
6 INTRODUCCIÓN AL DISEÑO DE EXPERIMENTOS
Los experimentos diseñados surgen en el marco de la inferencia estadística, sobre la cual se discute ampliamente en el capítulo 3 y muy particularmente en la sección 3.9.
La inferencia estadística clásica o frecuentista comprende el conjunto de herramientas mediante las cuales se realizan afirmaciones sobre parámetros poblacionales desconocidos, usando información muestral, con la mediación de un modelo probabilístico.
En el capítulo 4 se presentan las técnicas más usadas para responder preguntas sobre alguno de los parámetros que suelen utilizarse en la práctica investigativa para caracterizar poblaciones, esto es, la media, la varianza y la proporción. En tales casos, se usa la información suministrada por una muestra que se extrae de la población objetivo.
En el capítulo 5 se presentan las técnicas más usadas para la comparación de dos poblaciones, a través de sus parámetros. Se comparan varianzas, medias y proporciones. Para la realización de tales comparaciones se usan dos muestras: una de cada población.
En el presente capítulo se generalizan algunas de las técnicas presentadas en los capítulos precedentes, con el fin de comparar más de dos poblaciones a través de sus parámetros, lo que implica la obtención de una muestra por cada población.
Si bien cada una de las comparaciones entre múltiples parámetros proporciona información valiosa en contextos específicos, las pruebas de comparación de medias son, sin lugar a dudas, las más usadas en investigación.
Existen generalizaciones de la prueba de homogeneidad de varianzas que permiten comparar múltiples varianzas. Sin embargo, estas desempeñan un papel secundario y suelen utilizarse como herramientas diagnóstico para evaluar las condiciones requeridas para la realización de las pruebas de comparación de medias.
En cuanto al parámetro de la binomial, aunque se dispone de procedimientos específicos para la comparación de múltiples proporciones (cf. sección 5.4.2), en la práctica investigativa, tales situaciones suelen abordarse con base en la misma generalización que se utiliza para la comparación de medias.
En consecuencia, la generalización más importante de las técnicas inferenciales clásicas, en el contexto del diseño experimental, es la que se utiliza para la comparación de múltiples medias de poblaciones normales.
Aunque las técnicas que se presentan en este y en varios de los capítulos siguientes constituyen generalizaciones de las utilizadas con una y dos poblaciones, y comparten con ellas parte de su fundamento teórico, incorporan elementos adicionales que exigen ampliar algunas de las conceptualizaciones introducidas previamente.
Podría pensarse que los métodos inferenciales propios del diseño experimental son más complejos, pues implican la comparación simultánea de múltiples poblaciones. Sin embargo, la estructura que proporciona el diseño permite organizar dichas comparaciones de manera sistemática y eficiente.
6.1 Conceptos asociados con el diseño de experimentos
Como paso previo a la presentación de los conceptos asociados con los experimentos y su diseño, se define el experimento como una de las categorías resultantes de clasificar los estudios, según la intervención ejercida por el investigador. Seguidamente, se presentan algunos conceptos centrales de la experimentación diseñada.
6.1.1 Tipos de estudios, según el nivel de intervención
Muchos estudios pueden representarse mediante el esquema de la figura 6.1.
Aunque las denominaciones que se listan dentro de cada caja son equivalentes, su frecuencia de uso depende del contexto, haciendo que algunas expresiones —aunque correctas— puedan sonar extrañas al referirse a métodos particulares. El resaltado o atenuado de los elementos refleja su frecuencia de uso en el ámbito de los diseños experimentales.
Si bien los elementos de la caja izquierda son variables, muy a menudo se registran en escalas nominales u ordinales (cf. sección 1.2.1). Por tal motivo, resulta más natural designarlos como factores o tratamientos.
Incluso cuando tales variables se registran en una escala numérica, el modelo de análisis presentado en este capítulo omite dicha información, tomando cada nivel como una categoría diferente de una variable nominal (cf. sección 6.2).
Las denominaciones variable independiente, variable predictora o variable explicativa son más comunes en el contexto de análisis de regresión, en el que tales variables se miden en una escala numérica, y el método de análisis sí considera dicha información.
Por su parte, la denominación variable dependiente para el elemento del lado derecho es más usada en análisis de regresión, como contraparte de la variable independiente. En el contexto de los ensayos que se exploran en este capítulo, es más común referirse a este componente como respuesta o variable respuesta.
Nótese que la caja izquierda puede contener una o múltiples variables, mientras que la caja derecha solamente contiene una variable.
Nota 6.1: Técnicas univariantes
Es común que los ensayos generen múltiples respuestas. Sin embargo, en el contexto univariante se analizan una a una.
Las técnicas de análisis univariante usan un modelo probabilístico independiente para cada una de las variables respuesta registradas en el ensayo.
Este análisis no es incompatible con el uso adicional —cuando sea del caso— de técnicas bivariantes o multivariantes para explorar asociaciones entre las diferentes respuestas.
En la figura 6.1 resulta destacable el rol del material experimental como integrador de la relación entre las variables. No se hipotetiza una asociación abstracta entre variables, sino el efecto de unos tratamientos que actúan sobre un material experimental afectando una de sus características: la respuesta.
¡No implica causalidad!
Las pruebas estadísticas permiten declarar significancia de efectos.
La significancia, sin embargo, no implica por sí sola el establecimiento de relaciones de causalidad.
Los estudios en los que las variables tienen un rol asimétrico o diferenciado, como los representados en la figura 6.1, se clasifican a su vez en observacionales y experimentales, dependiendo del nivel de control o intervención ejercido por el investigador sobre los tratamientos.
En los estudios observacionales, el investigador se limita a observar, medir o registrar la respuesta de un fenómeno determinado, sin controlar ni modificar ninguno de los factores que pudieran tener un efecto sobre dicha respuesta.
En contraste, en los estudios experimentales, el investigador interviene, modifica, controla y establece los niveles de los tratamientos, acorde con sus requerimientos, para evaluar la respuesta bajo tales configuraciones.
Los estudios observacionales son muy comunes en investigaciones propias de las ciencias sociales, de la salud y del comportamiento, donde hay más restricciones para intervenir los hipotéticos factores causales.
Así, por ejemplo, un investigador de las ciencias médicas que deseara realizar un ensayo para respaldar la hipotética relación entre el hábito de fumar y el cáncer gástrico, no podría, por obvias razones éticas, intervenir el grupo de participantes, definiendo quiénes han de fumar y quiénes no.
En contraste, los estudios experimentales son más frecuentes en las investigaciones propias de las ciencias básicas y aplicadas, donde suelen existir menos limitaciones en el establecimiento y control de los hipotéticos factores causales.
Si, por ejemplo, un investigador de las ciencias agrarias deseara evaluar el efecto de diferentes densidades de siembra sobre el rendimiento de un cultivo, no tendría ninguna limitación para establecer parcelas con las diferentes densidades que deseara evaluar, siempre que contara, desde luego, con suficiente espacio y material vegetal.
Cuando se trabaja con personas, en adición a las limitaciones de carácter ético, las posibles alteraciones en el comportamiento también restringen el uso de los estudios experimentales. La aplicación consciente y dirigida de un estímulo sobre un grupo de individuos puede tener un efecto diferente al que dicho estímulo tendría si se presentara de manera natural.
El sesgo de deseabilidad social consiste en la tendencia de algunos individuos a tratar de responder acorde con lo que se supone que se espera de ellos. En tal sentido, los individuos sometidos a un tratamiento destinado a mejorar cierta habilidad podrían dedicar un esfuerzo extra en pro de mejorar la habilidad en cuestión, lo cual podría sesgar las conclusiones.
En otros casos, sin importar el área de investigación, las condiciones propias de los fenómenos estudiados hacen imposible un acercamiento experimental.
Un sociólogo que deseara investigar las dinámicas de las poblaciones que han sufrido desplazamiento forzado no podría realizar una aproximación experimental. Asimismo, un ecólogo que deseara comparar las dinámicas de dos ecosistemas no tendría más alternativa que observar dichas dinámicas en entornos que hubieran surgido de los procesos naturales propios de tales ecosistemas.
En el contexto del presente capítulo y los sucesivos, se utilizan indistintamente las expresiones experimento y estudio experimental en referencia a todos aquellos ensayos que se realizan con ánimo inferencial, en los que el investigador define y controla los niveles del factor cuyo efecto sobre la respuesta es motivo de evaluación.
El diseño de experimentos comprende el conjunto de protocolos que definen la manera adecuada de realizar tales estudios. A los ensayos que surgen en este contexto, también se les denomina experimentos diseñados.
Muestreo y diseño experimental
Aunque la clasificación de los estudios en observacionales y experimentales es una de las más extendidas en estadística aplicada y metodología científica, no es la única.
Así, por ejemplo, Hurlbert (1984) desarrolla una clasificación cuasi equivalente a la observacional/experimental, usando las denominaciones experimento mensurativo y experimento manipulativo, correspondientemente.
Asimismo, Hurlbert (1984) hace notar que la diferencia esencial es la misma que existe entre muestreo y experimentación: indica que lo concerniente a los experimentos mensurativos (estudios observacionales) suele compilarse en libros cuyo título habla de muestreo (sampling), mientras que lo relativo a los experimentos manipulativos (estudios experimentales) se desarrolla en libros cuyo título contiene el sustantivo diseño (design).
6.1.2 Factores de confusión
Aunque los factores de confusión pueden presentarse tanto en estudios observacionales como experimentales, en general, los estudios observacionales están más expuestos a estos.
Retomemos el ejemplo del investigador que desea evaluar la hipótesis de que el tabaquismo es un factor que incrementa el riesgo de cáncer gástrico. Descartada la opción de un estudio experimental, podría pensarse que para respaldar dicha hipótesis bastaría con comparar la prevalencia de cáncer gástrico en dos grupos: uno de fumadores y otro de no fumadores.
No obstante, más allá del factor de interés (el ser o no ser fumador) habría otros factores que podrían influir en el resultado, actuando como factores de confusión. Entre tales factores podrían mencionarse los hábitos alimentarios, el consumo de bebidas alcohólicas y el estrés.
Si, por ejemplo, en el grupo de fumadores los hábitos alimentarios fueran menos saludables que en el grupo de control, el consumo de bebidas alcohólicas más frecuente y los niveles de estrés más altos, estos actuarían como factores de confusión, sesgando el resultado y restándole validez.
Si, a partir de un estudio observacional, se encontrara que la prevalencia de cáncer gástrico es mayor en el grupo de fumadores que en el de no fumadores, sería difícil saber cuál o cuáles factores contribuyeron a dicho resultado: si se debió al hábito de fumar, a alguno o algunos de los factores no controlados que podrían estar asociados con los grupos comparados o a una combinación del factor de interés con los demás factores.
Teniendo en cuenta que, en el escenario planteado, no sería posible realizar un ensayo experimental, por los efectos deletéreos que ello podría conllevar sobre la salud de los participantes, supóngase que un investigador decide trabajar con ratas de laboratorio, sometiendo un grupo de estas a la inhalación de humo de tabaco y dejando el otro grupo libre de tal exposición.
Mediante este procedimiento podrían controlarse algunos de los posibles factores de confusión mencionados: los dos grupos recibirían exactamente el mismo alimento y no habría lugar a confusión por consumo de bebidas alcohólicas. No obstante, no se tendría garantía de estar controlando todos los posibles factores de confusión. Por mencionar solo uno, valga considerar el relativo al estrés. Podría suceder que las ratas sometidas a inhalación forzada de humo de tabaco experimentaran niveles más altos de estrés que las ratas del grupo control, en cuyo caso, el estrés sería un factor de confusión.
Además del estrés u otros posibles factores de confusión no vislumbrados, habría muchos otros aspectos que sería necesario considerar en un estudio como el planteado: ¿será comparable la sensación que experimentan los individuos que fuman por el placer que les produce y los individuos que se encuentran dentro de una cámara saturada con humo de tabaco?, ¿podría esta sensación diferencial sesgar los resultados?, ¿será igual el efecto en individuos sometidos a una exposición aguda que en aquellos con exposición crónica?, ¿constituyen las ratas un modelo adecuado para este tipo de estudios, pudiendo generalizarse los hallazgos a poblaciones humanas? La validez de este hipotético estudio tendría que argumentarse con base en las respuestas a esta y otras preguntas.
Supóngase ahora un estudio cuyo objetivo sea evaluar la efectividad de un medicamento. En principio podría considerarse el desarrollo de tal estudio mediante un esquema experimental, es decir, suministrando el medicamento a un grupo de pacientes, mientras que, para fines de comparación, otro grupo se mantendría como testigo, sin el medicamento.
Este diseño permitiría ejercer un mejor control sobre los posibles factores de confusión, mediante el balanceo de los dos grupos, teniendo en cuenta todos aquellos factores que, de acuerdo con el conocimiento y la experiencia del investigador, pudieran influir en el resultado.
Aunque un estudio como el planteado podría ser blanco de cuestionamientos éticos, por privar al grupo testigo del potencial efecto benéfico del medicamento evaluado, obviaremos este asunto para discutir cómo, aun en un estudio experimental como este, que permite controlar múltiples factores de confusión, podrían surgir otros factores de confusión.
En algunos ensayos médicos en los que se interviene una situación, la disposición sicológica de los pacientes puede convertirse en factor de confusión.
Los pacientes que saben o creen que se les suministró el tratamiento suelen tener una mejor disposición sicológica que aquellos que saben o creen que no se le suministró el tratamiento, lo que en cierto tipo de afecciones podría poner en ventaja a los primeros sobre los últimos, al grado de verse reflejado en los resultados. En este caso, el estado de ánimo actuaría como factor de confusión.
La necesidad de estrategias para controlar tales situaciones explica por qué en medicina son tan populares los estudios ciegos, en los que los pacientes no saben si pertenecen al grupo tratado o al grupo control. Esto evita que la disposición sicológica de los pacientes actúe como factor de confusión.
Desde luego, también debe considerarse la disposición sicológica de los médicos encargados de evaluar la respuesta.
