse a la diferencia mínima requerida entre medias muestrales para declarar significancia, de acuerdo con el procedimiento empleado.
En el contexto de la prueba de Tukey, este valor corresponde a la diferencia significativa honesta (DSH).
Para calcular el valor p asociado con la prueba de Tukey se tiene en cuenta el correspondiente estadístico de prueba genérico7:
\[
q_\text{c}=\dfrac{\left|\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet} \right|}{\sqrt{ \dfrac{\text{CME}}{r}}}\overset{H_0}\thicksim q_{(k,\,\text{gle})}
\]
Este estadístico mide cuántas veces la diferencia observada entre medias excede el error estándar, de manera análoga al estadístico \(t_\text{c},\) pero evaluado bajo la distribución del recorrido estudentizado.
Usando la función ptukey{stats}, se obtiene el valor p asociado a la cola superior:
ptukey(qc, nmeans = 4, df = 8, lower.tail = FALSE)La tabla 8.6 muestra el estadístico de prueba para los diferentes contrastes entre pares de medias y sus correspondientes valores p.
| Comparación | \(q_\text{c}\) | Valor p |
|---|---|---|
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}\) | 9.859006 | 0.0005 |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}\) | 3.286335 | 0.1714 |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}\) | 2.190890 | 0.4550 |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}\) | 6.572671 | 0.0072 |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}\) | 7.668116 | 0.0028 |
| \(\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}\) | 1.095445 | 0.8638 |
Nótese que los valores p obtenidos mediante la prueba de Tukey son mayores que los correspondientes valores p de la prueba DMS (cf. tabla 8.4). Esto refleja el ajuste que realiza la prueba de Tukey para controlar la TEF, lo que implica un criterio más exigente para declarar significancia.
8.5.1 Intervalos de Confianza de Tukey
Es posible obtener intervalos para todas las posibles diferencias de medias, con una confianza simultánea del \(100(1 − \alpha)\,\%,\) sumando y restando la DSH a cada diferencia de medias muestrales:
\[
\begin{align}
\text{IC}_{95\%}:&\left(\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet} \right)\pm\text{DSH}\\[1.4em]
=&\left(\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet} \right)\pm q_{\alpha(k,\,\text{gle})}\sqrt{\dfrac{\text{CME}}{2}\left(\dfrac{1}{r_i}+\dfrac{1}{r_{i'} } \right) }
\end{align}
\]
A continuación, se presentan intervalos de confianza del 95 % para las diferencias de medias del ejemplo 7.1.
\[
\begin{align}
\mu_{\text{A}}-\mu_{\text{B}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{B} \bullet}\right)
\pm \text{DSH}=0.9\pm 0.4134&:[0.4866&,\,1.3134]\:&*\\[0.5em]
\mu_{\text{A}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DSH}=0.3\pm 0.4134&:[-0.1134&,\,0.7134]\:&\text{ns}\\[0.7em]
\mu_{\text{A}}-\mu_{\text{D}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{D} \bullet}\right)
\pm \text{DSH}=0.2\pm 0.4134&:[-0.2134&,\,0.6134]\:&\text{ns}\\[0.7em]
\mu_{\text{B}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DSH}=-0.6\pm 0.4134&:[-1.0134&,\,-0.1866]\:&*\\[0.7em]
\mu_{\text{B}}-\mu_{\text{D}}&: \left(\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{D} \bullet}\right)
\pm \text{DSH}=-0.7\pm 0.4134&:[-1.1134&,\,-0.2866]\:&*\\[0.7em]
\mu_{\text{C}}-\mu_{\text{D}}&: \left(\overline{Y}_{\text{C}\bullet}-\overline{Y}_{\text{D} \bullet}\right)
\pm \text{DSH}=-0.1\pm 0.4134&:[-0.5134&,\,0.3134]\:&\text{ns}
\end{align}
\]
Nótese que todos los intervalos son más amplios que los correspondientes intervalos DMS. En virtud de ello, los intervalos HSD permiten asignar una confianza global del \(100(1−\alpha)\,\%\) al conjunto de comparaciones.
Para su obtención en R, se usa la siguiente instrucción, con base en la cual se obtienen, además de los intervalos de confianza, los valores p de la correspondiente comparación.
HSD.test(anova, "tto", group = FALSE, console = TRUE)
Study: anova ~ "tto"
HSD Test for pH
Mean Square Error: 0.025
tto, means
pH std r se Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of Studentized Range: 4.52881
Comparison between treatments means
difference pvalue signif. LCL UCL
A - B 0.9 0.0005 *** 0.4865781 1.3134219
A - C 0.3 0.1714 -0.1134219 0.7134219
A - D 0.2 0.4550 -0.2134219 0.6134219
B - C -0.6 0.0072 ** -1.0134219 -0.1865781
B - D -0.7 0.0028 ** -1.1134219 -0.2865781
C - D -0.1 0.8638 -0.5134219 0.3134219
La función TukeyHSD{stats} permite generar una representación gráfica de los intervalos de confianza simultánea para las diferencias de medias, que incluye una línea de referencia en cero, lo que ayuda a evaluar rápidamente si existe diferencia significativa entre las medias comparadas (figura 8.5).
plot(TukeyHSD(anova))
La figura 8.5 incluye los intervalos de confianza simultánea del 95 % para las seis posibles diferencias de medias del ejemplo 7.1. Aunque en este caso las diferencias se presentan en orden inverso al ejemplificado anteriormente, suministran exactamente la misma información.
Así, por ejemplo, la línea superior, que representa el intervalo de confianza para la diferencia \(\mu_\text{B} − \mu_\text{A}\) tiene sus dos límites en la región negativa8, lo que indica que la media del tratamiento \(\text{A}\) supera significativamente la media del tratamiento \(\text{B}.\) Análogamente, el intervalo para \(\mu_\text{C} − \mu_\text{B}\) tiene sus dos límites en la región positiva, lo que indica que la media del tratamiento \(\text{C}\) supera significativamente la media del tratamiento \(\text{B}.\) En contraste, el intervalo de confianza para \(\mu_\text{C} − \mu_\text{A}\) incluye el cero, lo que indica que la prueba no detecta diferencia estadísticamente significativa entre las medias de los tratamientos \(\text{C}\) y \(\text{A}.\)
Hsu y Peruggia (1994) presentan diversas alternativas de representación gráfica para la prueba de Tukey, desaconsejando algunas de ellas por no ser fieles a los resultados o por ser de difícil interpretación. Estos autores proponen una representación denominada diagrama de dispersión media-media (mean-mean scatterplot).
La figura 8.5, generada mediante la función TukeyHSD, recoge varios elementos de dicha propuesta, pudiendo interpretarse como una variante simplificada de la misma.
¿¡Y, los contrastes!?
La prueba HSD de Tukey está diseñada exclusivamente para la realización de las \(k(k-1)/2\) comparaciones por pares.
Si, además de estas comparaciones, se requiere evaluar contrastes entre grupos de medias, deberá emplearse una prueba que permita controlar la TEF en tales escenarios (cf. sección 8.6).
8.6 Prueba de Scheffé
Esta prueba, propuesta por Scheffé (1953), permite evaluar todas las posibles comparaciones —tanto entre pares de medias como entre grupos—, manteniendo controlada la TEF.
Si bien esta prueba garantiza el control de la TEF para una familia mucho más amplia de comparaciones, también presenta menor potencia en las comparaciones individuales. Por tal motivo, su uso debe reservarse para situaciones en las que, además de las comparaciones por pares, se requiera evaluar contrastes entre grupos de medias.
¡No la use para realizar únicamente comparaciones por pares!
En caso de que el interés se limite a comparaciones por pares —que es la situación más común— el propio Scheffé recomienda el uso de la prueba de Tukey, que produce intervalos de confianza más estrechos.
La prueba de Scheffé es la única que mantiene una concordancia estricta con el resultado global del ANOVA. Si el ANOVA es significativo, la prueba de Scheffé detectará al menos un contraste significativo; si no lo es, no detectará ninguno (Scheffé, 1953).
Esto la hace útil para explorar la naturaleza de las diferencias cuando, tras un ANOVA significativo, otras pruebas no identifican comparaciones específicas como significativas.
Al igual que en las pruebas presentadas en las secciones anteriores, el criterio de rechazo en la prueba de Scheffé se basa en comparar la magnitud de la diferencia observada de las medias o grupos de medias con un umbral crítico, denominado diferencia significativa de Scheffé (DSS).
La DSS para las comparaciones por pares se construye de manera similar a la DMS:
\[
\text{DSS}=\text{(valor crítico)}\times S_{\overline{Y}_{1}-\overline{Y}_{2}}
\]
El valor crítico de la prueba de Scheffé está basado en la distribución \(F\):
\[
\text{valor crítico}=\sqrt{(k-1)f_{\alpha(k-1,\,\text{gle})}}
\]
El elemento clave —que marca la diferencia con el valor crítico de la DMS— es el factor \((k-1),\) que incrementa el valor crítico para garantizar el control de la TEF sobre una familia mucho más amplia de comparaciones. En ausencia de este factor9, el valor crítico de la prueba de Scheffé coincide con el de la DMS.
El error estándar para la diferencia de medias se calcula de la misma forma que para la prueba de la DMS:
\[
S_{\overline{Y}_{1}-\overline{Y}_{2}} =\sqrt{\text{CME}\left(\dfrac{{1}}{r_1}+\dfrac{{1}}{r_2}\right)}
\]
Luego, la DSS está dada por:
\[
\text{DSS}=\sqrt{(k-1)f_{\alpha(k-1,\,\text{gle})}}\sqrt{\text{CME}\left(\dfrac{{1}}{r_1}+\dfrac{{1}}{r_2}\right)}
\]
Aunque los dos factores que conforman la DSS pueden reunirse bajo un mismo radical, es común escribirla manteniendo separado el valor crítico del error estándar de la diferencia.
La DSS al 5 % para las comparaciones por pares de las medias del ejemplo 7.1 es:
\[
\begin{align}
\text{DSS}&=\sqrt{(4-1)f_{0.05(3,\,8)}}\sqrt{0.025\left(\dfrac{{1}}{3}+\dfrac{{1}}{3}\right)}\\[1.4em]
&=3.4926\times0.1291\\[1.4em]
&=0.4509
\end{align}
\]
A continuación, se presentan los seis posibles contrastes entre pares de medias.
\[
\begin{align}
\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{B} \bullet}\right|=
\left|4.1-3.2\right|=0.9>0.4509\quad*\\[0.5em]
\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|4.1-3.8\right|=0.3<0.4509\quad\text{ns}\\[0.7em]
\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|4.1-3.9\right|=0.2<0.4509\quad\text{ns}\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|3.2-3.8\right|=0.6>0.4509\quad*\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|3.2-3.9\right|=0.7>0.4509\quad*\\[0.7em]
\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}&:\quad \left|\overline{Y}_{\text{C}\bullet}-\overline{Y}_{\text{D} \bullet}\right|=
\left|3.8-3.9\right|=0.1<0.4509\quad\text{ns}
\end{align}
\]
Aunque la DSS es mayor que la DSH (0.4509 vs. 0.4134), el resultado coincide —en términos de significancia al 5 %— con el de la prueba de Tukey. En consecuencia, el resumen de grupos homogéneos es el mismo que el de la tabla 8.5.
Este resultado ilustra que, aunque la prueba de Scheffé es más conservadora que la de Tukey, no necesariamente produce decisiones distintas en todos los casos.
El resumen de grupos homogéneos se obtiene en R mediante la función scheffe.test{agricolae}.
scheffe.test(anova, "tto", console = TRUE)
Study: anova ~ "tto"
Scheffe Test for pH
Mean Square Error : 0.025
tto, means
pH std r se Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of F: 4.066181
Minimum Significant Difference: 0.450898
Means with the same letter are not significantly different.
pH groups
A 4.1 a
D 3.9 a
C 3.8 a
B 3.2 bEs importante señalar que el valor 4.066181 que aparece en los resultados tras la leyenda Critical Value of F corresponde al valor crítico superior de la distribución \(F\) sin la corrección por el factor \((k-1);\) es decir, dicho valor es \(f_{0.05(3,\,8)}.\)
De igual forma, el valor que aparece tras la leyenda Minimum Significant Difference es la DSS; no la DMS.
El valor p asociado con la prueba de Scheffé se obtiene a partir del correspondiente estadístico de prueba, calculando el área de la cola derecha de la distribución \(F.\)
\[
F_\text{c}=\dfrac{\left(\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet}\right)^2}{(k-1)\text{CME}\left(\dfrac{{1}}{r_i}+\dfrac{{1}}{r_{i'}}\right)}\overset{H_0}\thicksim F_{(k-1,\,\text{gle})}
\]
Este estadístico mide la magnitud de la diferencia entre medias en relación con la variabilidad experimental, de manera análoga al estadístico \(t_\text{c}\) en la DMS y al estadístico \(q_\text{c}\) en la prueba de Tukey, pero ajustado para controlar la TEF sobre una familia más amplia de comparaciones.
La tabla 8.7 muestra el estadístico de prueba para los diferentes contrastes entre pares de medias y sus correspondientes valores p.
| Comparación | \(F_\text{c}\) | Valor p |
|---|---|---|
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}\) | 16.2 | 0.0009 |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}\) | 1.8 | 0.2250 |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}\) | 0.8 | 0.5279 |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}\) | 7.2 | 0.0116 |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}\) | 9.8 | 0.0047 |
| \(\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}\) | 0.2 | 0.8935 |
Nótese que los valores p obtenidos coinciden —en términos de significancia al 5 %— con los de la prueba de Tukey (cf. tabla 8.6), lo que confirma que, en este caso, el mayor conservadurismo de la prueba de Scheffé no altera las decisiones inferenciales.
8.6.1 Contrastes de Scheffé
La prueba de Scheffé está diseñada justamente para la evaluación de contrastes, admitiendo —en teoría— un número infinito de estos, sin que la TEF exceda el valor establecido por el usuario, aun cuando los contrastes no sean ortogonales ni hayan sido definidos a priori.
La evaluación se realiza —de manera análoga a la prueba de la DMS— comparando el valor absoluto del contraste estimado contra una DSS para el contraste.
El error estándar del contraste estimado se calcula así:
\[
S_\widehat\xi=\sqrt{\text{CME}\sum\limits_{i=1}^k\frac{c_i^2}{r_i}}
\]
Con base en este error estándar y el valor crítico superior de la distribución \(F\) se obtiene la DSS para el contraste.
\[
\text{DSS}_\xi=\sqrt{(k-1)f_{\alpha(k-1,\,\text{gle})}}\sqrt{\text{CME}\sum\limits_{i=1}^k{\frac{c_i^2}{r_i}}}
\]
El criterio de rechazo de la hipótesis nula se expresa así:
\[
\text{si }\left|\sum\limits_{i=1}^k c_i\overline{Y}_{i\bullet}\right|\ge\text{DSS}_\xi
\Rightarrow \text{rechaza } H_0 \text{ con un nivel de significancia }\alpha
\]
En el ejemplo 7.1, para comparar el pH medio de los tratamientos \(\text{A}\) y \(\text{D}\) (sistemas de empaque con atmósfera modificada) contra el pH medio del tratamiento \(\text{C}\) (sistema de empaque al vacío), se plantea el siguiente contraste:
\[
\xi= 0.5\mu_\text{A}-1\mu_\text{C}+0.5\mu_\text{D}
\]
El estimador del contraste para la comparación planteada \((\text{A},\text{D}\text{ vs. }\text{C})\) es:
\[
\begin{align}
\widehat\xi=& 0.5\overline{Y}_\text{A}-1\overline{Y}_\text{C}+0.5\overline{Y}_\text{D}\\[1.4em]
=&0.5\times 4.1-1\times 3.8+0.5\times3.9=0.2\\[1.4em]
\end{align}
\]
Fijando el nivel de significancia en 0.05, el valor crítico superior de la distribución \(F\) es:
\(f_{\alpha(k-1,\,\text{gle})}=f_{0.05(3,\,8)}:\)
qf(0.05, 3, 8, lower.tail = FALSE)[1] 4.066181El error estándar del contraste estimado se calcula así:
\[
\begin{align}
S_\widehat\xi=&\sqrt{\text{CME}\sum\limits_{i=1}^k \frac{c_i^2}{r_i}}\\[1.4em]
=&\sqrt{0.025\dfrac{(0.5)^2+(-1)^2+(0.5)^2}{3} }=0.1118034
\end{align}
\]
Por tanto, la DSS para el contraste es:
\[
\begin{align}
\text{DSS}_\xi&=\sqrt{(k-1)f_{\alpha(k-1,\,\text{gle})}}\sqrt{\text{CME}\sum\limits_{i=1}^k{\frac{c_i^2}{r_i}}}\\[1.4em]
&=\sqrt{3\times 4.066181}\times 0.1118034\\[1.4em]
&=0.3905
\end{align}
\]
Puesto que el valor absoluto del contraste estimado es menor que la DSS para el correspondiente contraste \((0.2 < 0.3905),\) no se rechaza la hipótesis nula con un nivel de significancia del 5 %.
En consecuencia, no puede concluirse —con una probabilidad de error máxima de 0.05— que el pH medio de la pulpa de guanábana en los sistemas de empaque basados en atmósfera modificada (tratamientos \(\text{A}\) y \(\text{D}\)) difiera del correspondiente al sistema de empaque al vacío (tratamiento \(\text{C}\)).
¡No todas las DSS son iguales!
Obsérvese que la DSS para este contraste difiere de la obtenida para las comparaciones por pares (0.3905 vs. 0.4509).
Esto se debe a que, en la prueba de Scheffé, cada contraste se evalúa con un error estándar propio, determinado por sus coeficientes.
De la misma forma en que se calculó el valor p para las comparaciones por pares, puede calcularse el valor p para el contraste.
El estadístico de prueba está dado por:
\[
\begin{align}
F_\text{c}&=\dfrac{\widehat{\xi}^2}{(k-1)\text{CME}\sum\limits_{i=1}^k\dfrac{c_i^2}{r_i}}\\[1.4em]
&=\dfrac{0.2^2}{3\times0.025\times0.5}\\[1.4em]
&=1.06667
\end{align}
\]
Valor p: pf(1.06667, 3, 8, lower.tail = FALSE) = 0.4158031.
Este valor ratifica la decisión de no rechazo con un nivel de significancia del 5 %.
Un intervalo de confianza para el contraste, que forma parte del conjunto de intervalos con una confianza global del \(100(1 − \alpha)\,\%,\) se obtiene con base en la siguiente expresión:
\[
\begin{align}
&\widehat{\xi}\pm\text{DSS}_\xi\\[1.4em]
=&\widehat{\xi}\pm\sqrt{(k-1)f_{\alpha(k-1,\,\text{gle})}}\sqrt{\text{CME}\sum\limits_{i=1}^k{\frac{c_i^2}{r_i}}}\\[1.4em]
=&0.2\pm 0.390489\\[1.4em]
\end{align}
\]
\[
[-0.1905,\;0.5905]
\]
Dado que el intervalo de confianza para \(\mu_\text{A, D}-\mu_\text{C}\) contiene el cero, se ratifica la decisión de no rechazo de la hipótesis nula.
La función personalizada scheffe facilita la realización de contrastes mediante el método de Scheffé, permitiendo evaluar simultáneamente comparaciones por pares y contrastes entre grupos de medias, junto con sus correspondientes valores p e intervalos de confianza.
Para ello, deben indicarse los coeficientes que definen el contraste, lo cual puede hacerse mediante un vector o una matriz. En este último caso, cada fila representa un contraste, lo que permite definir varios contrastes simultáneamente.
Las siguientes definiciones son equivalentes.
coef <- c(0.5, 0, -1, 0.5) # Vector
coef <- matrix(c(0.5, 0, -1, 0.5), nrow = 1) # MatrizPara realizar, por ejemplo, el contraste analizado anteriormente y un contraste adicional de los tratamientos \(\text{A},\) \(\text{C}\) y \(\text{D}\) contra el tratamiento \(\text{B},\) se define la siguiente matriz de coeficientes10:
coef <- matrix(c(0.5, 0, -1, 0.5,
1/3, -1, 1/3, 1/3),
nrow = 2, byrow = TRUE)Para personalizar las etiquetas de los contrastes, es necesario ingresar los coeficientes a través de una matriz, asingándoles nombres a sus filas. Los nombres de las filas de la matriz de coeficientes se toman como etiquetas de los contrastes:
rownames(coef) <- c("(A y D) - C", "(A, C y D) - B")La prueba de Scheffé está especialmente diseñada para la evaluación simultánea de múltiples comparaciones; en particular, para situaciones en las que, además de todas las posibles comparaciones por pares, se consideren otros contrastes entre grupos de medias.
En concordancia con ello, la función scheffe realiza todas las posibles comparaciones por pares y evalúa adicionalmente los contrastes especificados mediante coeficientes.
A continuación se ilustra el uso de la función scheffe para realizar todas las comparaciones por pares y dos contrastes adicionales entre grupos de medias:
source("scheffe.R")
coef <- matrix(c(0.5, 0, -1, 0.5,
1/3, -1, 1/3, 1/3),
nrow = 2, byrow = TRUE)
rownames(coef) <- c("(A y D) - C", "(A, C y D) - B")
scheffe(anova, coef = coef)Comparaciones múltiples mediante el método de Scheffé
estimado lwr 95% upr 95% valor p sig.
A - B 0.9000 0.4491 1.3509 0.0009 ***
A - C 0.3000 -0.1509 0.7509 0.2250
A - D 0.2000 -0.2509 0.6509 0.5279
B - C -0.6000 -1.0509 -0.1491 0.0116 *
B - D -0.7000 -1.1509 -0.2491 0.0047 **
C - D -0.1000 -0.5509 0.3509 0.8935
(A y D) - C 0.2000 -0.1905 0.5905 0.4158
(A, C y D) - B 0.7333 0.3652 1.1015 0.0009 ***8.7 Prueba de Dunnett
Esta prueba, propuesta por Dunnett (1955), permite realizar las \((k−1)\) comparaciones entre un tratamiento control y los tratamientos restantes, manteniendo controlada la TEF para esta familia de comparaciones.
En este escenario, la prueba de Dunnett es más potente que la prueba de Tukey, que controla la TEF para todas las comparaciones por pares y, por tanto, aplica un ajuste innecesariamente alto en este contexto.
¡Hasta de una cola, pero…!
A diferencia de los demás PCM, que únicamente permiten contrastar pruebas de dos colas, la prueba de Dunnett también permite evaluar pruebas de una cola.
No obstante, se recomienda usar siempre pruebas de dos colas, por las razones expuestas en la sección 5.6. Consecuentemente, en este texto solo se presenta dicha modalidad de la prueba.
Análogamente a las pruebas presentadas en las secciones anteriores, la prueba de Dunnett se realiza comparando el valor absoluto de la diferencia entre la media del control y la media del tratamiento contra la Diferencia Significativa de Dunnett (DSD).
La DSD se construye como el producto entre el valor crítico de la distribución \(t\) multivariante asociada al procedimiento de Dunnett y el error estándar de la diferencia entre la media del tratamiento control y la de los demás tratamientos.
La DSD está dada por la siguiente expresión, en la que se usa el subíndice 0 para denotar al tratamiento control:
\[
\begin{align}
\text{DSD}&=d_{\alpha(m,\,\text{gle})}S_{\overline{Y}_i-\overline{Y}_0}\\[1.4em]
&=d_{\alpha(m,\,\text{gle})}\sqrt{\text{CME}\left(\frac{1}{r_i}+\frac{1}{r_0}\right)}
\end{align}
\]
Los valores críticos de la distribución \(t\) multivariante no son de obtención trivial. Sin embargo, Dunnett (1955) los tabuló para las situaciones más comunes y posteriormente los actualizó (Dunnett, 1964), mejorando las aproximaciones.
