5 COMPARACIÓN DE DOS POBLACIONES
La forma más usual de comparar dos poblaciones es a través de sus parámetros. Aunque pueda parecer obvio, cabe señalar que las comparaciones siempre se realizan entre parámetros de la misma naturaleza, es decir, se comparan medias con medias, varianzas con varianzas y proporciones con proporciones.
En este capítulo se presentan los métodos clásicos para la comparación de varianzas y medias en dos poblaciones normales, así como para la comparación de las probabilidades de éxito en dos poblaciones binomiales.
El capítulo concluye con un decálogo sobre pruebas de hipótesis (cf. sección 5.7), en el que se sintetizan los aspectos más relevantes concernientes a la formulación e interpretación de esta herramienta inferencial.
5.1 Comparación de las varianzas de dos poblaciones normales
Aunque la prueba para comparar varianzas es análoga en su escritura a las pruebas para comparar medias1, suele hablarse de pruebas de “diferencias de medias” y pruebas de “homogeneidad de varianzas”.
Los términos usados en cada caso reflejan diferencias conceptuales en la naturaleza de estos parámetros.
Al ser la media un parámetro de posición, podría suceder que dos medias ocuparan la misma posición (medias iguales) o que ocuparan distintas posiciones (medias diferentes).
En contraste, siendo la varianza un parámetro de dispersión, esta no se conceptualiza a través de su posición (aunque pueda representarse mediante un número). Así, al comparar la dispersión de dos poblaciones, puede encontrarse que estas presentan una variabilidad similar (varianzas homogéneas) o que una de ellas exhibe mayor variabilidad que la otra (varianzas heterogéneas).
A la condición propia de un conjunto de poblaciones con varianzas homogéneas se le denomina homocedasticidad. Como contraparte, a la condición de un conjunto de poblaciones con varianzas que no son todas homogéneas, se le conoce como heterocedasticidad.
En última instancia…
A pesar de la diferenciación indicada, no es del todo inusual ni es incorrecto hablar de varianzas iguales/diferentes.
5.1.1 Prueba de hipótesis para comparar dos varianzas normales
Considérense dos muestras aleatorias independientes, provenientes de sendas poblaciones normales2:
\(X_{11},X_{12},...,X_{1n_1}\: \text{iid}\: N\left(\mu_1, \sigma_1^2\right)\quad\) y \(\quad X_{21},X_{22},...,X_{2n_2}\: \text{iid}\: N\left(\mu_2, \sigma_2^2\right)\)
Tal y como se ilustró en la sección 4.3.1.1, los siguientes estadísticos siguen distribuciones ji cuadrado.
\[
\frac{(n_1-1)S^2_1}{\sigma_1^2}\thicksim \chi^2_{(n_1-1)} \quad \text{y}\quad \frac{(n_2-1)S^2_2}{\sigma_2^2}\thicksim \chi^2_{(n_2-1)}
\]
En la sección 3.7.4 se mostró que la razón entre dos variables aleatorias ji cuadrado independientes divididas entre sus grados de libertad sigue una distribución \(F.\) En su forma general se expresa así:
\[
\frac{\textcolor{blue}{\chi^2_{(n_1-1)}}}{\textcolor{red}{(n_1-1)}}\Bigg/
\frac{\textcolor{blue}{\chi^2_{(n_2-1)}}}{\textcolor{red}{(n_2-1)}}
\thicksim F_{(n_1-1,\;n_2-1)}
\]
Para el presente caso, la razón adquiere la forma específica:
\[
\frac{\textcolor{blue}{(n_1-1)S^2_1}}{\textcolor{blue}{\sigma_1^2}\textcolor{red}{(n_1-1)}}\Bigg/
\frac{\textcolor{blue}{(n_2-1)S^2_2}}{\textcolor{blue}{\sigma_2^2}\textcolor{red}{(n_2-1)}}\thicksim F_{(n_1-1,\;n_2-1)}
\]
Al simplificarse adquiere la siguiente forma:
\[
\frac{S^2_1}{\sigma_1^2}\Bigg/
\frac{S^2_2}{\sigma_2^2}\thicksim F_{(n_1-1,\;n_2-1)}
\]
Considérese ahora el siguiente juego de hipótesis para comparar las varianzas de las dos poblaciones:
\(H_0:\sigma_1^2=\sigma_2^2\) (varianzas homogéneas)
\(H_a:\sigma_1^2\ne\sigma_2^2\) (varianzas heterogéneas)
¿¡Prueba de homogeneidad de varianzas!?
Cuando se contrasta un juego de hipótesis para comparar varianzas, lo que en realidad podría probarse es que las varianzas son heterogéneas.
Consecuentemente, a estas pruebas sería más correcto llamarlas de “heterogeneidad de varianzas”. No obstante, lo más común es denominarlas pruebas de “homogeneidad de varianzas”.
En este caso sucede algo análogo a lo que ocurre con las llamadas pruebas de normalidad, que son en realidad pruebas de falta de normalidad (cf. advertencia 4.1).
La hipótesis nula implica que las poblaciones comparadas tienen una varianza común, es decir,
\[
\sigma_1^2=\sigma_2^2=\sigma^2
\]
Bajo la hipótesis nula, el estadístico construido anteriormente adquiere la siguiente forma:
\[
\frac{S^2_1}{\sigma^2}\Bigg/
\frac{S^2_2}{\sigma^2}
={S^2_1}\big/
{S^2_2}
\thicksim F_{(n_1-1,\;n_2-1)}
\]
Esta expresión se usa como estadístico de prueba para contrastar el juego de hipótesis:
\[
F_\text{c}=\frac {S^2_1}
{S^2_2}\overset {H_0}\thicksim F_{(n_1-1,\;n_2-1)}
\]
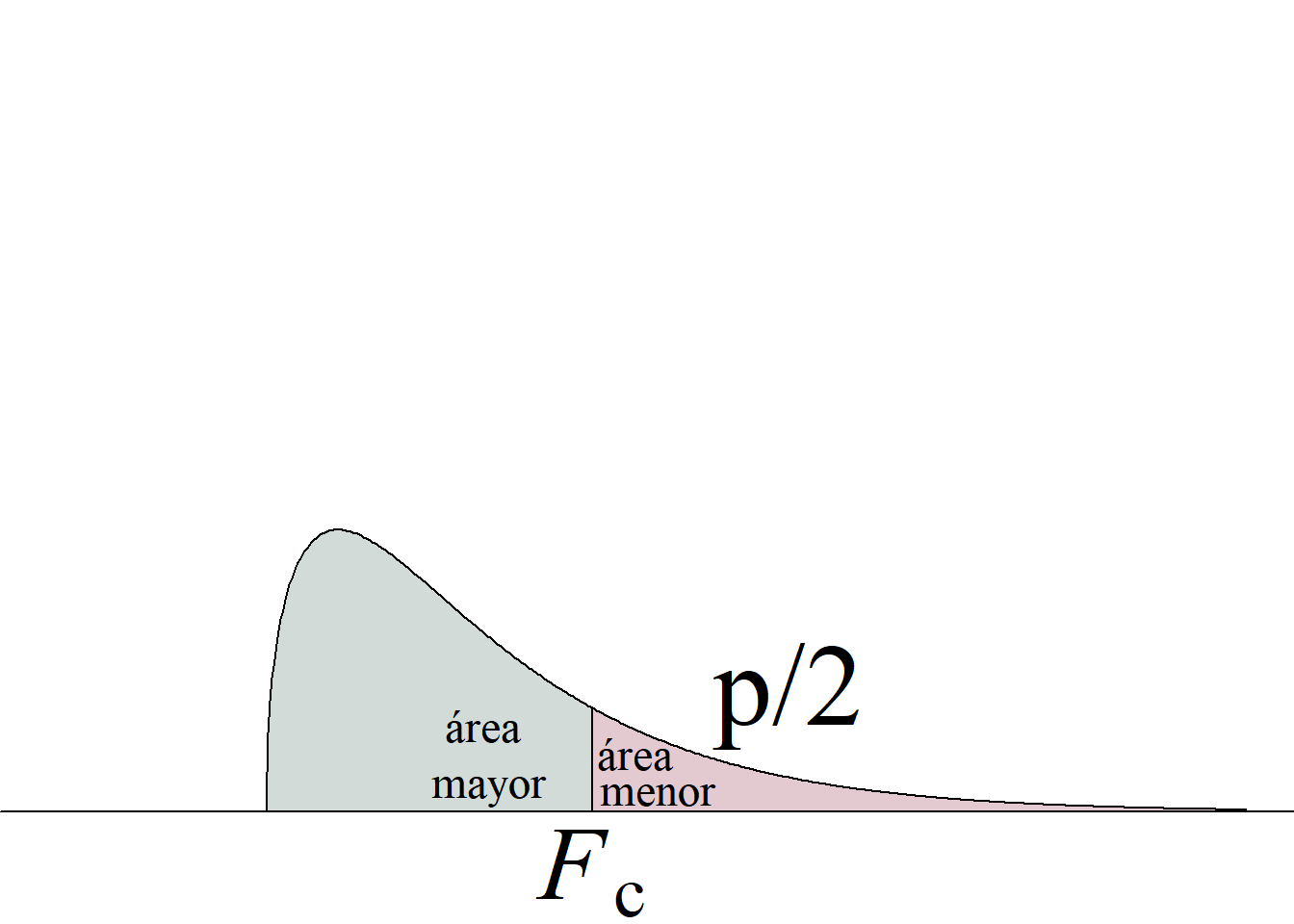
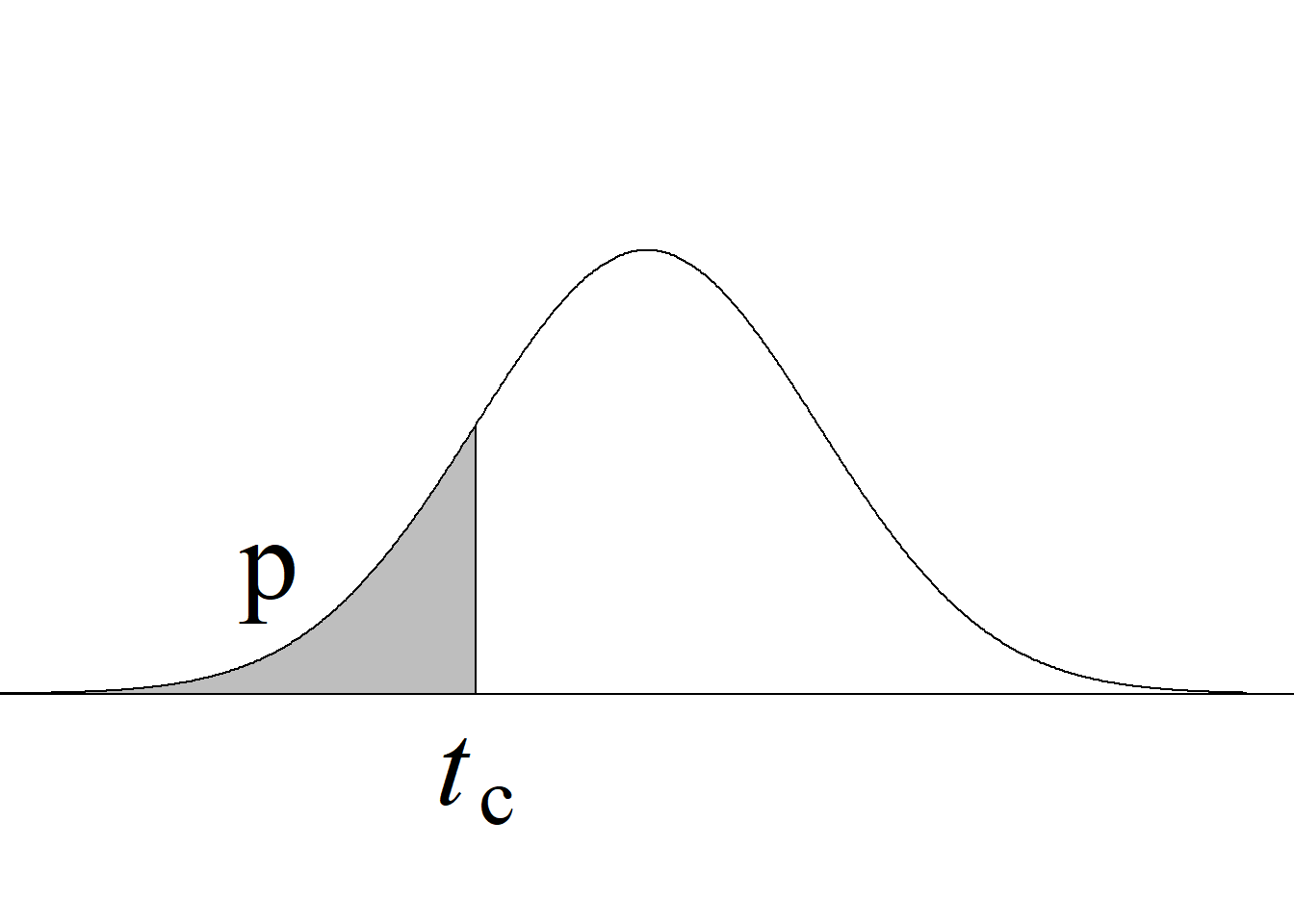
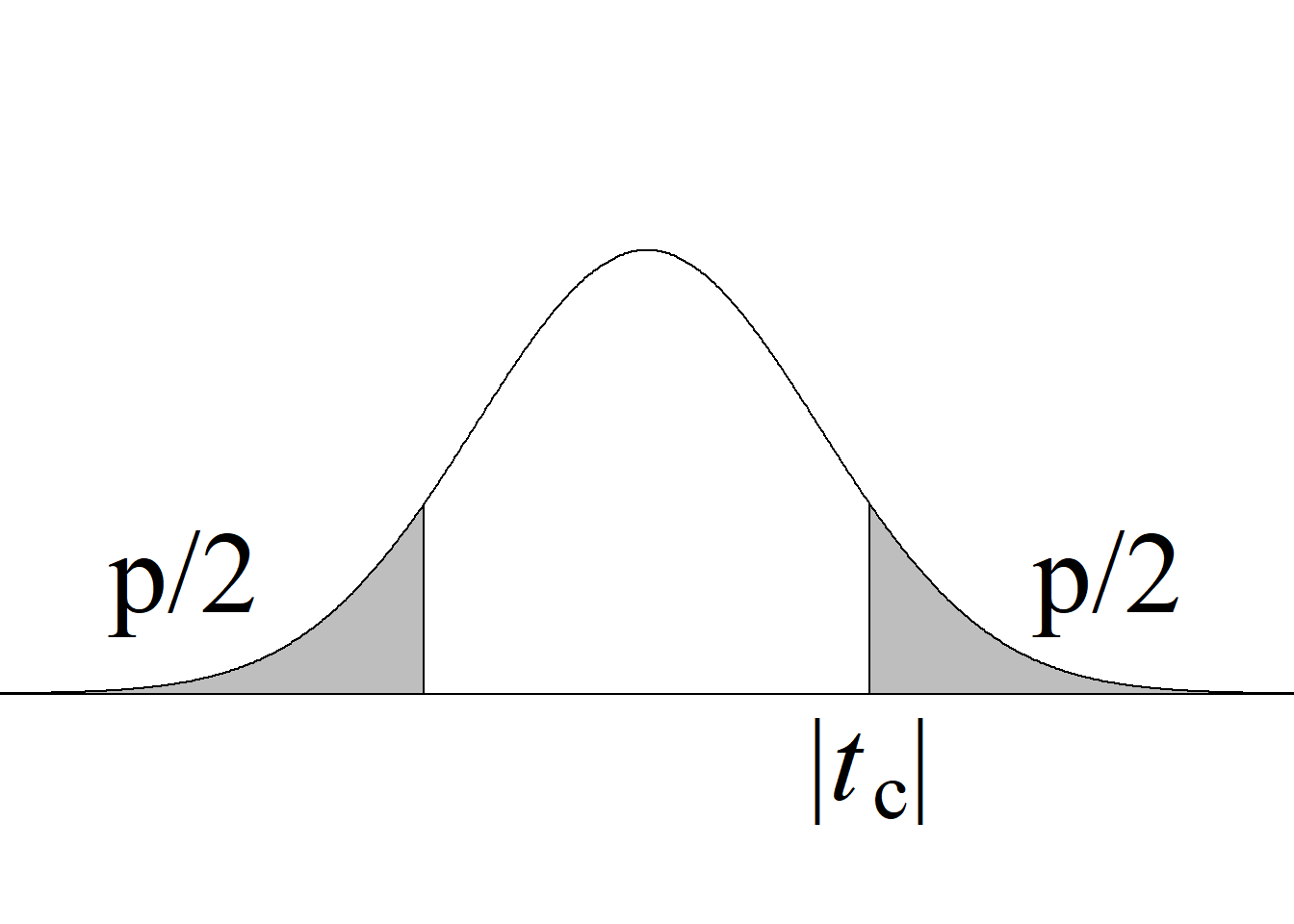
Para el juego de hipótesis planteado y el estadístico de prueba propuesto, la región de rechazo de la hipótesis nula con un nivel de significancia \(\alpha\) se define a partir de los valores críticos de la distribución \(F\) con \((n_1\!\!−\!\!1,\; n_2\!\!−\!\!1)\) gl que dejan áreas de \(\alpha/2\) en cada cola de la distribución.
En este caso, por tratarse de una región de rechazo construida con base en una distribución probabilística asimétrica, no es posible presentar una regla de rechazo simplificada usando valor absoluto.
El criterio de rechazo se escribe así:
Si \(F_\text{c} \le f_{1-\alpha/2(n_1-1,\; n_2-1)}\) o \(F_\text{c} \ge f_{\alpha/2(n_1-1,\; n_2-1)} \Rightarrow\) se rechaza \(H_0\) con un n. s. \(\alpha.\)
¿Cuál varianza va en el numerado y cuál en el denominador?
Puesto que la asignación de las etiquetas para las poblaciones comparadas es arbitraria, también lo es la construcción del estadístico de prueba, pudiendo tenerse cualquiera de las siguientes versiones para la misma comparación:
\(F_\text{c}=\dfrac {S^2_1}{S^2_2}\overset {H_0}\thicksim F_{(n_1-1,\;n_2-1)}\quad\) y \(\quad F_\text{c}^*=\dfrac {S^2_2}{S^2_1}\overset {H_0}\thicksim F_{(n_2-1,\;n_1-1)}\)
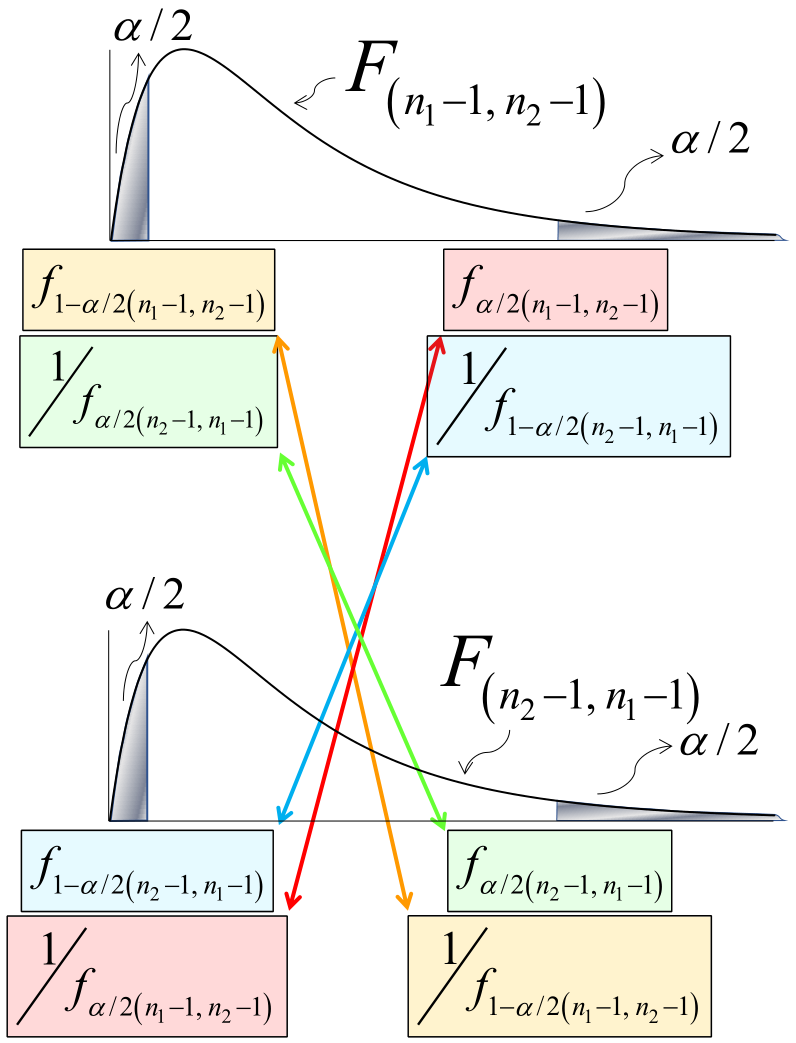
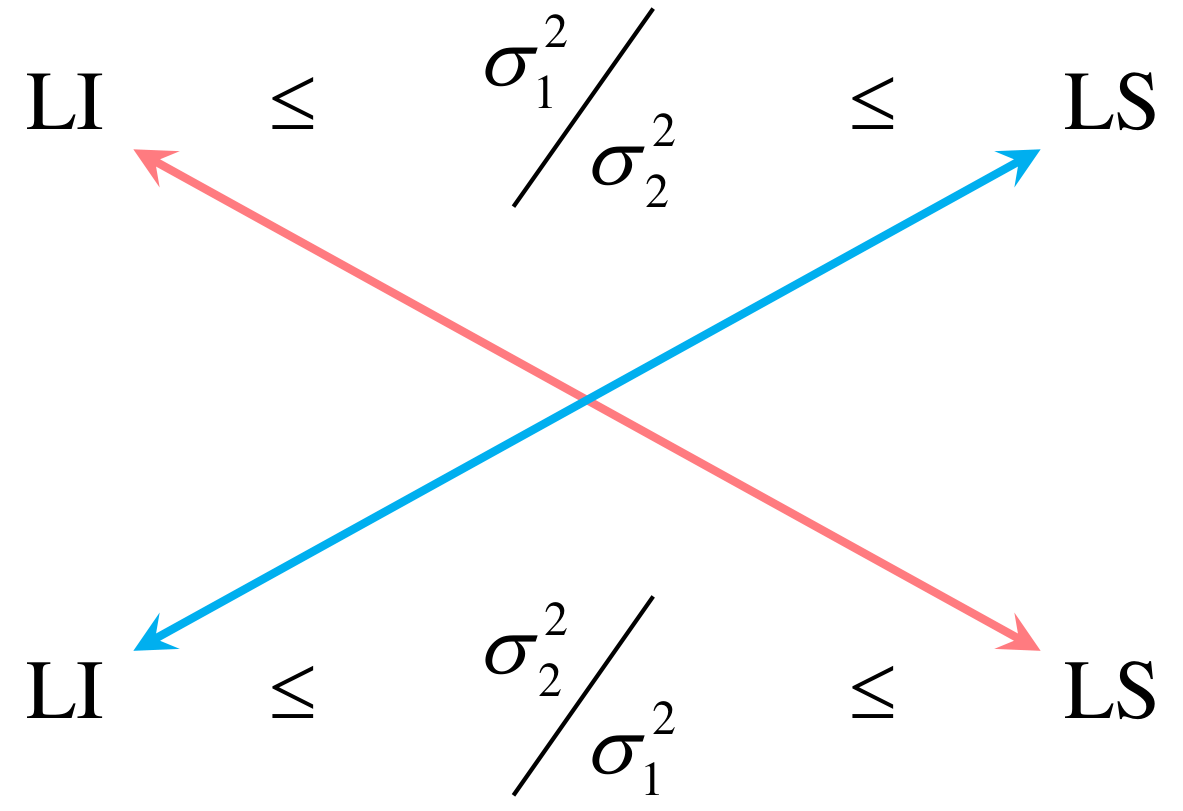
Aunque los estadísticos resultantes son diferentes y también lo es la distribución de referencia (obsérvese el cambio en los grados de libertad), ambas versiones conducen al mismo resultado, en virtud de las relaciones de inversión que se ilustran en la figura 5.1.
En la parte superior de la figura 5.1 se presenta la distribución que seguiría el estadístico \(F_\text{c},\) bajo \(H_0,\) esto es, una distribución \(F\) con \((n_1\!\!−\!\!1,\; n_2\!\!−\!\!1)\) gl, con sus correspondientes regiones de rechazo.
Análogamente, en la parte inferior se muestra el referente distribucional, bajo \(H_0,\) para el estadístico \(F_\text{c}^*,\) con sus correspondientes regiones de rechazo.
Los valores críticos unidos por flechas son inversos multiplicativos que se corresponden con el complemento de \(\alpha\) de la distribución \(F\) con los grados de libertad intercambiados, acorde con la siguiente identidad:
\[
f_{\alpha(n,\;m)}=\dfrac{1}{f_{1-\alpha(m,\;n)}}
\tag{5.1}\]
A continuación se ilustra esta equivalencia, partiendo del criterio de rechazo con un nivel de significancia \(\alpha\) cuando se usa el estadístico \(F_\text{c}\) y llegando al criterio de rechazo con el mismo nivel de significancia cuando se usa el estadístico \(F_\text{c}^*.\)
El criterio de rechazo de la hipótesis nula con un nivel de significancia \(\alpha\) para una prueba de dos colas cuando se usa el estadístico \(F_\text{c}\) es:
\[
F_\text{c} \le f_{1-\alpha/2(n_1-1,\;n_2-1)}\quad\text{o}\quad F_\text{c} \ge f_{\alpha/2(n_1-1,\;n_2-1)}
\]
Se remplaza \(F_\text{c}\) por la razón de varianzas muestrales, acorde con su definición:
\[
\dfrac{S_1^2}{S_2^2} \le f_{1-\alpha/2(n_1-1,\;n_2-1)}\quad\text{o}\quad \dfrac{S_1^2}{S_2^2} \ge f_{\alpha/2(n_1-1,\;n_2-1)}
\]
Puesto que todos los factores que conforman estas desigualdades son positivos, es posible reescribirlas de la siguiente manera, sin alterar su sentido:
\[
\dfrac{1}{f_{1-\alpha/2(n_1-1,\;n_2-1)}}\le\dfrac{S_2^2}{S_1^2}\quad\text{o}\quad \dfrac{1}{f_{\alpha/2(n_1-1,\;n_2-1)}} \ge \dfrac{S_2^2}{S_1^2}
\]
Usando la identidad 5.1 y la definición de \(F_\text{c}^*,\) este par de desigualdades pueden escribirse así:
\[
f_{\alpha/2(n_2-1,\;n_1-1)}\le F_\text{c}^* \quad\text{o}\quad f_{1-\alpha/2(n_2-1,\;n_1-1)} \ge F_\text{c}^*
\]
Al reorganizar estas desigualdades, se hace evidente que se ha llegado al criterio de partida:
\[
F_\text{c}^* \le f_{1-\alpha/2(n_2-1,\;n_1-1)}\quad\text{o}\quad F_\text{c}^* \ge f_{\alpha/2(n_2-1,\;n_1-1)}
\]
En concreto…
Es indiferente cuál varianza se ubique en el numerador y cuál otra en el denominador para la construcción del estadístico de prueba: el resultado será exactamente el mismo, en términos de significancia.
¡Pero a mí me habían dicho…!
Teniendo en cuenta que para la prueba de homogeneidad de varianzas de dos colas resulta indiferente construir el estadístico de prueba usando cualquiera de las varianzas muestrales en el numerador y la otra en el denominador, y considerando que las tablas de la distribución \(F\) usualmente presentan solo las áreas de la cola derecha, siendo necesario obtener las áreas acumuladas de manera indirecta (mediante la identidad 5.1), ha sido tradicional construir el estadístico de prueba de tal manera que se logre eludir la búsqueda del valor crítico inferior.
Para ello, se calcula el estadístico de prueba como la razón entre la varianza mayor y la varianza menor3, asegurando que su valor siempre sea mayor o igual que la unidad:
\[
F_\text{c}=\frac{\text{máx}\left(S_1^2,\;S_2^2\right)}{\text{mín}\left(S_1^2,\;S_2^2\right)}\equiv \frac{S_{(2)}^2}{S_{(1)}^2}\ge 1
\]
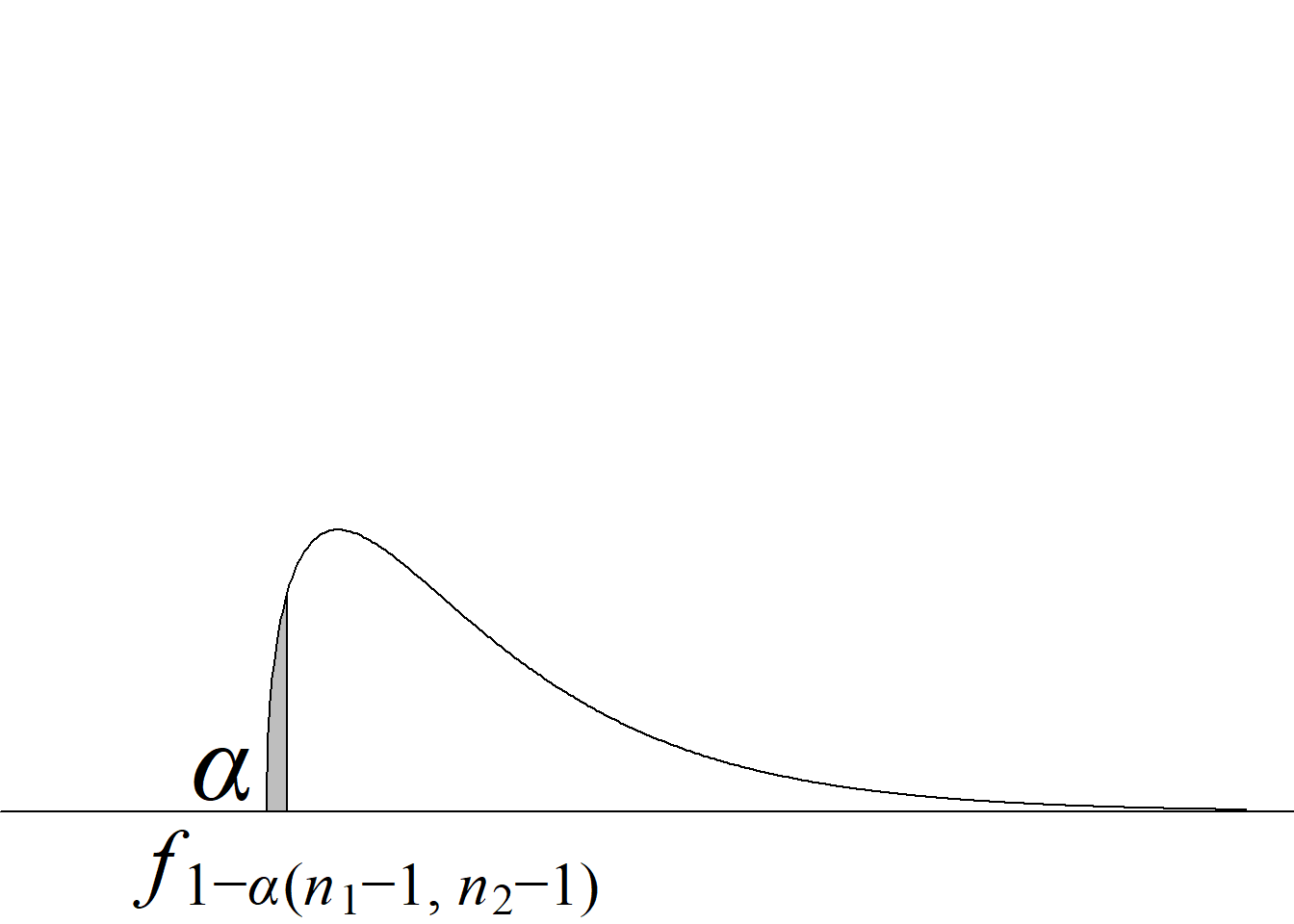
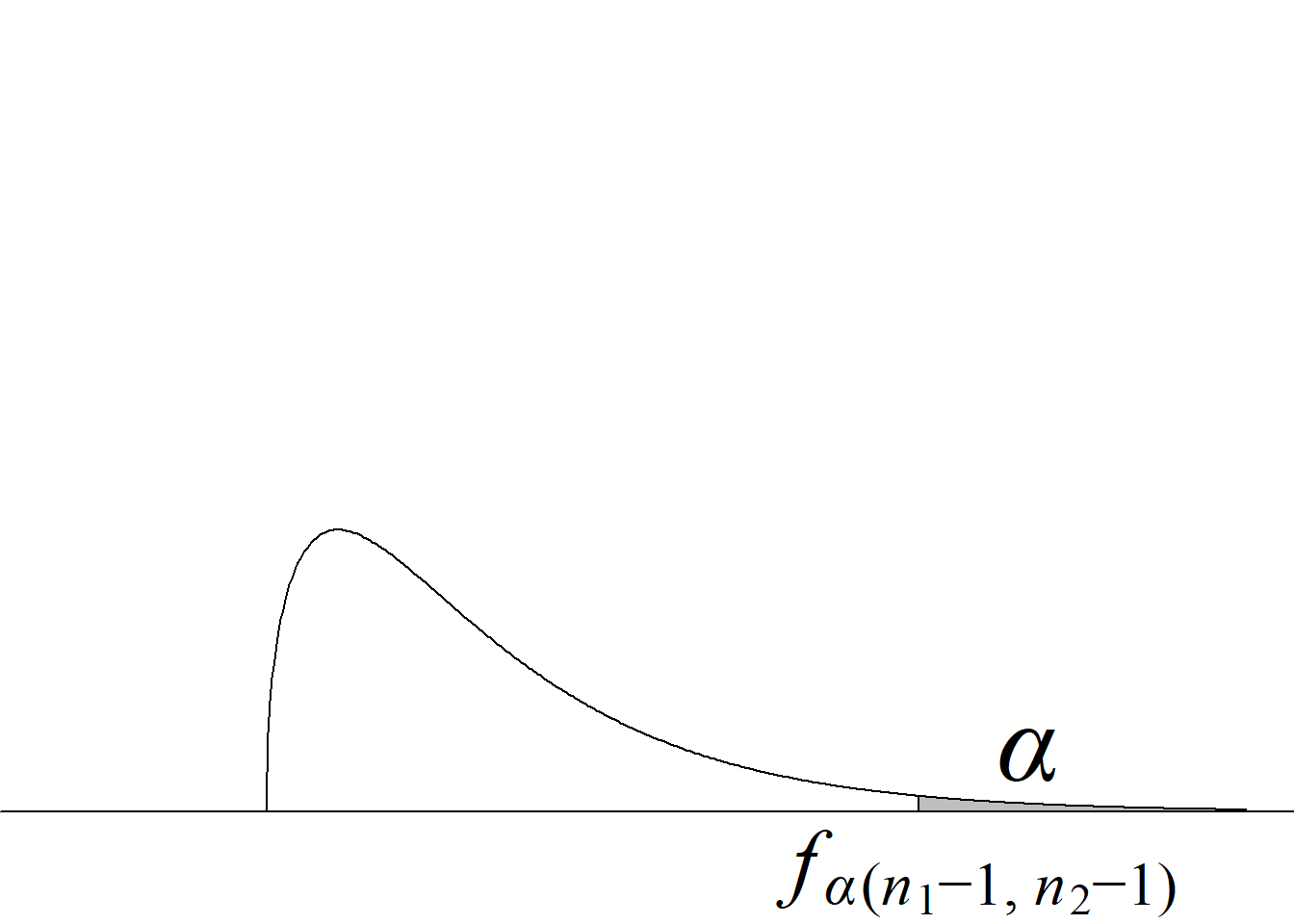
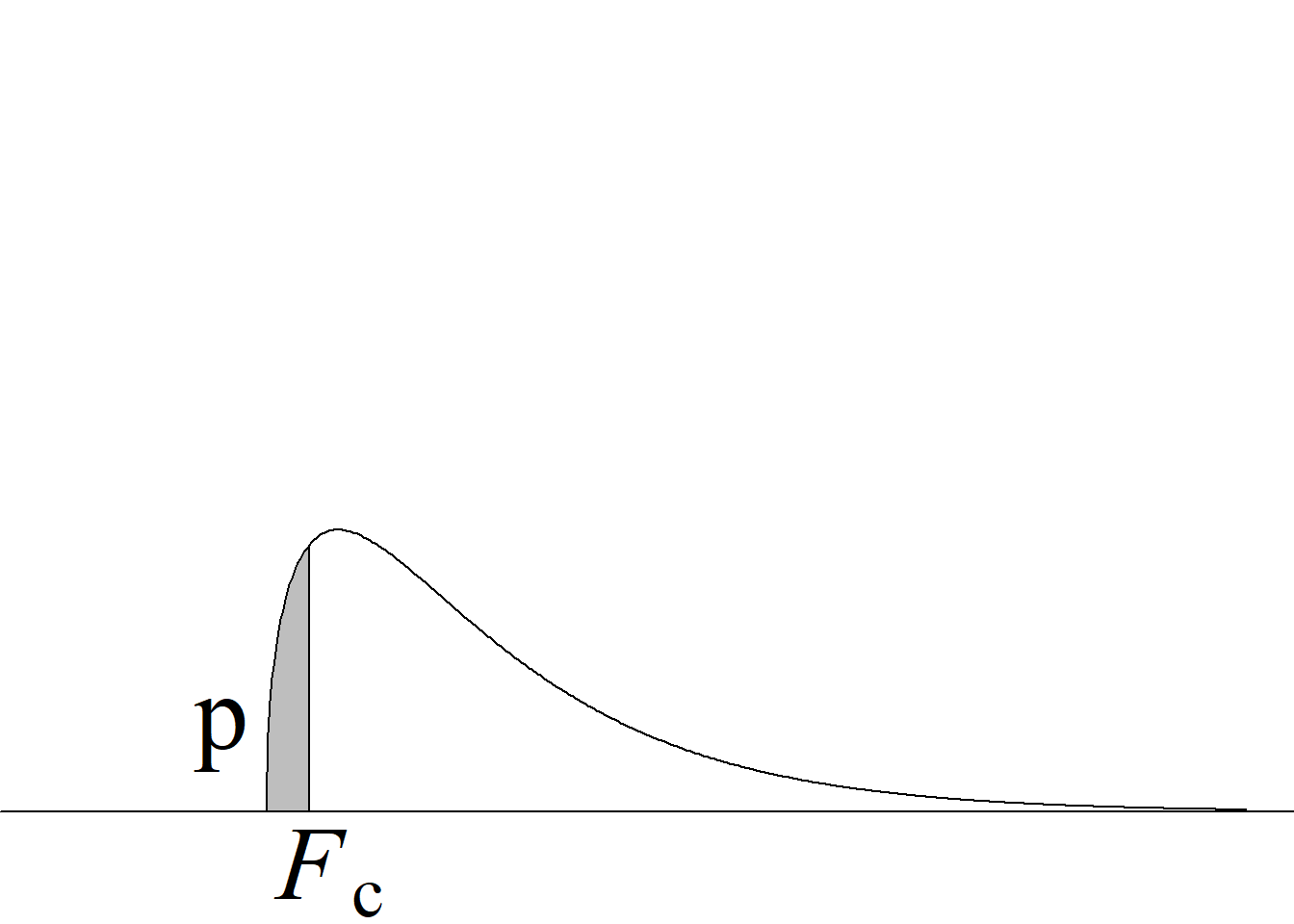
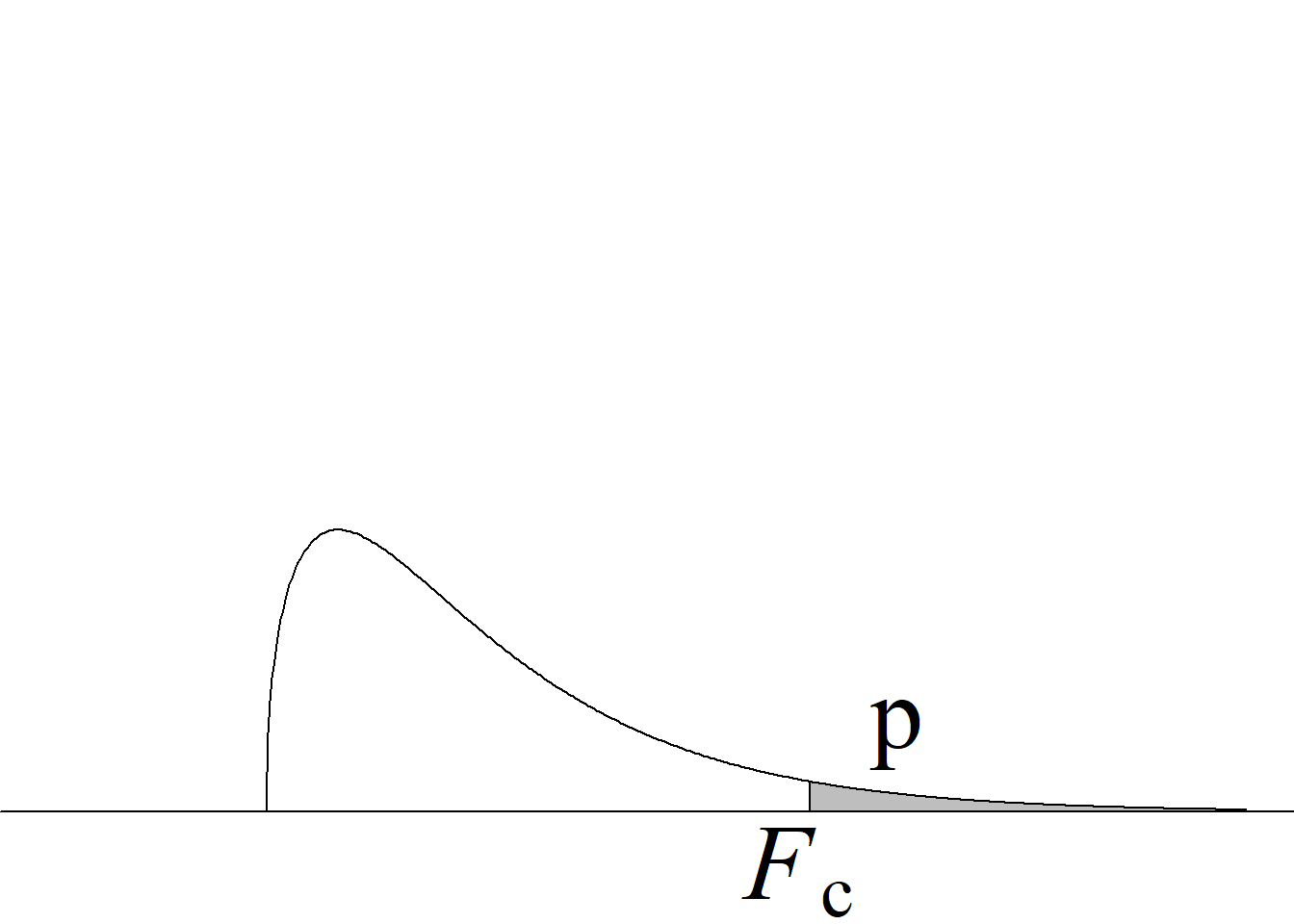
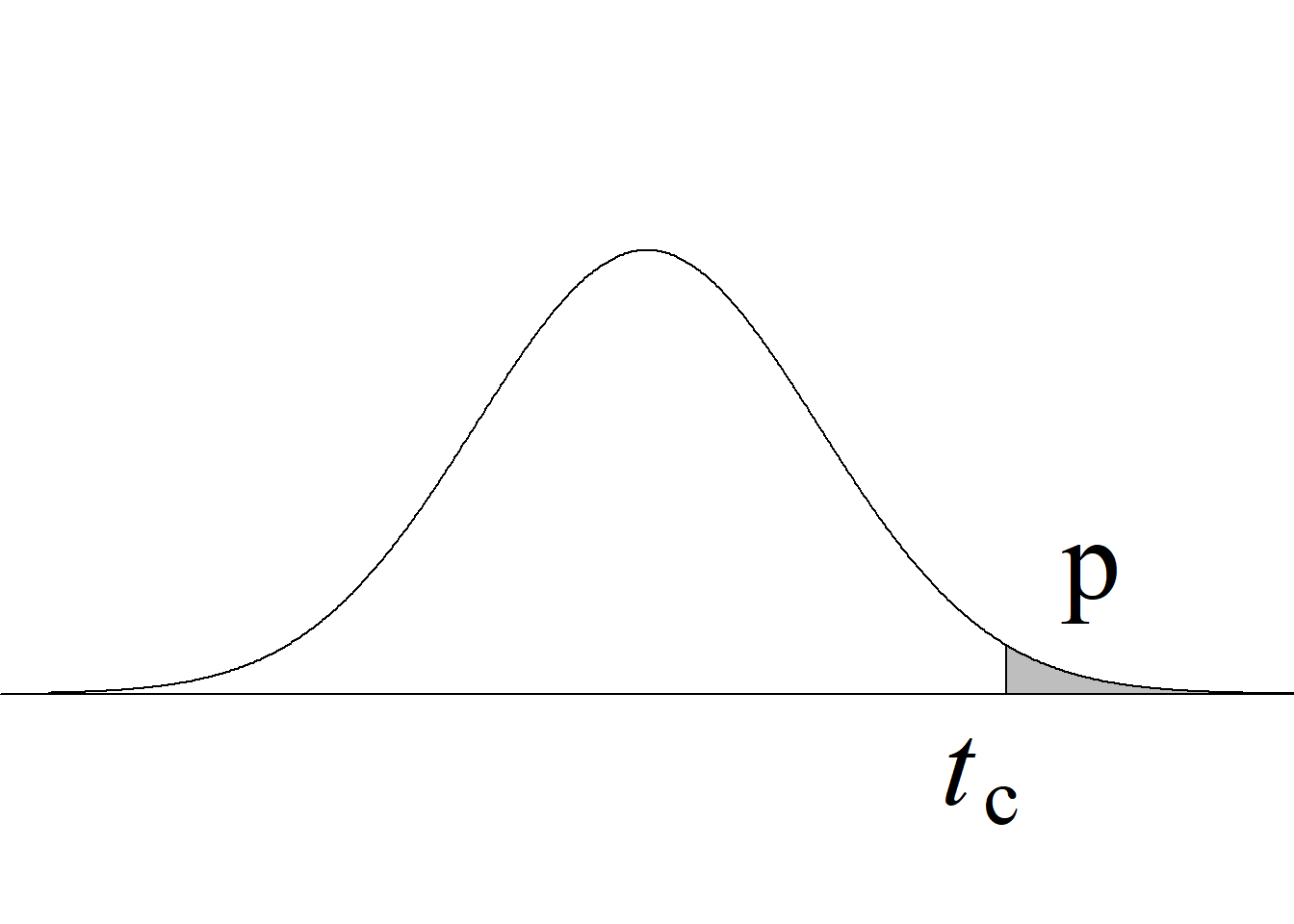
Y, puesto que el valor crítico inferior de la distribución \(F\) para los niveles de significancia usuales, v. gr. \(\alpha = 0.05,\) siempre es menor que 1 para cualquier miembro de la familia \(F,\) bastará con comparar el estadístico de prueba con el valor crítico superior, tal y como se ilustra en la figura 5.2.
Si el estadístico de prueba es mayor o igual que el valor crítico superior, se rechaza la hipótesis nula con un nivel de significancia \(\alpha;\) en caso contrario, no se rechaza la hipótesis nula con un nivel de significancia \(\alpha,\) sin que sea necesario verificar la región crítica inferior.

En resumen, la estrategia de calcular el estadístico de prueba como la razón entre la varianza mayor y la menor hacía más expedita la evaluación cuando el trabajo se realizaba de forma manual, pues permitía contrastar una prueba de dos colas verificando únicamente el valor crítico superior, que era el que solía aparecer tabulado.
Este “ahorro”, sin embargo, es irrelevante hoy en día en que los procesos están automatizados. Y aunque algunos programas estadísticos mantienen esta reminiscencia, otros más, como R, se despreocupan de estos detalles y proceden a calcular siempre la razón entre la primera y la segunda varianza, acorde con el orden en el que el usuario ingrese los argumentos.
Precaución 5.1: ¡Pero cuidado!
La equivalencia entre \(F_\text{c}\) y \(F_\text{c}^*\) se satisface únicamente para pruebas de dos colas.
Al contrastar pruebas de una cola, es necesario calcular el estadístico de prueba respetando el orden planteado en el juego de hipótesis.