Para evitar que los médicos realicen evaluaciones subjetivas intentando ver mejoría en los pacientes tratados y estancamiento o retroceso en los no tratados, suelen usarse estudios doble ciego, en los que ni los pacientes tratados ni los médicos evaluadores saben a qué grupo pertenece cada individuo.
En una situación en la que se considerara que los analistas también podrían sesgar los resultados, podría resultar conveniente que estos recibieran la información de manera codificada o enmascarada, con lo cual se tendría un estudio triple ciego.
Cuando únicamente los sujetos del tratamiento desconocen a qué grupo pertenecen, el estudio suele denominarse simple ciego.
Con respecto a tales denominaciones, Letelier, Manríquez y Claro (2004) indican que, dados los múltiples actores que suelen intervenir en los estudios, existen diversas interpretaciones entre los investigadores, editores de revistas biomédicas y autores de textos sobre métodos de investigación, en referencia a los ensayos en los que alguno o algunos de sus diferentes actores han sido objeto de técnicas de enmascaramiento de los tratamientos.
Consecuentemente, en lugar de tales denominaciones, recomiendan indicar explícitamente en todos los casos cuáles de los múltiples participantes fueron “ciegos”, es decir, quiénes desconocían la forma en que se aplicó la intervención sobre los grupos estudiados.
Una de las estrategias de enmascaramiento más usadas sobre los sujetos del tratamiento es el placebo, el cual consiste en un tratamiento que tenga exactamente la misma apariencia del tratamiento de interés, pero que difiera de este en lo esencial.
Si se estuviera ensayando, por ejemplo, un medicamento, el grupo no tratado debería recibir un producto lo más parecido posible al producto evaluado, teniendo en cuenta no solo el aspecto, en cuanto a presentación, textura, color, sabor, olor, temperatura y cualquier otra propiedad que pertinente, sino también en cuanto a la vía y frecuencia de administración. Lógicamente, el placebo carecería del principio activo cuyo efecto se deseara evaluar.
Con la administración de un placebo, se busca equiparar la disposición sicológica de los participantes, a fin de evitar que esta actúe como factor de confusión.
Aunque la acepción más común del placebo es la de un seudomedicamento, el término es generalizable a cualquier estrategia dirigida a darle a un tratamiento control la misma apariencia del tratamiento evaluado, de manera que todos los individuos crean estar recibiendo el mismo tratamiento.
Es importante usar un placebo siempre que la disposición de los sujetos pueda influir en los resultados. Podría pensarse que esta estrategia solo tendría lugar en estudios con personas; sin embargo, los especialistas en comportamiento animal podrían tener otra opinión al respecto. La pertinencia de incluir placebos en estudios con animales dependerá de la especie, de la naturaleza del efecto evaluado y de la respuesta que se registre.
En general, los estudios ciegos1, con el posible uso de placebo, pueden y deben usarse en cualquier situación en la que la disposición de los participantes, de los evaluadores o de cualquier otro actor del proceso pueda sesgar los resultados.
En un estudio con animales en el que no se considerara necesario aplicar una estrategia de enmascaramiento sobre los animales (placebo), pero sí sobre los evaluadores, cobraría especial relevancia la recomendación de Letelier et al. (2004), referente a la denominación de los estudios ciegos. ¿Cómo se llamaría un estudio con tales características? ¿Simple ciego o doble ciego?
Puesto que la estrategia de enmascaramiento estaría siendo usada únicamente sobre uno de los actores del ensayo (los evaluadores) podría pensarse en llamarlo simple ciego; no obstante, dicha denominación podría hacer creer que únicamente se usó estrategia de enmascaramiento sobre los animales. En consecuencia, resulta más claro indicar explícitamente cuál de los actores del ensayo desconocía la membresía de los individuos a los grupos de interés.
Aun en los estudios en los que se descarte un posible efecto por disposición sicológica de los participantes, pueden requerirse estrategias para equiparar aspectos secundarios a la aplicación de los tratamientos, de manera que estos sean comparables entre sí en lo esencial.
Así, por ejemplo, en un ensayo en el que la inoculación de un patógeno implique una punción en un tejido vegetal, sería necesario someter todos los tratamientos, incluso los que no consideren inoculación, al mismo protocolo, con punción incluida. Esto balancearía los tratamientos en lo concerniente a la punción y al protocolo de inoculación, descartando que estos pudieran actuar como factores de confusión. A tales acciones se les denomina genéricamente estrategias de control de factores de confusión.
Control de potenciales factores de confusión
Aunque, en general, los estudios experimentales permiten un mejor control de los potenciales factores de confusión, no garantizan su control absoluto.
Cuando la disposición de los participantes en un estudio pueda sesgar los resultados, es conveniente aplicar técnicas de enmascaramiento de la membresía de los sujetos a los diferentes grupos, mediante los denominados estudios ciegos.
La principal técnica de enmascaramiento para los sujetos del estudio consiste en suministrar un placebo al grupo control, con el fin de equilibrar la disposición sicológica entre los participantes de los grupos comparados.
Aun cuando el posible efecto sicológico de los participantes esté descartado —como en la mayoría de los estudios agrarios—, suele ser posible y necesario aplicar otras estrategias de control de factores de confusión.
6.1.3 Validez interna
Dado que la realización de inferencias válidas depende en gran parte del adecuado control de los posibles factores de confusión, la validez interna está determinada por el conjunto de acciones y condiciones que permiten ejercer dicho control en el estudio.
La validez interna es un concepto cualitativo. Cuando las condiciones en las que se realiza un estudio permiten ejercer un adecuado control sobre los principales factores de confusión, se dice que este tiene alta validez interna.
En contraste, los estudios que presentan fallas en el control de los posibles factores de confusión tienen baja validez interna.
En general, los protocolos experimentales empleados en ciencias básicas y aplicadas dan lugar a estudios con alta validez interna.
¡Es indispensable!
La validez interna es un requerimiento esencial de cualquier estudio en investigación.
Un estudio con baja validez interna, al no permitir inferencias válidas, no constituye un soporte adecuado para el avance científico.
6.1.4 Validez externa
Al igual que la validez interna, se trata de un concepto cualitativo. Cuanto mayor sea la validez externa de un estudio, mayor será su alcance. En contraste, el alcance de un estudio con baja validez externa será restringido.
La validez externa está ligada a las características del material experimental y a las condiciones en que se realice el estudio.
Las conclusiones de un estudio en el que se someta un material experimental muy específico a la acción de los tratamientos, bajo condiciones experimentales muy puntuales, difícilmente podrán generalizarse a poblaciones amplias. En tales casos, su alcance quedará restringido a las subpoblaciones del material experimental particular y a las condiciones en que se realizó el ensayo.
La validez externa resulta cuestionable, por ejemplo, cuando se realizan ensayos de laboratorio cuyas conclusiones pretenden generalizarse a situaciones de campo.
La validez externa de los procesos inferenciales es la contraparte de la denominada representatividad en los procesos de muestreo.
Aunque ambos conceptos se refieren a la congruencia entre la muestra y la población, pudiendo pensarse que basta con obtener una muestra representativa para tener alta validez externa, los procesos muestrales clásicos y los experimentos diseñados siguen vías opuestas.
Mientras que en los métodos de muestreo se parte de una población claramente definida2 y, acorde con las circunstancias, se plantean estrategias para extraer una muestra de dicha población que recoja, de la manera más fidedigna posible, sus características esenciales (representatividad), en los experimentos diseñados es común partir de la muestra, buscando que esta refleje las características esenciales de una población (validez externa), que muchas veces es difusa, desconocida o que incluso puede no existir (cf. figura 6.2).
Esta circunstancia exige un esfuerzo de abstracción por parte del investigador para enfocar adecuadamente los alcances y posibilidades de generalización de sus resultados.

¿¡Interna o externa!?
A diferencia de la validez interna, que constituye una condición indispensable para la obtención de inferencias estadísticas válidas, la validez externa es un atributo cuyo grado de importancia depende de los objetivos del estudio.
Un trabajo con alcance restringido puede aportar evidencia sólida y valiosa, siempre que su validez interna esté garantizada.
6.1.5 Ventajas de los estudios experimentales
Como se ha señalado, los estudios observacionales constituyen una aproximación fundamental en múltiples áreas del conocimiento, especialmente cuando existen restricciones éticas, prácticas o estructurales que impiden la manipulación de los factores de interés. En tales contextos, representan no solo una alternativa viable, sino con frecuencia la única vía posible para abordar determinados fenómenos.
No obstante, cuando las condiciones lo permiten, los estudios experimentales ofrecen ventajas metodológicas que los convierten en el soporte más robusto para la contrastación de hipótesis causales.
Los estudios experimentales generalmente son más eficientes que los observacionales para controlar y separar el efecto de los factores de interés del de otros factores secundarios que también afectan la respuesta. En otras palabras, posibilitan un mejor control de potenciales factores de confusión, dando lugar a estudios con mayor validez interna.
La aleatorización es el mecanismo más usado para dicho fin (cf. sección 6.1.11). En el capítulo 7 se discuten los esquemas de aleatorización más utilizados en el diseño de experimentos.
Otra de las ventajas de los estudios experimentales radica en la posibilidad que ofrecen de suponer y muestrear poblaciones hipotéticas, aun cuando las mismas no existan en la naturaleza.
Esta posibilidad surge del hecho de que el investigador no está restringido a observar los factores considerados causales, tal y como se presentan en su estado natural, sino que puede disponerlos como le resulte más conveniente para contrastar las hipótesis de interés.
Cada vez que se ensaya una nueva condición o ajuste en un proceso productivo, se está infiriendo sobre una población inexistente.
Un investigador podría evaluar un nuevo sustrato para la producción de bioetanol, aun si dicho sustrato nunca antes hubiese sido usado para dicho fin. En tal sentido, estaría infiriendo sobre una población que aún no existe. Si los resultados del ensayo fueran promisorios, bien podría escalarse el proceso, dando lugar a una población en la que se produzca bioetanol a partir de dicho sustrato.
Algo análogo sucede en los procesos de fitomejoramiento, donde se evalúan ciertos materiales, bajo condiciones en las cuales dichos genotipos quizá no no se encuentren naturalmente. Como resultado de dicho proceso podrían generarse poblaciones con el material o materiales que exhiban las respuestas más deseables.
Aunque los estudios experimentales no siempre son viables, bien sea por la naturaleza de los factores estudiados, por cuestiones éticas, económicas o de posible alteración de los resultados, estas limitantes suelen ser menos restrictivas en numerosos ámbitos de las ciencias básicas y aplicadas. Por tal motivo, y teniendo en cuenta su mayor eficiencia para el control de los potenciales factores de confusión, los estudios experimentales son el soporte más común de la investigación en dichas áreas.
Una de las misiones de los asesores estadísticos consiste en seleccionar el diseño experimental más adecuado para cada situación, es decir, aquel que permita un control eficaz de los factores de confusión y posibilite contrastar las hipótesis de interés con la mayor precisión y al menor costo posible.
¡Mejor los experimentales!
Las principales ventajas de los estudios experimentales con respecto a los observacionales son:
Permiten un mejor control de los factores de confusión, lo que generalmente se traduce en mayor validez interna.
Permiten suponer y muestrear poblaciones inexistentes o aún no realizadas en la práctica.
6.1.6 Tratamientos
Tratamiento es una denominación genérica para cada una de las categorías estudiadas, sin importar su naturaleza. Aunque en algunos experimentos médicos pueda referirse a las diferentes estrategias de manejo de una enfermedad, no se limita a ello.
En un experimento diseñado para evaluar el efecto de la luz sobre la producción de café, los tratamientos podrían ser con sombrío y libre exposición. Estas corresponden a dos categorías del factor manejo de la luz.
También es común usar el término tratamientos, en plural, como sinónimo de factor, especialmente cuando el experimento tiene un único factor. Para la presente situación bien podría decirse que se tienen dos tratamientos de manejo de la luz, consistentes en sombrío y libre exposición.
Cuando se establecen los tratamientos en un estudio experimental, queda definido un número igual de poblaciones. Para el presente ejemplo una de las poblaciones sería la de las plantaciones de café a libre exposición y la otra la de las plantaciones de café con sombrío.
La evaluación del efecto de las diferentes estrategias de manejo de la luz sobre la producción media de café es equivalente a lo estudiado en el capítulo 5, donde se evalúa, por ejemplo, el efecto de dos niveles de pH sobre la síntesis de PHA (ejemplo 5.2) o el efecto de enlatar los tomates sobre su contenido medio de hierro (ejemplo 5.4). Lo que difiere es principalmente el lenguaje específico utilizado en cada escenario.
Lo que en el contexto experimental es la variable respuesta o la respuesta, en el capítulo 5 se denomina simplemente la variable, sin ningún calificativo adicional. Esto se debe a que el modelo conceptual desarrollado en el capítulo 5 no considera la relación entre dos variables, sino el posible cambio en el parámetro de centralidad de una variable cuando esta se evalúa en dos condiciones específicas.
Asimismo, lo que en el contexto de los experimentos diseñados se ha definido como tratamientos, en el capítulo 5 suele denominarse grupos, aunque en ocasiones, también en el contexto de comparación de dos poblaciones, se hace referencia a este elemento como tratamiento o factor.
La denominación grupo, a pesar de su ambigüedad —y justamente gracias a ella— puede resultar conveniente, pues evita entrar en disquisiciones teóricas para precisar si se hace referencia a la muestra de campo, a la muestra teórica, a la población de campo o a la población teórica (cf. sección 3.9). Todo lo anterior queda recogido diciendo que se comparan dos grupos. Esta denominación también suele utilizarse en el contexto de los experimentos diseñados.
La situación planteada anteriormente —es decir, la de un experimento con dos tratamientos— corresponde con las presentadas en el capítulo 5, no solo en el ámbito conceptual, sino también en el operativo. El método de análisis que se desarrolla en la sección 6.2 es una generalización de la prueba de \(t\) descrita en la sección 5.2.1; al tratarse de una generalización, puede usarse para comparar más de dos grupos.