Aunque en la actualidad es posible obtener estos valores mediante métodos numéricos, siguen siendo aproximaciones, por lo que pueden observarse pequeñas diferencias entre ejecuciones de esta prueba.
Los valores críticos de la distribución \(t\) multivariante dependen del nivel de significancia \(\alpha,\) del número de medias que se comparan contra el control, que en este contexto se denota por \(m\) y del número de réplicas de los tratamientos, lo que determina las correlaciones entre las comparaciones.
\(m\) es \((k-1)\)
En este texto se utiliza \(m\) para representar las \((k-1)\) posibles comparaciones entre el control y los demás tratamientos.
Puesto que las comparaciones que se realizan mediante la prueba de Dunnett involucran el control, estas no son independientes entre sí.
¿¡No son independientes!?
Para un experimento con cuatro tratamientos en el que el primer tratamiento es el control, las comparaciones pueden expresarse mediante contrastes con los siguientes coeficientes:
\((1, -1, 0, 0)\)
\((1, 0, -1, 0)\)
\((1, 0, 0, -1)\)
Puesto que la suma del producto de los correspondientes coeficientes es diferente de cero, no se satisface la condición de ortogonalidad (cf. advertencia 8.1). Por tanto, las comparaciones no son independientes.
Cuando se satisface la condición de homogeneidad de varianzas, la correlación entre dos hipótesis depende del número de réplicas de los tratamientos que se comparan.
La correlación entre las hipótesis que involucran el \(i\)-ésimo y el \(j\)-ésimo tratamiento es:
\[
\rho_{ii'}=\sqrt{\left(\frac{r_i}{r_0+r_i}\right)\left(\frac{r_{i'}}{r_0+r_{i'}}\right)}
\tag{8.1}\]
Puede verificarse que, cuando el control y los tratamientos tienen el mismo número de réplicas, \(\rho = 0.5.\)
Si el grupo control tiene un número de réplicas diferente al de los grupos tratados, la correlación varía, pero es igual entre todos los pares de juegos de hipótesis. Así, por ejemplo, si el grupo control tuviera 5 réplicas, mientras que los grupos tratados tuvieran 3 réplicas, \(\rho=0.375.\)
Dunnett (1955, 1964) muestra que la eficiencia de la prueba se maximiza cuando la razón \(r_0/r_i\) es ligeramente inferior a la raíz cuadrada de \(m.\) Para un experimento con 4 tratamientos, uno de los cuales sea un grupo control —lo que da lugar a 3 comparaciones contra el control— la relación 5 a 3 se acerca a dicha condición.
Para ilustrar la aplicación de la prueba de Dunnett con los datos del ejemplo 7.1, supóngase que el empaque tipo \(\text{C}\) es un tratamiento control. Consecuentemente, se evalúan los juegos de hipótesis para comparar \(\mu_\text{A} \text{ vs. } \mu_\text{C},\) \(\mu_\text{B} \text{ vs. } \mu_\text{C}\) y \(\mu_\text{D} \text{ vs. } \mu_\text{C}.\)
El valor crítico puede aproximarse mediante la distribución \(t\) multivariante, usando la función cv_dunnett (código 8.2), con los siguientes argumentos:
alpha: Nivel de significancia de la prueba, cuyo valor por defecto es 0.05.m: Número de comparaciones o hipótesis que se contrastan, es decir, \((k-1).\)df: Grados de libertad del error.rVector con las réplicas del control y los demás tratamientos11.
Los valores de r se usan para calcular la correlación, mediante la expresión 8.1.
cv_dunnett <- function(alpha = 0.05, m, df, r) {
# Validación de r ------------------------------------------------------------
if (length(r) == 1)
r <- rep(r, m + 1)
else if (length(r) == 2)
r <- c(r[1], rep(r[2], m))
else if (length(r) == (m + 1))
r <- r
else
stop("\nEl vector r no satisface las especificaciones.")
# Matriz de correlaciones ----------------------------------------------------
R <- matrix(0, m, m)
for(i in 1:m) {
for(j in 1:m) {
if(i == j) {
R[i,j] <- 1
} else {
R[i,j] <- sqrt((r[i+1]/(r[1]+r[i+1]))*(r[j+1]/(r[1]+r[j+1])))
}
}
}
# Función objetivo -----------------------------------------------------------
f <- function(c) {
as.numeric(
mvtnorm::pmvt(
lower = rep(-c, m),
upper = rep(c, m),
df = df,
corr = R
)
) - (1 - alpha)
}
# Buscar raíz ----------------------------------------------------------------
uniroot(f, lower = 0, upper = 20)$root
}cv_dunnett(alpha = 0.05, m = 3, df = 8, r = 3)[1] 2.878Por tanto, \[
\begin{align}
\text{DSD}&=d_{\alpha(m,\,\text{gle})}\sqrt{\text{CME}\left(\frac{1}{r_i}+\frac{1}{r_0}\right)}\\[1.4em]
&=d_{0.05(3,\,8)}\sqrt{0.025\left(\frac{1}{3}+\frac{1}{3}\right)}\\[1.4em]
&=2.878\times 0.1291=0.3715
\end{align}
\]
El criterio de rechazo es:
\[
\text{si }\left|\overline{Y}_i-\overline{Y}_0\right|\ge\text{DSD}\Rightarrow
\text{ rechaza }H_0\text{ con un nivel de significancia }\alpha
\]
A continuación se ilustran las tres posibles comparaciones, contra el tratamiento control, \(\text{C}.\)
\[
\begin{align}
\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|4.1-3.8\right|=0.3<0.3715\quad\text{ns}\\[0.7em]
\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|3.2-3.8\right|=0.6>0.3715\quad*\\[0.7em]
\mu_{\text{D}}\text{ vs. } \mu_{\text{C}}&:\quad \left|\overline{Y}_{\text{D}\bullet}-\overline{Y}_{\text{C} \bullet}\right|=
\left|3.9-3.8\right|=0.1<0.3715\quad\text{ns}
\end{align}
\]
Para el presente ejemplo, la mayor potencia de la prueba de Dunnett frente a la de Tukey se ve reflejada en la diferencia significativa entre los tratamientos \(\text{B}\) y \(\text{C}.\)
Para construir intervalos de confianza simultánea para las diferencias entre las medias de los grupos tratados y el grupo control, basta con restar y sumar la DSD a la diferencia de las medias muestrales.
Para el presente ejemplo, se tienen los siguientes intervalos con una confianza simultánea del 95 %:
\[
\begin{align}
\mu_{\text{A}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{A}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DSD}=0.3\pm 0.3715&:[-0.0715&,\,0.6715]\:&\text{ns}\\[0.7em]
\mu_{\text{B}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{B}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DSD}=-0.6\pm 0.3715&:[-0.9715&,\,-0.2285]\:&*\\[0.7em]
\mu_{\text{D}}-\mu_{\text{C}}&: \left(\overline{Y}_{\text{D}\bullet}-\overline{Y}_{\text{C} \bullet}\right)
\pm \text{DSD}=0.1\pm 0.3715&:[-0.2715&,\,0.4715]\:&\text{ns}
\end{align}
\]
El valor p se obtiene a partir del estadístico de prueba de Dunnett. Bajo la hipótesis nula conjunta (todas las medias de los tratamientos son iguales a la del control), el vector de estadísticos sigue, conjuntamente, una distribución \(t\) multivariante con \(\text{gle}\) y la matriz de correlaciones determinada por el número de réplicas.
\[
t_\text{c}=\frac{\overline{Y}_i-\overline{Y}_0}{\sqrt{\text{CME}\left(\frac{1}{r_i}+\frac{1}{r_0}\right)}}
\]
El valor p puede calcularse como la función de supervivencia (cf. definición 3.25) de la distribución \(t\) multivariante asociada al conjunto de comparaciones.
Es posible obtener una aproximación, mediante la función p_dunnett (código 8.3), que evalúa la probabilidad acumulada mediante integración adaptativa.
p_dunnett <- function (tc, df, r) {
m <- length(tc)
# Validación de r ------------------------------------------------------------
if (length(r) == 1)
r <- rep(r, m + 1)
else if (length(r) == 2)
r <- c(r[1], rep(r[2], m))
else if (length(r) == (m + 1))
r <- r
else
stop("\nEl vector r no satisface las especificaciones.")
# Matriz de correlaciones ----------------------------------------------------
R <- matrix(0, m, m)
for(i in 1:m) {
for(j in 1:m) {
if(i == j) {
R[i,j] <- 1
} else {
R[i,j] <- sqrt((r[i+1]/(r[1]+r[i+1]))*(r[j+1]/(r[1]+r[j+1])))
}
}
}
# Cálculo del valor p ---------------------------------------------------------
p_val <- numeric(m)
for(i in 1:m) {
p_val[i] <- 1 - as.numeric(
mvtnorm::pmvt(
lower = rep(-max(abs(tc[i])), m),
upper = rep(max(abs(tc[i])), m),
df = df,
corr = R,
algorithm = mvtnorm::GenzBretz()
)
)
}
p_val
}Los valores de \(t_\text{c}\) son los que aparecen en la segunda columna de las filas 2, 4 y 6 de la tabla 8.4.
p_dunnett(c(0.775, 2.324, 4.648), df = 8, r = 3)[1] 0.11413 0.00406 0.78332El anterior procedimiento puede realizarse a través de la función glht{multcomp}, la cual compara todos los grupos contra el primero.
En caso de que el grupo control no sea el primero, debe usarse la función relevel para restablecer el orden interno de los tratamientos.
La línea 1 carga el paquete multcomp, que contiene las funciones glht y mcp.
La línea 2 establece el tratamiento \(\text{C}\) como nivel de referencia del factor (cf. R Paso a Paso).
La línea 3 reajusta el modelo deANOVA sobre el factor con el nivel de referencia redefinido. Este modelo se emplea como primer argumento de glht para la realización de la prueba de Dunnett.
La línea 4 ejecuta el proceso central de la prueba de Dunnett.
Se obtienen los siguientes resultados:
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Dunnett Contrasts
Fit: aov(formula = pH ~ tto, data = data)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
A - C == 0 0.3000 0.1291 2.324 0.114
B - C == 0 -0.6000 0.1291 -4.648 0.004 **
D - C == 0 0.1000 0.1291 0.775 0.783
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- single-step method)
¡Únicamente para comparaciones contra el tratamiento control!
La prueba de Dunnett resulta adecuada cuando las únicas hipótesis contrastadas son las \((k-1)\) comparaciones entre el control y los demás tratamientos.
Para el ejemplo 7.1 esto implicaría que el usuario no contrastaría \(\mu_\text{A} \text{ vs. } \mu_\text{B},\) \(\mu_\text{A} \text{ vs. } \mu_\text{D}\) ni \(\mu_\text{B} \text{ vs. } \mu_\text{D}.\)
Si además de las comparaciones contra el tratamiento control, el usuario también tuviera interés en las demás comparaciones por pares, la familia de comparaciones estaría conformada por las \(k(k-1)/2\) posibles comparaciones por pares, por lo que debería usarse únicamente la prueba de Tukey.
En la ?sec-fact-cont se presenta un escenario en el que la prueba de Dunnett tiene una aplicación natural cuando se incluye un control dentro de una estructura factorial de tratamientos.
8.8 Comparaciones contra la media general
Cuando un experimento está conformado por un gran número de tratamientos, v. gr., en ensayos de variedades, de resistencia o de patogenicidad, pueden resultar muchísimas comparaciones12 y, por ende, muchos grupos homogéneos traslapantes (cf. figura 8.3), con la consiguiente dificultad para su interpretación.
En estas circunstancias, podría ser conveniente comparar la media de cada tratamiento contra la media general, con lo cual se garantiza la generación de máximo tres grupos: el de los tratamientos cuya media supera significativamente la media general, el de los que son significativamente inferiores y el de los que no difieren de esta.
Cada una de las \(k\) comparaciones entre la media de un grupo y la media general se expresa como un contraste. En un experimento con \(k\) tratamientos, la hipótesis nula para comparar la media del primer tratamiento contra la media general tiene la siguiente forma:
\[
\begin{align}
H_0:&\quad\mu_1=\frac{r_1\mu_1+r_2\mu_2+\dotsb+r_k\mu_k}{n}\\[1.4em]
:&\quad\mu_1-\sum\limits_{i=1}^k\frac{r_i}{n}\mu_i=0\\[1.4em]
:&\quad\frac{n-r_1}{n}\mu_1-\sum\limits_{i=2}^k\frac{r_i}{n}\mu_i=0\\[1.4em]
\end{align}
\]
Luego, los correspondientes coeficientes del contraste son:
\[
c_1=\frac{n-r_1}{n},\quad c_2=-\frac{r_2}{n},\dotsc,\quad c_k=-\frac{r_k}{n}
\]
En general, los coeficientes para el contraste que representa la comparación entre el \(i\)-ésimo tratamiento y la media general son:
\[
c_i=\frac{n-r_i}{n},\quad c_{i'}=-\frac{r_{i'}}{n},\quad\forall\; i \ne i'
\]
Si todos los tratamientos tienen el mismo número de réplicas, esta expresión se simplifica así:
\[
c_i=\frac{k-1}{k},\quad c_{i'}=-\frac{1}{k},\quad\forall\; i \ne i'
\]
El error estándar del contraste estimado para la comparación entre el \(i\)-ésimo tratamiento y la media general se calcula así:
\[
\begin{align}
S_{\widehat{\xi}_i}&=\sqrt{\text{CME}\sum\limits_{i=1}^k \frac{c_i^2}{r_i}}\\[1.4em]
&=\sqrt{\text{CME}\left(\dfrac{\left(\dfrac{n-r_i}{n}\right)^2}{r_i}+\sum\limits_{i' \ne i}\dfrac{\left(-\frac{r_{i'}}{n}\right)^2}{r_{i'}}\right)}\\[1.4em]
&=\sqrt{\text{CME}\left(\dfrac{1}{r_i}-\frac{2}{n}+\frac{r_i}{n^2}+\sum\limits_{i'\ne i}\dfrac{r_{i'}}{n^2}\right)}\\[1.4em]
&=\sqrt{\text{CME}\left(\dfrac{1}{r_i}-\dfrac{2}{n}+\sum\limits_{i'=1}^k\dfrac{r_{i'}}{n^2}\right)}
\end{align}
\]
Si todos los tratamientos tienen el mismo número de réplicas, el error estándar del contraste estimado para la comparación entre cualquier tratamiento y la media general se simplifica así:
\[
\begin{align}
S_\widehat{\xi}&=\sqrt{\text{CME}\left(\dfrac{1}{r}-\frac{2}{n}+\sum\limits_{i=1}^k\dfrac{r}{n^2}\right)}\\[1.4em]
&=\sqrt{\text{CME}\left(\dfrac{1}{r}-\frac{2}{n}+\frac{kr}{n^2}\right)}\\[1.4em]
&=\sqrt{\text{CME}\left(\dfrac{1}{r}-\frac{1}{n}\right)}\\[1.4em]
&=\sqrt{\text{CME}\left(\dfrac{k-1}{n}\right)}\\[1.4em]
\end{align}
\]
El estadístico de prueba se calcula como la razón entre la diferencia estimada y el error estándar del contraste:
\[
t_\text{c}=\frac{\overline{Y}_{i\bullet}-\overline{Y}_{\bullet\bullet}}{\sqrt{\text{CME}\left(\dfrac{k-1}{n}\right)}}
\overset{H_0}\thicksim t_{(\text{gle})}
\]
Para aplicar este procedimiento al ejemplo 7.1, se obtiene inicialmente la media general:
\[
\overline{Y}_{i\bullet\bullet}=\frac{4.1+3.2+3.8+3.9}{4}=3.75
\]
A continuación se calculan los estadísticos de prueba para cada una de las cuatro comparaciones.
Para la comparación entre la media del tratamiento \(\text{A}\) y la media general, el estadístico de prueba se calcula así:
\[
\begin{align}
t_\text{c}&=\frac{\overline{Y}_\text{A}-\overline{Y}_{\bullet\bullet}}{\sqrt{\text{CME}\left(\dfrac{k-1}{n}\right)}}\\[1.4em]
&=\frac{4.1-3.75}{\sqrt{0.025\left(\dfrac{4-1}{12}\right)}}\\[1.4em]
&=\frac{0.35}{0.07906}\\[1.4em]
&=4.4272
\end{align}
\]
La tabla 8.8 presenta los estadísticos de prueba para las cuatro comparaciones del ejemplo 7.1.
| Comparación | \(t_\text{c}\) |
|---|---|
| \(\mu_{\text{A}}-\text{media general}\) | 4.4272 |
| \(\mu_{\text{B}}-\text{media general}\) | −6.9570 |
| \(\mu_{\text{C}}-\text{media general}\) | 0.6325 |
| \(\mu_{\text{D}}-\text{media general}\) | 1.8974 |
Tales comparaciones pueden realizarse mediante la función glht{multcomp}, incluyendo la opción "GrandMean", mediante la cual se aplica un ajuste por multiplicidad que tiene en cuenta las correlaciones entre los contrastes (Bretz, Hothorn and Westfall, 2011), como se ilustra a continuación.
library(multcomp)
contrastes <- summary(glht(anova, linfct = mcp(tto="GrandMean")))
names(contrastes$test$coefficients) <- paste(anova$xlevels$tto,
"- Media general")
print (contrastes)
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: GrandMean Contrasts
Fit: aov(formula = pH ~ tto, data = data)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
A - Media general == 0 0.35000 0.07906 4.427 0.0075 **
B - Media general == 0 -0.55000 0.07906 -6.957 <0.001 ***
C - Media general == 0 0.05000 0.07906 0.632 0.9040
D - Media general == 0 0.15000 0.07906 1.897 0.2651
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- single-step method)Como se indicó anteriormente, los resultados pueden interpretarse en términos de un número máximo de tres grupos: los tratamientos que superan significativamente la media general, los que son significativamente menores y los que no difieren de la media general.
El signo de los valores estimados facilita la interpretación. Por la forma en la que realizan las comparaciones (tratamiento − media general):
Las comparaciones significativas con estimados positivos corresponden a tratamientos que superan a la media general (como el tratamiento \(\text{A}\))
Las comparaciones significativas con estimados negativos corresponden a tratamientos significativamente inferiores a la media general (como el tratamiento \(\text{B}\))
Las comparaciones no significativas (como las de los tratamientos \(\text{C}\) y \(\text{D}\)) indican que tales tratamientos no difieren significativamente de la media general.
La función personalizada comp_gm facilita la estructuración automática de tales grupos.
A continuación se ilustra su uso:
source("comp_gm.R")
data <- readxl::read_excel("Ejemplo 7.1.xlsx")
data$tto <- factor(data$tto)
anova <- aov(pH ~ tto, data = data)
comp_gm(anova)
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: GrandMean Contrasts
Fit: aov(formula = pH ~ tto, data = data)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
A - Media general == 0 0.35000 0.07906 4.427 0.00751 **
B - Media general == 0 -0.55000 0.07906 -6.957 < 0.001 ***
C - Media general == 0 0.05000 0.07906 0.632 0.90380
D - Media general == 0 0.15000 0.07906 1.897 0.26521
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- single-step method)
Comparaciones contra la media general (3.75)
Media Diferencia Grupo
A 4.1 0.35 mayor
D 3.9 0.15 ns
C 3.8 0.05 ns
B 3.2 -0.55 menor
---
Los grupos se estructuran con un nivel de significancia de 0.058.9 Corrección de Bonferroni
Esta corrección, basada en la desigualdad de Bonferroni13 (también conocida como desigualdad de Boole) y popularizada en el contexto de comparaciones múltiples por Dunn (1961), permite evaluar simultáneamente múltiples combinaciones lineales de medias en pruebas como la DMS, manteniendo la TEF en un nivel inferior o igual al predeterminado por el usuario.
La corrección consiste en realizar cada una de las pruebas dividiendo el nivel de significancia de la prueba original entre el número de comparaciones. Así, para evaluar \(m\) juegos de hipótesis, se realiza cada prueba con un nivel de significancia \(\alpha/m.\)
Si se empleara la corrección de Bonferroni para realizar todas las posibles comparaciones por pares, el nivel de significancia de cada comparación sería el resultante de dividir la significancia de la familia entre \(k(k−1)/2.\)
¡Aunque mejor no!
La autora es clara en señalar que su propuesta resulta ventajosa cuando se usa para evaluar un número pequeño de combinaciones lineales predeterminadas, siendo preferible usar la prueba de Tukey para la comparación de todos los pares de medias.
No obstante, es precisamente este uso el que suele dársele, ya sea por desconocimiento o por la forma en que viene implementada en los programas estadísticos.
Haciendo esta salvedad, y con el único fin de ilustrar su desempeño con respecto a otros procedimientos, se ilustra a continuación la comparación entre todos los pares de medias del ejemplo 7.1, mediante la DMS con corrección de Bonferroni.
\[
\begin{align}
\text{DMS}_\text{bon}&=t_{\frac{\alpha/2}{\textcolor{red}{k(k-1)/2}}}\sqrt{\dfrac{2\text{CME}}{r}}\\[1.4em]
&=t_{\frac{0.025}{\textcolor{red}{6}}}\sqrt{\dfrac{2\times0.025}{r}}\\[1.4em]
&=3.478879\times0.129099\\[1.4em]
&=0.4491
\end{align}
\]
Nótese que la diferencia exigida entre medias muestrales para declarar significancia es mayor que la exigida por la prueba de Tukey para este mismo ejemplo (0.4491 vs. 0.4134), lo que refleja el carácter conservador —e incluso excesivo— de esta corrección cuando se emplea para comparar todos los posibles pares de medias.
En R, la DMS con corrección de Bonferroni se obtiene mediante la función LSD.test, incluyendo la opción p.adj = "bonferroni".
LSD.test(anova, "tto", p.adj = "bonferroni", console = TRUE)
Study: anova ~ "tto"
LSD t Test for pH
P value adjustment method: bonferroni
Mean Square Error: 0.025
tto, means and individual ( 95 %) CI
pH std r se LCL UCL Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.889492 4.310508 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 2.989492 3.410508 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.589492 4.010508 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.689492 4.110508 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of t: 3.478879
Minimum Significant Difference: 0.4491214
Treatments with the same letter are not significantly different.
pH groups
A 4.1 a
D 3.9 a
C 3.8 a
B 3.2 bEl uso de la corrección queda explícito en las salidas mediante la leyenda: “P value adjustment method: bonferroni”.
Los intervalos de confianza simultánea se construyen de manera similar a lo indicado para la prueba DMS sin corrección; solo que a cada diferencia de medias se le suma y se le resta la \(\text{DMS}_\text{bon},\) tal y como puede verificarse en las salidas de R:
LSD.test(anova, "tto", p.adj = "bonferroni", group = FALSE, console = TRUE)
Study: anova ~ "tto"
LSD t Test for pH
P value adjustment method: bonferroni
Mean Square Error: 0.025
tto, means and individual ( 95 %) CI
pH std r se LCL UCL Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.889492 4.310508 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 2.989492 3.410508 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.589492 4.010508 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.689492 4.110508 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of t: 3.478879
Comparison between treatments means
difference pvalue signif. LCL UCL
A - B 0.9 0.0007 *** 0.4508786 1.3491214
A - C 0.3 0.2918 -0.1491214 0.7491214
A - D 0.2 0.9596 -0.2491214 0.6491214
B - C -0.6 0.0099 ** -1.0491214 -0.1508786
B - D -0.7 0.0038 ** -1.1491214 -0.2508786
C - D -0.1 1.0000 -0.5491214 0.3491214Cuando se usa esta corrección, se obtiene para cada prueba un valor p ajustado por multiplicidad.
De la anterior definición se desprende que si, por ejemplo, el valor p ajustado de una prueba es 0.07, dicha prueba podría declararse significativa siempre que se fije un nivel de significancia global (TEF) mayor o igual que 0.07.