La tabla 5.1 y la figura 5.3 resumen los criterios de rechazo para diferentes tipos de pruebas.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
Cola izquierda \(H_0:\sigma_1^2\ge\sigma^2_2\) |
\(F_\text{c}\le f_{1-\alpha (n_1-1,\;n_2-1)}\) |
\(P\left(F_{(n_1-1,\;n_2-1)} < F_\text{c}\right)\) |
Cola derecha \(H_0:\sigma_1^2\le\sigma^2_2\) |
\(F_\text{c}\ge f_{\alpha (n_1-1,\;n_2-1)}\) |
\(P\left(F_{(n_1-1,\;n_2-1)}> F_\text{c}\right)\) |
Dos colas \(H_0:\sigma_1^2=\sigma^2_2\) \(H_a:\sigma_1^2\ne\sigma_2^2\) |
\(F_\text{c} \le f_{1-\alpha/
2(n_1-1,\;n_2-1)}\) o |
\(2\,\text{mín}\Big(P\big(F_{(n_1-1,\;n_2-1)}<F_\text{c}\big),\) |
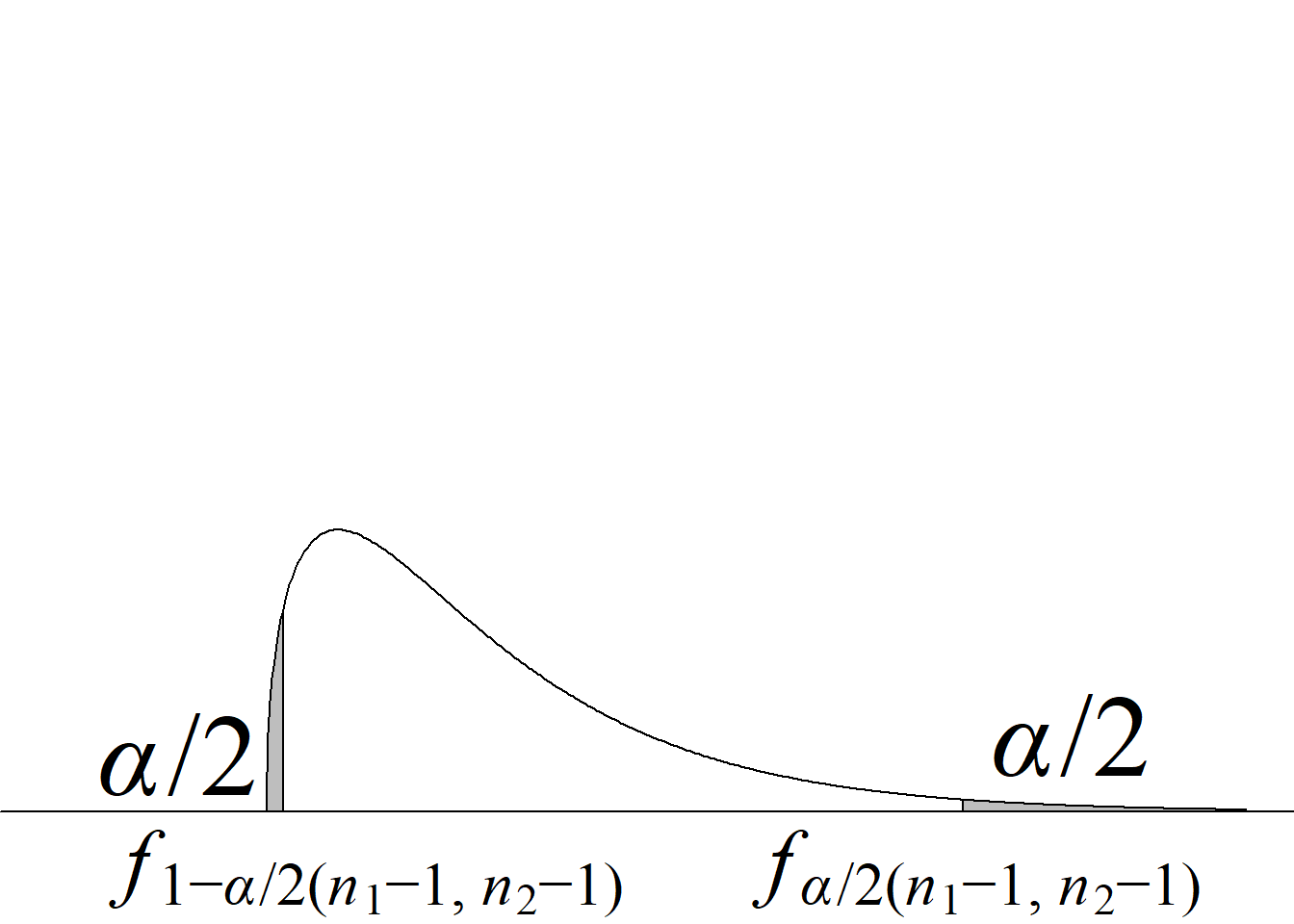
5.1.2 Intervalo de confianza para la razón de dos varianzas normales
El juego de hipótesis para comparar varianzas puede expresarse equivalentemente en términos de un juego de hipótesis para la razón de las varianzas, así:
\[
H_0: \sigma_1^2=\sigma_2^2 \quad \Leftrightarrow \quad \sigma_1^2/\sigma_2^2=1
\]
\[
H_a: \sigma_1^2\ne\sigma_2^2 \quad\Leftrightarrow \quad \sigma_1^2/\sigma_2^2\ne1
\]
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para la razón \(\sigma_1^2/\sigma_2^2\) se construye así:
\[
\left[\frac{S_1^2/S_2^2}{f_{\alpha/2(n_1-1,\; n_2-1)}},\;\; \frac{S_1^2/S_2^2}{f_{1-\alpha/2(n_1-1,\; n_2-1)}}\right]
\]
Si una muestra da lugar al rechazo de la hipótesis nula con un nivel de significancia \(\alpha,\) el correspondiente intervalo de confianza del \(100(1−\alpha)\,\%\) para la razón \(\sigma_1^2/\sigma_2^2\) no incluye la unidad; equivalentemente, cuando no es posible rechazar la hipótesis nula con un nivel de significancia \(\alpha,\) el respectivo intervalo de confianza del \(100(1−\alpha)\,\%\) para la razón \(\sigma_1^2/\sigma_2^2\) incluye el 1.
¡Es lo mismo!
Rechazar que la razón de varianzas es 1 equivale a rechazar que las varianzas son iguales u homogéneas.
¡También es lo mismo!
Aunque el intervalo de confianza del \(100(1−\alpha)\,\%\) para la razón \(\sigma_1^2/\sigma_2^2\) no coincide numéricamente con el intervalo de confianza del \(100(1−\alpha)\,\%\) para la razón \(\sigma_2^2/\sigma_1^2\), ambos intervalos son informacionalmente equivalentes, puesto que el límite inferior de uno de los intervalos es el inverso multiplicativo del límite superior del otro y viceversa, tal y como se ilustra en la figura 5.4, donde los inversos multiplicativos se encuentran unidos por una flecha.
Los intervalos de confianza unilaterales del \(100(1−\alpha)\,\%\) para la razón \(\sigma_1^2/ \sigma_2^2\) se obtienen así:
Para \(H_0: \sigma_1^2 \ge \sigma_2^2\,\) vs. \(H_a: \sigma_1^2 < \sigma_2^2,\) \(\quad\quad\text{LS}=\frac{S_1^2/S_2^2}{f_{1-\alpha(n_1-1,\; n_2-1)}}\)
Para \(H_0: \sigma_1^2 \le \sigma_2^2\,\) vs. \(H_a: \sigma_1^2 > \sigma_2^2,\) \(\quad\quad\text{LI}=\frac{S_1^2/S_2^2}{f_{\alpha(n_1-1,\; n_2-1)}}\)
Ejemplo 5.1
Se desea comparar la precisión de dos métodos para determinación de magnesio en suelos, con un nivel de significancia del 5 %.
Usando una muestra homogenizada de suelo, se realizan 14 determinaciones independientes por el método \(\text{A}\) y 11 determinaciones independientes por el método \(\text{B},\) obteniéndose los resultados que se presentan en la tabla 5.2.
| Método A | 1.48 | 0.21 | 0.56 | 0.36 | 1.27 | 2.01 | 0.84 | 1.08 | 1.46 | 1.24 | 0.96 | 1.27 | 1.63 | 1.49 |
| Método B | 0.88 | 0.43 | 0.67 | 2.80 | 1.12 | 0.36 | 1.21 | 1.45 | 0.56 | 1.33 | 1.01 |
A continuación se resaltan algunas particularidades conceptuales del planteamiento experimental.
¿¡Qué se está comparando!?
Para comparar contenidos de magnesio de diferentes suelos, sería necesario tomar muestras independientes de los dos suelos objetivo y realizar las determinaciones por un único método; seguidamente se realizaría la comparación, mediante una prueba de medias (cf. sección 5.2.2).
Si el interés radicara en comparar los dos métodos, dicha comparación podría enfocarse en la exactitud o en la precisión de los mismos, de manera análoga a lo expuesto en los ejemplos 4.2 y 4.3.
Si se pretendiera comparar la exactitud de los dos métodos, lo único que podría averiguarse es si estos conducen a las mismas determinaciones medias. Sin embargo, en caso de encontrar diferencias, no sería posible saber cuál de los métodos goza de mayor exactitud4, a no ser que se contara con una prueba de oro5.
El ejemplo 5.1 ilustra cómo comparar la precisión de los dos métodos, es decir, la consistencia de las diferentes lecturas alrededor de la media. En estos casos se requiere que los diferentes métodos sean aplicados sobre una muestra homogenizada de suelo, pues de otra manera se estaría incorporando la variabilidad propia del suelo.
Para responder la pregunta planteada, se establece el siguiente juego de hipótesis:
\(H_0: \sigma_\text{A}^2=\sigma_\text{B}^2\,\) (las varianzas de los dos métodos son homogéneas)
\(H_a: \sigma_\text{A}^2\ne\sigma_\text{B}^2\,\) (las varianzas de los dos métodos son heterogéneas)
Para el cálculo del estadístico de prueba, se obtienen las varianzas muestrales:
\[
S_\text{A}^2=0.2551,\quad S_\text{B}^2=0.4600
\]
Tal y como se ha indicado, resulta indiferente la posición relativa de las varianzas muestrales en el estadístico de prueba, pudiendo usarse cualquiera de ellas en el numerador y la otra en el denominador, sin que ello altere los resultados. Por consiguiente, cualquiera de los siguientes estadísticos de prueba es válido y conduce al mismo resultado:
\[
F_\text{c}=0.4600/0.2551=1.8032,\quad F_\text{c}^*=0.2551/0.4600=0.5546
\]
La elección del estadístico de prueba determina los grados de libertad de la función probabilística de referencia. Puesto que el estadístico \(F_\text{c}\) usa en el numerador la varianza de la muestra \(\text{B},\) la cual es de tamaño 11 y en el denominador, la varianza de la muestra \(\text{A},\) de tamaño 14, se compara con una distribución \(F\) con 10 y 13 gl; análogamente, el estadístico \(F_\text{c}^*\) se compara con una distribución \(F\) con 13 y 10 gl.
Para usar el método de contraste tradicional al 5 %, se requieren los valores críticos que dejan áreas de 0.025 en las colas de las correspondientes distribuciones.
Si se usa \(F_\text{c},\) estos valores se obtienen así:
Valor crítico inferior: qf(0.025, 10, 13) = 0.2790809.
Valor crítico superior: qf(0.025, 10, 13, lower.tail = F) = 3.249668.
Para \(F_\text{c}^*,\) estos serían los valores críticos:
Valor crítico inferior: qf(0.025, 13, 10) = 0.3077237.
Valor crítico superior: qf(0.025, 13, 10, lower.tail = F) = 3.583191.
El presente ejemplo permite verificar que se satisface la equivalencia de criterios ilustrada en la figura 5.1. Obsérvese que 1/0.2790809=3.583191 y que 1/3.249668=0.3077237.
Cualquiera que sea el estadístico de prueba utilizado, este se ubica en la región de aceptación de su correspondiente distribución de referencia, por lo que no se rechaza la hipótesis nula al 5 %, es decir que no es posible afirmar con baja probabilidad de error que exista diferencia en la precisión de los dos métodos comparados.
Asimismo, puede verificarse que, sin importar cuál estadístico de prueba se use, se obtiene el mismo valor p, el cual se calcula con base en la expresión presentada en la tabla 5.1, para las pruebas de dos colas, así:
Usando \(F_\text{c}:\)
p: 2 * min(pf(1.8032, 10, 13), pf(1.8032, 10, 13, lower.tail = F)) = 0.3167.
Usando \(F_\text{c}^*:\)
p: 2 * min(pf(0.5546, 13, 10), pf(0.5546, 13, 10, lower.tail = F)) = 0.3167.
Un intervalo de confianza del 95% para la razón de varianzas \(\sigma_\text{A}^2/\sigma_\text{B}^2\) se obtiene así:
\[
\left[\frac{S_\text{A}^2/S_\text{B}^2}{f_{\alpha/2(n_\text{A}-1,\; n_\text{B}-1)}},\; \frac{S_\text{A}^2/S_\text{B}^2}{f_{1-\alpha/2(n_\text{A}-1,\; n_\text{B}-1)}}\right]
\]
\[
\left[\frac{0.2551/0.4600}{f_{0.025(13,\; 10)}},\; \frac{0.2551/0.4600}{f_{0.975(13,\; 10)}}\right]
=\left[\frac{0.5546}{3.5832},\; \frac{0.5546}{0.3077}\right]
\]
\[ \text{IC}_{\sigma_\text{A}^2/\sigma_\text{B}^2}:\quad\left[0.1547,\; 1.8024\right] \]
Tal y como era de esperarse, conociendo el resultado del contraste de hipótesis, el intervalo de confianza para la razón de las varianzas contiene el valor 1, por lo que no puede afirmarse con una probabilidad de error menor de 0.05 que los métodos evaluados difieran en precisión.
Invirtiendo los anteriores límites, se obtiene un intervalo de confianza del 95 % para \(\sigma_\text{B}^2/\sigma_\text{A}^2,\) el cual, desde luego, también contiene la unidad:
\[ \text{IC}_{\sigma_\text{B}^2/\sigma_\text{A}^2}:\quad\left[1/1.8024,\; 1/0.1547 \right] =\left[0.5548,\; 6.4641 \right] \]
El siguiente script en R permite reproducir los anteriores resultados. Inicialmente se importan los datos contenidos en el archivo ejemplo 5.1.xlsx y se evalúa el supuesto de normalidad para cada una de las muestras.
data <- readxl::read_excel("ejemplo 5.1.xlsx")
shapiro.test(data$met.A)
Shapiro-Wilk normality test
data: data$met.A
W = 0.96307, p-value = 0.7731shapiro.test(data$met.B)
Shapiro-Wilk normality test
data: data$met.B
W = 0.84597, p-value = 0.03781No se detectan desviaciones severas del supuesto de normalidad para ninguna de las dos muestras. Por tanto, es razonable aplicar la metodología expuesta para la comparación de varianzas.
with(data, var.test(met.A, met.B))
F test to compare two variances
data: met.A and met.B
F = 0.55453, num df = 13, denom df = 10, p-value = 0.3166
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.1547587 1.8020382
sample estimates:
ratio of variances
0.55453
¿Y qué pasa si se invierte el orden de los argumentos?
¡Compruébelo usted mismo!
data <- readxl::read_excel("ejemplo 5.1.xlsx")
with(data, var.test(met.B, met.A))
¡Atención con las pruebas de una cola!
La función var.test construye el estadístico de prueba ubicando en el numerador la varianza de la muestra cuya etiqueta aparece como primer argumento de la función, y en el denominador la varianza de la muestra cuya etiqueta aparece como segundo argumento.
Consecuentemente, cuando se use la función var.test para evaluar pruebas de una cola, es necesario asegurarse de que el orden de los argumentos corresponda con el orden en el que está planteado el juego de hipótesis.
Considérense, por ejemplo, dos muestras: una con la etiqueta \(\text{m}302\) y otra con la etiqueta \(\text{m}071\). Y supóngase que se desea probar que la varianza de la primera población es mayor que la varianza de la segunda:
\[
H_0: \sigma_{\text{m}302}^2\le\sigma_{\text{m}071}^2\Rightarrow \sigma_{\text{m}302}^2/\sigma_{\text{m}071}^2\le 1
\]
\[
H_a: \sigma_{\text{m}302}^2>\sigma_{\text{m}071}^2 \Rightarrow \sigma_{\text{m}302}^2/\sigma_{\text{m}071}^2>1
\]
La segunda manera de escribir el juego de hipótesis (como razón de varianzas) muestra que la forma correcta de construir el estadístico de prueba es con \(S_{\text{m}302}^2\) en el numerador y \(S_{\text{m}071}^2\) en el denominador. Para ello, debe escribirse la etiqueta m302 como primer argumento de la función var.test, y la etiqueta m071 como segundo argumento:
var.test(m302, m071, alternative = 'greater')Supóngase ahora que se desea probar que la varianza de la primera población es menor que la varianza de la segunda:
\[
H_0: \sigma_{\text{m}302}^2\ge\sigma_{\text{m}071}^2\Leftrightarrow \sigma_{\text{m}302}^2/\sigma_{\text{m}071}^2\ge 1
\]
\[
H_a: \sigma_{\text{m}302}^2<\sigma_{\text{m}071}^2 \Leftrightarrow \sigma_{\text{m}302}^2/\sigma_{\text{m}071}^2<1
\]
De nuevo, la forma correcta de construir el estadístico de prueba es con \(S_{\text{m}302}^2\) en el numerador y \(S_{\text{m}071}^2\) en el denominador; lo que cambia respecto al caso anterior no es el estadístico de prueba, sino la dirección de la hipótesis alternativa. Para ello, se utiliza la siguiente instrucción en R:
var.test(m302, m071, alternative = 'less')5.2 Comparación de las medias de dos poblaciones normales
La normal es el modelo por excelencia de numerosas poblaciones de campo y, en particular, el parámetro \(\mu\) de esta distribución sirve de modelo a las correspondientes medias de campo (cf. sección 3.9). En consecuencia, la comparación de medias es uno de los métodos inferenciales básicos de mayor uso en la práctica estadística.
Hay dos estrategias para recolectar la información que sirve de sustento a la comparación de medias:
Tomando una muestra independiente de cada una de las poblaciones objetivo.
Usando en cada población una muestra que se relacione elemento a elemento con la muestra de la otra población.
A la primera estrategia se le denomina de muestras independientes; a la segunda, de muestras pareadas.
La técnica de comparación de medias basada en muestras independientes cuenta con dos versiones, una de las cuales se usa cuando las varianzas de las poblaciones comparadas son homogéneas, y otra, cuando son heterogéneas.
En adición a estas dos versiones de la prueba de medias, existe una tercera prueba que se usa siempre que se colecte la información mediante muestras pareadas, sin que exista en este caso ningún requerimiento relativo a las varianzas poblacionales.
La figura 5.5 esquematiza estas tres pruebas de comparación de medias.
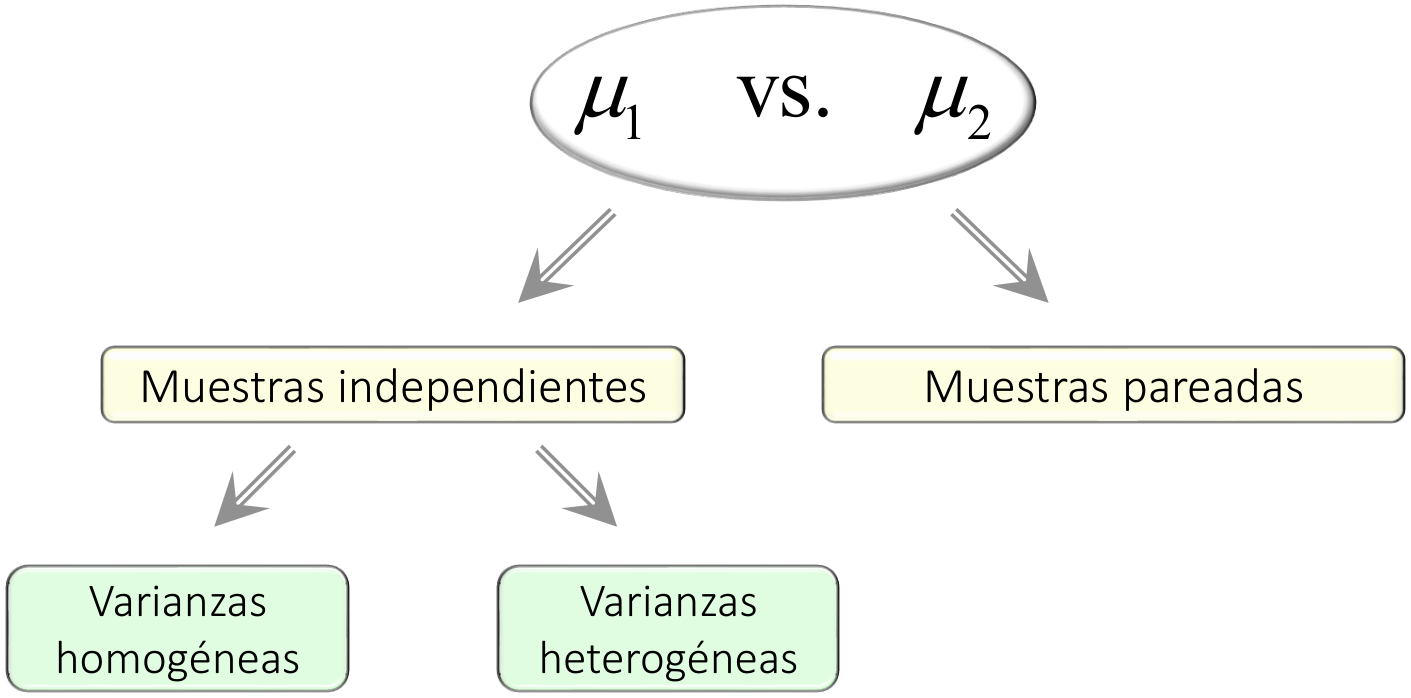
La comparación de medias utilizando muestras pareadas —cuando ello es viable— suele resultar más efectiva que la correspondiente comparación usando muestras independientes. Esta estrategia se detalla en la sección 5.2.3.
El uso de muestras independientes, por su parte, es la opción que muchos investigadores adoptan por defecto, ya que estas muestras suelen ser las de más fácil obtención en campo.
Cuando se habla de muestras independientes, es importante precisar que la independencia a la que se hace mención es entre muestras. Esta no remplaza ni modifica el requisito de independencia que debe existir entre las lecturas que conforman cada una de las muestras, es decir, dentro de cada muestra (cf. secciones 3.6.2 y 3.9: Muestra).
Aunque en campo no es posible garantizar la independencia de las lecturas que conforman una muestra, esta suele propiciarse mediante la obtención de muestras aleatorias. Por su parte, la independencia entre muestras se da de manera natural cuando no existen vínculos entre los procesos muestrales que se realizan en las dos poblaciones.
En las dos secciones siguientes se presentan las metodologías más populares para la comparación de medias, a partir de muestras independientes. La metodología de la sección 5.2.1, que se denomina prueba de \(t,\) es apta para los casos en que las varianzas poblacionales son homogéneas.
Zimmerman (2004) advierte que el uso de esta prueba en situación de heterocedasticidad afecta las tasas de error tipo I, en particular cuando se tienen diferentes tamaños de muestra. Cuando las mayores varianzas se asocian con los mayores tamaños de muestra, la probabilidad de error tipo I cae por debajo del nivel nominal; cuando sucede a la inversa, se incrementa muy por encima del nivel de significancia nominal .
En la sección 5.2.2 se presenta la prueba de Welch, que permite realizar la comparación de medias cuando las varianzas poblacionales son heterogéneas, manteniendo la tasa de error tipo I en su nivel nominal y disminuyendo simultáneamente la probabilidad de error tipo II (Zimmerman, 2004).
Aunque es lógico razonar que antes de efectuar la prueba de comparación de medias deben evaluarse las varianzas usando la prueba que se presentó en la sección 5.1 —y de hecho ese fue el procedimiento seguido durante mucho tiempo—, estudios como el de Moser y Stevens (1992) analizan otras posibilidades:
Utilizar siempre la prueba de \(t\) sin evaluar previamente homogeneidad de varianzas.
Utilizar siempre la prueba de Welch sin evaluar previamente homogeneidad de varianzas.
Utilizar una u otra prueba, dependiendo del resultado de la prueba de homogeneidad de varianzas.
Estos autores concluyen que —excepto cuando se tienen tamaños de muestra diferentes y se sabe (no cuando se infiere mediante una prueba) que las varianzas poblacionales son iguales— la segunda estrategia, es decir, el uso no condicionado de la prueba de Welch, tiene un mejor desempeño.
Y puesto que en la práctica nunca se conocen las varianzas poblacionales, el uso directo de la prueba de Welch constituye la mejor estrategia en todos los casos.
Zimmerman (2004) realizó un estudio de simulación, calculando las probabilidades asociadas al proceso de elegir una prueba en función de los resultados de la prueba de homogeneidad de varianzas. Concluye que cuando se usa la prueba de Welch de manera no condicionada al resultado de la prueba de homogeneidad de varianzas, la tasa de error tipo I se mantiene muy cerca de su nivel nominal. En contraste, para la mayoría de condiciones evaluadas, su desempeño es mucho peor cuando se usa acoplada a una prueba de homogeneidad de varianzas. Este autor concluye que, cuando se tienen diferentes tamaños de muestra, la estrategia más eficiente consiste en realizar la prueba de Welch no condicionada al resultado de la prueba de homogeneidad de varianzas.
Delacre, Lakens y Leys (2017), quienes discuten el uso de estas pruebas y otra más (la de Yuen) en el ámbito de la investigación en sicología, usándolas tanto de manera directa como condicionada al resultado de la prueba de homogeneidad de varianzas, también concluyen que la mejor estrategia consiste en el uso directo de la prueba de Welch.
Tomando en consideración los argumentos expuestos por estos autores, igualmente recomendamos el uso directo de la prueba de Welch para la comparación de las medias de dos poblaciones normales. De hecho, esta es la prueba de medias que R trae implementada por defecto en la función de t.test{stats}.
¡Use siempre la prueba de Welch!
La prueba de Welch constituye la mejor estrategia para comparar medias de dos poblaciones normales, sin importar lo que se especule o infiera sobre las varianzas poblacionales.
5.2.1 Comparación de medias, usando muestras independientes, con varianzas homogéneas: Prueba de \(t\)
Reiterando la recomendación de no usar la prueba de \(t\) para la comparación de medias de dos poblaciones normales, consideramos pertinente su exposición, ya que constituye la base conceptual de métodos como el análisis de varianza (cf. sección 6.2) —que puede verse como una generalización de la prueba de \(t\)— y la prueba de la diferencia mínima significativa (cf. sección 8.4) —que es la misma prueba de \(t\) presentada bajo otro formato—.
5.2.1.1 Prueba de hipótesis para la comparación de medias, usando muestras independientes, con varianzas homogéneas
Considérense dos muestras aleatorias independientes, provenientes de sendas poblaciones normales6:
\(X_{11},X_{12},...,X_{1n_1}\: \text{iid}\: N\left(\mu_1, \sigma_1^2\right)\quad\) y \(\quad X_{21},X_{22},...,X_{2n_2}\: \text{iid}\: N\left(\mu_2, \sigma_2^2\right)\)
La media de cada una de estas muestras —que es una combinación lineal de variables aleatorias normales— tiene a su vez distribución normal.
\[
\overline{X}_1\thicksim N\left(\mu_1,\;\sigma_1^2/n_1\right)
\]
\[
\overline{X}_2\thicksim N\left(\mu_2,\;\sigma_2^2/n_2\right)
\]
La diferencia de estas medias es también una variable aleatoria normal:
\[
\left(\overline{X}_1-\overline{X}_2\right)\thicksim N\left(\mu_1-\mu_2,\;\;\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}\right)
\]
Estandarizando se llega a una normal estándar:
\[
\frac{\Big(\overline{X}_1-\overline{X}_2\Big)-\Big(\mu_1-\mu_2\Big)}
{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}} \thicksim N\left(0,\;1\right)
\]
Si las varianzas poblacionales son iguales7, es decir, si \(\sigma_1^2=\sigma_2^2=\sigma^2,\) la anterior expresión puede escribirse así:
\[
\frac{\Big(\overline{X}_1-\overline{X}_2\Big)-\Big(\mu_1-\mu_2\Big)}
{\sqrt{\sigma^2\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)}} \thicksim N\left(0,\;1\right)
\tag{5.2}\]
Para generar un estadístico de prueba, se requiere remplazar la varianza poblacional, \(\sigma^2,\) con un estimador muestral. Para tal efecto, se usa un promedio ponderado8 de las varianzas muestrales, tomando los denominadores de las varianzas muestrales como factores de ponderación.
\[
S_\text{p}^2=\frac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2}
\tag{5.3}\]
Al estimador que se obtiene de esta manera suele denominársele varianza combinada o varianza ponderada. Este último nombre puede resultar más nemotécnico, por estar acorde con el subíndice que se hereda del término en inglés (pooled).
¿Son promediables?
Aunque todo es promediable numéricamente, no todo es conceptualmente promediable (cf. precaución 2.1).
Esta admonición cobra particular relevancia en el presente contexto, en el que \(S^2_\text{p}\) solo tendría sentido como representante de la varianza común de las dos poblaciones si \(\sigma_1^2=\sigma_2^2.\)
En escenarios de heterocedasticidad, \(S^2_\text{p}\) no representaría adecuadamente ni a \(\sigma_1^2\) ni a \(\sigma_2^2,\) por lo cual, la prueba de \(t\) tendría un pobre desempeño en comparación con la prueba de Welch.
Si se remplaza el valor de la varianza poblacional que aparece en el denominador de la expresión 5.2 por el de su estimador combinado (expresión 5.3), se obtiene un estadístico que sigue una distribución \(t\) con grados de libertad correspondientes al denominador de la varianza ponderada:
\[
\frac{\Big(\overline{X}_1-\overline{X}_2\Big)-\Big(\mu_1-\mu_2\Big)}
{\sqrt{S_\text{p}^2\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)}}
\thicksim t_{\left(n_1+n_2-2\right)}
\tag{5.4}\]
Considérese el siguiente juego de hipótesis:
\[
H_0:\mu_1=\mu_2\Leftrightarrow \mu_1-\mu_2=0
\] \[
H_a:\mu_1\ne\mu_2\Leftrightarrow \mu_1-\mu_2\ne0
\]
El estadístico de prueba se obtiene condicionando la expresión 5.4 a que la hipótesis nula sea cierta, es decir, haciendo la diferencia \(\mu_1-\mu_2=0\!:\)
\[
t_\text{c}=\frac{\overline{X}_1-\overline{X}_2}
{\sqrt{S_\text{p}^2\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)}}
\overset {H_0}\thicksim t_{\left(n_1+n_2-2\right)}
\tag{5.5}\]
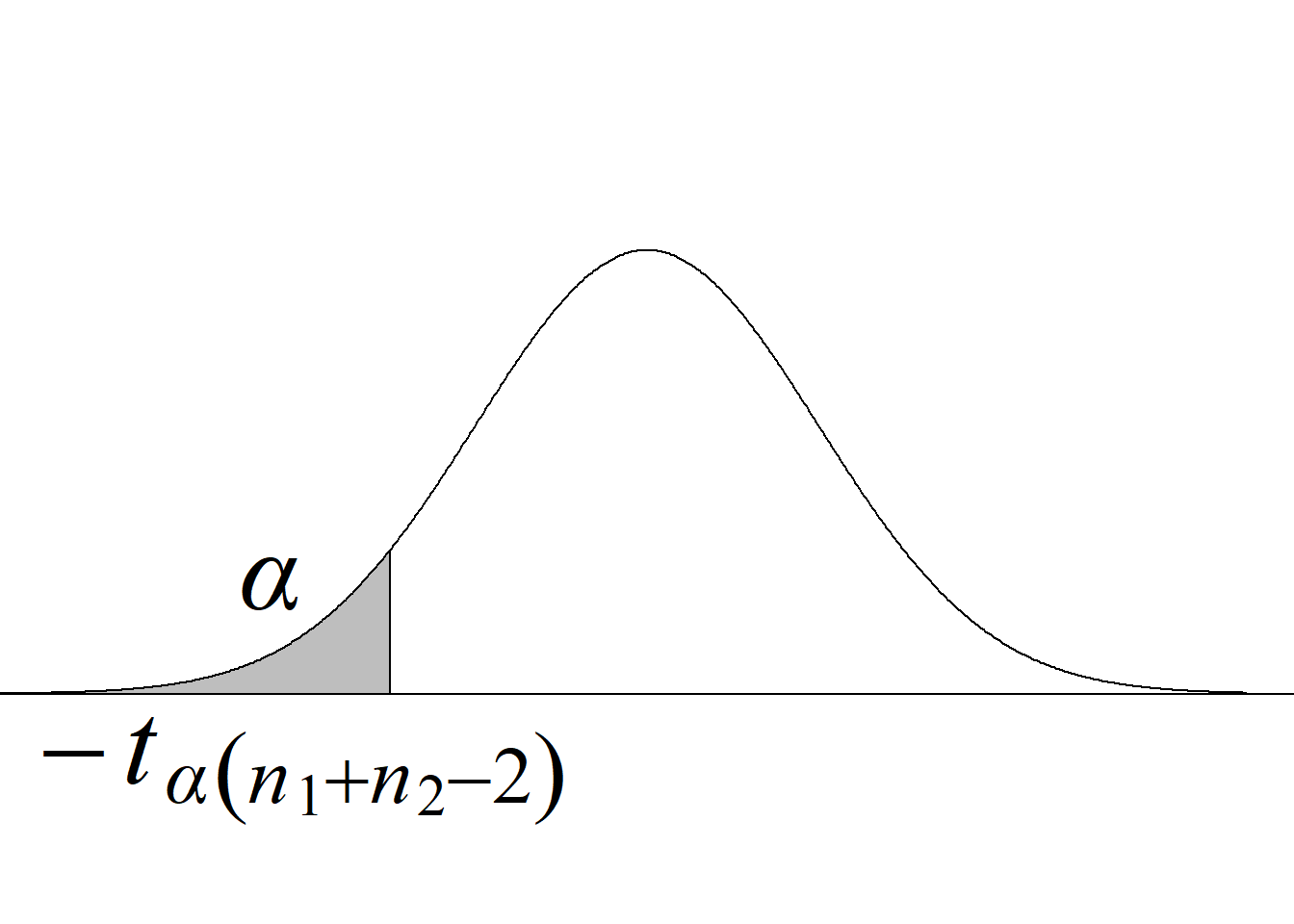
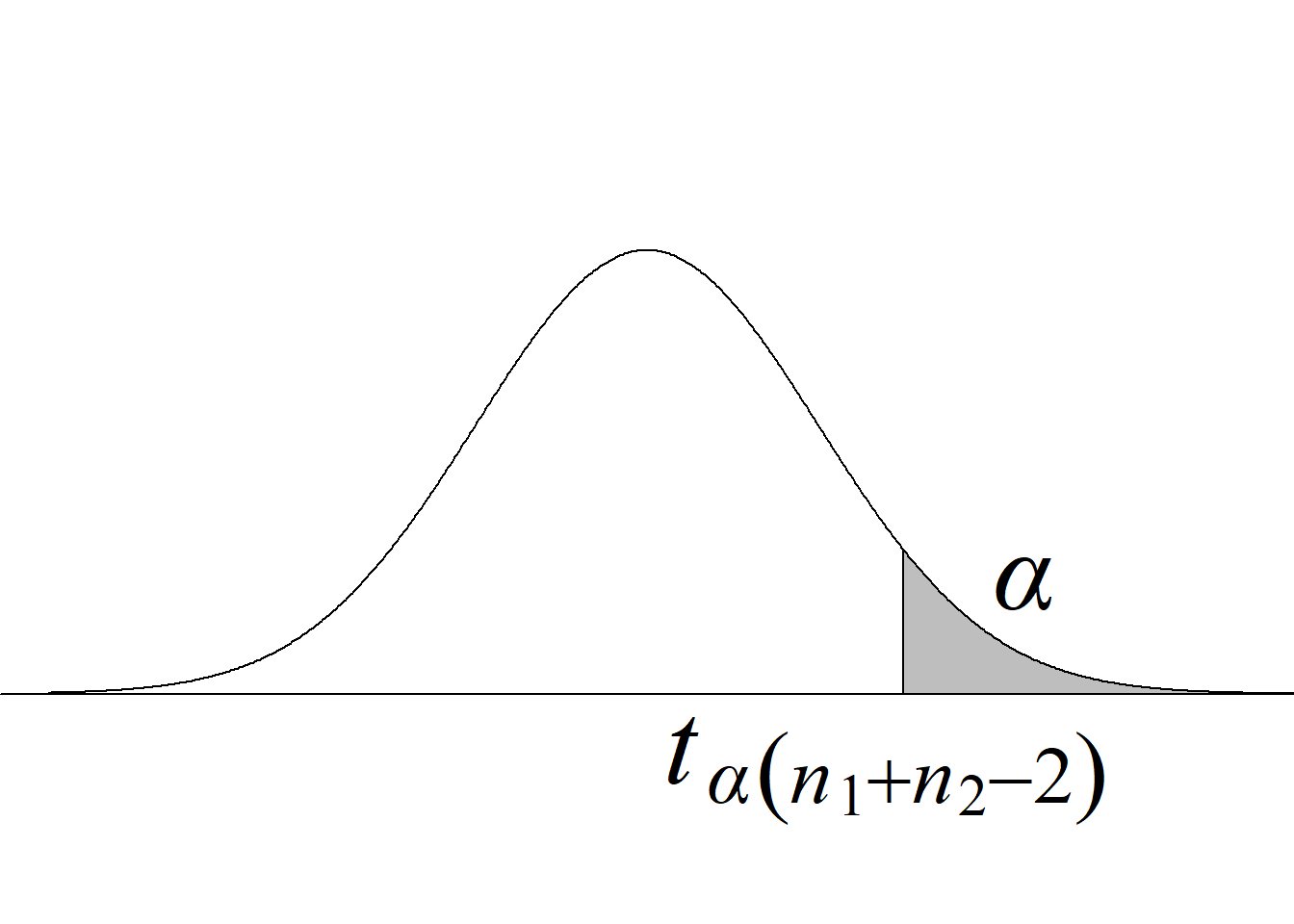
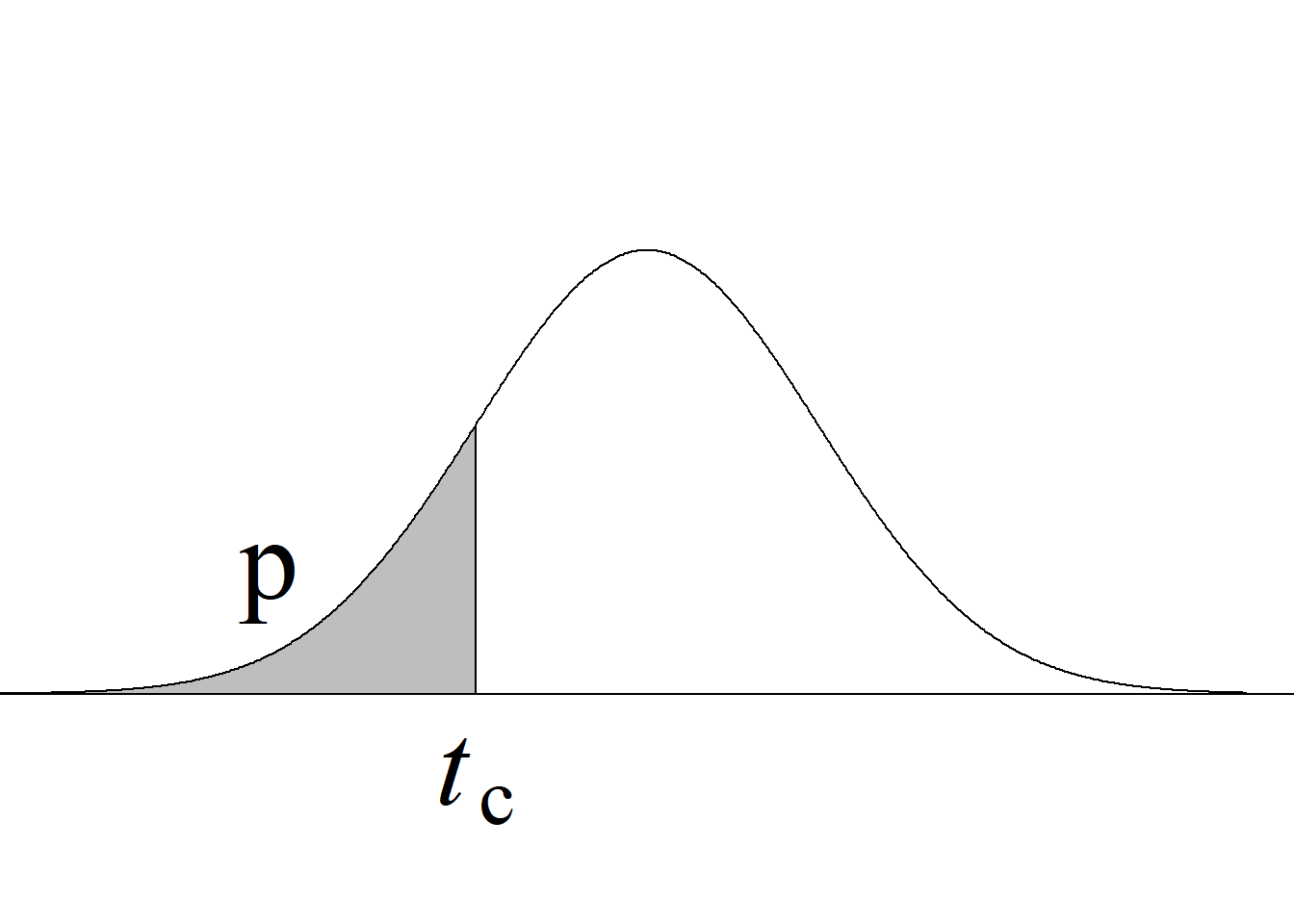
Puesto que, bajo la hipótesis nula, el estadístico de prueba sigue una distribución \(t,\) a la prueba basada en este estadístico se le conoce como prueba de \(t.\) La tabla 5.3 y la figura 5.6 resumen los criterios de rechazo para diferentes tipos de pruebas.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda \(H_0:\mu_1\ge\mu_2\) \(H_a:\mu_1<\mu_2\) |
\(t_\text{c}\le−t_{\alpha(n_1+n_2-2)}\) |
\(P(t_{(n_1+n_2-2)} < t_\text{c})\) |
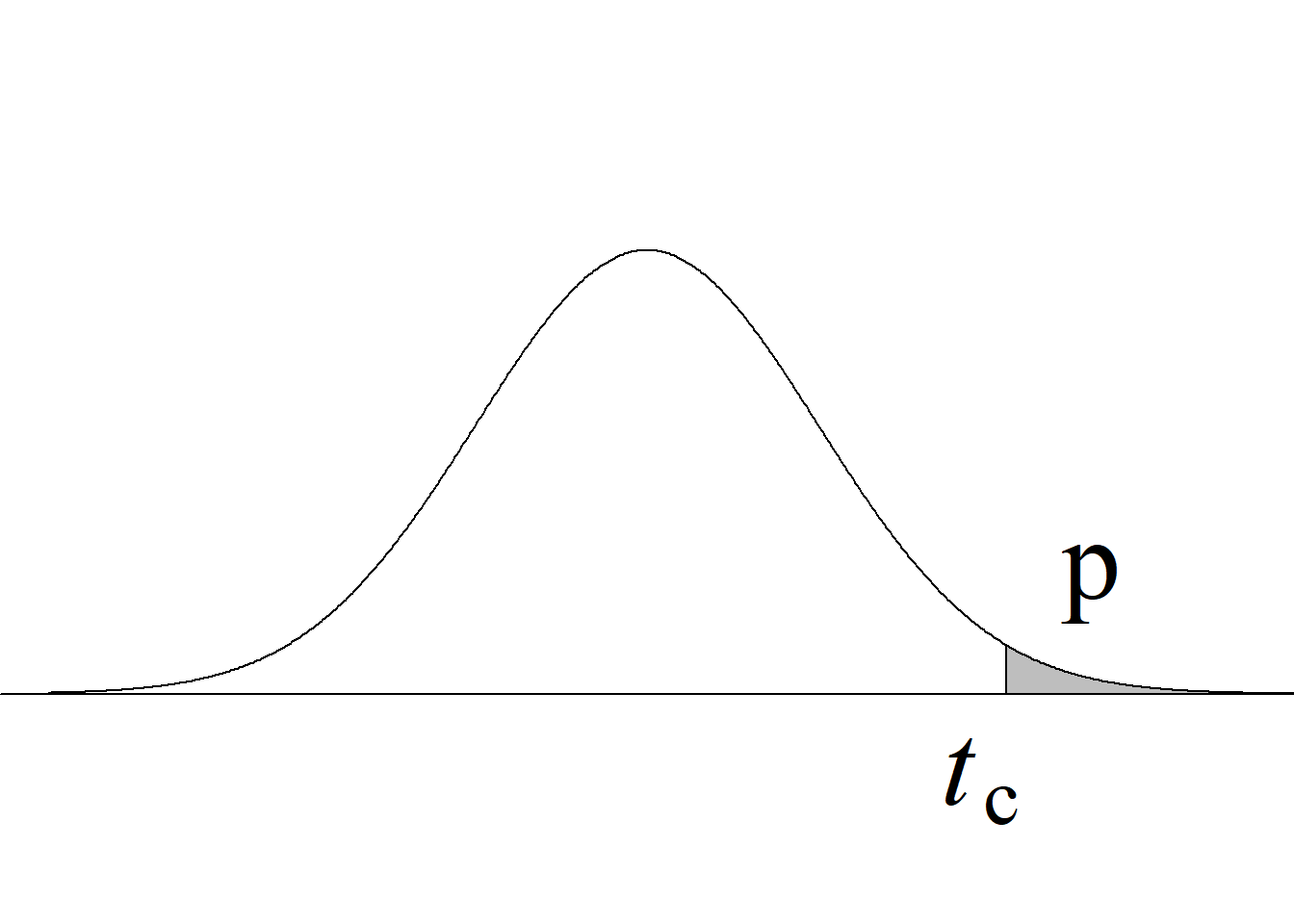
| Cola derecha \(H_0:\mu_1\le\mu_2\) \(H_a:\mu_1>\mu_2\) |
\(t_\text{c}\ge t_{\alpha(n_1+n_2-2)}\) |
\(P(t_{(n_1+n_2-2)} > t_\text{c})\) |
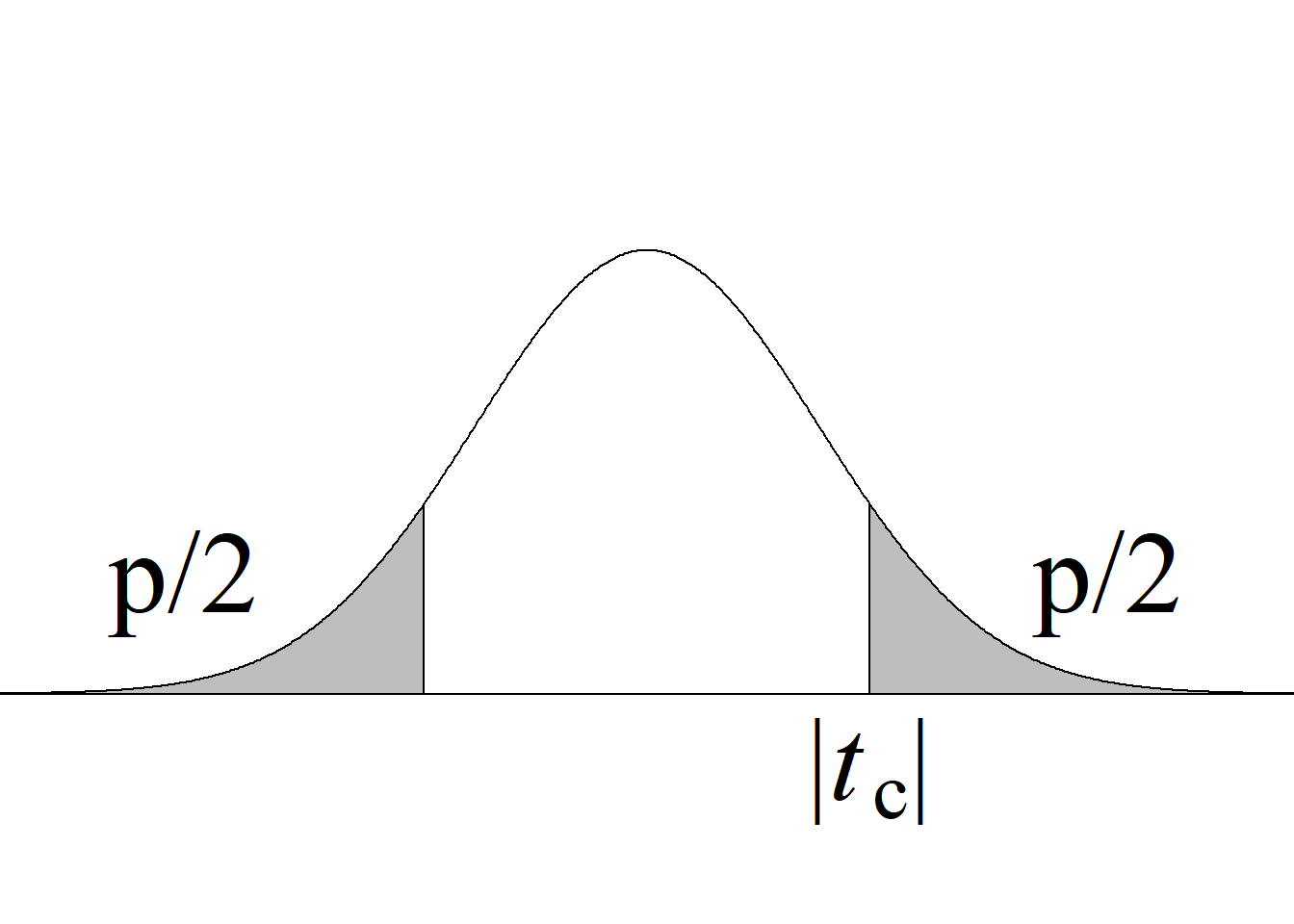
| Dos colas \(H_0:\mu_1=\mu_2\) \(H_a:\mu_1\ne\mu_2\) |
\(|t_\text{c}|\ge t_{\alpha/2(n_1+n_2-2)}\) |
\(2 \, P(t_{(n_1+n_2-2)} > |t_\text{c}|)\) |
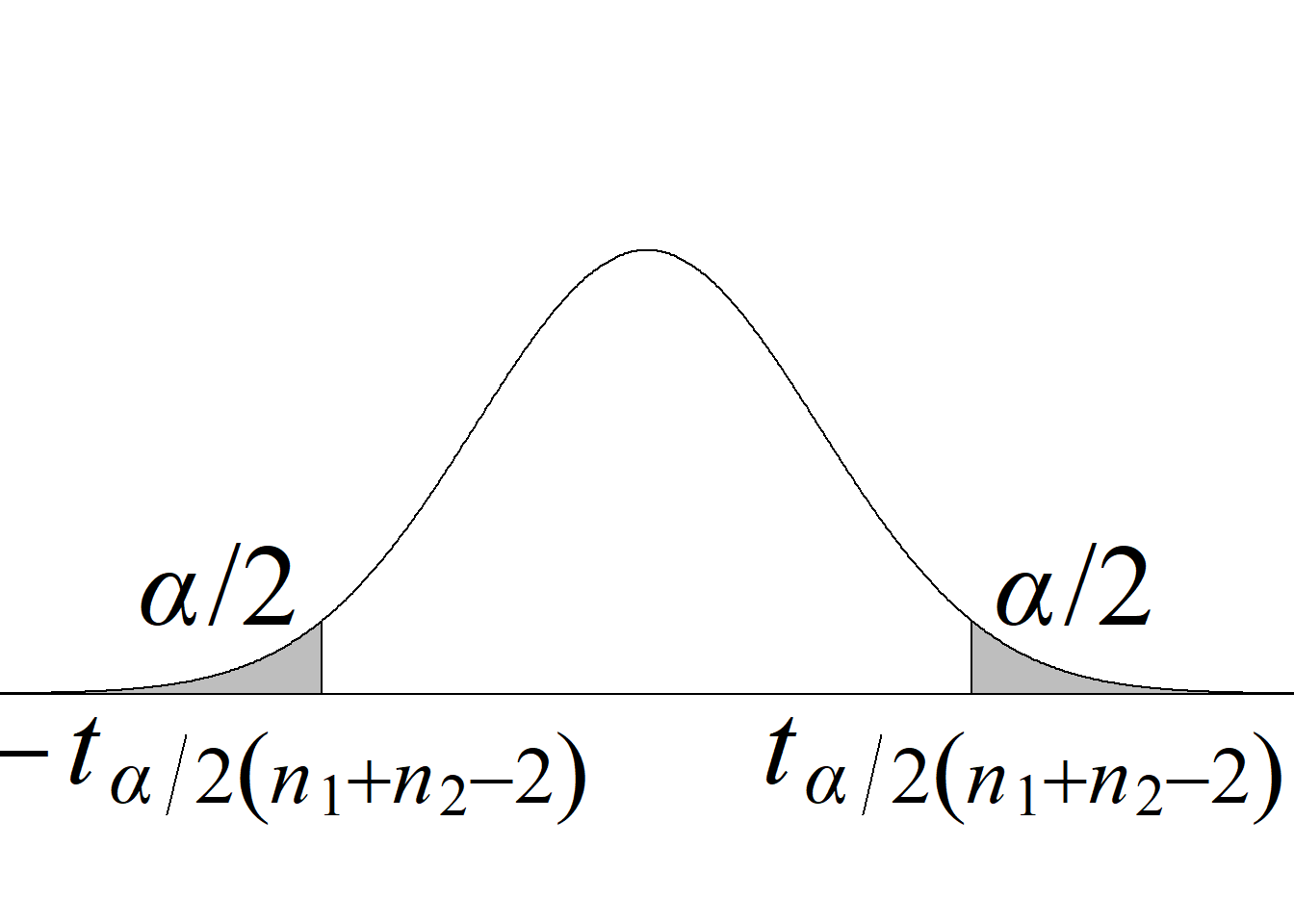
5.2.1.2 Intervalo de confianza para la diferencia de dos medias normales, usando muestras independientes, con varianzas homogéneas
El juego de hipótesis para comparar dos medias puede escribirse en términos de la diferencia entre tales medias:
\[
H_0:\mu_1-\mu_2=0
\] \[
H_a:\mu_1-\mu_2\ne0
\]
Consecuentemente, se construye un intervalo de confianza para la diferencia de las medias poblacionales como contraparte del juego de hipótesis para la comparación de medias.