Si en la investigación que busca averiguar el efecto de manejo de la luz sobre la producción de café se quisiera evaluar más de dos modalidades de dicho factor, bien podría abordarse mediante un experimento diseñado, usando el método de análisis descrito en la sección 6.2. El investigador podría tener interés, por ejemplo, en evaluar el efecto de los tratamientos sombrío, semisombra y libre exposición sobre la producción de café.
En un estudio para evaluar el efecto de antioxidantes en la conservación de semen porcino, los tratamientos podrían ser vitamina E, quercetina y vitamina E + quercetina. El investigador puede elegir los tratamientos, de acuerdo con sus necesidades, sin que sea necesario que cada tratamiento esté restringido a una categoría básica del factor. No hay, por tanto, limitación alguna para definir un tratamiento a partir de la combinación de otros tratamientos, si se considerara que dicha estrategia es viable y promisoria.
En estudios más complejos, como aquellos que involucran sistemas silvopastoriles, cada uno de los tratamientos podría quedar definido con base en la conglomeración de los factores que caracterizan cada uno de los sistemas de interés; es decir que para la definición de cada tratamiento se tendría en cuenta cuáles son los componentes del sistema arbóreo, su densidad de siembra y distribución, el componente pastura, el componente animal, así como el manejo propio de cada sistema.
Debe tenerse presente, sin embargo, que un estudio con estas características tendría necesariamente una validez externa restringida. Las conclusiones serían aplicables únicamente a sistemas que reproduzcan de manera simultánea el conjunto de condiciones estructurales que definen cada uno de los arreglos evaluados. En consecuencia, la población de referencia no estaría constituida por “los sistemas silvopastoriles” en general, sino por aquellos que compartan integralmente la configuración específica considerada en el estudio.
Adicionalmente, si se encontraran diferencias entre los sistemas comparados, no sería posible atribuirlas con claridad a un componente particular. Al evaluarse configuraciones completas y no factores aislados, los efectos observados corresponderían al resultado conjunto de múltiples elementos que actúan de manera simultánea, lo que limita la capacidad de identificar la contribución individual de cada uno de ellos3.
En nutrición vegetal es común utilizar la técnica del elemento faltante, en la cual los tratamientos se definen mediante la sustracción del elemento cuyo efecto se desea evaluar. Un ensayo de esta índole podría considerar los siguientes tratamientos: completo, sin N, sin P, sin K, sin Ca, sin Mg, sin S y sin B. Desde luego, el conjunto de tratamientos podrá variar según la especie y el sustrato.
Para evaluar el efecto de un extracto de nim (Azadirachta indica) en el control del gusano cogollero (Spodoptera frugiperda), se consideran tres concentraciones en partes por millón: 1000, 2000 y 3000. En este caso, a diferencia de los descritos anteriormente, los tratamientos se definen con base en algunos valores de una variable numérica (concentración). No obstante, el método de análisis de los experimentos diseñados (cf. sección 6.2) no considera la información numérica que pudiera estar involucrada en la definición de los tratamientos y sus correspondientes etiquetas, pudiendo usarse cualquier otro juego de etiquetas, tal como \(\text{c1},\) \(\text{c2},\) \(\text{c3}\) o \(\text{a},\) \(\text{b},\) \(\text{c},\) sin que ello afecte el resultado.
Con frecuencia, cada tratamiento surge de las combinaciones de los niveles de dos o más factores. Si en el ensayo para evaluar productividad en café, adicionalmente al factor manejo de la luz, se quisiera evaluar el factor densidad de siembra, con 2500 plantas/ha, 5000 plantas/ha y 10000 plantas/ha, los tratamientos estarían constituidos por las 6 combinaciones de los 2 niveles de manejo de la luz y los 3 niveles de densidad, así:
sombrío, 2500 plantas/ha
sombrío, 5000 plantas/ha
sombrío, 10000 plantas/ha
libre exposición, 2500 plantas/ha
libre exposición, 5000 plantas/ha
libre exposición, 10000 plantas/ha
Si en el mismo ensayo adicionalmente se quisieran evaluar 4 estrategias de fertilización, se tendrían \(2\times3\times4=24\) tratamientos. Esta situación se cubre en el capítulo 10.
6.1.6.1 Controles
Con el fin de establecer referentes de comparación, a menudo resulta conveniente, e incluso necesario, considerar uno o más tratamientos control —tradicionalmente denominados tratamientos testigo en experimentación agraria—, que pueden ser de varios tipos: positivos, negativos, absolutos o relativos.
Este tratamiento se incluye justamente cuando se requiera controlar la idoneidad de las condiciones experimentales, pues permite descartar fallas en la conducción del experimento en caso de que los demás tratamientos no generen la respuesta esperada. En tal sentido, contribuye a controlar posibles falsos negativos.
Así, por ejemplo, en los ensayos de susceptibilidad de plantas a algún patógeno, debe incluirse un material cuya alta susceptibilidad a la enfermedad evaluada sea conocida. Si el control positivo no manifestara los síntomas de la enfermedad, habría que reconsiderar la viabilidad de las cepas y/o los protocolos de inoculación.
Un ensayo en el que se evaluaran diferentes patógenos podría exigir varios controles positivos. Aunque el análisis de los resultados puede contemplar la comparación entre estos y los demás tratamientos, en muchas ocasiones —cuando la uniformidad de su respuesta puede generar dificultades para el cumplimiento de los supuestos del análisis de varianza (cf. sección 6.3)— se incluyen únicamente para verificar la idoneidad de las condiciones experimentales.
La inclusión de un control negativo facilita detectar el efecto de factores no previstos sobre la respuesta.
En pruebas médicas de diagnóstico, por ejemplo, es usual incluir como parte del ensayo general una muestra sobre cuya negatividad se tenga certeza. Un resultado positivo en dicha muestra evidenciaría fallas en la conducción del ensayo, ya sea por contaminación, por problemas con el reactivo o por cualquier otra circunstancia, lo que obligaría a descartar el material comprometido y a repetir las pruebas realizadas bajo tales condiciones.
Los controles negativos disminuyen la posibilidad de falsos positivos.
En un estudio en el que se evalúen diversas sustancias para inhibir el crecimiento de un microorganismo podrían incluirse varios controles negativos, según los sustratos o solventes utilizados. Con ello se descarta que los efectos observados puedan atribuirse a dichos sustratos o solventes.
En un ensayo de fertilidad, el control absoluto consistiría en no aplicar fertilizante. En un experimento sobre el manejo de una enfermedad en un cultivo, implicaría no aplicar intervención alguna.
En tales casos, los controles absolutos podrían brindar información relevante en etapas tempranas de la investigación, cuando se esté evaluando si se justifica aplicar fertilizante o implementar alguna estrategia de control de enfermedades.
No obstante, en etapas avanzadas de la investigación, cuando ya se tenga certeza de que el cultivo exige fertilización y requiere estrategias de manejo de enfermedades para evitar pérdidas significativas o incluso totales, no sería conveniente incluir controles absolutos.
En otros casos, los ensayos no admiten la inclusión de un control absoluto, dada la imposibilidad de observar el proceso bajo tales condiciones.
Así ocurre, por ejemplo, cuando se evalúan diferentes sustratos para el cultivo de un microorganismo, pues no es posible considerar un tratamiento que contemple su crecimiento sin medio de cultivo alguno.
En un ensayo de variedades, el control relativo sería la variedad más frecuentemente usada en una localidad determinada4.
Es muy importante que los ensayos incluyan controles relativos siempre que ello sea posible, puesto que estos constituyen el referente de comparación para los nuevos tratamientos.
Lógicamente, no todos los ensayos admiten controles relativos, en particular los correspondientes a los procesos de innovación, en los que no se cuenta con ningún referente.
Conviene advertir que las denominaciones anteriores no obedecen a un único criterio de clasificación ni constituyen categorías necesariamente excluyentes. Mientras que los controles positivos y negativos se definen en función del comportamiento esperado de la respuesta bajo determinadas condiciones experimentales, los controles absolutos y relativos se caracterizan por el tipo de intervención realizada o por su relación con la práctica habitual en la población objetivo. En consecuencia, un mismo tratamiento podría recibir distintas denominaciones según el aspecto que se desee resaltar, lo que dificulta la construcción de una tipología exhaustiva y mutuamente excluyente.
Dada la cantidad de controles o referentes que pueden surgir en un experimento, en ocasiones las denominaciones presentadas pueden quedarse cortas, e incluso hay casos en los que no resulta del todo claro cuál sea la denominación más adecuada.
Si en un estudio sobre la inhibición del crecimiento de un hongo mediante extractos bacterianos se incluyera un tratamiento en el que el hongo estuviera solo en el sustrato, sin extracto bacteriano alguno, ¿cómo habría de denominarse dicho tratamiento? ¿Control negativo, por cuanto al no aplicar extracto bacteriano no debería observarse inhibición en el crecimiento del hongo? ¿Control positivo, dado que el hongo se evalúa bajo las condiciones en las que debería crecer sin impedimento alguno?
Análogamente a lo recomendado por Letelier et al. (2004) en referencia a los estudios ciegos (cf. sección 6.1.2), consideramos que, en lugar de precisar o restringir las acepciones de las denominaciones presentadas —o de generar nuevas etiquetas— con la expectativa de que todos los usuarios de nuestras investigaciones adopten nuestros mismos criterios, resulta más conveniente explicar con claridad en qué consisten los tratamientos de control incluidos en un experimento.
De hecho, conviene recordar que, cualquiera que sea la denominación de tales grupos —o incluso si no reciben ninguna en particular—, estos son tratamientos, y en muchas ocasiones se analizan conjuntamente con los demás tratamientos.
¡Ayudan a controlar posibles factores de confusión!
Más allá de cualquier clasificación, los tratamientos control cumplen una función esencial: permiten aislar el efecto de interés frente a posibles factores de confusión.
Siempre que sea posible y pertinente, debería contemplarse su inclusión en el diseño experimental.
6.1.7 Unidad experimental
Cuando se evalúa un medicamento sobre un conjunto de pacientes, la unidad experimental es el paciente. Análogamente, si se suministra un tratamiento hormonal a un grupo de búfalas, la unidad experimental es cada búfala. Cuando se realiza una poda de raíz en árboles de café, la unidad experimental es cada árbol.
Aunque esta aproximación —en la que la unidad experimental es un individuo— es la más directa, no es la única posible. El hecho de que la denominación del concepto incluya el término unidad no convierte automáticamente a los individuos en unidades experimentales.
El aspecto clave que distingue a las unidades experimentales es la independencia de las respuestas que se evalúan en ellas.
En muchas ocasiones, la unidad experimental puede ser una fracción de lo que para otros fines se consideraría una unidad.
Este escenario es muy común en experimentos con plantas, en los que no necesariamente se toma el árbol completo como unidad experimental. Al evaluar podas aéreas, la unidad experimental podría ser una rama. En un ensayo de patogenicidad, la unidad experimental podría ser una hoja o una rodaja de hoja.
Aunque esta situación es menos común en animales o personas, en la sección 5.2.3, al hacer referencia a las muestras pareadas, se menciona una hipotética situación en la que se ensayan dos protectores solares de uso tópico, realizando sendas aplicaciones en los miembros superiores de un individuo. En tal caso, cada brazo del individuo constituye una unidad experimental.
En la evaluación de tres diluyentes para la criopreservación de semen bovino, podría dividirse el eyaculado de un toro en tres partes, para evaluar cada uno de los diluyentes en un tercio del eyaculado. En este caso, cada tercio del eyaculado constituye una unidad experimental.
En otras ocasiones, la unidad experimental surge de la integración de varios elementos. En ensayos agronómicos de campo, la unidad experimental suele estar constituida por un conjunto de plantas, denominado parcela. La unidad experimental en un ensayo de nutrición animal podría ser el grupo de animales en una jaula. Para los ensayos con insectos, la unidad experimental a menudo está conformada por un grupo de individuos. En los ensayos de viabilidad o de germinación suele tomarse un grupo de semillas como unidad experimental.
Existen varias razones para utilizar unidades experimentales conformadas por la integración de elementos. Para su análisis, a estas razones las denominaremos distribucionales, de validez externa, de previsión y de reducción de la variabilidad.
La razón distribucional consiste en establecer condiciones que propicien la convergencia a la distribución normal, en virtud del teorema central del límite (cf. teorema 3.1).
Cuando la aplicación del tratamiento da lugar a una respuesta binaria de cada uno de los elementos, (cf. sección 3.6.1), se hace necesario tomar un conjunto de tales elementos, de manera que la respuesta consistente en el número de éxitos del conjunto —que sigue una distribución binomial (cf. sección 3.6.2)— pueda aproximarse a la normal, posibilitando la aplicación de la técnica de análisis expuesta en la sección 6.2.
Una situación similar surge cuando la respuesta sobre cada elemento es de tipo Poisson, es decir, cuando se evalúa el número de eventos que se presentan en una región espacial o temporal, con independencia del número de eventos que puedan presentarse en cualquier otra región disjunta5, en particular, cuando el valor esperado de tales variables es pequeño, i. e., \(\lambda<5.\)
En general, siempre que se prevea que la distribución de las respuestas sobre los elementos individuales se aparte significativamente de la normal, será conveniente usar unidades experimentales conformadas por un grupo de elementos, analizando la respuesta media de tales unidades experimentales.
Otro criterio para usar unidades experimentales conformadas por conjuntos de elementos, incluso cuando no hay respuestas binarias, Poisson o de otro tipo diferente a la normal es la razón de validez externa.
Cuando la población objetivo está conformada por grupos de elementos cuyas respuestas puedan diferir de las que se obtendrían de los elementos aislados, se hace necesario trabajar con unidades experimentales que reproduzcan la dinámica de tales grupos.
Si un sistema de producción de gallinas ponedoras suele manejarse con base en una densidad de cinco gallinas por jaula, todo ensayo que se realice para evaluar el efecto de algún otro factor (dietas, por ejemplo), deberá estar basado en unidades experimentales conformadas por grupos de cinco gallinas en una jaula, con lo cual se propicia la validez externa, en lo que a densidad se refiere.