El valor p ajustado permite evaluar la significancia de cada prueba, mediante su comparación con el nivel de significancia global, rechazando la hipótesis nula cuando \(\text{p}_\text{aj}\le\text{TEF}\) y no haciéndolo en caso contrario.
\[
\text{si }\text{p}_\text{aj}\le\text{TEF}\Rightarrow\text{rechaza } H_0 \text{ con un nivel de significancia }\alpha
\]
Wright (1992) realiza una completa disertación sobre los valores p ajustados para diferentes PCM. Es importante anotar que, aunque los valores p ajustados constituyen una poderosa herramienta conceptual, su uso e interpretación está estrictamente circunscrito a una prueba y una familia de hipótesis particulares, no teniendo ningún otro uso o interpretación por fuera de dicho contexto.
Para calcular el valor p ajustado por el procedimiento de Bonferroni, basta con multiplicar el valor p de cada prueba DMS por el valor usado como denominador de la significancia. En el presente caso, en que cada comparación se realiza dividiendo la significancia entre \(k(k − 1)/2 = 6,\) el valor p ajustado se obtiene como el producto entre cada valor p (cf. tabla 8.4) y dicho factor, imponiendo una restricción por cota superior en 1, es decir, haciendo 1 cualquier producto que supere la unidad.
\[
\text{p}_\text{bon}=\mathrm{mín}(m\text{p},1)
\]
¿Y para Tukey, Scheffé, Dunnett…?
Aunque la corrección de Bonferroni no está circunscrita al método de la DMS, este es el único método de los cubiertos en este capítulo que no incorpora un control explícito de la TEF, siendo, por tanto, el único método al que le sería aplicable.
Procedimientos como el de Tukey y Scheffé ya incorporan el control de la TEF por multiplicidad, no siendo procedente realizar correcciones adicionales.
8.10 Corrección de Holm
El método de Bonferroni presentado en la sección 8.9 —en el que no hay un orden establecido para la realización de las pruebas y en el que las decisiones sobre cada hipótesis no dependen de los resultados de otras— se denomina método de un solo paso (single step). En estos métodos puede decirse que todas las pruebas se realizan de manera simultánea.
En contrate, existen métodos secuenciales o métodos paso a paso (stepwise), en los que las diferentes comparaciones se realizan en una secuencia determinada, con niveles de significancia ajustados en cada paso, y donde la decisión en un paso condiciona los pasos siguientes.
Holm (1979) propone un método de rechazo secuencial basado en la corrección de Bonferroni, que asegura el control de la TEF y presenta una potencia mayor o igual que la del método de Bonferroni de un solo paso14.
Por tal motivo, su autor recomienda usar este método en todos los casos en los que —no existiendo métodos más especializados para la evaluación de las hipótesis— la corrección de Bonferroni resulte indicada.
¿¡Entonces, también es Bonferroni!?
En efecto, el método propuesto por Holm (1979) —al igual que el propuesto por Dunn (1961)— también está basado en la desigualdad de Bonferroni.
Para diferenciarlos, al método de Dunn (1961) podría denominársele corrección de Bonferroni de un solo paso, y al de Holm (1979) corrección secuencial de Bonferroni.
Sin embargo, en la práctica, suele usarse la etiqueta Bonferroni para la corrección propuesta por Dunn (1961), y Holm para la propuesta por Holm (1979). Esta son las denominaciones empleadas en este texto.
El método de Holm —así como el de Bonferroni— es bastante flexible, pudiendo aplicarse a cualquier tipo de prueba paramétrica o no paramétrica, sin imponer restricciones adicionales ni de independencia ni de ningún otro tipo, exigiendo únicamente que puedan obtenerse los valores p individuales de las pruebas que conforman la familia.
El procedimiento de Holm es de naturaleza secuencial; en particular, es un método secuencial descendente (step-down), es decir, que parte de la comparación más significativa y avanza hacia las menos significativas.
Para su aplicación, se calculan los valores p de las \(m\) diferentes pruebas DMS15 y se obtienen sus correspondientes estadísticos de orden (cf. definición 2.1), es decir, se ordenan de menor a mayor: de la hipótesis más significativa a la menos significativa.
Se decide sobre la hipótesis correspondiente al mínimo de los valores p, comparándolo con \(\alpha/m.\) Si \(\text{p}_{(1)}\le\alpha/m,\) se rechaza dicha hipótesis y se pasa a contrastar la hipótesis correspondiente al siguiente valor p, mediante la comparación de este contra \(\alpha/(m−1).\) Se continúa de la misma manera, restándole uno al denominador del nivel de significancia en cada paso, hasta haber rechazado todas las hipótesis o hasta encontrar la primera situación de no rechazo, en cuyo caso no se rechaza ninguna de las hipótesis posteriores.
¡Notación!
Para facilitar la identificación de las hipótesis, estas se indexan de acuerdo con el orden de los valores p.
Así, la hipótesis correspondiente al primer estadístico de orden de los valores p —es decir, al menor valor p— se denota \(H_{(1)},\) mientras que \(H_{(m)}\) corresponde a la hipótesis asociada al mayor valor p en un conjunto de \(m\) comparaciones.
Debe tenerse presente que esta notación constituye un cierto abuso, dado que las hipótesis no son valores numéricos susceptibles de ordenamiento; sin embargo, resulta conveniente para asociar cada hipótesis con el orden de su valor p.
Sintéticamente, el método de Holm puede describirse con base en el siguiente criterio de decisión, mediante el cual se evalúa secuencialmente cada hipótesis, empezando con \(H_{(1)}:\)
\[
\begin{equation}
\text{criterio}
\begin{cases}
\text{si } \text{p}_{(i)}\le\dfrac{\alpha}{m-i+1}\Rightarrow\text{rechaza }H_{(i)}\text{ e incrementa } i\text{ en una unidad},\\
\\
\text{si } \text{p}_{(i)}>\dfrac{\alpha}{m-i+1}\Rightarrow\text{no rechaza }H_{(j)},\quad j=i, i+1, \dotsc, m.\\
\end{cases}
\end{equation}
\]
A continuación, se describe paso a paso el procedimiento para todas las posibles comparaciones por pares entre las medias del ejemplo 7.1, usando un nivel de significancia \(\alpha=0.05.\) Los resultados se compilan en la tabla 8.9.
Se compara \(\text{p}_{(1)}\) contra \(\alpha/6.\) Dado que \(0.000116 < 0.0083,\) se rechaza \(H_{(1)}.\)
Se compara \(\text{p}_{(2)}\) contra \(\alpha/5.\) Dado que \(0.000629 < 0.01,\) se rechaza \(H_{(2)}.\)
Se compara \(\text{p}_{(3)}\) contra \(\alpha/4.\) Dado que \(0.001650 < 0.0125,\) se rechaza \(H_{(3)}.\)
Se compara \(\text{p}_{(4)}\) contra \(\alpha/3.\) Dado que \(0.048630 > 0.0166,\) no se rechaza \(H_{(4)}.\)
No se rechaza ninguna de las hipótesis con valores p mayores que \(\text{p}_{(4)}\): ni \(H_{(5)}\) ni \(H_{(6)}.\) Las rayas (—) en la tabla 8.9 indican que las correspondientes hipótesis no se evalúan, debido al criterio de parada derivado del no rechazo de \(H_{(4)}.\)
| Paso | Comparación | Hipótesis | Valor p DMS | \(\text{p}_{(i)}\) | \(\dfrac{\alpha}{m-i+1}\) | Significancia |
|---|---|---|---|---|---|---|
| 1 | \(\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}\) | \(H_{(1)}\) | 0.000116 | \(\text{p}_{(1)}\) | 0.05/6=0.0083 | * |
| 4 | \(\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}\) | \(H_{(4)}\) | 0.048630 | \(\text{p}_{(4)}\) | 0.05/3=0.0166 | \(\text{ns}\) |
| 5 | \(\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}\) | \(H_{(5)}\) | 0.159927 | \(\text{p}_{(5)}\) | — | \(\text{ns}\) |
| 3 | \(\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}\) | \(H_{(3)}\) | 0.001650 | \(\text{p}_{(3)}\) | 0.05/4=0.0125 | * |
| 2 | \(\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}\) | \(H_{(2)}\) | 0.000629 | \(\text{p}_{(2)}\) | 0.05/5=0.0100 | * |
| 5 | \(\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}\) | \(H_{(6)}\) | 0.460855 | \(\text{p}_{(6)}\) | — | \(\text{ns}\) |
En el presente ejemplo, la potencia del método de Holm se refleja en que produce exactamente los mismos rechazos que la prueba DMS sin corrección, pero con la ventaja adicional de mantener controlada la TEF. Esta coincidencia, sin embargo, no es general y depende de la configuración particular de los valores p.
Los valores p ajustados se obtienen de manera secuencial, multiplicando cada valor p de la DMS por \((m − i + 1),\) iniciando con \(\text{p}_{(1)}\) y avanzando hacia los mayores estadísticos de orden. Al igual que en el método de Bonferroni, se impone la restricción por cota superior en 1, remplazando por 1 cualquier producto que supere la unidad.
Una primera aproximación al ajuste está dada por:
\[
\text{p}_\text{holm(i)}=\mathrm{mín}((m − i + 1)\text{p}_{(i)},\,1)
\]
Para garantizar la monotonicidad del procedimiento es necesario verificar que el valor p ajustado en cada paso sea mayor o igual que el valor p ajustado en el paso anterior.
¿¡Monotonicidad!?
Los métodos habituales de ajuste de los valores p respetan el orden de las significancias de las hipótesis.
Sería incoherente, por ejemplo, un método en el que, para dos hipótesis cualesquiera \(H_1\) y \(H_2\), si inicialmente \(H_1\) fuera más significativa que \(H_2\), tras el ajuste \(H_2\) resultara más significativa que \(H_1.\)
El procedimiento de Holm garantiza la siguiente relación:
| \(\text{p}_{(1)}\) | \(\le\) | \(\text{p}_{(2)}\) | \(\le\) | \(\cdots\) | \(\le\) | \(\text{p}_{(m)}\) |
| \(\updownarrow\) | \(\updownarrow\) | \(\updownarrow\) | ||||
| \(H_{(1)}\) | \(H_{(2)}\) | \(H_{(m)}\) | ||||
| \(\updownarrow\) | \(\updownarrow\) | \(\updownarrow\) | ||||
| \(\text{p}_{\text{holm}(1)}\) | \(\le\) | \(\text{p}_{\text{holm}(2)}\) | \(\le\) | \(\cdots\) | \(\le\) | \(\text{p}_{\text{holm}(m)}\) |
El proceso de ajuste de los valores p se sintetiza así:
\[
\begin{equation}
\text{p}_{\text{holm}(i)}=
\begin{cases}
(m-i+1)\text{p}_{(i)}, &\text{si }(m-i+1)\text{p}_{(i)}\le1\text{ y }(m-i+1)\text{p}_{(i)}>\text{p}_{\text{holm}(i-1)},\\
\\
\text{p}_{\text{holm}(i-1)}, &\text{si }(m-i+1)\text{p}_{(i)}\le1\text{ y }(m-i+1)\text{p}_{(i)}\le\text{p}_{\text{holm}(i-1)},\\
\\
1, &\text{si }(m-i+1)\text{p}_{(i)}>1.
\end{cases}
\end{equation}
\]
A continuación, se describe paso a paso el procedimiento de obtención de los valores p ajustados, para todas las posibles comparaciones por pares entre las medias del ejemplo 7.1.
Puesto que, en el presente ejemplo, en todos los pasos se obtienen valores mayores que el anterior y menores que 1, ninguna de las restricciones de procedimiento —ni la de monotonicidad ni la de cota superior en 1— entre en juego. Por lo tanto, todos los ajustes se obtienen simplemente multiplicando \(\text{p}_{(i)}\) por \(m−i+1.\)
Los resultados se compilan en la tabla 8.10.
\(\text{p}_{\text{holm}(1)}=(6 − 1 + 1)\text{p}_{(1)}=6\text{p}_{(1)}=6\times0.000116=0.000696\)
\(\text{p}_{\text{holm}(2)}=(6 − 2 + 1)\text{p}_{(2)}=5\text{p}_{(2)}=5\times0.000629=0.003145\)
\(\text{p}_{\text{holm}(3)}=(6 − 3 + 1)\text{p}_{(3)}=4\text{p}_{(3)}=4\times0.001650=0.006600\)
\(\text{p}_{\text{holm}(4)}=(6 − 4 + 1)\text{p}_{(4)}=3\text{p}_{(4)}=3\times0.048630=0.14589\)
\(\text{p}_{\text{holm}(5)}=(6 − 5 + 1)\text{p}_{(5)}=2\text{p}_{(5)}=2\times0.159927=0.319854\)
\(\text{p}_{\text{holm}(6)}=(6 − 6 + 1)\text{p}_{(6)}=1\text{p}_{(6)}=1\times0.460855=0.460855\)
| Comparación | Hipótesis | Valor p DMS | \(\text{p}_{(i)}\) | Valor p ajustado |
|---|---|---|---|---|
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{B}}\) | \(H_{(1)}\) | 0.000116 | \(\text{p}_{(1)}\) | \(6\text{p}_{(1)}=0.000696\) |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{C}}\) | \(H_{(4)}\) | 0.048630 | \(\text{p}_{(4)}\) | \(3\text{p}_{(4)}=0.14589\) |
| \(\mu_{\text{A}}\text{ vs. } \mu_{\text{D}}\) | \(H_{(5)}\) | 0.159927 | \(\text{p}_{(5)}\) | \(2\text{p}_{(5)}=0.319854\) |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{C}}\) | \(H_{(3)}\) | 0.001650 | \(\text{p}_{(3)}\) | \(4\text{p}_{(3)}=0.006600\) |
| \(\mu_{\text{B}}\text{ vs. } \mu_{\text{D}}\) | \(H_{(2)}\) | 0.000629 | \(\text{p}_{(2)}\) | \(5\text{p}_{(2)}=0.003145\) |
| \(\mu_{\text{C}}\text{ vs. } \mu_{\text{D}}\) | \(H_{(6)}\) | 0.460855 | \(\text{p}_{(6)}\) | \(1\text{p}_{(6)}=0.460855\) |
Los valores p ajustados que aparecen en la última columna de la tabla 8.10 se comparan contra el nivel de significancia elegido (\(\alpha=0.05\) en el presente ejemplo) para decidir sobre la significancia de cada comparación.
Es importante recordar que los valores p ajustados solo tienen sentido dentro del PCM específico y de la familia de comparaciones considerada.
Para aplicar este procedimiento en R, se incluye la opción p.adj = "holm" en la función LSD.test.
LSD.test(anova, "tto", p.adj = "holm", group = FALSE, console = T)
Study: anova ~ "tto"
LSD t Test for pH
P value adjustment method: holm
Mean Square Error: 0.025
tto, means and individual ( 95 %) CI
pH std r se LCL UCL Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.889492 4.310508 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 2.989492 3.410508 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.589492 4.010508 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.689492 4.110508 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of t: 3.478879
Comparison between treatments means
difference pvalue signif.
A - B 0.9 0.0007 ***
A - C 0.3 0.1459
A - D 0.2 0.3199
B - C -0.6 0.0066 **
B - D -0.7 0.0031 **
C - D -0.1 0.4609 En el resultado anterior es notoria la ausencia de intervalos de confianza. Esto se debe a que el método de Holm no permite construir intervalos de confianza simultánea bilaterales en el sentido tradicional de procedimientos como el de Tukey, ya que su estructura secuencial fue concebida para pruebas de hipótesis.
No obstante, autores como Strassburger y Bretz (2008) y Guilbaud (2008) han elaborado propuestas para la construcción de límites de confianza unilaterales compatibles con la decisión de la prueba. Este enfoque permite determinar qué tan lejos estuvieron las hipótesis no rechazadas de alcanzar el rechazo. Sin embargo, estos límites resultan poco informativos para las comparaciones que sí son significativas.
La aplicación de la corrección de Holm no está limitada a los valores p provenientes de la prueba DMS. Este procedimiento es aplicable a cualquier tipo de prueba paramétrica o no paramétrica, exigiendo únicamente que puedan obtenerse por separado los valores p de cada una de las pruebas. Desde luego, la prueba original no deberá imponer correcciones para el control de la TEF, pues en tal caso se estaría aplicando una doble corrección.
La función p.adjust{stats} permite aplicar la corrección de Holm sobre cualquier vector numérico de valores p.
Para las seis comparaciones por pares del ejemplo 7.1, el ajuste de los valores p ajustados se realiza así (cf. tabla 8.10):
p.adjust(c(0.000116, 0.048630, 0.159927, 0.001650, 0.000629, 0.460855), method = "holm")[1] 0.000696 0.145890 0.319854 0.006600 0.003145 0.460855Puesto que en el ejemplo 7.1, la corrección de Holm no activa ni la corrección por monotonicidad ni la de cota superior en 1, a continuación se presenta un miniejemplo que ilustra estos aspectos.
Supóngase que se comparan 6 hipótesis mediante una prueba DMS y se obtienen los correspondientes valores p, tras lo cual se aplica la corrección de Holm.
A continuación se describe el procedimiento paso a paso. En cada paso se calcula inicialmente el valor candidato \((m-i+1)\text{p}_{(i)}\). Este valor no se adopta automáticamente como valor p ajustado, sino que debe verificarse que satisfaga las restricciones de monotonicidad y de cota superior en 1. De no ser así, se reemplaza conforme a dichas restricciones. Los resultados se compilan en la tabla 8.11.
\(6\text{p}_{(1)}=6\times0.0003=0.0018\). Por tratarse del primer valor ajustado, no hay lugar a comparación con el anterior para verificar monotonicidad. En este caso únicamente se verifica que se satisfaga la restricción por cota superior en 1. Dado que \(0.0018<1,\) \(\text{p}_{\text{holm}(1)}=0.0018.\)
\(5\text{p}_{(2)}=5\times0.0011=0.0055.\) Dado que \(0.0018<0.0055<1,\) \(\text{p}_{\text{holm}(2)}=0.0055.\)
\(4\text{p}_{(3)}=4\times0.0389=0.1556.\) Dado que \(0.0055<0.1556<1,\) \(\text{p}_{\text{holm}(3)}=0.1556.\)
\(3\text{p}_{(4)}=3\times0.0487=0.1461.\) Dado que \(0.1461<0.1556,\) se hace necesario activar la restricción por monotonicidad. Por tanto, \(\text{p}_{\text{holm}(4)}=0.1556.\)
\(2\text{p}_{(5)}=2\times0.6892=1.3784.\) En este caso se activa la restricción por cota superior en 1, puesto que el valor excede la unidad. Por tanto, \(\text{p}_{\text{holm}(5)}=1.\)
Por restricción de monotonicidad, se requiere que \(\text{p}_{\text{holm}(6)}\ge\text{p}_{\text{holm}(5)}.\) Asimismo, por restricción de cota superior en 1, se requiere que \(\text{p}_{\text{holm}(6)}\le 1.\) El único valor que satisface simultáneamente ambas restricciones es 1, por lo que \(\text{p}_{\text{holm}(6)}=1.\)
| Estadísticos de orden | Valores \(\text{p}\) DMS | Valores \(\text{p}_{\text{holm}}\) |
|---|---|---|
| \(\text{p}_{(1)}\) | 0.0003 | 0.0018 |
| \(\text{p}_{(2)}\) | 0.0011 | 0.0055 |
| \(\text{p}_{(3)}\) | 0.0389 | 0.1556 |
| \(\text{p}_{(4)}\) | 0.0487 | 0.1556 |
| \(\text{p}_{(5)}\) | 0.6892 | 1 |
| \(\text{p}_{(6)}\) | 0.8745 | 1 |
Los anteriores resultados pueden verificarse en R, mediante la siguiente instrucción:
p.adjust(c(0.0003, 0.0011, 0.0389, 0.0487, 0.6892, 0.8745), method = "holm")[1] 0.0018 0.0055 0.1556 0.1556 1.0000 1.0000
¿Bonferroni o Holm?
El método de Bonferroni se presenta como antesala del método de Holm, por ser más directo en su aplicación y por haber gozado de mayor popularidad durante mucho tiempo.
No obstante, recomendamos el método de Holm —por su mayor potencia— en todos los casos en los que la corrección de Bonferroni resulte indicada.
Solo si la obtención de los intervalos de confianza fuera de alto interés, podría considerarse el método de Bonferroni.
Digresión sobre Holm-Šidák
En la sección 8.1 se mostró que la probabilidad de cometer al menos un error tipo I cuando se realizan \(m\) comparaciones independientes es \(1-(1-\alpha_\text{c})^m.\)
Para establecer la restricción de cometer al menos un error tipo I en una familia de comparaciones independientes, debe satisfacerse la siguiente identidad:
\[
\text{TEF}=1-(1-\alpha_\text{c})^m
\]
Al despejar \(\alpha_\text{c},\) aparece la condición que debe satisfacer cada una de las pruebas individuales para mantener controlada la TEF a un nivel determinado:
\[
\begin{align}
(1-\alpha_\text{c})^m&=1-\text{TEF}\\[1.4em]
\alpha_\text{c}&=1-(1-\text{TEF})^{1/m}\\[1.4em]
\end{align}
\]
Luego, cada comparación individual debe realizarse con un nivel de significancia igual a \(1-(1-\text{TEF})^{1/m}.\)
Esta expresión, aunque había sido perfilada por Dunn (1958, 1959), fue popularizada por Šidák (1967), quien demostró que la conjetura de Dunn era generalizable a situaciones más amplias que las consideradas originalmente por esta autora. Por tal razón, a esta expresión se le conoce como ecuación de Šidák. Games (1977) reforzó esta idea, al señalar que —aunque el desarrollo parte de pruebas independientes— el uso de esta expresión proporciona una cota superior válida de la TEF para cualquier conjunto de contrastes, sean ortogonales o no.
Holm (1979) menciona este recurso como una posible extensión de su propuesta, indicando que su implementación computacional sería tan simple como la de aplicar la corrección de Bonferroni de manera secuencial, bastando con remplazar las constantes de comparación \(\alpha/m,\) \(\alpha/(m-1),\dotsc,\) \(\alpha/1\) por \(1-(1-\alpha)^{1/m},\) \(1-(1-\alpha)^{1/(m-1)},\dotsc,\) \(1-(1-\alpha)^1.\) Sin embargo, no discute los resultados de Šidák (1967) ni de Games (1977), y prefiere desarrollar su propuesta por la vía de las desigualdades aditivas, tradicionalmente consideradas más generales y directamente aplicables sin requerir supuestos adicionales sobre la estructura de dependencia.
Abdi (2010) rescata la idea de acoplar el procedimiento secuencial de Holm con la aproximación de Šidák, y lo denomina procedimiento Holm-Šidák. No obstante, justifica esta integración bajo otro enfoque. Partiendo de la desigualdad de Šidák como el caso más general, presenta a Bonferroni como una aproximación más simple, haciendo notar que es el primer término lineal de la expansión de Taylor de la desigualdad de Šidák. Concluye que la aproximación de Bonferroni probablemente es más conocida y citada debido a la facilidad para su cálculo.