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia de dos medias, \(\mu_1 − \mu_2,\) usando muestras independientes, cuando las varianzas poblacionales son homogéneas, está dado por:
\[
\left(\overline{X}_1-\overline{X}_2\right)\pm t_{\alpha/2\left(n_1+n_2-2\right)}
\sqrt{S_\text{p}^2\left(\frac{1}{n_1}+\frac{1}{n_2}\right)}
\tag{5.6}\]
Nota 5.1: Interpretación intervalos de confianza para la diferencia de medias
Interpretación general
Si \(\text{LI}\) y \(\text{LS}\) representan, respectivamente, los límites inferior y superior de un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia \(\mu_1 − \mu_2,\) se tiene una confianza del \(100(1−\alpha)\,\%\) en que la diferencia \(\mu_1 − \mu_2\) está contenida entre \(\text{LI}\) y \(\text{LS}.\)
¿¡Y si ambos límites son positivos!?
Un intervalo de confianza para \(\mu_1 − \mu_2\) en el que ambos límites sean positivos es el reflejo de que \(\mu_1\) supera significativamente a \(\mu_2.\) Se tendrá una confianza del \(100(1−\alpha)\,\%\) en que \(\mu_1\) supera a \(\mu_2\) en una cantidad que está entre \(\text{LI}\) y \(\text{LS}\) (cf. figura 5.7).
¿¡Y si ambos límites negativos!?
Un intervalo de confianza para \(\mu_1 − \mu_2\) en el que ambos límites sean negativos es el reflejo de que \(\mu_2\) supera significativamente a \(\mu_1.\) Se tendrá una confianza del \(100(1−\alpha)\,\%\) en que \(\mu_2\) supera a \(\mu_1\) en una cantidad que está entre \(-\text{LS}\) y \(-\text{LI}\) (cf. figura 5.7).
¿¡Y si el límite inferior es negativo y el superior positivo!?
Un intervalo de confianza para \(\mu_1 − \mu_2\) en el que el límite inferior sea negativo y el superior positivo, es decir, que contenga el cero, indica que no hay diferencia estadísticamente significativa entre \(\mu_1\) y \(\mu_2,\) esto es, que la diferencia entre tales parámetros podría ser cero (cf. figura 5.7).
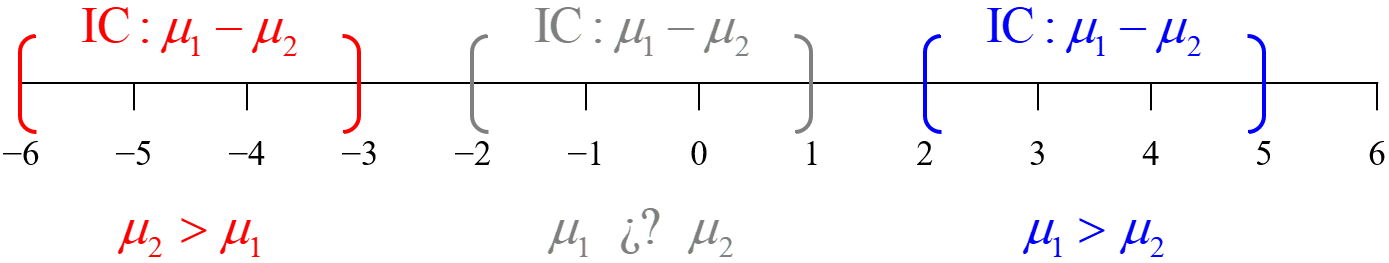
Tip 5.1: ¡No es lo mismo, pero da igual!
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_1 − \mu_2\), obtenido con base en una muestra particular, brinda la misma información que un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_2 − \mu_1\), construido con base en esa misma muestra.
En efecto, el límite inferior de uno de los intervalos es el opuesto del límite superior del otro intervalo, es decir, el mismo valor con signo contrario, tal y como lo ilustra la figura 5.8.
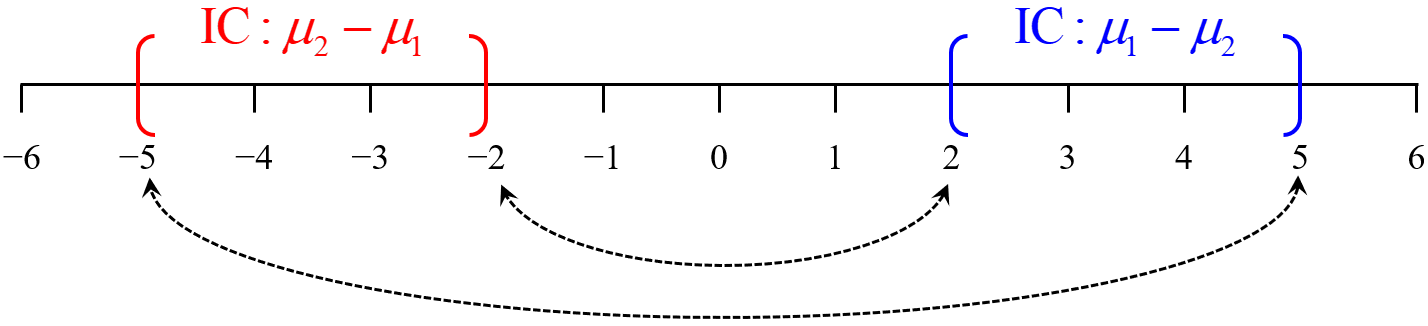
No obstante lo anterior, es necesario tener presente a cuál diferencia de medias corresponde un intervalo dado, pues de ello depende su correcta interpretación.
Ejemplo 5.2
Para evaluar el efecto del pH en la síntesis de polihidroxialcanoatos (PHA) por parte de Bacillus megaterium, con glicerol residual como sustrato, a una concentración de 15 g/L y una temperatura de 25 \(^{\circ}\text{C},\) se realizaron 30 ensayos independientes; 15 de ellos a un pH de 7.0 y otros 15 a un pH de 8.0. Los resultados se presentan en la tabla 5.4.
| pH 7.0 | 2.71 | 4.18 | 3.32 | 4.09 | 2.37 | 1.59 | 2.90 | 2.32 | 1.10 | 1.70 | 2.30 | 2.27 | 4.40 | 2.09 | 2.38 |
| pH 8.0 | 0.59 | 2.60 | 0.15 | 1.64 | 1.60 | 2.67 | 1.83 | 0.17 | 1.41 | 2.75 | 2.00 | 2.36 | 2.06 | 3.53 | 2.89 |
Se usa un nivel de significancia del 5 % para evaluar si el contenido medio de PHA se ve afectado por el pH.
Para tal efecto, se plantea el siguiente juego de hipótesis:
\[
H_0: \mu_{\text{pH}7.0}=\mu_{\text{pH}8.0}
\] \[
H_a: \mu_{\text{pH}7.0}\ne\mu_{\text{pH}8.0}
\]
A continuación, se presentan los estadísticos básicos de cada muestra:
| pH 7.0: \(n=15,\quad\overline{X}=2.648,\quad S^2=0.947\) |
| pH 8.0: \(n=15,\quad\overline{X}=1.889,\quad S^2=1.001\) |
Usando la expresión 5.3, se calcula la varianza combinada:
\[
S_\text{p}^2=\frac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2}
=\frac{14\times 0.947+14\times 1.001}{15+15-2}=0.974
\]
¡No hay ponderación!
Cuando se tienen muestras de igual tamaño, cada varianza recibe la misma ponderación; en consecuencia, la varianza combinada coincide con el promedio aritmético de las varianzas.
Seguidamente, se calcula el estadístico de prueba, usando la expresión 5.5:
\[
t_\text{c}=\frac{\overline{X}_1-\overline{X}_2}
{\sqrt{S_\text{p}^2\left(\dfrac{1}{n_1}+\dfrac{1}{n_2}\right)}}
=\frac{2.648-1.889}
{\sqrt{0.974\left(\dfrac{1}{15}+\dfrac{1}{15}\right)}}=2.106
\]
Bajo la hipótesis nula, el estadístico de prueba sigue una distribución \(t\) con 28 gl. Dado que se está evaluando un juego de hipótesis de dos colas, el valor absoluto del estadístico de prueba se compara con el valor crítico superior 0.025 de la distribución \(t\) con 28 gl (cf. tabla 5.3 y figura 5.6 (c)).
qt(0.025, 28, lower.tail = F)[1] 2.048407| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(|t_\text{c}|\) \(2.106\) |
\(>\) \(>\) |
\(t_{0.025(28)}\) \(2.048\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) se rechaza \(H_0\) con \(α = 0.05\) |
Por tanto, puede afirmarse, con una probabilidad máxima de error de 0.05, que la producción media de PHA difiere entre las dos condiciones evaluadas de pH.
Aunque la prueba sea no direccional, puede saberse con cuál de los dos pH se espera una mayor síntesis media de PHA. Para tal efecto, basta con observar las medias muestrales.
En este caso, la media muestral de PHA correspondiente al pH 7.0 es mayor que la correspondiente al pH 8.0. Por lo tanto, puede precisarse que cuando el bioproceso se realiza a pH 7.0 se espera una mayor producción media de PHA que a pH 8.0.
La figura 5.9 muestra los elementos que participan en el contraste, representados en la distribución que sigue el estadístico de prueba bajo la hipótesis nula: \(t\) con 28 gl.

Al tratarse de una prueba de dos colas, la región de rechazo está conformada por los valores que dejan áreas de \(\alpha/2\) en cada una de las colas de la distribución, es decir, los valores menores que −2.048 y los mayores que 2.048. Las correspondientes áreas, que suman 0.05, aparecen sombreadas en color naranja.
Sin importar el orden en el que se tome la diferencia de las medias muestrales para el cálculo del estadístico de prueba, su valor absoluto se ubicará en la región de rechazo. Este orden tampoco afecta el cálculo del valor p, el cual se obtiene con base en la correspondiente expresión para pruebas de dos colas que se presenta en la tabla 5.3. Se usan líneas oblicuas de color vinotinto para representar la correspondiente semiárea.
Precaución 5.1: ¿El orden importa?
Puesto que el criterio de rechazo para una prueba de dos colas consiste en rechazar la hipótesis nula si \(|t_\text{c}|\ge t_{\alpha/2(n_1+n_2-2)},\) la conclusión será la misma, sin importar cuál de las medias muestrales actúe como minuendo y cuál otra como sustraendo en el numerador de la expresión 5.5.
Si para calcular el estadístico de prueba del ejemplo 5.2 se hubiera tomado \(\overline{X}_2-\overline{X}_1,\) en lugar de \(\overline{X}_1-\overline{X}_2,\) se habría obtenido un estadístico de prueba con signo contrario, es decir, −2.106, con base en el cual se habría llegado a las mismas conclusiones, ya fuera usando el método tradicional o el valor p.
Esto, sin embargo, no se cumple para pruebas de una cola, en las que sí es necesario tomar las diferencias de las medias muestrales en el orden planteado en el juego de hipótesis.
La diferencia de las medias muestrales que aparece en el numerador del estadístico de prueba de la expresión 5.5 es el estimador de la diferencia de las medias poblacionales bajo la hipótesis nula, cuando el juego de hipótesis se escribe como diferencia de medias:
\[ 1.\quad H_0: \mu_1 - \mu_2 = 0,\, \text{se usa} \;\overline{X}_1-\overline{X}_2 \] \[ 2.\quad H_0: \mu_1 - \mu_2 \ge 0,\, \text{se usa} \;\overline{X}_1-\overline{X}_2 \]
\[ 3.\quad H_0: \mu_1 - \mu_2 \le 0,\, \text{se usa} \;\overline{X}_1-\overline{X}_2 \]
\[ 4.\quad H_0: \mu_2 - \mu_1 = 0,\, \text{se usa} \;\overline{X}_2-\overline{X}_1 \]
\[ 5.\quad H_0: \mu_2 - \mu_1 \ge 0,\, \text{se usa} \;\overline{X}_2-\overline{X}_1 \]
\[ 6.\quad H_0: \mu_2 - \mu_1 \le 0,\, \text{se usa} \;\overline{X}_2-\overline{X}_1 \]
Resulta evidente que solo los casos 1 y 4 —correspondientes a pruebas de dos colas— son equivalentes. En cualquiera de los otros casos, el orden en el que se calcule la diferencia de las medias muestrales debe reflejar el orden en el que se hipotetiza la diferencia entre las medias poblacionales.
Un intervalo de confianza del 95 % para la diferencia media en la producción de PHA, \(\mu_{\text{pH}7.0} − \mu_{\text{pH}8.0},\) se obtiene con base en la expresión 5.6:
\[
\left(2.648-1.889\right)\pm 2.048
\sqrt{0.974\left(\frac{1}{15}+\frac{1}{15}\right)}=
0.759\pm 0.738
\]
\[
\text{IC}_{\mu_{\text{pH}7.0} − \mu_{\text{pH}8.0}}:\quad[0.021,\;1.497]
\]
Con base en el anterior intervalo puede decirse que se tiene una confianza del 95 % en que la síntesis media de PHA por parte de Bacillus megaterium, usando glicerina residual como sustrato en una concentración de 15 g/L, a una temperatura de 25 \(^{\circ}\text{C},\) con un pH de 7.0, supera la síntesis media de PHA, cuando se trabaja a pH de 8.0 en una cantidad que está entre 0.021 y 1.497 mg/L.
5.2.1.3 Uso de R para realizar inferencia sobre la diferencia de dos medias normales, usando muestras independientes, con varianzas homogéneas
El siguiente script de R facilita la realización de los procedimientos inferenciales del ejemplo 5.2.
La primera línea importa la información de la tabla 5.4, la cual está contenida en el archivo ejemplo 5.2.xlsx.
Las líneas 2 y 3 realizan la prueba de Shapiro-Wilk para evaluar la normalidad de cada una de las dos muestras. Este es el resultado de la ejecución de la línea 2:
Shapiro-Wilk normality test
data: data$pH7.0
W = 0.92727, p-value = 0.2483Puesto que \(\text{p} = 0.2483,\) no se detectan desviaciones severas del supuesto de normalidad para la muestra pH7.0.
Y este es el resultado de la ejecución de la línea 3:
Shapiro-Wilk normality test
data: data$pH8.0
W = 0.94668, p-value = 0.4737Puesto que \(\text{p} = 0.4737,\) no se detectan desviaciones severas del supuesto de normalidad para la muestra pH8.0.
Para la parte central del contraste se utiliza la función t.test{stats} (línea 4). Entre los argumentos que esta función trae por defecto está que la diferencia de las dos medias es cero (mu = 0), que la confianza es 95 % (conf.level = 0.95) y que las varianzas son heterogéneas (var.equal = FALSE). Puesto que para el presente ejemplo se suponen varianzas homogéneas, es necesario indicarlo explícitamente (var.equal = TRUE).
Se obtiene el siguiente resultado:
Two Sample t-test
data: pH7.0 and pH8.0
t = 2.1053, df = 28, p-value = 0.04436
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.02050979 1.49682355
sample estimates:
mean of x mean of y
2.648000 1.889333
¡¿Y el orden?!
En la función t.test, el valor del primer argumento se usa como minuendo de la diferencia de medias, mientras que el valor del segundo argumento se usa como sustraendo.
De acuerdo con lo indicado anteriormente, el orden en el que se introduzcan los argumentos no altera la decisión inferencial en pruebas de dos colas. No obstante, sí define cuál media actúa como minuendo y cuál como sustraendo en el intervalo de confianza.
Por otra parte, cuando se contrastan pruebas de una cola es esencial ingresar los dos primeros argumentos de la función t.test en correspondencia con el orden de la diferencia planteada.
5.2.2 Comparación de medias, usando muestras independientes, con varianzas heterogéneas: Prueba de Welch
Considérense dos muestras aleatorias independientes, provenientes de sendas poblaciones normales9:
\(X_{11},X_{12},...,X_{1n_1}\: \text{iid}\: N\left(\mu_1, \sigma_1^2\right)\quad\) y \(\quad X_{21},X_{22},...,X_{2n_2}\: \text{iid}\: N\left(\mu_2, \sigma_2^2\right)\)
La media de cada una de estas muestras —que es una combinación lineal de variables aleatorias normales— tiene a su vez distribución normal.
\[
\overline{X}_1\thicksim N\left(\mu_1,\;\sigma_1^2/n_1\right)
\]
\[
\overline{X}_2\thicksim N\left(\mu_2,\;\sigma_2^2/n_2\right)
\]
La diferencia de estas medias también es una variable aleatoria normal:
\[
\left(\overline{X}_1-\overline{X}_2\right)\thicksim N\left(\mu_1-\mu_2,\;\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}\right)
\]
Estandarizando:
\[
\frac{\Big(\overline{X}_1-\overline{X}_2\Big)-\Big(\mu_1-\mu_2\Big)}
{\sqrt{\dfrac{\sigma_1^2}{n_1}+\dfrac{\sigma_2^2}{n_2}}} \thicksim N\left(0,\;1\right)
\]
Se busca un estadístico de prueba que permita contrastar el siguiente juego de hipótesis:
\[
H_0:\mu_1=\mu_2\Leftrightarrow \mu_1-\mu_2=0
\]
\[
H_a:\mu_1\ne\mu_2\Leftrightarrow \mu_1-\mu_2\ne0
\]
Cuando la hipótesis nula es cierta, la variable aleatoria anterior adquiere la siguiente forma:
\[
\frac{\overline{X}_1-\overline{X}_2}
{\sqrt{\dfrac{\sigma_1^2}{n_1}+\dfrac{\sigma_2^2}{n_2}}} \thicksim N\left(0,\;1\right)
\]
En la sección 5.2.1.1 se mostró que si las varianzas fueran iguales \(\left(\sigma_1^2=\sigma_2^2=\sigma^2\right),\) sería pertinente estimar \(\sigma^2\) combinando las varianzas muestrales (cf. expresión 5.3). No obstante, cuando las varianzas son heterogéneas \(\left(\sigma_1^2\ne\sigma_2^2\right)\) —al no existir una varianza común, \(\sigma^2\)— esta estimación deja de ser aplicable.
¡Qué problema!
Behrens fue el primero en proponer, en 1929, una prueba para comparar las medias de dos poblaciones normales con varianzas heterogéneas. En 1935, Fisher reenfocó este problema en el marco teórico de las distribuciones fiduciales, desarrollando una solución que coincidía con la de Behrens.
En honor a estos dos autores, al problema que surge cuando se comparan medias de dos poblaciones normales con varianzas heterogéneas se le conoce como problema de Behrens-Fisher.
Puesto que en este caso no sería pertinente estimar una varianza común, \(\sigma^2,\) cada una de las varianzas poblacionales se estima mediante su mejor estimador insesgado (cf. sección 3.9.1.1.2), dando lugar a la siguiente expresión:
\[
\frac{\overline{X}_1-\overline{X}_2}
{\sqrt{\dfrac{S_1^2}{n_1}+\dfrac{S_2^2}{n_2}}}
\]
Welch (1938) demostró que este estadístico sigue una distribución aproximadamente \(t\) con \(\nu\) gl, siendo \(\nu\) un parámetro desconocido que se estima mediante la fórmula de los grados de libertad efectivos, la cual también fue deducida en otro contexto por Satterthwaite (1946), por lo que se le conoce como la aproximación de Welch-Satterthwaite.
El estadístico de la prueba de Welch se expresa así:
\[
t_\text{c} = \frac{\Big(\overline{X}_1-\overline{X}_2\Big)}
{\sqrt{\dfrac{S_1^2}{n_1}+\dfrac{S_2^2}{n_2}}} \overset{H_0}{\overset{\cdot}{\thicksim}} t_{(\nu)}
\tag{5.7}\]
Donde \(\nu\) se estima mediante la aproximación de Welch-Satterthwaite, así10:
\[
\widehat\nu=\dfrac{\left(\dfrac{S_1^2}{n_1}+\dfrac{S_2^2}{n_2}\right)^2}
{\dfrac{\left(\dfrac{S_1^2}{n_1}\right)^2}{n_1-1}+\dfrac{\left(\dfrac{S_2^2}{n_2}\right)^2}{n_2-1} }
\tag{5.8}\]
Al contraste de hipótesis basado en la expresión 5.7 se le conoce como prueba de Welch.
¡Notación!
En los textos clásicos era común denotar el estadístico de prueba de la expresión 5.7 como \(T_\text{c}\) o \(t’_\text{c}\;\), para distinguirlo del estadístico de prueba de la expresión 5.5 que se utiliza en la prueba estándar de \(t.\)
En la actualidad, la tendencia consiste en simplificar la notación, usando \(t_\text{c}\) (o simplemente \(t\)) para cualquiera de estos estadísticos de prueba, enfatizando la metodología en el contexto de la prueba.
Advertencia 5.2: !No los redondee!
Puesto que los grados de libertad efectivos usualmente tienen una parte decimal, una práctica común ha sido redondearlos al entero inferior (función piso o parte entera), con lo cual, a la vez que se resuelve el problema de llevar los grados de libertad a un valor obtenible en tablas, se le “ayuda” un poco a la prueba, disminuyendo la probabilidad de error tipo I.
En la actualidad no hay ninguna razón para ello, puesto que existen muchas aplicaciones informáticas, v. gr., R, que permiten obtener los valores críticos de una distribución \(t\) con grados de libertad no enteros.
Por otra parte, debe tenerse en cuenta que, si bien el redondeo al entero inferior disminuye la tasa de error tipo I, también disminuye la potencia de la prueba.
¿Mejor la prueba “exacta”?
El hecho de que una prueba esté basada en una distribución aproximada no la hace peor que una prueba análoga basada en una distribución exacta.
Así, por ejemplo, al comparar diferentes pruebas para inferir sobre una proporción binomial, se ha encontrado que “aproximado es mejor que exacto”, tal y como lo destacan Agresti y Coull (1998) (cf. sección 4.4.2).
En el mismo sentido, las diferentes pruebas y estrategias destinadas a inferir sobre la diferencia de medias de dos poblaciones normales deben someterse a evaluación bajo diferentes condiciones, mediante ensayos de simulación.
Producto de tales evaluaciones, Zimmerman (2004) y Delacre et al. (2017) coinciden en señalar que, en la mayoría de casos, el uso directo de la prueba de Welch, es decir, sin que esté condicionado al resultado de una prueba de homogeneidad de varianzas, da lugar a tasas de error más cercanas a la nominal y mayores potencias (cf. sección 5.2).
En consecuencia, se recomienda usar siempre la prueba de Welch para inferir sobre la diferencia de medias de dos poblaciones normales.
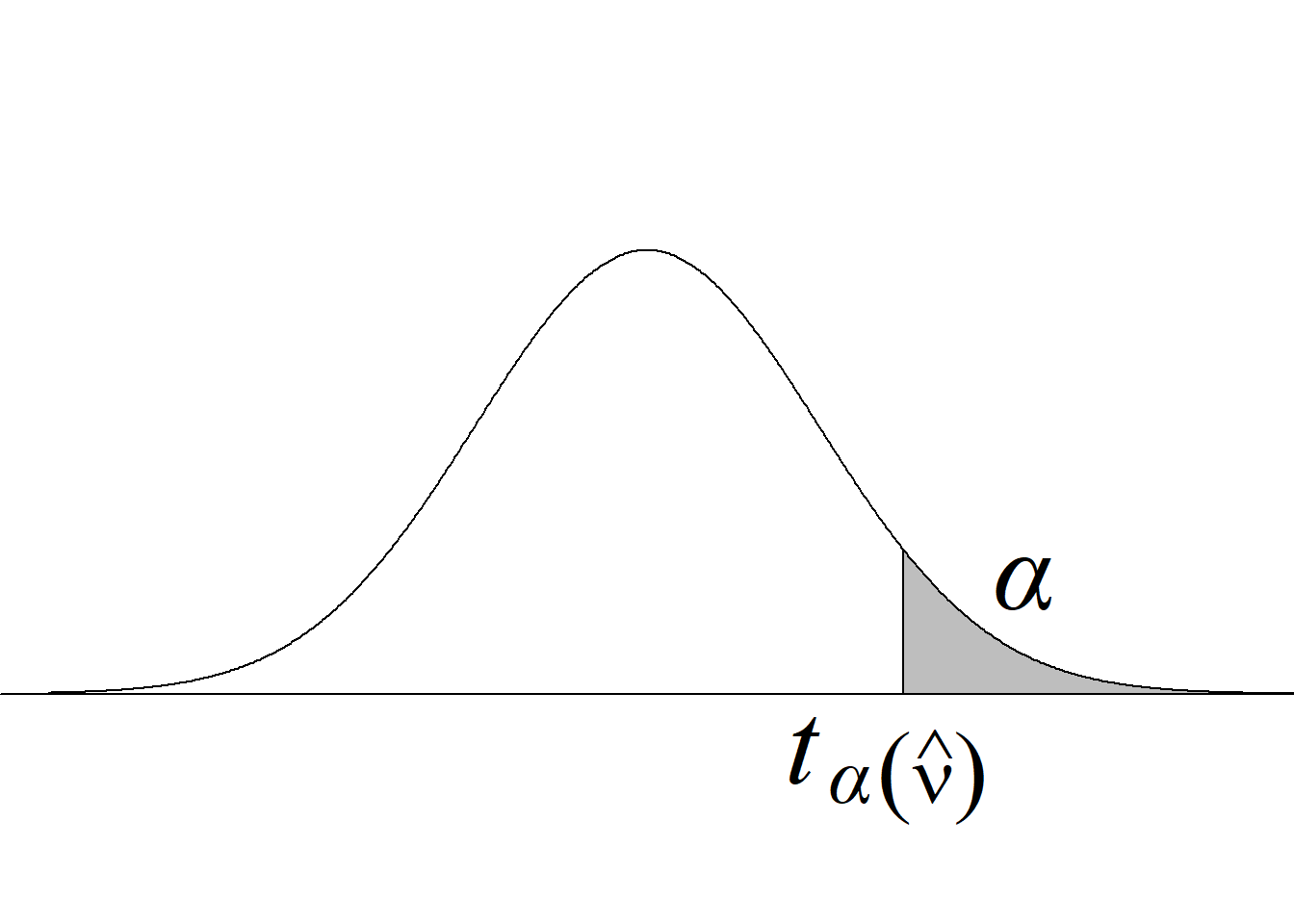
La tabla 5.5 y la figura 5.10 resumen los criterios de rechazo para diferentes tipos de pruebas.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda \(H_0:\mu_1\ge\mu_2\) \(H_a:\mu_1<\mu_2\) |
\(t_\text{c}\le−t -{\alpha(\widehat\nu)}\) |
\(P(t_{(\widehat\nu)} < t_\text{c})\) |
| Cola derecha \(H_0:\mu_1\le\mu_2\) \(H_a:\mu_1>\mu_2\) |
\(t_\text{c}\ge t_{\alpha(\widehat\nu)}\) |
\(P(t_{(\widehat\nu)} > t_\text{c})\) |
| Dos colas \(H_0:\mu_1=\mu_2\) \(H_a:\mu_1\ne\mu_2\) |
\(|t_\text{c}|\ge t_{\alpha/2(\widehat\nu)}\) |
\(2 \, P(t_{(\widehat\nu)} > |t_\text{c}|)\) |
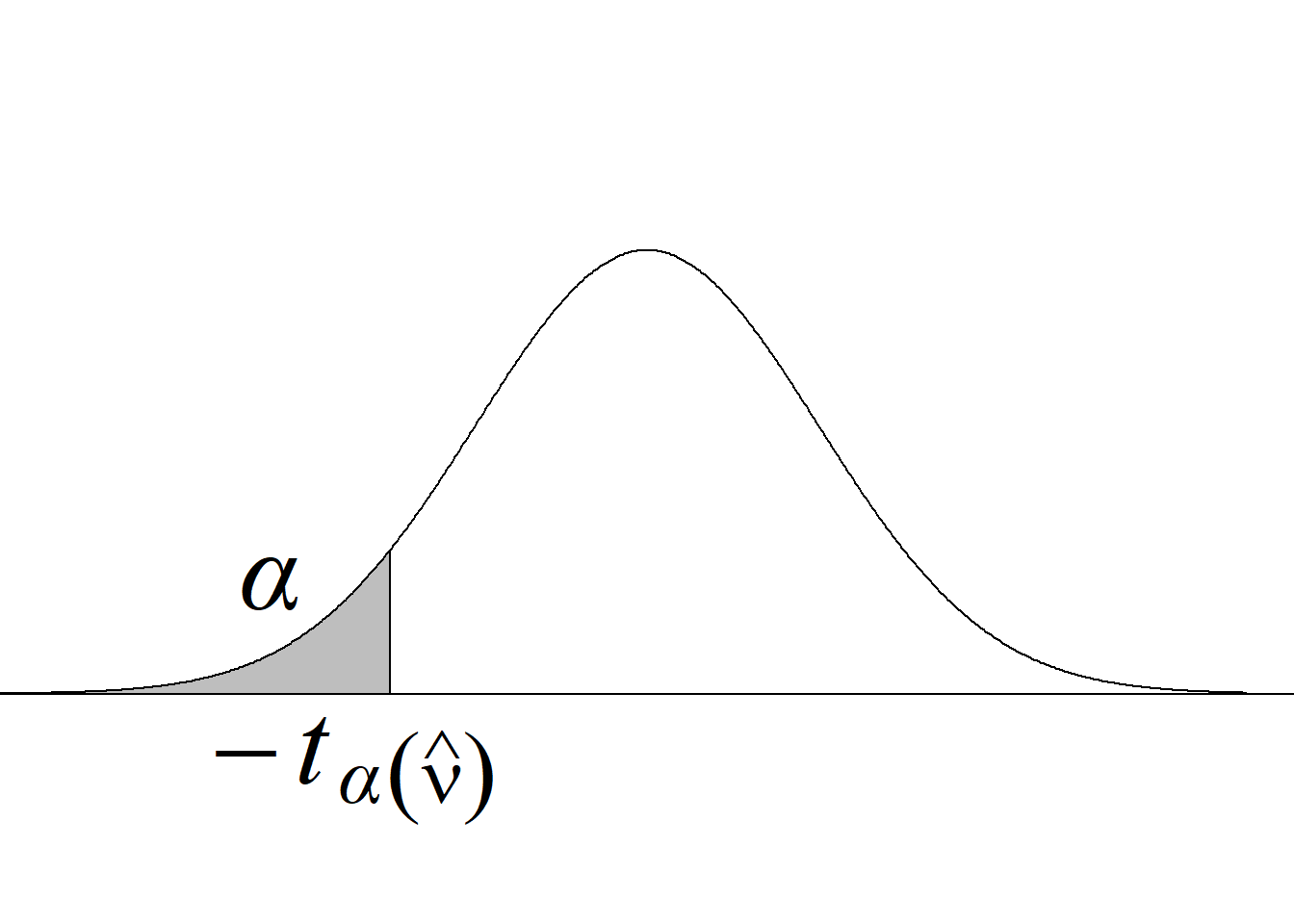
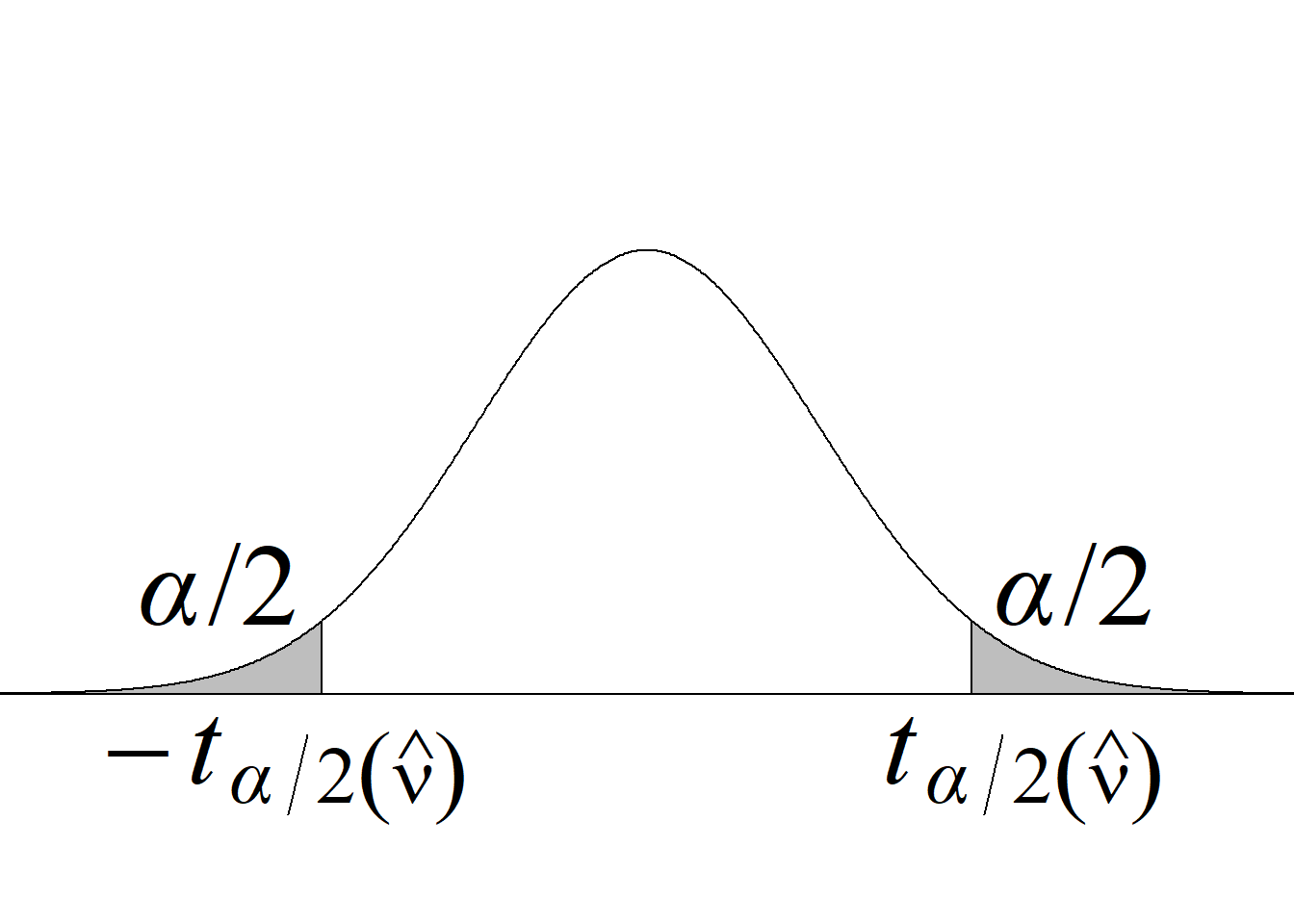
5.2.2.1 Intervalo de confianza para la diferencia de dos medias normales, usando muestras independientes, con varianzas heterogéneas
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia de dos medias, \(\mu_1 − \mu_2,\) basado en la prueba de Welch, está dado por la siguiente expresión:
\[
\Big(\overline{X}_1-\overline{X}_2\Big)
\pm t_{\alpha/2(\widehat\nu)} \sqrt{\frac{S_1^2}{n_1}+\frac{S_2^2}{n_2}}
\tag{5.9}\]
Ejemplo 5.3
Se realiza una investigación para evaluar las posibles causas de un síndrome detectado en abejas angelita (Tetragonisca angustula). Se cree que las colonias ubicadas en bosque húmedo tropical (bh-T) podrían tener un mayor riesgo que las ubicadas en bosque húmedo premontano (bh-PM).
Se ubican 10 colonias en bh-T y 8 en bh-PM; en cada una de ellas, se realiza un registro visual durante 30 minutos contabilizando los individuos que manifiestan el síndrome.
Los resultados se presentan en la tabla 5.6.
| bh-T | 15 | 17 | 8 | 11 | 10 | 11 | 5 | 12 | 14 | 11 |
| bh-PM | 6 | 11 | 13 | 6 | 8 | 9 | 7 | 10 |
Para probar si las colonias ubicadas en bh-T tienen un mayor riesgo que las ubicadas en bh-PM, se plantea el siguiente juego de hipótesis.
\[
H_0: \mu_{\text{bh-T}}\le \mu_{\text{bh-PM}}
\] \[
H_a: \mu_{\text{bh-T}} > \mu_{\text{bh-PM}}
\]
Advertencia 5.3: ¿Es lo mismo?
Existen dos formas equivalentes de plantear un juego de hipótesis unilateral para la comparación de dos parámetros; una de ellas da lugar a una prueba de cola izquierda, mientras que la otra corresponde a una prueba de cola derecha.
El juego de hipótesis planteado anteriormente —que da lugar a una prueba de cola derecha— equivale al siguiente juego de hipótesis de cola izquierda:
\[
H_0: \mu_{\text{bh-PM}}\ge \mu_{\text{bh-T}}
\] \[H_a: \mu_{\text{bh-PM}} < \mu_{\text{bh-T}}\]
Ambos planteamientos corresponden a la misma pregunta y conducen exactamente al mismo resultado11.
Esto no debe confundirse, sin embargo, con lo ilustrado en el ejemplo 4.4, donde lo que se plantea no es la misma pregunta desde lados opuestos, sino que se considera la posibilidad de formular una pregunta diferente, dando lugar a una prueba en la que los tipos de error y el control que se ejerce sobre los mismos quedan definidos de distinta manera.
¿¡Y la normalidad!?
A primera vista puede parecer extraño usar el conteo de individuos como insumo en una prueba de comparación de medias de dos poblaciones normales.
Aunque el modelo exacto para la variable aleatoria que representa el número de individuos con el síndrome es el Poisson12, la normal brinda una buena aproximación cuando \(\lambda \ge 7\) (Correa-Londoño y Castillo-Morales, 2000).
!Muestree la muestra!
Vale la pena llamar la atención sobre el uso de submuestreo cuando el registro de la información muestral es complejo y/o costoso. En la sección 6.1.7.1 se aborda nuevamente este tópico.
En el presente ejemplo, la muestra correspondiente a la población bh-T consta de 10 colonias, y la correspondiente a la población bh-PM, de 8. La lectura real de cada unidad muestral sería el número de abejas afectadas por el síndrome en cada una de las colonias. Puesto que dicha lectura implicaría la destrucción de las colonias, puede encontrarse conveniente muestrear cada unidad muestral, esto es, hacer un submuestreo.
El objetivo del submuestreo es obtener, a partir de un menor número de lecturas, una estimación del valor de la variable en la unidad muestral. Aunque el objetivo es claro, la estrategia dependerá de las características del ensayo y de la muestra.
En general, si la característica de interés se manifiesta homogéneamente sobre la unidad muestral, podrá usarse una submuestra de menor tamaño que si esta se manifiesta de forma heterogénea. Cada ensayo tiene particularidades que el investigador deberá resolver acorde con su experiencia y buen tino.
Así, en el ejemplo planteado, el investigador tendrá que resolver si la observación en el exterior de la colmena sí brinda una adecuada estimación de su estado interno. Tendrá que considerar, por ejemplo, si el síndrome que se está estudiando puede afectar la movilidad o la disposición de las abejas para salir al exterior, lo cual, de ser así, sesgaría los resultados, dando lugar a una subestimación del número de individuos con el síndrome. Tendrá que considerar asimismo cuál es la hora más adecuada para realizar las observaciones y cuál lapso de tiempo puede proporcionar una mejor estimación.
Para contrastar el juego de hipótesis planteado, se calculan los grados de libertad efectivos y el estadístico de prueba, a partir de las expresiones 5.8 y 5.7, respectivamente.
\[ \widehat\nu=\dfrac{\left(\dfrac{S_1^2}{n_1}+\dfrac{S_2^2}{n_2}\right)^2} {\dfrac{\left(\dfrac{S_1^2}{n_1}\right)^2}{n_1-1}+\dfrac{\left(\dfrac{S_2^2}{n_2}\right)^2}{n_2-1}} =\dfrac{\left(\dfrac{11.82}{10}+\dfrac{6.21}{8}\right)^2} {\dfrac{\left(\dfrac{11.82}{10}\right)^2}{10-1}+\dfrac{\left(\dfrac{6.21}{8}\right)^2}{8-1}} =15.89 \]
\[ t_\text{c} = \frac{\overline{X}_1-\overline{X}_2} {\sqrt{\dfrac{S_1^2}{n_1}+\dfrac{S_2^2}{n_2}}} =\frac{11.4-8.75} {\sqrt{\dfrac{11.82}{10}+\dfrac{6.21}{8}}} =1.893 \]
La región de rechazo para el juego de hipótesis planteado (de cola derecha) está constituida por los valores mayores o iguales que \(t_{0.05(15.89)}\) (cf. tabla 5.5 y figura 5.10 (b)). El valor crítico superior se obtiene en R mediante la siguiente instrucción:
qt(0.05, 15.89, lower.tail = FALSE)[1] 1.746625| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(t_\text{c}\) \(1.893\) |
\(>\) \(>\) |
\(t_{0.05(15.89)}\) \(1.747\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) se rechaza \(H_0\) con \(α = 0.05\) |
Puede afirmarse, con una probabilidad máxima de error de 0.05, que la afectación media por el síndrome es superior en bh-T que en bh-PM.
El valor p se obtiene como el área a la derecha del estadístico de prueba (cf. tabla 5.5 y figura 5.10 (e)):
pt(1.893, 15.89, lower.tail = FALSE)[1] 0.03835871| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.038\) |
\(<\) \(<\) |
\(\alpha\) \(0.05\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) se rechaza \(H_0\) |
La probabilidad de obtener, bajo la hipótesis nula, resultados muestrales iguales o más extremos que los actuales es 0.038. Por tanto, se rechaza la hipótesis nula y se concluye que la afectación media por el síndrome es mayor en bh-T que en bh-PM.
El estimador puntual de la diferencia está dado por la diferencia entre las correspondientes medias muestrales, así:
\[
\overline{X}_{\text{bh-T}}-\overline{X}_{\text{bh-PM}}=11.4-8.75=2.65
\]
Asimismo, puede obtenerse un intervalo de confianza unilateral inferior del 95 %, para la diferencia \(\mu_{\text{bh-T}} - \mu_{\text{bh-PM}},\) adaptando la 5.9:
\[
\begin{align}
\text{IC}_{\mu_{\text{bh-T}} - \mu_{\text{bh-PM}}}:\quad&\Big(\overline{X}_1-\overline{X}_2\Big)-t_{\alpha(\widehat\nu)} \sqrt{\frac{S_1^2}{n_1}+\frac{S_2^2}{n_2}}\\[1.4em]
=&\Big(\overline{X}_{\text{bh-T}}-\overline{X}_{\text{bh-PM}}\Big)-t_{0.05(15.89)} \sqrt{\frac{S_{\text{bh-T}}^2}{n_{\text{bh-T}}}+\frac{S_{\text{bh-PM}}^2}{n_{\text{bh-PM}}}}\\[1.4em]
=&\left(11.4-8.75\right)-1.7466 \sqrt{\frac{11.82}{10}+\frac{6.21}{8}}\\[1.4em]
=&0.205
\end{align}
\]
Se tiene una confianza del 95 % en que la afectación media de las abejas angelita por el síndrome en el bh-T supera la afectación media que estas presentan en el bh-PM en al menos 0.205 individuos por colonia.
5.2.2.2 Uso de R para realizar inferencia sobre la diferencia de dos medias normales, usando muestras independientes
El siguiente script de R facilita la realización de los procedimientos inferenciales del ejemplo 5.3.
La primera línea importa la información de la tabla 5.6, la cual está contenida en el archivo ejemplo 5.3.xlsx.
Las líneas 2 y 3 realizan la prueba de Shapiro-Wilk para evaluar la normalidad de cada una de las dos muestras. Este es el resultado de la ejecución de la línea 2:
Shapiro-Wilk normality test
data: data$bh.T
W = 0.97161, p-value = 0.9053Puesto que p = 0.9053, no se detectan desviaciones severas del supuesto de normalidad para la muestra bh-T.
Y este es el resultado de la ejecución de la línea 3:
Shapiro-Wilk normality test
data: data$bh.PM
W = 0.94124, p-value = 0.6233Puesto que p = 0.6233, no se detectan desviaciones severas del supuesto de normalidad para la muestra bh-PM.
Para la parte central del contraste se utiliza la función t.test{stats} (línea 4). Entre los argumentos que esta función trae por defecto está: la diferencia de las dos medias es cero (mu = 0), la confianza del intervalo es 95 % (conf.level = 0.95), las varianzas son heterogéneas (var.equal = FALSE) y la prueba es de dos colas (alternative = two.sided).
Puesto que para el presente ejemplo se está contrastando una prueba de cola derecha, es necesario indicarlo explícitamente (alternative = "greater").
¡Si no sabe…!
Cuando los argumentos de las funciones para R traen algún valor por defecto, es común que dicho valor corresponda al más frecuente o al recomendado.
Ese es el caso del argumento var.equal, cuyo valor por defecto es FALSE, con lo cual se realiza la prueba de Welch para comparar medias de dos poblaciones normales, lo que está acorde con las recomendaciones de Zimmerman (2004) y Delacre et al. (2017).
Consecuentemente, cuando no tenga mucha claridad sobre el efecto que pudiera tener la asignación de algún valor particular a un argumento, debería dejarlo con su valor por defecto.
Desde luego, una mejor opción consiste en entender el efecto que tiene cada uno de los posibles valores del argumento y elegir el más conveniente.
La ejecución de la línea 4 del script produce el siguiente resultado:
Welch Two Sample t-test
data: bh.T and bh.PM
t = 1.8933, df = 15.892, p-value = 0.03833
alternative hypothesis: true difference in means is greater than 0
95 percent confidence interval:
0.2053584 Inf
sample estimates:
mean of x mean of y
11.40 8.75 5.2.3 Comparación de medias usando muestras pareadas
En contraste con las muestras independientes, en las que las observaciones de una de las muestras no guardan relación con las de la otra (cf. ejemplos 5.2 y 5.3), en las muestras pareadas cada una de las observaciones de una muestra se relaciona con una observación en la otra muestra.
En estos casos, la muestra total está conformada por pares de observaciones, que pueden quedar constituidos naturalmente o estructurarse a criterio del investigador.
Un ejemplo de las muestras pareadas constituidas naturalmente se da en los denominados estudios antes-después, en los que se evalúa una característica sobre un grupo de unidades muestrales antes de una intervención o tratamiento, y posteriormente —tras la intervención— vuelve a evaluarse la característica sobre el mismo grupo.
En este caso, la primera muestra está conformada por el conjunto de lecturas obtenidas antes de la asignación del tratamiento, mientras que la segunda muestra consta de las lecturas registradas sobre las mismas unidades después de la asignación del tratamiento.
A cada una de las lecturas que se registran antes de la intervención le corresponde una lectura después de la intervención, con lo cual, la muestra pareada total consta de pares de observaciones antes-después.
El análisis de este tipo de ensayos se basa en comparar la lectura de cada unidad muestral antes de la intervención con la lectura de esa misma unidad muestral después de la intervención, de manera que cada unidad muestral contenga su propio referente o testigo.
Este tipo de comparación intraunidades permite controlar los factores de confusión asociados con diferencias entre las unidades.
¡Qué confusión!
Se denomina factor de confusión a cualquier condición cambiante o disímil entre grupos que se comparan, que —sin tratarse del factor cuyo efecto se pretende evaluar— puede dar lugar a una parte o a la totalidad de los cambios observados en la respuesta, y cuyo efecto no es separable del efecto del factor de interés.
Este concepto —de alta relevancia en el diseño de experimentos— se amplía en la sección 6.1.2.
Para ilustrar el concepto de los factores de confusión, considérese un ensayo mediante el cual se desea evaluar la efectividad de una dieta de reducción de peso en humanos, usando muestras independientes.
En adición a la dieta —que es el factor de interés y que se postula como causante de la reducción de peso— hay otros factores que pueden propiciar o dificultar la reducción de peso, como la actividad física, la edad y la condición metabólica, entre otros.
Al realizar el ensayo con base en muestras independientes, podría suceder que los participantes de uno de los grupos reunieran un conjunto de condiciones que —sin importar la dieta— propiciaran la reducción de peso.
Si tal grupo coincidiera con el que se somete a la dieta de reducción, no sería posible saber si las diferencias observadas con respecto al grupo control fueron debidas a la dieta, al conjunto de condiciones secundarias o a una combinación de dieta y factores secundarios.
Análogamente, si el grupo que reúne las condiciones favorables actuara como grupo control, sería más difícil detectar un posible efecto benéfico de la dieta evaluada.
En cualquier caso, el conjunto de condiciones favorables (o desfavorables) actuaría como factor de confusión.
Si bien es cierto que un especialista podría tratar de prevenir una situación como la descrita, balanceando los participantes de los dos grupos con base en los niveles de cada uno de los factores que considere más relevantes, difícilmente podría garantizar un efectivo balance de todos estos.
Probablemente tendría en cuenta que la proporción de hombres y mujeres fuera similar en los dos grupos, que la distribución de edades fuera asimismo similar y que las condiciones metabólicas promedio de los dos grupos fueran comparables; también podría incorporar elementos relacionados con la actividad física.
Sin embargo, no podría balancear estos factores por separado, sino que tendría que hacerlo de tal manera que las diferentes combinaciones sexo-edad-condición metabólica-actividad física quedaran balanceadas entre los dos grupos comparados.
Aun si todos los factores relevantes hubieran sido considerados, el balance obtenido difícilmente sería tan eficiente como el que se obtendría mediante el pareamiento antes-después, que garantiza que el grupo sometido a la dieta es exactamente igual al grupo que no estaba sometido a la dieta.
La estrategia antes-después permite mitigar los potenciales factores de confusión asociados con variaciones entre los individuos, siempre que tales factores permanezcan relativamente constantes a lo largo del estudio.
¡No siempre son factibles!
Los estudios antes-después se basan en el postulado de que los factores secundarios antes de la intervención son muy similares a los exhibidos por el grupo después de la intervención.
En muchas ocasiones, la satisfacción de este postulado depende del tiempo que transcurra entre el antes y el después de la intervención. Mientras mayor sea el tiempo entre las dos lecturas, mayor será la posibilidad de que surjan otros factores de confusión asociados con el tiempo.
Aunque las observaciones antes-después resultan muy intuitivas para entender la conformación de muestras paredas, no son las únicas que dan lugar a pares de observaciones naturalmente constituidas.
Considérese un ensayo mediante el cual se pretende comparar la efectividad de dos protectores solares de uso tópico. Para ello podría protegerse uno de los brazos de cada participante con uno de los productos, y el otro brazo —como par natural— con el otro producto. Tras un periodo determinado de exposición a la radiación solar se tomarían lecturas que den cuenta del estado de la piel en ambos brazos.
Lógicamente, las lecturas que se registren para cada individuo en cada uno de sus dos miembros superiores constituyen pares de observaciones. Esto permitiría controlar la gran mayoría de los factores asociados con variaciones dermatológicas entre los diferentes individuos. Asimismo, se controlarían factores asociados con el tiempo y el nivel de exposición, el cual podría variar entre individuos.
¡Pero eso no es todo!