Lógicamente, si el factor que se desea evaluar es precisamente la densidad, esta habrá de modificarse acorde con los tratamientos.
En sistemas de producción agroindustriales, el rendimiento de las unidades productivas difiere del que se obtendría de sumar los rendimientos que generaría individualmente cada uno de los elementos que conforman dichas unidades al ser plantado aisladamente, debido a la competencia, el microambiente y otras interacciones que se generan al interior de las unidades productivas.
Consecuentemente, deben tomarse unidades experimentales en las que se reproduzcan tales condiciones. El tamaño de tales unidades experimentales o parcelas depende del tipo y la magnitud de tales interacciones, lo cual a su vez depende del tipo de cultivo, así como de la respuesta y los tratamientos que se evalúen.
La otra razón para usar unidades experimentales conformadas por un conjunto de elementos tiene que ver con la previsión de eventualidades. En consecuencia, la hemos denominado razón de previsión.
Cuando hay alta probabilidad de mortalidad o daño de los elementos durante el desarrollo del experimento, el uso de unidades experimentales conformadas por varios elementos puede proteger contra la pérdida de la unidad experimental.
En tales casos, debe analizarse si las causas de la mortalidad o daño de los elementos son imputables a los tratamientos o no. Si así fuera, esto tendría que verse reflejado en la respuesta de la unidad experimental, para lo cual podría tomarse, por ejemplo, la suma de las respuestas individuales. En caso contrario, podría tomarse la respuesta media de los elementos sobrevivientes.
Finalmente está la razón de reducción de la variabilidad. Las respuestas de las unidades experimentales conformadas por varios elementos presentan menor variabilidad que las lecturas de los elementos individuales. Esto se traduce en una mayor potencia de la prueba para comparación de medias (cf. sección 6.1.9).
¡Tienen ventajas!
El uso de unidades experimentales conformadas por un conjunto de elementos es una estrategia que conlleva varias ventajas:
Propicia la convergencia de las respuestas a la distribución normal
Incrementa la validez externa
Protege contra la eventual pérdida de elementos
Disminuye la variabilidad de las respuestas
6.1.7.1 Submuestreo
En ocasiones, puede ser recomendable o incluso necesario evaluar la respuesta sobre una muestra de cada unidad experimental, en lugar de hacerlo sobre la totalidad de esta.
Esta estrategia se presentó en el ejemplo 5.3, donde se muestreó cada una de las unidades muestrales; es decir, se muestreó la muestra. De ahí la denominación de submuestreo.
En el presente contexto, el conjunto de unidades experimentales sometido a un tratamiento es equivalente a las muestras mencionadas en el capítulo 5, por lo que igualmente se habla de submuestreo6.
Las lecturas de las subunidades se usan para estimar la respuesta de la correspondiente unidad experimental. Aunque con frecuencia se usa la media para tal fin, consideramos que la mediana puede resultar más adecuada en estas situaciones, dado que ofrece estimaciones más estables en presencia de valores extremos (cf. sección 2.1.1.2).
Un ejemplo de esta estrategia se da al realizar conteos de microorganismos. En tales casos, por la dificultad subyacente en contabilizar los microorganismos sobre toda la unidad experimental, se contabilizan las UFC en un número determinado de campos en la unidad experimental y se toma la media o la mediana de dichas lecturas.
La estrategia del submuestreo podría parecer contraria a la de usar unidades experimentales conformadas por la integración de elementos (cf. sección 6.1.7). No obstante, el hecho de que en un experimento se utilicen unidades experimentales constituidas por varios elementos no implica que sea necesario evaluar la totalidad de estos, en particular si dicha estrategia se usa para propiciar la validez externa o para mantener el balance ante la eventual pérdida de elementos7.
Así, al evaluar un tratamiento para el control de una plaga en un cultivo, resulta conveniente que las unidades experimentales sean parcelas que reproduzcan las condiciones en las que suele presentarse la plaga y en las que se aplicaría el tratamiento en la población objetivo (validez externa). No obstante, dado lo dispendioso que puede resultar el registro de la respuesta en todos los elementos que conforman cada unidad experimental, puede recurrirse al muestreo para estimar la respuesta de interés en cada una de ellas.
¡Mejor la mediana!
Al realizar submuestreo, es preferible usar la mediana como estimador de la respuesta en la unidad experimental, dada su robustez frente a valores extremos.
6.1.8 Replicación y conceptos afines
La replicación ha sido reconocida como un principio central de la experimentación científica desde la primera mitad del siglo xx, con la consolidación de la estadística aplicada al diseño de experimentos.
Una afirmación realizada en 1930 por Fisher y Wishart, reproducida por Hurlbert (1984), lo expresa con claridad:
En la actualidad a nadie se le ocurriría evaluar la respuesta a un tratamiento mediante la comparación de dos parcelas: una tratada y la otra sin tratar.
Esta aseveración resulta fácil de asimilar en el escenario planteado: en un ensayo de campo, si se observaran diferencias (o la ausencia de estas) entre dos parcelas, no sería posible discernir si obedecen al tratamiento o a otros factores que podrían diferir entre las parcelas —como el microclima, los suelos, el drenaje, la microbiota, el nivel de fertilidad o el historial de manejo—, o bien a la combinación de estos con el tratamiento.
Además, con una sola parcela por condición (tratamiento/sin tratamiento) no sería posible determinar si las respuestas observadas representan el comportamiento típico bajo tales condiciones o si corresponden a casos extremos. En otras palabras, sin replicación no sería posible valorar la consistencia de las respuestas.
¡Sin replicación, no hay experimentación estadística!
La replicación proporciona una base sólida para estimar la variabilidad inherente a los sistemas estudiados, permitiendo realizar comparaciones confiables entre tratamientos.
En ausencia de replicación, los resultados de un ensayo carecen del sustento necesario para ser interpretados con rigor científico.
La replicación es el concepto; las réplicas son los valores específicos mediante los cuales se cristaliza este concepto para cada tratamiento.
Si en un experimento cada tratamiento se asigna de manera independiente a tres unidades experimentales, se considera que dicho tratamiento tiene tres réplicas. Si un tratamiento se aplicara a una única unidad experimental, tendría una réplica; sin embargo, en tal caso no existiría replicación del tratamiento.
¿¡Réplica o repetición!?
No existe consenso sobre la diferencia —si es que la hay— entre réplica y repetición. Algunos autores presentan un único concepto, definiéndolo mediante uno de estos términos. Otros, que también conciben un único concepto, utilizan indistintamente ambos términos como sinónimos. Hay quienes proponen dos conceptos claramente diferenciados, e incluso quienes lo hacen, pero invirtiendo las correspondencias entre las definiciones y los términos.
Puesto que lo relevante es el concepto, más que el término, en el presente texto se utiliza el término réplica, sin descalificar otras denominaciones o distinciones.
¡Sin réplicas, no hay confianza!
La construcción de intervalos de confianza exige contar con réplicas. Entre más réplicas se tengan, mayor será la precisión de los intervalos y la potencia de las comparaciones.
Además de las réplicas de cada tratamiento, el experimento completo también puede replicarse, ya sea por diferentes investigadores, en diferentes momentos o lugares, y utilizando diferente material experimental. De ahí surge el concepto de replicabilidad.
La falta de replicabilidad de un ensayo no necesariamente implica sesgo o alteración de los resultados por parte del investigador, pudiendo deberse a condiciones particulares que rodearon el experimento inicial. Sin embargo, constituye una seria limitación, pues impide fundamentar aplicaciones o implementaciones a partir de las conclusiones originales.
¡Sin replicabilidad, no hay alcance!
Cuando la replicabilidad de un experimento se pone en duda, el alcance de sus conclusiones queda automáticamente limitado, por más significativos que hayan podido ser los resultados.
La repetibilidad es un concepto estrechamente relacionado con el de replicabilidad, pero circunscrito a condiciones más controladas.
La falta de repetibilidad indicaría que las diferencias observadas (o ausencia de estas) en algunos de los ensayos —o quizá en todos— son manifestaciones de factores aleatorios no controlados.
La falta de repetibilidad entre ensayos obligaría a una reconceptualización teórica, no siendo adecuado fundamentar ninguna acción en los resultados de algún ensayo particular.
¡Sin repetibilidad, no hay fiabilidad!
Cuando un experimento no logra ser repetible, la confianza en sus resultados queda comprometida.
Para que las conclusiones de una serie de ensayos sean generalizables, es indispensable que sean consistentes entre sí.
Aunque el concepto de reproducibilidad no se asocia directamente con la fase experimental, sino más bien con el análisis de los datos, se incluye en esta sección para establecer un paralelo con los conceptos presentados anteriormente.
¡Sin reproducibilidad, no hay trasparencia!
En ocasiones, la falta de reproducibilidad es debida a la no disponibilidad de los datos originales o del código utilizado para el procesamiento de la información.
En tales casos, los resultados carecen de transparencia.
La tabla 6.1 sintetiza la idea central de la replicación junto con los conceptos afines discutidos en esta sección. La concurrencia de estos criterios le confiere confianza, alcance, fiabilidad y trasparencia a la experimentación estadística.
| Concepto | Idea central | Lema asociado |
|---|---|---|
| Replicación | Evaluar cada tratamiento varias veces en unidades independientes para estimar la variabilidad y permitir comparaciones confiables | ¡Sin replicación, no hay experimentación estadística! |
| Réplicas | Número de unidades experimentales independientes en las que se evalúa cada tratamiento | ¡Sin réplicas, no hay confianza! |
| Replicabilidad | Consistencia de los resultados cuando el experimento completo se repite en otros contextos (investigadores, lugares, momentos, material) | ¡Sin replicabilidad, no hay alcance! |
| Repetibilidad | Consistencia de los resultados cuando el experimento se repite bajo las mismas condiciones (mismo lugar, equipos, técnicos, material comparable) | ¡Sin repetibilidad, no hay fiabilidad! |
| Reproducibilidad | Posibilidad de obtener los mismos resultados numéricos al repetir un análisis sobre los mismos datos, incluso con otro analista o software | ¡Sin reproducibilidad, no hay trasparencia! |
6.1.9 Error experimental
¿Error…?
La denominación de este concepto es un tanto desafortunada, puesto que puede hacer pensar en fallas asociadas con la conducción del experimento o en los tipos de error propios de las pruebas de hipótesis (cf. tabla 3.4).
No obstante, el error experimental se refiere a variabilidad, acorde con lo presentado en la sección 2.1.2.1.
Desde un punto de vista conceptual —e incluso operacional—, el error experimental es un promedio ponderado de las varianzas dentro de cada tratamiento.
El error experimental puede verse como una generalización de la varianza combinada, \(S^2_\text{p},\) usada como estimador de la varianza común de dos poblaciones normales cuyas medias se comparan mediante una prueba de \(t\) (cf. expresión 5.3).
La expresión equivalente a \(S^2_\text{p}\) para calcular el error experimental en un ensayo con \(k\) tratamientos y \(r_i\) réplicas para el \(i\)-ésimo tratamiento es la siguiente:
\[
\text{EE}=\frac{(r_1-1)S_1^2+(r_2-1)S_2^2+\dotsb+(r_k-1)S_k^2}
{\sum\limits_{i=1}^{k}r_i-k}
\tag{6.1}\]
Si bien el error experimental es equivalente —tanto en lo conceptual como en lo operacional— a la varianza combinada, \(S^2_\text{p},\) presentada en la sección 5.2.1.1, la expresión 6.1 rara vez se utiliza para su cálculo. En la sección 6.2.3 se presenta una estrategia operacional más práctica para su obtención (cf. nota 6.3).
No obstante, la expresión 6.1 permite visualizar lo que representa el error experimental, facilitando analizar cuáles son sus fuentes y qué estrategias pueden seguirse para su control.
En la sección 6.1.8 se indicó que la replicación es necesaria para valorar la consistencia de las respuestas asociadas con cada tratamientos. Esta consistencia —entendida como la similitud entre las respuestas de diferentes unidades experimentales sometidas a un mismo tratamiento— se mide a través de la varianza dentro de cada grupo, es decir, el error experimental.
De este modo, la noción intuitiva de consistencia introducida anteriormente adquiere una formulación matemática: sin replicación no sería posible estimar dicha varianza y, por tanto, no sería posible valorar la consistencia de las respuestas.
Mientras menor sea el error experimental, más consistentes serán los resultados y menor será la incertidumbre de los procesos inferenciales. Por el contrario, una alta variación en las respuestas dentro de un mismo tratamiento denota una menor consistencia y, por tanto, una incertidumbre mayor en los procesos inferenciales.
¡Y que las consistencias sean consistentes: homogeneidad de varianzas!
El análisis de varianza, la técnica inferencial que se presenta en la sección 6.2, supone que las respuestas a los diferentes tratamientos presentan una misma consistencia, lo que se expresa como el supuesto de homogeneidad de varianzas (cf. sección 6.3.3).
Si dicho supuesto es válido, también resulta válido obtener una estimación de la variabilidad promedio dentro de los tratamientos, usando la expresión 6.1.
¡Consistencia del experimento!
El error experimental constituye el referente de la consistencia, precisión o variabilidad interna de los tratamientos, y permite valorar la incertidumbre de las inferencias que se realizan sobre las medias poblacionales a partir de los resultados de un experimento.
Un error experimental bajo produce estimaciones más precisas.
6.1.10 Papel de las réplicas
La precisión de las estimaciones no solo se ve afectada por la magnitud del error experimental, sino también por el número de réplicas. A mayor número de réplicas, mayor será la precisión de las estimaciones.