Tanto Holm (1979) como Abdi (2010) señalan que los resultados obtenidos a partir de estas dos aproximaciones son muy cercanos entre sí. Y, en efecto, esto es así, tal y como se ilustra en la tabla 8.12, en la que se muestra el alfa corregido mediante ambas aproximaciones, así como la diferencia entre las correspondientes correcciones.
| Comparaciones | Alfa corregido Bonferroni | Alfa corregido Šidák | Diferencia |
|---|---|---|---|
| 1 | 0.050000 | 0.050000 | 0.000000 |
| 2 | 0.025000 | 0.025321 | 0.000321 |
| 4 | 0.012500 | 0.012741 | 0.000241 |
| 8 | 0.006250 | 0.006391 | 0.000141 |
| 16 | 0.003125 | 0.003201 | 0.000076 |
| 32 | 0.001563 | 0.001602 | 0.000039 |
| 64 | 0.000781 | 0.000801 | 0.000020 |
| 128 | 0.000391 | 0.000401 | 0.000010 |
| 256 | 0.000195 | 0.000200 | 0.000005 |
| 512 | 0.000098 | 0.000100 | 0.000003 |
| 1024 | 0.000049 | 0.000050 | 0.000001 |
Se observa que —excepto en el caso trivial de \(m=1\), donde no hay lugar a ninguna corrección— el alfa corregido mediante el procedimiento de Šidák es ligeramente mayor que el correspondiente valor corregido mediante el procedimiento de Bonferroni, lo que le confiere una ligera ventaja en potencia al procedimiento basado en la corrección de Šidák.
La máxima diferencia se presenta cuando \(m=2\) y es de 0.000321. A medida que se incrementa el número de comparaciones esta diferencia se hace cada vez más pequeña.
En conclusión, dado que la aproximación de Šidák proporciona una cota superior válida de la TEF aun en escenarios de comparaciones dependientes, el procedimiento secuencial Holm-Šidák conserva la misma validez general que el procedimiento de Holm-Bonferroni y domina en potencia al procedimiento original. No obstante, las diferencias en potencia entre ambos procedimientos son despreciables.
Probablemente, que Holm-Bonferroni sea el método propuesto originalmente por su autor, que esté implementado a través de p.adjust(..., method = "holm") y que sus resultados difieran muy poco de los que se obtendrían con el método de Holm-Šidák, constituyen las principales razones por las que el método Holm-Bonferroni es más utilizado y reportado.
8.11 Corrección de Hochberg
Hochberg (1988) propone un procedimiento, basado en el método de Simes (1986), que puede ser igual o más potente que el procedimiento de Holm, manteniendo controlada la TEF en los contextos para los cuales fue propuesto.
Se trata de un método secuencial ascendente (step-up), que parte de la comparación menos significativa (el valor p más alto), avanzando en cada paso hacia las más significativas.
Inicialmente, se obtienen los valores p de las \(m\) diferentes pruebas DMS y sus correspondientes estadísticos de orden. Se decide sobre la hipótesis con el mayor valor p, comparándolo contra \(\alpha\). Si \(\text{p}_{(m)}\le\alpha,\) se rechazan todas las hipótesis. En caso contrario, se continúa con la siguiente hipótesis; si \(\text{p}_{(m-1)}\le\alpha/2,\) se rechaza esa hipótesis y las que tengan menores valores p. Se continúa de la misma manera hasta encontrar el primer valor que satisfaga el criterio de rechazo o hasta completar todas las comparaciones.
El método puede describirse sintéticamente de la siguiente manera:
Empezando con \(\text{p}_{(m)},\) evaluar:
\[
\begin{equation}
\text{criterio}
\begin{cases}
\text{si } \text{p}_{(i)}\le\dfrac{\alpha}{m-i+1}\Rightarrow\text{rechaza }H_{(j)},\quad j=i, i-1, \dotsc, 1.\\
\\
\text{si } \text{p}_{(i)}>\dfrac{\alpha}{m-i+1}\Rightarrow\text{no rechaza }H_{(i)} \text{ y disminuye } i\text{ en una unidad}.\\
\end{cases}
\end{equation}
\]
Para el ajuste de los valores p, se parte de \(\text{p}_{(m)},\) avanzando hacia los menores estadísticos de orden, multiplicando cada valor p de la DMS por \((m − i + 1),\) así:
\[
\begin{equation}
\text{p}_{\text{hoch}(i)}=
\begin{cases}
(m-i+1)\text{p}_{(i)}, &\text{si }(m-i+1)\text{p}_{(i)}\le1\text{ y }(m-i+1)\text{p}_{(i)}\le\text{p}_{\text{hoch}(i+1)},\\
\\
\text{p}_{\text{hoch}(i+1)}, &\text{si }(m-i+1)\text{p}_{(i)}\le1\text{ y }(m-i+1)\text{p}_{(i)}>\text{p}_{\text{hoch}(i+1)},\\
\\
1, &\text{si }(m-i+1)\text{p}_{(i)}>1.
\end{cases}
\end{equation}
\]
Para aplicar este procedimiento en R, se incluye la opción p.adj = "hochberg" en la función LSD.test o bien se usan los valores p como primer argumento de la función p.adjust, agregando el argumento method = "hochberg".
Para el ejemplo 7.1, el método de Hochberg produce exactamente los mismos resultados que el método de Holm, por lo que su presentación no aportaría información adicional. Este es uno de esos casos en los que ambos métodos son igualmente potentes.
El método de Hochberg, al ser de tipo secuencial, tampoco genera intervalos de confianza simultánea.
A continuación se ilustra el procedimiento paso a paso —tanto por el método de Holm, como por el de Hochberg— de un hipotético ejemplo en el que el método de Hochberg es más potente que el método de Holm. Los resultados se compilan en la tabla 8.13.
Procedimiento de Holm:
Se compara \(\text{p}_{(1)}\) contra \(\alpha/6.\) Dado que \(0.044 > \frac{0.05}{6}=0.0083,\) no se rechaza \(H_{(1)}.\)
No se rechazan las hipótesis con valores p mayores que \(\text{p}_{(1)},\) es decir, ninguna de las hipótesis.
Procedimiento de Hochberg:
Se compara \(\text{p}_{(6)}\) contra \(\alpha.\) Dado que 0.049 < 0.05, se rechaza \(H_{(6)}.\)
Se rechazan las hipótesis con valores p menores que \(\text{p}_{(6)},\) es decir, todas las hipótesis restantes.
| Rango | \(H_{(i)}\) | \(\text{p}_{(i)}\) | Valor p | \(\alpha/(m − i + 1)\) | Significancia Holm | Significancia Hochberg |
|---|---|---|---|---|---|---|
| 1 | \(H_{(1)}\) | \(\text{p}_{(1)}\) | 0.044 | 0.0083 | \(\text{ns}\) | * |
| 2 | \(H_{(2)}\) | \(\text{p}_{(2)}\) | 0.045 | 0.0100 | \(\text{ns}\) | * |
| 3 | \(H_{(3)}\) | \(\text{p}_{(3)}\) | 0.046 | 0.0125 | \(\text{ns}\) | * |
| 4 | \(H_{(4)}\) | \(\text{p}_{(4)}\) | 0.047 | 0.0166 | \(\text{ns}\) | * |
| 5 | \(H_{(5)}\) | \(\text{p}_{(5)}\) | 0.048 | 0.0250 | \(\text{ns}\) | * |
| 6 | \(H_{(6)}\) | \(\text{p}_{(6)}\) | 0.049 | 0.0500 | \(\text{ns}\) | * |
A continuación se ilustra el procedimiento paso a paso para el ajuste de los valores p por ambos métodos:
Ajuste de los valores p mediante el procedimiento de Holm:
\((m−i+1)\text{p}_{(1)}=(6−1+1)0.044=6\times0.044=0.264.\) Luego, \(\text{p}_{\text{holm}(1)}=0.264.\)
\((m−i+1)\text{p}_{(2)}=(6−2+1)0.045=5\times0.045=0.225.\) Puesto que \(0.225<0.264,\) se activa la restricción por monotonicidad. Por tanto, \(\text{p}_{\text{holm}(2)}=0.264.\)
Puede verificarse que, en todos los casos restantes, el producto entre \((m−i+1)\) y los demás estadísticos de orden de los valores p es menor que 0.264, por lo que —por restricción de monotonicidad— todos los valores p ajustados por el método de Holm se hacen iguales a 0.264.
p.adjust(c(0.044, 0.045, 0.046, 0.047, 0.048, 0.049), method = "holm")[1] 0.264 0.264 0.264 0.264 0.264 0.264Ajuste de los valores p mediante el procedimiento de Hochberg:
\((m−i+1)\text{p}_{(6)}=(6−6+1)0.049=1\times0.049=0.049.\) Luego, \(\text{p}_{\text{hoch}(6)}=0.049.\)
\((m−i+1)\text{p}_{(5)}=(6−5+1)0.048=2\times0.048=0.096.\) Por restricción de monotonicidad, dado que \(0.096>0.049,\) \(\text{p}_{\text{hoch}(5)}=0.049.\)
Puede verificarse que el producto entre \((m−i+1)\) y los demás estadísticos de orden de los valores p es mayor que 0.049 en todos los casos restantes, por lo que —por restricción de monotonicidad— todos los valores p ajustados por el método de Hochberg se hacen iguales a 0.049.
p.adjust(c(0.044, 0.045, 0.046, 0.047, 0.048, 0.049), method = "hochberg")[1] 0.049 0.049 0.049 0.049 0.049 0.049La disimilitud entre los ajustes generados por los métodos de Holm y de Hochberg resalta lo indicado anteriormente en cuanto a que los valores p ajustados únicamente se usan para evaluar significancia en el contexto de un conjunto de pruebas y un método determinado, sin que tengan ningún otro uso o interpretación por fuera de dicho contexto.
Nota 8.3: ¿Holm o Hochberg?
El procedimiento de Hochberg es uniformemente al menos tan potente como el de Holm. Esta mayor potencia —ilustrada de manera dramática en el ejemplo de esta sección— podría hacer creer que la elección es obvia. No obstante, deben considerarse otros aspectos.
El método de Hochberg, al estar basado en el método de Simes (1986), hereda tanto sus ventajas como sus limitaciones.
Simes parte de un marco conceptual de pruebas independientes en el que demuestra que su procedimiento tiene una cota máxima de probabilidad de error tipo I igual a \(\alpha.\) Asimismo, muestra —mediante simulación— que en escenarios de pruebas correlacionadas positivamente, el procedimiento se vuelve conservador16, pero no tanto como el procedimiento clásico de Bonferroni. Este resultado es ratificado formalmente por Sarkar (1998).
Block, Savits y Wang (2008) demuestran que este comportamiento se invierte ante ciertas formas de dependencia negativa, con lo cual, la prueba se vuelve anticonservadora, es decir, la probabilidad de error tipo I resulta mayor que la significancia nominal.
No obstante, Gou y Tamhane (2018) conjeturan que, por el conservadurismo implícito en la construcción del procedimiento de Hochberg, este suele mantenerse por debajo del nivel de significancia nominal, aun en muchas situaciones prácticas de dependencias negativas. Mediante simulación estos autores muestran la validez de su conjetura para una amplia gama de escenarios.
En consecuencia, si se requiere garantía sobre del conservadurismo del procedimiento17 para cualquier situación, debe usarse el procedimiento de Holm.
Si resulta admisible el uso de un procedimiento conservador en la mayoría de las situaciones prácticas —que eventualmente pudiera volverse anticonservador en casos muy particulares— puede considerarse el uso del procedimiento de Hochberg.
8.12 Corrección de Hommel
Hommel (1988) propone un procedimiento de comparación múltiple basado en el método de Simes (1986), que brinda mayor potencia y mantiene controlada la TEF bajo los mismos supuestos de independencia o dependencia positiva.
El método de Hommel, al igual que el de Hochberg, se basa en la prueba global de Simes. Sin embargo, el método de Hochberg constituye una simplificación computacional del procedimiento cerrado basado en Simes, mientras que el de Hommel implementa dicho principio de manera exacta y completa, lo que le confiere mayor potencia.
A diferencia de los métodos de Holm y Hochberg —que siguen una secuencia lineal (stepwise), donde la decisión sobre cada hipótesis depende del resultado de las comparaciones anteriores—, el método de Hommel es un procedimiento por etapas (stagewise).
Se parte del principio de pruebas cerradas para determinar un índice global que permite rechazar un grupo de hipótesis simultáneamente, basándose en la configuración conjunta de todos los valores p.
A continuación se describe el algoritmo general de Hommel para la evaluación de \(m\) pruebas:
Etapa 1. Para el conjunto de las \(m\) hipótesis evaluadas, se busca \(j\), el mayor número de hipótesis que podrían ser verdaderas, es decir, el mayor número de hipótesis que pueden considerarse simultáneamente compatibles con la hipótesis nula global.
\(j\) es el máximo valor que satisface \[ \text{p}_{(m-j+k)}>\frac{k\alpha}{j},\quad \forall \; k=\{1, \dotsc, j\}. \]
La búsqueda de \(j\) se realiza mediante una serie de subetapas. En la primera se evalúa si \(j\) podría ser \(m\). Si se falla, se buscaría si puede ser \(m-1\); si no, se evaluaría si puede ser \(m-2\) y se continuaría el proceso hasta obtener \(j\).
Tras obtener \(j\) se decide sobre la significancia de las hipótesis, así:
Si \(j=0,\) se rechazan todas las hipótesis.
Si \(j \ge 1,\) se continúa con la etapa 2.
Etapa 2. Se rechazan todas las hipótesis \(H_{(i)}\) tales que \(\text{p}_{(i)} \le \dfrac{\alpha}{j}\)
A continuación se ilustran las diferentes etapas del procedimiento de Hommel para las seis comparaciones por pares del ejemplo 7.1, con \(\alpha=0.05\), partiendo de los valores p obtenidos mediante la prueba de la diferencia mínima significativa (cf. tabla 8.4). Los resultados se compilan en la tabla 8.14:
Etapa 1. Para el conjunto de las \(m=6\) hipótesis evaluadas, se busca \(j,\) el número más grande de hipótesis que podrían ser verdaderas.
\(j\) es el máximo valor que satisface \[ \text{p}_{(6-j+k)}>\frac{k\times 0.05}{j},\quad \forall \; k=\{1, \dotsc, j\}. \]
Los estadísticos de orden de los valores p de la prueba DMS se presentan en la columna 3 de la tabla 8.14.
Etapa 1a. Se evalúa si \(j\) puede ser 6, es decir, si todas las hipótesis contrastadas podrían ser verdaderas. \(¿\,j=6\,?\)
Se evalúa la satisfacción de la condición para \(k=1, 2, 3, 4, 5, 6\) con el umbral \(\dfrac{k\times0.05}{6}\)
- \(k=1\quad\): \(\text{p}_{(6-6+1)}=\text{p}_{(1)}=0.000116;\quad \frac{1\times 0.05}{6}=0.0083\)
\(\quad\quad¿0.000116>0.0083?\) Falso \(\Rightarrow\) se descarta \(j=6.\)
Etapa 1b. Se evalúa si \(j\) puede ser 5. \(¿\,j=5\,?\)
Se evalúa la satisfacción de la condición para \(k=1, 2, 3, 4, 5\) con el umbral \(\dfrac{k\times0.05}{5}\)
- \(k=1\quad\): \(\text{p}_{(6-5+1)}=\text{p}_{(2)}=0.000629;\quad \frac{1\times 0.05}{5}=0.01\)
\(\quad\quad¿0.000629 >0.01?\) Falso \(\Rightarrow\) se descarta \(j=5.\)
Etapa 1c. Se evalúa si \(j\) puede ser 4. \(¿\,j=4\,?\)
Se evalúa la satisfacción de la condición para \(k=1, 2, 3, 4\) con el umbral \(\dfrac{k\times0.05}{4}\)
- \(k=1\quad\): \(\text{p}_{(6-4+1)}=\text{p}_{(3)}=0.001650;\quad \frac{1\times 0.05}{4}=0.0125\)
\(\quad\quad¿0.001650>0.0125?\) Falso \(\Rightarrow\) se descarta \(j=4.\)
Etapa 1d. Se evalúa si \(j\) puede ser 3. \(¿\,j=3\,?\)
Se evalúa la satisfacción de la condición para \(k=1, 2, 3\) con el umbral \(\dfrac{k\times0.05}{3}\)
- \(k=1\): \(\text{p}_{(6-3+1)}=\text{p}_{(4)}=0.048630;\quad \frac{1\times 0.05}{3}=0.01666\)
\(\quad\quad¿0.048630>0.01666?\) Verdadero
- \(k=2\quad\): \(\text{p}_{(6-3+2)}=\text{p}_{(5)}=0.159927;\quad \frac{2\times 0.05}{3}=0.0333\)
\(\quad\quad¿0.159927>0.0333?\) Verdadero
- \(k=3\quad\): \(\text{p}_{(6-3+3)}=\text{p}_{(6)}=0.460855;\quad \frac{3\times 0.05}{3}=0.05\)
\(\quad\quad¿0.460855>0.05?\) Verdadero
Puesto que \(j=3\) es el máximo valor que satisface la condición, se pasa a la siguiente etapa. Se rechazan todas las hipótesis \(H_{(i)}\) tales que \(\text{p}_{(i)} \le \dfrac{\alpha}{j}\)
Etapa 2.
El umbral de corte es \(\dfrac{0.05}{3}=0.01666\)
\(H_{(1)}:\quad\) Dado que \(\text{p}_{(1)}=0.000116 \le 0.01666\), se rechaza \(H_{(1)}.\)
\(H_{(2)}:\quad\)Dado que \(\text{p}_{(2)}=0.000629 \le 0.01666\), se rechaza \(H_{(2)}.\)
\(H_{(3)}:\quad\)Dado que \(\text{p}_{(3)}=0.001650 \le 0.01666\), se rechaza \(H_{(3)}.\)
\(H_{(4)}:\quad\)Dado que \(\text{p}_{(4)}=0.048630 > 0.01666\), no se rechaza \(H_{(4)}.\)
\(H_{(5)}:\quad\)Dado que \(\text{p}_{(5)}=0.159927 > 0.01666\), no se rechaza \(H_{(5)}.\)
\(H_{(6)}:\quad\)Dado que \(\text{p}_{(6)}=0.460855 > 0.01666\), no se rechaza \(H_{(6)}.\)
| \(H_{(i)}\) | \(\text{p}_{(i)}\) | Valor p | Significancia |
|---|---|---|---|
| \(H_{(1)}\) | \(\text{p}_{(1)}\) | 0.000116 | * |
| \(H_{(2)}\) | \(\text{p}_{(2)}\) | 0.000629 | * |
| \(H_{(3)}\) | \(\text{p}_{(3)}\) | 0.001650 | * |
| \(H_{(4)}\) | \(\text{p}_{(4)}\) | 0.048630 | \(\text{ns}\) |
| \(H_{(5)}\) | \(\text{p}_{(5)}\) | 0.159927 | \(\text{ns}\) |
| \(H_{(6)}\) | \(\text{p}_{(6)}\) | 0.460855 | \(\text{ns}\) |
¡No es stepwise!
Aunque el procedimiento de Hommel consta de varias etapas, una vez obtenido el valor de \(j\), la evaluación de las hipótesis se realiza en simultánea, tomando un único umbral de decisión para todas las pruebas.
Esto permite evaluar las hipótesis en cualquier orden, sin que el resultado de una prueba dependa del resultado de las pruebas anteriores.
Aunque Hommel (1988) no describe un algoritmo para la obtención de los valores p ajustados, estos pueden obtenerse en R, incorporando el argumento p.adj = "hommel" en la función LSD.test o ingresado directamente el vector de valores p en la función p.adjust:
p.adjust(c(0.000116, 0.000629, 0.001650, 0.048630, 0.159927, 0.460855), "hommel")[1] 0.000696 0.003145 0.006600 0.145890 0.319854 0.460855
¿Holm, Hochberg o Hommel?
Los procedimientos de Hochberg y Hommel —al estar basados en el método de Simes— presentan un comportamiento generalmente conservador en muchos escenarios prácticos, aunque pueden volverse anticonservadores bajo ciertas estructuras de dependencia.
Ambos métodos son más potentes que el procedimiento de Holm.
El método de Hommel es, a su vez más potente que el método de Hochberg. Aunque históricamente su uso estuvo limitado por su mayor complejidad computacional, este aspecto resulta irrelevante en la actualidad.
Si se requiere garantía sobre el control de la TEF para cualquier situación, debe usarse el procedimiento de Holm (cf. nota 8.3).
Si resulta admisible asumir condiciones sobre la estructura de dependencia entre las pruebas, puede considerarse el uso del procedimiento de Hommel.
8.13 Procedimiento de Dunnett-Tamhane
En el marco de las \((k-1)\) comparaciones contra un control, es posible emplear un procedimiento secuencial descendente (step-down) que ofrece mayor potencia con respecto al procedimiento de un solo paso (single-step), manteniendo controlada la TEF (Dunnett and Tamhane, 1991).
No obstante, de la misma manera en que el procedimiento secuencial ascendente (step-up) de Hochberg resulta más potente que el procedimiento secuencial descendente de Holm, la versión secuencial ascendente para comparaciones contra un control, propuesta por Dunnett y Tamhane (1992, 1995), resulta más potente que su contraparte secuencial descendente, manteniendo controlada la TEF. Esta es, por tanto, la versión que presentamos a continuación.
¡También es step-up, pero no es Hochberg!
A diferencia del procedimiento de Hochberg —cuyo control de la TEF depende de supuestos sobre la estructura de dependencia entre las pruebas—, el procedimiento de Dunnett-Tamhane se formula directamente en términos de la distribución conjunta de los estadísticos de prueba, incorporando explícitamente las correlaciones entre las comparaciones contra el control.
Por tal motivo, no requiere condiciones adicionales sobre la dependencia y mantiene el control de la TEF dentro de su marco de aplicación.
El procedimiento parte de los estadísticos de orden del estadístico de prueba definido mediante la expresión 8.2:
\[
t_\text{c}=\frac{\left|\overline{Y}_i-\overline{Y}_0\right|}{\sqrt{\text{CME}\left(\dfrac{1}{r_i}+\dfrac{1}{r_0}\right)}}
\tag{8.2}\]
Las hipótesis se evalúan secuencialmente, empezando por la correspondiente al menor estadístico de prueba.
¡La lógica cambia!
Los procedimientos secuenciales expuestos en las secciones 8.10 y 8.11 están basados en los estadísticos de orden de los valores p. En consecuencia, los primeros estadísticos de orden corresponden a las hipótesis más significativas.
En contraste, el procedimiento de Dunnett-Tamhane está basado en los estadísticos de orden del estadístico de prueba \(t_\text{c}.\) Por tal motivo, los primeros estadísticos de orden corresponden a las hipótesis menos significativas.
Así, en los procedimientos de Holm y Hochberg, \(H_{(1)}\) representa a la hipótesis más significativa, mientras que en el procedimiento de Dunnett-Tamhane representa la menos significativa.
Se aplica el siguiente criterio:
\[
\begin{equation}
\text{criterio}
\begin{cases}
\text{si } t_{\text{c}(i)} \ge c_i\Rightarrow\text{rechaza }H_{(j)},\quad j=i, i+1, \dotsc, m.\\
\\
\text{si } t_{\text{c}(i)} < c_i\Rightarrow\text{no rechaza }H_{(i)} \text{ e incrementa } i\text{ en una unidad}.\\
\end{cases}
\end{equation}
\]
Este procedimiento, al ser de tipo secuencial, emplea una constante crítica \(c_i\) específica para cada paso.
La aproximación de las constantes \(c_i\) considera la correlación entre las hipótesis evaluadas, la cual depende del número de réplicas de cada tratamiento, acorde con la expresión 8.1.
En implementaciones antiguas para la aproximación de las constantes \(c_i\) se empleaba una única correlación. Siguiendo la recomendación de Dunnett y Tamhane (1995), esta se tomaba como el promedio de las correlaciones entre pares de comparaciones, lo que daba lugar a pruebas ligeramente conservadoras.
Implementaciones más recientes, como la ilustrada en el código 8.2, hacen posible trabajar con la matriz de correlaciones completa, lo que permite una aproximación más precisa.