Para controlar el potencial factor de confusión asociado con el costado, por la mayor exposición que podría tener el brazo izquierdo en conductores de vehículos que tienen el volante al lado izquierdo, la asignación de los productos entre las dos extremidades debería realizarse al azar.
En general, siempre que sea posible debe aleatorizarse la asignación de los tratamientos entre los dos elementos del par.
Debe tenerse presente, sin embargo, que no siempre es factible aplicar aleatorización, tal y como sucede en los estudios antes-después13.
En adición a los estudios en los que los pares de observaciones quedan naturalmente constituidos, pueden diseñarse ensayos con muestra pareadas en los que el investigador conforma las parejas de unidades muestrales según su criterio. Esta estrategia amplía el abanico de posibilidades para el diseño de ensayos en investigación aplicada.
En estos casos, el investigador elige pares de unidades, de manera que los miembros de cada par sean muy similares en todos aquellos factores que —en adición al factor principal— puedan afectar la respuesta. Con ello se evita que los factores secundarios actúen como factores de confusión.
Para ilustrarlo, consideremos un estudio realizado por Márquez, López, Correa, Pareja y Giraldo (2003), en el que se evaluó el efecto de la exposición a agentes potencialmente genotóxicos sobre la integridad del genoma.
El equipo de investigación sabía que el daño genético también depende de factores como la edad, el género, el grupo étnico, el consumo de medicamentos y los hábitos, los cuales podrían actuar como factores de confusión.
Con el fin de reforzar los conceptos presentados en esta sección, se invita a reflexionar alrededor de las siguientes cuestiones, en el contexto del estudio de Márquez et al. (2003). Seguidamente, se invita a desplegar el contenido de la caja para contrastar las reflexiones con la discusión que allí se presenta:
¿Cómo evitar que los factores secundarios actúen como factores de confusión?
¿Será más conveniente usar muestras independientes o muestras pareadas?
¿Sería viable la estrategia antes-después?
Esta lógica de homogenización no está limitada a la comparación de dos condiciones:
Bloqueo
El concepto de bloqueo que se presenta en la sección 7.2 es una generalización del concepto de pareamiento.
Se usan pares de observaciones cuando se requiere comparar dos grupos o condiciones, homogenizando por las condiciones que podrían actuar como factores de confusión.
Si fueran a compararse tres, cuatro o \(n\) grupos, se usarían ternas, cuádruplas o \(n\text{-tuplas},\) en lugar de pares.
A los grupos de unidades experimentales homogenizadas con base en uno o más factores secundarios se les denomina genéricamente bloques.
5.2.3.1 Prueba de hipótesis para la comparación de medias, usando muestras pareadas
Considérese un par de muestras aleatorias pareadas provenientes de poblaciones normales:
\(X_{11},X_{12},...,X_{1n}\: \text{iid}\: N\left(\mu_1,\; \sigma_1^2\right)\quad\) y \(\quad X_{21},X_{22},...,X_{2n}\: \text{iid}\: N\left(\mu_2,\; \sigma_2^2\right)\)
El primer subíndice de las variables aleatorias representa la población; el segundo, la variable. Así, por ejemplo, \(X_{21}\) representa la variable aleatoria 1 de la población 2.
Cada una de las variables de la población 1 está pareada con una variable de la población 2, en correspondencia con el segundo subíndice. Así, por ejemplo, \(X_{25}\) es la variable de la segunda población que se empareja con la variable \(X_{15}\) de la primera población.
¿\(\text{iid}\)? ¿Entonces son independientes o no?
Si bien las variables aleatorias que conforman la muestra aleatoria de cada población son independientes, las variables emparejadas entre poblaciones no lo son, debido al pareamiento.
En razón del pareamiento, la varianza de la diferencia entre dos variables emparejadas no depende únicamente de las varianzas marginales, sino también de su covarianza, así.
\[
\begin{align}
V(X_{1i}-X_{2i})&=V(X_{1i})+V(X_{2i})-2\;\text{Cov}(X_{1i}, X_{2i})\\[0.7em]
&= \sigma_1^2+ \sigma_2^2-2\;\text{Cov}(X_{1i}, X_{2i})
\end{align}
\]
La covarianza positiva que existe entre variables adecuadamente pareadas —al restarse en la expresión anterior— da lugar a una reducción en la varianza de las diferencias. Es por ello que —cuando se aplica adecuadamente el criterio de pareamiento— esta estrategia resulta más eficiente que la basada en muestras independientes.
En los diseños con pareamiento, se asume que esta estructura de dependencia es la misma para todos los pares, es decir, que la covarianza entre las variables emparejadas es la misma para cualquier par:
\[
\text{Cov}(X_{1i}, X_{2i})=\text{Cov}(X_{1}, X_{2})\;\forall\; i=1,2,\dotsc,n
\]
El conjunto de diferencias entre variables aleatorias emparejadas conforma a su vez una muestra aleatoria normalmente distribuida:
\[
X_{11}-X_{21},X_{12}-X_{22},...,X_{1n}-X_{2n}\: \text{iid}\: N\left(\mu_1-\mu_2,\; \sigma_1^2+\sigma_2^2-2\;\text{Cov}(X_{1}, X_{2})\right)
\]
Con el fin de simplificar la escritura, definimos una notación basada en \(\delta\) para representar los elementos derivados de las diferencias entre las dos muestras, así:
\[
\begin{align}
X_{1i}-X_{2i}&:=\delta_i\\[0.7em]
\mu_1-\mu_2&:=\mu_\delta\\[0.7em]
\sigma_1^2+\sigma_2^2-2\;\text{Cov}(X_{1}, X_{2})&:=\sigma_\delta^2
\end{align}
\]
La muestra aleatoria de diferencias de variables aleatorias puede escribirse simplificadamente así:
\[
\delta_1,\delta_2,...,\delta_n\: \text{iid}\: N\left(\mu_\delta,\; \sigma_\delta^2\right)
\tag{5.10}\]
¡Es lo mismo!
La muestra aleatoria representada mediante la expresión 5.10 es equivalente a la usada para contrastar la hipótesis sobre la media de una población normal (cf. expresión 4.1). En consecuencia, aplican los mismos desarrollos presentados en la sección 4.2.1.
Y es que, en efecto, el juego de hipótesis para comparar las medias de dos poblaciones normales con muestras pareadas es equivalente al juego de hipótesis para contrastar que la media del vector diferencia es cero.
El promedio de las \(n\) diferencias también es una variable aleatoria con distribución normal:
\[
\overline\delta\thicksim N\left(\mu_\delta,\; \frac{\sigma_\delta^2}{n}\right)
\]
Estandarizando, se obtiene una variable aleatoria normal con media cero y varianza uno:
\[
\frac{\overline\delta-\mu_\delta}{\sqrt{\frac{\sigma_\delta^2}{n}}}\thicksim N\left(0,\;1 \right)
\]
Puesto que la varianza poblacional, \(\sigma_\delta^2,\) es desconocida, se estima a partir de su mejor estimador insesgado (cf. sección 3.9.1.1.2), usando para su cálculo la expresión 2.2:
\[
S^2_\delta=\frac{\sum\limits_{i=1}^{n}{\delta}_i^2- \frac{\left(\, \sum\limits_{i=1}^{n}{\delta}_i \right)^2} {n}} {n-1}
\]
Al remplazar la varianza poblacional por su estimador en la variable aleatoria estandarizada, se obtiene una variable aleatoria que sigue una distribución \(t\) con \(n−1\) gl:
\[
\frac{\overline\delta-\mu_\delta}{\sqrt{\frac{S_\delta^2}{n}}}\thicksim t_{\left(n-1\right)}
\tag{5.11}\]
Considérese el siguiente juego de hipótesis para la comparación de las medias:
\[
H_0:\mu_1=\mu_2\Leftrightarrow \mu_1-\mu_2=0 \Leftrightarrow \mu_\delta=0
\]
\[
H_a:\mu_1\ne\mu_2\Leftrightarrow \mu_1-\mu_2\ne0 \Leftrightarrow \mu_\delta\ne 0
\]
Al imponer el cumplimiento de la hipótesis nula en la expresión 5.11, se obtiene el siguiente estadístico de prueba:
\[
t_\text{c}=\frac{\overline\delta}{S_\delta/\sqrt{n}}\overset {H_0}\thicksim t_{\left(n-1\right)}
\tag{5.12}\]
La tabla 5.7 y la figura 5.11 ilustran la forma en la que se usa el estadístico de prueba para definir el criterio de rechazo y calcular el valor p en los diferentes tipos de pruebas.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda \(H_0:\mu_\delta\ge0\) \(H_a:\mu_\delta<0\) |
\(t_\text{c}\le−t_{\alpha(n-1)}\) |
\(P(t_{(n-1)} < t_\text{c})\) |
| Cola derecha \(H_0:\mu_\delta\le0\) \(H_a:\mu_\delta>0\) |
\(t_\text{c}\ge t_{\alpha(n-1)}\) |
\(P(t_{(n-1)} > t_\text{c})\) |
| Dos colas \(H_0:\mu_\delta=0\) \(H_a:\mu_\delta\ne0\) |
\(|t_\text{c}|\ge t_{\alpha/2(n-1)}\) |
\(2 \, P(t_{(n-1)} > |t_\text{c}|)\) |
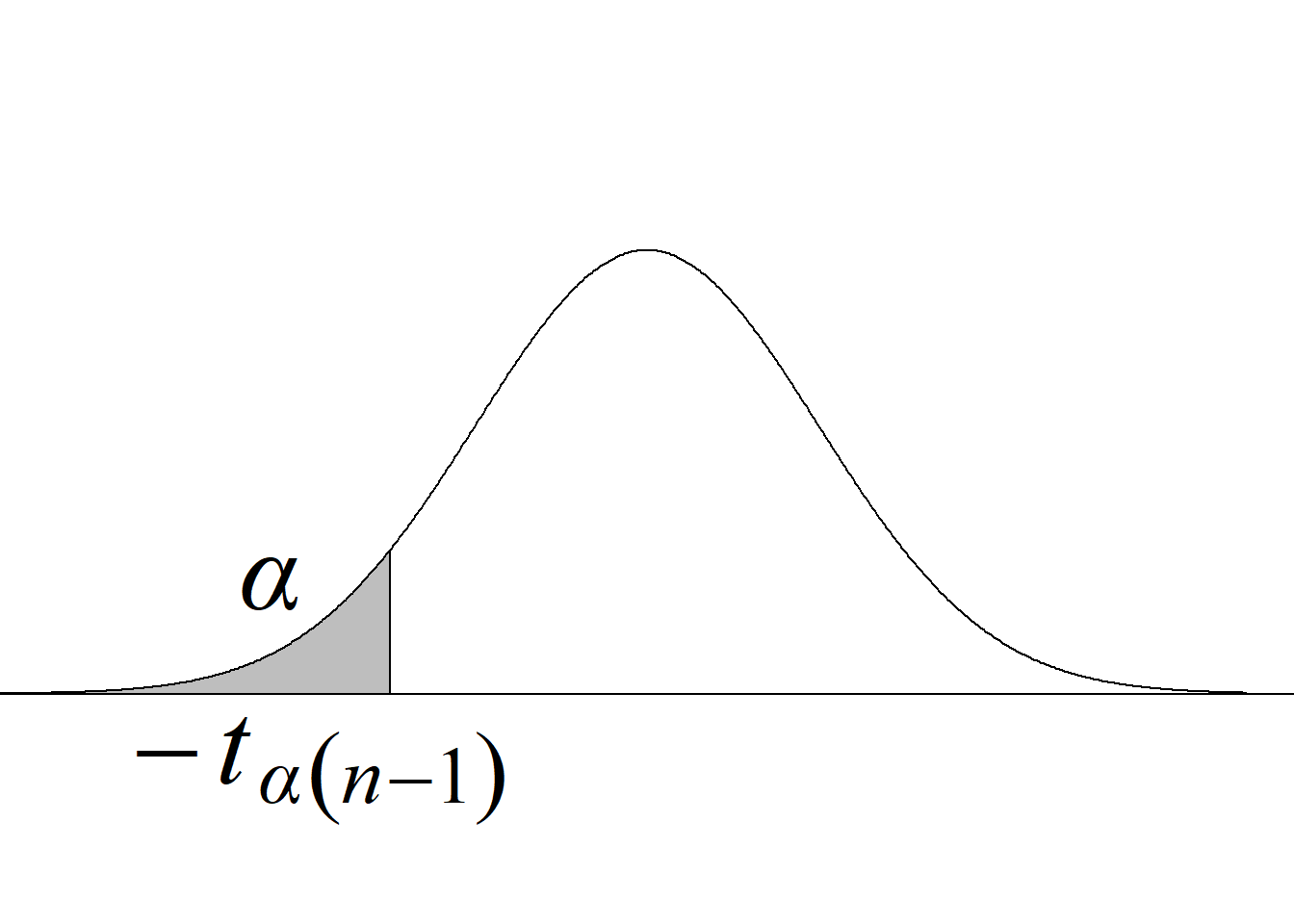
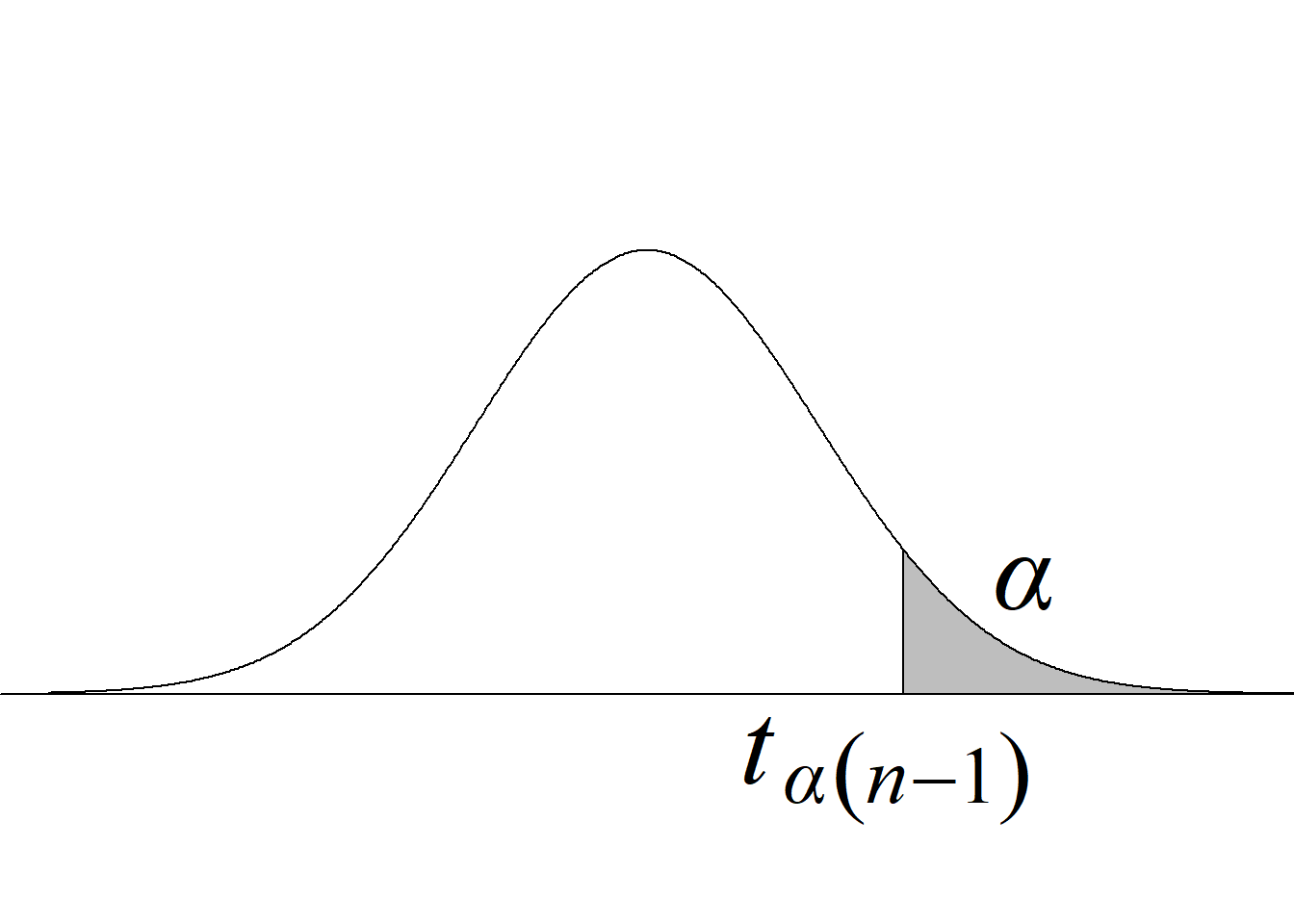
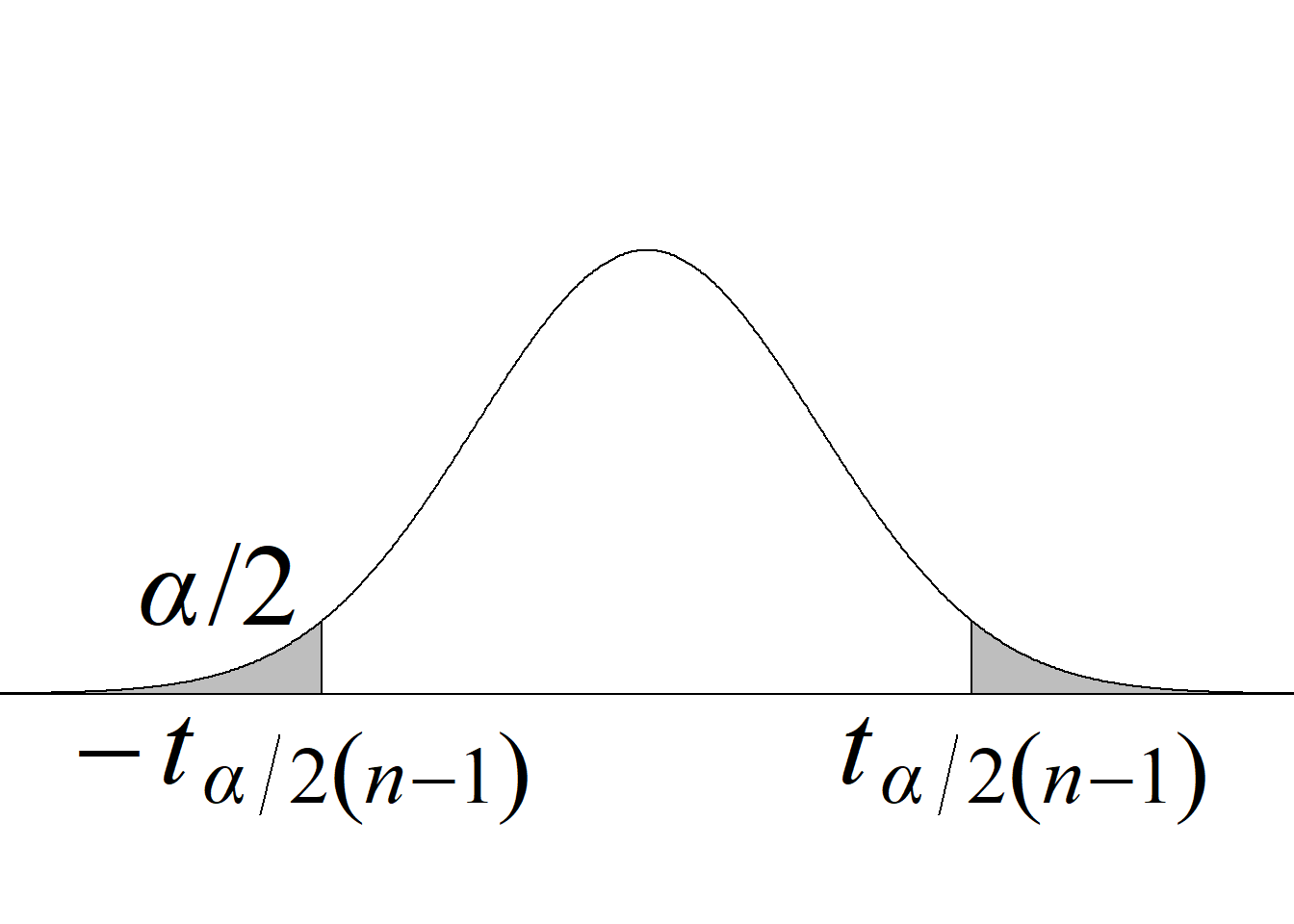
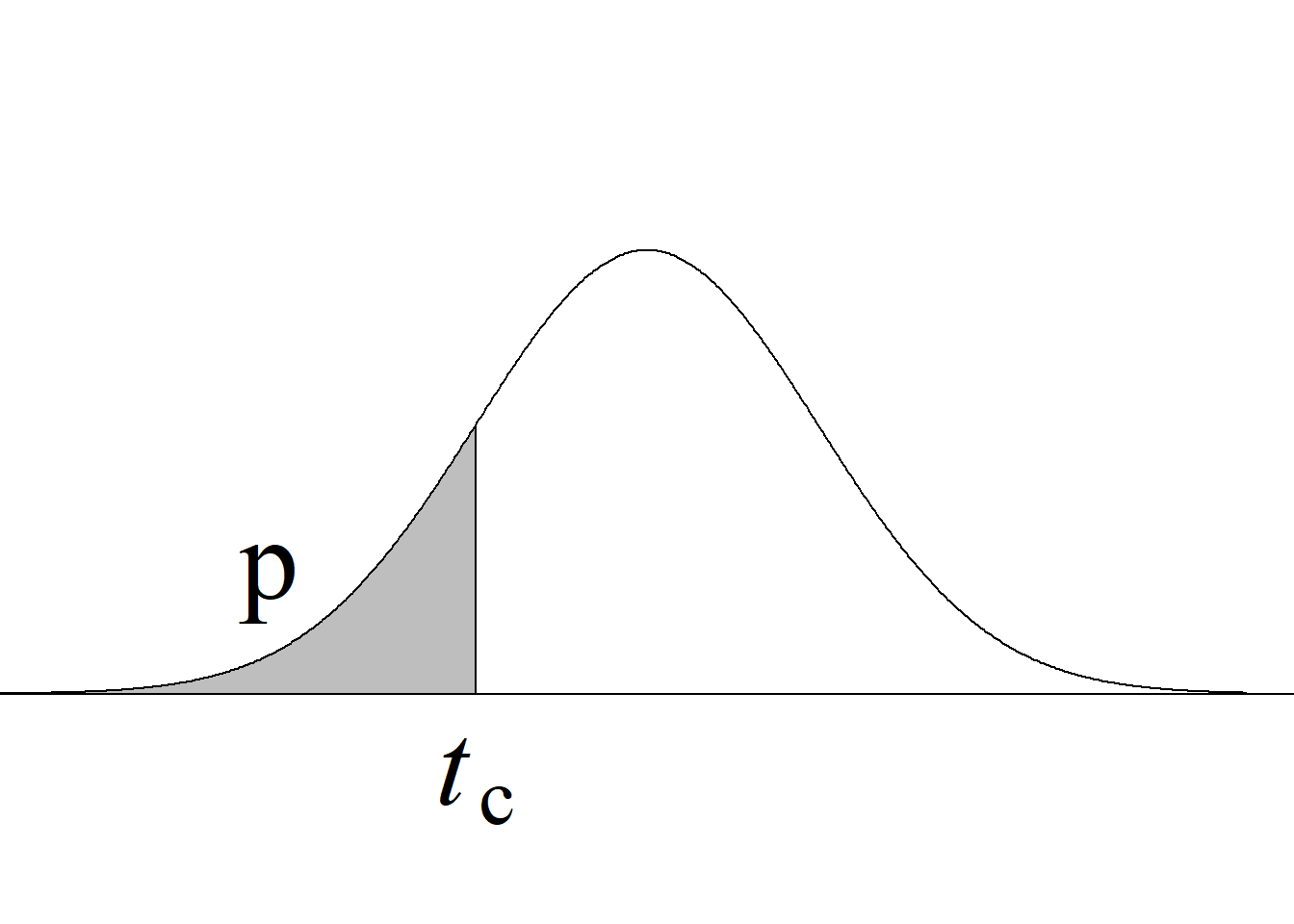
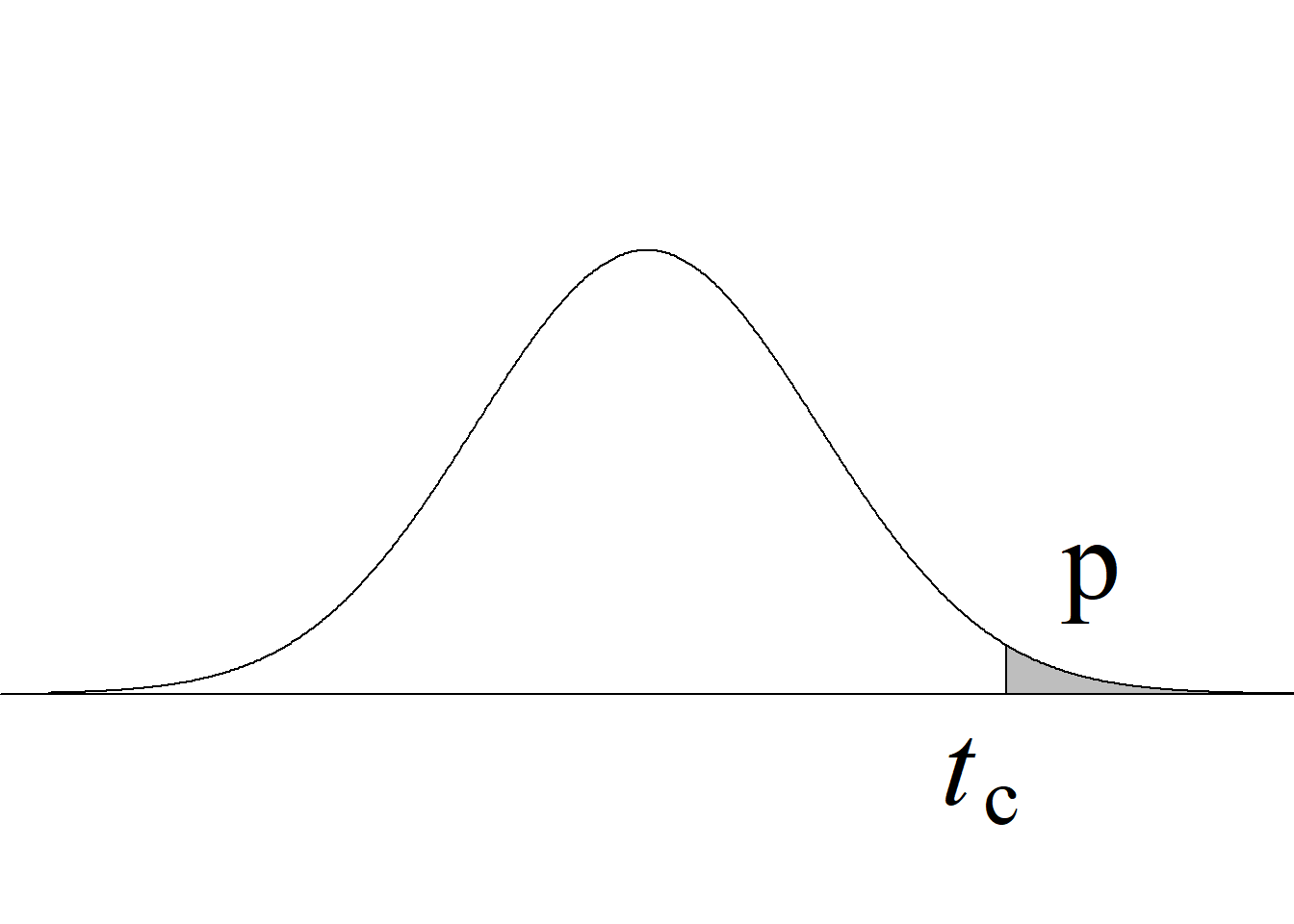
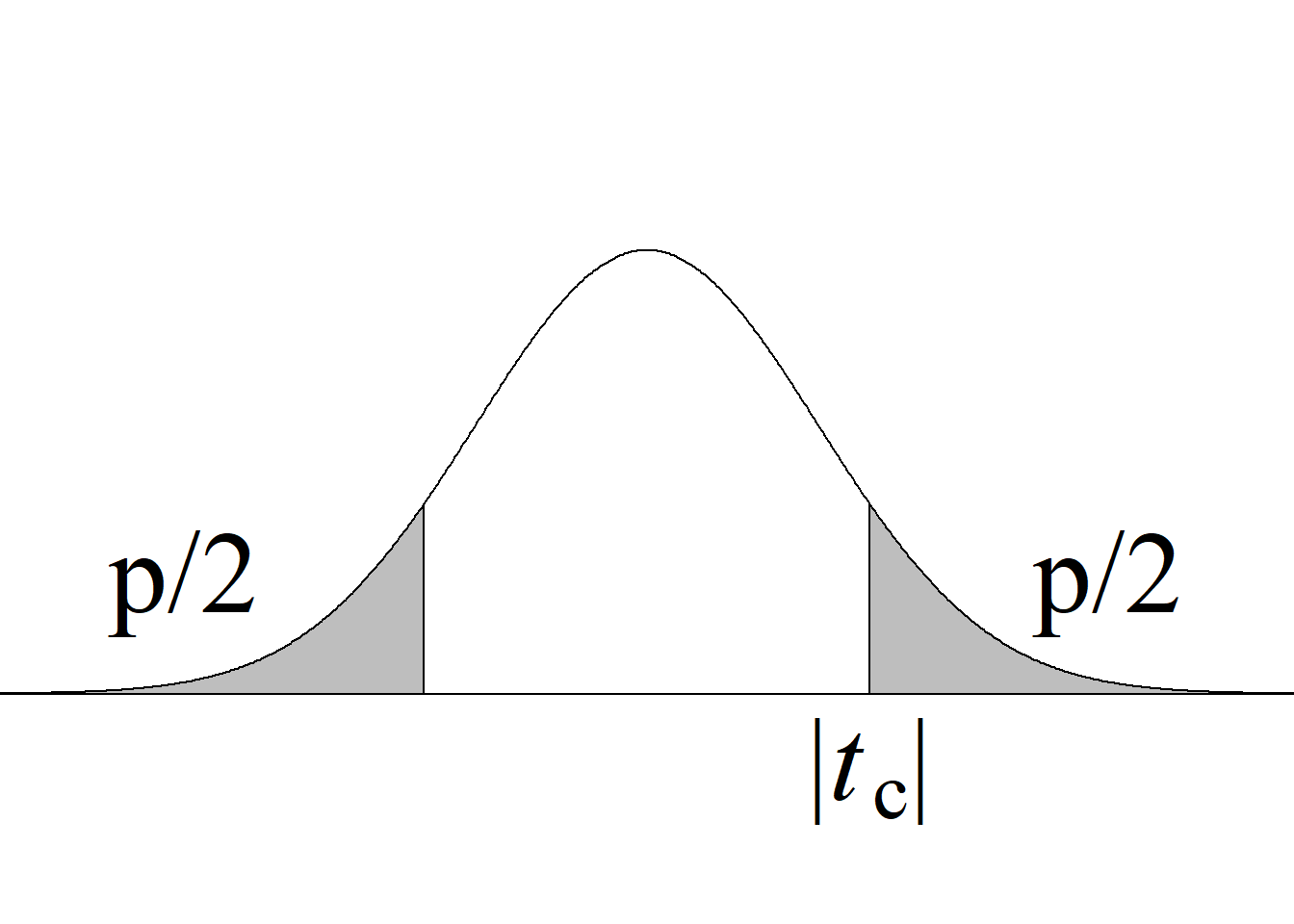
¡Es lo mismo!
Los criterios presentados en la tabla 5.7 y la figura 5.11 para la comparación de las medias de dos poblaciones normales usando muestras pareadas son iguales a los presentados en la tabla 4.1 y la figura 4.1 para contrastar un juego de hipótesis sobre la media, \(\mu,\) de una población normal (cf. sección 4.2.1).
Si bien se parte de dos muestras, al calcular las diferencias \(X_{1i}-X_{2i},\) se pasa a una muestra: la muestra de las diferencias \(\delta_i\,.\)
En el escenario de muestras pareadas, probar que \(\mu_1\ne\mu_2\) es equivalente a probar que \(\mu_\delta\ne0,\) por lo cual —al tratarse de la hipótesis sobre la media de una población normal— se resuelve mediante las herramientas presentadas en la sección 4.2.1.
Advertencia 5.4: ¡Atención a los supuestos!
Puesto que el proceso inferencial para comparar las medias de dos poblaciones normales usando muestras pareadas está basado en una única muestra (la muestra de las diferencias), no es aplicable ningún requerimiento sobre las varianzas poblacionales.
No obstante, sí debe satisfacerse que la distribución de las diferencias no se aleje significativamente de la distribución normal.
5.2.3.2 Intervalo de confianza para la diferencia de medias, usando muestras pareadas
Cuando se usan muestras pareadas, el juego de hipótesis para comparar dos medias puede escribirse equivalentemente en términos de la diferencia de las medias o en términos de la media de las diferencias.
\[
H_0:\mu_1=\mu_2\Leftrightarrow \mu_1-\mu_2=0 \Leftrightarrow \mu_\delta=0
\]
\[
H_a:\mu_1\ne\mu_2\Leftrightarrow \mu_1-\mu_2\ne0 \Leftrightarrow \mu_\delta\ne 0
\]
En consecuencia, un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_1-\mu_2\) es equivalente a un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_\delta.\)
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(\mu_\delta\) se obtiene con base en la siguiente expresión:
\[
\overline\delta\pm t_{\alpha/2(n-1)}\frac{S_\delta}{\sqrt{n}}
\tag{5.13}\]
¡Tenga presente el sentido de las diferencias!
Aunque la expresión 5.13 simplifica el cálculo del intervalo de confianza para la diferencia de dos medias, es esencial tener presente el sentido en el que estas se definen, a fin de interpretar el intervalo adecuadamente.
Ejemplo 5.4
En la industria alimentaria, los envases metálicos utilizados para la conservación de los productos deben contar con un recubrimiento interno que evite la migración de metales hacia los alimentos.
Un fabricante ha desarrollado un nuevo tipo de recubrimiento para latas de acero, mediante el cual se busca brindar una mayor protección contra la corrosión y evitar la contaminación por hierro. Se quiere diseñar un ensayo que permita determinar la posible contaminación con hierro en tomates enlatados.
Para ello no bastaría con evaluar el contenido de hierro en tomates enlatados, puesto que los tomates frescos también incorporan hierro, bien sea por haberlo absorbido durante su crecimiento o porque se acumula en su superficie por contaminación del suelo, de las aguas de riego y/o del aire. Por tanto, se hace necesario comparar el contenido medio de hierro de tomates enlatados con el contenido medio de hierro de tomates frescos.
Debe tenerse presente que el contenido medio de hierro en un lote particular de tomate depende de las condiciones anotadas anteriormente, las cuales pueden cambiar entre lotes. Luego, si se usaran muestras independientes, el efecto del recubrimiento podría quedar enmascarado por el efecto de los factores secundarios.
Bien podría suceder, por ejemplo, que —por azar— las muestras evaluadas en fresco proviniesen de lotes con altos niveles de contaminación, mientras que las que se someten al proceso de enlatado no hubieran estado expuestas a tales factores. Esto disminuiría la probabilidad de encontrar diferencias significativas en los contenidos medios de hierro o incluso podría dar lugar a diferencias en dirección contraria a la esperada.
Para controlar la variabilidad entre lotes, evitando que los factores secundarios actúen como factores de confusión, garantizando así que cualquier diferencia en los niveles de hierro se deba al proceso de enlatado, el ensayo se realiza con base en un esquema de muestras pareadas.
Se seleccionan 15 lotes de tomate fresco, cada uno de los cuales se divide en dos partes: una de estas, elegida al azar, se analiza en fresco para determinar su contenido de hierro; la otra es enlatada durante 30 días en los nuevos envases metálicos, tras lo cual se le mide su contenido de hierro.
La tabla 5.8 muestra los contenidos de hierro en mg/kg de este conjunto datos pareados.
| Lote | Fresco | Enlatado |
|---|---|---|
| 1 | 2.3 | 2.7 |
| 2 | 1.9 | 1.9 |
| 3 | 2.7 | 2.8 |
| 4 | 2.0 | 1.8 |
| 5 | 2.7 | 3.2 |
| 6 | 2.4 | 2.4 |
| 7 | 2.2 | 2.3 |
| 8 | 2.1 | 1.8 |
| 9 | 2.4 | 2.3 |
| 10 | 2.6 | 2.9 |
| 11 | 2.0 | 2.1 |
| 12 | 1.7 | 2.0 |
| 13 | 2.8 | 3.0 |
| 14 | 2.3 | 2.3 |
| 15 | 2.1 | 2.6 |
Para averiguar si el contenido medio de hierro en tomate difiere entre las condiciones evaluadas, se plantea el siguiente juego de hipótesis:
\[
H_0:\mu_\text{E}=\mu_\text{F}\Leftrightarrow \mu_\text{E}-\mu_\text{F}=0 \Leftrightarrow \mu_\delta=0
\] \[
H_a:\mu_\text{E}\ne\mu_\text{F}\Leftrightarrow \mu_\text{E}-\mu_\text{F}\ne0 \Leftrightarrow \mu_\delta\ne 0
\]
¿Dos colas?
Si bien es cierto que la pregunta esencial del ensayo es si la lata libera hierro —no esperándose que esta pudiera llegar a absorber el que estuviera presente en un producto fresco—, es necesario formular un juego de hipótesis que permita detectar el resultado inesperado, en caso de que se presente.
Esto se logra mediante un juego de hipótesis de dos colas, acorde con lo que se discute en la sección 5.6.
Puesto que el estadístico de prueba está basado en las diferencias \(\delta_i=\text{E}_i-\text{F}_i,\) se parte de su cálculo, tal y como se muestra en la última columna de la tabla 5.9.
| Lote | Fresco | Enlatado | \(\delta\) |
|---|---|---|---|
| 1 | 2.3 | 2.7 | 0.4 |
| 2 | 1.9 | 1.9 | 0 |
| 3 | 2.7 | 2.8 | 0.1 |
| 4 | 2.0 | 1.8 | -0.2 |
| 5 | 2.7 | 3.2 | 0.5 |
| 6 | 2.4 | 2.4 | 0 |
| 7 | 2.2 | 2.3 | 0.1 |
| 8 | 2.1 | 1.8 | -0.3 |
| 9 | 2.4 | 2.3 | -0.1 |
| 10 | 2.6 | 2.9 | 0.3 |
| 11 | 2.0 | 2.1 | 0.1 |
| 12 | 1.7 | 2.0 | 0.3 |
| 13 | 2.8 | 3.0 | 0.2 |
| 14 | 2.3 | 2.3 | 0 |
| 15 | 2.1 | 2.6 | 0.5 |
¿¡Y el orden!?
Las diferencias \(\delta_i\) se calculan acorde con el orden especificado en el juego de hipótesis14, de manera análoga a lo indicado en la precaución 5.1.
Sea cual sea el juego de hipótesis, las diferencias se calculan en un único sentido; nunca en valor absoluto.
¿Y cuál es el \(n\)?
Aunque, al procesar información de un ensayo basado en muestra pareadas, el usuario eventualmente podría dudar en lo concerniente a la definición del tamaño de muestra \(n,\) no sabiendo si este se refiere al tamaño conjunto de las dos muestras o al tamaño de una sola muestra, esto se resuelve fácilmente si se tiene en cuenta que la propuesta de contraste reduce el problema de dos muestras a un problema de una única muestra: la muestra de las diferencias.
Por ende, siempre que se comparan las medias de dos poblaciones normales, usando muestras pareadas, \(n\) se refiere al número de diferencias.
Todos los elementos requeridos para calcular el estadístico de prueba se obtienen del vector de diferencias: el número de diferencias, el promedio de las diferencias y la desviación estándar de las diferencias.
Para ilustración, obtenemos inicialmente el promedio y la desviación estándar de las 15 diferencias.
\[
\begin{align}
\overline\delta&=\frac{\sum\limits_{i=1}^{n}\delta_i}{n}=\frac{1.9}{15}=0.12667\\[2.4em]
S_\delta&=\sqrt{\frac{\sum\limits_{i=1}^{n}\delta_i^2-\frac{\left(\sum\limits_{i=1}^{n}\delta_i\right)^2}{n}}{n-1}}=
\sqrt{\frac{1.05-\frac{1.9^2}{15}}{14}}=0.24044
\end{align}
\]
A continuación, se calcula el estadístico de prueba (cf. expresión 5.12):
\[
t_\text{c}=\frac{\overline\delta}{S_\delta/\sqrt{n}}=
\frac{0.12667}{0.24044/\sqrt{15}}=2.0404
\]
Bajo la hipótesis nula, el estadístico de prueba seguiría una distribución \(t_{(14)}.\) El valor crítico para \(\alpha = 0.05\) se obtiene así:
qt(0.025, 14, lower.tail = FALSE)[1] 2.144787| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(|t_\text{c}|\) \(2.0404\) |
\(<\) \(<\) |
\(t_{0.025(14)}\) \(2.1448\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no se rechaza \(H_0\) con \(α = 0.05\) |
No puede afirmarse, con una probabilidad máxima de error de 0.05, que el contenido medio de hierro difiera entre tomates frescos y tomates enlatados.
El valor p se obtiene como la probabilidad de obtener —bajo la hipótesis nula— un valor igual o más extremo que el del estadístico de prueba (cf. tabla 5.7 y figura 5.11 (f)):
2 * pt(2.0404, 14, lower.tail = FALSE)[1] 0.06063856| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.061\) |
\(>\) \(>\) |
\(\alpha\) \(0.05\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no se rechaza \(H_0\) |
Dado que el \(\text{p}=0.061\), no se rechaza la hipótesis nula, no pudiendo concluirse que el contenido medio de hierro difiera entre tomate fresco y enlatado.
Un intervalo de confianza del 95 % para la diferencia \(\mu_\delta=\mu_\text{E}-\mu_\text{F},\) se calcula a partir de la expresión 5.13:
\[
\overline\delta\pm t_{\alpha/2(n-1)}\frac{S_\delta}{\sqrt{n}}=
0.12667\pm 2.1448\frac{0.24044}{\sqrt{15}}=
0.12667\pm 0.13315
\]
\[
\text{IC}_{\mu_\text{E}-\mu_\text{F}}:\quad[-0.00648,\;0.25982]
\]
Puesto que el intervalo de confianza contiene el cero, no puede afirmarse con una confianza del 95 % que el contenido medio de hierro en tomate enlatado difiera del contenido medio de hierro en tomate fresco.
5.2.3.3 Uso de R para comparar medias de dos poblaciones normales, usando muestras pareadas
A continuación se presenta el script en R para realizar los procedimientos del ejemplo 5.4:
La primera línea importa la información de la tabla 5.8, la cual está contenida en el archivo ejemplo 5.4.xlsx.
La línea 2 realiza la prueba de Shapiro-Wilk para evaluar la normalidad del vector diferencia (cf. advertencia 5.4). Este es el resultado de su ejecución:
Shapiro-Wilk normality test
data: enlatados - frescos
W = 0.96282, p-value = 0.7412Puesto que \(\text{p}=0.7412\), no se detectan desviaciones severas del supuesto de normalidad para el vector diferencia.
Para la parte central del contraste se utiliza la función t.test{stats} (línea 3). Entre los argumentos que esta función trae por defecto está que las muestras son independientes (paired = FALSE). Siempre que se tenga un esquema de muestras pareadas, como en el presente ejemplo, es necesario indicarlo explícitamente (paired = TRUE). Se obtiene el siguiente resultado:
Paired t-test
data: enlatados and frescos
t = 2.0404, df = 14, p-value = 0.06064
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-0.006482414 0.259815747
sample estimates:
mean difference
0.1266667
¡Es lo mismo!
Es fácil verificar que los resultados que se obtienen al usar muestras pareadas coinciden con los de inferir sobre la media de la diferencias.
Para ello basta con aplicar la prueba \(t\) sobre el vector diferencia:
data <- readxl::read_excel("ejemplo 5.4.xlsx")
data$diferencia <- data$enlatados - data$frescos
with(data, t.test(diferencia, mu = 0))
One Sample t-test
data: diferencia
t = 2.0404, df = 14, p-value = 0.06064
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.006482414 0.259815747
sample estimates:
mean of x
0.1266667 5.2.4 La función t.test en R
Para todo lo concerniente a la inferencia sobre una o dos medias de poblaciones normales se usa en R la misma función: t.test{stats}. Y es que, más allá de las variantes que estas pruebas puedan presentar, todas ellas están basadas en un estadístico de prueba que, bajo la hipótesis nula, sigue una distribución \(t\) de Student. Por tanto, todas ellas son pruebas de \(t.\)
La función t.test debe incluir un primer argumento obligatorio x, mediante el que se indica cuál es el vector numérico que contiene la información muestral. Este argumento podría ser suficiente para contrastar, mediante una prueba de dos colas, si la media de la población de la cual se obtuvo la muestra es cero.
Para comparar las medias de dos poblaciones, se requiere un segundo argumento, y, mediante el que se indique cuál es el vector numérico que contiene la información de la segunda muestra, tal y como se ha ilustrado en los ejemplos 5.2, 5.3 y 5.4.
En tales casos también podría usarse una fórmula tipo respuesta ~ grupo, si se tuviera la información de las dos muestras en un único vector, denominado respuesta, señalando la membresía de cada observación a una de las dos muestras, mediante un vector indicador grupo, constituido por dos niveles.
Todos los demás argumentos de la función son optativos, es decir que traen un valor por defecto que bien podría dejarse como tal si satisficiera las necesidades del usuario o podría modificarse.
Así, el argumento alternative especifica el tipo de prueba. Los posibles valores que este argumento puede tomar son two.sided (o simplemente t), para pruebas de dos colas, siendo este el valor por defecto de este argumento; less (o l), para pruebas de cola izquierda, y greater (o g), para pruebas de cola derecha.
El argumento var.equal permite especificar cómo se consideran las varianzas poblacionales cuando se comparan medias usando muestras independientes. El valor por defecto de este argumento es FALSE, que indica que las varianzas no se consideran iguales (varianzas heterogéneas); en tal caso, se realiza la prueba de Welch, ilustrada en la sección 5.2.2. El usuario también puede especificar el valor TRUE si sabe que las varianzas son homogéneas, en cuyo caso se realiza la prueba de \(t\) que se ilustró en la sección 5.2.1.
Cuando se comparan las medias de dos poblaciones, la función asume por defecto que se usan muestras independientes, lo cual viene especificado a través del argumento paired = FALSE. Para especificar que se usan muestras pareadas, se usa el valor TRUE en dicho argumento.
En todos los casos, la función t.test calcula por defecto un intervalo de confianza del 95 % para la media o para la diferencia de medias. Si se desea obtener un intervalo con una confianza diferente, puede especificarse a través del argumento conf.level, mediante el cual se expresa la confianza como una probabilidad entre 0 y 1.
¡Cuidado con el argumento
mu cuando compare dos poblaciones!
La interpretación del argumento mu es inmediata cuando se usa en pruebas de hipótesis para una población; no así cuando se comparan dos medias.
En pruebas de hipótesis sobre la media de una población normal, el argumento mu representa el valor de referencia contra el cual se compara la media, es decir, \(\mu_0.\)
Así, en el ejemplo 4.2, donde se buscaba contrastar el juego de hipótesis \(H_0: \mu=750\;\text{vs.}\;H_a: \mu\ne750,\) se usó mu = 750.
Cuando se comparan dos medias, el argumento mu representa la hipotética diferencia entre las dos medias. Su valor por defecto es cero, lo cual se corresponde con las pruebas de hipótesis usuales, tales como las presentadas en los ejemplos 5.2, 5.3 y 5.4.
En el ejemplo 5.2 se tenía el siguiente juego de hipótesis:
\[
H_0: \mu_{\text{pH}7.0}=\mu_{\text{pH}8.0} \Rightarrow \mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}=\textcolor{red}{0}
\] \[
H_a: \mu_{\text{pH}7.0}\ne\mu_{\text{pH}8.0}\Rightarrow \mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}\ne\textcolor{red}{0}
\]
En el ejemplo 5.3 se contrastó el siguiente juego de hipótesis:
\[ H_0: \mu_{\text{bh-T}}\le \mu_{\text{bh-PM}}\Rightarrow \mu_{\text{bh-T}}-\mu_{\text{bh-PM}}\le \textcolor{red}{0} \]
\[
H_a: \mu_{\text{bh-T}} > \mu_{\text{bh-PM}}\Rightarrow \mu_{\text{bh-T}}-\mu_{\text{bh-PM}}> \textcolor{red}{0}
\]
En el ejemplo 5.4 se usó el siguiente juego de hipótesis:
\[ H_0:\mu_\text{E}=\mu_\text{F}\Leftrightarrow \mu_\text{E}-\mu_\text{F}=0 \Leftrightarrow \mu_\delta=\textcolor{red}{0} \]
\[
H_a:\mu_e\ne\mu_f\Leftrightarrow \mu_e-\mu_f\ne0 \Leftrightarrow \mu_\delta\ne \textcolor{red}{0}
\]
En todos estos ejemplos, sin importar que se estuvieran contrastando pruebas de una o de dos colas, se usó el valor por defecto (mu = 0), lo que equivale a comparar las dos medias.
Supóngase ahora que, en el escenario planteado para el ejemplo 5.3, se hubiera deseado probar que el síndrome medio en las colonias ubicadas en bosque húmedo tropical (bh-T) superaba en 0.2 el síndrome medio en las colonias ubicadas en bosque húmedo premontano (bh-PM).
Para ello, se habría planteado el siguiente juego de hipótesis:
\[
H_0: \mu_{\text{bh-T}}-\mu_{\text{bh-PM}}\le \textcolor{red}{0.2}
\]
\[
H_a: \mu_{\text{bh-T}}-\mu_{\text{bh-PM}}> \textcolor{red}{0.2}
\]
Y se habría usado la siguiente instrucción en R:
with(data, t.test(bh.T, bh.PM, alternative = "greater", mu = 0.2))En un escenario como este —de prueba de hipótesis de una cola— el uso del argumento mu es correcto y perfectamente interpretable.
El problema interpretativo surge si se cambia el valor por defecto del argumento mu en una prueba de dos colas para comparar dos medias, tal y como se ilustra a continuación.
Considérese la asignación de un valor diferente de 0 para mu en el escenario del ejemplo 5.2:
with(data, t.test(pH7.0, pH8.0, var.equal = TRUE, mu = 1))Esta instrucción contrasta el siguiente juego de hipótesis:
\[
H_0: \mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}=\textcolor{red}{1}
\]
\[
H_a: \mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}\ne\textcolor{red}{1}
\]
Este juego de hipótesis permitiría evaluar si la diferencia entre la producción media de PHA cuando se trabaja a pH = 7.0 y la producción media de PHA cuando se trabaja a pH = 8.0 —en ese orden15— es exactamente 1. Este juego de hipótesis difícilmente se asociaría con una pregunta de investigación relevante.
Es cierto que un investigador podría querer averiguar si una de las condiciones de pH, por ejemplo 7.0, genera producciones medias de PHA que superen a las obtenidas bajo la otra condición de pH en al menos 1 unidad. La respuesta a esta pregunta se plantearía, sin embargo, a través de un juego de hipótesis de una cola:
\[
H_0: \mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}\le\textcolor{red}{1}
\]
\[
H_a: \mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}>\textcolor{red}{1}
\]
with(data, t.test(pH7.0, pH8.0, alternative = "g", var.equal = TRUE, mu = 1))También es cierto que el usuario podría querer averiguar si la producción media de PHA difiere en al menos 1 unidad entre las dos condiciones de pH, lo que se plantearía mediante el siguiente juego de hipótesis:
\[
H_0: |\mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}|\le\textcolor{red}{1}
\]
\[
H_a: |\mu_{\text{pH}7.0}-\mu_{\text{pH}8.0}|>\textcolor{red}{1}
\]
¡Y tampoco es esto lo que se responde mediante la instrucción discutida!