Considérese un intervalo de confianza del \(100(1−\alpha)\,\%\) para la diferencia entre dos medias, \(\mu_1 − \mu_2,\) cuando se tienen varianzas homogéneas, el cual está dado por la siguiente expresión (cf. expresión 5.6):
\[
\left(\overline{X}_1-\overline{X}_2\right)\pm t_{\alpha/2\left(n_1+n_2-2\right)}
\sqrt{S_\text{p}^2\left(\frac{1}{n_1}+\frac{1}{n_2}\right)}
\]
En el contexto de los experimentos diseñados, un intervalo de confianza equivalente para la diferencia de medias de dos tratamientos está dado por la siguiente expresión (cf. sección 8.4.1):
\[
\left(\overline{Y}_{1\bullet}-\overline{Y}_{2\bullet}\right)\pm t_{\alpha/2\left(\text{gle}\right)}
\sqrt{\text{CME}\left(\frac{1}{r_1}+\frac{1}{r_2}\right)}
\]
Nótese que las réplicas de los tratamientos (\(r_1\) y \(r_2\)), equivalentes a los tamaños de muestra (\(n_1\) y \(n_2\)), aparecen en el denominador del término que se suma y se resta a la diferencia de medias muestrales para construir el intervalo. Consecuentemente, para un error experimental dado (representado por \(\text{CME}\): cf. sección 6.2), mientras mayor sea el número de réplicas, más estrechos serán los intervalos de confianza, es decir que las inferencias serán más precisas.
Dada la relación existente entre intervalos de confianza y pruebas de hipótesis (cf. sección 4.5), un mayor número de réplicas implica una mayor potencia en las comparaciones; es decir, se hace más probable declarar diferencias significativas que correspondan con diferencias reales entre las medias poblacionales.
¡El número de réplicas importa!
En general, a mayor número de réplicas, mayor será la precisión en las estimaciones y mayor será la potencia de las pruebas.
¡Pero…!
Aunque la precisión de las estimaciones y la potencia son características deseables, el incremento en el número de réplicas también implica, en general, tiempos de experimentación más largos, costos más elevados y mayores dificultades operativas que pueden traducirse en errores de manejo del experimento y de registro de la información.
En consecuencia, el número de réplicas de un experimento es un aspecto que debe definirse conjuntamente entre el estadístico y el investigador, considerando las particularidades del ensayo y buscando la máxima eficiencia posible. En la sección 7.3.1 se presentan algunas pautas para ello.
6.1.11 Aleatorización
La aleatorización es exclusiva de los estudios experimentales, no solo porque su definición involucra los conceptos de tratamientos y unidades experimentales, sino también por la dificultad de realizar una acción equivalente en los estudios observacionales.
Aun si se adapta el lenguaje —tomando los diferentes niveles del factor en los estudios observacionales como equivalentes de los tratamientos, y las unidades observacionales como equivalentes a las unidades experimentales—, en los estudios observacionales sigue siendo inviable realizar una asignación al azar de los diferentes niveles del factor sobre las unidades observacionales.
Esta imposibilidad o dificultad en la manipulación de los niveles del factor para asignarlos sobre las unidades es lo que caracteriza los estudios observacionales. En la sección 6.1.1 se ilustró esta limitación al considerar un ensayo para respaldar la hipotética relación entre el hábito de fumar y el cáncer gástrico, donde, por obvias razones, no era posible intervenir el grupo de participantes, definiendo quiénes habrían de fumar y quiénes no.
La aleatorización constituye el principal mecanismo de los estudios experimentales para controlar potenciales factores de confusión. Gracias a ella, los estudios experimentales gozan, en general, de mayor validez interna que los estudios observacionales.
Mediante la aleatorización se espera que, en caso de que existan factores secundarios asociados con las unidades experimentales que puedan tener efecto sobre la respuesta, sus niveles queden repartidos entre los diferentes grupos.
En el hipotético experimento mencionado en la sección 6.1.2, consistente en evaluar el efecto de la exposición al humo de tabaco sobre el cáncer gástrico en ratas de laboratorio, supóngase que se cuenta con 20 ratas. Un posible experimento consiste en someter 10 de esas ratas —elegidas al azar— a la inhalación de humo de tabaco, dejando las otras 10 como grupo control, sin inhalación.
Un correcto mecanismo de aleatorización debe garantizar que cualquiera de las 20 ratas tenga exactamente la misma probabilidad de ser asignada a cualquiera de los dos grupos experimentales. Con esto se espera que, en caso de existir factores genéticos que hagan que algunos individuos sean más propensos que otros a desarrollar el cáncer gástrico, los niveles de tales factores queden distribuidos al azar entre los dos grupos, disminuyendo la posibilidad de que actúen como factores de confusión.
Desde un punto de vista didáctico, una de las mejores maneras de ilustrar el proceso de aleatorización consiste en enumerar las ratas de 1 a 20. Paralelamente, se generan etiquetas equivalentes en cartones u otro soporte físico, que se introducen en un recipiente que impida su visualización. A continuación, se extraen 10 de tales etiquetas al azar; las correspondientes ratas se asignan a uno de los grupos y las demás ratas se asignan al otro grupo.
Lógicamente, este proceso puede ser poco práctico, especialmente en experimentos grandes. Durante mucho tiempo fueron muy populares las tablas de números aleatorios, con base en las cuales se realizaban los procesos de aleatorización. En la actualidad, tales procesos suelen realizarse con alguna ayuda informática.
En R se usa la siguiente instrucción para seleccionar 10 números diferentes del 1 al 20. ¡Compruébelo!
sample(1:20, 10)Si se estuviera diseñando un experimento con base en la técnica del elemento faltante, usando los 8 tratamientos descritos en la sección 6.1.6, con cuatro réplicas por tratamiento, se requerirían 32 unidades experimentales.
La aleatorización podría estar basada en los resultados de ejecutar la siguiente instrucción en R, asignando el primer tratamiento a las unidades identificadas con los cuatro primeros números generados, el segundo tratamiento a las cuatro siguientes y así sucesivamente hasta aplicar todos los tratamientos sobre las unidades experimentales.
sample(1:32, 32)Los escenarios anteriores ejemplifican una de las modalidades de la aleatorización: aleatorización en la asignación de los tratamientos sobre las unidades experimentales. Esta modalidad se corresponde con lo expresado en la definición 6.16.
En ensayos agronómicos en los que se tiene la parcela como unidad experimental, el proceso de aleatorización queda reflejado en la disposición espacial de las parcelas. Se le denomina, por tanto, aleatorización espacial.
Supóngase que se desean evaluar cuatro tratamientos \((\text{A},\) \(\text{B},\) \(\text{C}\) y \(\text{D}),\) con tres réplicas, para lo cual se requieren 12 parcelas. El esquema más equilibrado consiste en asignar cada tratamiento a 3 unidades experimentales al azar, tal y como se ilustra en la figura 6.3.
\(\text{A}\)
\(\text{C}\)
\(\text{D}\)
\(\text{B}\)
\(\text{D}\)
\(\text{B}\)
\(\text{C}\)
\(\text{A}\)
\(\text{C}\)
\(\text{A}\)
\(\text{B}\)
\(\text{D}\)
Los ensayos de campo exigen particular atención, por las diferencias en microclima, fisiografía y suelos que pueden existir entre las parcelas. Se espera que la magnitud de tales diferencias sea directamente proporcional a la distancia, es decir, que estas diferencias sean más marcadas entre parcelas distantes que entre parcelas vecinas, dando lugar a un gradiente.
Cuando no se sabe si tales condiciones cambiantes están presentes, y mucho menos el gradiente o dirección de máximo cambio de estas, la aleatorización espacial, consistente en distribuir las unidades experimentales al azar en el espacio disponible, evita que tales gradientes, en caso de existir, favorezcan o desfavorezcan algún tratamiento particular.
En tal sentido, la aleatorización espacial protege contra posibles factores de confusión asociados con la posición de la unidad experimental.
Si en el ensayo agronómico que se ilustra en la figura 6.3 hubiese algún gradiente (pendiente, fertilidad, humedad, profundidad efectiva, densidad del suelo, radiación solar, etc.) que resultara favorable para las unidades ubicadas a la izquierda y desfavorable para las ubicadas a la derecha8, este afectaría aleatoriamente algunas réplicas de algunos tratamientos, sin sesgar el resultado.
Este efecto protector de la aleatorización contra posibles factores de confusión no se tendría si los tratamientos estuvieran ordenados, quedando, por ejemplo, las tres réplicas del tratamiento \(\text{A}\) en la primera columna, las de \(\text{B}\) en la segunda, etc.
La aleatorización espacial también protege contra el sesgo por alteraciones externas que, sin estar intrínsecamente asociadas con la posición de la unidad experimental, pueden aparecer en una dirección determinada. Este sería el caso, por ejemplo, de vientos que soplaran en una dirección determinada o algún foco de una plaga o enfermedad que surgiera en un punto dado.
Aunque la posibilidad de gradientes o cambios asociados con la posición de las unidades experimentales es mayor en ensayos de campo que en ensayos de invernadero o de laboratorio, en estos últimos pueden actuar factores de confusión más sutiles, como la intensidad de la luz, la aireación, la temperatura o la humedad relativa, manteniéndose presente, además, la posibilidad de alteraciones por factores externos, tales como la contaminación.
Consecuentemente, estos ensayos, así como cualquier otro en el que las unidades experimentales ocupen una posición fija, también deben someterse a un proceso de aleatorización espacial, con el fin de controlar posibles factores de confusión asociados con la posición de las unidades experimentales.
En muchos experimentos, las unidades experimentales, a pesar de no estar fijas en un primer momento, como las parcelas en los ensayos de campo, van a ocupar una posición fija una vez se inicie el ensayo. Este sería el caso de unidades experimentales conformadas por macetas, bolsas, bandejas y cajas de petri, entre otras.
En tales casos, también es necesario realizar aleatorización espacial. Sería muy pobre el control sobre los factores de confusión si el investigador se limitara a aleatorizar la asignación de los tratamientos sobre las unidades experimentales, ubicando luego las unidades experimentales de manera ordenada, con todas las réplicas de un mismo tratamiento contiguas entre sí.
Lógicamente, la aleatorización espacial solo es aplicable cuando las unidades experimentales ocupan una posición fija durante el desarrollo del experimento.
Si se consideran, por ejemplo, los ensayos con animales que no están sometidos a confinamiento, la aleatorización se aplica únicamente al momento de asignar los tratamientos a las unidades experimentales disponibles. Durante el desarrollo del experimento, los animales podrán desplazarse, acorde con el manejo dispuesto para estos.
En muchos ensayos, particularmente en los que dependen de equipos para su realización, no es posible realizar todas las corridas experimentales simultáneamente.
En tales casos, se calibra el equipo a las condiciones exigidas por un tratamiento, se realiza el proceso experimental y finalmente se toma la lectura de la variable o variables respuesta. Una vez finalizada esta corrida experimental, se recalibra el equipo para las condiciones experimentales de una segunda corrida y se repite todo el proceso hasta concluir todas las corridas experimentales.
En tales casos, es necesario realizar una aleatorización temporal, es decir, ejecutar las corridas en un orden aleatorio, de manera que se controlen los posibles factores de confusión asociados con el tiempo.
A pesar de ser muchos los factores secundarios que pueden variar a lo largo del tiempo, estos pueden agruparse en las siguientes categorías: condiciones medioambientales, condiciones imputables al equipo o instrumento y condiciones asociadas con el evaluador. La variabilidad de tales factores depende de la duración del ensayo y de las características del mismo.
El potencial de las condiciones medioambientales para actuar como factores de confusión es especialmente alto en campo, en invernaderos o en galpones. No obstante, tales condiciones también podrían alterar algunos ensayos de laboratorio.
Los equipos y herramientas pueden verse afectados por el desgaste acumulativo de piezas o componentes, dando lugar a variaciones sistemáticas9 en los resultados.
Cuando las lecturas pueden verse afectadas por el criterio, la pericia, el entrenamiento o el cansancio que el operario va acumulando a lo largo del tiempo, tales factores también pueden aportar confusión.
En cualquier caso, se espera que las corridas experimentales más cercanas en el tiempo compartan condiciones más homogéneas de los factores secundarios que aquellas más distantes en el tiempo. Por tal motivo, debe evitarse la contigüidad temporal de las diferentes réplicas de cada tratamiento.
Mediante la aleatorización temporal se busca romper cualquier posible asociación entre los tratamientos y los factores secundarios asociados con el tiempo, evitando que estos actúen como factores de confusión.
La tabla 6.2 resume los diferentes tipos de aleatorización y la protección que ofrecen.
| Tipo | Protección |
|---|---|
| Aleatorización en la asignación de los tratamientos sobre las unidades experimentales | Contra factores de confusión asociados con las unidades experimentales |
| Aleatorización espacial | Contra factores de confusión asociados con la posición de las unidades experimentales |
| Aleatorización temporal | Contra factores de confusión asociados con el momento de ejecución |
¡Aleatorice!
Todos los estudios experimentales deben someterse a los tipos de aleatorización que les sean aplicables, acorde con su naturaleza.
El primer paso de aleatorización generalmente consiste en asignar los tratamientos de manera aleatoria sobre las unidades experimentales disponibles. Un segundo paso puede consistir en una aleatorización espacial o temporal.
En ocasiones, los niveles del factor son inherentes a las unidades experimentales, lo que impide realizar el proceso de aleatorización.
Cuando se evalúa, por ejemplo, el efecto del factor sexo sobre una respuesta cualquiera, no es posible partir de un grupo de unidades experimentales asexuadas, asignándole al azar un nivel del factor sexo (macho o hembra) a cada una de ellas. Lo mismo sucede cuando se evalúan razas, variedades, clones, cepas o cualquier otra característica intrínseca a la unidad experimental.
¿Entonces sería observacional?
¡Exactamente!
La aleatorización es un mecanismo propio de los estudios experimentales. Si no es posible realizar una asignación aleatoria de los tratamientos sobre las unidades experimentales, se trata de un estudio observacional.
No obstante, este aspecto suele pasar desapercibido, dado que el modelo de análisis es el mismo que se emplea para los estudios experimentales.
¿Son cuasiexperimentos?
Shadish, Cook y Campbell (2002) definen los cuasiexperimentos como ensayos que comparten propósitos y detalles estructurales con los experimentos, diferenciándose de estos únicamente en la falta de aleatorización.