Para aplicar el procedimiento de Dunnett-Tamhane a los datos del ejemplo 7.1, con un nivel de significancia del 5 %, tomando el empaque tipo \(\text{C}\) como tratamiento control, se comparan los estadísticos de prueba ordenados de menor a mayor, con las correspondientes constantes, las cuales pueden obtenerse mediante el código 8.2, haciendo \(m=1, 2, 3\).
A continuación, se describe el procedimiento, paso a paso, incluyendo los preliminares. Los resultados se sintetizan en la tabla 8.15:
Preliminares
Se calculan los estadísticos de prueba para cada una de las comparaciones, mediante la expresión 8.2:
\(\mu_\text{A}\text{ vs. }\mu_\text{C}: t_\text{c}=2.324\)
\(\mu_\text{B}\text{ vs. }\mu_\text{C}: t_\text{c}=4.648\)
\(\mu_\text{D}\text{ vs. }\mu_\text{C}: t_\text{c}=0.775\)
Se obtienen sus correspondientes estadísticos de orden (cf. columna 3 de la tabla 8.15).
Usando el código 8.2, con
m = 1,m = 2ym = 3, se aproximan las constantes \(c_1,\) \(c_2\) y \(c_3\) para comparación con los estadísticos de orden de \(t_\text{c}\) (cf. columna 4 de la tabla 8.15).
# Aproximación de c1
cv_dunnett(m = 1, df = 8, r = 3) [1] 2.306 # Aproximación de c2
cv_dunnett(m = 2, df = 8, r = 3) [1] 2.673 # Aproximación de c3
cv_dunnett(m = 3, df = 8, r = 3) [1] 2.878Prueba de Dunnett-Tamhane
Se compara \(t_{\text{c}(1)}\) contra \(c_1.\) Dado que 0.775 < 2.306, no se rechaza \(H_{(1)}\).
Se compara \(t_{\text{c}(2)}\) contra \(c_2.\) Dado que 2.324 < 2.673, no se rechaza \(H_{(2)}\).
Se compara \(t_{\text{c}(3)}\) contra \(c_3.\) Dado que 4.648 > 2.878, se rechaza \(H_{(3)}\).
Se rechazan todas las hipótesis con estadísticos mayores o iguales a \(t_{\text{c}(3)}\), si las hubiera.
| Hipótesis | Comparación | \(t_{\text{c}(i)}\) | \(c_i\) | Significancia |
|---|---|---|---|---|
| \(H_{(1)}\) | \(\mu_\text{D}-\mu_\text{C}\) | 0.775 | 2.306 | \(\text{ns}\) |
| \(H_{(2)}\) | \(\mu_\text{A}-\mu_\text{C}\) | 2.324 | 2.673 | \(\text{ns}\) |
| \(H_{(3)}\) | \(\mu_\text{B}-\mu_\text{C}\) | 4.648 | 2.878 | * |
Aunque en el presente ejemplo, el procedimiento secuencial genera los mismos resultados —en términos de significancia— que el procedimiento de un solo paso, el hecho de emplear constantes menores que 2.878 para las primeras comparaciones pone en evidencia su mayor potencia.
Los valores p ajustados no se obtienen directamente a partir de las comparaciones con las constantes \(c_i,\) sino mediante la evaluación de probabilidades conjuntas de la distribución \(t\) multivariante sobre subconjuntos de hipótesis.
Para ello, los estadísticos de prueba se ordenan según su magnitud y se consideran subconjuntos anidados, lo que permite obtener los valores p ajustados de manera eficiente, garantizando el control de la TEF.
Mediante la función personalizada dunnett_tam pueden obtenerse los valores p ajustados mediante este procedimiento, para cada una de las hipótesis contrastadas.
Para el presente ejemplo, los valores p ajustados se obtienen:
data$tto <- relevel(data$tto, "C")
anova.d <- aov(pH ~ tto, data = data)
source("dunnett_tam.R")
dunnett_tam(anova.d)
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Dunnett Contrasts
Fit: aov(formula = pH ~ tto, data = data)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
A - C == 0 0.3000 0.1291 2.324 0.08485 .
B - C == 0 -0.6000 0.1291 -4.648 0.00442 **
D - C == 0 0.1000 0.1291 0.775 0.46086
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- Dunnett-Tamhane step-up method)
¿¡Dónde está la diferencia!?
Compárese el resultado anterior con el que se obtiene al realizar el procedimiento de un solo paso de Dunnett (cf. código 8.4).
8.14 Corrección de Benjamini y Hochberg
El enfoque clásico de los PCM consiste en controlar la probabilidad de cometer al menos un error tipo I en una familia de comparaciones. Como consecuencia de este tipo de controles, las comparaciones individuales se realizan a un nivel de significancia menor que el usado para la familia18, con la consiguiente disminución de su potencia.
Benjamini y Hochberg (1995) indican que el concepto clásico de las tasas de error puede ser innecesariamente exigente, pudiendo bastar con procedimientos que permitan controlar la Tasa de Falsos Descubrimientos (TFD) (False Discovery Rate–FDR).
¿¡Descubrimientos!? ¿¡Y quién los descubrió!?
Benjamini y Hochberg (1995) adoptan el término descubrimiento para referirse al rechazo de una hipótesis nula, siguiendo a Soriç (1989), quien establece explícitamente esta equivalencia.
No obstante, el término ya había sido utilizado previamente por Holm, al asociar el rechazo de la hipótesis nula con la realización de un “descubrimiento” (cf. Holm 1979, pág 65).
Aunque la definición de la TFD es similar a la de la TEF, pudiendo pensarse que en ambos casos se trata de la probabilidad de error tipo I, expresada con diferentes nombres, realmente existe una diferencia fundamental.
Cuando se plantea un PCM con una TEF igual a \(\alpha,\) se busca asegurar que la probabilidad de cometer al menos un error tipo I no supere \(\alpha,\) mientras que cuando se plantea un PCM con TFD igual a \(q,\) se busca controlar la proporción esperada de errores tipo I entre las hipótesis rechazadas.
Así, en un experimento en el que se realizaran 100 comparaciones, al controlar la TEF en 0.05 se reduce considerablemente la probabilidad de cometer al menos un error tipo I, mientras que al controlar la TFD en 0.05 se esperaría que, en promedio, alrededor del 5 % de las hipótesis rechazadas correspondan a errores tipo I.
Desde luego, los PCM basados en el control de la TFD son más potentes que los que se basan en el control de la TEF.
¡Un cambio de paradigma!
Esta aproximación conceptual ha supuesto una ráfaga de aire fresco para los PCM, permitiéndoles declarar resultados significativos en experimentos con muchos tratamientos, en los que los PCM clásicos imponían correcciones demasiado severas.
No obstante, ello no significa ni que los PCM clásicos estén obsoletos, ni que el tema esté cerrado.
Tal y como exponen Benjamini y Hochberg (1995), habrá situaciones en las que pueda resultar preferible el enfoque del control de la TEF. Este sería el caso si la conclusión general que se obtuviera a partir de varias inferencias individuales resultara errónea por el hecho de que al menos una de tales inferencias lo fuera.
Habrá otros casos, en los que una pequeña proporción de errores no cambiarán la validez general de las conclusiones, con lo cual será más pertinente el uso de un PCM que controle la TFD.
Estos autores exponen que la estrategia de control de la TFD también puede ser adecuada en estudios en los que no exista una conclusión global, sino que cada comparación tenga valor per se, o en estudios de tamizaje, en los que se desee seleccionar un número de efectos de interés para evaluar en etapas posteriores del proyecto investigativo.
Para la implementación de la estrategia de control de la TFD, se aplica un procedimiento secuencial ascendente (step-up), basado en los estadísticos de orden de los valores p de la prueba DMS19.
Inicialmente, se compara \(\text{p}_{(m)}\) contra \(q,\) siendo \(q\) la tasa de falsos descubrimientos que es fijada por el usuario. Si \(\text{p}_{(m)} ≤ q,\) se rechazan todas las hipótesis; en caso contrario, se continúa con la siguiente hipótesis. Si \(\text{p}_{(m−1)} \le \frac{m-1}{m}q ,\) se rechaza esa hipótesis y las que tengan menores valores p. Se continúa de la misma manera hasta encontrar un valor significativo o hasta realizar la última comparación.
Partiendo de \(\text{p}_{(m)},\) el método puede describirse sintéticamente mediante el siguiente criterio:
\[
\begin{equation}
\text{criterio}
\begin{cases}
\text{si } \text{p}_{(i)} \le \frac{i}{m}q \Rightarrow\text{rechaza }H_{(j)},\quad j=i, i-1, \dotsc, 1.\\
\\
\text{si } \text{p}_{(i)} > \frac{i}{m}q \Rightarrow\text{no rechaza }H_{(i)} \text{ y disminuye } i\text{ en una unidad}.\\
\end{cases}
\end{equation}
\]
A continuación, se describe paso a paso el procedimiento para las comparaciones por pares del ejemplo 7.1, usando una tasa de falsos descubrimientos, \(q=0.05.\) Los valores p aparecen en la tabla 8.4.
Se compara \(\text{p}_{(6)}\) contra \(\frac{6}{6}0.05.\) Dado que 0.460855 > 0.05, no se rechaza \(H_{(6)}.\)
Se compara \(\text{p}_{(5)}\) contra \(\frac{5}{6}0.05.\) Dado que 0.159927 > 0.041, no se rechaza \(H_{(5)}.\)
Se compara \(\text{p}_{(4)}\) contra \(\frac{4}{6}0.05.\) Dado que 0.04863 > 0.033, no se rechaza \(H_{(4)}.\)
Se compara \(\text{p}_{(3)}\) contra \(\frac{3}{6}0.05.\) Dado que 0.00165 < 0.025, se rechaza \(H_{(3)}.\)
Se rechazan todas las hipótesis con valores p menores que \(\text{p}_{(3)}\): \(H_{(2)}\) y \(H_{(1)}.\)
¿No que era más potente?
Los resultados obtenidos para las 6 comparaciones por pares del ejemplo 7.1 no difieren —en términos de decisiones de rechazo— de los obtenidos mediante procedimientos como el de Holm y el de Hochberg, que controlan la TEF.
Esto no es de extrañar cuando se realizan pocas comparaciones, donde el incremento en potencia es muy modesto.
No obstante, cuanto mayor sea el número de comparaciones realizadas, mayor será la ganancia en potencia de los procedimientos que controlan la TFD, con respecto a los que controlan la TEF.
Los valores p ajustados se obtienen multiplicando los valores p de la DMS por \(\frac{m}{i},\) empezando por \(\text{p}_{(m)}\) y avanzando hacia los menores estadísticos de orden, así:
\[
\begin{equation}
\text{p}_{\text{BH}(i)}=
\begin{cases}
\frac{m}{i}\text{p}_{(i)}, &\text{si }\frac{m}{i}\text{p}_{(i)} \le 1\text{ y } \frac{m}{i}\text{p}_{(i)} \le \text{p}_{\text{BH}(i+1)},\\
\\
\text{p}_{\text{BH}(i+1)}, &\text{si }\frac{m}{i}\text{p}_{(i)} \le 1\text{ y }\frac{m}{i}\text{p}_{(i)} > \text{p}_{\text{BH}(i+1)},\\
\\
1, &\text{si }\frac{m}{i}\text{p}_{(i)} > 1.
\end{cases}
\end{equation}
\]
A continuación, se muestra paso a paso el procedimiento de obtención de los valores p ajustados. Puesto que, para el presente ejemplo, en todos los pasos se obtienen valores menores que el valor ajustado del paso anterior y menores que 1, todos los ajustes consisten en multiplicar \(\text{p}_{(i)}\) por \(\frac{m}{i},\) sin que se activen las restricciones por monotonicidad ni por cota superior en 1.
\[
\begin{align}
\text{p}_{\text{BH}(6)}&=\frac{6}{6}\text{p}_{(6)}=1 \times 0.460855=0.460855\\[1.4em]
\text{p}_{\text{BH}(5)}&=\frac{6}{5}\text{p}_{(5)}=1.2 \times 0.159927=0.191912\\[1.4em]
\text{p}_{\text{BH}(4)}&=\frac{6}{4}\text{p}_{(4)}=1.5 \times 0.048630=0.072945\\[1.4em]
\text{p}_{\text{BH}(3)}&=\frac{6}{3}\text{p}_{(3)}=2 \times 0.001650=0.003300\\[1.4em]
\text{p}_{\text{BH}(2)}&=\frac{6}{2}\text{p}_{(2)}=3 \times 0.000629=0.001887\\[1.4em]
\text{p}_{\text{BH}(1)}&=\frac{6}{1}\text{p}_{(1)}=6 \times 0.000116=0.000696
\end{align}
\]
En R, la corrección de Benjamini y Hochberg se obtiene incluyendo el argumento p.adj = BH o p.adj = fdr20 en la función LSD.test, así:
LSD.test(anova, "tto", p.adj = "BH", , group = FALSE, console = TRUE)
Study: anova ~ "tto"
LSD t Test for pH
P value adjustment method: BH
Mean Square Error: 0.025
tto, means and individual ( 95 %) CI
pH std r se LCL UCL Min Max Q25 Q50 Q75
A 4.1 0.2 3 0.09128709 3.889492 4.310508 3.9 4.3 4.00 4.1 4.20
B 3.2 0.1 3 0.09128709 2.989492 3.410508 3.1 3.3 3.15 3.2 3.25
C 3.8 0.1 3 0.09128709 3.589492 4.010508 3.7 3.9 3.75 3.8 3.85
D 3.9 0.2 3 0.09128709 3.689492 4.110508 3.7 4.1 3.80 3.9 4.00
Alpha: 0.05 ; DF Error: 8
Critical Value of t: 2.306004
Comparison between treatments means
difference pvalue signif.
A - B 0.9 0.0007 ***
A - C 0.3 0.0729 .
A - D 0.2 0.1919
B - C -0.6 0.0033 **
B - D -0.7 0.0019 **
C - D -0.1 0.4609 Aunque el procedimiento de Benjamini y Hochberg fue formulado inicialmente bajo supuestos de independencia entre las pruebas, también es válido bajo ciertas formas de dependencia positiva. Un estudio de simulación realizado por Williams, Jones y Tukey (1999) indica que este procedimiento puede mantener un adecuado control de la TFD cuando se usa para evaluar todas las posibles comparaciones entre pares de medias.
8.15 Corrección de Benjamini y Yekutieli
Benjamini y Yekutieli (2001) proponen un procedimiento de corrección que —aunque es menos potente que el de Benjamini y Hochberg— puede usarse bajo estructuras de dependencia arbitrarias entre las pruebas.
Para la implementación de esta estrategia se usa un procedimiento step-up basado en los estadísticos de orden de la prueba DMS, similar al usado en el procedimiento de Benjamini y Hochberg, pero incluyendo en el denominador la suma armónica de los rangos.
La suma armónica se define así:
\[
H_m=\sum\limits_{k=1}^m\frac{1}{k}
\]
Para un número determinado de comparaciones, \(m,\) la suma armónica, \(H_m,\) es una constante. Así, por ejemplo, para \(m=6:\)
\[
\begin{align}
H_6&=\sum_{k=1}^6 \frac{1}{k}\\[1.4em]
&=\frac{1}{1}+\frac{1}{2}+\frac{1}{3}+\frac{1}{4}+\frac{1}{5}+\frac{1}{6}\\[1.4em]
&=2.45
\end{align}
\]
Para aplicar el procedimiento de Benjamini y Yekutieli, se parte de \(\text{p}_{(m)},\) se evalúa cada hipótesis con base en el siguiente criterio:
\[
\begin{equation}
\text{criterio}
\begin{cases}
\text{si } \text{p}_{(i)}\le\dfrac{i}{mH_m}q\Rightarrow \text{rechaza }H_{(j)},\quad j=i, i-1, \dotsc, 1.\\
\\
\text{si } \text{p}_{(i)}>\dfrac{i}{mH_m}q\Rightarrow\text{no rechaza }H_{(i)} \text{ y disminuye } i \text{ en una unidad}.\\
\end{cases}
\end{equation}
\]
A continuación, se describe paso a paso el procedimiento para las comparaciones por pares del ejemplo 7.1, usando una TFD, \(q=0.05\).
Se compara \(\text{p}_{(6)}\) contra \(\left(\frac{6}{6\times2.45}\right)0.05.\) Dado que 0.460855 > 0.02040, no se rechaza \(H_{(6)}.\)
Se compara \(\text{p}_{(5)}\) contra \(\left(\frac{5}{6\times2.45}\right)0.05.\) Dado que 0.159927 > 0.017000, no se rechaza \(H_{(5)}.\)
Se compara \(\text{p}_{(4)}\) contra \(\left(\frac{4}{6\times2.45}\right)0.05.\) Dado que 0.048630 > 0.013605, no se rechaza \(H_{(4)}.\)
Se compara \(\text{p}_{(3)}\) contra \(\left(\frac{3}{6\times2.45}\right)0.05.\) Dado que 0.001650 < 0.010204, se rechaza \(H_{(3)}.\)
Se rechazan todas las hipótesis con valores p menores que \(\text{p}_{(3)}:\) \(H_{(2)}\) y \(H_{(1)}.\)
El ajuste de los valores p se realiza mediante el siguiente procedimiento, empezando por \(\text{p}_{(m)}\) y avanzado hacia los menores estadísticos de orden:
\[
\begin{equation}
\text{p}_{\text{BY}(i)}=
\begin{cases}
\dfrac{mH_m}{i}\text{p}_{(i)}, &\text{si }\dfrac{mH_m}{i}\text{p}_{(i)} \le 1\text{ y } \dfrac{mH_m}{i}\text{p}_{(i)} \le \text{p}_{\text{BY}(i+1)},\\
\\
\text{p}_{\text{BY}(i+1)}, &\text{si }\dfrac{mH_m}{i}\text{p}_{(i)} \le 1\text{ y } \dfrac{mH_m}{i}\text{p}_{(i)} > \text{p}_{\text{BY}(i+1)},\\
\\
1, &\text{si }\dfrac{mH_m}{i}\text{p}_{(i)} > 1.
\end{cases}
\end{equation}
\]
A continuación, se muestra el procedimiento, paso a paso, de obtención de los valores p ajustados.
\[
\begin{align}
\text{p}_{\text{BY}(6)}&= \left(\frac{6\times2.45}{6}\right)\text{p}_{(6)} = 2.45 \times 0.460855= 1.13 \rightarrow 1.0\\[1.4em]
\text{p}_{\text{BY}(5)}& = \left(\frac{6\times2.45}{5}\right)\text{p}_{(5)} = 2.94\times 0.159927=0.470185\\[1.4em]
\text{p}_{\text{BY}(4)}& = \left(\frac{6\times2.45}{4}\right)\text{p}_{(4)}= 3.675 \times 0.048630=0.178715\\[1.4em]
\text{p}_{\text{BY}(3)}& = \left(\frac{6\times2.45}{3}\right)\text{p}_{(3)} = 4.9\times 0.001650= 0.008085\\[1.4em]
\text{p}_{\text{BY}(2)}& = \left(\frac{6\times2.45}{2}\right)\text{p}_{(2)} = 7.35\times 0.000629= 0.004623\\[1.4em]
\text{p}_{\text{BY}(1)}& = \left(\frac{6\times2.45}{1}\right)\text{p}_{(1)} = 14.7\times 0.000116=0.001705
\end{align}
\]
Para aplicar este procedimiento en R, se incluye el argumento p.adj = "BY" en la función LSD.test o se usa directamente el vector de valores p en la función p.adjust, así:
p.adjust(c(0.000116, 0.000629, 0.001650, 0.048630, 0.159927, 0.460855), "BY")[1] 0.00170520 0.00462315 0.00808500 0.17871525 0.47018538 1.00000000
¿Benjamini y Hochberg o Benjamini y Yekutieli?
El procedimiento de Benjamini y Hochberg fue formulado inicialmente bajo independencia entre las pruebas, pero también es válido bajo ciertas formas de dependencia positiva. Estudios empíricos sugieren que mantiene un adecuado control de la TFD en muchos escenarios prácticos.
El procedimiento de Benjamini y Yekutieli, por su parte, garantiza el control de la TFD bajo estructuras de dependencia arbitrarias entre las pruebas, a costa de una menor potencia.
En consecuencia, si se requiere garantía de control de la TFD en cualquier situación, debe usarse el procedimiento de Benjamini y Yekutieli.
Si se prefiere una mayor potencia y se considera razonable asumir condiciones de independencia o dependencia positiva, puede usarse el procedimiento de Benjamini y Hochberg.
p.adjust
Las correcciones sobre los valores p presentadas en las secciones precedentes se implementan mediante el argumento method de la función p.adjust.
Se admiten los siguientes valores:
"holm": corrección de Holm (sección 8.10)"hochberg": corrección de Hochberg (sección 8.11)"hommel": corrección de Hommel (sección 8.12)"bonferroni": corrección de Bonferroni (sección 8.9)"BH"o"fdr": corrección de Benjamini y Hochberg (sección 8.14)"BY": corrección de Benjamini y Yekutieli (sección 8.15)"none": sin corrección
Asimismo, estas correcciones pueden incorporarse en la función LSD.test, mediante el argumento p.adj, empleando los mismos valores.
8.16 Procedimientos de comparación múltiple con varianzas heterogéneas
Todos los métodos presentados en las secciones precedentes —al emplear el \(\text{CME}\) como estimador común de la varianza dentro de tratamientos— requieren que se satisfaga el supuesto de homogeneidad de varianzas (cf. sección 6.3.3). Algunos otros, sin embargo, están diseñados para realizar múltiples comparaciones de medias en escenarios de heterocedasticidad.
A continuación presentamos los cuatro métodos que, de acuerdo con diversos estudios, alcanzan el mejor desempeño para la realización de todas las comparaciones por pares:
El estadístico de prueba en el que se basan estos métodos corresponde al estadístico de Welch empleado para la comparación de las medias de dos poblaciones normales con varianzas heterogéneas (cf. expresión 5.7):
\[
t_\text{c}=\dfrac{\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet}}{\sqrt{\dfrac{S_i^2}{r_i}+\dfrac{S_{i'}^2}{r_{i'}}}}
\]
La diferencia fundamental entre estos métodos radica en la manera en la que se elige el valor crítico que se utiliza tanto para determinar la significancia de la comparación como para construir los correspondientes intervalos de confianza.
El valor crítico se denota genéricamente así:
\[
A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}\,,
\]
donde \(\alpha\) es el nivel de significancia nominal para la familia de comparaciones, \(k\) es el número de tratamientos y \(\widehat\nu_{ii'}\) representa los grados de libertad de la distribución de referencia.
Este valor se utiliza, junto con el error estándar de la diferencia de las medias para generar un umbral o diferencia mínima significativa y también para construir intervalos de confianza.
El error estándar es:
\[
S_{\overline{Y}_i-\overline{Y}_{i'}}=\sqrt{\dfrac{S_i^2}{r_i}+\dfrac{S_{i'}^2}{r_{i'}}}
\]
La regla de decisión para evaluar la hipótesis sobre la diferencia de dos medias es:
\[
\text{si }\left|\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet}\right|\ge
A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}\ S_{\overline{Y}_i-\overline{Y}_{i'}}
\Rightarrow \text{rechaza } H_0 \text{ con un nivel }\alpha
\]
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia de dos medias se obtiene así:
\[
\text{IC}_{\mu_i-\mu_{i'}}:\quad \left(\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet}\right) \pm
A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}\ S_{\overline{Y}_i-\overline{Y}_{i'}}
\]
En las siguientes secciones se ilustran las particularidades de los cuatro métodos de interés. Posteriormente se ilustra su aplicación mediante un ejemplo común.