5.2.5 Prueba de equivalencia
El juego de hipótesis para comparar las medias de dos poblaciones normales se expresa así:
\[
H_0:\mu_1=\mu_2
\] \[
H_a:\mu_1\ne\mu_2
\]
El rechazo de la hipótesis nula permite probar, con probabilidad máxima de error \(\alpha,\) que las medias comparadas difieren.
No obstante, si la información muestral no permite rechazar la hipótesis nula, todo lo que puede decirse es que no hay elementos para probar la diferencia de medias, pero en ningún caso puede tomarse el no rechazo de la hipótesis nula como una prueba de que las medias sean iguales (cf. sección 3.9.2.1).
En ocasiones, la meta del investigador es probar que no existen diferencias entre las medias. Tal es el caso en estudios en los que se propone un sustituto más económico para un producto, pero “garantizando” que el resultado no diferirá del esperado para el producto estándar.
Un caso paradigmático surge en los estudios de bioequivalencia, donde se quiere asegurar, por ejemplo, que un medicamento genérico tiene efectos similares a los del medicamento de referencia.
¡Ni se le ocurra!
Puesto que la única manera de probar estadísticamente una hipótesis es concluyendo en favor de la alternativa, mediante el rechazo de \(H_0,\) el usuario podría verse tentado a reescribir el juego de hipótesis así:
\[
H_0:\mu_1\ne\mu_2
\]
\[
H_a:\mu_1=\mu_2
\]
Sin embargo, no existe ninguna metodología estadística que permita contrastar un juego de hipótesis en el que la hipótesis nula se plantee como diferencia de medias y la alternativa como igualdad.
La hipótesis nula siempre tiene que incluir la igualdad, pues es a partir de esta que se calcula la máxima probabilidad de cometer error tipo I (cf. tip 3.4).
Aunque en sentido estricto no es posible probar que dos medias sean iguales, sí es posible probar que su diferencia no excede una pequeña cantidad \(\delta\) definida por el usuario. Esto puede expresarse mediante el siguiente juego de hipótesis:
\[
H_0:|\mu_1-\mu_2|\ge\delta
\]
\[
H_a:|\mu_1-\mu_2|<\delta
\]
El valor absoluto de este juego de hipótesis se usa para indicar la inadmisibilidad de diferencias mayores o iguales que \(\delta\) en cualquier sentido.
Para probar el anterior juego de hipótesis, es necesario probar que ninguna de las medias supera a la otra en una cantidad mayor o igual que \(\delta.\)
Esto puede visualizarse despejando el valor absoluto de la hipótesis alternativa:
\[
H_a:-\delta< \mu_1-\mu_2<\delta
\]
Para probar que se satisface la condición establecida mediante la hipótesis alternativa, es necesario probar, por una parte, que:
\[
-\delta<\mu_1-\mu_2\quad\Rightarrow\quad \mu_2-\mu_1<\delta
\]
Y, por otra parte, que:
\[
\mu_1-\mu_2<\delta
\]
Esto implica probar dos juegos de hipótesis:
| \(H_0: \mu_2-\mu_1\ge\delta\) \(H_a: \mu_2-\mu_1<\delta\) |
\(H_0: \mu_1-\mu_2\ge\delta\) \(H_a: \mu_1-\mu_2<\delta\) |
TOST
Para probar que \(|\mu_1-\mu_2|<\delta\) es necesario realizar dos pruebas de una cola:
| \(H_0: \mu_2-\mu_1\ge\delta\) \(H_a: \mu_2-\mu_1<\delta\) |
\(H_0: \mu_1-\mu_2\ge\delta\) \(H_a: \mu_1-\mu_2<\delta\) |
Consecuentemente, a esta metodología se le denomina TOST, por sus iniciales en inglés: Two one-sided tests.
La visualización del problema de contrastar los dos juegos de hipótesis de una cola se facilita, enfocándolo a partir de los correspondientes intervalos de confianza unilaterales.
Puesto que los juegos de hipótesis que surgen de esta metodología son de cola izquierda, se les asocian intervalos de confianza unilaterales de límite superior. Los juegos de hipótesis planteados se rechazan si y solo si los intervalos no contienen el valor \(\delta,\) es decir, si los límites superiores de ambos intervalos son menores que \(\delta.\)
¡Tienen que satisfacerse las dos condiciones!
Cuando se utiliza la metodología TOST para probar equivalencia, es necesario que se satisfagan simultáneamente las 2 condiciones evaluadas.
Si el análisis se realiza mediante la evaluación de dos pruebas de hipótesis de una cola, se requiere que ambas sean significativas.
Si en su lugar se usan los correspondientes intervalos de confianza, se requiere que los límites superiores de ambos intervalos sean menores que \(\delta.\)
Aunque la conceptualización de la condición de equivalencia a partir de dos juegos de hipótesis sugiere que sería necesario resolver dos juegos de hipótesis o calcular dos límites de confianza unilaterales, en la práctica es posible obtener los resultados a partir de un único intervalo de confianza.
Para entender la lógica subyacente, deben considerarse los siguientes aspectos, cuya esquematización se presenta en la figura 5.12:
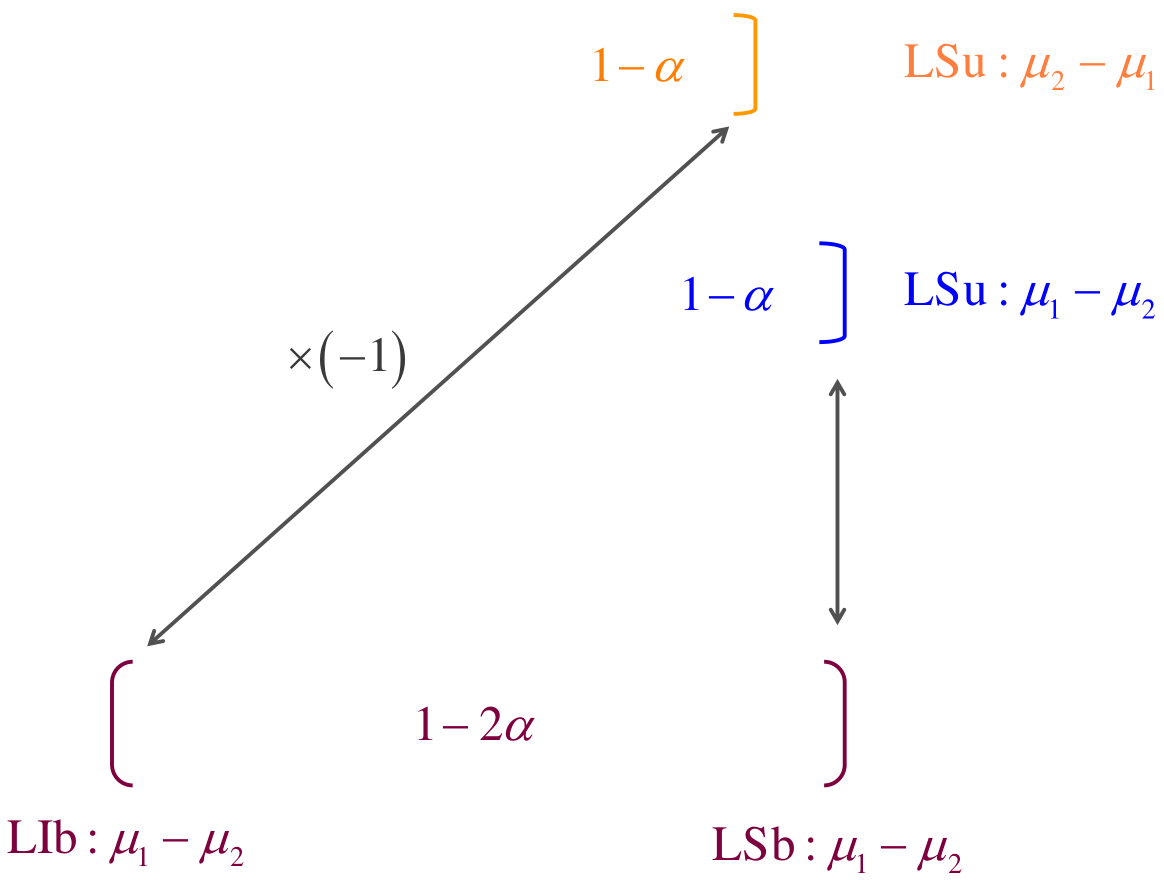
En virtud de estas relaciones, la información de los límites superiores unilaterales para las diferencias de medias puede extraerse de un intervalo de confianza bilateral \(100(1−2\alpha)\,\%\) para \(\mu_1 − \mu_2\) (o para \(\mu_2 − \mu_1\)).
Y, teniendo en cuenta que los dos juegos de hipótesis que estructuran la metodología TOST únicamente se rechazan cuando los límites superiores de sus correspondientes intervalos son menores que \(\delta,\) esto es equivalente a exigir que el valor absoluto de los dos límites del intervalo de confianza bilateral \(100(1−2\alpha)\,\%\) para \(\mu_1 − \mu_2\) sea menor que \(\delta.\)
En resumen…
Si \(\text{LIb}\) y \(\text{LSb}\) representan los correspondientes límites inferior y superior de un intervalo de confianza bilateral \(100(1−2\alpha)\,\%\) para \(\mu_1 − \mu_2,\) es posible declarar equivalencia entre las medias siempre que \(\text{|LIb|}<\delta\) y \(\text{|LSb|}<\delta.\)
En principio, el valor \(\delta\) habría de definirlo el investigador, pues es quien cuenta con el criterio para establecer la máxima diferencia admisible entre dos medias para considerarlas equivalentes.
No obstante, en ocasiones no se tiene un criterio claro para su definición o simplemente se desea formular una pregunta más amplia, en lugar de una específica para un \(\delta\) puntual: ¿Cuál es el valor mínimo de \(\delta\) para el cual podría declararse equivalencia con un nivel de significancia dado?
Teniendo en cuenta los desarrollos presentados anteriormente, es fácil responder esta pregunta.
Puesto que, para declarar equivalencia con un nivel de significancia \(\alpha\) se requiere que \(\text{|LIb|}<\delta\) y \(\text{|LSb|}<\delta,\) el delta mínimo será el máximo entre \(\text{|LIb|}\) y \(\text{|LSb|}.\)
Es necesario tener presente que el \(\delta_{\text{crítico}}\) no debe interpretarse como un umbral científicamente relevante, sino como una referencia inferencial condicionada por los datos.
Ejemplo 5.5
En búsqueda de una fuente energética de bajo costo para alimentación de bovinos se evalúa la glicerina como posible sustituto de la melaza.
Para esta evaluación, se cuenta con un grupo de 12 animales con condiciones fisiológicas comparables. Se suministra melaza a 6 de estos, elegidos al azar, y glicerina a los otros 6. La tabla 5.10 presenta los datos de energía metabolizable en cada uno de los dos grupos.
| melaza | 8.7 | 7.6 | 8.8 | 8.5 | 7.9 | 8.3 |
| glicerina | 6.8 | 8.5 | 8.0 | 8.3 | 7.5 | 7.7 |
Consideremos inicialmente el juego de hipótesis clásico:
\[
H_0:\mu_\text{M}=\mu_\text{G}
\] \[
H_a:\mu_\text{M}\ne\mu_\text{G}
\]
Puesto que el contraste de este juego de hipótesis se realiza mediante el procedimiento de Welch (cf. sección 5.2.2), el cual se expuso en detalle en el ejemplo 5.3, prescindimos de la ilustración por pasos y realizamos la prueba directamente en R.
Inicialmente importamos la información de la tabla 5.10, la cual se ha organizado en el archivo ejemplo 5.5.xlsx, y procedemos a evaluar normalidad en cada una de las dos muestras.
data <- readxl::read_excel("ejemplo 5.5.xlsx")
shapiro.test(data$melaza)
Shapiro-Wilk normality test
data: data$melaza
W = 0.93433, p-value = 0.6139shapiro.test(data$glicerina)
Shapiro-Wilk normality test
data: data$glicerina
W = 0.96096, p-value = 0.8271Puesto que no se detectan desviaciones severas del supuesto de normalidad en ninguna de las dos muestras, procedemos a contrastar el juego de hipótesis planteado.
with(data, t.test(melaza, glicerina))
Welch Two Sample t-test
data: melaza and glicerina
t = 1.5864, df = 9.3588, p-value = 0.1458
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.2088231 1.2088231
sample estimates:
mean of x mean of y
8.3 7.8 Dado que el \(\text{p}=0.1458\), no puede afirmarse con baja probabilidad de error que exista diferencia en la energía metabolizable media de las dos poblaciones comparadas.
¡Todavía no son equivalentes!
Un usuario incauto podría sentirse muy satisfecho con este resultado, dándolo por suficiente y viéndose tentado a declarar estas dos fuentes de energía como equivalentes.
Debe tenerse presente, sin embargo, que el no rechazo de la hipótesis nula no tiene carácter de prueba, no pudiendo interpretarse que las medias sean iguales o equivalentes (cf. sección 3.9.2.1).
Supóngase que se desea probar equivalencia con \(\delta = 1\) y con \(\alpha = 0.05.\)
Acorde con lo indicado anteriormente, se obtiene un intervalo de confianza bilateral al 90 % para la diferencia16:
with(data, t.test(melaza, glicerina, conf.level = 0.9))
Welch Two Sample t-test
data: melaza and glicerina
t = 1.5864, df = 9.3588, p-value = 0.1458
alternative hypothesis: true difference in means is not equal to 0
90 percent confidence interval:
-0.07523393 1.07523393
sample estimates:
mean of x mean of y
8.3 7.8 Puesto que el valor absoluto del límite superior del intervalo es mayor que \(\delta,\) no es posible declarar equivalencia al 5 % para \(\delta = 1.\)
¿¡Y si se hubieran contrastado las 2 pruebas de 1 cola!?
Si se hubieran realizado las 2 pruebas de 1 cola, el resultado habría sido el mismo. ¡Compruébelo!
La comprobación puede enfocarse en las pruebas de hipótesis: habrá que verificar que el valor p sea menor que 0.05 para ambas pruebas.
with(data, t.test(melaza, glicerina, mu = 1, alternative = "l"))
with(data, t.test(glicerina, melaza, mu = 1, alternative = "l"))También podría enfocarse en los intervalos de confianza. En esta caso, habrá que verificar que el valor absoluto de ambos límites sea menor que 1.
with(data, t.test(melaza, glicerina, alternative = "l"))
with(data, t.test(glicerina, melaza, alternative = "l"))¡Recuerde que al aplicar la metodología TOST es necesario verificar la satisfacción de las 2 condiciones evaluadas!
Dado que no fue posible declarar equivalencia para \(\delta = 1,\) ¿será posible declararla para un \(\delta\) mayor?
La respuesta a este tipo de preguntas es afirmativa. Siempre es posible declarar equivalencia entre dos medias si se elige un \(\delta\) suficientemente grande.
Tal y como se indicó anteriormente, el \(\delta\) crítico, es decir, el mínimo \(\delta\) que permitiría declarar equivalencia entre las medias se obtiene como el máximo de los valores absolutos de los límites del intervalo de confianza bilateral \(100(1−2\alpha)\,\%\) para la diferencia de medias.
Luego, para el presente ejemplo:
\[
\delta_{\text{crítico}}=\text{máx}(|-0.0752|,\;|1.0752|)=1.0752
\]
En tal sentido, si un valor de 1.0752 o mayor satisficiera el criterio de equivalencia establecido por el investigador, sí podrían declararse que los dos productos son equivalentes, con un nivel de significancia \(\alpha=0.05.\)
Vale la pena insistir, sin embargo, en el hecho de que este valor no debe utilizarse para redefinir a posteriori un criterio de relevancia práctica.
Los anteriores resultados pueden obtenerse de manera expedita usando la función personalizada equiv:
source("equiv.R")
equiv("melaza", "glicerina")
Se tiene una confianza del 95 % en que la diferencia entre
las medias poblacionales es menor o igual que 1.0752
¡Cuéntame más sobre
equiv!
La función equiv se usa así:
equiv(x = 1, y = 2, conf.level = 0.95, data = NULL)
En adición a los argumentos x y y, que representan las dos muestras (la función busca por defecto en las dos primeras columnas del data frame), es posible especificar la confianza, mediante el argumento conf.level, el cual toma por defecto el valor 0.95.
Mediante el cuarto argumento se especifica el nombre del data frame que contiene la información de las dos muestras. Por defecto, se busca un data frame llamado data en el ambiente de trabajo.
La función equiv es bastante versátil en la identificación de las muestras: pueden especificarse con sus nombre entre comillas, con sus nombres sin entrecomillar, o mediante los número de las columnas del data frame contenedor. Las siguientes 3 invocaciones de la función equiv son equivalentes y generan el mismo resultado:
Para el ejemplo 5.5, en el que la información de las muestras se encuentra en las dos primeras columnas del data frame data y que se desea un intervalo del 95 %, puede invocarse la función sin ningún argumento, con lo cual se usan todos los valores por defecto:
equiv()
¿¡Y qué hay de la potencia!?
La conceptualización de la potencia puede resultar engañosa cuando se evalúa equivalencia entre dos productos.
En principio podría pensarse que, dado que lo que se desea es que no haya diferencias, resultaría más conveniente trabajar con muestras pequeñas y que, por el contrario, los tamaños de muestra grandes incrementarían la potencia de la prueba, haciendo más probable encontrar diferencias significativas (cf. nota 3.2).
Y aunque esto sería cierto para la elaboración clásica que se presentó al inicio de esta sección \(\left(H_0:\mu_1=\mu_2 \text{ vs. } H_a:\mu_1\ne\mu_2\right),\) no lo es para la reelaboración TOST basada en dos pruebas de una cola.
Puesto que la estrategia TOST se basa en declarar equivalencia entre dos medias únicamente si se rechazan las dos pruebas de una cola, la potencia o capacidad de rechazo se relaciona directamente con el tamaño de las muestras.
Para ilustrar este hecho, se han construido muestras ampliadas de tamaño 12 para el ejemplo 5.5, manteniendo las medias y las desviaciones estándar de las muestras originales17. Esta información se ha organizado en la segunda hoja (muestra ampliadas) del archivo ejemplo 5.5.xlsx. A continuación se ilustra la evaluación de equivalencia.
data <- readxl::read_excel("ejemplo 5.5.xlsx", sheet = 2)
source("equiv.R")
equiv()
Se tiene una confianza del 95 % en que la diferencia entre
las medias poblacionales es menor o igual que 0.8841Se observa que al aumentar los tamaños de muestra se incrementa la potencia de la prueba de equivalencia, es decir, la probabilidad de afirmar con un nivel de significancia dado que el valor absoluto de la diferencia entre dos medias poblacionales es menor que \(\delta.\)
5.3 Comparación de dos proporciones binomiales
La comparación de dos proporciones binomiales puede realizarse a partir de muestras independientes o de muestras pareadas, de manera análoga a las estrategias de comparación de medidas de dos poblaciones normales (cf. secciones 5.2.2 y 5.2.3).
No obstante, el uso de muestras pareada no es tan frecuente en la comparación de proporciones binomiales como lo es en la comparación de medias. Tanto es así que, cuando se exponen los métodos para comparar proporciones binomiales, suele quedar tácito que se usan muestras independientes, sin indicarlo explícitamente y sin hacer mención alguna al escenario en el que se usan muestras pareadas.
En este texto se diferencian claramente estos dos escenarios y se dedica una sección al análisis detallado de cada uno de ellos.
5.3.1 Comparación de dos proporciones binomiales usando muestras independientes
Las pruebas de hipótesis y los intervalos de confianza se encuentran estrechamente asociados en el núcleo de muchos métodos inferenciales, siendo posible obtener los intervalos de confianza mediante la inversión de la región de aceptación de la prueba de hipótesis (cf. sección 4.2.2). No obstante, hay situaciones en las que esto no es así.
En algunos casos se aplican correcciones sobre los intervalos de confianza clásicos, las cuales, aunque pueden mejorar el desempeño de los intervalos de confianza, hacen que se pierda la relación con la prueba de hipótesis original.
En otros casos, los intervalos de confianza se construyen a partir de procesos independientes que nunca han estado formalmente asociados con una prueba de hipótesis.
Este hecho, sin embargo, no debe ser motivo de preocupación, puesto que, tal y como lo indican Correa y Sierra (2003), el uso de los intervalos de confianza se privilegia cada vez más frente a las pruebas de hipótesis, debido a que el intervalo aporta información tanto sobre la magnitud del efecto, como sobre la precisión de la estimación.
Esta priorización —particularmente notoria en disciplinas como la medicina y la epidemiología— coincide con la recomendación de apoyarse en los intervalos de confianza para la toma de decisiones, dado que estos ofrecen mayores elementos que un valor p acompañado de una estimación puntual (cf. tabla 3.7).
La práctica de basar los procesos inferenciales principalmente en los intervalos de confianza es especialmente visible en la comparación de dos proporciones binomiales con muestras independientes.
La mayoría de estudios se centran en proponer y comparar intervalos de confianza para la diferencia de dos proporciones. Y aunque algunos de tales intervalos tienen asociada una prueba de hipótesis, algunos otros no, sin que ello constituya impedimento alguno para su evaluación y uso.
Los criterios de comparación de las diferentes técnicas inferenciales se fundamentan, en general, en estudios de simulación, mediante los cuales se evalúan sus desempeños bajo diferentes condiciones. Suele analizarse la probabilidad de cobertura, la amplitud del intervalo y su estabilidad en situaciones extremas, como las que surgen cuando se tienen tamaños de muestra pequeños o proporciones cercanas a 0 o a 1.
A partir de tales evaluaciones se recomiendan las técnicas que presentan un comportamiento satisfactorio en rango más amplio de condiciones, aun cuando para escenarios muy específicos puedan existir métodos con mejor desempeño.
En esta sección se presentan tres métodos inferenciales para la comparación de dos proporciones binomiales, usando muestras independientes: el de Wald (sección 5.3.1.1), el de Agresti y Caffo (sección 5.3.1.2) y el de Newcombe (sección 5.3.1.3). Seguidamente se ilustrará su uso mediante un ejemplo común.
5.3.1.1 Método de Wald
Considérense dos variables aleatorias independientes con distribución binomial:
\[
X_1\thicksim \text{bin}(n_1,\;p_1)\quad\text{y}\quad X_2\thicksim \text{bin}(n_2,\;p_2)
\]
\[ E(X_i)=n_ip_i\;\;\text{y}\;\; V(X_i)=n_ip_iq_i,\text{ siendo } q_i=1-p_i,\text{ para } i=1, 2 \]
Cuando \(n_1\) y \(n_2\) son grandes, el comportamiento probabilístico de estas variables puede aproximarse mediante la distribución normal:
\[
X_1\overset{\cdot}{\thicksim}N(n_1p_1,\;n_1p_1q_1)\quad\text{y}\quad
X_2\overset{\cdot}{\thicksim}N(n_2p_2,\;n_2p_2q_2)
\]
Asimismo, los estimadores puntuales de las proporciones, \(p_i,\) esto es, las correspondientes proporciones observadas, se distribuirán de forma aproximadamente normal:
\[
\hat{p}_1=\frac{X_1}{n_1}\overset{\cdot}{\thicksim}N(p_1,\;\frac{p_1q_1}{n_1})\quad\text{y}\quad
\hat{p}_2=\frac{X_2}{n_2}\overset{\cdot}{\thicksim}N(p_2,\;\frac{p_2q_2}{n_2})
\]
La diferencia de estos estimadores también sigue una distribución aproximadamente normal:
\[
\left(\hat{p}_1-\hat{p}_2\right)\overset{\cdot}{\thicksim}N(p_1-p_2,\;\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2})
\]
Estandarizando, se tiene:
\[
\frac{\left(\hat{p}_1-\hat{p}_2\right)-\left(p_1-p_2\right)}{\sqrt{\dfrac{p_1q_1}{n_1}+\dfrac{p_2q_2}{n_2}}}\overset{\cdot}{\thicksim}N(0,\;1)
\]
Considérese ahora el siguiente juego de hipótesis para la comparación de las dos proporciones:
\[
H_0:p_1=p_2\Leftrightarrow p_1-p_2=0
\] \[
H_a:p_1\ne p_2\Leftrightarrow p_1-p_2\ne 0
\]
Bajo la hipótesis nula, la anterior variable aleatoria adquiere la forma:
\[
\frac{\hat{p}_1-\hat{p}_2}{\sqrt{\dfrac{p_1q_1}{n_1}+\dfrac{p_2q_2}{n_2}}}\overset{\cdot}{\thicksim}N(0,\;1)
\tag{5.14}\]
El estadístico de prueba del método de Wald se obtiene remplazando los parámetros desconocidos que aparecen en el denominador de la expresión 5.14 por sus correspondientes estimadores puntuales, así:
\[ Z_\text{W}=\frac{\hat{p}_1-\hat{p}_2}{\sqrt{\dfrac{\hat{p}_1\widehat{q}_1}{n_1}+\dfrac{\hat{p}_2\widehat{q}_2}{n_2}}}\overset{\cdot}{\thicksim}N(0\;,1) \]
Nota 5.2: Método de Wald usando la varianza conjunta
El estadístico de prueba del método de Wald también puede construirse usando un estimador agrupado de la varianza.
Bajo la hipótesis nula, es decir, cuando \(p_1 = p_2,\) el estimador conjunto de \(p\) se obtiene como la razón entre el número total de éxitos en las dos muestras y el tamaño conjunto de las dos muestras:
\[
\hat{p}=\frac{x_1+x_2}{n_1+n_2};\;\widehat{q}=1-\hat{p}
\]
El estadístico de prueba que usa la varianza conjunta tiene la siguiente forma:
\[
Z_\text{W}=\dfrac{\hat{p}_1-\hat{p}_2}{\sqrt{\dfrac{\hat{p}\widehat{q}}{n_1}+\dfrac{\hat{p}\widehat{q}}{n_2}}}=
\dfrac{\hat{p}_1-\hat{p}_2}{\sqrt{\hat{p}\widehat{q}\left(\dfrac{1}{n_1}+\dfrac{1}{n_1}\right)}}
\]
Aunque en este texto se prefiere el estadístico de prueba basado en la varianza no agrupada, por ser el que exhibe una relación uno a uno con el intervalo de confianza para la diferencia entre las proporciones, se hace mención al estadístico que usa la varianza agrupada por ser el que coincide con el estadístico \(\chi^2_\text{c}\) de la prueba de homogeneidad (cf. expresión 5.20).
Los criterios de rechazo se establecen acorde con el tipo de prueba, tal y como se muestra en la tabla 5.11 y la figura 5.13.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda \(H_0:p_1\ge p_2\) \(H_a:p_1<p_2\) |
\(Z_\text{W}\le−z_{\alpha}\) |
\(P(Z < Z_\text{W})\) |
| Cola derecha \(H_0:p_1\le p_2\) \(H_a:p_1>p_2\) |
\(Z_\text{W}\ge z_{\alpha}\) |
\(P(Z > Z_\text{W})\) |
| Dos colas \(H_0:p_1=p_2\) \(H_a:p_1\ne p_2\) |
\(|Z_\text{W}|\ge z_{\alpha/2}\) |
\(2 \, P(Z > |Z_\text{W}|)\) |
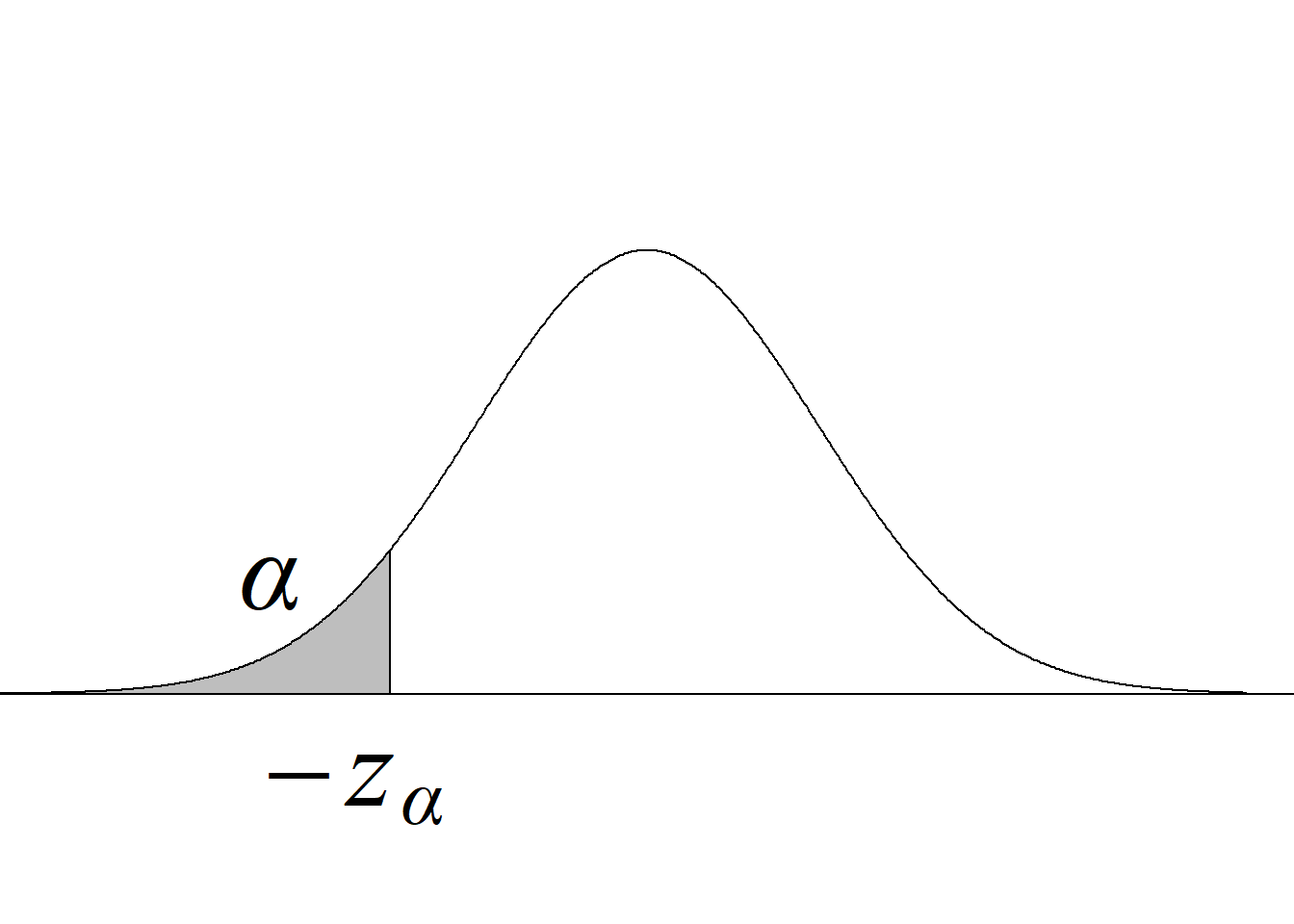
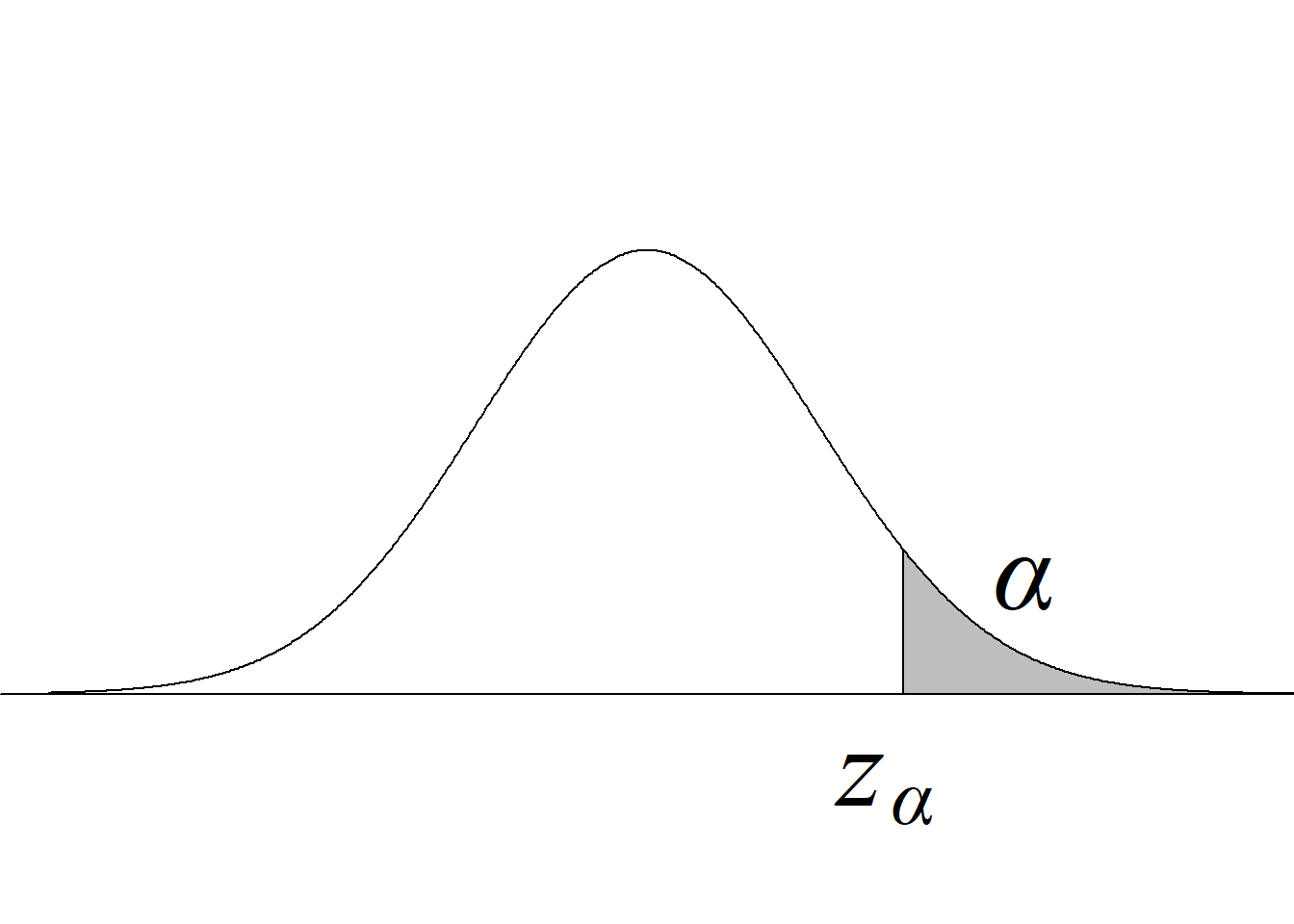
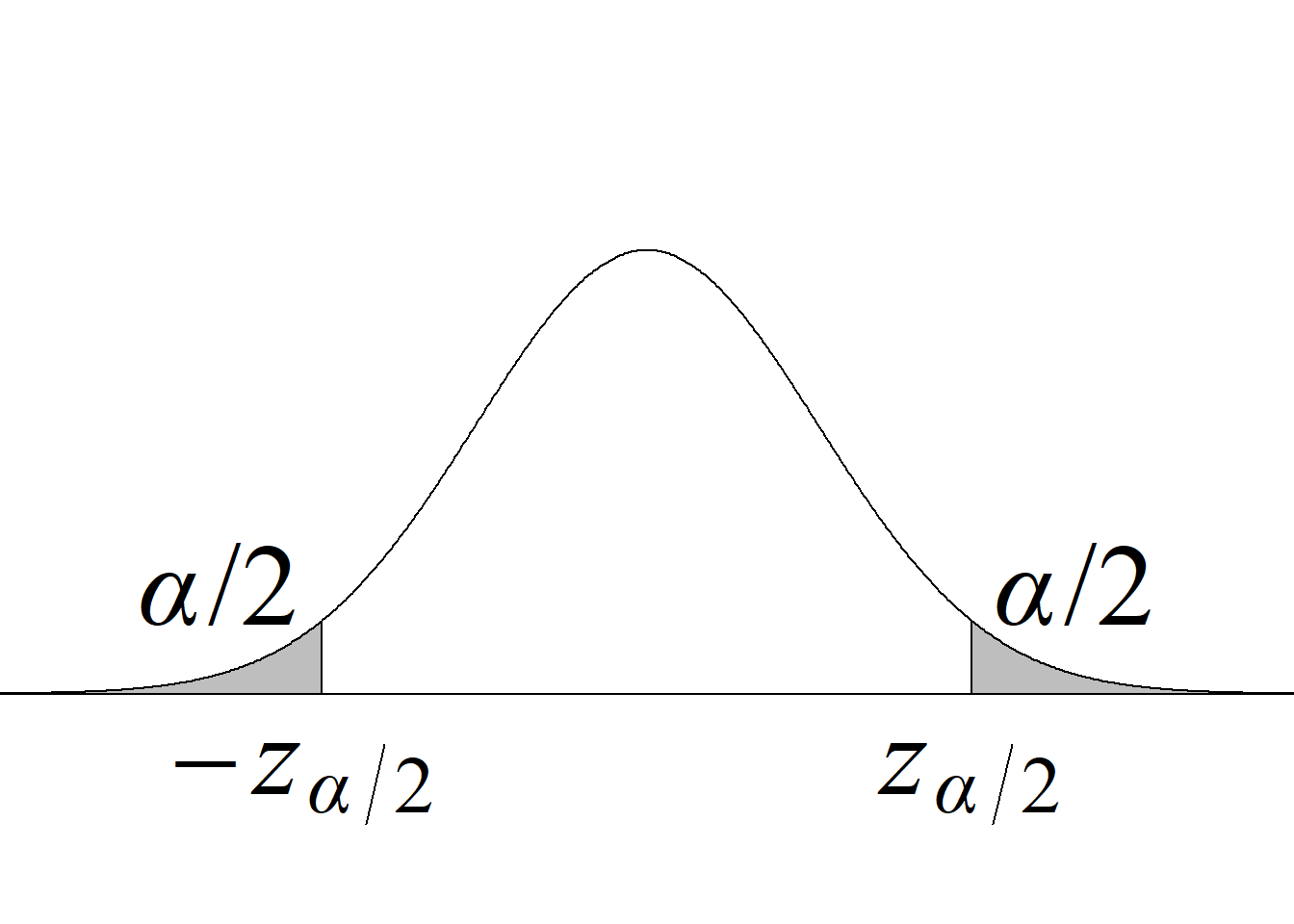
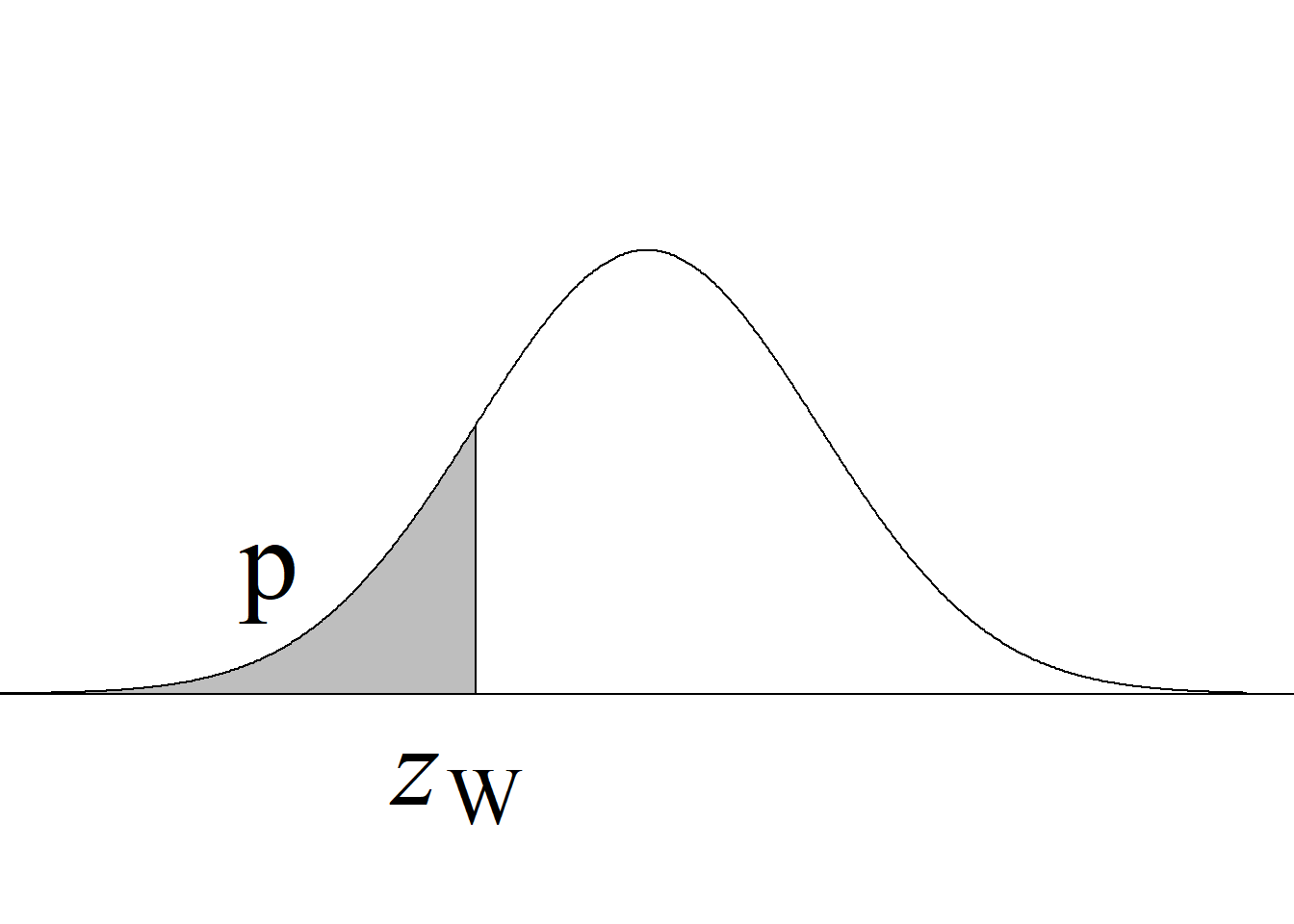
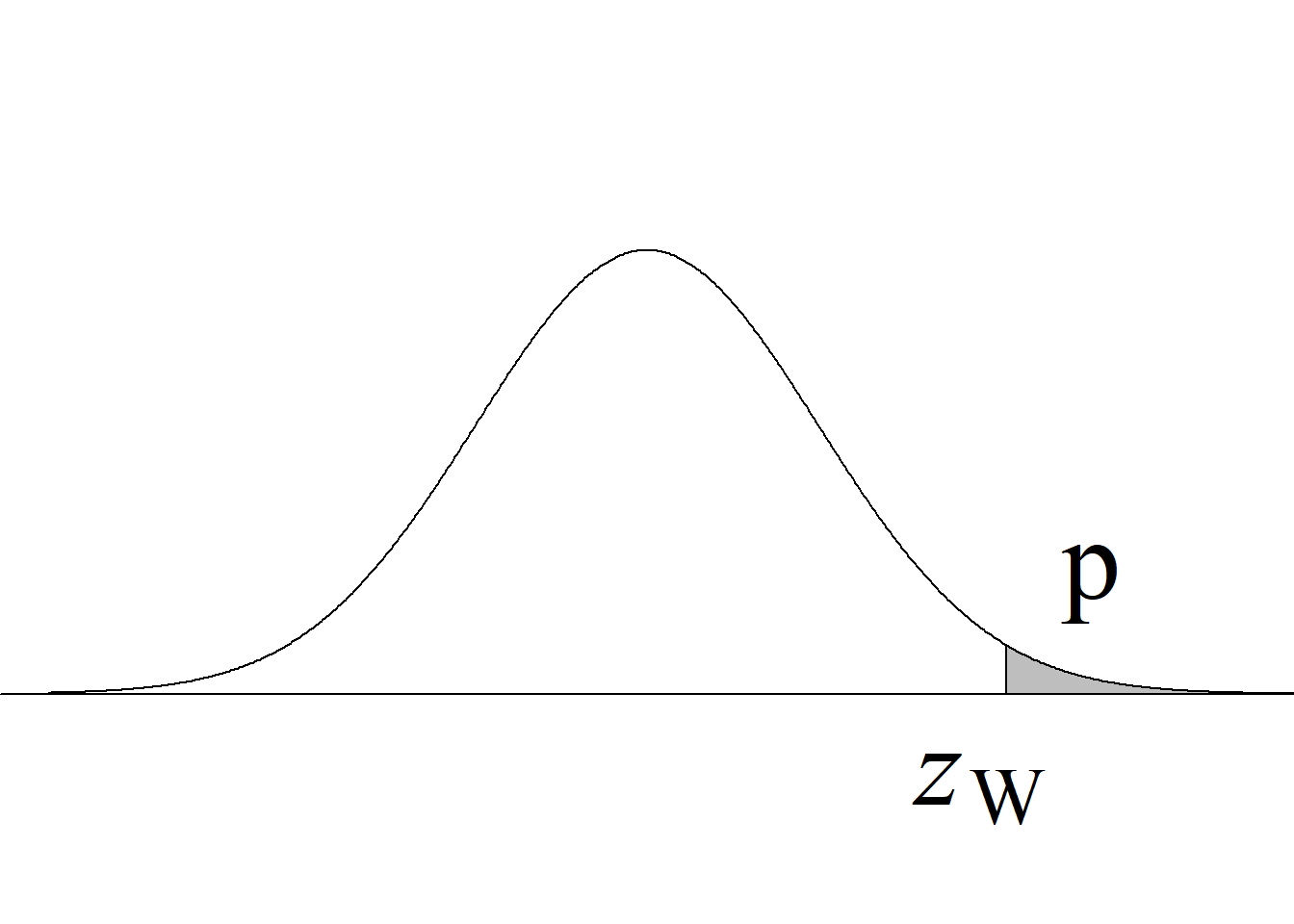
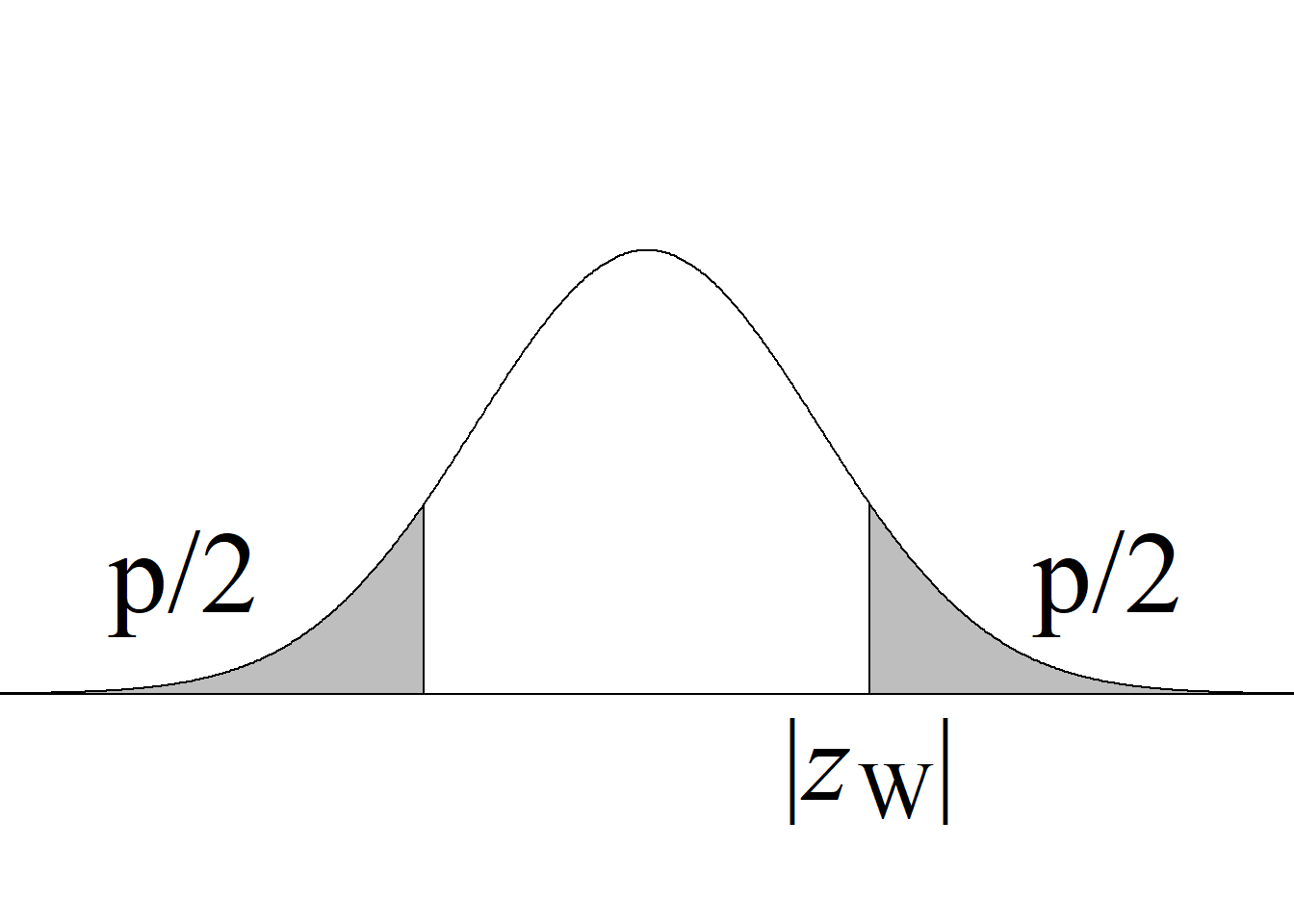
Invirtiendo la región de aceptación de la prueba de hipótesis, se obtiene el siguiente intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia \(p_1 − p_2\):
\[
\text{IC}:\quad\left(\hat{p}_1-\hat{p}_2\right)\pm z_{\alpha/2}\sqrt{\frac{\hat{p}_1\widehat{q}_1}{n_1}+\frac{\hat{p}_2\widehat{q}_2}{n_2}}
\tag{5.15}\]
Advertencia 5.5: ¡No lo use!
Este método se presenta como referencia, por ser el que aparece en la mayoría de los textos clásicos, además de servir de base al método de Agresti y Caffo (cf. sección 5.3.1.2).
No obstante, múltiples autores coinciden en señalar que la única ventaja del método de Wald es su sencillez, pero que debido a su pobre desempeño no debe usarse (Newcombe, 1998; Agresti and Caffo, 2000; Correa y Sierra, 2003; Brown and Li, 2005; Fagerland, Lydersen and Laake, 2011).
5.3.1.2 Método de Agresti y Caffo
Con el propósito de superar las deficiencias de desempeño del método de Wald (cf. advertencia 5.5), pero tratando de mantener su sencillez y siguiendo una lógica similar a la propuesta por Agresti y Coull (1998) para la inferencia sobre una proporción binomial (cf. sección 4.4.2), Agresti y Caffo (2000) proponen un ajuste que consiste en adicionar cuatro seudoobservaciones: un éxito y un fracaso en cada muestra.
Mediante simulaciones, estos autores establecieron que este mismo ajuste resulta adecuado incluso para intervalos de confianza distintos del 95 %.