Aunque resulta tentador aplicar esta denominación a los ensayos descritos anteriormente, Shadish et al. (2002) conceptualizan los cuasiexperimentos en el contexto de las ciencias sociales, mencionando como posibles causas para la ausencia de aleatorización el hecho de que los individuos que participan en el ensayo se autoseleccionen en alguno de los grupos de interés o que sean asignados de manera subjetiva por el administrador del experimento, quien decide cuáles individuos han de recibir cada tratamiento.
Esta situación difiere de la descrita anteriormente, en la que no se trata de fallas o limitaciones en el proceso de aleatorización, sino de una imposibilidad estructural de aplicarla. En tal sentido, no encontramos conveniente denominarlos cuasiexperimentos.
En los estudios cuasiexperimentales descritos por Shadish et al. (2002) existe la posibilidad de un sesgo de selección que actúe como factor de confusión, por lo que estos estudios presentan, en general, menor validez interna que los estudios experimentales.
Los estudios en los que los tratamientos son inherentes a las unidades experimentales —aunque son observacionales10— no son susceptibles al sesgo de selección y suelen realizarse en condiciones más controladas que las de muchos otros estudios observacionales, por lo que su validez interna suele ser comparable a la de los estudios experimentales, con posible disminución en su validez externa.
Aunque, en los casos descritos, la imposibilidad de aleatorizar podría suplirse mediante la obtención de muestras aleatorias de las correspondientes poblaciones objetivo, esto tampoco se cumple en la práctica.
Una muestra verdaderamente aleatoria de los machos y las hembras de una especie determinada exigiría contar con un marco de muestreo de la población objetivo, en el que cada individuo tuviera la misma probabilidad de ser seleccionado. Desde luego, esto es igualmente irrealizable.
En la práctica se trabaja con muestras disponibles, es decir, con los animales que se tengan en la estación experimental, con el material vegetal que pueda adquirirse o con las cepas con las que cuente el laboratorio, según sea la naturaleza del ensayo.
En estos casos, es necesario analizar a profundidad si el material experimental disponible sí representa plenamente las características de las poblaciones objetivo; de no ser así, la validez externa quedaría comprometida.
Aunque estos ensayos no admiten un proceso de asignación aleatoria de los tratamientos sobre las unidades experimentales, podrían permitir aplicar un proceso de aleatorización espacial: el esquema ilustrado en la figura 6.3 bien podría corresponder a un ensayo de variedades.
Esta posibilidad, aunada al nulo sesgo de selección, es la que permite manejar y analizar estos ensayos de igual manera que los estudios experimentales.
En ocasiones pueden mezclarse factores experimentales y observacionales en un mismo estudio. Por ejemplo, al suministrar una dieta en machos y hembras, lo referente a las dietas sería experimental y, por tanto, susceptible de aleatorización; lo concerniente a los sexos sería observacional.
6.1.11.1 Intercalamiento
La aleatorización constituye el principal mecanismo de los estudios experimentales para controlar potenciales factores de confusión. Se espera que, si existen factores secundarios asociados con las unidades experimentales que pudieran tener efecto sobre la respuesta, sus niveles queden repartidos entre los diferentes grupos.
En consonancia con este objetivo, Hurlbert (1984) resalta la necesidad de propiciar un adecuado intercalamiento (interspersion) espacial o temporal entre las unidades experimentales, de manera que las réplicas de un mismo tratamiento no queden agrupadas.
Este autor señala que el intercalamiento es la característica crítica en el control de factores de confusión; la aleatorización es solo el mecanismo que generalmente —aunque no siempre— permite lograr dicho intercalamiento.
La figura 6.4 representa un posible esquema de asignación de tratamientos en un ensayo agronómico, el cual —aunque podría haber surgido de un proceso de aleatorización— no permitiría controlar factores de confusión, por no contar con un adecuado intercalamiento espacial, ya que las réplicas de cada tratamiento quedan agrupadas.
\(\text{A}\)
\(\text{B}\)
\(\text{C}\)
\(\text{D}\)
\(\text{A}\)
\(\text{B}\)
\(\text{C}\)
\(\text{D}\)
\(\text{A}\)
\(\text{B}\)
\(\text{C}\)
\(\text{D}\)
Para evitar este tipo de situaciones, podría pensarse que —en lugar de un esquema aleatorio— sería preferible utilizar un arreglo sistemático11.
De hecho, esta era, según Hurlbert (1984), la posición de William S. Gosset (Student), quien la defendió frente a Ronald A. Fisher, padre de la aleatorización, durante 13 años, tanto a través de correspondencias, como mediante argumentaciones públicas en la Royal Statistical Society.
Acorde con Hurlbert (1984), esta discusión nunca quedó zanjada y fueron algunas circunstancias históricas las que finalmente inclinaron la balanza en favor de la aleatorización: tras la muerte de Gosset, Fisher —quien lo sobrevivió 25 años y lo supero notablemente en producción académica (más de 300 artículos y 7 libros, frente a los 22 artículos de Gosset)— tuvo suficiente tiempo para consolidar su posición a través de su rol como profesor, consultor y consejero de otros científicos, a nivel mundial.
Uno de los argumentos en contra de los arreglos sistemáticos es que estos no siempre protegen contra los factores de confusión, en particular en situaciones en las que el intervalo del espaciamiento coincida con el periodo de variación de algún factor.
Hurlbert (1984) señala que este riesgo es muy pequeño en la mayoría de las situaciones de campo, puesto que cuando algún factor fluctúa en magnitud en un área experimental, suele hacerlo de manera irregular, más que periódica. En tal sentido, habría mayor riesgo de obtener una estimación sesgada del efecto de los tratamientos usando algunos arreglos aleatorizados que usando arreglos sistemáticos.
El principal argumento en contra de los arreglos sistemáticos es que su uso impide el cálculo exacto del nivel de significancia nominal, \(\alpha.\)
No obstante, tal y como lo indica Hurlbert (1984), el nivel de significancia nominal de un experimento corresponde al promedio de los niveles de significancia que se obtendrían al considerar todos los posibles arreglos aleatorizados.
Los arreglos estrictamente aleatorizados permiten calcular de manera exacta el nivel de significancia nominal del experimento, pero algunos de tales arreglos —particularmente aquellos en los que las réplicas de los tratamientos queda agrupadas— ejercen un control muy pobre sobre los posibles factores de confusión.
Por su parte, los arreglos sistemáticos, aunque no permiten conocer el valor exacto del nivel de significancia nominal, suelen dar lugar a niveles de significancia efectivos menores para el ensayo.
Cuando existen gradientes, los arreglos intercalados, sean sistemáticos o no, usualmente logran un nivel de significancia menor que el nominal, es decir que protegen mejor contra el error tipo I, mientras que los arreglos con tratamientos agrupados (como el de la figura 6.4) dan lugar a niveles de significancia superiores al nominal.
Hurlbert (1984) cierra la discusión sobre este tema con una pregunta retórica: ¿Es más útil saber que el alfa nominal elegido representa un límite superior probable para el nivel de significancia del ensayo o conocer exactamente el valor del alfa nominal sin tener idea sobre el posible límite superior del nivel de significancia del ensayo?12
¿¡Aleatorizado o intercalado!?
Tomando lo mejor de ambas estrategias —aun a sabiendas de que esta solución pueda no ser la más ortodoxa—, se recomienda usar esquemas de asignación de tratamientos que, estando basados en la aleatorización, produzcan un adecuado nivel de intercalamiento.
Esta recomendación, aunque parezca temeraria, realmente no es novedosa: es lo que muchos investigadores hacen en la práctica, aunque rara vez se describa explícitamente.
6.1.12 Seudoreplicación
La definición de replicación tiene un elemento central: la independencia (cf. definición 6.10). Hurlbert (1984) acuñó el término seudoreplicación para describir las situaciones en las que se usan unidades de evaluación que —por no ser independientes— no cumplen el objetivo de la replicación (cf. sección 6.1.8).
Recordemos que el objetivo de la replicación es valorar la consistencia de las respuestas dentro de cada grupo o, en otras palabras, estimar la variabilidad entre unidades experimentales sometidas a un mismo tratamiento mediante el error experimental (cf. sección 6.1.9).
El caso más común de seudoreplicación surge en situaciones en las que la unidad experimental está conformada por la integración de elementos (cf. sección 6.1.7), y se usa la variabilidad entre tales elementos en representación de la variabilidad entre unidades experimentales sometidas al mismo tratamiento.
Al no existir independencia entre las respuestas de tales elementos, estas suelen ser más similares entre sí —es decir, menos variables— que las provenientes de unidades experimentales independientes.
En la sección 6.1.7, haciendo referencia a un ensayo con gallinas ponedoras, se justificó el uso de cinco gallinas por jaula para propiciar la validez externa. En este experimento sería inadecuado calcular el error experimental con base en la variabilidad existente entre las gallinas que comparten jaula, puesto que se encuentran sometidas a las mismas condiciones ambientales, sanitarias, de interacción, etc., no siendo posible suponer independencia entre las respuestas registradas sobre cada una de ellas.
Si el objetivo del estudio consiste en evaluar el efecto de una serie de tratamientos sobre el sistema productivo de las gallinas ponedoras —que se maneja en jaulas de 5 gallinas—, las respuestas individuales observadas sobre cada una de las gallinas no reflejan el comportamiento del componente básico de la población: el grupo de 5 gallinas dentro de cada jaula.
La diferencia esencial entre la respuesta del conjunto y las de sus elementos individuales es la misma que existe entre la unidad experimental y sus componentes.
No es que la evaluación de elementos individuales sea incorrecta. Es una práctica común en experimentación y se denomina submuestreo (cf. sección 6.1.7.1). Sin embargo, en tales casos es necesario integrar dicha información mediante alguna medida de tendencia central13 que represente la respuesta de la unidad experimental. La seudoreplicación consiste en usar las lecturas de las submuestras —como si fueran réplicas verdaderas— para calcular el error experimental.
En un estudio realizado por Muñoz, García, Correa, Atencio y Pardo (2012), se evalúa el efecto de sustratos para perifiton sobre los parámetros fisicoquímicos del agua en estanques con policultivo de tilapia (Oreochromis niloticus) y bocachico (Prochilodus magdalenae). En tal caso, aunque las respuestas se registran sobre una muestra colectada en diferentes puntos del estanque, la unidad experimental es el estanque.
Las réplicas en este ensayo son los estanques a los que se les asigna cada tratamiento de manera independiente. Aunque esto pueda ser evidente por el tipo de respuestas, podría no serlo tanto si en lugar de evaluar parámetros fisicoquímicos del agua se estuviera evaluando producción.
En tal caso, el investigador podría verse tentado a tomar las lecturas registradas en peces individuales —como si fueran verdaderas réplicas— para calcular el error experimental. No obstante, dado que los peces dentro de un estanque están sometidos a una expresión común del efecto del sustrato para perifiton, las respuestas expresadas por cada uno de estos no son independientes.
La cuestión que debe tenerse en mente al valorar si una lectura constituye o no una verdadera réplica es si refleja adecuadamente la variabilidad existente en las poblaciones correspondientes a los tratamientos evaluados. En el estudio de Muñoz et al. (2012), la variabilidad que existe en las poblaciones con un sustrato particular para perifiton únicamente se expresa entre estanques.
Otro caso ampliamente reconocido como seudoreplicación es el que surge cuando se comparan tratamientos empleando un término de error construido con base en lecturas tomadas a lo largo del tiempo sobre la misma unidad.
El problema no radica en tomar lecturas lo largo del tiempo sobre la misma unidad experimental. Esto es correcto y permite estimar la variabilidad aportada por el tiempo, con base en la cual pueden realizarse comparaciones entre los tiempos. El problema de la seudoreplicación radica en usar la variabilidad entre tiempos para comparar tratamientos.
Para realizar comparaciones válidas entre tratamientos es necesario contar con una estimación de la variabilidad de estos, la cual únicamente puede obtenerse a partir de unidades que expresen de manera independiente el efecto del tratamiento; no de las variaciones a lo largo del tiempo de una misma unidad sometida a un tratamiento particular. El análisis de las medidas repetidas en el tiempo se desarrolla en la ?sec-med-rep.
Además de ser inadecuada para estimar el error experimental, la seudoreplicación no permite controlar posibles factores de confusión.
Supóngase que en un estudio de producción piscícola en el que solo se cuenta con dos estanques, se busca comparar dos estrategias de alimentación, aplicando sendas estrategias a los estanques disponibles.
Para solventar el problema que conlleva tener tratamientos sin replicación, un investigador podría verse tentado a usar las lecturas de los individuos dentro de cada estanque para calcular la variabilidad dentro de cada grupo y comparar los tratamientos.
No obstante, si se produjera algún tipo de contaminación en uno de los estanques, todos los peces dentro de ese estanque estarían en una condición desfavorable frente a los peces del estanque no contaminado. Consecuentemente, la contaminación actuaría como factor de confusión en dicho ensayo, no siendo posible establecer con baja probabilidad de error si las diferencias observadas (o la falta de diferencias) se deberon a la estrategia de alimentación, a la contaminación o a una combinación de ambos factores. La solución, desde luego, consiste en usar varios estanques por estrategia de alimentación.
En tal caso, si se usara un esquema de aleatorización con un adecuado intercalamiento (cf. sección 6.1.11.1), sería muy poco probable que se presentara una situación en la que se contaminaran todos los estanques de un tratamiento, quedando libres de contaminación los del otro tratamiento.
Una situación en la que también surge la seudoreplicación aparece cuando, una vez iniciado un ensayo de campo y asignados los tratamientos, se pretende aumentar su potencia, particionando las parcelas en subparcelas, con la pretensión de hacerlas fungir como réplicas.
Estos ensayos adolecerían de los mismos problemas anotados anteriormente. Por una parte, la vecindad espacial de las subparcelas probablemente haría que estas exhibieran un comportamiento más similar que el de unidades intercaladas espacialmente; por otra parte, la vecindad de las unidades dejaría más expuesto el ensayo al sesgo por factores de confusión.