8.16.1 Método de Games-Howell
El valor crítico del método de Games-Howell está basado en la distribución del recorrido estudentizado:
\[
A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}=\dfrac{q_{\alpha,\,k,\,\widehat\nu_{ii'}}}{\sqrt{2}},
\]
donde \(q_{\alpha,\,k,\,\widehat\nu_{ii'}}\) es el valor crítico superior de la distribución del recorrido estudentizado y \(\widehat\nu_{ii'}\) son los grados de libertad estimados mediante la aproximación de Satterthwaite:
\[
\widehat\nu_{ii'}=\dfrac{\left(\dfrac{S_i^2}{r_i}+\dfrac{S_{i'}^2}{r_{i'}}\right)^2}
{\dfrac{\left(\dfrac{S_i^2}{r_i}\right)^2}{r_i-1}+\dfrac{\left(\dfrac{S_{i'}^2}{r_{i'}}\right)^2}{r_{i'}-1} }
\]
¿¡Vendría siendo como Tukey-Kramer!?
El error estándar en el método Tukey Kramer es (cf. nota 8.2):
\[
S_{\overline{Y}}=\sqrt{\dfrac{\text{CME}}{2}\left(\frac{1}{r_i}+\frac{1}{r_{i'}} \right)},
\]
donde \(S_{\overline{Y}}\) corresponde al error estándar de la diferencia entre dos medias, el cual puede reescribirse así:
\[
S_{\overline{Y}}=\dfrac{1}{\sqrt 2}\sqrt{\frac{\text{CME}}{r_i}+\frac{\text{CME}}{r_{i'}}}
\]
No obstante, en el contexto heterocedástico no es adecuado emplear el \(\text{CME}\) como estimador común de las varianzas de los grupos comparados. En su lugar, se utiliza la varianza muestral de cada grupo:
\[
S_{\overline{Y}}=\dfrac{1}{\sqrt 2}\sqrt{\frac{S_i^2}{r_i}+\frac{S_{i'}^2}{r_{i'}}}
\]
Al no ser utilizable el \(\text{CME}\) como estimador conjunto de variabilidad, tampoco son utilizables sus grados de libertad, \(\text{gle}\).
Los grados de libertad apropiados para el error estándar anterior serían justamente los obtenidos mediante la aproximación de Satterthwaite.
En este contexto, un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia de dos medias se obtiene así:
\[
\text{IC}_{\mu_i-\mu_{i'}}:\quad \left(\overline{Y}_{i\bullet}-\overline{Y}_{i'\bullet}\right) \pm
q_{\alpha,\,k,\,\widehat\nu_{ii'}}\,\dfrac{1}{\sqrt 2}\sqrt{\frac{S_i^2}{r_i}+\frac{S_{i'}^2}{r_{i'}}}
\]
Esta expresión coincide exactamente con la utilizada en el método de Games-Howell para la construcción de intervalos de confianza.
Luego, el método de Games-Howell equivale a aplicar el procedimiento de Tukey-Kramer, empleando el error estándar de la prueba de Welch y los grados de libertad efectivos de Satterthwaite.
8.16.2 Método T2 de Tamhane
Este método, propuesto por Tamhane (1979), controla la TEF mediante la corrección de Šidák (Šidák, 1967), que aplica un control análogo al de la corrección de Bonferroni, pero logrando una mejor aproximación al nivel de significancia global cuando las comparaciones son independientes o aproximadamente independientes.
La corrección de Šidák consiste en utilizar \(\gamma\) en lugar de \(\alpha\), siendo \(\gamma\) el nivel de significancia individual que garantiza una TEF igual a \(\alpha\) en una familia de \(m\) comparaciones, bajo el supuesto de independencia.
Para el caso general de \(m\) comparaciones, \(\gamma\) se define así:
\[
\gamma=1-(1-\alpha)^{1/m}
\]
Para el caso particular de las \(k(k-1)/2\) comparaciones por pares:
\[
\gamma=1-(1-\alpha)^{\frac{2}{k(k-1)}}
\]
El valor crítico para la prueba T2 de Tamhane se obtiene con base en la distribución \(t\) con \(\widehat{\nu}_{ii'}\) grados de libertad, aplicando la corrección de Šidák:
\[
A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}=t_{\gamma/2\,(\widehat\nu_{ii'})}
\]
8.16.3 Método T2′ de Tamhane
El método T2′ es una variante del método T2, consistente en utilizar los grados de libertad de la prueba de \(t\) clásica, \(r_i+r_{i'}-2,\) si se satisfacen ciertas condiciones de homogeneidad entre las réplicas de los tratamientos comparados y sus errores estándar.
Ury y Wiggins (1971) señalan que, si bien el uso de los grados de libertad efectivos constituye una salvaguarda en situaciones de desbalance, puede resultar innecesariamente conservador cuando el desbalance es leve.
El desbalance tiene que ver tanto con el número de réplicas como con los errores estándar. Estos autores sugieren no corregir los grados de libertad, si se satisface cualquiera de las siguientes condiciones de balance o desbalance leve:
En esencia, estas condiciones evalúan si el número de réplicas de los tratamientos comparados es aproximadamente igual o si los errores estándar de sus medias muestrales son similares.
Si se satisface al menos una de estas condiciones, no se corrigen los grados de libertad, lo que implica usar \((r_i + r_{i'} − 2),\) en lugar de los grados de libertad efectivos.
Tamhane incorpora este criterio en su prueba T2′. Puesto que \((r_i + r_{i'} − 2),\) constituye el límite máximo de los grados de libertad efectivos, los grados de libertad de la prueba T2′ siempre serán mayores o iguales que los de la prueba T2. En consecuencia, habrá escenarios en los que la prueba T2′ resulte más potente, sin ser nunca menos potente.
Los grados de libertad para la prueba T2′ se obtienen así:
\[
\begin{equation}
\widehat\nu_{ii'}=
\begin{cases}
r_i+r_{i'}-2,&\text{ si se satisface C1, C2, C3 o C4}\\
\\
\\
\dfrac{\left(\dfrac{S_i^2}{r_i}+\dfrac{S_{i'}^2}{r_{i'}}\right)^2}
{\dfrac{\left(\dfrac{S_i^2}{r_i}\right)^2}{r_i-1}+\dfrac{\left(\dfrac{S_{i'}^2}{r_{i'}}\right)^2}{r_{i'}-1} },&\text{ en los demás casos.}\\
\end{cases}
\end{equation}
\]
8.16.4 Método T3 de Dunnett
El valor crítico de \(A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}\) para el método T3 es el valor crítico del máximo módulo estudentizado, usando los grados de libertad efectivos mediante la aproximación de Satterthwaite.
Aunque la obtención de estos valores no es trivial, en la actualidad existen implementaciones computacionales que permiten aproximarlos de manera eficiente.
La tabla 8.16 resume las estrategias de control de la TEF y los grados de libertad empleados en las cuatro pruebas expuestas.
| Prueba | Corrección por multiplicidad | Grados de libertad | \(\boldsymbol{A_{ii',\,\alpha,\,k,\,\widehat\nu_{ii'}}}\) |
|---|---|---|---|
| Games-Howell | Intrínseca en la distribución del recorrido estudentizado | Satterthwaite | \(\dfrac{q_{\alpha,\,k,\,\widehat\nu_{ii'}}}{\sqrt{2}}\) |
| T2 | Šidák | Satterthwaite | \(t_{\gamma/2\,(\widehat\nu_{ii'})}\) |
| T2′ | Šidák | Híbridos (criterios de Ury-Wiggins) | \(t_{\gamma/2\,(\widehat\nu_{ii'})}\) |
| T3 | Intrínseca en la distribución del máximo módulo estudentizado | Satterthwaite | Valor crítico del máximo módulo estudentizado |
¿¡Con cuál me quedo!?
Diversos estudios, entre los que se destacan los realizados por Tamhane (1979), Dunnett (1980b) y Korhonen (1982) muestran que el método Games-Howell —aunque es el más potente— no siempre controla adecuadamente la tasa de error por familia, pudiendo resultar anticonservador en ocasiones.
El método T2′ exhibe un mejor desempeño que el T2.
El método T3 presenta un mejor desempeño que T2 y T2′ permitiendo el mejor control de la TEF, particularmente en escenarios con bajo número de réplicas.
En consecuencia, se recomienda el método T3 de Dunnett para la realización de todas las posibles comparaciones por pares, por ofrecer un mejor equilibrio entre potencia y control de la TEF.
Ejemplo 8.1
Considérese un experimento en el que se comparan cinco tratamientos con diferente número de réplicas y varianzas heterogéneas.
La tabla 8.17 presenta las observaciones, así como los estadísticos básicos de cada grupo.
| Tratamiento | \(\boldsymbol{r_i}\) | \(\overline{Y}_{i\bullet}\) | \(S_i^2\) | |||||
|---|---|---|---|---|---|---|---|---|
| \(\text{A}\) | 5.8 | 6.3 | 4.4 | 3 | 5.5 | 0.97 | ||
| \(\text{B}\) | 11.7 | 15.5 | 9.3 | 7.1 | 6.9 | 5 | 10.1 | 12.9 |
| \(\text{C}\) | 12.7 | 12.7 | 12.9 | 13.3 | 4 | 12.9 | 0.08 | |
| \(\text{D}\) | 8.5 | 6.3 | 2 | 7.4 | 2.42 | |||
| \(\text{E}\) | 0.8 | 4.3 | 5.4 | 1.4 | 3.6 | 5 | 3.1 | 3.79 |
A continuación, se ilustran los cálculos manuales para la comparación entre \(\mu_\text{B}\) y \(\mu_\text{E},\) usando \(\alpha=0.05.\) Para las demás comparaciones, los cálculos se realizan de manera análoga.
Tomemos como punto de partida, los valores correspondientes a esta comparación. Cuando el contexto lo permita, tales valores se denotarán simplemente con el subíndice \(\text{BE}.\)
El estadístico de prueba es:
\[
\begin{align}
t_\text{c}=t_\text{BE}&=\frac{\overline{Y}_\text{B}-\overline{Y}_{\text{E}}}{\sqrt{\dfrac{S_\text{B}^2}{r_\text{B}}+\dfrac{S_\text{E}^2}{r_\text{E}}}}\\[1.4em]
&=\frac{10.1-3.1}{\sqrt{\dfrac{12.9}{5}+\dfrac{3.79}{5}}}\\[1.4em]
&=\frac{7.0}{1.8270}\\[1.4em]
&=3.8314
\end{align}
\]
El error estándar es:
\[
\begin{align}
S_{\overline{Y}_{\text{B}}-\overline{Y}_{\text{E}}}=S_{\text{BE}}&={\sqrt{\dfrac{S_\text{B}^2}{r_\text{B}}+\dfrac{S_\text{E}^2}{r_\text{E}}}}\\[1.4em]
&={\sqrt{\dfrac{12.9}{5}+\dfrac{3.79}{5}}}\\[1.4em]
&=1.8270\\[1.4em]
\end{align}
\]
Y los grados de libertad efectivos de Satterthwaite se obtienen así:
\[
\begin{align}
\widehat\nu_\text{BE}&=\dfrac{\left(\dfrac{S_\text{B}^2}{r_\text{B}}+\dfrac{S_\text{E}^2}{r_\text{E}}\right)^2}
{\dfrac{\left(\dfrac{S_\text{B}^2}{r_\text{B}}\right)^2}{r_\text{B}-1}+\dfrac{\left(\dfrac{S_\text{E}^2}{r_\text{E}}\right)^2}{r_\text{E}-1}}\\[1.4em]
&=\dfrac{\left(\dfrac{12.9}{5}+\dfrac{3.79}{5}\right)^2}
{\dfrac{\left(\dfrac{12.9}{5}\right)^2}{5-1}+\dfrac{\left(\dfrac{3.79}{5}\right)^2}{5-1}}\\[1.4em]
&=\dfrac{11.1422}
{1.8077}\\[1.4em]
&=6.1637
\end{align}
\]
En resumen, se tienen los siguientes valores para el contraste \(\mu_\text{B}-\mu_\text{E}:\)
\[
\begin{align}
t_\text{BE}&=3.8314\\[1.4em]
S_\text{BE}&=1.8270\\[1.4em]
\widehat\nu_\text{BE}&=6.1637
\end{align}
\]
A continuación se ilustran las particularidades de los tres primeros métodos. El método T3 —por su complejidad— se ilustra únicamente mediante su implementación en R.
Método de Games-Howell
El valor crítico del método Games-Howell es:
\[
\begin{align}
A_{\text{BE},\,\alpha,\,k,\,\widehat\nu_\text{BE}}=A_{\text{BE}}&=\dfrac{q_{\alpha,\,k,\,\widehat\nu_\text{BE}}}{\sqrt{2}}\\[1.4em]
&=\dfrac{q_{0.05,\,5,\,6.1637}}{\sqrt{2}}
\end{align}
\]
El valor crítico superior del recorrido estudentizado se obtiene así:
qtukey(0.05, nmeans = 5, df= 6.1637, lower.tail = FALSE)[1] 5.258268Por tanto:
\[
\begin{align}
A_{\text{BE}}&=\dfrac{5.258296}{\sqrt{2}}\\[1.4em]
&= 3.7182
\end{align}
\]
Para realizar la comparación directa, por la vía clásica, se evalúa si el valor absoluto de la diferencia de las medias es mayor o igual que la diferencia mínima significativa del método Games-Howell, así:
\[
\begin{align}
\left|\overline{Y}_\text{B}-\overline{Y}_{\text{E}}\right| &\overset?\ge A_\text{BE}\ S_\text{BE}\\[1.4em]
7.0 &\overset?\ge 3.7182 \times 1.8270\\[1.4em]
7.0 &\ge 6.7932\\[1.4em]
\end{align}
\]
Por tanto, se rechaza \(H_0\) y se declara significativa la diferencia entre \(\mu_\text{B}\) y \(\mu_\text{E}.\)
El estadístico de prueba de Games-Howell para el cálculo del valor p es:
\[
\begin{align}
q_\text{BE}&=\sqrt 2\ |t_\text{BE}| \\[1.4em]
&=1.4142 \times 3.8314\\[1.4em]
&=5.4184
\end{align}
\]
El valor p se obtiene como el área a la derecha de \(q_\text{BE}\) en la distribución del recorrido estudentizado:
ptukey(5.4184, nmeans = 5, df = 6.1637, lower.tail = FALSE)[1] 0.04405184Este valor p es coherente con la decisión de rechazo obtenida mediante el criterio basado en la diferencia mínima significativa.
Un intervalo de confianza del 95 % para \(\mu_\text{B} - \mu_\text{E}\) está dado por:
\[
\begin{align}
\left(\overline{Y}_\text{B}-\overline{Y}_\text{E}\right) &\pm
A_\text{BE}\ S_\text{BE}\\[1.4em]
7.0 &\pm 3.7182 \times 1.8270\\[1.4em]
7.0 &\pm 6.7932\\[1.4em]
\text{IC}:\quad [0.2068&, 13.7932]
\end{align}
\]
Como es de esperarse en una comparación significativa al nivel \(\alpha=0.05,\) el intervalo de confianza del 95 % no contiene el cero.
Método T2 de Tamhane
El valor de \(\gamma\) correspondiente a la corrección de Šidák aplicada a una familia de 10 comparaciones con \(\alpha=0.05\) es:
\[
\gamma = 1-(1-0.05)^{1/10}=0.005116197
\]
El valor crítico para la comparación entre las medias de los tratamientos \(\text{B}\) y \(\text{E},\) mediante la prueba T2 es:
\[
\begin{align}
A_{\text{BE},\,\alpha,\,k,\,\widehat\nu_\text{BE}}&=t_{\gamma/2\,(\widehat\nu_\text{BE})}\\[1.4em] &=t_{0.002558099\ (6.1637)}
\end{align}
\]
Este valor crítico se obtiene a partir de la distribución \(t\):
qt(0.002558099, df = 6.1637, lower.tail = FALSE)[1] 4.240646Luego, \(A_{\text{BE}}=4.2406.\)
Para realizar la comparación directa, mediante el criterio basado en la diferencia mínima significativa, se evalúa si el valor absoluto de la diferencia de las medias es mayor o igual que la diferencia mínima significativa del método T2, así:
\[
\begin{align}
\left|\overline{Y}_\text{B}-\overline{Y}_{\text{E}}\right| &\overset?\ge A_\text{BE} \ S_\text{BE}\\[1.4em]
7.0 &\overset?\ge 4.2406 \times 1.8270\\[1.4em]
7.0 &\ngeq 7.7476\\[1.4em]
\end{align}
\]
Por tanto, no se rechaza \(H_0.\)
Para obtener los valores p que incorporen la corrección de Šidák, es necesario aplicar la transformación inversa sobre los valores p que se obtienen del estadístico \(t_\text{BE}.\)
La transformación inversa se obtiene despejando \(\alpha\) de la corrección de Šidák, así:
\[
\begin{align}
\gamma&=1-(1-\alpha)^{1/m}\\[1.4em]
1-\gamma&=(1-\alpha)^{1/m}\\[1.4em]
(1-\gamma)^m&=1-\alpha\\[1.4em]
\alpha&=1-(1-\gamma)^m\\[1.4em]
\end{align}
\]
Si denotamos con \(\text{p}_\gamma\) al valor p ajustado con corrección de Šidák a nivel familiar y con \(\text{p}_\alpha\) al valor p individual obtenido directamente del estadístico \(t_\text{BE},\) puede establecerse la siguiente relación para las comparaciones por pares de un experimento:
\[
\begin{align}
\text{p}_\gamma= 1-(1-\text{p}_\alpha)^{k(k-1)/2}
\\[1.4em]
\end{align}
\]
El valor p sin corrección, \(\text{p}_\alpha\), se obtiene así:
2 * pt(abs(3.8314), df = 6.1637, lower.tail = FALSE)[1] 0.008212597Por tanto:
\[
\begin{align}
\text{p}_\gamma&= 1-(1-\text{p}_\alpha)^{k(k-1)/2}\\[1.4em]
&= 1-(1-0.008212597)^{10}\\[1.4em]
&= 0.0792
\end{align}
\]
Este valor p es coherente con la decisión de no rechazo de la hipótesis nula al que se llegó por la vía clásica.
Un intervalo de confianza del 95 % para \(\mu_\text{B} - \mu_\text{E}\) está dado por:
\[
\begin{align}
\left(\overline{Y}_\text{B}-\overline{Y}_\text{E}\right) &\pm
A_\text{BE}\ S_\text{BE}\\[1.4em]
7.0 &\pm 4.2406 \times 1.8270\\[1.4em]
7.0 &\pm 7.7476\\[1.4em]
\text{IC}:\quad[-0.7476&, 14.7476]
\end{align}
\]
La inclusión del cero en el intervalo de confianza del 95 % es coherente con la decisión de no rechazo de \(H_0\) con \(\alpha=0.05.\)
Método T2′ de Tamhane
Para obtener \(A_{\text{BE},\,\alpha,\,k,\,\widehat\nu_\text{BE}},\) es necesario determinar inicialmente \(\widehat\nu_\text{BE},\) que constituye justamente el aspecto diferenciador entre las pruebas T2 y T2′.
Inicialmente, se verifica si se satisface al menos una de las cuatro condiciones que permiten usar los grados de libertad de la prueba de \(t.\)
Para ello, es conveniente calcular inicialmente las razones con base en las cuales se definen las condiciones:
\[
\begin{align}
R_r&=\dfrac{r_\text{B}}{r_\text{E}}=\dfrac{5}{5}=1\\[1.4em]
R_S&=\dfrac{S_\text{B}^2/r_\text{B}}{S_\text{E}^2/r_\text{E}}=\dfrac{12.9/5}{3.79/5}=3.40
\end{align}
\]
A continuación se evalúa la satisfacción de estas condiciones, utilizando valores decimales, en lugar de fraccionarios, para facilitar la visualización:
El hecho de que los dos tratamientos comparados tengan el mismo número de réplicas garantiza el cumplimiento de la condición \(\text{C}1\) y, por tanto, permite el uso de los grados de libertad de la prueba \(t\) clásica, lo que le confiere potencia adicional a este contraste21:
\[
\widehat\nu_\text{BE}=5+5-2=8
\]
El valor de \(\gamma\) para la corrección de Šidák aplicada a una familia de 10 comparaciones con \(\alpha=0.05\) es el mismo empleado en T2:
\[
\gamma = 1-(1-0.05)^{1/10}=0.005116197
\]
El valor crítico para la comparación entre las medias de los tratamientos \(\text{B}\) y \(\text{E},\) mediante la prueba T2′ es:
\[
\begin{align}
A_{\text{BE},\,\alpha,\,k,\,\widehat\nu_\text{BE}}&=t_{\gamma/2\,(\widehat\nu_\text{BE})}\\[1.4em] &=t_{0.002558099\ (8)}
\end{align}
\]
Este valor se obtiene a partir de la distribución \(t\):
qt(0.002558099, df = 8, lower.tail = FALSE)[1] 3.816351Luego, \(A_{\text{BE}}=3.8164.\)
Para realizar la comparación directa, por la vía clásica, se evalúa si el valor absoluto de la diferencia de las medias es mayor o igual que la diferencia mínima significativa del método T2′, así:
\[
\begin{align}
\left|\overline{Y}_\text{B}-\overline{Y}_{\text{E}}\right| &\overset?\ge A_\text{BE} \ S_\text{BE}\\[1.4em]
7.0 &\overset?\ge 3.8164 \times 1.8270\\[1.4em]
7.0 &\ge 6.9726\\[1.4em]
\end{align}
\]
Por tanto, se rechaza \(H_0.\) Obsérvese que la diferencia entre T2 y T2′ en este caso se debe exclusivamente al aumento en los grados de libertad, lo que reduce el valor crítico y favorece el rechazo.
Los valores p se obtienen de manera análoga a la prueba T2.
El valor p sin corrección, \(\text{p}_\alpha\), es:
2 * pt(abs(3.8314), df = 8, lower.tail = FALSE)[1] 0.005007949Por tanto:
\[
\begin{align}
\text{p}_\gamma&= 1-(1-\text{p}_\alpha)^{k(k-1)/2}\\[1.4em]
&= 1-(1-0.005007949)^{10}\\[1.4em]
&= 0.0490
\end{align}
\]
Este valor p es coherente con la decisión de rechazo de la hipótesis nula declarado por la vía clásica.
Un intervalo de confianza del 95 % para \(\mu_\text{B} - \mu_\text{E}\) está dado por:
\[
\begin{align}
\left(\overline{Y}_\text{B}-\overline{Y}_\text{E}\right) &\pm
A_\text{BE}\ S_\text{BE}\\[1.4em]
7.0 &\pm 3.8164 \times 1.8270\\[1.4em]
7.0 &\pm 6.9726\\[1.4em]
\end{align}
\] \[
\text{IC}:\quad[0.0274, 13.9726]
\]
La no inclusión del cero en el intervalo de confianza del 95 % es coherente con la decisión de rechazo de \(H_0\) con \(\alpha=0.05.\)
¡Puede ser más potente!
En escenarios de desbalance marcados no se satisfará ninguna de las condiciones necesarias para el uso de valor máximo de los grados de libertad, con lo cual, la prueba T2′ generará exactamente los mismos resultados que T2.
Sin embargo, habrá situaciones, como la ilustrada en este ejemplo, en las que la prueba T2′ exhibirá un mejor desempeño que la T2.
8.16.5 Uso de R para comparaciones por pares con varianzas heterogéneas
Los métodos presentados en esta sección —incluyendo el T3 de Dunnett— se encuentran implementados en la función personalizada hetero_pairs.
Esta función admite los siguientes argumentos:
anova: Un objeto de la claseaovolmcon la información del ANOVA ajustado. Este es el único argumento obligatorio.tto: Nombre del factor cuyas medias se desean comparar. En modelos de una vía en DCA, donde el único factor corresponde a los tratamientos, este argumento puede omitirse; la función lo extrae automáticamente del objetoanova.method: Identificador del método de comparación múltiple. Por defecto,method = "T3". También pueden elegirse las etiquetas"GH","T2"y"T2'".alpha: Define el nivel de significancia y la confianza \((1-\alpha).\) Por defectoalpha = 0.05.