Para aplicar el método propuesto, se redefinen las proporciones estimadas y los tamaños de muestra así:
\[
\widetilde{p}_1:=\frac{X_1+1}{n_1+2},\quad \widetilde{q}_1:=1-\widetilde{p}_1, \quad \widetilde{n}_1:=n_1+2
\] \[
\widetilde{p}_2:=\frac{X_2+1}{n_2+2},\quad \widetilde{q}_2:=1-\widetilde{p}_2, \quad \widetilde{n}_2:=n_2+2
\]
El estadístico de prueba adquiere la siguiente forma:
\[
Z_\text{AC}=\frac{\widetilde{p}_1-\widetilde{p}_2}{\sqrt{\dfrac{\widetilde{p}_1\widetilde{q}_1}{n_1}+\dfrac{\widetilde{p}_2\widetilde{q}_2}{n_2}}} \overset{H_0}{\overset{\cdot}{\thicksim}} N(0\;,1)
\]
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia \(p_1 − p_2\) se obtiene a partir de la siguiente expresión:
\[
\text{IC}:\quad\left(\widetilde{p}_1-\widetilde{p}_2\right)\pm z_{\alpha/2}\sqrt{\frac{\widetilde{p}_1\widetilde{q}_1}{\widetilde{n}_1}+\frac{\widetilde{p}_2\widetilde{q}_2}{\widetilde{n}_2}}
\]
Los criterios de rechazo son los mismos presentados en la tabla 5.11 y en la figura 5.13, usando \(Z_{\text{AC}}\) en lugar de \(Z_\text{W}.\)
En estudios realizados por Brown y Li (2005) y Fagerland et al. (2011), se constata que el método de Agresti y Caffo tiene un desempeño mucho mejor que el de Wald, exhibiendo una probabilidad de cobertura considerablemente más cercana al nivel nominal, especialmente en muestras pequeñas o cuando las proporciones son extremas.
5.3.1.3 Método del score híbrido de Newcombe
A partir de los intervalos de confianza individuales construidos mediante el método del score para \(p_1\) y para \(p_2\) (cf. sección 4.4.3, expresión 4.8), Newcombe (1998) propone un intervalo híbrido para la diferencia \(p_1 − p_2.\)
Supóngase que un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(p_1,\) obtenido mediante el método del score, está dado por:
\[
[\textcolor{cyan}{l_1},\quad \textcolor{blue}{u_1}]
\]
Y que un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(p_2,\) obtenido mediante el método del score, está dado por:
\[
[\textcolor{magenta}{l_2},\quad \textcolor{red}{u_2}]
\]
El intervalo de confianza del \(100(1−\alpha)\,\%\) para \(p_1 − p_2,\) propuesto por Newcombe, se calcula así:
\[
\begin{align}
\text{LI}&:\quad \hat{p}_1-\hat{p}_2-z_{\alpha/2}\sqrt{\frac{\textcolor{cyan}{l_1}(1-\textcolor{cyan}{l_1})}{n_1}+\frac{\textcolor{red}{u_2}(1-\textcolor{red}{u_2})}{n_2}},\\[2.4em]
\text{LS}&:\quad \hat{p}_1-\hat{p}_2+z_{\alpha/2}\sqrt{\frac{\textcolor{blue}{u_1}(1-\textcolor{blue}{u_1})}{n_1}+\frac{\textcolor{magenta}{l_2}(1-\textcolor{magenta}{l_2})}{n_2}}
\end{align}
\]
Acorde con Fagerland et al. (2011), el método del score híbrido de Newcombe tiende a presentar una probabilidad de cobertura cercana al nivel nominal, con amplitudes generalmente menores que las del método de Agresti y Caffo.
Ejemplo 5.6
Se estudia el efecto de un tratamiento hormonal sobre el porcentaje de preñez en búfalas. Para ello, se someten 150 hembras al tratamiento y se mantienen 100 hembras como grupo control.
De las hembras sometidas al tratamiento, 57 quedaron en estado de preñez. Entre las búfalas seleccionadas como control, 35 quedaron preñadas.
La información obervada se resume así:
\[
n_1=150,\;\; x_1=57\;\; \Rightarrow\;\; \hat{p}_1=\frac{57}{150}=0.38,\;\; \widehat{q}_1=1-\hat{p}_1=0.62
\] \[
n_2=100,\;\; x_2=35\;\; \Rightarrow\;\; \hat{p}_2=\frac{35}{100}=0.35,\;\; \widehat{q}_2=1-\hat{p}_2=0.65
\]
Para averiguar si es posible declarar la existencia de diferencias significativas entre los porcentajes de preñez de búfalas tratadas y de búfalas sin tratar, se plantea el siguiente juego de hipótesis:
\[
H_0:p_1=p_2
\]
\[
H_a:p_1\ne p_2
\]
A continuación se usa cada uno de los tres métodos presentados anteriormente para resolver la pregunta planteada.
Método de Wald
\[ Z_\text{W}=\dfrac{\hat{p}_1-\hat{p}_2}{\sqrt{\frac{\hat{p}_1\widehat{q}_1}{n_1}+\dfrac{\hat{p}_2\widehat{q}_2}{n_2}}}= \dfrac{0.38-0.35}{\sqrt{\dfrac{0.38\times0.62}{150}+\dfrac{0.35\times0.65}{100}}}=0.4838 \]
Para un nivel de significancia \(\alpha=0.05,\) se obtiene el valor crítico con base en la variable aleatoria normal estándar que deja a su derecha un área de 0.025, así:
Valor crítico: qnorm(0.025, lower.tail = FALSE) = 1.959964.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(|Z_\text{W}|\) \(0.4838\) |
\(<\) \(<\) |
\(z_{0.025}\) \(1.959964\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no rechaza \(H_0\) con \(α = 0.05\) |
Esto quiere decir que no existen elementos probatorios de que el tratamiento hormonal tenga algún efecto sobre la preñez de las búfalas.
El valor p se obtiene como la probabilidad de obtener un valor más extremo que 0.4838. Considerando que se está contrastando una prueba de dos colas, este valor se calcula de la siguiente manera:
Valor p: 2 * pnorm(0.4838, lower.tail = FALSE) = 0.6285278.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.6285\) |
\(>\) \(>\) |
\(\alpha\) \(0.05\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no rechaza \(H_0\) con \(α = 0.05\) |
Se ratifica el no rechazo de la hipótesis nula.
Un intervalo de confianza del 95 % para la diferencia \(p_1 − p_2,\) basado en el método de Wald, se calcula así:
\[
\begin{align}
\text{IC}_{p_1 − p_2}:\quad&\left(\hat{p}_1-\hat{p}_2\right)\pm z_{\alpha/2}\sqrt{\frac{\hat{p}_1\widehat{q}_1}{n_1}+\frac{\hat{p}_2\widehat{q}_2}{n_2}}\\[1.4em]
=&\left(0.38-0.35\right)\pm 1.96\sqrt{\frac{0.38\times0.62}{150}+\frac{0.35\times0.65}{100}}
\end{align}
\]
\[
\text{IC}_{p_1 − p_2}:\quad[-0.0915,\quad 0.1515]
\]
Puesto que el intervalo de confianza para la diferencia \(p_1 − p_2\) contiene al cero, no puede concluirse que exista diferencia a nivel poblacional entre las dos proporciones.
La función wald2ci{PropCIs} permite obtener el intervalo de confianza para la diferencia de proporciones. Los cuatro primeros argumentos corresponden a \(x_1,\) \(n_1,\) \(x_2\) y \(n_2,\) respectivamente:
PropCIs::wald2ci(57, 150, 35, 100, conf.level = 0.95, adjust = "Wald")
data:
95 percent confidence interval:
-0.09154411 0.15154411
sample estimates:
[1] 0.03Método de Agresti y Caffo
Se empieza por adicionar cuatro seudoobservaciones: un éxito y un fracaso ficticios en cada muestra, lo que da lugar a las siguientes definiciones para la primera muestra:
\[
\begin{align}
\widetilde{n}_1&=150+2=152\\[1.4em]
\widetilde{x}_1&=57+1=58\\[1.4em]
\widetilde{p}_1&=\frac{58}{152}=0.3816\\[1.4em]
\widetilde{q}_1&=1-0.3816=0.6184\\[1.4em]
\end{align}
\]
Análogamente, para la segunda muestra:
\[
\begin{align}
\widetilde{n}_2&=100+2=102\\[1.4em]
\quad \widetilde{x}_2&=35+1=36\\[1.4em]
\widetilde{p}_2&=\frac{36}{102}=0.3529\\[1.4em]
\widetilde{q}_2&=1-0.3529=0.6471
\end{align}
\]
El estadístico de prueba se calcula a partir de estos valores ajustados, así:
\[
Z_\text{AC}=\frac{\widetilde{p}_1-\widetilde{p}_2}{\sqrt{\dfrac{\widetilde{p}_1\widetilde{q}_1}{n_1}+\dfrac{\widetilde{p}_2\widetilde{q}_2}{n_2}}}=
\frac{0.3816-0.3529}{\sqrt{\dfrac{0.3816\times0.6184}{152}+\dfrac{0.3529\times0.6471}{102}}}=0.4661
\]
Para un nivel de significancia \(\alpha=0.05,\) se obtiene el valor crítico con base en la variable aleatoria normal estándar que deja a su derecha un área de 0.025 (cf. tabla 5.11 y figura 5.13 (c)), así:
Valor crítico: qnorm(0.025, lower.tail = F) = 1.959964.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(|Z_\text{AC}|\) \(0.4661\) |
\(<\) \(<\) |
\(z_{0.025}\) \(1.959964\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no rechaza \(H_0\) con \(α = 0.05\) |
Esto quiere decir que no es posible afirmar con una probabilidad máxima de error 0.05 que el tratamiento hormonal tenga algún efecto sobre la preñez de las búfalas.
La probabilidad exacta de cometer error tipo I si se rechazara la hipótesis nula con base en la presente información muestral se calcula tal y como se indica en la tabla 5.11 y en la figura 5.13 (f)):
Valor p: 2 * pnorm(0.4661, lower.tail = FALSE) = 0.6411439.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.6411\) |
\(>\) \(>\) |
\(\alpha\) \(0.05\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no rechaza \(H_0\) con \(α = 0.05\) |
Se ratifica el no rechazo de la hipótesis nula.
Un intervalo de confianza del 95 % para la diferencia \(p_1 − p_2,\) basado en el método de Agresti y Caffo, se calcula así:
\[
\begin{align}
\text{IC}_{p_1 − p_2}:\quad\left(\widetilde{p}_1-\widetilde{p}_2\right) &\pm z_{\alpha/2}\sqrt{\frac{\widetilde{p}_1\widetilde{q}_1}{\widetilde{n}_1}+\frac{\widetilde{p}_2\widetilde{q}_2}{\widetilde{n}_2}}\\[1.4em]
=\left(0.3816-0.3529\right) &\pm 1.96\sqrt{\frac{0.3816\times0.6184}{152}+\frac{0.3529\times0.6471}{102}}
\end{align}
\]
\[
\text{IC}_{p_1 − p_2}:\quad[-0.0920,\quad 0.1494]
\]
Puesto que el intervalo de confianza para la diferencia \(p_1 − p_2\) contiene al cero, no puede concluirse que exista diferencia a nivel poblacional entre las dos proporciones.
Para obtener este intervalo de confianza en R, se incluye el argumento adjust = "AC" en la función wald2ci{PropCIs}, así:
PropCIs::wald2ci(57, 150, 35, 100, conf.level = 0.95, adjust = "AC")
data:
95 percent confidence interval:
-0.09204628 0.14932182
sample estimates:
[1] 0.02863777
¿¡Y qué tal…!?
Compruebe usted mismo el resultado de realizar la prueba de Wald tras aplicar la adición manual de las 4 seudoobservaciones, así:
PropCIs::wald2ci(58, 152, 36, 102, conf.level = 0.95, adjust = "Wald")Método de Newcombe
Inicialmente se obtienen los intervalos de confianza del 95 % para \(p_1\) y \(p_2,\) mediante el método del score, acorde con la expresión 4.8:
\[
\text{IC}_{p_1}: [\textcolor{cyan}{l_1},\quad \textcolor{blue}{u_1}]=\frac{1}{1+\frac{z_{0.025}^2}{n_1}}\left(\hat{p}_1+\frac{z_{0.025}^2}{2n_1}\pm z_{0.025}\sqrt{\frac{\hat{p}_1\widehat{q}_1}{n_1}+\frac{z_{0.025}^2}{4n_1^2}}\right)
\]
\[=\frac{1}{1+\frac{1.96^2}{150}}\left(0.38+\frac{1.96^2}{2\times 150}\pm 1.96\sqrt{\frac{0.38\times0.62}{150}+\frac{1.96^2}{4\times 150^2}}\right)
\]
\[
[\textcolor{cyan}{0.3062},\quad \textcolor{blue}{0.4598}]
\]
\[
\text{IC}_{p_2}: [\textcolor{magenta}{l_2},\quad \textcolor{red}{u_2}]= \frac{1}{1+\frac{z_{0.025}^2}{n_2}}\left(\hat{p}_2+\frac{z_{0.025}^2}{2n_2}\pm z_{0.025}\sqrt{\frac{\hat{p}_2\widehat{q}_2}{n_2}+\frac{z_{0.025}^2}{4n_2^2}}\right)
\]
\[
=\frac{1}{1+\dfrac{1.96^2}{100}}\left(0.35+\frac{1.96^2}{2\times 100}\pm 1.96\sqrt{\frac{0.35\times0.65}{100}+\frac{1.96^2}{4\times 100^2}}\right)
\]
\[
[\textcolor{magenta}{0.2636},\quad \textcolor{red}{0.447}]
\]
El intervalo de confianza del 95 % para \(p_1-p_2\) se calcula así:
\[
\begin{multline}
\Biggl[\;\hat{p}_1-\hat{p}_2-z_{\alpha/2}\sqrt{\frac{\textcolor{cyan}{l_1}(1-\textcolor{cyan}{l_1})}{n_1}+\frac{\textcolor{red}{u_2}(1-\textcolor{red}{u_2})}{n_2}},\\
\hat{p}_1-\hat{p}_2+z_{\alpha/2}\sqrt{\frac{\textcolor{blue}{u_1}(1-\textcolor{blue}{u_1})}{n_1}+\frac{\textcolor{magenta}{l_2}(1-\textcolor{magenta}{l_2})}{n_2}}\;\,\Biggr]
\end{multline}
\]
\[
\begin{multline}
\Biggl[\; 0.38-0.35-1.96\sqrt{\frac{\textcolor{cyan}{0.3062}(1-\textcolor{cyan}{0.3062})}{150}+\frac{\textcolor{red}{0.447}(1-\textcolor{red}{0.447})}{100}},\\
0.38-0.35+1.96\sqrt{\frac{\textcolor{blue}{0.4598}(1-\textcolor{blue}{0.4598})}{150}+\frac{\textcolor{magenta}{0.2636}(1-\textcolor{magenta}{0.2636})}{100}}\;\Biggr]
\end{multline}
\]
\[
\text{IC}_{p_1 − p_2}:\quad[-0.092,\quad 0.148]
\]
Este intervalo puede obtenerse de forma directa, mediante la función Prop.diff, que forma parte del paquete pairwiseCI. En esta función los dos primeros argumentos son vectores con los éxitos y los fracasos de cada una de las muestras.
pairwiseCI::Prop.diff(c(57, 93), c(35, 65), CImethod = "NHS")$conf.int
[1] -0.09222327 0.14755243
attr(,"methodname")
[1] "Newcombes Hybrid Score interval for the difference of proportions"
$estimate
[1] 0.03Puesto que el intervalo de confianza para la diferencia \(p_1 − p_2\) contiene al cero, no puede concluirse que exista diferencia a nivel poblacional entre las dos proporciones.
Nota 5.3: En resumen…
En estudios realizados por Brown y Li (2005) y Fagerland et al. (2011), se concluye que el método de Wald tiene los más bajos desempeños generales; por tal motivo, nunca debe utilizarse.
En todos los casos, el método de Agresti y Caffo tiene mejor desempeño que el de Wald. Este es un método que bien podría considerarse si se tuviera interés en mantener la sencillez del método de Wald.
El método del score híbrido de Newcombe tiende a generar intervalos más estrechos que los obtenidos mediante el método de Agresti y Caffo, asegurando buenas probabilidades de cobertura cuando se tienen muestras mayores o iguales a 40, con coberturas aceptables para tamaños de muestra tan bajos como 10. Este es, por tanto, el método recomendado para la comparación de dos proporciones binomiales.
5.3.1.4 Uso de R para la comparación de dos proporciones binomiales usando muestras independientes
En los apartados anteriores se han mencionado algunas funciones para realizar inferencia sobre la diferencia de dos proporciones binomiales.
La función
wald2ci{PropCIs}permite obtener el intervalo de confianza para la diferencia de proporciones, bien sea usando el método clásico de Wald (adjust = "Wald") o el método de Agresti y Caffo (adjust = "AC"). Sin embargo, no presenta lo concerniente a la prueba de hipótesis: estadístico de prueba y valor p.La función
Prop.diff{pairwiseCI}permite obtener el intervalo de confianza para la diferencia de proporciones, usando el método del score híbrido de Newcombe (CImethod = "NHS"). La propuesta de Newcombe (1998), al ser de tipo híbrido, genera directamente el intervalo de confianza, no estando asociada con un estadístico de prueba ni con un valor p.La función personalizada inf_2p es nuestra recomendada. Esta función implementa las tres técnicas expuestas, generando en todos los casos un intervalo de confianza para la diferencia de las proporciones. En adición, para los métodos de Wald (
method = "wald") y de Agresti y Caffo (method = "ac"), genera el estadístico de prueba y el correspondiente valor p. Y, como novedad para el método de Newcombe (method = "newcombe"), genera el valor p.
A continuación se ilustra su uso para contrastar el juego de hipótesis del ejemplo 5.6:
Mediante la primera línea se carga la función personalizada inf_2p. En la segunda línea se alimentan los valores de número de éxitos de la primera muestra, número de éxitos de la segunda muestra, número de ensayos de la primera muestra y número de ensayos de la segunda muestra, respectivamente.
Los demás argumentos toman sus valores por defecto: method = "newcombe", alternative = "two.sided" y conf.level = 0.95.
Se obtiene el siguiente resultado:
Evaluación de la diferencia de dos proporciones binomiales
mediante el método del score híbrido de Newcombe
Prueba de dos colas (Ha: p1 diferente de p2)
Valor p = 0.63
Intervalo de confianza del 95 % para p1 - p2
[-0.0922, 0.1476]5.3.1.4.1 Tamaño de muestra para la estimación de la diferencia de dos proporciones
La función personalizada n_2p calcula el tamaño de muestra requerido para detectar diferencias entre dos proporciones binomiales con una precisión, una significancia y una potencia determinadas.
Los cálculos están basados en el intervalo de confianza del score híbrido de Newcombe. No obstante, con el fin de ilustrar algunos conceptos, consideramos inicialmente el intervalo de confianza de Wald del \(100(1−\alpha)\,\%\) para la diferencia \(p_1 − p_2\) (cf. expresión 5.15).
En casos como este, donde el intervalo es simétrico alrededor del estimador puntual, el procedimiento de construcción del intervalo garantiza que, en el \(100(1−\alpha)\,\%\) de las muestra posibles, la distancia entre la verdadera diferencia \(p_1-p_2\) y su estimador \(\hat{p}_1-\hat{p}_2\) sea no mayor que la semiamplitud del intervalo.
\[
\text{semiamplitud}=z_{\alpha/2}\sqrt{\frac{\hat{p}_1\hat{q}_1}{n_1}+\frac{\hat{p}_2\hat{q}_2}{n_2}}
\]
Si se asume el mismo tamaño para las dos muestras, es decir, \(n_1=n_2=n,\) esta expresión se simplifica así:
\[
\text{semiamplitud}=z_{\alpha/2}\sqrt{\frac{\hat{p}_1\hat{q}_1}{n}+\frac{\hat{p}_2\hat{q}_2}{n}}=
z_{\alpha/2}\sqrt{\frac{\hat{p}_1\hat{q}_1+\hat{p}_2\hat{q}_2}{n}}
\]
El tamaño de muestra requerido se obtiene despejando \(n\) de la expresión anterior. Elevando al cuadrado ambos miembros de la ecuación, se tiene:
\[
{\text{semiamplitud}}^2=(z_{\alpha/2})^2\frac{\hat{p}_1\hat{q}_1+\hat{p}_2\hat{q}_2}{n}
\]
Luego:
\[
n=\left(\frac{z_{\alpha/2}} {\text{semiamplitud}}\right)^2 \left(\hat{p}_1\hat{q}_1+\hat{p}_2\hat{q}_2\right)
\]
Puede observarse que —en adición a la semiamplitud— el cálculo de \(n\) depende del nivel de significancia \(\alpha\)18 y de los productos \(\hat{p}_1\hat{q}_1\) y \(\hat{p}_2\hat{q}_2.\) Cada uno de estos productos es mayor cuanto más cercanos están sus factores a 0.5 (cf. figura 4.9).
La expresión anterior ayuda a entender el rol de estos elementos en la determinación de los tamaños de muestra. No obstante, dado que el intervalo de confianza basado en el método del score híbrido de Newcombe tiene mejor desempeño (cf. nota 5.3), este es el que se implementa en la función n_2p.
Puesto que los intervalos de confianza de Newcombe no son simétricos alrededor de \(\hat{p}_1-\hat{p}_2\), deja de ser adecuado el concepto de semiamplitud del intervalo. En lugar de ello, se busca el mínimo tamaño muestral cuyo intervalo de confianza esperado bajo el escenario alternativo considerado, no contenga el cero.
¿Intervalo de confianza esperado?
Denominamos intervalo de confianza esperado al que se obtiene cuando el número de éxitos de cada muestra corresponde (o se redondea) a su valor esperado.
Es el intervalo con máxima probabilidad de aparición bajo el escenario alternativo considerado.
Sin considerar aún la sintaxis de la función, supongamos que se busca el tamaño muestral mínimo requerido para detectar diferencias de magnitud 0.1 o mayores, cuando los parámetros poblacionales oscilan alrededor de 0.5.
La función n_2p reparte la magnitud de la diferencia alrededor de 0.5, es decir, que plantea un escenario alternativo con \(p_1=0.45\) y \(p_2=0.55.\) Mediante una búsqueda iterativa, arroja como resultado \(n=192.\)
Los correspondientes éxitos esperados para este tamaño de muestra en el escenario alternativo planteado son:
\[
E(X_1|n=192,\, p=0.45)=86.4 \approx 86
\]
\[
E(X_2|n=192,\, p=0.55)=105.6 \approx 106
\]
Puede verificarse que el intervalo de confianza de Newcombe del 95 % para la diferencia \(p_1-p_2\) cuando se usan dos muestras de tamaño 192 y se obtienen 86 éxitos en la primera y 106 en la segunda es \([-0.2012,-0.0042]\)19. Este es el intervalo de confianza esperado y, bajo el escenario alternativo planteado, es también el de mayor probabilidad de aparición.
Y puesto que este intervalo de confianza no contiene el cero, indica que es posible rechazar la hipótesis de igualdad de proporciones con \(\alpha=0.05.\) Pero este es solo el punto de partida.
El resultado anterior es incompleto, dado que no informa sobre la potencia \((1-\beta)\), es decir, la probabilidad de rechazar la hipótesis nula o, en otras palabras, de detectar diferencias entre las proporciones.
La potencia se calcula como la probabilidad, bajo el escenario alternativo \((p_1=0.45\) y \(p_2=0.55),\) de obtener intervalos de confianza que den lugar al rechazo de la hipótesis nula.
En el presente ejemplo, si bien es cierto que cuando se toman muestras de tamaño \(n=192\) y se obtienen 86 éxitos en la primera muestra y 106 en la segunda se logra el rechazo de la hipótesis nula con \(\alpha=0.05\), este rechazo también se lograría con valores menores que 86 para la primera muestra (manteniendo los de la segunda mayores o iguales que 106), mayores que 106 para la segunda (manteniendo los de la primera menores o iguales que 86) o con algunas otras combinaciones particulares que, aunque menos probables, también contribuyen a la potencia20.
La suma de las probabilidades de todos estos resultados constituye la potencia. Para el presente caso, es decir, cuando se usan muestras de tamaño \(n=192,\) buscando detectar diferencias de 0.1 o mayores entre proporciones que oscilan alrededor de 0.5, con un nivel de significancia \(\alpha = 0.05\), se tiene una potencia de 0.49.
¡El conflicto entre la significancia y la potencia!
\(¿\)Cómo se entiende una significancia relativamente buena (\(\alpha=0.05\)) con una baja potencia \((1-\beta=0.49)?\)
¿Una prueba que —usando muestras de tamaño \(n=192\)— permita detectar diferencias de 0.1 o mayores es “buena” o no?
Esto dependerá del resultado de la prueba. Si tras realizar el correspondiente ensayo se produce el rechazo de la hipótesis nula (se declara diferencia entre las dos proporciones), será poco probable (probabilidad menor o igual que \(\alpha\)) estar tomando una decisión errada, es decir, estar declarando diferencias que realmente no existen.
Sin embargo, si tras realizar el ensayo no se logra rechazar la hipótesis nula, no se tendrá suficiente confianza en inexistencia de diferencias.
Y esto no tiene que ver únicamente con el carácter no concluyente de la aceptación de la hipótesis nula, sino con la baja potencia de la prueba.
En el escenario de la hipótesis alternativa que se está planteando (\(p_1=0.45\) y \(p_2=0.55\)) un ensayo realizado con sendas muestras de tamaño \(n=192\) únicamente lograría rechazar la hipótesis nula con probabilidad 0.49.
Por tanto, la respuesta es que esta prueba no podría considerarse “buena”.
Se considera que una prueba es buena cuando su probabilidad de detectar diferencias es alta: ojalá mayor o igual que 0.8.
La función n_2p calcula el tamaño de muestra requerido para detectar diferencias de una magnitud determinada (dif) entre dos proporciones binomiales que oscilan alrededor de un valor (por defecto p = 0.5), con un nivel de significancia específico (por defecto alpha = 0.05) y una potencia dada (power).
Esta es la sintaxis de la función:
n_2p(alpha = 0.05, dif = 0.1, p = 0.5, power = NULL)Si la ejecución se realiza sin definir ningún valor para el argumento power, la función calcula la potencia asociada al tamaño de muestra mínimo que permite rechazar con nivel \(\alpha\) cuando se obtiene el intervalo esperado. De ahí surge la potencia de 0.49 presentada anteriormente.
Si el usuario buscara una potencia mayor, bastaría con indicarla como valor del argumento power. En tal caso, la función realiza procesos iterativos hasta que la potencia sea mayor o igual que la potencia objetivo.
Casi siempre es mayor
Por la naturaleza discreta del método, la potencia alcanzada suele ser ligeramente mayor que la potencia objetivo.
La potencia real aparece en las salidas de la función con dos cifras decimales.
Por la naturaleza iterativa del algoritmo, los requerimientos que solo se satisfacen con tamaños de muestra mayores que 500 tardan muchísimo tiempo en procesarse. En general, estos grandes tamaños de muestra son los exigidos cuando se buscan diferencias menores o iguales que 0.05.
La tabla 5.12 presenta algunos tamaños de muestra para diferentes valores de potencia objetivo.
dif para p alrededor de 0.5 con potencias objetivo entre 0.5 y 0.95
| dif | 0.5 | 0.55 | 0.6 | 0.65 | 0.7 | 0.75 | 0.8 | 0.85 | 0.9 | 0.95 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.40 | 12 | 16 | 17 | 18 | 22 | 23 | 28 | 31 | 38 | |
| 0.30 | 22 | 23 | 25 | 30 | 32 | 38 | 41 | 48 | 57 | 70 |
| 0.20 | 48 | 56 | 60 | 69 | 79 | 84 | 97 | 111 | 128 | 160 |
| 0.10 | 195 | 218 | 243 | 270 | 299 | 343 | 393 | 450 | 521 | 651 |
| 0.05 | 768 | 862 | 982 | 1112 | 1230 | 1385 | 1560 | 1790 | 2100 | 2594 |
La figura 5.14 muestra el comportamiento de la potencia de las pruebas para la detección de diferencias entre 0.05 y 0.4, para proporciones que oscilan alrededor de 0.5, en función del tamaño de las muestras.
Recomendaciones
Al calcular tamaños de muestra, el nivel de significancia suele estar fuera de discusión, por lo que se desaconseja usar cualquier valor diferente del especificado por defecto:
alpha = 0.05.Aunque la especificación de valores de \(p\) diferentes al usado por defecto (
p = 0.5) da lugar a menores tamaños de muestra, este recurso únicamente debe aplicarse si se tienen claros indicios de que las probabilidades oscilan alrededor de algún otro valor. En los demás casos, debe usarse el valor por defecto, que conduce a cálculos más conservadores.Se desaconseja proyectar una investigación con tamaños de muestra que den lugar a potencias inferiores a 0.8.
5.3.2 Comparación de dos proporciones binomiales usando muestras pareadas
En algunos ensayos que tienen por objeto la comparación de dos proporciones binomiales, cada una de las observaciones de una muestra se relaciona con una observación en la otra muestra, dando lugar a muestras pareadas.
Este esquema es análogo al presentado en la sección 5.2.3, con la única diferencia de que en este caso se registra una respuesta dicotómica.
Son varios los escenarios en los que el pareamiento resulta útil y hasta necesario para la comparación de proporciones binomiales, tales como los que se exponen a continuación:
Comparación de métodos de diagnóstico: Para evaluar la consistencia de dos métodos de diagnóstico, se aplican ambos métodos sobre el mismo grupo de pacientes, comparando el resultado arrojado por el método \(\text{A}\) para un paciente particular con el resultado obtenido por el método \(\text{B}\) para el mismo paciente.
Estudios de fiabilidad: Esta situación es análoga a la expuesta anteriormente, con la diferencia de que el diagnóstico es emitido por dos evaluadores. Este escenario surge cuando dos evaluadores califican dicotómicamente un grupo de individuos o de situaciones comunes.
Comparación entre órganos o partes del cuerpo que conformen un par: El uso de muestras pareadas se hace necesario para comparar alguna condición dicotómica entre órganos pareados. Por ejemplo, para comparar la incidencia de una enfermedad degenerativa entre el ojo izquierdo y el ojo derecho de un paciente.
También podría usarse para comparar la aparición de alguna afectación cutánea entre el miembro superior izquierdo y el miembro superior derecho de un paciente.
Estudios antes-después: Cuando se registra una respuesta dicotómica sobre una misma muestra en dos momentos diferentes.
Los escenarios con dos condiciones que impliquen pareamiento dan lugar a una muestra aleatoria de pares, en cada uno de los cuales se registran dos respuestas dicotómicas.
Las frecuencias marginales correspondientes a cada condición pueden modelarse mediante distribuciones binomiales con probabilidades \(p_1\) y \(p_2,\) respectivamente, aunque ambas se encuentran vinculadas por la estructura de pareamiento.
La comparación entre la probabilidad de éxito en las dos condiciones o poblaciones se expresa así:
\[
H_0: p_{1} = p_{2}
\]
\[
H_a: p_{1} \neq p_{2}
\]
McNemar (1947) formalizó una de las primeras pruebas para contrastar este juego de hipótesis. Posteriormente se han desarrollado variantes de su prueba, así como enfoques alternativos basados en la razón de verosimilitud.
No obstante, Fagerland, Lydersen y Laake (2013), quienes realizaron un estudio comparativo de cinco versiones de la prueba de McNemar, concluyen que no existen diferencias prácticas entre el enfoque de McNemar y el que se basa en la razón de verosimilitud, por lo que recomiendan el uso de pruebas basadas en el estadístico de McNemar, debido a su simplicidad y amplia aceptación.
A continuación se esbozan las cinco pruebas que Fagerland et al. (2013) compararon en 9595 escenarios diferentes. Al final de la exposición se presentan sus conclusiones y nuestras recomendaciones.
5.3.2.1 Prueba asintótica de McNemar
La información proveniente de ensayos en los que se usan muestras pareadas para comparar proporciones binomiales suele organizarse en una tabla de contingencia \(2 \times 2,\) en la que se presentan las frecuencias de aparición de las diferentes combinaciones de éxitos y fracasos, como lo ilustra la tabla 5.13.
¿Tabla de contingencia?
Aunque una tabla de contingencia \(2 \times 2\) resulta muy intuitiva, sin que se haga necesaria una presentación formal previa, en la sección 5.4 se amplían la definición y los alcances de esta herramienta.
| Muestra 2 | |||
\(\\\) \(\\\) \(\\\) Muestra 1 |
éxito | fracaso | |
| éxito | \(a\) | \(b\) | |
| fracaso | \(c\) | \(d\) | |
McNemar (1947) basó su prueba en la información proveniente de las parejas discordantes (éxito-fracaso, fracaso-éxito), pues bajo la hipótesis nula —que plantea igual probabilidad de éxito en ambas poblaciones— se espera que las frecuencias \(b\) y \(c\) sean similares.
El estadístico de prueba de McNemar se calcula así:
\[
\chi^2_\text{c} = \frac{(b-c)^2}{b+c}
\tag{5.16}\]
Bajo la hipótesis nula \((p_{1} = p_{2}),\) el estadístico de prueba sigue aproximadamente una distribución ji cuadrado con 1 grado de libertad.
Puesto que el estadístico de prueba recoge la discrepancia entre \(b\) y \(c\) —cualquiera que sea su sentido—, el valor p se calcula como la probabilidad de obtener un valor mayor que el del estadístico de prueba bajo la hipótesis nula, es decir, \(P\left(\chi^2_{(1)}>\chi^2_\text{c}\right).\)
5.3.2.2 Prueba asintótica de McNemar con corrección por continuidad
Edwards (1948) propuso ajustar la prueba asintótica de McNemar (cf. sección 5.3.2.1), incorporando una corrección por continuidad, así:
\[
\chi^2_\text{c} = \frac{\left(|b-c|-1\right)^2}{b+c}
\tag{5.17}\]
Bajo la hipótesis nula \((p_{1} = p_{2}),\) y para tamaños de muestra suficientemente grandes, el estadístico de prueba se distribuye aproximadamente ji cuadrado con 1 grado de libertad. El valor p se calcula como la probabilidad de obtener un valor mayor que el del estadístico de prueba bajo la hipótesis nula, es decir, \(P\left(\chi^2_{(1)}>\chi^2_\text{c}\right).\)
5.3.2.3 Prueba exacta condicional de McNemar
Siguiendo la lógica de la prueba asintótica de McNemar (cf. sección 5.3.2.1), cuyo estadístico de prueba mide la fuerza de la evidencia contra la hipótesis nula con base en la magnitud de la diferencia entre los pares discordantes \((b-c),\) es posible construir una prueba exacta, condicionada al hecho de que se obtuvieron \(n=b+c\) pares discordantes.
Si se parte del hecho de haber obtenido \(n=b+c\) pares de observaciones discordantes, bajo la hipótesis nula, las discordancias deberían compensarse en promedio. En otras palabras, bajo la hipótesis nula se espera que \(b=c.\)
Por tanto, en un experimento en el que se obtuvieron \(n=b+c\) pares discordantes, la probabilidad de que una observación particular de ese conjunto de pares discordantes pertenezca al grupo éxito-fracaso es igual a la probabilidad de que pertenezca al grupo fracaso-éxito, esto es, 0.5.
Y, puesto que el desbalance entre \(b\) y \(c\) constituye la evidencia en contra de la hipótesis nula, el valor p se calcula como la probabilidad de obtener, bajo la hipótesis nula, un desbalance entre \(b\) y \(c\) igual o más extremo que el observado. Para ello, es posible tomar cualquiera de los dos valores, entre \(b\) y \(c,\) como estadístico de prueba.
Si se toma el mínimo valor entre \(b\) y \(c,\) se calcula inicialmente la probabilidad de un valor menor o igual que el observado. Si se toma el máximo, se calcula la probabilidad de un valor mayor o igual que el observado.
Así se calcularía la probabilidad para el caso en el que se tome el mínimo entre \(b\) y \(c\) como estadístico de prueba:
\[
\sum\limits_{i=0}^{\text{mín}(b,\,c)} {{n}\choose{i}}0.5^i(1-0.5)^{n-i}
\]
¡Podría simplificarse!
Desde luego, la anterior expresión podría simplificarse, lo que facilitaría los cálculos si fueran a realizarse manualmente, quedando así:
\[
\sum\limits_{i=0}^{\text{mín}(b,\,c)} {{n}\choose{i}}0.5^n
\]
No obstante, tomando en consideración lo expedito que resulta realizar los cálculos mediante la función pbinom, preferimos mantener la presentación previa, que ayuda a visualizar la distribución binomial en la que se basa el cálculo.
El desbalance entre \(b\) y \(c\) puede presentarse porque \(b<c\) o porque \(b>c.\) Por tanto, el valor p se obtiene multiplicando por 2 la probabilidad calculada anteriormente:
\[
\text{valor p}=2\sum\limits_{i=0}^{\text{mín}(b,\,c)} {{n}\choose{i}}0.5^i(1-0.5)^{n-i}
\tag{5.18}\]
5.3.2.4 Prueba mid-p de McNemar
Los métodos mid-p buscan un equilibrio entre las pruebas exactas —que suelen ser excesivamente conservadoras— y los métodos asintóticos —que frecuentemente violan el nivel de significancia nominal—.
La versión mid-p de la prueba de McNemar se obtiene restando la mitad de la probabilidad puntual de \(b\) (o de \(c\)) del valor p de la probabilidad exacta para prueba de una cola. Seguidamente se multiplica el valor obtenido por 2, para obtener el correspondiente valor p de la prueba bilateral.
Estos dos pasos se simplifican, dando lugar a la siguiente expresión:
\[
\text{valor p}=2\sum\limits_{i=0}^{\text{mín}(b,\,c)} {{n}\choose{i}}0.5^i\times0.5^{n-i}-{{n}\choose{b}}0.5^b\times0.5^{n-b}
\tag{5.19}\]
5.3.2.5 Prueba exacta no condicional de McNemar
La prueba exacta no condicional de McNemar, propuesta por Suissa y Shuster (1991), es una variante de la prueba de McNemar que, a diferencia de la prueba exacta condicional (cf. sección 5.3.2.3) usa toda la información disponible en la muestra pareada: tanto la proporcionada por los pares discordantes \(b\) y \(c,\) como la de los pares coincidentes \(a\) y \(d.\) Esto permite una evaluación más completa de la evidencia en contra de la hipótesis nula.
El valor p se obtiene sumando las probabilidades de todas las tablas \(2\times2\) basadas en \(N=a+b+c+d\) pares de observaciones, que sean iguales o más extremas que la observada, bajo la hipótesis nula.
Para ello, se modela la distribución conjunta de los pares \(a,\,b,\,c,\,d\) con base en una distribución multinomial con cuatro categorías, donde las probabilidades de cada tipo de par (éxito-éxito, éxito-fracaso, fracaso-éxito y fracaso-fracaso) se determinan bajo la hipótesis nula.
La implementación de esta prueba requiere cálculos computacionalmente intensivos, ya que implica explorar un espacio de posibles resultados mucho más amplio que en la prueba condicional. Además, el cálculo de las probabilidades exactas bajo la distribución multinomial requiere evaluar un gran número de configuraciones de tablas \(2\times2,\) lo que puede volverse computacionalmente prohibitivo para muestras grandes.
Otra dificultad radica en la necesidad de definir un criterio claro para determinar qué tablas son “iguales o más extremas” que la observada, lo que añade una capa adicional de complejidad algorítmica.
¡Notación!
Puesto que, en el contexto de la prueba de McNemar, \(n\) representa el número de parejas discordantes, se utiliza \(N\) para representar el número total de parejas, es decir, el tamaño de la muestra, así:
\(n=b+c\)
\(N=a+b+c+d\)
¡Conclusiones!
A continuación presentamos las conclusiones de la evaluación realizada por Fagerland et al. (2013) sobre las cinco versiones de la prueba de McNemar, a las cuales haremos referencia con una etiqueta.
Prueba asintótica de McNemar (as)
Prueba asintótica de McNemar con corrección por continuidad (ascc)
Prueba exacta condicional de McNemar (ex)
Prueba mid-p de McNemar (midp)
Prueba exacta no condicional de McNemar (exnc)
La primera conclusión queda recogida en el título del artículo: Las pruebas mid-p (midp) y asintótica (as) son mejores que la exacta condicional (ex).
A estas alturas, esta conclusión no es tan sorprendente, pues ya se había discutido, al comparar diferentes métodos para realizar inferencia sobre una proporción, que el apelativo “exacto” puede resultar engañoso (cf. advertencia 4.3) y que aproximado puede ser mejor que exacto (Agresti and Coull, 1998). Esto es justamente lo que destacan Fagerland et al. (2013) al comparar métodos aproximados contra un método exacto.
La prueba as exhibió tasas de error cercanas a la nominal para la mayoría de parámetros, excediéndolos a menudo, pero no por mucho. Su desempeño fue particularmente destacado para muestras con \(N\le30,\) en las que únicamente excedió el nivel de significancia nominal en un 3.7 % de los escenarios evaluados, sin que la tasa de error tipo I excediera en ningún caso el valor 0.0529.
Las pruebas ascc y ex se comportaron de manera muy similar en todos los escenario evaluados. Resultaron ser excesivamente conservadoras, exhibiendo, por tanto, las menores potencias. Los autores del estudio no recomiendan usarlas en ninguna situación.
La prueba exnc no excedió nunca el nivel de significancia nominal. No obstante, su potencia no fue muy alta para muestras con \(N\le30.\) Su mejor desempeño se presentó para muestras con \(30<N\le100.\)
La prueba midp no violó el nivel de significancia nominal en ninguno de los escenarios evaluados. Los autores del estudio la presentan como una excelente alternativa a la muchísimo más compleja prueba exnc.
Tip 5.2: ¡Recomendaciones!
Si \(N\le30,\) use la prueba as
Si \(30<N\le100,\) use la prueba exnc
Si \(N>100,\) use la prueba midp
No use nunca la prueba ex ni la prueba ascc
A continuación se ilustra la aplicación de las diferentes versiones de la prueba de McNemar con base en un ejemplo común.
Ejemplo 5.7
En un futuro muy, muy lejano, se quiere averiguar si hubo cambios en la proporción de apoyos que la orden PROGRES (por su denominación en inglés: Pan-Republican Order for Galactic Reawakening, Enlightenment, and Sporecasting) recibió en dos momentos clave de su liderazgo.
La tabla 5.14 contiene información proveniente de 20 planetas recogida al azar por el DANE (por su denominación en inglés: Digital Aggregator of Notable Events), relativa al apoyo ofrecido a la orden PROGRES en los años 20022 y 20026.
| Planeta | Apoyo 20022 |
Apoyo 20026 |
|---|---|---|
| 1 | Sí | No |
| 2 | No | No |
| 3 | No | Sí |
| 4 | Sí | Sí |
| 5 | No | No |
| 6 | No | No |
| 7 | Sí | No |
| 8 | No | No |
| 9 | No | No |
| 10 | No | No |
| 11 | Sí | No |
| 12 | Sí | No |
| 13 | Sí | No |
| 14 | Sí | Sí |
| 15 | Sí | No |
| 16 | No | No |
| 17 | Sí | No |
| 18 | No | No |
| 19 | No | No |
| 20 | Sí | No |
Teniendo en cuenta que la respuesta evaluada es de tipo dicotómico (apoyo/no apoyo), las frecuencias marginales de apoyo en cada año pueden modelarse mediante distribuciones binomiales, aunque estén vinculadas por la estructura de pareamiento.
La evolución de los apoyos en los dos momentos de interés puede contrastarse mediante el siguiente juego de hipótesis:
\[
H_0: p_{20022} = p_{20026}
\]
\[
H_a: p_{20022} \neq p_{20026}
\]
El análisis apropiado de esta información debe tener en cuenta la condición de pareamiento. De hecho, esa es la razón por la que se ha incluido el identificador Planeta en la tabla 5.14: para hacer notar que la información registrada en cada fila corresponde a una misma unidad. En esta base de datos se tienen 20 pares de observaciones.
Los resultados de esta muestra pareada se compilan en una tabla \(2 \times 2\) (tabla 5.15):
| 20026 | |||
\(\\\) \(\\\) \(\\\) 20022 |
No apoyó | Sí apoyó | |
| No apoyó | 9 | 1 | |
| Sí apoyó | 8 | 2 | |
Total de pares de observaciones
En una tabla de contingencia para datos pareados, el número total de pares de datos (20 en la tabla tabla 5.15) se obtiene sumando las frecuencias de todas las celdas.
Prueba asintótica de McNemar
Se calcula el estadístico de prueba con base en la expresión 5.16:
\[
\chi^2_\text{c} = \frac{(b-c)^2}{b+c}= \frac{(1-8)^2}{1+8}=5.44
\]
El valor p se calcula como el área a la derecha del estadístico de prueba:
pchisq(5.44, 1, lower.tail = FALSE)[1] 0.01968067Prueba asintótica de McNemar con corrección por continuidad
Se calcula el estadístico de prueba con base en la expresión 5.17:
\[
\chi^2_\text{c} = \frac{(|b-c|-1)^2}{b+c}=\frac{(|1-8|-1)^2}{1+8}=4
\]
El valor p se calcula como el área a la derecha del estadístico de prueba:
pchisq(4, 1, lower.tail = FALSE)[1] 0.04550026Prueba exacta condicional de McNemar
El valor p se calcula con base en la expresión 5.18, con \(n=1+8=9\) y \(\text{mín}(b,\,c)=1.\)
\[
\text{valor p}=2\sum\limits_{i=0}^{\text{mín}(b,\,c)} {{n}\choose{i}}0.5^i(1-0.5)^{n-i}
\]
2 * pbinom(1, 9, prob = 0.5)[1] 0.0390625Prueba mid-p de McNemar
El valor p se calcula con base en la expresión 5.19, con \(n=1+8=9\) y \(\text{mín}(b,\,c)=1:\)
\[
\text{valor p}=2\sum\limits_{i=0}^{\text{mín}(b,\,c)} {{n}\choose{i}}0.5^i\times0.5^{n-i}-{{n}\choose{b}}0.5^b\times0.5^{n-b}
\]
2 * pbinom(1, 9, prob = 0.5) - dbinom(1, 9, prob = 0.5)[1] 0.02148437Prueba exacta no condicional de McNemar
Por su complejidad, su cálculo manual resulta impracticable.
En conclusión
Para el presente ejemplo, los resultados, en términos del valor p, son relativamente similares.
Para un nivel de significancia \(\alpha=0.05,\) cualquiera de las pruebas ilustradas anteriormente da lugar al rechazo de la hipótesis nula, es decir, que puede afirmarse, con baja probabilidad de error, que hubo un cambio en el apoyo brindado a la orden PROGRES en los dos periodos evaluados.
5.3.2.6 Uso de R para la comparación de dos proporciones binomiales usando muestras pareadas
La función personalizada mcnemar facilita la realización de las cinco pruebas expuestas en las secciones anteriores. Por defecto, se realiza la prueba recomendada, acorde con el número de observaciones pareadas (cf. tip 5.2), así:
Si \(N\le30,\) se usa la prueba asintótica de McNemar
Si \(30<N\le100,\) se usa la prueba exacta no condicional de McNemar
Si \(N>100,\) se usa la prueba mid-p de McNemar
Esta es la sintaxis de la función mcnemar:
mcnemar(method = c("rec", "as", "ascc", "ex", "midp", "exnc"), data = NULL)La función puede leer la información de entrada desde dos formatos diferentes:
- Un data frame con las muestras pareadas conformadas por datos binarios. La información de las dos muestras debe estar contenida en las dos primeras columnas del data frame. Puede usarse cualquier par de números o cadenas de caracteres como marcadores dicotómicos de las categorías que se comparan.
¡Preste atención al formato del data frame!
Aunque la tabla 5.14 contiene un identificador muestral en la primera columna (Planeta), mediante el cual se enfatiza la naturaleza pareada de las muestras, los data frames que se usen como valores del argumento data deben contener únicamente la información de las dos muestras, sin ningún tipo de identificador para las observaciones.
- Una matriz de dos filas y dos columnas con una tabla de contingencia \(2 \times 2\) que contenga las frecuencias de cada una de las 4 posibles combinaciones de las 2 categorías en las 2 muestras.
A continuación se ilustra el uso de la función mcnemar para analizar los datos del ejemplo 5.7, leyendo la información de las muestras pareadas desde un data frame:
La primera línea importa a un data frame los datos presentados en la tabla 5.14 —sin incluir el identificador de cada muestra—, los cuales están contenidos en el archivo Excel ejemplo 5.7.xlsx.
La segunda línea carga la función personalizada mcnemar. La tercera línea invoca la función, con todos sus argumentos por defecto: se aplica la prueba recomendada, acorde con el tamaño de muestra, y se busca la información en un objeto llamado data.
La prueba recomendada para una muestra de tamaño \(N=20\) es la asintótica (cf. tip 5.2). Esta es, por tanto, la prueba que la función mcnemar aplica automáticamente para procesar los datos del ejemplo 5.7. Igualmente, esta sería la prueba realizada si se hubiera usado el argumento method = "as".
Se obtiene el siguiente resultado:
Prueba de McNemar
Método asintótico
Ji cuadrado calculado = 5.444 (1 gl)
valor p = 0.01963066 A continuación se ilustran los resultados de las otras cuatro pruebas.
Método asintótico con corrección
data <- readxl::read_excel("ejemplo 5.7.xlsx")
source("mcnemar.R")
mcnemar("ascc")Prueba de McNemar
Método asintótico con corrección
Ji cuadrado calculado = 4 (1 gl)
valor p = 0.04550026 Método exacto
source("mcnemar.R")
data <- readxl::read_excel("ejemplo 5.7.xlsx")
mcnemar("ex")Prueba de McNemar
Método exacto
valor p = 0.0390625 Método mid-p
source("mcnemar.R")
data <- readxl::read_excel("ejemplo 5.7.xlsx")
mcnemar("midp")Prueba de McNemar
Método mid-p
valor p = 0.02148437 Método exacto no condicional
source("mcnemar.R")
data <- readxl::read_excel("ejemplo 5.7.xlsx")
mcnemar("exnc")Prueba de McNemar
Método exacto no condicional
Z calculado = -2.333
valor p = 0.02017002
¿Y si los datos están en una tabla \(2\times2\)?
El argumento data de la función mcnemar también admite el ingreso de información consolidada en una tabla \(2\times2.\) Para ello debe usarse un objeto de la clase matrix. Hay varias maneras de hacerlo.
Si la información está organizada inicialmente en un archivo Excel, es necesario importarla y convertirla en una matriz antes de usarla como argumento de la función mcnemar21.
A continuación se ilustra esta opción, leyendo la segunda hoja del archivo Excel ejemplo 5.7.xlsx, que contiene los datos presentados en la tabla 5.15. Las frecuencias consolidadas están en las dos primeras columnas del archivo Excel, cada una de las cuales tiene un encabezado. Este encabezado, aunque no desempeña ningún rol en los cálculos de la prueba de McNemar, evita mensajes molestos durante la importación.
data <- as.matrix(readxl::read_excel("ejemplo 5.7.xlsx", sheet = 2))
print(data) No apoyó Sí apoyó
[1,] 9 1
[2,] 8 2Si no se usaran encabezados para las columnas, sería necesario agregar el argumento, col_names = FALSE, con lo cual se evitaría que se tomara la primera fila como encabezado.