Es importante aclarar que en estos casos la seudoreplicación surge por particionar las unidades tras haber asignado los tratamientos, con lo cual se generan grupos de unidades vecinas con un mismo tratamiento.
Si el problema del bajo número de réplicas fuera diagnosticado antes de asignar los tratamientos, sería correcto realizar la partición de unidades grandes en otras más pequeñas, de manera que al asignar los tratamientos, estos quedaran intercalados entre las unidades disponibles.
En este caso se contaría con verdaderas réplicas, bastando con evaluar si las unidades resultantes son del tamaño necesario para brindar una adecuada validez externa (cf. sección 6.1.4).
En estudios en los que se busca comparar sistemas o condiciones de gran escala, se hace necesario trabajar con unidades en las que las respuestas puedan no ser totalmente independientes.
En un estudio realizado por Suescún et al. (2017), en el que se evalúa el efecto de diferentes coberturas vegetales sobre la pérdida de nutrientes por escorrentía, se parte de cuatro áreas con las coberturas que son objeto de análisis.
Dentro de cada una de tales áreas se establecen varias parcelas de escorrentía, para valorar el comportamiento de la escorrentía en cada cobertura.
Aunque podría pensarse que la cobertura vegetal es un factor susceptible de aleatorizarse sobre las unidades experimentales, en la práctica no es así, ya sea por el tiempo que tomaría su establecimiento o por el hecho de que algunas de las coberturas no han sido establecidas, sino que han surgido por procesos naturales (con intervención antrópica o sin ella). En tal sentido, estos estudios son de tipo observacional.
Podría pensarse, entonces, en elegir las unidades con base en un muestreo aleatorio que incluya todas las áreas en las que estén presentes las coberturas de interés, dentro de la región objetivo. Esto, aunque es deseable desde el punto de vista estadístico, es poco factible por razones logísticas.
En la práctica, suelen elegirse algunas áreas con las coberturas de interés, en las que sea viable trabajar: un área por cobertura. Dentro de cada una de tales áreas, se establecen las unidades de registro, mediante las cuales se evalúa la dinámica en cada cobertura.
Ante la imposibilidad de intercalar las unidades de registro y buscando disminuir el nivel de dependencia, estas se establecen dentro de cada cobertura evitando la proximidad espacial, sin que esto constituya una garantía de independencia. Al reportar los resultados de este tipo de estudios, es necesario detallar la forma en que se han establecido las unidades y las limitaciones que ello puede acarrear.
Aunque, en términos estrictos, una situación como la descrita se corresponde con un estudio de caso, en el que —bajo la visión más ortodoxa— lo único que se está comparando son esas cuatro áreas particulares, pudiendo ser que las diferencias encontradas fueran explicables o no en razón de sus coberturas, una adecuada discusión en la que se contrasten las condiciones presentes en los sitios evaluados y en otros con las mismas coberturas podría guiar al lector acerca de la plausibilidad de generalizar los resultados.
La solución honesta en estos casos consiste en reconocer que la variabilidad interna de una cobertura particular —estimada a partir de las parcelas dentro de cada área— podría ser menor que la variabilidad existente entre diferentes expresiones de esa misma cobertura en otros lugares. En tales condiciones, el análisis tendería a sobrepotenciar el ensayo y a disminuir su validez externa.
¡Sin embargo, son analizables!
Los análisis inferenciales realizados con base en un protocolo como el descrito pueden ser válidos, sin que configuren necesariamente un caso de seudoreplicación.
Hurlbert (1984) señala que, en estudios observacionales, la seudoreplicación surge cuando la información obtenida en un espacio físico restringido se utiliza para inferir sobre una población más amplia.
En consecuencia, mientras los resultados se interpreten como correspondientes a los sitios evaluados —reconociendo explícitamente las limitaciones para su generalización— el análisis estadístico es legítimo.
Aunque, por definición, la seudoreplicación está claramente diferenciada de la verdadera replicación, en la práctica, el límite puede ser difuso. La independencia es el aspecto diferenciador. En ocasiones, un revisor con experiencia o con una visión más amplia podría cuestionar la independencia entre unidades asumidas como independientes por el investigador.
En un ensayo para comparar diferentes procesos de preparación de una bebida láctea fermentada, podría cuestionarse la independencia de las respuestas por el hecho de haber partido de una preparación común, aun cuando los procesos fermentativos de las diferentes unidades se hubieran surtido de forma independiente.
En estudios de pastoreo es necesario considerar el tipo de respuestas que se evalúan, así como las interacciones que se dan al interior del potrero, para establecer si la unidad experimental es el potrero o cada uno de los animales dentro de este.
Las evaluaciones del suelo, así como las del componente forrajero, tendrán, desde luego, al potrero como unidad experimental. Aunque algunas de tales respuestas podrían exigir muestreos dentro del potrero, la información proveniente de las muestras se integraría para generar un único valor de cada variable por potrero.
Algunas otras variables, tales como ganancia de peso, producción, consumos, emisiones de metano, composición de sangre, heces y orina, se evalúan sobre cada uno de los animales.
Aunque en principio podría considerarse que algunas de tales respuestas son independientes entre individuos, esto no siempre es así. En tales casos es necesario analizar el tipo de interacciones que se dan entre los animales que comparten potrero y la forma en que estas podrían afectar la independencia de las respuestas.
En cualquier caso, sea que se considere adecuado tomar a cada individuo como unidad experimental o que se considere más pertinente tomar el grupo de animales dentro de cada potrero como unidad experimental, es conveniente plasmar las correspondientes consideraciones en la memoria del ensayo.
En resumen…
La seudoreplicación surge de calcular la variabilidad dentro de los tratamientos, usando lecturas que —por no ser independientes— subestiman dicha variabilidad.
Solo las lecturas independientes de cada tratamiento constituyen verdaderas réplicas.
Solo las verdaderas réplicas conforman unidades experimentales.
6.1.13 Fuentes de error experimental
Teniendo en cuenta que el error experimental es la variabilidad existente entre las unidades experimentales sometidas a un mismo tratamiento y que, por definición, todas las variables exhiben una variación típica o inherente, no es extraño que todo experimento tenga asociado un error experimental.
Cualquier condición que genere variabilidad entre las unidades experimentales sometidas a un mismo tratamiento constituye una fuente de error experimental.
Todo experimento está sujeto a fuentes de variabilidad natural, que dependen del área de investigación. La variabilidad natural en la experimentación biológica proviene de tres fuentes principales: variación genética propia del material experimental, variación del sustrato o medio y variación ambiental.
La variación genética es la expresada por unidades experimentales de una misma especie (variedad, raza, cepa, clon, etc.), con características comparables (sexo, edad, estado fisiológico, etc.) y sometidas a condiciones idénticas de manejo (alimentación, fertilización, estímulos, etc.).
La variabilidad genética del material biológico condiciona la variabilidad de las respuestas registradas sobre tales unidades.
La variabilidad del sustrato o medio en el que se desarrollan los organismos también da lugar a variaciones en sus respuestas. En ensayos con microorganismos, en los que se usa algún medio de cultivo, la variabilidad aportada por los medios puede ser despreciable; asimismo, puede lograrse alta homogeneidad en ensayos en los que el organismo se desarrolla en un medio líquido.
En los ensayos que exigen suelo como sustrato, este puede hacer una alta aportación a la variabilidad, en particular, en ensayos de campo, en los que el suelo puede exhibir grandes variaciones en aspectos como la densidad, la porosidad, la textura, la estructura, la humedad, la conductividad eléctrica y la composición química.
La variabilidad ambiental afecta principalmente los ensayos de campo y, en menor medida, los ensayos de invernadero; los ensayos de laboratorio, por el nivel de control al que están sometidos, suelen verse menos expuestos a variaciones ambientales.
Los factores ambientales comprenden condiciones microclimáticas como sombras, humedad relativa, vientos y temperatura, que pueden afectar diferencialmente las unidades experimentales sometidas a un mismo tratamiento.
¡Es omnipresente!
La variabilidad natural siempre está presente, incluso en contextos no biológicos, debido a diferencias entre materiales o componentes constitutivos de las unidades experimentales.
Aunque existen técnicas para controlar la variabilidad natural, v. gr., el bloqueo (cf. sección 7.2), ni es posible ni se pretende eliminarla completamente. Esta variabilidad es el reflejo de la variación presente en la población objetivo y se usa para construir referentes para la comparación de las medias.
Por lo general, el establecimiento y desarrollo de los ensayos conllevan una serie de labores que deben realizarse de la manera más uniforme posible en todas las unidades experimentales, permitiendo que las unidades se diferencien únicamente en lo concerniente a los tratamientos.
Así, por ejemplo, en un ensayo de campo mediante el cual se quiera comparar el desempeño de diferentes clones, lo único que debería variar entre las unidades experimentales es el clon, manteniendo constantes todas las condiciones de siembra y manejo: preparación del sustrato; material vegetal de iguales condiciones fisiológicas y sanitarias; momento de la siembra; densidad de siembra; aporque; poda; riego; fertilización; aplicación de herbicidas, insecticidas y fungicidas; etc.
La desuniformidad en el manejo de las unidades experimentales puede afectar de diferente manera el ensayo, dependiendo de la forma en que se presente. Si la desuniformidad se diera entre tratamientos, es decir, manejo uniforme dentro de cada tratamiento, cambiando entre tratamientos, esta constituiría un factor de confusión, no permitiendo saber si las eventuales diferencias observadas entre tratamientos (o falta de diferencias) se deben a la naturaleza de los tratamientos o al manejo diferenciado entre tratamientos.
Si la desuniformidad se diera de manera aleatoria, afectando al azar algunas unidades de algunos tratamientos, produciría un incremento en el error experimental.
En ocasiones, por el tamaño del ensayo o por la laboriosidad de las prácticas, estas deben realizarse en un amplio lapso de tiempo, con la consiguiente posibilidad de que tengan efectos diferenciados, en función del momento de su realización. En tales casos, es conveniente diseñar experimentos que permitan manejar pequeños grupos de unidades experimentales o bloques dentro de los cuales sea posible aplicar de manera uniforme las prácticas en cuestión (cf. sección 7.2).
Durante la ejecución de los ensayos, pueden surgir situaciones imprevistas que alteren los resultados.
Hurlbert (1984) —con su particular sentido del humor— se refiere a tales situaciones como “intrusión no demoniaca”, por cuanto estas —más que responder a un plan malévolo o a una conspiración sobrenatural (intrusión demoniaca)— pueden surgir por la naturaleza imprevisible del mundo real o, en ocasiones, por la falta de experiencia o previsión del investigador.
Hurlbert (1984) agrega, sin embargo, que tales situaciones aparecen en todos los experimentos y que, por definición, es imposible prever su naturaleza, magnitud, frecuencia y efecto.
En ensayos de campo, tales imprevistos pueden estar representados por plagas, enfermedades, inundaciones o daños mecánicos del material experimental.
Puesto que, en muchas ocasiones, el efecto de tales factores se focaliza en alguna o algunas áreas de la parcela, los esquemas de aleatorización con adecuado intercalamiento constituyen la mejor estrategia para evitar que tales imprevistos, en caso de presentarse, se concentren en alguno o algunos de los tratamientos, actuando como factores de confusión.
No obstante, este tipo de situaciones —aun habiendo aplicado aleatorización con intercalamiento— suelen incrementar la variabilidad entre las unidades experimentales sometidas a un mismo tratamiento, es decir, el error experimental, con la consiguiente pérdida de potencia. El investigador deberá tomar todas las medidas necesarias para prevenir tales eventualidades.
¡Podrían generar confusión!
Hurlbert (1984) presenta un ejemplo en el que los gavilanes usan las cercas experimentales —que diferencian los tratamientos— como perchas para cazar, generando un efecto alineado con los tratamientos. En este caso, esta situación imprevista se configura como factor de confusión.
Aunque las mediciones y transcripciones erróneas usualmente producen un incremento del error experimental, se da por descontado que el investigador realiza todas las acciones necesarias para evitar que estas fallas de registro se presenten.
Entre tales acciones, cabe mencionar, entre otras, la revisión de los protocolos experimentales; la verificación del estado de los equipos e instrumentos, procediendo a su calibración cuando sea necesario, y la capacitación del personal de apoyo.
En resumen…
Las fuentes de error experimental pueden categorizarse en cuatro grupos:
Variabilidad natural
Variabilidad por manejo desuniforme de las unidades experimentales
Variabilidad por imprevistos
Variabilidad por fallas de registro
Idealmente, el error experimental debería estar conformado únicamente por la variabilidad natural de la población objetivo.
Debe evitarse toda situación que conduzca a un manejo desuniforme de las unidades experimentales, usando la estrategia de bloqueo de ser necesario (cf. sección 7.2).
Asimismo, debe controlarse en lo posible la ocurrencia de eventos imprevistos durante la ejecución del ensayo. Aunque la formulación de estrategias efectivas para dicha prevención es un aspecto que depende en gran parte de la visión y la experiencia del investigador, en muchos casos también puede estar mediado por la disponibilidad de recursos.
Por su parte, las fallas de registro deben estar totalmente conjuradas en cualquier ensayo.
6.1.14 Control del error experimental
Aunque el error experimental puede controlarse actuando directamente sobre las fuentes de variabilidad reseñadas en la sección 6.1.13, también puede controlarse mediante estrategias basadas en el diseño experimental.
En general, todo intento por reducir directamente la variabilidad natural se traduce en una pérdida de validez externa (cf. sección 6.1.4).
Lógicamente, las respuestas generadas por un grupo de unidades experimentales altamente homogéneas, desarrollándose en un sustrato homogéneo y en un entorno ambiental altamente controlado, serán menos variables que las generadas por otro grupo de unidades experimentales en el que el material experimental exhiba mayor variabilidad genética, desarrollándose en un sustrato con la variabilidad natural de campo y sujeto a las variaciones ambientales propias de dicho entorno.