El método T3 se implementa a través de la función dunnettT3Test del paquete PMCMRplus.
Los intervalos de confianza correspondientes a esta prueba se construyen mediante una aproximación basada en la distribución del recorrido estudentizado con grados de libertad por comparación.
Estos intervalos deben interpretarse como aproximaciones coherentes con el procedimiento de prueba, dado que no existe una forma canónica única ampliamente aceptada para su construcción.
A continuación se ilustra el uso de la función para aplicar el método T3 sobre los datos del ejemplo 8.1, los cuales están organizados en el archivo ejemplo 8.1.xlsx.
data <- readxl::read_excel("ejemplo 8.1.xlsx")
data$tto <- factor(data$tto)
anova <- aov(y ~ tto, data = data)
source("hetero_pairs.R")
hetero_pairs(anova)
Comparación de medias por el método T3 de Dunnett
estimado statistic gl p value lwr 95% upr 95% sig.
A - B -4.6 -2.6997 4.91 0.2432 -14.3379 5.1379
A - C -7.4 -12.6291 2.25 0.0235 -13.0195 -1.7805 *
A - D -1.9 -1.5344 1.55 0.7345 -15.3738 11.5738
A - E 2.4 2.3080 5.97 0.3437 -3.1261 7.9261
B - C -2.8 -1.7365 4.06 0.6280 -12.8576 7.2576
B - D 2.7 1.3869 4.59 0.8014 -8.7521 14.1521
B - E 7.0 3.8314 6.16 0.0606 -2.6070 16.6070 .
C - D 5.5 4.9592 1.03 0.2939 -6.5677 17.5677
C - E 9.8 11.1106 4.21 0.0023 4.3961 15.2039 **
D - E 4.3 3.0652 2.41 0.3172 -8.2934 16.8934
Los intervalos de confianza para el método T3 no son exactos
------------------------------------------------------------
medias grupos
C 12.9 a
B 10.1 ab
D 7.4 ab
A 5.5 b
E 3.1 b
Los tratamientos con una letra común no difieren
significativamente al 5 %
¡
NA en Games-Howell!
El método de Games-Howell no es aplicable en comparaciones cuyos grados de libertad efectivos son menores que 2.
Esto es debido a que las aproximaciones a los valores críticos y los valores p de la distribución del recorrido estudentizado —implementadas a través de las funciones qtukey y ptukey respectivamente— pueden volverse numéricamente inestables en estos escenarios.
En tales casos, la función genera una alerta e invita a utilizar otro método.
8.16.6 Prueba de Brown-Forsythe
El método propuesto por Brown y Forsythe (1974) permite evaluar cualquier número de contrastes (cf. definición 8.3) en escenarios de heterocedasticidad, manteniendo controlada la TEF.
Este método está basado en la distribución \(F.\)
La significancia de los contrastes puede evaluarse comparando el valor absoluto del contraste estimado con una diferencia mínima significativa, la cual se define así:
\[
\text{DMBF}=\sqrt{(k-1)f_{\alpha(k-1,\, \widehat{\nu}_\widehat\xi)}}\ S_\widehat\xi\\[1.4em]
\]
\[
\text{si }\left|\widehat\xi\right| \ge \text{DMBF}\Rightarrow \text{rechaza } H_0 \text{ con un nivel de significancia }\alpha
\]
El error estándar del contraste estimado se calcula así:
\[
S_\widehat\xi=\sqrt{\sum\limits_{i=1}^k{\dfrac{c_i^2S_i^2}{r_i}}}
\]
Bajo la hipótesis de nulidad del contraste, el estadístico de prueba sigue una distribución \(F\) con \((k-1)\) y \(\nu_\widehat{\xi}\) grados de libertad.
Los grados de libertad efectivos del denominador se estiman mediante la aproximación de Satterthwaite:
\[
\widehat\nu_{\widehat\xi}=\dfrac{\left(\sum\limits_{i=1}^k{\dfrac{c_i^2S_i^2}{r_i}}\right)^2}
{\sum\limits_{i=1}^k\dfrac{c_i^4S_i^4}{r_i^2(r_i-1)}}
\]
¿¡Vendría siendo como Scheffé!?
El método de Brown-Forsythe está basado en los mismos principios que el método de Scheffé y tiene su misma estructura.
No obstante, a diferencia del método de Scheffé, donde se utiliza el \(\text{CME}\) como estimador de la varianza conjunta dentro de tratamientos, el método de Brown-Forsythe calcula el error estándar directamente a partir de las varianzas muestrales de los grupos involucrados en el contraste. Y, en lugar de los grados de libertad del error, emplea los grados de libertad efectivos de Satterthwaite.
Para ilustrar la aplicación de la prueba de Brown-Forsythe, considérese el siguiente contraste entre grupos de medias del ejemplo 8.1:
\[
\mu_\text{A, B, E} - \mu_\text{C, D}
\]
Los coeficientes que definen este contraste se obtienen mediante la metodología descrita en la sección 8.2.1:
\[
\begin{align}
c_1&=3/13\\
c_2&=5/13\\
c_3&=-2/3\\
c_4&=-1/3\\
c_5&=5/13
\end{align}
\]
El error estándar de este contraste es:
\[
\begin{align}
S_\widehat\xi&=\sqrt{\sum\limits_{i=1}^k{\dfrac{c_i^2S_i^2}{r_i}}}\\[1.4em]
&=\sqrt{\dfrac{\left(\frac{3}{13}\right)^2\times0.97}{3}+\dfrac{\left(\frac{5}{13}\right)^2\times12.9}{5}+\dotsb+\dfrac{\left(\frac{5}{13}\right)^2\times 3.79}{5}}\\[1.4em]
&=0.8089
\end{align}
\]
Los grados de libertad efectivos de Satterthwaithe se obtienen así22:
\[
\begin{align}
\widehat\nu_{\widehat\xi}&=\dfrac{\left(\sum\limits_{i=1}^k{\dfrac{c_i^2S_i^2}{r_i}}\right)^2}
{\sum\limits_{i=1}^k{\dfrac{c_i^4S_i^4}{r_i^2(r_i-1)}}}\\[1.4em]
&=\dfrac{0.8089^4}
{\dfrac{\left(\frac{3}{13}\right)^4\times0.97^2}{3^2(3-1)}+\dfrac{\left(\frac{5}{13}\right)^4\times12.9^2}{5^2(5-1)}+\dotsb+\dfrac{\left(\frac{5}{13}\right)^4\times 3.79^2}{5}\\[1.4em]}\\[1.4em]
&=\dfrac{0.4281}{0.0578}\\[1.4em]
&=7.41\\[1.4em]
\end{align}
\]
BF′
Tamhane (1979) propuso adaptar los grados de libertad de los contrastes entre pares de medias, de manera análoga a la adaptación de la prueba T2′ con respecto a la prueba T2.
La adaptación consiste en utilizar los grados de libertad de la prueba clásica de \(t\), es decir \(r_i+r_{i'}-2,\) en lugar de los grados de libertad efectivos, si se satisface cualquiera de las condiciones de Ury y Wiggins sobre balance o desbalance leve, lo que puede brindar potencia adicional en tales casos. A esta prueba la denominó BF′.
Esto aplica únicamente para las comparaciones por pares. Para los contrastes más generales se utilizan siempre los grados de libertad efectivos de Satterthwaite.
Si en el presente ejemplo se aplica la prueba BF′ incluyendo las comparaciones por pares, los grados de libertad correspondientes a la comparación entre las medias de los tratamientos \(\text{B}\) y \(\text{E}\) son 8, tal y como se ilustró al desarrollar la prueba T2′.
Para el cálculo de la \(\text{DMBF}\) se requiere el valor crítico superior de la distribución \(F\):
qf(0.05, df1 = 4, df2 = 7.41, lower.tail = FALSE)[1] 3.992516Luego,
\[
\begin{align}
\text{DMBF}&=\sqrt{(k-1)f_{\alpha(k-1,\, \widehat{\nu}_\widehat\xi)}}\ S_\widehat\xi\\[1.4em]
&=3.9962 \times 0.8089\\[1.4em]
&=3.2325
\end{align}
\]
El contraste estimado es:
\[
\begin{align}
\widehat{\xi}&=c_1\overline{Y}_\text{A}+c_2\overline{Y}_\text{B}+c_3\overline{Y}_\text{C}+c_4\overline{Y}_\text{D}+c_5\overline{Y}_\text{E}\\[1.4em]
&=\frac{3}{13} \times 5.5 + \frac{5}{13} \times 10.1
-\frac{2}{3} \times 12.9 -\frac{1}{3} \times 7.4 +\frac{5}{13} \times 3.1\\[1.4em]
&=-4.7205
\end{align}
\]
Dado que:
\[
|-4.7205|>3.2325,\,\text{se rechaza } H_0
\]
El valor p se calcula a partir del correspondiente estadístico de prueba:
\[
\begin{align}
F_\text{c}&=\dfrac{\widehat{\xi}^2}{(k-1)S^2_\widehat{\xi}}\\[1.4em]
&=\dfrac{-4.7205^2}{(5-1)\times0.8089^2}\\[1.4em]
&=\dfrac{22.2831}{2.6173}\\[1.4em]
&=8.5138
\end{align}
\]
El valor p se obtiene como el área a la derecha de \(F_\text{c}\) en la distribución \(F_{(k-1,\, \widehat{\nu}_\widehat\xi)}:\)
pf(8.5138, df1 = 4, df2 = 7.41, lower.tail = FALSE)[1] 0.006852535Puesto que el valor p es menor que 0.05 se rechaza la hipótesis nula de igualdad entre las medias de los grupos comparados, lo cual es coherente con el rechazo obtenido al comparar la magnitud del contraste con la \(\text{DMBF}.\)
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para el contraste se obtiene así:
\[
\text{IC}_\xi:\quad \widehat{\xi} \pm \text{DMBF}
\]
En particular, el intervalo de confianza del 95 % para el contraste \(\{\mu_\text{A}, \mu_\text{B}, \mu_\text{E}\} - \{\mu_\text{C}, \mu_\text{D}\}\) es:
\[
\text{IC}_\xi:\quad -4.7205 \pm 3.2325
\] \[
[-7.9530,\ -1.4880]
\]
La no inclusión del cero en el intervalo de confianza del 95 % es coherente con la decisión de rechazo de \(H_0\) con \(\alpha=0.05.\)
Y, puesto que los límites son negativos, la diferencia es a favor del sustraendo del contraste: se tiene una confianza del 95 % en que la media conjunta de los tratamientos \(\text{C},\,\text{D}\) supera la media conjunta de los tratamientos \(\text{A},\,\text{B},\,\text{E}\) en una cantidad entre 1.4880 y 7.9530.
La función personalizada hetero_contrasts implementa la prueba de Brown-Forsythe, tanto en su versión original, como en la versión adaptada por Tamhane. Esta última es la que realiza por defecto.
A diferencia de los procedimientos específicos para comparaciones por pares, hetero_contrasts permite realizar inferencias simultáneas sobre contrastes arbitrarios entre grupos de medias, manteniendo controlada la TEF en escenarios de heterocedasticidad.
Esta función admite los siguientes argumentos:
anova: Un objeto de la claseaovolmcon la información del ANOVA ajustado.tto: Nombre del factor cuyas medias se desean comparar. En modelos de una vía en DCA, donde el único factor corresponde a los tratamientos, este argumento puede omitirse; la función lo extrae automáticamente del objetoanova.coef: Vector o matriz de coeficientes, con cada fila definiendo un contraste.coef.simp: Marcador lógico que indica si los coeficientes se ingresan en formato simplificado (+1,0-1) o en formato estándar.BFp: Marcador lógico que indica si se realiza la prueba BF′ (por defectoBFp = TRUE) o la prueba BF original.alpha: Define el nivel de significancia del procedimiento y la confianza \((1-\alpha)\) simultánea para los intervalos. Por defectoalpha = 0.05.
A continuación se ilustra el uso de la función para realizar todas las posibles comparaciones por pares del ejemplo 8.1, junto con un contraste adicional, mediante el método BF′. Los datos están organizados en el archivo ejemplo 8.1.xlsx.
Se usan coeficientes simplificados, los cuales son transformados internamente en coeficientes ponderados acordes con el número de réplicas de cada tratamiento.
data <- readxl::read_excel("ejemplo 8.1.xlsx")
data$tto <- factor(data$tto)
anova <- aov(y ~ tto, data = data)
coef <- matrix(c(1, 1, -1, -1, 1), nrow = 1)
rownames(coef) <- c("A, B, E - C, D")
source("hetero_contrasts.R")
hetero_contrasts(anova, coef = coef, coef.simp = TRUE)
Contrastes de medias mediante la prueba de Brown-Forsythe
estimado Fc gl lwr 95% upr 95% p value sig.
A - B -4.6000 1.8220 4.91 -12.4231 3.2231 0.2641
A - C -7.4000 39.8738 2.25 -11.9293 -2.8707 0.0172 *
A - D -1.9000 0.5886 1.55 -17.1931 13.3931 0.7171
A - E 2.4000 1.3317 5.97 -2.0362 6.8362 0.3588
B - C -2.8000 0.7538 4.06 -10.8861 5.2861 0.6040
B - D 2.7000 0.4809 4.59 -6.5027 11.9027 0.7514
B - E 7.0000 3.6699 8.00 -0.1584 14.1584 0.0556 .
C - D 5.5000 6.1484 1.03 -25.1056 36.1056 0.2847
C - E 9.8000 30.8612 4.21 5.4560 14.1440 0.0023 **
D - E 4.3000 2.3488 2.41 -5.8473 14.4473 0.2888
A, B, E - C, D -4.7205 8.5136 7.41 -7.9535 -1.4875 0.0069 **
Se aplicó la prueba BF′ con corrección de Tamhane
Esta prueba controla la TEF8.16.7 Control de la tasa de falsos descubrimientos bajo heterocedasticidad
Todos los procedimientos descritos anteriormente para realizar comparaciones en escenarios de varianzas heterogéneas están diseñados para controlar la TEF.
Para controlar la TFD (cf. definición 8.5), se adopta el marco común del estadístico tipo Welch empleado en las pruebas Games-Howell, T2, T2′ y T3 y se aplican posteriormente las correcciones de Benjamini-Hochberg o Benjamini-Yekutieli sobre los correspondientes valores p.
Pueden utilizarse los grados de libertad efectivos de Satterthwaite en todos los casos o los grados de libertad híbridos, acorde con la propuesta de Ury y Wiggins (1971), popularizada por Tamhane (1979).
Para el caso más general de un contraste cualquiera entre medias de tratamientos, el estadístico de prueba se define así:
\[
t_\text{c}=\dfrac{\left|\widehat{\xi}\right|}{S_\widehat\xi} \overset{H_0} \thicksim t_{(\widehat\nu_{\widehat{\xi}})}
\]
El error estándar se obtiene así:
\[
S_\widehat\xi=\sqrt{\sum\limits_{i=1}^k{\dfrac{c_i^2S_i^2}{r_i}}}\\[1.4em]
\]
Los grados de libertad efectivos se estiman mediante la aproximación de Satterthwaithe así:
\[
\widehat\nu_{\widehat\xi}=\dfrac{\left(\sum\limits_{i=1}^k{\dfrac{c_i^2S_i^2}{r_i}}\right)^2}
{\sum\limits_{i=1}^k{\dfrac{c_i^4S_i^4}{r_i^2(r_i-1)}}}\\[1.4em]
\]
En comparaciones por pares y bajo escenarios de balance o desbalance leve (cf. condiciones de Ury-Wiggins) es posible emplear los grados de libertad de la prueba clásica de \(t,\) en lugar de los grados de libertad efectivos de Satterthwaite.
La función personalizada hetero_fdr implementa el procedimiento descrito anteriormente, aplicando por defecto la corrección de Benjamini-Hochberg y la adaptación de Ury-Wiggins para los grados de libertad.
A continuación se ilustra su uso para evaluar simultáneamente todas las posibles comparaciones por pares del ejemplo 8.1 y el contraste \(\{\mu_\text{A}, \mu_\text{B}, \mu_\text{E}\} - \{\mu_\text{C}, \mu_\text{D}\}.\) Los datos están organizados en el archivo ejemplo 8.1.xlsx.
Se usan coeficientes simplificados, los cuales son transformados internamente en coeficientes ponderados acordes con el número de réplicas de cada tratamiento.
data <- readxl::read_excel("ejemplo 8.1.xlsx")
data$tto <- factor(data$tto)
anova <- aov(y ~ tto, data = data)
coef <- matrix(c(1, 1, -1, -1, 1), nrow = 1)
rownames(coef) <- c("A, B, E - C, D")
source("hetero_fdr.R")
hetero_fdr(anova, coef = coef, coef.simp = TRUE)
Contrastes mediante el método de Benjamini y Hochberg
estimado tc gl p adj. sig.
A - B -4.6000 -2.6997 4.91 0.0959 .
A - C -7.4000 -12.6291 2.25 0.0138 *
A - D -1.9000 -1.5344 1.55 0.2979
A - E 2.4000 2.3080 5.97 0.1112
B - C -2.8000 -1.7365 4.06 0.1911
B - D 2.7000 1.3869 4.59 0.2519
B - E 7.0000 3.8314 8.00 0.0138 *
C - D 5.5000 4.9592 1.03 0.1661
C - E 9.8000 11.1106 4.21 0.0029 **
D - E 4.3000 3.0652 2.41 0.1144
A, B, E - C, D -4.7205 -5.8356 7.41 0.0029 **
Este método controla la tasa de falsos descubrimientos (TFD)8.16.8 Comparaciones con un control bajo heterocedasticidad
Existen varios procedimientos para realizar las \((k − 1)\) posibles comparaciones contra un tratamiento control partiendo de estadísticos tipo Welch.
En lugar de trabajar con el \(\text{CME}\) como estimador conjunto de la varianza dentro de los tratamientos, se utilizan estadísticos tipo Welch con las varianzas muestrales de los grupos comparados, lo que los hace pertinentes para realizar comparaciones en escenarios de heterocedasticidad.
Para el caso particular de comparaciones contra un grupo control, el cual se denota con el subíndice 0, estos estadísticos tienen la forma:
\[
t_\text{c}=\frac{\overline{Y}_i-\overline{Y}_0}{\sqrt{\dfrac{S_i^2}{r_i}+\dfrac{S_0^2}{r_0}}}\overset{H_0} \thicksim t_{(\widehat\nu_{i0})}, \quad i=1, \dotsc, k-1
\]
Los grados de libertad para la distribución de referencia se obtienen mediante la aproximación de Satterthwaite:
\[
\widehat\nu_{i0}=\dfrac{\left(\dfrac{S_i^2}{r_i}+\dfrac{S_{0}^2}{r_{0}}\right)^2}
{\dfrac{\left(\dfrac{S_i^2}{r_i}\right)^2}{r_i-1}+\dfrac{\left(\dfrac{S_{0}^2}{r_{0}}\right)^2}{r_{0}-1} }
\]
Li y Ning (2012) proponen un método basado en la desigualdad de Slepian, lo que garantiza la generación de intervalos con una confianza simultánea que nunca es menor del \(100(1-\alpha)\,\%.\) A este método lo denominan HET-2.
El método HET-2 ha mostrado un buen desempeño en diversos escenarios heterocedásticos, en los que otros métodos pueden resultar muy conservadores —como el T2 de Tamhane, adecuando la corrección de Šidák al número de comparaciones (cf. sección 8.16.2)— o no mantenían controlada la TEF —como el método PI de Hasler y Hothorn (2008).
El procedimiento HET-2 parte del hecho de que los estadísticos de prueba para las comparaciones contra el control están correlacionados positivamente. Esto permite emplear la desigualdad de Slepian para obtener una aproximación conservadora de la cobertura simultánea.
Los intervalos están basados en un único valor crítico \(q,\) que aunque se expresa en términos de una integral doble de compleja evaluación analítica, puede aproximarse mediante métodos numéricos.
Este método es conservador porque la probabilidad de cobertura simultánea es mayor o igual que el producto de las probabilidades de cobertura marginales. En este sentido, garantiza que la \(\text{TEF} \le \alpha.\)
En un escenario, en el que se tuviera interés en controlar la TFD en lugar de la TEF, los valores p de las pruebas individuales pueden ajustarse mediante los procedimientos de Benjamini y Hochberg o Benjamini y Yekutieli.
La función personalizada hetero_control implementa la prueba HET-2 que controla la TEF, así como el procedimiento basado en los estadísticos individuales tipo Welch con corrección de Benjamini y Hochberg o Benjamini y Yekutieli, para el control de la TFD.
La información se extrae desde un objeto de la clase aov o lm, correspondiente a un modelo lineal ajustado.
El argumento control permite especificar el tratamiento que se utiliza como control. Por defecto, se toma el primer nivel del factor.
La función hetero_control implementa tres métodos, que pueden elegirse mediante el argumento method:
HET2: Método HET-2 de Li y Ning, que controla la tasa de error por familia.BH: Procedimiento basado en pruebas de Welch con corrección de Benjamini y Hochberg para controlar la tasa de falsos descubrimientos.BY: Procedimiento basado en pruebas de Welch con corrección de Benjamini y Yekutieli para controlar la tasa de falsos descubrimientos.
Se utiliza el argumento conf.level para definir la confianza simultánea de los intervalos que se obtienen mediante el método HET-2. Por defecto, conf.level = 0.95.
A continuación se ilustra el uso de hetero_control, aplicado a los datos del ejemplo 8.1, tomando el tratamiento \(\text{E}\) como control:
1data <- readxl::read_excel("ejemplo 8.1.xlsx")
data$tto <- factor(data$tto)
anova <- aov(y ~ tto, data = data)
2source("hetero_control.R")
3hetero_control(anova, control = "E")- 1
- Importación y preparación de la base de datos y ajuste del modelo ANOVA.
- 2
-
Carga de la función
hetero_control. - 3
-
Llamado de la función, especificando el tratamiento
"E"como control.
Comparaciones bilaterales con un control,
usando el método HET-2 de Li y Ning
estimado tc gl lwr 95% upr 95% p value sig.
A - E 2.4 2.3080 5.9684 -2.2513 7.0513 0.2883
B - E 7.0 3.8314 6.1636 -1.1721 15.1721 0.0777 .
C - E 9.8 11.1106 4.2100 5.8547 13.7453 0.0043 **
D - E 4.3 3.0652 2.4090 -1.9749 10.5749 0.1438
Este método controla la TEF bajo heterocedasticidad8.17 Resumen de PCM
Cualquier prueba de hipótesis conlleva una relación inversa entre protección contra el error tipo I y potencia. Cuando se aplica un procedimiento particular a una muestra específica, el incremento en las especificaciones de uno de estos indicadores implica la reducción en el desempeño del otro.
Por tal motivo, cuando existen diferentes pruebas para la evaluación de un juego de hipótesis, estas suelen compararse con base en su potencia, fijando el nivel de significancia, bajo diferentes configuraciones muestrales.
Cuando se evalúan simultáneamente dos o más hipótesis usando la información de un experimento, surge un elemento adicional relacionado con la probabilidad de rechazar algunas de esas hipótesis por mero azar. Mientras mayor sea el número de pruebas evaluadas, mayor será dicha probabilidad.
Aparece el concepto de tasa de error por famila (TEF), que se define como la probabilidad de rechazar erróneamente al menos una hipótesis nula, cuando se evalúa una familia de hipótesis.