A continuación se ilustra esta opción, leyendo la tercera hoja del archivo Excel ejemplo 5.7.xlsx, que contiene las frecuencias presentadas en la tabla 5.15, sin encabezado. Nótense los mensajes molestos a los que se hacía referencia anteriormente.
data <- as.matrix(readxl::read_excel("ejemplo 5.7.xlsx", sheet = 3,
col_names = FALSE))New names:
• `` -> `...1`
• `` -> `...2`print(data) ...1 ...2
[1,] 9 1
[2,] 8 2Otra opción consiste en incorporar directamente en el script de R las 4 frecuencias que definen la tabla de contingencia, sin necesidad de importarla.
En este caso, se define una matriz, a la que podrían agregársele los atributos de nombre de las dimensiones y nombres de las categorías de cada una de las dimensiones definidas.
Estos atributos tienen una función meramente estética, haciendo que la matriz tenga un aspecto similar al de la tabla 5.15.
data <- matrix(c(9, 1, 8, 2), nrow = 2, byrow = TRUE,
dimnames = list("20022" = c("No", "Sí"),
"20026" = c("No", "Sí")))
print(data) 20026
20022 No Sí
No 9 1
Sí 8 2También es posible nombrar las filas y las columnas de la matriz tras haberla definido. De nuevo, estos nombres no tienen más que una función estética:
data <- matrix(c(9, 1, 8, 2), nrow = 2, byrow = TRUE)
rownames(data) <- c("No", "Sí")
colnames(data) <- c("No", "Sí")
print(data) No Sí
No 9 1
Sí 8 2La manera más sencilla de incorporar la información es creando una matriz que contenga únicamente las cuatro frecuencias \((a,\) \(b,\) \(c\) y \(d),\) sin nombrar las dimensiones, ni las filas, ni las columnas:
data <- matrix(c(9, 1, 8, 2), nrow = 2, byrow = TRUE)
print(data) [,1] [,2]
[1,] 9 1
[2,] 8 2Cualquiera de las matrices data construidas anteriormente puede usarse como valor del argumento data en la función mcnemar, bien sea creando la matriz antes de la invocación de la función o definiéndola directamente en la invocación:
source("mcnemar.R")
mcnemar(data = matrix(c(9, 1, 8, 2), nrow = 2, byrow = TRUE)) La función detecta, a través de la clase del objeto data, el formato en el que se han ingresado los datos, sin necesidad de ninguna especificación adicional.
5.4 Tablas de contingencia
Las tablas de contingencia constituyen la herramienta por excelencia para organizar y contrastar información de variables categóricas (cf. sección 1.2.2.1).
Las más comunes son las bidimensionales o de dos vías, es decir, las que cruzan la información de dos variables categóricas. Las categorías de una de las variables se organizan en filas; las de la otra, en columnas. Al interior de la tabla se presentan las frecuencias de aparición de las diferentes combinaciones de categorías de las dos variables. En tal sentido, las tablas de contingencia también son tablas de frecuencias (cf. sección 2.2).
¡Las más sencillas!
Entre las tablas bidimensionales, las más sencillas son las \(2\times2,\) es decir, las que cruzan dos variables dicotómicas.
A continuación se ilustra el uso de una tabla de contingencia \(2\times2\) para compilar la información de una encuesta aplicada a un grupo de personas seleccionadas al azar, a quienes se les preguntó por el hábito de fumar y si habían presentado estados depresivos en los últimos seis meses. Las respuestas a ambas preguntas se registraron de manera dicotómica (sí/no).
Las categorías de la variable hábito de fumar se organizaron en filas, dejando para las columnas las categorías de la variable depresión. No obstante, podrían haberse organizado al contrario sin que ello cambiara la esencia de la tabla.
| Sí presentó depresión |
No presentó depresión |
|
| Sí fuma | 14 | 37 |
| No fuma | 41 | 253 |
Las tablas de contingencia \(2\times2\) pueden usarse igualmente para organizar la información de un ensayo binomial como el que se describe en el ejemplo 5.6.
En estos casos, la población es una de las variables categóricas, siendo la membresía a una u otra población el criterio dicotómico para esta variable (población tratada, población no tratada). La otra variable es la condición evaluada en este tipo de ensayos: estado de preñez, con categorías preñada y no preñada.
| Preñadas | No preñadas | |
| Tratadas | 57 | 93 |
| No tratadas | 35 | 65 |
5.4.1 Prueba ji cuadrado para tablas \(2\times2\)
Más allá de su valor descriptivo, las tablas de contingencia suelen tener un propósito inferencial. Mediante su análisis se busca responder si existe relación entre las dos variables categóricas.
Dependiendo de cómo se haya realizado el ensayo o recolectado la información, esta pregunta puede plantearse de dos maneras: como una prueba de independencia entre las dos variables o como una prueba de homogeneidad de las distribuciones de frecuencias de una de las variables categóricas cuando se consideran en las diferentes categorías de la otra variable.
Prueba de independencia. Surge cuando se toman muestras aleatorias de un conjunto de unidades muestrales, y se registran los resultados de dos variables categóricas, sin haber prefijado el tamaño de ninguno de los grupos.
Este sería el caso del ensayo mediante el cual se buscaba establecer la asociación entre el hábito de fumar y los estados depresivos. Cada individuo fue elegido al azar, sin preseleccionar ni el número de individuos dentro de cada categoría de la variable hábito de fumar, ni dentro de cada categoría de la variable estados depresivos.
La hipótesis nula es que las dos variables analizadas (hábito de fumar y estados depresivos) son independientes; la hipótesis alternativa es que las dos variables son dependientes.
Prueba de homogeneidad. En estos casos se parte de dos grupos de tamaño predeterminado. A cada uno de los elementos muestrales de cada grupo se le evalúa una respuesta dicotómica.
En el ejemplo 5.6 se predefinió el tamaño de cada una de las muestras: 150 búfalas que recibirían el tratamiento hormonal y 100 búfalas que se usarían como control. A cada una de las búfalas de los dos grupos se le registró el resultado de la variable dicotómica estado de preñez (preñada, no preñada).
La hipótesis nula es que la proporción de individuos (búfalas) en las diferentes categorías (preñadas/no preñadas) es la misma en los dos grupos (tratadas y sin tratar). La hipótesis alternativa es que las proporciones difieren en los dos grupos.
Este acercamiento conceptual es bastante similar al que se realiza cuando se comparan dos proporciones binomiales. Nótese que basta con reformular el juego de hipótesis anterior, considerando como éxito la condición preñada.
La hipótesis nula es que la proporción de éxitos es igual en ambos grupos (que la proporción de búfalas preñadas es igual en el grupo tratado y en el no tratado).
La hipótesis alternativa es que la proporción de éxitos difiere entre las poblaciones comparadas (que la proporción de búfalas preñadas es diferente en el grupo tratado y en el grupo sin tratar).
En última instancia…
Cualquiera que sea la forma en la que se conceptualice la prueba —como prueba de homogeneidad o como prueba de independencia— la hipótesis nula puede pensarse en términos de que las dos variables consideradas no están relacionadas; la hipótesis alternativa será que las variables sí están relacionadas.
En cualquier caso, sea que el juego de hipótesis se conceptualice como una prueba de homogeneidad o de independencia, se usa el mismo procedimiento inferencial.
La prueba en cuestión está basada en la comparación entre las frecuencias observadas (las que aparecen en la tabla de contingencia) y las esperadas bajo la hipótesis nula, es decir, las que se obtendrían bajo la hipótesis de homogeneidad de las distribuciones o de independencia entre las dos variables.
Sea cual sea la conceptualización, las frecuencias esperadas bajo la hipótesis nula se calculan a partir de los totales marginales, es decir, los totales de las categorías fila y de las categorías columna.
Considérese la siguiente nomenclatura para representar las frecuencias de cada celda y las frecuencias totales.
| columna 1 | columna 2 | Totales fila | |
|---|---|---|---|
| fila 1 | \(f_{11}\) | \(f_{12}\) | \(f_{1\bullet}\) |
| fila 2 | \(f_{21}\) | \(f_{22}\) | \(f_{2\bullet}\) |
| Totales columna | \(f_{\bullet1}\) | \(f_{\bullet2}\) | \(f_{\bullet\bullet}\) |
El valor de la frecuencia esperada de la \(ij\)-ésima celda se calcula como el producto de las frecuencias totales de su correspondiente fila y columna, dividido por total general.
\[
E_{ij}\equiv E(f_{ij}) = \frac{f_{i\bullet}\,f_{\bullet j}}{f_{\bullet\bullet}}
\]
En la siguiente tabla se presenta, de manera genérica, el cálculo de las frecuencias esperadas para cada celda.
| columna 1 | columna 2 | |
|---|---|---|
| fila 1 | \(\frac{f_{1\bullet}\,f_{\bullet 1}}{f_{\bullet\bullet}}\) | \(\frac{f_{1\bullet}\,f_{\bullet 2}}{f_{\bullet\bullet}}\) |
| fila 2 | \(\frac{f_{2\bullet}\,f_{\bullet 1}}{f_{\bullet\bullet}}\) | \(\frac{f_{2\bullet}\,f_{\bullet 2}}{f_{\bullet\bullet}}\) |
El estadístico de prueba se calcula con base en la siguiente expresión:
\[
\chi^2_\text{c}=\sum_{i=1}^r\sum_{j=1}^c\frac{(O_{ij}-E_{ij})^2}{E_{ij}},
\tag{5.20}\]
en la que \(r\) representa el número de filas; \(c,\) el número de columnas; \(O_{ij},\) la \(ij\)-ésima frecuencia observada, y \(E_{ij},\) la \(ij\)-ésima frecuencia esperada.
Bajo la hipótesis nula y para tamaños de muestra grandes, la distribución aproximada del estadístico de prueba es \(\chi^2_{\big((r-1)(c-1)\big)}.\)
En particular, el estadístico de prueba que se obtiene de una tabla \(2\times2\) sigue una distribución ji cuadrado con 1 grado de libertad cuando la hipótesis nula es cierta.
El valor p se calcula como la probabilidad de obtener un valor igual o más extremo que el del estadístico de prueba, es decir, la probabilidad de un valor mayor que el del estadístico de prueba.
¿¡Y, por qué mayor!?
El numerador de la expresión 5.20, al ser una diferencia cuadrática, recoge de la misma manera las inconsistencias entre las frecuencias observadas y las esperadas bajo la hipótesis nula, sin importar el sentido de las mismas.
Mientras mayores sean las inconsistencias entre las frecuencias observadas y las esperadas, mayor será el valor de \(\chi^2_\text{c}\) y menos probable será que las variables no estén relacionadas.
Es por esta razón que el valor p se calcula como la probabilidad de obtener un valor mayor que \(\chi^2_\text{c}\) en la distribución de referencia.
Ejemplo 5.8
Reexaminemos el ejemplo 5.6: se estudia el efecto de un tratamiento hormonal para mejorar el porcentaje de preñez en búfalas. Para ello, se sometieron 150 hembras al tratamiento, de las cuales 57 alcanzaron el estado de preñez y 93 no. Por otra parte, se mantuvieron 100 hembras como control, de las cuales 35 quedaron preñadas y 65 no.
La tabla 5.16 compila esta información, junto con los totales marginales.
| Grupo | Preñadas | No preñadas | Totales grupo |
|---|---|---|---|
| Tratado | 57 | 93 | 150 |
| Control | 35 | 65 | 100 |
| Totales Preñez | 92 | 158 | 250 |
A continuación se presentan las frecuencias observadas y, después de la coma, las esperadas en cada celda.
| Grupo | Preñadas | No preñadas | Totales grupo |
|---|---|---|---|
| Tratado | \(57,\frac{150\times 92}{250}\) | \(93,\frac{150\times 158}{250}\) | 150 |
| Control | \(35,\frac{100\times 92}{250}\) | \(65,\frac{100\times 158}{250}\) | 100 |
| Totales Preñez | 92 | 158 | 250 |
En la siguiente tabla se omiten los totales marginales, dejando únicamente las frecuencias observadas y las esperadas de cada celda.
| Grupo | Preñadas | No preñadas |
|---|---|---|
| Tratado | 57, \(\quad\) 55.2 | 93, \(\quad\) 94.8 |
| Control | 35, \(\quad\) 36.8 | 65, \(\quad\) 63.2 |
El estadístico de prueba se calcula mediante la expresión 5.20:
\[ \begin{align} \chi^2_\text{c}&=\frac{(57-55.2)^2}{55.2}+\frac{(93-94.8)^2}{94.8}+\frac{(35-36.8)^2}{36.8}+\frac{(65-63.2)^2}{63.2}\\[1.4em] &=0.05869565+0.03417722+0.08804348+0.05126582\\[1.4em] &=0.23218217 \end{align} \]
Puesto que, bajo la hipótesis nula, el estadístico de prueba sigue una distribución \(\chi^2_{(1)},\) el valor p se obtiene así:
pchisq(0.23218217, 1, lower.tail = FALSE)[1] 0.6299105
Tip 5.3: ¡Como parecido al valor p del método de Wald!, ¿no?
La prueba ji cuadrado de homogeneidad es equivalente a la prueba de Wald para comparar dos proporciones binomiales (cf. sección 5.3.1.1).
La razón por la que los valores p obtenidos en el ejemplo 5.8 son solo similares a los del ejemplo 5.6, y no exactamente iguales, es que la equivalencia se establece entre la prueba ji cuadrado de homogeneidad y el estadístico de prueba de Wald calculado a partir de la varianza conjunta (cf. nota 5.2).
A continuación se verifica la equivalencia numérica entre \(Z_\text{W}\) y \(\chi_\text{c}^2,\) así como entre los valores p generados, para los datos del ejemplo 5.6:
El estimador conjunto de la probabilidad de éxito es:
\[
\hat{p}=\frac{x_1+x_2}{n_1+n_2}=\frac{57+35}{150+100}=\frac{92}{250}=0.368
\]
El estadístico de prueba de Wald que usa el estimador conjunto de la probabilidad de éxito se calcula así:
\[
\begin{align}
Z_\text{W}&=\frac{\hat{p}_1-\hat{p}_2}{\sqrt{\hat{p}(1-\hat{p})\left(\frac{1}{n_1}+\frac{1}{n_2}\right)}}\\[1.4em]
&=\frac{0.38-0.35}{\sqrt{0.368(1-0.368)\left(\frac{1}{150}+\frac{1}{100}\right)}}\\[1.4em]
&=0.48185285
\end{align}
\]
El valor p se obtiene así:
2 * pnorm(0.48185285, lower.tail = FALSE)[1] 0.6299105Nótese que este valor coincide con el obtenido mediante la prueba ji cuadrado de homogeneidad.
Asimismo, puede verificarse la equivalencia numérica entre los estadísticos de prueba:
\[
Z_\text{W}=0.48185285\Rightarrow Z_\text{W}^2=(0.48185285)^2=0.2321822=\chi^2_\text{c}
\]
El paso distribucional de una normal estándar a una ji cuadrado con un grado de libertad está explicado por la expresión 3.7.
Bajo la hipótesis nula, \(Z_\text{W}\) se distribuye \(N(0,\,1);\) luego, \(Z_\text{W}^2\) se distribuye \(\chi^2_{(1)}.\)
La demostración general de la equivalencia entre estas dos pruebas es un tanto más elaborada. Sin embargo, puede resultar entretenida.
Precaución 5.2: ¡No la use…!
Dada la equivalencia entre la prueba ji cuadrado de homogeneidad y la prueba de Wald, y considerando que esta última se ha desaconsejado para la comparación de proporciones binomiales (cf. advertencia 5.5), también se desaconseja el uso de la prueba ji cuadrado para la comparación de variables categóricas con 2 niveles, si el muestreo se realizó con tamaños de grupo predeterminados (prueba de homogeneidad).
En su lugar, se recomienda formular el problema como una comparación de dos proporciones binomiales y utilizar el método del score híbrido de Newcombe (cf. nota 5.3).
La prueba de ji cuadrado sigue siendo pertinente, sin embargo, para realizar pruebas de independencia, en situaciones en las que los tamaños de grupo no hayan sido prefijados por el diseño del estudio.
Ejemplo 5.9
Un estudio busca evaluar la posible relación entre el hábito de fumar y la presencia de estados depresivos. Para ello, se aplicó una encuesta a un grupo de personas seleccionadas al azar, a quienes se les preguntó por el hábito de fumar y si habían presentado estados depresivos en los últimos seis meses. Las respuestas a ambas preguntas se registraron de manera dicotómica (sí/no) y se resumen en la tabla 5.18.
| Hábito de fumar | Sí presentó depresión | No presentó depresión | Totales hábito de fumar |
|---|---|---|---|
| Sí fuma | 14 | 37 | 51 |
| No fuma | 41 | 253 | 294 |
| Totales depresión | 55 | 290 | 345 |
En este caso, puesto que la muestra se tomó al azar, sin prefijar el tamaño de ninguno de los grupos, la pregunta relativa a la relación entre las dos variables categóricas se responde mediante una prueba de independencia.
\(H_0:\) hábito de fumar y depresión son independientes
\(H_a:\) existe dependencia entre el hábito de fumar y depresión
A continuación se presentan las frecuencias observadas junto con las frecuencias esperadas (después de la coma) en cada celda.
| Hábito de fumar | Sí presentó depresión | No presentó depresión | Totales hábito de fumar |
|---|---|---|---|
| Sí fuma | \(14,\frac{51\times 55}{345}\) | \(37,\frac{51\times 290}{345}\) | 51 |
| No fuma | \(41,\frac{294\times 55}{345}\) | \(253,\frac{294\times 290}{345}\) | 294 |
| Totales depresión | 55 | 290 | 345 |
En la siguiente tabla se omiten los totales marginales, dejando únicamente las frecuencias observadas y las esperadas de cada celda.
| Hábito de fumar | Sí presentó depresión | No presentó depresión |
|---|---|---|
| Sí fuma | 14, \(\quad\) 8.1304 | 37, \(\quad\) 42.8696 |
| No fuma | 41, \(\quad\) 46.8696 | 253, \(\quad\) 247.1304 |
El estadístico de prueba se calcula mediante la expresión 5.20:
\[
\begin{multline}
\chi^2_\text{c}=\frac{(14-8.1304)^2}{8.1304}
+\frac{(37-42.8696)^2}{42.8696}\\
+\frac{(41-46.8696)^2}{46.8696}
+\frac{(253-247.1304)^2}{247.1304}\\
\end{multline}
\]
\[
\chi^2_\text{c}=4.237455+0.803651+0.735065+0.139409=5.91558
\]
Puesto que, bajo la hipótesis nula, el estadístico de prueba sigue una distribución \(\chi^2_{(1)},\) el valor p se obtiene así:
pchisq(5.91558, 1, lower.tail = FALSE)[1] 0.01500756Dado que el valor p es menor que 0.05, se rechaza la hipótesis nula de independencia, lo que sugiere evidencia de asociación entre el hábito de fumar y la presencia de estados depresivos.
Los anteriores resultados pueden obtenerse en R mediante la función chisq.test:
x <- matrix(c(14, 37, 41, 253), nrow = 2, byrow = TRUE)
chisq.test(x, correct = FALSE)
Pearson's Chi-squared test
data: x
X-squared = 5.9155, df = 1, p-value = 0.01501
En resumen…
Cuando se tiene una tabla de contingencia \(2\times2\) correspondiente a un estudio en el que se hayan fijado previamente los tamaños de las categorías de cada una de las variables, la prueba de homogeneidad ji cuadrado es equivalente a la prueba de Wald usando la varianza conjunta (cf. sección 5.3.1.1 y nota 5.2).
En consecuencia, se desaconseja su uso. En su lugar se recomienda enfocar el problema como una comparación de dos proporciones binomiales y usar el método del score híbrido de Newcombe (cf. sección 5.3.1.3).
Por otra parte, la prueba ji cuadrado es la más pertinente para realizar pruebas de independencia, en situaciones en las que el muestreo no haya implicado la fijación previa de los tamaños de grupo.
5.4.2 Prueba ji cuadrado para tablas \(2\times k\)
Las tablas \(2\times k\) surgen al organizar la información de dos variables categóricas: una con 2 categorías, usualmente dispuestas en las filas, y otra con \(k\) categorías, dispuestas en las columnas.
De acuerdo con lo indicado en la sección 5.4.1, el procedimiento inferencial para evaluar la relación entre las dos variables depende de la manera en la que se haya realizado el estudio o recolectado la información.
Se plantea como una prueba de independencia cuando se toma una muestra aleatoria de un conjunto de unidades muestrales, sin haber prefijado el tamaño de los grupos.
En este caso se plantea el siguiente juego de hipótesis:
\[
\begin{align}
H_0&: \text{las variables son independientes}\\[1.4em]
H_a&: \text{las variables no son independientes}
\end{align}
\]
En contraste, cuando se dispone de muestras aleatorias de tamaño predeterminado para cada una de las \(k\) categorías de una variable, y sobre cada elemento muestral se registra una respuesta dicotómica, se plantea como una prueba de homogeneidad.
Esta conceptualización permite expresar la comparación mediante el siguiente juego de hipótesis:
\[
\begin{align}
H_0&: p_1=p_2=\dotsb=p_k\\[1.4em]
H_a&: \text{al menos dos proporciones difieren entre sí}
\end{align}
\]
En ambos casos, el contraste puede formularse mediante el estadístico de prueba ji cuadrado (cf. expresión 5.20) obtenido a partir de la correspondiente tabla de contingencia \(2\times k.\)
Bajo la hipótesis nula:
\[
\chi^2_\text{c} \thicksim \chi^2_{(k-1)}
\]
Ejemplo 5.10
Considérese un estudio en el que se desea evaluar la posible relación entre las siguientes variables:
Leucosis bovina: con categorías negativa y positiva
Linfocitosis: con categorías puntual, persistente y negativa
| Leucosis bovina | Linfo. puntual | Linfo. persistente | Linfo. negativa | Totales Leucosis bovina |
|---|---|---|---|---|
| Negativa | 12 | 12 | 40 | 64 |
| Positiva | 39 | 23 | 74 | 136 |
| Totales Linfocitosis | 51 | 35 | 114 | 200 |
La información se recolectó sin predefinir el tamaño de los grupos, por lo cual la hipótesis nula es de independencia entre leucosis bovina y linfocitosis.
La siguiente tabla presenta las frecuencias observadas, seguida, después de la coma, de las frecuencias esperadas.
| Leucosis bovina | Linf. puntual | Linf. persistente | Linf. negativa | Totales Leucosis bovina |
|---|---|---|---|---|
| Negativa | 12, 16.32 | 12, 11.2 | 40, 36.48 | 64 |
| Positiva | 39, 34.68 | 23, 23.8 | 74, 77.52 | 136 |
| Totales Linfocitosis | 51 | 35 | 114 | 200 |
El estadístico calculado es:
\[
\chi^2_\text{c}=2.26517852
\]
Dado que la variable linfocitosis tiene \(k=3\) categorías, los grados de libertad son 2.
El valor p se obtiene así:
pchisq(2.26517852, 2, lower.tail = FALSE)[1] 0.3221979Puesto que el valor p es mayor de 0.05, no se rechaza la hipótesis nula de independencia. En consecuencia, no se encuentra evidencia estadísticamente significativa de asociación entre la leucosis bovina y la linfocitosis.
Esta prueba puede realizarse en R mediante la función chisq.test{stats}.
Inicialmente debe organizarse la información en una matriz o data frame, sea que se importe o se genere directamente.
La correspondiente matriz para el presente ejemplo se genera así:
data <- matrix(c(12, 12, 40, 39, 23, 74), nrow = 2, byrow = TRUE)
rownames(data) <- c("Negativa", "Positiva")
colnames(data) <- c("Linf. puntual", "Linf. persistente", "Linf. negativa")
print(data) Linf. puntual Linf. persistente Linf. negativa
Negativa 12 12 40
Positiva 39 23 74chisq.test(data, correct = FALSE)
Pearson's Chi-squared test
data: data
X-squared = 2.2652, df = 2, p-value = 0.3222Dado que \(\text{p} = 0.3222,\) no se rechaza la hipótesis nula de independencia. Por lo tanto, no se encuentra evidencia estadísticamente significativa de asociación entre las variables.
¿¡Y si hubiera resultado significativo!?
Cuando el contraste global resulta significativo, puede examinarse la contribución de cada celda al valor del estadístico ji cuadrado mediante los residuos estandarizados ajustados. Este análisis permite identificar qué categorías explican la dependencia observada.
La metodología general para realizar este desglose se presenta en la sección 5.4.3.
¿¡Y si se tratara de una prueba de homogeneidad!?
El estadístico de prueba se calcularía igualmente mediante expresión 5.20. No obstante, tal y como se ilustró en el tip 5.3, la prueba ji cuadrado también correspondería en este caso a una prueba de Wald con varianza conjunta.
Siendo consistentes con lo indicado en la precaución 5.2, desaconsejamos el uso de la prueba ji cuadrado (o Wald) para la comparación de proporciones binomiales.
Se recomienda realizar la comparación de proporciones binomiales —sean dos o más—, mediante el método del score híbrido de Newcombe. Debe tenerse en cuenta, sin embargo, que cuando se comparan más de dos proporciones, se requiere aplicar un ajuste para controlar el incremento de la tasa de error tipo I por familia (cf. sección 8.10).
En tablas de contingencia \(2\times k\), la prueba ji cuadrado deberá usarse únicamente como prueba de independencia, es decir, cuando no se hayan predefinido los tamaños de los grupos.
5.4.3 Prueba ji cuadrado para tablas \(r\times c\)
Al cruzar la información de dos variables categóricas en una tabla de contingencia, con las categorías de una de ellas dispuestas en las filas (rows) y las de la otra en las columnas (columns), se obtiene una tabla \(r\times c.\)
Análogamente a lo expuesto en las secciones 5.4.1 y 5.4.2, el juego de hipótesis guarda correspondencia con la manera en que se haya recolectado la información: prueba de independencia cuando se realiza un muestreo sin predefinir tamaños de grupos, y prueba de homogeneidad cuando el tamaño de los grupos conformados por las categorías de alguna de las variables ha sido predefinido.
Cuando se fijan por diseño los tamaños de los grupos correspondientes a alguna de las variables (prueba de homogeneidad) surge un modelo que, aunque análogo al modelo binomial considerado en las tablas \(2\times k,\) presenta particularidades que deben examinarse.
Para el análisis de estas particularidades, consideremos inicialmente una tabla \(2 \times k,\) con tamaños prefijados para las categorías columna.
Supóngase que se desea realizar una prueba de homogeneidad para evaluar el apoyo a un partido político en relación con el nivel educativo del encuestado, definiendo la inclusión de 200 personas por nivel educativo:
| Apoyo al partido | Primaria | Secundaria | Profesional |
|---|---|---|---|
| Sí | \(a\) | \(b\) | \(c\) |
| No | \(d\) | \(e\) | \(f\) |
| Totales nivel educativo | 200 | 200 | 200 |
La variable apoyo al partido es dicotómica (sí/no). Si se define sí como éxito, la pregunta que se desea responder es si el apoyo al partido es homogéneo entre los niveles educativos evaluados o, en otras, palabras, si la probabilidad de apoyo al partido es la misma en los distintos niveles educativos:
\[
\begin{align}
H_0&: p_\text{primaria}=p_\text{secundaria}=p_\text{profesional}\\[1.4em]
H_a&: \text{al menos dos proporciones difieren entre sí}
\end{align}
\]
Puesto que este juego de hipótesis se construye sobre los parámetros de modelos binomiales, se mantiene la recomendación de utilizar pruebas de hipótesis basadas en el método del score híbrido de Newcombe, aplicando ajuste de Holm (cf. sección 5.4.2).
Consideremos ahora el caso de una tabla \(r\times c\) con \(r>2\) y \(c>2\), en la que se fijan por diseño los tamaños de los grupos.
Aunque es indiferente ubicar en filas o en columnas las categorías cuyos tamaños se fijan —dado que ambas disposiciones conducen al mismo resultado—, fijaremos los tamaños de las categorías columna para visualizar una extensión del ejemplo anterior.
Consideremos ahora una situación en la que, tras definir el tamaño de cada categoría de nivel educativo, se les consulta a los encuestados, su intención de voto por alguno de los partidos \(\text{A},\) \(\text{B},\) \(\text{C}\) o \(\text{ninguno}.\)
| Apoyo | Primaria | Secundaria | Profesional |
|---|---|---|---|
| \(\text{A}\) | \(a\) | \(b\) | \(c\) |
| \(\text{B}\) | \(d\) | \(e\) | \(f\) |
| \(\text{C}\) | \(g\) | \(h\) | \(i\) |
| \(\text{ninguno}\) | \(j\) | \(k\) | \(l\) |
| Totales nivel educativo | 200 | 200 | 200 |
La pregunta que se quiere responder en este escenario es si la distribución de los apoyos es homogénea entre los niveles educativos considerados.
En este caso, al no tener una respuesta dicotómica para la variable apoyo, sino una respuesta con múltiples opciones, ya no aplica el modelo binomial dentro de cada nivel educativo, sino un modelo multinomial, que en lugar de tener un único parámetro que representan la probabilidad de éxito, incluye una probabilidad asociada a cada una de las categorías posibles, cuya suma es igual a 1.
Así, por ejemplo, para el grupo de nivel educativo primaria se tendría el siguiente modelo para las variables aleatorias \(X_\text{A},\) \(X_\text{B},\) \(X_\text{C}\) y \(X_\text{ninguno},\) que representan las frecuencias de respuesta para cada una de las opciones de apoyo consideradas:
\[
\left(X_\text{A}, X_\text{B}, X_\text{C}, X_\text{ninguno}\right)\thicksim \text{multinomial}(n=200; p_\text{A}, p_\text{B}, p_\text{C}, p_\text{ninguno})
\]
La pregunta sobre la homogeneidad de los apoyos entre los niveles educativos es equivalente —en términos del modelo multinomial— a que el vector \((p_\text{A}, p_\text{B}, p_\text{C}, p_\text{ninguno})\) sea igual en los diferentes niveles educativos.
Si definimos \(p_{ij}\) como la probabilidad de que una observación seleccionada de la población \(j\) (ubicada en columnas) pertenezca a la categoría \(i\) (ubicada en filas), la forma general del juego de hipótesis, para una prueba de homogeneidad, basada en una tabla \(r\times c,\) con tamaños predefinidos para las poblaciones es:
\[
H_0: (p_{11}, p_{21}, \dotsc, p_{r1})=(p_{12}, p_{22}, \dotsc, p_{r2})=\dotsb=(p_{1c}, p_{2c}, \dotsc, p_{rc})
\] \[
Ha: \text{no todos los vectores de probabilidades son iguales entre sí}
\]
La hipótesis nula equivale a afirmar que todas las poblaciones comparten la misma distribución categórica.
Independientemente del diseño utilizado para recolectar la información en una tabla \(r\times c\) —ya sea que conduzca a una prueba de independencia o de homogeneidad—, el juego de hipótesis se contrasta mediante el mismo estadístico de prueba ji cuadrado (cf. expresión 5.20), cuya distribución bajo la hipótesis nula tiene \((r-1)(c-1)\) grados de libertad:
\[
\chi_\text{c}^2\overset {H_0}\thicksim \chi^2_{\big((r-1)(c-1)\big)}
\]
En contraste con el caso \(2\times k,\) en el que, al realizar pruebas de homogeneidad, puede aprovecharse la estructura binomial para efectuar comparaciones más eficientes entre proporciones, en tablas \(r\times c\) con \(r>2\) no existe una reducción análoga.
En consecuencia, la prueba basada en el estadístico ji cuadrado constituye la alternativa natural para contrastar la hipótesis de homogeneidad en tablas \(r\times c\) con \(r>2.\)
¡No son solo los cálculos!
Si bien es cierto que el estadístico de prueba y los cálculos numéricos son iguales, sin importar que el juego de hipótesis se haya formulado como prueba de homogeneidad o de independencia, se recomienda mantener en mente el modelo subyacente, de manera que las conclusiones estén acordes con el diseño utilizado.
Ejemplo 5.11
Un estudio busca comparar la composición de malezas en parcelas agrícolas bajo diferentes sistemas de manejo del suelo: labranza convencional, siembra directa y manejo integrado.
Se seleccionaron 50 parcelas independientes de \(100\,\text{m}^2\) dentro de cada sistema de manejo. En cada parcela se identificó el tipo de maleza predominante, clasificándola en una de las siguientes categorías: gramínea, hoja ancha, ciperácea o mixta.
Se tiene interés en determinar si la distribución del tipo de maleza predominante es la misma en los tres sistemas de manejo, o si existen diferencias en la composición de malezas entre ellos.
Teniendo presente que se fijó el tamaño de muestra para cada sistema de manejo (50 parcelas), la pregunta planteada corresponde a una prueba de homogeneidad.
La hipótesis nula establece que la distribución de probabilidades del tipo de maleza predominante es la misma en los tres sistemas de manejo. De manera expandida, puede visualizarse así:
\[
\begin{align}
H_0: &(p_\text{gramínea}, p_\text{hoja ancha}, p_\text{ciperácea}, p_\text{mixta})_\text{labranza convencional}\\[1.4em]
=&(p_\text{gramínea}, p_\text{hoja ancha}, p_\text{ciperácea}, p_\text{mixta})_\text{siembra directa}\\[1.4em]
=&(p_\text{gramínea}, p_\text{hoja ancha}, p_\text{ciperácea}, p_\text{mixta})_\text{manejo integrado}
\end{align}
\]
Esta escritura permite apreciar explícitamente que se comparan los vectores de probabilidades correspondientes a cada sistema de manejo. No obstante, la forma usual de expresar la hipótesis de homogeneidad es mediante notación vectorial:
\[
H_0: \boldsymbol{p}_\text{LC}=\boldsymbol{p}_\text{SD}=\boldsymbol{p}_\text{MI},
\]
donde \(\boldsymbol{p}_j\) denota el vector de probabilidades de las cuatro categorías de maleza en el sistema \(j.\)
La hipótesis alternativa plantea que no todos los vectores de probabilidades son iguales entre sí.
Bajo el modelo multinomial, el estadístico ji cuadrado surge como aproximación basada en la normalidad multivariante del vector de frecuencias.
Las frecuencias observadas se organizan en una tabla de contingencia \(4\times3:\)
| Tipo de maleza | Labranza convencional | Siembra directa | Manejo integrado | Totales maleza |
|---|---|---|---|---|
| Gramínea | 25 | 13 | 11 | 49 |
| Hoja ancha | 10 | 22 | 12 | 44 |
| Ciperácea | 7 | 8 | 14 | 29 |
| Mixta | 8 | 7 | 13 | 28 |
| Totales sistema | 50 | 50 | 50 | 150 |
Es importante aclarar que lo que configura una situación de homogeneidad no es que los totales de sistema resulten iguales22, sino que hayan sido fijados por diseño.
Incluso podría suceder que —por diseño— se hubieran prefijado diferentes tamaños muestrales para cada sistema (por ejemplo 50, 40, 35), y el escenario seguiría correspondiendo a una prueba de homogeneidad.
La siguiente tabla presenta las frecuencias observadas, seguidas por coma de las frecuencias esperadas, las cuales se calculan mediante el procedimiento que se detalla en la sección 5.4.1:
| Tipo de maleza | Labranza convencional | Siembra directa | Manejo integrado | Totales maleza |
|---|---|---|---|---|
| Gramínea | 25, 16.33 | 13, 16.33 | 11, 16.33 | 49 |
| Hoja ancha | 10, 14.67 | 22, 14.67 | 12, 14.67 | 44 |
| Ciperácea | 7, 9.67 | 8, 9.67 | 14, 9.67 | 29 |
| Mixta | 8, 9.33 | 7, 9.33 | 13, 9.33 | 28 |
| Totales sistema | 50 | 50 | 50 | 150 |
Nótese que, en este caso en el que los grupos de labranza son del mismo tamaño, las frecuencias esperadas son iguales para cada sistema. Esto se corresponde con la hipótesis de homogeneidad.
A continuación se calcula el estadístico de prueba, usando la expresión 5.20:
\[
\begin{align}
\chi^2_\text{c}&=\frac{(25-16.33)^2}{16.33}
+\frac{(10-14.67)^2}{14.67}
+\frac{(7-9.67)^2}{9.67}
+\frac{(8-9.33)^2}{9.33}\\[1.4em]
&=\frac{(13-16.33)^2}{16.33}
+\frac{(22-14.67)^2}{14.67}
+\frac{(8-9.67)^2}{9.67}
+\frac{(7-9.33)^2}{9.33}\\[1.4em]
&=\frac{(11-16.33)^2}{16.33}
+\frac{(12-14.67)^2}{14.67}
+\frac{(14-9.67)^2}{9.67}
+\frac{(13-9.33)^2}{9.33}
\end{align}
\]
\[
\begin{multline}
\chi^2_\text{c}=4.6031+1.4866+0.7372+0.1896\\
+0.6791+3.6625+0.2884+0.5819\\
+1.7397+0.4860+1.9389+1.4436
\end{multline}
\]
\[
\chi^2_\text{c}=17.8366
\]
Puesto que, bajo la hipótesis nula, el estadístico de prueba sigue una distribución ji cuadrado con \((4-1)(3-1)=6\) grados de libertad, el valor p se obtiene así:
pchisq(17.8366, 6, lower.tail = FALSE)[1] 0.006653781Los anteriores resultados pueden obtenerse en R mediante la función chisq.test:
x <- matrix(c(25, 13, 11,
10, 22, 12,
7, 8, 14,
8, 7, 13), nrow = 4, byrow = TRUE)
chisq.test(x, correct = FALSE)
Pearson's Chi-squared test
data: x
X-squared = 17.837, df = 6, p-value = 0.006654Puesto que el valor p es menor que el nivel de significancia habitual, se rechaza la hipótesis nula de homogeneidad. Por tanto, se concluye que la distribución de los tipos de maleza no es la misma en los tres sistemas de labranza.
No obstante, el estadístico ji-cuadrado global únicamente indica heterogeneidad entre las distribuciones23, pero no revela qué celdas contribuyen de manera sustantiva a dicha discrepancia.
Para identificar los patrones específicos que explican la significancia observada, se procede al análisis de los residuos estandarizados ajustados24.
La siguiente tabla recoge los elementos necesarios para el cálculo de los residuos estandarizados ajustados, incluyendo las proporciones marginales de fila y columna que intervienen en el denominador de la expresión 5.23.
| Tipo de maleza | Labranza convencional | Siembra directa | Manejo integrado | Proporción marginal maleza |
|---|---|---|---|---|
| Gramínea | 25, 16.33 | 13, 16.33 | 11, 16.33 | 0.3267 |
| Hoja ancha | 10, 14.67 | 22, 14.67 | 12, 14.67 | 0.2933 |
| Ciperácea | 7, 9.67 | 8, 9.67 | 14, 9.67 | 0.1933 |
| Mixta | 8, 9.33 | 7, 9.33 | 13, 9.33 | 0.1867 |
| Proporción marginal sistema | 0.3333 | 0.3333 | 0.3333 |
La siguiente tabla presenta los residuos estandarizados ajustados, calculados con base en la expresión 5.23 y redondeados a dos cifras decimales:
| Tipo de maleza | Labranza convencional | Siembra directa | Manejo integrado |
|---|---|---|---|
| Gramínea | 3.20 | -1.23 | -1.97 |
| Hoja ancha | -1.78 | 2.79 | -1.02 |
| Ciperácea | -1.17 | -0.73 | 1.90 |
| Mixta | -0.59 | -1.04 | 1.60 |
Los residuos estandarizados ajustados positivos indican que la frecuencia observada fue superior a la esperada bajo homogeneidad, mientras que los negativos dan cuenta de valores observados menores que los esperados.
Bajo \(H_0,\) los residuos estandarizados ajustados siguen una distribución aproximadamente normal estándar, lo que permite valorarlos objetivamente con base en lo esperado para esta distribución de referencia.
Aunque podría calcularse, bajo la hipótesis nula, la probabilidad asociada a un residuo estandarizado ajustado tan extremo como el observado, no es habitual abordar este análisis con pretensiones inferenciales formales debido a la multiplicidad de comparaciones implícitas. En su lugar, se utiliza el valor absoluto de 2 como guía interpretativa práctica para identificar celdas responsables de desviaciones relevantes.
Teniendo presente lo anterior, la tabla de residuos estandarizados ajustados permite observar que el rechazo de la hipótesis nula en el presente ejemplo está marcado principalmente por la mayor frecuencia de gramíneas en el sistema de labranza convencional y la mayor frecuencia de malezas de hoja ancha en el sistema de siembra directa.
También se observa una menor frecuencia de gramíneas bajo el sistema de manejo integrado, con un residuo estandarizado ajustado cercano al umbral interpretativo establecido, junto con una tendencia hacia una mayor proporción de ciperáceas en dicho sistema.
Los residuos estandarizados ajustados se obtienen en R mediante la función chisq.test{stats}. Aunque al ejecutar la función no se presentan directamente en la consola, pueden recuperarse desde el componente stdres de la lista que se genera al asignar los resultados de la función a un objeto.
x <- matrix(c(25, 13, 11,
10, 22, 12,
7, 8, 14,
8, 7, 13), nrow = 4, byrow = TRUE)
prueba <- chisq.test(x, correct = FALSE)
prueba$stdres [,1] [,2] [,3]
[1,] 3.2007021 -1.2310393 -1.969663
[2,] -1.7753312 2.7898062 -1.014475
[3,] -1.1695773 -0.7309858 1.900563
[4,] -0.5926956 -1.0372173 1.629913Antes de concluir esta sección, conviene detenerse en un aspecto fundamental que sustenta la validez de la aproximación asintótica del estadístico de prueba ji cuadrado: las frecuencias esperadas.
Bajo la hipótesis nula, el estadístico de prueba se distribuye aproximadamente como una ji cuadrado, siempre que las frecuencias esperadas no sean demasiado pequeñas.
Al igual que ocurre con los residuos estandarizados ajustados, las frecuencias esperadas se valoran con base en umbrales interpretativos prácticos que resumen décadas de experiencia metodológica y evidencia empírica sobre la robustez del procedimiento.
La recomendación más difundida consiste en verificar que todas las frecuencias esperadas sean mayores o iguales que 5. No obstante, esta regla suele ser más restrictiva de lo necesario.
Una formulación más matizada establece que ninguna frecuencia esperada debe ser menor que 1 y que no haya más del 20 % de las celdas pueden presentar valores esperados inferiores a 5. En el caso particular de tablas \(2\times 2,\) suele recomendarse que todas las frecuencias esperadas sean mayores o iguales que 10.
Esta segunda formulación es la que, en la práctica contemporánea, se considera una referencia estándar para juzgar la adecuación de la aproximación asintótica.
Frecuencias esperadas
Ninguna frecuencia esperada debe ser menor que 1.
La proporción de celdas con frecuencias esperadas menores que 5 no debe exceder el 20 %.
En tablas \(2\times 2,\) ninguna frecuencia esperada debe ser menor que 10.
En todos los ejemplos desarrollados en esta sección, la frecuencia esperada más baja superó holgadamente el umbral de 5, por lo que la aproximación mediante la distribución ji cuadrado resulta adecuada en cada uno de los casos analizados.
¿Y si no…?
Cuando no se satisfacen los criterios basados en las frecuencias esperadas, es necesario considerar alternativas metodológicas.
Agrupar categorías. Deben tenerse en cuenta dos aspectos: el operacional y el interpretativo. Para que esta estrategia constituya una solución efectiva, es necesario agrupar categorías con bajos valores esperados. No obstante, las nuevas categorías deben conservar sentido sustantivo e interpretabilidad.
Aplicar la prueba exacta de Fisher en tablas \(2\times 2\)
En tablas de mayor tamaño aplicar la prueba ji cuadrado con estimación del valor p mediante simulación Monte Carlo.
La prueba exacta de Fisher no depende de aproximaciones asintóticas. Se basa en la distribución hipergeométrica condicional a los márgenes y calcula de manera exacta la probabilidad de obtener tablas de contingencia iguales o más extremas que la observada bajo la hipótesis nula. Puede calcularse en R mediante la función fisher.test{stats}.
La estimación del valor p mediante simulación Monte Carlo tampoco depende de la aproximación asintótica de la distribución ji cuadrado. Viene implementada en la función chisq.test{stats} a través del argumento simulate.p.value, cuyo valor por defecto es FALSE. Para utilizar esta estrategia, debe asignársele el valor TRUE. Asimismo, se recomienda trabajar con un número de replicaciones (B) igual o superior a 10 000, con el fin de reducir la variabilidad inherente al procedimiento de simulación.
A continuación se presenta un resumen con los diferentes criterios de decisión para la evaluación de tablas de contingencia:
Criterio decisional
- Tablas \(2\times 2\):
- Homogeneidad: Score híbrido de Newcombe
- Independencia:
- Satisface criterio de frecuencias esperadas: Ji cuadrado asintótico
- No satisface criterio de frecuencias esperadas: Prueba exacta de Fisher
- Tablas \(2\times k\):
- Homogeneidad: Score híbrido de Newcombe con corrección de Holm
- Independencia:
- Satisface criterio de frecuencias esperadas: Ji cuadrado asintótico
- No satisface criterio de frecuencias esperadas: Ji cuadrado con estimación del valor p mediante simulación Monte Carlo
- Tablas \(r\times c\) con \(r>2\):
- Homogeneidad o independencia:
- Satisface criterio de frecuencias esperadas: Ji cuadrado asintótico
- No satisface criterio de frecuencias esperadas: Ji cuadrado con estimación del valor p mediante simulación Monte Carlo
- Homogeneidad o independencia:
5.5 Comparación de dos parámetros, usando intervalos de confianza individuales
Suele creerse que es posible contrastar los parámetros de dos poblaciones mediante la simple comparación de sus respectivos intervalos de confianza.
Si existe algún traslape entre tales intervalos, la interpretación habitual es que los parámetros no difieren significativamente. Si, por el contrario, los intervalos no se traslapan en ninguna región, se interpretaría como una diferencia significativa entre los parámetros.
Para ilustrar qué hay de cierto y de falso en este razonamiento, se considerará inicialmente el caso de dos poblaciones normales con varianzas homogéneas, cuyas medias se desea comparar a partir de muestras independientes. Al final de esta sección, los resultados se generalizan a otras situaciones.
La siguiente tabla resume las características muestrales de cada uno de los dos grupos.
| Muestra 1 | \(\overline{X}_1=5\) | \(S_1^2=625\) | \(n_1=100\) |
| Muestra 2 | \(\overline{X}_2=13\) | \(S_2^2=625\) | \(n_2=100\) |
Un intervalo de confianza del 95 % para \(\mu_1\) se construye así:
\[
\overline{X}_1\pm t_{0.025(99)}\sqrt\frac{S_1^2}{{n_1}}
= 5\pm 1.984217\sqrt\frac{625}{{100}}
=5\pm 4.96054
\]
\[
\textcolor{red}{\text{IC}_{\mu_1}:[0.04,\;\; 9.96]}
\]
Un intervalo de confianza del 95 % para \(\mu_2\) está dado por:
\[
\overline{X}_2\pm t_{0.025(99)}\sqrt\frac{S_2^2}{{n_2}}
= 13\pm 1.984217\sqrt\frac{625}{{100}}
=13\pm 4.96054
\]
\[
\textcolor{blue}{\text{IC}_{\mu_2}:[8.04,\;\; 17.96]}
\]
En la figura 5.15 se representan simultáneamente los dos intervalos de confianza.

A partir del traslape entre los dos intervalos de confianza, resulta tentador concluir que no existe una diferencia significativa entre \(\mu_1\) y \(\mu_2.\) Si uno se preguntara, por ejemplo, si \(\mu_1\) pudiera ser 9, la respuesta sería afirmativa; la misma respuesta se obtendría si se planteara la pregunta para \(\mu_2.\)
No obstante, la manera formal de comparar las medias de dos poblaciones normales es mediante una prueba de \(t\) (cf. secciones 5.2, 5.2.1 y 5.2.2), la cual tiene una relación uno a uno con un intervalo de confianza para la diferencia de las medias (cf. secciones 4.2.2, 5.2.1.2 y 5.2.2.1).
Si a partir de un par de muestras aleatorias tomadas de manera independiente, se construye un intervalo de confianza para la diferencia de las medias poblacionales y dicho intervalo contiene el cero, no se rechazará la hipótesis nula de igualdad de medias. Si, por el contrario, el intervalo para la diferencia de medias no contiene el cero, podrá rechazarse dicha hipótesis con un nivel de significancia \(\alpha\) (cf. nota 5.1).
Para el presente ejemplo, en el que las varianzas coinciden, un intervalo de confianza del 95 % para \(\mu_2-\mu_1\) se obtiene así:
\[
\begin{align}
\left(\overline{X}_2-\overline{X}_1\right)&\pm t_{0.025\left(198\right)}
\sqrt{\frac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2} \left(\frac{1}{n_1}+\frac{1}{n_2}\right)}\\[1.4em]
=\left(13-5\right)&\pm 1.972017
\sqrt{\frac{99\times625+99\times625}{100+100-2} \left(\frac{1}{100}+\frac{1}{100}\right)}\\[1.4em]
=8 & \pm 1.972017\times 3.5355\\[1.4em]
=8 & \pm 6.9721
\end{align}
\]
\[
\text{IC}_{\mu_2-\mu_1}:[1.03,\;\; 14.97]
\]
Puesto que el intervalo de confianza para la diferencia de medias no contiene el cero, puede rechazarse la hipótesis de igualdad de medias con un nivel de significancia del 5 %. Se tiene una confianza del 95 % en que \(\mu_2\) supera a \(\mu_1\) en una cantidad comprendida entre 1.03 y 14.97.
Este resultado es contrastante con el que se obtendría al interpretar los intervalos individuales, haciéndose evidente que la comparación de intervalos individuales para las medias no es equivalente a evaluar un intervalo de confianza para la diferencia de dos medias.
Para que el criterio basado en el traslape de intervalos individuales coincidiera con el criterio del intervalo de confianza para la diferencia de medias, sería necesario que el límite superior del intervalo individual correspondiente a la menor media fuera menor que el límite inferior del intervalo individual correspondiente a la mayor media (no traslape), siempre que el intervalo de confianza para la diferencia de medias no contuviera el cero.