Uno de los procedimientos pioneros para comparar medias normales fue el de la diferencia mínima significativa (DMS), propuesto por Fisher en 1935. Se le atribuye a Fisher la recomendación de realizar las comparaciones entre medias únicamente cuando el ANOVA sea significativo (DMS protegida), a fin de obtener protección contra la inflación de la TEF. No obstante, Hochberg y Tamhane (1987) indican que la significancia del ANOVA únicamente brinda protección en sentido débil, es decir, si la hipótesis nula del ANOVA es cierta, en cuyo caso no procederían las comparaciones por pares.
En la década del 50 del siglo pasado surgieron muchos PCM enfocados en controlar la TEF. Entre los más populares se encuentran las pruebas de Duncan, Tukey, Scheffé y Dunnett.
La prueba de Duncan, que por mucho tiempo fue bastante utilizada, especialmente en investigación agraria —aunque resulta un tanto más exigente que la DMS— realmente no controla la TEF, mientras que las otras tres pruebas mencionadas sí lo hacen. Por tal razón, si se busca controlar la TEF, no debe considerarse este procedimiento.
La prueba de Tukey garantiza el control de la TEF cuando se realizan las \(k(k − 1)/2\) posibles comparaciones entre los pares de medias de un experimento. Muy a menudo, tales comparaciones son las únicas que se realizan y reportan en los trabajos de investigación. Si ese fuera el caso y se tuviera particular interés en controlar la TEF, la prueba de Tukey sería la indicada. Asimismo, esta es la prueba que debe usarse para obtener intervalos de confianza simultánea coherentes con el control de la TEF.
Si en adición a todas las comparaciones por pares, se quieren evaluar contrastes para comparar grupos de medias, la prueba de Scheffé es la indicada, ya que permite realizar un infinito número de contrastes, manteniendo controlada la TEF. Aunque esta prueba tiene propiedades teóricas interesantes, el investigador usualmente no desea evaluar infinitos contrastes, por lo que al usar esta prueba podría estar “pagando” más de lo que finalmente estaría “adquiriendo”.
Si la pregunta específica que el investigador desea responder es cuáles de los tratamientos difieren del control, la prueba de Dunnett proporciona mayor potencia que la prueba de Tukey para este tipo de comparaciones, manteniendo controlada la TEF.
Posteriormente, abarcando un periodo entre 1961 y 1995, surgen adaptaciones de las pruebas clásicas, así como nuevas pruebas. Resulta destacable en dicho periodo el auge de los métodos de ajuste de los valores p y, en particular, de los métodos secuenciales (stepwise), que aunque se reportan desde 1975, cobran importancia en 1979 con la adaptación que realiza Holm de la corrección de Bonferroni, propuesta en 1961 por Dunn23.
La propuesta de Dunn, mejor conocida como corrección de Bonferroni, se presenta sin pretensiones de competir contra la prueba de Tukey para la realización de todas las posibles comparaciones por pares. Dunn (1961) señala claramente que esta estrategia resulta ventajosa cuando se usa para evaluar un número pequeño de hipótesis predeterminadas.
Aunque en su momento, la corrección de Bonferroni no fue presentada como un método de ajuste de los valores p, constituyó la base de muchos de estos, tales como los métodos de Simes, Holm, Hochberg y Hommel, así como los que de estos se derivan.
Holm (1979) muestra que al aplicar la corrección de Bonferroni, mediante un método secuencial descendente (step-down), se gana en potencia sin sacrificar el control de la TEF.
Posteriormente, en 1988, Hochberg propone un procedimiento secuencial ascendente (step-up), el cual puede ofrecer mayor potencia que el de Holm, manteniendo controlada la TEF en los escenarios para los cuales fue propuesto.
En 1988, Hommel propone un procedimiento secuencial que, en lugar de realizarse de manera lineal paso a paso (stepwise), como los procedimientos de Holm y Hochberg, se realiza por etapas (stagewise), lo que le confiere una mayor potencia con respecto al método de Hochberg.
Dunnett y Tamhane (1992, 1995) proponen una adaptación de tipo secuencial ascendente para el método de Dunnett (1955, 1964) de comparaciones contra un control.
Hasta este punto, los procedimientos de comparación múltiple pueden interpretarse, desde un punto de vista conceptual, en dos grandes enfoques.
Por una parte, se encuentran los métodos basados en la distribución conjunta de los estadísticos de prueba, como los procedimientos de Tukey, Scheffé y Dunnett (incluyendo la propuesta secuencial ascendente de Dunnett-Tamhane), en los que el control de la TEF se logra incorporando directamente la estructura de correlación entre las comparaciones.
Por otra parte, se encuentran los métodos basados en cotas, como la corrección de Bonferroni y sus extensiones secuenciales (Holm, Hochberg), los cuales controlan la TEF mediante desigualdades generales sobre los valores p, sin modelar explícitamente la estructura conjunta exacta de dependencia entre las pruebas.
En términos generales, los métodos del primer grupo suelen ofrecer mayor potencia en los escenarios específicos para los cuales fueron diseñados, mientras que los del segundo proporcionan una mayor flexibilidad al poder aplicarse en contextos más generales.
En la medida en que un experimento tenga más tratamientos, hay lugar a un mayor número de comparaciones y consecuentemente a que las pruebas que controlan la TEF impongan correcciones más severas sobre las comparaciones individuales, con la consiguiente pérdida de potencia. Esto ha llevado a que autores como Saville (1990) defiendan el uso de la prueba DMS, sin ningún tipo de corrección, preocupándose únicamente por la tasa de error por comparación.
Buscando un compromiso entre las severas correcciones impuestas por los métodos que controlan la TEF y el ignorar completamente el problema de la multiplicidad, Benjamini y Hochberg (1995) presentan una solución práctica y potente: el control de la tasa de falsos descubrimientos (TFD). Bajo esta aproximación no se requiere controlar la probabilidad de cometer al menos un error tipo I cuando se evalúa una familia de hipótesis —condición bastante restrictiva—, sino que se controla la proporción de errores tipo I en las hipótesis rechazadas.
Habrá casos en los que el enfoque de control de la TFD resulte más pertinente que el de control de la TEF. Aquí cobra especial relevancia una de las preguntas que Tukey nos invitaba a formularnos en su artículo de 1995 sobre la filosofía de las comparaciones múltiples: ¿qué queremos que hagan las comparaciones múltiples?
Benjamini y Hochberg (1995), a la vez que plantean el nuevo paradigma de la TFD, también proponen un procedimiento secuencial ascendente basado en este, el cual es conocido actualmente como procedimiento de Benjamini y Hochberg (BH) y puede usarse para evaluar hipótesis independientes o correlacionadas positivamente, así como para realizar todas las posibles comparaciones por pares o comparaciones contra un grupo control.
Posteriormente, en 2001, Benjamini y Yekutieli proponen un procedimiento que, aunque puede usarse para evaluar cualquier conjunto de pruebas, sean independientes o no, es menos potente que el de Benjamini y Hochberg.
Paralelamente al desarrollo de las pruebas clásicas, que están basadas en el supuesto de homogeneidad de varianzas, se elaboraron alternativas para la comparación de medias cuando no se satisface dicha condición. En el presente capítulo se compilan algunas de estas.
La prueba T3 de Dunnett es la recomendada para todas las posibles comparaciones por pares. La prueba de Brown-Forsythe, con ajuste de Ury-Wiggins, proporciona un marco más general que permite realizar cualquier número de contrastes entre grupos de medias. La prueba HET-2 de Li y Ning es la que exhibe el mejor desempeño para las \((k-1)\) comparaciones contra un tratamiento control. Asimismo, los valores p derivados de estadísticos tipo Welch pueden ajustarse mediante los procedimientos de Benjamini-Hochberg o Benjamini-Yekutieli si se busca controlar la TFD.
Vale la pena anotar que las pruebas que suponen varianzas homogéneas, al usar un estimador conjunto de la variabilidad interna de los tratamientos (el \(\text{CME}\)), cuentan con más grados de libertad, por lo que en general son más potentes y deben constituir la primera alternativa para la comparación de medias o grupos de medias, siempre que no existan evidencias importantes de heterocedasticidad.
Aunque la investigación sobre los PCM sigue estando plenamente activa, siendo muchas las propuestas que han surgido en el presente siglo, se ha optado por establecer un corte en este punto, de manera que el investigador cuente con elementos para elegir algunos de los PCM más populares y en particular algunos de factible aplicación, gracias a su implementación en R.
En síntesis, lo ideal es que el investigador defina a priori las comparaciones que desea realizar y el tipo de error global que desea controlar: la TEF o la TFD. Si por las características de su ensayo y por las implicaciones que los errores tipo I puedan tener, decide que debe controlar la TEF, se recomiendan los procedimientos de Tukey, Scheffé y Dunnett-Tamhane, en caso de que se satisfaga el supuesto de homogeneidad de varianzas, y los procedimientos T3, Brown-Forsythe y Li-Ning en caso contrario.
Bajo homocedasticidad, se recomienda la prueba de Tukey para realizar todas las posibles comparaciones por pares y para la obtención de intervalos de confianza simultánea; la prueba de Dunnett-Tamhane para las comparaciones de todos los tratamientos contra un control; y la prueba de Scheffé, si se realiza un número de comparaciones mayor que \(k(k-1)/2.\)
Bajo heterocedasticidad, se recomienda la prueba T3 de Dunnett para comparaciones por pares, la prueba de Brown-Forsythe con ajuste de Ury-Wiggins para un número de comparaciones mayor que \(k(k-1)/2\) y la prueba de Li y Ning para comparaciones contra un tratamiento testigo.
Si en lugar de controlar la TEF, el investigador define que le resulta más pertinente el control de la TFD, tendrá a su disposición las correcciones de Benjamini y Hochberg (BH) y la de Benjamini y Yekutieli (BY), que podrá usar sobre los valores p provenientes de la prueba DMS si se satisface el supuesto de homogeneidad de varianzas o sobre los valores p de estadísticos tipo Welch con grados de libertad de Satterthwaite en caso contrario.
La tabla 8.18 presenta una clasificación de los PCM, basada en dos criterios: el tipo de control por multiplicidad (TEF o TFD) y la homogeneidad de varianzas (homogéneas o heterogéneas). Esta clasificación da lugar a cuatro grupos de pruebas. En cada grupo se anotan las pruebas recomendadas para situaciones específicas.
| Control de la TEF | Control de la TFD | |
|---|---|---|
| Varianzas homogéneas |
|
|
| Varianzas heterogéneas |
|
|
Finalmente, es importante comentar un asunto sobre el que existen criterios encontrados. ¿Es válido realizar algún PCM si el ANOVA no es significativo? Aunque muchos autores han proscrito dicha práctica, otros tantos la consideran válida y recomendable.
El único procedimiento que explícitamente exige un ANOVA significativo para su realización es el de la DMS protegida de Fisher, el cual, como se discutió previamente, solo protege la TEF en sentido débil, es decir, cuando la hipótesis nula es cierta.
¿¡Y la DMS con corrección de valores p!?
La DMS protegida de Fisher confía —ingenuamente— el control de la TEF al hecho de que el ANOVA resulte significativo.
En contraste, procedimientos como el de Holm, Hochberg, Hommel, BH y BY no se fundamentan en una protección previa de la TEF, sino que se aplican sobre una familia de hipótesis en las que cada valor p sea válido para la correspondiente hipótesis individual. Esto sí lo hace la prueba DMS, sea que el ANOVA resulte significativo o no.
En consecuencia, las estrategias de ajuste son aplicables a los valores p resultantes de la prueba DMS, sin necesidad de que el ANOVA haya sido significativo.
Una de las primeras recomendaciones explícitas acerca del uso no condicionado de los PCM es presentada por Scheffé (1977), quien, respondiendo a una crítica de Olshen (1973) sobre el uso condicional del método \(S\) para la estimación de intervalos de confianza simultánea, reconoce que dicho método debe aplicarse de manera no condicionada, es decir, sin importar el resultado del ANOVA, siempre que esté pensado como método de comparación múltiple.
Hochberg y Tamhane (1987) mencionan que esto no solo es válido para la prueba \(S\), sino para cualquier PCM. Rafter, Abell y Braselton (2002) indican que la práctica de emplear algún PCM únicamente tras un ANOVA significativo es teóricamente innecesaria y que implicaría un proceso de dos pasos que podría hacer que se pierdan resultados importantes. Bretz, Hothorn y Westfall (2011) recomiendan igualmente realizar los PCM sin importar si el ANOVA es significativo o no.
En coincidencia con lo señalado anteriormente, consideramos que los PCM deben realizarse en todo experimento con más de dos tratamientos, sin importar que el ANOVA haya sido significativo o no.
¿¡Y, entonces, el ANOVA para qué!?
El ANOVA, más allá de facilitar la estimación del \(\text{CME}\) y de constituir el insumo de algunas funciones en R, configura el marco en el que debe verificarse la satisfacción de los supuestos del modelo.
Desde luego, la presentación del ANOVA clásico en el reporte final de un experimento heterocedástico sería cuestionable. Por coherencia, en tales casos debe reportarse el resultado del ANOVA de Welch (cf. sección 6.4) como prueba global.
Referencias bibliográficas
Abdi, Hervé. (2010). Holm’s sequential Bonferroni procedure. En N. J. Salkind (Ed.), Encyclopedia of Research Design. Sage.
Abdi, Hervé and Williams, Lynne J. (2010). Tukey’s honestly significant difference (HSD) test. En N. J. Salkind (Ed.), Encyclopedia of Research Design. Sage.
Benjamini, Y. and Braun. H. (2002). John W. Tukey’s contributions to multiple comparisons. The American Statistician, 30(6), 1576-1594.
Benjamini, Y. and Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological), 57(1), 289-300.
Benjamini, Y. y Yekutieli, D. (2001). The control of the false discovery rate in multiple testing under dependency. The annals of statistics, 29(4), 1165-1188.
Block, H. W., Savits, T. H. and Wang, J. (2008). Negative dependence and the Simes inequality. Journal of Statistical Planning and Inference, 138(12), 4107-4110. https://doi.org/10.1016/j.jspi.2008.03.026
Braun, Henry I. (Ed.). (1994). The Collected Works of John W. Tukey. Volume VIII: Multiple Comparisons: 1948–1983. Chapman and Hall/CRC.
Bretz, F., Hothorn, T. and Westfall, P. (2011). Multiple comparisons using R. Chapman & Hall/CRC.
Brown, M. B. and Forsythe, A. B. (1974). The anova and multiple comparisons for data with heterogeneous variances. Biometrics, 30(4), 719-724.
Cox, D. R. (1965). A remark on multiple comparison methods. Technometrics, 72(2), 223-224.
Day, R. W. and Quinn, G. P. (1989). Comparisons of treatments after an analysis of variance in ecology. Ecological Monographs, 59(4), 433-463.
Duncan, D. B. (1955). Multiple Range and Multiple F Tests. Biometrics, 11(1), 1-42.
Dunn, O. J. (1958). Estimation of the Means of Dependent Variables. The Annals of Mathematical Statistics, 29(4), 1095-1111.
Dunn, O. J. (1959). Confidence Intervals for the Means of Dependent, Normally Distributed Variables. Journal of the American Statistical Association, 54(287), 613-621.
Dunn, O. J. (1961). Multiple comparisons among means. Journal of the American Statistical Association, 56(293), 52-64.
Dunnett, C. W. (1955). A multiple comparison procedure for comparing several treatments with a control. Journal of the American Statistical Association, 50(272), 1096-1121.
Dunnett, C. W. (1964). New tables for multiple comparisons with a control. Biometrics, 20(3), 482-491.
Dunnett, C. W. (1980a). Pairwise multiple comparisons in the homogeneous variance, unequal sample size case. Journal of the American Statistical Association, 75(372), 789-785.
Dunnett, C. W. (1980b). Pairwise multiple comparisons in the unequal variance case. Journal of the American Statistical Association, 75(372), 796-800.
Dunnett, C. W. and Tamhane, A. C. (1991). Step-Down Multiple Tests for Comparing Treatments With a Control in Unbalanced One-way Layouts. Statistics in Medicine, 10(6), 939-947. https://doi.org/10.1002/sim.4780100614
Dunnett, C. W. and Tamhane, A. C. (1992). A step-up multiple test procedure. Journal of the American Statistical Association, 87(417), 162-170.
Dunnett, C. W. and Tamhane, A. C. (1995). Step-up multiple testing of parameters with unequally correlated estimates. Biometrics, 51(1), 217-227.
Games, P. A. (1977). An Improved t Table for Simultaneous Control on g Contrasts. Journal of the American Statistical Association, 72(359), 531-534.
Games, P. A. y Howell, J. F. (1976). Pairwise multiple comparison procedures with unequal n’s and/or variances: A Monte Carlo study. Journal of Educational Statistics, 1(2), 113-125.
Gou, J. and Tamhane, A. C. (2018). Hochberg procedure under negative dependence. Statistica Sinica, 28(1), 339-362. https://doi.org/10.5705/ss.202016.0306
Guilbaud, O. (2008). Simultaneous Confidence Regions Corresponding to Holm’s Step-Down Procedure and Other Closed-Testing Procedures. Biometrical Journal, 50(5), 678-692. https://doi.org/10.1002/bimj.200710449
Hasler, M. and Hothorn, A. L. (2008). Multiple contrast tests in the presence of heteroscedasticity. Biometrical Journal, 50(5), 793-800.
Hayter, A. J. (1984). A proof of the conjecture that the Tukey-Kramer multiple comparison procedure is conservative. The Annals of Statistics, 12(1), 61-75.
Hochberg, Y. (1988). A sharper Bonferroni procedure for multiple tests of significance. Biometrika, 75(4), 800-802.
Hochberg, Y. and Tamhane, A. C. (1987). Multiple Comparison Procedures. Wiley.
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6(2), 65-70.
Hommel, G. (1988). A Stagewise Rejective Multiple Test Procedure Based on a Modified Bonferroni Test. Biometrika, 75(2), 383-386.
Hsu, J. C. and Peruggia, M. (1994). Graphical representations of Tukey’s multiple comparison method. Journal of Computational and Graphical Statistics, 3(2), 143-161.
Korhonen, M. P. (1982). On the performance of some multiple comparison procedures with unequal variances. Scandinavian Journal of Statistics, 9(4), 241-247.
Kramer, C. Y. (1956). Extension of multiple range tests to group means with unequal numbers of replications. Biometrics, 12(3), 307-310.
Li, H. and Ning, W. (2012). Multiple comparisons with a control under heteroscedasticity. Journal of Applied Statistics, 39(10), 2275-2283. http://dx.doi.org/10.1080/02664763.2012.706269
Mead, R., Gilmour, S. G. y Mead, A. (2012). Statistical principles for the design of experiments. Cambridge.
O’Brien, P. C. (1983). The appropriateness of analysis of variance and multiple-comparison procedures. Biometrics, 39(3), 787-788.
Olshen, R. A. (1973). The conditional level of the F-test. Journal of the American Statistical Association, 68(343), 692-698.
Ozkaya, G. and Ercan, I. (2012). Examining Multiple Comparison Procedures According to Error Rate, Power Type and False Discovery Rate. Journal of Modern Applied Statistics Methods, 11(2), 348-360. https://doi.org/10.22237/jmasm/1351742760
Rafter, J. A., Abell, M. L. and Braselton, J. P. (2002). Multiple comparison methods for means. SIAM Review, 44(2), 259-278.
Sarkar, S. K. (1998). Some probability inequalities for ordered \(\text{MTP}_2\) random variables: A proof of the Simes conjecture. The Annals of Statistics, 26(2), 494-504.
Saville, D. J. (1990). Multiple comparison procedures: the practical solution. The American Statistician, 44(2), 174-180.
Scheffé, H. (1953). A method for judging all contrasts in the analysis of variance. Biometrika, 40(1), 87-104.
Scheffé, H. (1977). A note on a reformulation of the S-method of multiple comparison. Journal of the American Statistical Association, 72(357), 143-144.
Šidák, Z. (1967). Rectangular confidence regions for the means of multivariate normal distributions. Journal of the American Statistical Association, 62(318), 626-633.
Simes, R. J. (1986). An improved Bonferroni procedure for multiple tests of significance. Biometrika, 73(3), 751-754.
Soriç, B. (1989). Statistical «discoveries» and effect-size estimation. Journal of the American Statistical Association, 84(406), 608-610.
Strassburger, K. and Bretz, F. (2008). Compatible simultaneous lower confidence bounds for the Holm procedure and other Bonferroni-based closed tests. Statistics in Medicine, 27(24), 4914-4927. https://doi.org/10.1002/sim.3338
Tamhane, A. C. (1979). A comparison of procedures of means with unequal variances. Journal of the American Statistical Association, 74(366), 471-480.
Tukey, J. W. (1991). The philosophy of multiple comparisons. Statistical Science, 6(1), 100-116.
Ury, H. K. y Wiggins, A. D. (1971). Large sample and other multiple comparisons among means. British Journal of Mathematical and Statistical Psychology, 24(2), 174-191. https://doi.org/10.1111/j.2044-8317.1971.tb00465.x
Williams, V. S. L., Jones, L. V. and Tukey, J. W. (1999). Controlling error in multiple comparisons, with examples from state-to-state differences in educational achievement. Journal of Educational and Behavioral Statistics, 24(1), 1005-1013.
Wright, S. P. (1992). Adjusted p-values for simultaneous inference. Biometrics, 48, 1005-1013.
International Conference on Multiple Comparison Procedures↩︎
Se presentan los valores críticos para \(\alpha=0.05\) y \(\alpha=0.01\).↩︎
Aunque ha caído en desuso, también fue muy común utilizar líneas para unir las medias de los tratamientos entre los cuales no se presentara diferencia estadísticamente significativa.↩︎
Esta variante se le atribuye a Fisher.↩︎
No obstante, circuló durante mucho tiempo como un memorando interno de la Universidad de Princeton, con el título The Problem of Multiple Comparisons. No fue sino hasta 1994 que Henry Braun compiló este y otros trabajos en el volumen VIII de la obra The Collected Works of John W. Tukey (Braun, 1994).↩︎
Este aparente descuido es explicable por el hecho de que la propuesta de Tukey no apareció en una publicación seriada, sino que circuló como un memorando interno de la Universidad de Princeton.↩︎
En el caso de tratamientos con diferente número de réplicas, se usa el error estándar de la prueba de Tukey-Kramer.↩︎
El intervalo de confianza para \(\mu_\text{A} − \mu_\text{B}\) tiene ambos límites en la región positiva.↩︎
Y también cuando \(k=2.\)↩︎
Los saltos de línea y los espaciamientos entre coeficientes tienen como único fin el facilitar la visualización de los contrastes.↩︎
Puede usarse un solo valor si las réplicas son iguales↩︎
Un ensayo con 50 tratamientos daría lugar a 1225 comparaciones por pares.↩︎
Nombrada en honor del matemático italiano Carlo Emilio Bonferroni.↩︎
La potencia generalmente es mayor; solo en casos triviales, que no revisten interés, es igualmente potente.↩︎
Podrían ser los valores p de cualquier otra prueba, siempre que dicha prueba no imponga correcciones para el control de la TEF, pues en tal caso se estaría aplicando una doble corrección.↩︎
La probabilidad error tipo I es menor que la significancia nominal.↩︎
Que la probabilidad de error tipo I no exceda el nivel de significancia nominal.↩︎
En ocasiones, bastante menor↩︎
El procedimiento es aplicable a cualquier otra prueba en la que no se haya realizado control de TEF.↩︎
False discovery rate.↩︎
En este ejemplo, esta es la única hipótesis para la que se satisface al menos una condición.↩︎
Nótese que el numerador de la expresión para el cálculo de los grados de libertad es la cuarta potencia del error estándar del contraste.↩︎
Holm cita una propuesta de U. D. Naik de 1975, donde se discuten procedimientos del mismo tipo y otra de R. Marcus, E. Peritz y K. R. Gabriel, de 1976, en la que se discuten procedimientos equivalentes.↩︎