Con el fin de ilustrar qué se requeriría para que se satisficiera la condición anterior, supóngase que las varianzas poblacionales son conocidas. En tal caso, el límite superior para el intervalo individual correspondiente a la menor media estaría dado por:
\[
\overline{X}_{(1)}+ z_{\alpha/2}\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}},
\]
donde el índice dentro de paréntesis hace referencia al estadístico de orden, mientras que los índices entre corchetes se refieren a la población correspondiente a dicho estadístico. Así, \(\overline{X}_{(1)}\) es el primer estadístico de orden, es decir, la menor de las dos medias muestrales; \(n_{[1]}\) es el tamaño de la muestra que da lugar a \(\overline{X}_{(1)}\); \(\sigma_{[1]}^2\) es la varianza de la población que da lugar a \(\overline{X}_{(1)}.\)
Análogamente, el límite inferior para el intervalo individual correspondiente a la mayor media estaría dado por:
\[
\overline{X}_{(2)}- z_{\alpha/2}\sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}
\]
Para que los intervalos individuales no se traslapen, se requiere:
\[
\overline{X}_{(1)}+ z_{\alpha/2}\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}<\overline{X}_{(2)}- z_{\alpha/2}\sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}
\]
\[ \Rightarrow\overline{X}_{(2)}-\overline{X}_{(1)}> z_{\alpha/2}\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ z_{\alpha/2}\sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}} \]
\[
\Rightarrow\overline{X}_{(2)}-\overline{X}_{(1)}> z_{\alpha/2}\left(\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}\right)
\tag{5.24}\]
Por otra parte, para que el intervalo de confianza para la diferencia de dos medias no contenga el cero, se requiere que la semiamplitud del intervalo de confianza sea menor que la diferencia entre la máxima y la mínima media muestral:
\[
\Rightarrow\overline{X}_{(2)}-\overline{X}_{(1)}> z_{\alpha/2}\sqrt{\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \frac{\sigma_{[2]}^2}{{n_{[2]}}}}
\tag{5.25}\]
Para que los dos criterios coincidieran, se requeriría que se satisficiera la siguiente igualdad:
\[
z_{\alpha/2}\left(\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}\right)
\overset {?}=z_{\alpha/2}\sqrt{\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \frac{\sigma_{[2]}^2}{{n_{[2]}}}}
\]
No obstante, esta igualdad no se satisface, tal y como se ilustra a continuación:
\[
\left(\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}\right)
\overset {?}=\sqrt{\frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \frac{\sigma_{[2]}^2}{{n_{[2]}}}}
\]
Elevando al cuadrado ambos lados de la ecuación, se obtiene:
\[
\begin{align}
\left(\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}\right)^2 + \left(\sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}\right)^2
+2\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}\sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}
&\overset {?}= \frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \frac{\sigma_{[2]}^2}{{n_{[2]}}}\\[1.4em]
\frac{\sigma_{[1]}^2}{{n_{[1]}}} + \frac{\sigma_{[2]}^2}{{n_{[2]}}}
+2\sqrt\frac{\sigma_{[1]}^2}{{n_{[1]}}}\sqrt\frac{\sigma_{[2]}^2}{{n_{[2]}}}
&\overset {?}= \frac{\sigma_{[1]}^2}{{n_{[1]}}}+ \frac{\sigma_{[2]}^2}{{n_{[2]}}}
\end{align}
\]
Puesto que el tercer término del lado izquierdo de la expresión es estrictamente positivo, la igualdad nunca se satisface.
Además de evidenciarse que los dos criterios no coinciden, puede observarse que, para que no exista traslape de intervalos individuales, siempre se exigirá la distancia entre las medias muestrales sea superior a la mínima requerida para declarar una diferencia estadísticamente significativa (cf. expresiones 5.24 y 5.25).
Por tanto, aunque la ausencia de traslape entre intervalos individuales sí puede tomarse como evidencia de una diferencia estadísticamente significativa, el traslape no equivale al no rechazo de la hipótesis nula para la diferencia de las medias. Pueden darse situaciones, como la ilustrada en el presente ejemplo, en las que, a pesar de existir traslape entre los intervalos individuales \(100(1−\alpha)\,\%,\) se declara diferencia estadísticamente significativa con un nivel de significancia \(\alpha.\)
Aunque la anterior ilustración se ha realizado para el caso particular de la comparación de medias de dos poblaciones normales con varianzas conocidas, la conclusión es generalizable a cualquier situación en la que se comparen dos parámetros.
Esto se explica por el hecho de que la probabilidad conjunta de que dos intervalos de confianza individuales contengan simultáneamente sus correspondientes parámetros es menor que la probabilidad de que un solo intervalo contenga su parámetro.
La probabilidad de que un intervalo individual contenga su parámetro es \((1−\alpha).\) Cuando los intervalos se construyen a partir de muestras independientes —situación que es la más común en la práctica investigativa—, la probabilidad de que ambos intervalos contengan simultáneamente sus correspondientes parámetros es \((1− \alpha)^2.\) Y puesto que \((1− \alpha) < 1,\) se tiene que \((1− \alpha)^2 < (1− \alpha).\)
Así, por ejemplo, la probabilidad de que dos intervalos de confianza del 95 % contengan simultáneamente sus correspondientes parámetros es \(0.95^2=0.9025\).
Consecuentemente, no es válido combinar dos herramientas inferenciales cuya confianza conjunta es inferior a la confianza objetivo.
¡No los use así!
El traslape de los intervalos de confianza individuales para dos parámetros no implica que no haya diferencia significativa entre tales parámetros.
5.6 Pruebas de una cola vs. pruebas de dos colas
Las pruebas unilaterales pueden ser de cola izquierda o de cola derecha. Ya se ha discutido que, al comparar dos parámetros, existen dos formas equivalentes de plantear una misma pregunta, dando lugar a una prueba de cola izquierda en un caso y de cola derecha en el otro, sin que cambie la pregunta que se responde ni el control de los errores asociados con las diferentes decisiones (cf. advertencia 5.3).
Asimismo, se ha mostrado que, en pruebas unilaterales, el usuario puede definir preguntas distintas al modificar la forma forma en la que plantea el contraste, dando lugar a distintas pruebas, en las que cambia el subespacio paramétrico de interés y, por ende, los tipos de errores que se controlan (cf. ejemplos 4.3 y 4.4).
En la presente sección no se retoman estos aspectos, sino que se comparan globalmente las pruebas de dos colas con las pruebas de una cola.
Algunos procedimientos que involucran pruebas de hipótesis preestablecen el tipo de prueba, acorde con sus fines. Así, por ejemplo, a través del análisis de varianza se busca probar si la variación entre grupos supera la variación dentro de grupos, lo cual se logra mediante una prueba \(F\) de homogeneidad de varianzas de cola derecha (cf. secciones 5.1.1 y 6.2). Puesto que en casos como este, el usuario no tiene oportunidad real de elección, estas situaciones no resultan informativas para la presente discusión.
En otros casos, el usuario debe elegir el tipo de prueba que le permita responder certeramente la pregunta formulada.
En el ejemplo 4.2 se evalúa la exactitud de un equipo, mediante el siguiente juego de hipótesis:
\(H_0:\mu=750\) (calibrado)
\(H_a:\mu\ne750\) (descalibrado)
Hay un único punto que satisface el requerimiento de calibración: \(\mu=750.\) Cualquier desviación de este valor, ya sea por encima o por debajo, constituye una descalibración. Mediante una prueba de hipótesis de dos colas se particiona el espacio paramétrico de forma coherente con los puntos del espacio muestral que representan las respuestas de interés (calibrado/descalibrado).
En contraste, en el ejemplo 4.3, en el que se evalúa lo concerniente a la precisión del equipo se planteó el siguiente juego de hipótesis:
\(H_0:\sigma\ge12\) (inadecuado)
\(H_a:\sigma<12\) (adecuado)
Habiéndose establecido que la precisión del equipo es adecuada siempre que \(\sigma < 12,\) el requerimiento de calibración no se satisface en un único punto, sino en una subregión del espacio paramétrico. Si la desviación estándar del equipo es 10, el equipo se considera adecuado; asimismo, si su desviación estándar es 5, 2 o 1. La única forma de hacer corresponder la partición del espacio paramétrico con los puntos muestrales de las respuestas de interés es mediante una prueba de una cola.
En oposición con las anteriores elecciones incuestionables del tipo de prueba para responder las preguntas de interés, la elección del tipo de prueba en el ejemplo 5.3 no es tan trasparente. En este ejemplo, se elige una prueba de una cola a partir de la percepción, conocimiento o expectativa que se tiene sobre la dirección de la diferencia.
El planteamiento decía: “se cree que las colonias ubicadas en bosque húmedo tropical (bh-T) podrían tener un mayor riesgo que las ubicadas en bosque húmedo premontano (bh-PM)”.
Consecuentemente, se postuló el siguiente juego de hipótesis:
\(H_0: \mu_{\text{bh-T}}\le \mu_{\text{bh-PM}}\)
\(H_a: \mu_{\text{bh-T}} > \mu_{\text{bh-PM}}\)
Aunque podría pensarse que este es un detalle menor y que en cualquier caso se hubiera llegado a la misma conclusión, esto no siempre es así. Para ilustrarlo, considérese a continuación un planteamiento basado en una prueba de dos colas para el ejemplo 5.3:
\(H_0: \mu_{\text{bh-T}}= \mu_{\text{bh-PM}}\)
\(H_a: \mu_{\text{bh-T}} \ne \mu_{\text{bh-PM}}\)
El estadístico de prueba es el mismo que se obtiene para el planteamiento unilateral: \(t_\text{c}=1.893.\) No obstante, el valor crítico para la prueba de dos colas es diferente:
Valor crítico: qt(0.025, 15.89, lower.tail = FALSE) = 2.1211.
Y también es diferente la conclusión:
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(t_\text{c}\) \(1.893\) |
\(<\) \(<\) |
\(t_{0.025(15.89)}\) \(2.1211\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no rechaza \(H_0\) con \(α = 0.05\) |
Asimismo, cambia el valor p:
Valor p: 2 * pt(1.893, 15.89, lower.tail = FALSE) = 0.0767.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.0767\) |
\(>\) \(>\) |
\(\alpha\) \(0.05\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no rechaza \(H_0\) con \(α = 0.05\) |
Se tiene, pues, que —al contrastar un juego de hipótesis de dos colas— no es posible afirmar con una probabilidad máxima de error de 0.05 que la afectación media por el síndrome difiera entre las dos zonas de vida comparadas.
El paradójico resultado surge por el hecho de que las pruebas de una cola tienen mayor potencia en la dirección evaluada (la definida por la hipótesis alternativa) que las correspondientes pruebas de dos colas con el mismo nivel de significancia.
En ocasiones, este aspecto es aprovechado por el usuario, ya sea de manera consciente o inconsciente, para lograr resultados significativos, mediante el simple recurso de cambiar el tipo de prueba.
Supóngase que un investigador que se enfrenta al problema planteado en el ejemplo 5.3 quiere averiguar si el número medio de abejas afectadas por el síndrome difiere entre las dos zonas de vida comparadas. Para tal efecto plantea una prueba de dos colas como la que acaba de realizarse, sin que pueda declararse una diferencia significativa.
No obstante, al observar que, a nivel muestral, el número medio de abejas afectadas por el síndrome por colonia es mayor en bh-T que en bh-PM \((\overline{X}_{\text{bh-T}}=11.4,\) \(\overline{X}_{\text{bh-PM}}=8.75)\) y que el valor p queda cerca del umbral de significancia, siendo suficiente reducirlo a la mitad para alcanzar la significancia deseada, el investigador podría verse tentado a hacer caso omiso del resultado obtenido mediante la prueba de dos colas y contrastar un juego de hipótesis de una cola, como el presentado inicialmente en el ejemplo 5.3.
Autores como Freedman, Pisani y Purves (2007) indican que no importa mucho qué tipo de prueba se use, siempre que se deje claramente establecido cuál se usó. Aunque compartimos plenamente la indicación de estos autores sobre dejar claramente establecido qué tipo de prueba se usó, nos apartamos de su criterio con respecto a la irrelevancia de su elección.
Otra prescripción frecuente indica que el tipo de prueba debe elegirse antes de realizar el experimento, basándose únicamente en las necesidades y expectativas del usuario. Este procedimiento, aunque pueda parecer sano, no elimina los sesgos, pues es bastante común que los investigadores que conocen suficientemente sus áreas puedan predecir las tendencias de un experimento aun antes de realizarlo.
Si el investigador del ejemplo 5.3 anticipara que la prevalencia del síndrome es mayor en bh-T que en bh-PM, ¿tendría vía libre para plantear un juego de hipótesis de una cola, bastando con que lo hiciera antes de realizar el experimento? Consideramos que no.
De acuerdo con Lombardi y Hurlbert (2009), las pruebas de una cola deben plantearse únicamente cuando todo el subespacio paramétrico definido por la hipótesis nula sea igualmente irrelevante y se tenga interés únicamente en el subespacio paramétrico definido por la hipótesis alternativa.
Lo anterior está acorde con lo recomendado por Kimmel (1957), quien señala que las pruebas de una cola están prescritas para situaciones en las que los resultados en la dirección de la hipótesis nula no determinen, bajo ninguna circunstancia, un comportamiento diferente al que determinaría la no diferencia.
Analicemos cómo se traduce esta prescripción en el contexto de varios de los ejemplos desarrollados en el capítulo 4 y en el capítulo 5.
Retomemos el juego de hipótesis del ejemplo 4.3:
\(H_0:\sigma\ge 12\) (equipo inadecuado)
\(H_a:\sigma< 12\) (equipo adecuado)
¿Los resultados en la dirección de la hipótesis nula no determinan, bajo ninguna circunstancia, un comportamiento diferente al que determinaría la no diferencia?
El equipo es tan inadecuado si su desviación estándar es 12 como si es 100; en cualquier caso, la decisión será la misma: recalibrar el equipo. Se verifica, pues, que ninguno de los resultados en la dirección de la hipótesis nula determina un comportamiento diferente al que determinaría la no diferencia \((\sigma=12).\) Luego, la prueba de una cola es adecuada en este caso.
Consideremos ahora el ejemplo 4.4 y su juego de hipótesis:
\(H_0: p \le 0.9\) (la semilla no es mejorada)
\(H_a: p > 0.9\) (la semilla sí es mejorada)
La decisión del potencial comprador sería la misma para cualquier proporción menor o igual de 0.9: no comprar el lote. De nuevo, se verifica que ninguno de los resultados en la dirección de la hipótesis nula determina un comportamiento diferente al que determinaría la no diferencia \((p=0.9),\) por lo que el uso de una prueba de una cola en el presente caso podría considerarse adecuado.
Contrastemos los anteriores usos adecuados con el que surge al considerar el juego de hipótesis del ejemplo 5.3:
\(H_0: \mu_{\text{bh-T}}\le \mu_{\text{bh-PM}}\)
\(H_a: \mu_{\text{bh-T}} > \mu_{\text{bh-PM}}\)
En términos del manejo de las abejas angelita, ¿es indiferente que la prevalencia del síndrome no difiera entre zonas de vida o que sea menor en bh-T? La respuesta es un no rotundo.
No es que el investigador no tenga interés en averiguar si la prevalencia en bh-T podría ser menor, sino que, por el conocimiento previo que tuviera del fenómeno o por la observación de los resultados del experimento, podría verse tentado a “ayudar” a que la prueba logre ser significativa. En tal sentido, la elección de una prueba de una cola para el presente contexto podría no ser la más adecuada.
¿¡O sea que estaba malo!?
A la luz de lo anterior, la elección del juego de hipótesis en el ejemplo 5.3 podría considerarse cuestionable.
No obstante, es necesario separar dos planos: el operacional y el conceptual.
El ejemplo 5.3, tal y como se desarrolló en la sección 5.2.2 es operacionalmente correcto para el juego de hipótesis planteado.
Y aunque encontramos conceptualmente criticable la forma en la que allí se formula el juego de hipótesis, consideramos que este ejemplo —así como está desarrollado— junto con la discusión de esta sección, constituye una interesante herramienta pedagógica.
A menudo se aprende más de los errores que de los procedimientos perfectamente depurados.
Para zanjar discusiones sobre la relevancia o no de un resultado, Lombardi y Hurlbert (2009) indican que no basta con que el usuario declare que una subregión del espacio paramétrico no es de su interés, sino que es necesario definir un interés colectivo de la ciencia y la sociedad.
Según estos autores, en cada área del conocimiento siempre habrá un interés colectivo por conocer los resultados que se opongan a lo predicho o a lo que sea del interés original de los investigadores individuales. Agregan que las excepciones a esta regla son tan pocas que podrían ignorarse y concluyen, por tanto, que las pruebas de una cola deberían evitarse en la gran mayoría de contextos.
Estos autores discuten una hipotética situación en la que se evalúa un nuevo medicamento. Aunque podría pensarse que en estos casos el único resultado de interés sería el que evidenciara que el nuevo medicamento es más efectivo que el tradicional, para lo cual podría usarse una prueba de una cola, estos autores advierten que un resultado inesperado en cuanto a que el nuevo medicamento es significativamente inferior que el estándar es tan valioso como el resultado buscado, por cuanto pondría en alerta a la comunidad científica que se encuentre trabajando alrededor de este tema, obligándola a plantearse nuevas preguntas, realizar nuevos experimentos y eventualmente a modificar la teoría dominante.
Consecuentemente, más allá del interés inmediato que el usuario pudiera tener en probar que el nuevo medicamento es más efectivo que el tradicional, este contraste debe realizarse usando una prueba de dos colas, en aras del interés colectivo de la ciencia y la sociedad.
El criterio de considerar el interés colectivo de la ciencia y la sociedad pareciera entrar en contradicción con lo expresado anteriormente, con respecto a lo adecuadas que resultaban las pruebas de una cola en los ejemplos 4.3 y 4.4. Sin embargo, es posible encontrar un punto de conciliación.
Los ejemplos reseñados corresponden a situaciones operativas, donde las poblaciones objetivo son bastante restringidas. La población objetivo del ejemplo 4.3 es la cantidad en gramos de fertilizante dispensado por el equipo empacador dentro de cada bolsa. Este ejemplo no tienen el trasfondo de un programa de investigación basado en unos postulados teóricos; simplemente se trata de decidir con baja probabilidad de error si el equipo está calibrado o no.
Análogamente, la población objetivo del ejemplo 4.4 es un lote de semillas (o quizá toda la semilla de una especie determinada) de un productor dado. En este caso, simplemente se trata de decidir con baja probabilidad de error si comprar la semilla con denominación de mejorada o la estándar.
En casos como estos, donde lo que se realiza es más un control de calidad que un ensayo dentro de un programa de investigación, es suficiente el interés particular, sin que se requieran consideraciones adicionales sobre el interés colectivo.
En contraste, los ejemplos 5.1, 5.2 y 5.3 se basan en un contexto que trasciende el interés particular, donde cualquier resultado, por inesperado que sea bajo la teoría dominante, merece ser considerado, con miras a redireccionar y corregir las teorías si fuera del caso.
Bajo esta misma lógica, podría reexaminarse el hipotético ejemplo del nuevo medicamento. ¿En qué contexto se está realizando el ensayo? Si se trata de un programa de investigación, cuyos resultados han de ser publicados, para contribuir al avance de la ciencia y la sociedad, debe manterse la recomendación de usar prueba de dos colas. Sin embargo, si se trata de un ensayo interno de una farmacéutica que no tiene ningún interés en que la competencia conozca los resultados de sus ensayos, sino que usará los resultados para decidir sobre la implementación del nuevo medicamento, el interés particular —y por tanto, la prueba de una cola— sería perfectamente defendible.
Luego, a la prescripción de Lombardi y Hurlbert (2009) sobre el interés colectivo de la ciencia y la sociedad podría agregársele: “si hubiera lugar a ello”. También podría agregrársele una capa adicional de temporalidad para que quede completa.
Supóngase que se está evaluando un nuevo producto cuya implementación sería relevante únicamente si muestra superioridad frente al producto estándar. En este caso, la ciencia y la sociedad estarían de acuerdo en que es igualmente irrelevante que el nuevo producto sea igual o inferior al estándar: en cualquiera de esos casos no se implementaría… al menos no en las condiciones actuales.
Habría que considerar, sin embargo, que en algún otro escenario futuro de cambio tecnológico, ambiental o social, escasez del producto estándar o cualquier otra situación contingente, la no inferioridad del nuevo producto podría volverse relevante. En tal sentido la definición anterior debería incluir este componente de temporalidad.
5.7 Decálogo sobre pruebas de hipótesis
Las pruebas de hipótesis suelen enseñarse como un procedimiento mecánico: se plantea un juego de hipótesis, se calcula un estadístico de prueba, se obtiene un valor p y se toma una decisión. Sin embargo, detrás de esa aparente simplicidad se esconden múltiples sutilezas conceptuales y metodológicas que, de no advertirse, pueden conducir a interpretaciones equivocadas o a decisiones injustificadas.
Este decálogo no está constituido por reglas nuevas ni excepciones exóticas. Por el contrario, condensa algunos de los fundamentos esenciales desarrollados en los capítulos anteriores, permitiendo comprender con mayor claridad la estructura lógica las pruebas de hipótesis, la naturaleza probabilística de sus decisiones y las implicaciones metodológicas que de ellas se derivan.
1) La hipótesis nula siempre incluye la igualdad
Esta afirmación es cierta en todos los casos del marco clásico de las pruebas de hipótesis. En pruebas de dos colas resulta evidente que la hipótesis nula siempre plantea la igualdad \((\theta=\theta_0).\) En el marco clásico de las pruebas de hipótesis no es válido formular una hipótesis nula de diferencia, esto es, del tipo \(\theta\ne\theta_0.\)
Cuando se formulan pruebas de una cola, siempre es necesario incluir la igualdad en la hipótesis nula: es correcto plantear como hipótesis nula que \(\theta \le \theta_0\) o que \(\theta \ge \theta_0,\) no siendo válido formular como hipótesis nula expresiones del tipo \(\theta < \theta_0\) o \(\theta > \theta_0\) (cf. sección 3.9.2).
Esto se debe a que el punto en el que se satisface la igualdad —y que pertenece al subespacio paramétrico de la hipótesis nula— es el que se utiliza para calcular la máxima probabilidad de error tipo I (cf. secciones 3.9.2.1, 3.9.2.2 y 4.5). La probabilidad de rechazar la hipótesis nula cuando el valor del parámetro es igual al valor hipotético es \(\alpha.\)
A manera de corolario, puede decirse que la hipótesis alternativa nunca lleva la igualdad; siempre plantea desigualdades estrictas.
2) La hipótesis nula plantea nulidad de efectos
Esta afirmación (cf. sección 3.9.2) debe entenderse con carácter descriptivo, más que como una obligación al definir la formulación de un juego de hipótesis.
En el contexto de pruebas de dos colas, donde el subespacio paramétrico que define la hipótesis nula consta de un único punto, esta afirmación suele ser cierta, siendo posible afirmar que la condición en la que el valor del parámetro coincide con el valor hipotético representa el estándar.
En contraste, en pruebas de una cola, dado que el subespacio paramétrico que define la hipótesis nula es una región, suele resultar inadecuado afirmar que todos los posibles valores del parámetro admitidos por la hipótesis nula constituyen lo establecido o lo esperable.
En adición, cuando el juego de hipótesis se formula a partir de las demás consideraciones incluidas en este decálogo, esta afirmación puede quedar completamente fuera de lugar.
En el ejemplo 4.3 resulta evidente que esta afirmación no tiene asidero, no siendo correcto decir que lo esperable es que la desviación estándar del equipo sea 12, 15, 50, 100 o, en general, cualquier valor mayor o igual que 12.
Asimismo, en el ejemplo 4.4 estaríamos afirmando que lo esperable es que la viabilidad de la semilla sea cualquier valor entre 0 y 0.9. Lógicamente, no es en absoluto esperable ni estándar que la viabilidad de un lote de semillas sea del 0 %.
Podría pensarse que para conferirle validez a esta afirmación en el contexto de las pruebas unilaterales deberíamos evaluar únicamente el punto en el que se satisface la igualdad. No obstante, no es esta la manera correcta de definir el subespacio paramétrico cuando se plantean pruebas de una cola (cf. sección 3.9.2). Cuando la hipótesis nula consta de un único punto, la prueba resultante es necesariamente de dos colas.
3) Solo el rechazo de la hipótesis nula tiene carácter de prueba
Esta afirmación es válida tanto para pruebas de una cola como para pruebas de dos colas. En la sección 3.9.2.1 se discute que el no rechazo (o aceptación, si así se le quiere llamar) de la hipótesis nula no tiene carácter probatorio, debiendo tomarse como una hipótesis temporal que se mantiene hasta que se tengan más elementos que permitan rechazarla con baja probabilidad de error.
Luego, los resultados de una prueba que permita —vía rechazo de la hipótesis nula— respaldar la hipótesis de que \(θ < θ_0\) no son equivalentes a los de una prueba que —por imposibilidad de rechazar la hipótesis nula— lleve a aceptar que \(θ \le θ_0.\) De hecho, la manera más correcta de expresar esta última situación sería diciendo que no es posible probar que \(θ > θ_0.\)
Asimismo, debe tenerse presente que el carácter de prueba que se le adjudica al rechazo de la hipótesis nula debe entenderse desde un punto de vista estadístico, esto es, como una afirmación con baja probabilidad de error, en la que se tiene bajo control la máxima probabilidad de cometer dicho error.
4) Hay que escribir lo que se quiere probar en la hipótesis alternativa
Más que afirmar que el investigador pone lo que quiere probar en la alternativa, lo que habría que decir es que solo puede probarse lo que esté en la alternativa (cf. numeral 3). Aunque el investigador puede usar esta circunstancia en pro de sus intereses cuando trabaja con pruebas de una cola (cf. ejemplos 4.3 y 4.4), no puede hacerlo en pruebas de dos colas.
Si se considera la situación analizada en el ejemplo 4.2, se verá que, por la limitación detallada en el numeral 1 de esta sección, no sería posible probar que el equipo está calibrado, por más que el investigador quisiera hacerlo.
Cuando se trabaja con pruebas de una cola, este limitación sí es manejable, sin que la restricción concerniente a que la igualdad quede en la hipótesis nula sea impedimento para ello.
Los ejemplos de libro suelen postular situaciones en las que la igualdad siempre forme parte de la hipótesis nula, de manera que no haya lugar a conflictos, tal y como se hace en el ejemplo 4.3, en el que se indica que la norma técnica establece que la desviación estándar debe ser estrictamente menor de 12.
Al definir la subregión paramétrica \(\sigma< 12\) para la hipótesis alternativa, el valor \(\sigma=12\) pasa de manera automática a formar parte de la hipótesis nula, que es justamente lo que se requiere. El juego de hipótesis puede escribirse de manera limpia y elegante, así:
\[
H_0: \sigma \ge 12
\] \[
H_a: \sigma < 12
\]
Supóngase ahora que en el mismo contexto del ejemplo 4.3 nos hubiéramos encontrado con una situación en la que la norma técnica estableciera que el requerimiento de calibración se satisficiera con \(σ\le 12.\) En tal caso —aun siendo esto lo que se desee probar—, no podría escribirse esta desigualdad amplia en la hipótesis alternativa, por la limitación indicada en el corolario del numeral 1.
Podría pensarse, entonces, que la única manera válida de escribir un juego de hipótesis que refleje la situación descrita es la siguiente:
\[
H_0: \sigma \le 12
\] \[
H_a: \sigma > 12
\]
Aunque el anterior juego de hipótesis es válido, resulta poco conveniente para el investigador, puesto que redefine los tipos de error, con respecto a la definición que estos tenían en el ejemplo 4.3. En este caso ya no se tendría bajo control el error que se había considerado más delicado.
Por extraño que parezca, la solución más conveniente —y completamente ortodoxa— consiste en formular el juego de hipótesis de acuerdo con el tipo de error que se desee controlar, incluyendo el punto frontera en la hipótesis nula, sin importar cómo esté formulado el planteamiento con relación a ese punto particular.
Luego, si en el ejemplo ilustrado se desea mantener bajo control la probabilidad de declarar calibrado en precisión un equipo que no lo está, y la norma técnica estableciera que el requerimiento de calibración se satisficiera con \(σ\le 12,\) el juego de hipótesis correcto sería:
\[
H_0: \sigma \ge 12
\] \[
H_a: \sigma < 12
\]
Luego, el criterio fundamental para definir el juego de hipótesis no es la forma puntual de la norma técnica, sino el error que se desea mantener bajo control.
Sobre la irrelevancia del punto frontera en parámetros continuos
Aprovechando la continuidad del parámetro25, puede usarse un valor hipotético tan cercano como se quiera al punto de corte, para establecer la igualdad en la hipótesis nula.
Así, podría tomarse, por ejemplo, un valor hipotético que esté desplazado en una milbillonésima de unidad del punto de corte y escribir un juego de hipótesis como el siguiente:
\[
H_0: \sigma \ge 12+1\times10^{-15}
\] \[
H_a: \sigma < 12+1\times10^{-15}
\]
Puede observarse que, sin desvirtuar la esencia del planteamiento, se ha logrado escribir lo que se quiere probar en la hipótesis alternativa como desigualdad estricta —aun así incluyendo el 12— y se ha respetado la escritura de desigualdad amplia en la hipótesis nula, respetando también lo establecido en el planteamiento en el que se declaraba un equipo como descalibrado si se observaba una desviación estándar estrictamente mayor que 12.
El valor p de este juego de hipótesis coincide con el generado por el juego de hipótesis original del ejemplo 4.3 hasta la decimoséptima cifra decimal.
Resulta evidente que la adición de una milbillonésima de unidad al punto de corte (o una cifra aún menor, si se quisiera) no cambia ni la esencia ni los resultados del juego de hipótesis. No se trata más que de un artificio para ilustrar la irrelevancia de este aspecto.
Si un juego de hipótesis como el planteado da lugar a los mismos resultados que el juego de hipótesis que se presentó en el ejemplo 4.3, resulta innecesaria la adición de esta cantidad infinitesimal, pudiendo mantenerse el juego de hipótesis que se había escrito inicialmente, sin importar que en el planteamiento hubiera cambiado por la inclusión del punto en el subespacio paramétrico complementario.
5) La alternativa es la hipótesis de investigación
Esta afirmación es consecuencia directa de lo analizado en los numerales 2, 3 y 4 de esta sección. Cuando se contrasta un juego de hipótesis mediante una prueba de dos colas, en la que la hipótesis nula representa la situación usual, conocida, estándar, de nulidad de efectos, y en la que el investigador quiere y puede probar la alternativa, que representa un rompimiento con el statu quo, un cambio en el proceso, un descubrimiento, desde luego que la hipótesis alternativa es la hipótesis de investigación.
Asimismo, si en un contexto investigativo se estuviera contrastando un juego de hipótesis mediante una prueba de una cola, el investigador tendría que poner lo que desee probar en la alternativa (cf. numeral 4), en cuyo caso también se diría que esa es la hipótesis de investigación.
No obstante, en contextos básicos, por fuera del ámbito investigativo, en los que se hubiera estructurado el juego de hipótesis con base en otros criterios, como los que se ilustran en los ejemplos 4.3 y 4.4, podría sonar un tanto extraño afirmar, por ejemplo, que la hipótesis de investigación es que un equipo para empacar fertilizante está calibrado en precisión.
Asimismo, esta afirmación resulta claramente inapropiada si se consideran los juegos de hipótesis en los que se basan las denominadas pruebas de bondad de ajuste (cf. sección 4.1).
6) El usuario solo tiene control directo sobre el error tipo I
Ya sea que se contraste un juego de hipótesis mediante una prueba de una o de dos colas, el investigador solo puede ejercer control directo sobre el error tipo I, fijando la máxima probabilidad de este (cf. sección 3.9.2.2).
Por consiguiente, cuando se usan pruebas de una cola, estas se construyen de manera que el error que se considere más delicado y al que, por tanto, desee acotársele su probabilidad de ocurrencia, quede definido como error tipo I, tal y como se ilustró en los ejemplos 4.3 y 4.4.
Cuando se contrasta un juego de hipótesis mediante una prueba de dos colas, los dos errores quedan automáticamente definidos, sin que haya lugar a su redefinición, sin importar cuál de estos resulte más inconveniente para el investigador.
Si, en un contexto tan claramente definido como el que plantea el escenario B en el ejemplo 4.2, se detectara que el error tipo II es más inconveniente que el error tipo I, lo único que podría hacerse para reducir la probabilidad de error tipo II —con un tamaño de muestra fijo— sería relajar \(α.\)
Si bien es cierto que mediante esta acción se logra una reducción de \(β,\) dicho efecto es indirecto. Para valorar el comportamiento de \(β\) sería necesario analizar la potencia de la prueba, fijando una serie de valores alternativos del parámetro.
Podría pensarse —de manera razonable, aunque no óptima— que la estrategia de flexibilizar/endurecer \(\alpha\) para controlar indirectamente \(\beta\) también es aplicable a pruebas de una cola. Así, si en el ejemplo 4.3 se hubiera planteado el escenario A, el error más inconveniente sería declarar descalibrado en precisión un equipo que estaba calibrado.
Consecuentemente, podría pensarse en dejar el juego de hipótesis tal y como se planteó, pero contrastarlo con \(\alpha = 0.1,\) en lugar de hacerlo con \(\alpha = 0.01,\) para así controlar \(\beta.\) No obstante, esta sería una estrategia un tanto burda para dicha situación, si se tiene en cuenta que el control de \(\beta\) sería indirecto. Mucho mejor que esto, sería reformular el juego de hipótesis, escribiéndolo de la siguiente manera, la cual resulta válida, aun como está planteada la norma técnica (cf. numeral 4):
\[
H_0: \sigma \le 12
\]
\[
H_a: \sigma > 12
\]
Este ejemplo ilustra que, cuando se desea priorizar el control de un error específico en pruebas de una cola, la estrategia adecuada no es modificar \(\alpha\) para controlar indirectamente \(\beta\), sino reformular el juego de hipótesis de manera que el error más delicado quede definido como error tipo I.
7) El valor p tiene que ser bajo
Teniendo en cuenta que la alternativa suele ser la hipótesis de investigación (cf. numeral 5), es comprensible que los bajos valores p sean tan deseables, puesto que representan la probabilidad de errar cuando se concluye en favor de la alternativa con base en la información de una muestra particular.
No obstante, debe tenerse en cuenta que el valor p es una probabilidad y, como tal, puede tomar cualquier valor entre 0 y 1. Asimismo, tal y como lo exponen Sackrowitz y Samuel-Cahn (1999) y Correa-Londoño y Castillo-Morales (2000), bajo la hipótesis nula, el valor p es una variable aleatoria uniforme continua, cuyos límites están en el rango \([0,\,1].\) En tal sentido, en el escenario de la hipótesis nula, es igualmente factible obtener cualquier valor dentro de dicho rango, sin que ninguno de ellos evidencie una inadecuada construcción del juego de hipótesis.
8) Existe una relación uno a uno entre pruebas de hipótesis e intervalos de confianza
En el marco de un procedimiento inferencial definido y usando una muestra dada, a toda prueba de hipótesis contrastada con nivel de significancia \(\alpha\) puede asociársele un intervalo de confianza del \(100(1−\alpha)\, \%\) que conduce a la misma decisión en términos del rechazo/no rechazo de la hipótesis nula. En efecto, el valor hipotético del parámetro quedará por fuera del intervalo si y solo si el valor p es menor o igual que \(\alpha\), y quedará dentro del intervalo si y solo si el valor p es mayor que \(\alpha\).
Esto es válido tanto para pruebas de dos colas como de una cola. Las pruebas de dos colas se asocian con intervalos de confianza bilaterales; las de cola izquierda, con intervalos unilaterales superiores, y las de cola derecha con intervalos unilaterales inferiores (cf. sección 4.5).
Debe tenerse presente, sin embargo, que una muestra particular permite contrastar infinitas pruebas de hipótesis (para diferentes valores hipotéticos del parámetro) y construir infinitos intervalos de confianza (para diferentes confianzas). Consecuentemente, la relación uno a uno a la que se hace referencia se da entre una prueba particular en la que se haya fijado tanto el nivel de significancia \(\alpha\) como el hipotético valor del parámetro, y el correspondiente intervalo de confianza del \(100(1−\alpha)\,\%.\)
¿¡Infinitos!?
Considérese un juego de hipótesis de cola izquierda para el parámetro de posición de una distribución normal:
\[
H_0:\mu\ge\mu_0
\] \[
H_a:\mu<\mu_0
\]
La figura 5.16 ilustra diferentes posibilidades de pruebas de hipótesis e intervalos de confianza asociados con este escenario26, para una muestra particular. Las regiones sombreadas representan las regiones paramétricas de rechazo (cf. sección 4.5):

Aunque la figura 5.16 solo presenta tres posibles valores de \(\mu:\) \((\mu_1,\) \(\mu_2\) y \(\mu_3)\) es suficiente para ilustrar las infinitas posibilidades de formulación de juegos de hipótesis sobre este parámetro, que surgen en virtud de su espacio paramétrico continuo.
Asimismo, los tres intervalos de confianza actúan en representación de los infinitos intervalos de confianza posibles.
Para ilustrar la relación entre pruebas de hipótesis e intervalos de confianza, tomemos como referencia el intervalo de confianza del 95 %. Cualquier prueba de hipótesis de cola izquierda que se plantee para un hipotético valor de \(\mu,\) que esté por fuera del intervalo, es decir, en la región paramétrica de rechazo27, v. gr., \(\mu_2\) y \(\mu_3,\) dará lugar a un valor p menor o igual de 0.05, permitiendo rechazar para \(\alpha=0.05.\)
Por el contrario, cualquier prueba de hipótesis de cola izquierda que se plantee para un hipotético valor de \(\mu\) dentro del intervalo, v. gr., \(\mu_1,\) dará lugar a un valor p mayor de 0.05, no permitiendo rechazar para \(\alpha=0.05.\)
Asimismo, el rechazo o no rechazo de una prueba para un \(\mu\) específico depende del nivel de significancia que se fije. Así, si consideramos la prueba de cola izquierda en la que se postula \(\mu_3\) como valor hipotético, cuyo valor p es 0.03, se observa que es posible rechazar con un \(\alpha = 0.05.\) No obstante, si se fijara \(\alpha=0.01,\) la prueba en cuestión ya no podría rechazarse.
Esto mismo puede visualizarse a través de los correspondientes intervalos de confianza: el intervalo de confianza del 95 % deja por fuera el valor \(\mu_3\), lo que permite rechazar con un nivel de significancia \(\alpha = 0.05,\) pero el intervalo de confianza del 99 % incluye el hipotético valor \(\mu_3,\) no permitiendo rechazar con un nivel de significancia \(\alpha=0.01.\)
9) La elección de pruebas de una o de dos colas depende del criterio del investigador
Las pruebas de dos colas son las únicas que, por construcción, restringen completamente la influencia del sesgo direccional del investigador. Por tal motivo, constituyen el estándar metodológico en investigación aplicada.
Las pruebas de una cola solamente resultan adecuadas cuando cualquier valor del parámetro en el subespacio definido por la hipótesis nula tenga exactamente las mismas implicaciones, tomando en consideración el interés colectivo presente y futuro de la ciencia y la sociedad.
En tal sentido, aunque las pruebas de una cola podrían tener un nicho natural en ensayos de control de calidad, donde prime el interés particular, en general no resultan adecuadas en investigación.
Sobre la consistencia de pruebas de una cola opuestas
Teniendo presente que las pruebas de dos colas son las únicas que, por construcción, restringen completamente la influencia del sesgo direccional del investigador (cf. numeral 9), y que en los casos particulares en los que las pruebas de una cola resultan adecuadas deben formularse de manera que permitan controlar el error que se considera más inconveniente (cf. numeral 6), conviene aclarar lo concerniente a la consistencia de pruebas de una cola opuestas.
Consideremos inicialmente las siguientes parejas de postulados:
\(\text{p1: } a\ge b,\quad\text{p2: } a< b\)
\(\text{p3: } a\le b,\quad \text{p4: } a>b\)
Puede establecerse lo siguiente:
Si \(\text{p4}\) es verdadero, también lo es \(\text{p1}\)
Si \(\text{p2}\) es verdadero, también lo es \(\text{p3}\)
Sin embargo,
Si \(\text{p1}\) es verdadero, no necesariamente lo será \(\text{p4},\) pues puede ocurrir que \(a=b\)
Si \(\text{p3}\) es verdadero, no necesariamente lo será \(\text{p2},\) pues puede ocurrir que \(a=b\)
Las anteriores conclusiones, por estar referidas a expresiones algebraicas, son incontestables.
No obstante, al pasar de formulaciones algebraicas a juegos de hipótesis, la situación adquiere mayor complejidad.
En el contexto de pruebas de hipótesis, los anteriores pares de postulados equivalen a dos juegos de hipótesis: uno de cola izquierda y otro de cola derecha:
\(H_0: \theta\ge \theta_0,\quad H_a: \theta< \theta_0\)
\(H_0: \theta\le \theta_0, \quad H_a: \theta>\theta_0\)
En adición a la falta de correspondencia perfecta entre las dos parejas de postulados, la formulación de los dos juegos de hipótesis agrega varias capas de complejidad.
Por una parte, ya no se pregunta si un postulado es cierto28, sino si es posible apoyarlo con baja probabilidad de error. Así, por ejemplo, para el primer juego de hipótesis, lo que puede responderse no es si \(\theta< \theta_0,\) sino si puede respaldarse dicha afirmación con baja probabilidad de error.
Por otra parte está el carácter no concluyente —ni siquiera en términos estadísticos— de la aceptación de la hipótesis nula: si una prueba de hipótesis conduce a un escenario en el que no se tienen elementos para negar con baja probabilidad de error que \(\theta\ge \theta_0\), no puede afirmarse que \(\theta\ge \theta_0.\)
Al combinar la falta de complementariedad algebraica entre las pruebas de cola izquierda y las de cola derecha con las incertidumbres inherentes al proceso inferencial, podría pensarse que, dependiendo de cómo se formulen, las pruebas podrían generar resultados inconsistentes. No obstante, el procedimiento inferencial conserva una coherencia interna estricta, pese a estas fuentes de asimetría.
Para dos juegos de hipótesis unilaterales opuestos, construidos sobre el mismo procedimiento inferencial, con el mismo nivel de significancia y evaluados sobre una misma muestra, se cumple:
El rechazo de una prueba de cola izquierda siempre está asociado al no rechazo de una prueba de cola derecha.
El rechazo de una prueba de cola derecha siempre está asociado al no rechazo de una prueba de cola izquierda.
El no rechazo de una prueba de hipótesis unilateral —independientemente de su dirección— no implica el rechazo de la prueba opuesta, pudiendo coincidir ambas en el no rechazo.
10) Las pruebas de una cola son más potentes que las pruebas de dos colas
Las pruebas de una cola son más potentes que las correspondientes pruebas de dos colas en la dirección de la hipótesis alternativa. Sin embargo, su potencia en la dirección de la la hipótesis nula tiende a cero.
Esta condición podría dar lugar a que, al usar pruebas de una cola, se pasen por alto resultados inesperados. De ahí la recomendación de usar siempre pruebas de dos colas en investigación aplicada (cf. numeral 9).
¿Potencia cero?
Considérese el siguiente juego de hipótesis:
\[
H_0: \mu\le\mu_0
\] \[
H_a: \mu>\mu_0
\]
La hipótesis nula se rechaza con un nivel de significancia \(\alpha\) siempre que \(t_\text{c}>t_{\alpha(n-1)}\) (cf. región azul en figura 5.17).
Si se tuviera una prueba de dos colas y se contrastara con base en la misma información muestral, la hipótesis nula se rechazaría con un nivel de significancia \(\alpha\) siempre que \(|t_\text{c}|>t_{\alpha/2(n-1)}\) (cf. región roja en figura 5.17).

Y, puesto que \(t_{\alpha(n-1)}<t_{\alpha/2(n-1)},\) la probabilidad de rechazar la hipótesis nula de la prueba de cola derecha es mayor que la probabilidad de rechazar la hipótesis nula de la prueba de dos colas, para valores positivos de \(t_\text{c}.\)
\[
P(t_\text{c}>t_{\alpha(n-1)}) >P(t_\text{c}>t_{\alpha(n-1)})
\]
En otras palabras, la potencia de la prueba de una cola es mayor que la potencia de la prueba de dos colas, siempre que se obtengan resultados coherentes con la hipótesis alternativa: \(\overline{X}>\mu_0.\)
Observemos, sin embargo, el comportamiento de la prueba de una cola en el escenario de la hipótesis nula, que postula que la media poblacional es menor que un valor hipotético.
En dicho escenario, se espera que \(\overline{X}<\mu_0.\) Luego, se esperaría que el estadístico de prueba, cuyo numerador es \(\overline{X}-\mu_0,\) fuera negativo.
Y, dado que el criterio de rechazo solo contempla valores grandes y positivos del estadístico, la prueba de una cola no tiene capacidad para detectar desviaciones en la dirección opuesta. En consecuencia, cuando el parámetro se encuentra en esa región, la probabilidad de rechazo es despreciable y tiende a cero a medida que la desviación aumenta.
Esto es diferente a lo que sucede con la prueba de dos colas, en la que también se rechaza la hipótesis nula si \(t_\text{c}<-t_{\alpha/2(n-1)}.\)
Referencias bibliográficas
Agresti, A. and Caffo, B. (2000). Simple and effective confidence intervals for proportions and differences of proportions result from adding two successes and two failures. The American Statistician, 54(4), 280-288. https://doi.org/10.1080/00031305.2000.10474560
Agresti, A. and Coull, B. A. (1998). Approximate is better than «exact» for interval estimation of Binomial proportions. The American Statistician, 52(2), 119-126. https://doi.org/10.2307/2685469
Brown, L. and Li, X. (2005). Confidence intervals for two sample binomial distribution. Journal of Statistical Planning and Inference, 130(1), 359-375.
Correa, J. C. y Sierra, E. (2003). Intervalos de confianza para la comparación de dos proporciones. Revista Colombiana de Estadística, 26(1), 61-75.
Correa-Londoño, G. A. y Castillo-Morales, A. (2000). Tamaño de muestra para aproximación de un estadístico a la distribución normal. Agrociencia, 34(4), 467-476.
Delacre, M., Lakens, D. and Leys, C. (2017). Why psychologists should by default use Welch’s t-test instead of Student’s t-test. International Review of Social Psychology, 30(1), 92-101. http://doi.org/10.5334/irsp.82
Edwards, A.L. (1948). Note on the Correction for Continuity in Testing the Significance of the Difference between Correlated Proportions. Psychometrika, 13(3), 185-187. https://doi.org/10.1007/BF02289261
Fagerland, M. W., Lydersen, S. and Laake, P. (2011). Recommended confidence intervals for two independent binomial proportions. Statistical Methods in Medical Research, 24(2), 224-254. http://doi.org/10.1177/0962280211415469
Fagerland, M. W., Lydersen, S. and Laake, P. (2013). The McNemar test for binary matched-pairs data: mid-p and asymptotic are better than exact conditional. BMC Medical Research Methodology, 13(91). https://doi.org/10.1186/1471-2288-13-91
Freedman, D., Pisani, R. and Purves, R. (2007). Statistics (4th ed.). W.W. Norton & Company.
Kimmel, H. D. (1957). Three criteria for the use of one-tailed tests. Psychological Bulletin, 54(4), 351-353.
Lombardi, C. M. and Hurlbert, S. H. (2009). Misprescription and misuse of one-tailed tests. Austral Ecology, 34(4), 447-468. https://doi.org/10.1111/j.1442-9993.2009.01946.x
Márquez Fernández, M. E., López Ortiz, J. B., Correa Londoño, G., Pareja López, A. y Giraldo Solano, N. A. (2003). Detección del daño genotóxico agudo y crónico en una población de laboratoristas ocupacionalmente expuestos. Iatreia, 16(4), 275-282.
McNemar, Quinn. (1947). Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2), 153-157. https://doi.org/10.1007/BF02295996
Moser, B. K. and Stevens, G. R. (1992). Homogeneity of variance in the two-sample means test. The American Statistician, 46(1), 19-21. https://doi.org/10.1080/00031305.1992.10475839
Newcombe, R. G. (1998). Interval estimation for the difference between independent proportions: comparison of eleven methods. Statistics in Medicine, 17(8), 873-890. https://doi.org/10.1002/(SICI)1097-0258(19980430)17:8%3C873::AID-SIM779%3E3.0.CO;2-I
Sackrowitz, H. and Samuel-Cahn, E. (1999). P values as random variables–Expected p values. The American Statistician, 53(4), 326-331. https://doi.org/10.2307/2686051
Satterthwaite, F. E. (1946). An approximate distribution of estimates of variance components. Biometrics Bulletin, 2(6), 110-114. https://doi.org/10.2307/3002019
Suissa, S., & Shuster, J. J. (1991). The 2 x 2 Matched-Pairs Trial: Exact Unconditional Design and Analysis. Biometrics, 47(2), 361-372. https://doi.org/10.2307/2532131
Welch, B. L. (1938). The significance of the difference between two means when the population variances are unequal. Biometirka, 29(3/4), 350-362. https://doi.org/10.2307/2332010
Zimmerman, D. W. (2004). A note on preliminary tests of equality of variances. British Journual of Mathematical and Statistical Psychology, 57 Pt.1, 173-181. https://doi.org/10.1348/000711004849222
En ambos casos, la hipótesis nula plantea que los parámetros son iguales, mientras que la hipótesis alternativa plantea que son diferentes.↩︎
El primer subíndice de las variables aleatorias representa la población; el segundo indexa la variable dentro de dicha población. Así, por ejemplo, \(X_{21}\) representa la variable aleatoria 1 de la población 2.↩︎
La expresión a la derecha del símbolo de equivalencia está basada en los estadísticos de orden (cf. definición 2.1).↩︎
Mayor cercanía a la verdadera media poblacional.↩︎
Prueba o método que permite definir un resultado de manera inequívoca, constituyendo el referente de comparación y validación de cualquier otro método.↩︎
El primer subíndice de las variables aleatorias representa la población; el segundo indexa la variable dentro de dicha población. Así, por ejemplo, \(X_{21}\) representa la variable aleatoria 1 de la población 2.↩︎
Esta es una situación teórica que no puede verificarse en la práctica. Por esta razón, se recomienda el uso general de la prueba de Welch, que se presenta en la sección 5.2.2.↩︎
cf. sección 2.1.1.3.↩︎
El primer subíndice de las variables aleatorias representa la población; el segundo indexa la variable dentro de dicha población. Así, por ejemplo, \(X_{21}\) representa la variable aleatoria 1 de la población 2.↩︎
Aunque las notaciones \(\widehat\nu\) y \(\nu\) no son equivalentes, siendo más formal \(\widehat\nu,\) que representa al estimador del parámetro \(\nu,\) frecuentemente se obvia esta precisión.↩︎
Plantear que \(\mu_2\) es mayor que \(\mu_1\) es exactamente lo mismo que plantear que \(\mu_1\) es menor que \(\mu_2.\)↩︎
Este es el modelo probabilístico para el número de eventos que se presentan en una región espacial o temporal, con independencia del número de eventos que puedan presentarse en cualquier otra región disjunta. Si \(X \thicksim \text{Poisson} (\lambda),\) \(E(X)=\lambda,\) \(V(X)=\lambda.\)↩︎
¿¡Con dieta antes de iniciar el estudio y sin dieta después!?↩︎
\(\mu_\text{E}-\mu_\text{F}\) en el presente caso.↩︎
En este caso dejaría de ser válido lo indicado en la precaución 5.1 en cuanto a la irrelevancia del orden de los argumentos cuando se contrastan pruebas de dos colas.↩︎
\(100(1-2\times 0.05)\,\%=100(1-0.1)\,\%=90\,\%\)↩︎
Las medias son exactamente iguales a las de las muestras originales; las desviaciones estándar coinciden hasta la segunda cifra decimal.↩︎
mientras menor sea \(\alpha,\) mayor será \(n.\)↩︎
inf_2p(86, 106, 192, 192)↩︎por ejemplo \(X_1 = 90\) y \(X_2 = 110\).↩︎
Los objetos que resultan de importar datos de Excel mediante la función
read_excel{readxl}son de la clasedata.frame.↩︎Podrían haber quedado iguales por azar.↩︎
O asociación para el caso de las pruebas de independencia.↩︎
También denominados residuos tipificados ajustados en algunos textos.↩︎
Aunque los parámetros no son variables aleatorias, sus espacios paramétricos son continuos: existen infinitos valores entre cualquier par de valores del parámetro, sin importar cuan cercanos se encuentren entre sí. Esto aplica a todos los parámetros que suelen usarse en inferencia estadística, v. gr., \(\mu,\) \(\sigma^2\) y \(p.\)↩︎
Los intervalos de confianza para el presente caso son unilaterales superiores.↩︎
La región sombreada.↩︎
En el ámbito algebraico las proposiciones se evalúan en términos de verdad o falsedad; en el ámbito inferencial, se evalúan en términos de evidencia y riesgo de error.↩︎