Sin embargo, la forma en la que el primer grupo refleje la dinámica de la población objetivo puede ser cuestionable.
¡Que refleje la variabilidad poblacional!
Antes de elegir el material experimental y las condiciones experimentales, es necesario definir la población objetivo y el alcance que se pretende para el estudio.
Con base en ello, deberán elegirse los materiales y las condiciones que reflejen la variabilidad de tal población.
En ocasiones, los ensayos forman parte de programas de investigación en los que se estipulan evaluaciones iniciales bajo condiciones altamente controladas que representarían subpoblaciones muy particulares dentro de la población objetivo final.
Aunque tales ensayos tienen baja validez externa, los hallazgos derivados de estos permiten direccionar los ensayos posteriores, los cuales deben ir recogiendo —cada vez en mayor medida— las condiciones de variabilidad de la población objetivo final, incrementando así su validez externa.
En cuanto a las fallas de registro, se reitera que estas son absolutamente inaceptables y que el investigador debe empeñarse al máximo en evitar su ocurrencia. Esto parte, desde luego, de asegurar que todo el personal de apoyo cuente con una adecuada capacitación.
El investigador puede disminuir la probabilidad de aparición de los denominados imprevistos cuando cuenta con suficiente experiencia, visión y recursos.
Así, por ejemplo, aunque podría pensarse que la aparición de una plaga o enfermedad en un cultivo es un imprevisto o evento aleatorio, no debería serlo para quien conozca la dinámica de dicho cultivo, quien, con los recursos necesarios, podría aplicar los productos del caso para prevenir su aparición.
Finalmente, en lo que respecta a intervenciones directas, está lo relativo al establecimiento y manejo del experimento, el cual debe ser lo más uniforme posible.
Cuando el tamaño del experimento no permita un establecimiento o manejo uniforme, debe recurrirse a estrategias mediadas por el diseño experimental (cf. sección 7.2).
La principal estrategia de control mediante el diseño experimental consiste en estructurar el experimento de modo que permita extraer del error experimental la variabilidad aportada por efectos adicionales, ya sean fijos o aleatorios. En el capítulo 10, se cubre lo concerniente a los efectos fijos. Los efectos aleatorios se refieren al bloqueo y sus generalizaciones (cf. secciones 7.2 y 7.3). En cualquiera de los dos casos, tales efectos se incluyen en el modelo como factores o variables de clasificación.
El análisis de covarianza permite un control análogo, usando efectos numéricos. Así, por ejemplo, si se realizara un experimento nutricional con individuos pertenecientes a distintos grupos etarios, la edad contribuiría a incrementar el error experimental. No obstante, sería posible aislar la variabilidad debida a la edad, mediante su inclusión en el modelo.
El tamaño de la unidad experimental puede influir en la magnitud del error experimental. En general, la variabilidad y, por consiguiente, el error experimental, es mayor en unidades experimentales pequeñas que en unidades experimentales grandes. No obstante, este es un aspecto que amerita una discusión más detallada y sobre el cual se amplía en la sección 6.1.15.
Aunque podría creerse que el número de réplicas se relaciona con el control del error experimental, esto no es estrictamente cierto, si lo que se entiende por controlar el error experimental es lograr su disminución. No obstante, vale la pena destacar que, en general, un mayor número de réplicas conduce a estimaciones más precisas y comparaciones más potentes.
¿¡Y todo esto, para qué!?
En última instancia, el objetivo del control del error experimental es mejorar la capacidad del experimento para detectar diferencias reales entre los tratamientos.
Esto depende del contraste entre la variabilidad atribuible a los tratamientos y la variabilidad existente entre unidades experimentales sometidas a un mismo tratamiento.
6.1.15 Tamaño de la unidad experimental
En la sección 6.1.7 se presentan cuatro razones para usar unidades experimentales conformadas por la agregación de elementos: distribucionales, de validez externa, de previsión y de reducción de la variabilidad.
Asimismo, en la sección 6.1.10 se indica que, mientras mayor sea el número de réplicas de un experimento, mayor será su potencia.
Por tanto, en general, es deseable tener unidades experimentales grandes y también un alto número de réplicas.
No obstante, cuando el material experimental es limitado —lo que es habitual en investigación—, el tamaño de la unidad experimental y el número de réplicas entran en conflicto.
Así, por ejemplo, si se contara con 24 elementos para un experimento con tres tratamientos, con unidades experimentales de igual tamaño e igual número de réplicas (mayores que uno), existirían tres opciones para distribuir el material experimental:
usar 8 réplicas de tamaño 1
usar 4 réplicas de tamaño 2
usar 2 réplicas de tamaño 4
En este caso, el número total de elementos disponibles fija el producto entre el número de réplicas y el tamaño de la unidad experimental, de modo que aumentar uno de estos factores necesariamente implica reducir el otro.
Análogamente, si en un experimento se dispusiera de un lote de 20 000 m2, para evaluar dos tratamientos con unidades experimentales de igual tamaño e igual número de réplicas, existirían múltiples combinaciones posibles de tamaño de parcela y número de réplicas: 2 réplicas de 5 000 m2, 3 réplicas de 3 333.33 m2, 4 réplicas de 2 500 m2, etc.
Constituye un caso especial aquel en el que —por razones de validez externa— el tamaño de la unidad experimental se encuentra predefinido, como en el ejemplo que se ilustra en la sección 6.1.7 para sistemas de producción de gallinas ponedoras que suelen trabajarse con densidades de cinco gallinas por jaula. En tales casos, lo recomendable es usar unidades experimentales que satisfagan la condición poblacional.
Cuando se usan unidades experimentales agregadas por razones distribucionales o de previsión, no existe un límite superior para su tamaño. En general, mientras mayor sea el tamaño de la unidad experimental, mejor se satisfarán tales objetivos.
De igual manera, cuando se usan unidades experimentales agregadas por razones de validez externa, sin que exista un tamaño de unidad predefinido, como es el caso de los cultivos agroindustriales, también se obtendrán mejores resultados con unidades experimentales grandes. Es en tal sentido que se afirma que, en general, las unidades experimentales grandes ofrecen un mejor desempeño que las pequeñas.
Un aspecto levemente esbozado en la sección 6.1.14 es el de la variabilidad entre unidades experimentales, en función del tamaño de la unidad experimental. En general, la variabilidad es mayor entre unidades experimentales pequeñas que entre unidades experimentales grandes.
Esto se hace evidente al evaluar el promedio en unidades experimentales conformadas por un grupo de elementos. En tal caso, la varianza de dicho promedio tiende a disminuir aproximadamente en proporción a \(V(X)/n,\) siendo \(n\) el número de elementos que conforman la unidad experimental.
Los ensayos en los que se usa la parcela como unidad experimental merecen una consideración especial. Aunque podría pensarse, por lo expresado anteriormente, que no existe un límite superior para el tamaño de las parcelas y que entre más grandes sean, darán lugar a una variabilidad menor y, por tanto, a un menor error experimental, esto no es así.
Petersen (1994) indica que, si bien la variabilidad entre parcelas suele disminuir a medida que estas incrementan de tamaño, esta tiende a incrementarse nuevamente a partir de aproximadamente 500 m2. Esto se explica por cuanto las áreas incorporadas en tales parcelas contribuyen a una mayor variabilidad.
Asimismo, este autor señala una serie de factores que deben considerarse para establecer el tamaño de unidades experimentales basadas en parcelas.
Los cereales, así como otros cultivos que se siembran a altas densidades, no exigen parcelas tan grandes como otros cultivos que se siembran en surcos.
Para frutales y otros cultivos perennes, se requieren parcelas mayores
Para estudios de pastoreo, se requieren unidades experimentales aun más grandes.
En ensayos agronómicos (fertilización, podas, riegos, etc.), las parcelas son usualmente más grandes que en ensayos de mejoramiento, debido a que en los primeros se requiere más espacio para maniobrar.
El tamaño de la parcela tiende a incrementarse a medida que avanza el programa de investigación. En estudios de mejoramiento, por ejemplo, donde se inicia con gran cantidad de material experimental, la unidad experimental de las primeras fases podría ser tan pequeña como una planta; en generaciones posteriores, podrían usarse unidades experimentales constituidas por un surco de plantas, luego dos, llegando a utilizar en las etapas finales de investigación parcelas de hasta 500 o 1 000 m2.
Petersen (1994).
Otro aspecto que debe tenerse en cuenta cuando se trabaja con parcelas es el efecto de borde14. Los elementos ubicados en los bordes de la parcela podrían estar sometidos a condiciones diferentes a las de los elementos ubicados al interior de la parcela, ya sea por menor competencia (si el borde de la parcela coincidiera con una zona no cultivada) o por efecto de los tratamientos asignados a las unidades experimentales vecinas.
Con el fin de evitar que la respuesta de tales elementos —posiblemente atípicos— sesgue los resultados, suele omitirse su lectura, evaluando únicamente los elementos ubicados al interior de la parcela. Al conjunto de elementos ubicados al interior de la parcela se le denomina parcela efectiva.
El número de elementos cuya lectura se omite para proteger contra el efecto de borde depende de la naturaleza de los tratamientos. Así, por ejemplo, en experimentos en los que se aplique un tratamiento por aspersión habrá mayores posibilidades de que tal tratamiento afecte algunas unidades de las parcelas vecinas, que en experimentos en los que se evalúen variedades.
De igual manera, en ensayos de fertilización potásica se tendrá mayor efecto de borde, por la alta movilidad de este elemento en suelo húmedo, que en ensayos de fertilización con fósforo, dada la muy baja movilidad de este último, en relación con el potasio.
En los ensayos de campo basados en parcelas suele usarse al menos una fila de plantas para proteger contra el efecto de borde.
Este es un aspecto que también debe tenerse en cuenta al momento de definir el tamaño de la unidad experimental, de manera que la parcela efectiva quede con el tamaño deseado.
En resumen, son muchos los factores que deben tenerse en cuenta para la definición del tamaño de la unidad experimental: la distribución de la variable respuesta; la propensión a daños o pérdidas; lo bien que la unidad experimental logre reflejar las dinámicas de la población objetivo; la necesidad de omitir las lecturas de las unidades ubicadas en los bordes de la parcela; el uso de maquinaria; el número de elementos por unidad experimental, acorde con el estado del programa investigativo, y la variabilidad entre unidades, acorde con el tipo de cultivo.
Solución al conflicto entre el tamaño de la unidad experimental y el número de réplicas
Dada la competencia por recursos que se da entre el tamaño de la unidad experimental y el número de réplicas, el investigador debe elegir unidades experimentales que, con el menor tamaño posible, satisfagan todos los requerimientos enumerados anteriormente o los que sean específicos de su ensayo, dedicando el resto del material experimental a incrementar el número de réplicas.
Aunque para las situaciones básicas de inferencia estadística existen expresiones para el cálculo del número de réplicas15, tomando en consideración la magnitud del error experimental, el tamaño de la diferencia que se desea detectar, y la magnitud de los errores tipo I y tipo II que el investigador está dispuesto a tolerar, en ensayos complejos —es decir, los que involucran tres o más tratamientos— se tiene en cuenta el número de tratamientos y la cantidad de recursos que se pueda asignar al experimento (dinero, tiempo, material experimental, recursos humanos, etc.).
Para tal efecto suele utilizarse la fórmula de los recursos, propuesta por Mead, Gilmour y Mead (2012), la cual se detalla en la sección 7.3.1.
6.1.16 Coeficiente de variación
Lo ideal es que el error experimental de un ensayo recoja únicamente la variabilidad natural, sin verse afectado por la variabilidad adicional ocasionada por imprevistos, manejo desuniforme o fallas de registro.
Como herramienta de diagnóstico, la variabilidad de un experimento debe contrastarse con la que suele presentarse en experimentos similares dentro de la correspondiente área. El coeficiente de variación del experimento resulta adecuado para tal fin.
El coeficiente de variación de un experimento es análogo al coeficiente de variación usado en el contexto descriptivo como medida de variabilidad relativa, el cual se calcula como la razón porcentual entre la desviación estándar y la media (cf. sección 2.1.2.3).
En el contexto de los experimentos diseñados, el coeficiente de variación también es una medida de variabilidad relativa que se calcula como la razón porcentual entre la raíz cuadrada del error experimental16 y la media de la variable respuesta.
La ventaja del coeficiente de variación de un experimento es que, al igual que en el contexto descriptivo, constituye una medida adimensional que no se ve afectada por la escala de medición de la variable respuesta.
En experimentos en los que el error experimental esté constituido únicamente por la variabilidad natural, el coeficiente de variación será, en general, menor que en experimentos en los que el error experimental se infle por manejo desuniforme, por situaciones imprevistas o por fallas de registro.
Para juzgar la magnitud del coeficiente de variación de un experimento, este debe compararse con el esperado para experimentos realizados bajo condiciones similares, en los que se evalúe la misma variable respuesta, con base en el mismo diseño experimental.
Si se obtiene un coeficiente de variación muy alto con respecto a dicho referente, habrá indicios de que el control experimental no fue el más adecuado y que quizás hubo manejos desuniformes, imprevistos o fallas de registro que produjeron un incremento del error experimental.
Usando como insumo los coeficientes de variación de ensayos realizados en áreas específicas, algunos autores han propuesto escalas o límites máximos permisibles para calificar el nivel de control de la variabilidad en los experimentos de tales áreas.
Así, por ejemplo, Faria Filho et al. (2010) proponen las categorías bajo, intermedio, alto y muy alto para los coeficientes de variación de nueve variables de respuesta productiva y de calidad, en estudios relacionados con la producción de huevos para consumo, tomando como referente artículos publicados durante un periodo de diez años en algunas de las principales revistas brasileñas.
De manera similar, usando la información proveniente de ensayos de campo realizados en 25 estaciones experimentales, en un estado del occidente de la India, durante un periodo de cuatro años, con base en esquemas de bloques completos al azar, Patel, Patel y Shiyani (2001) proponen un límite máximo permisible para el coeficiente de variación del rendimiento de leguminosas.
No obstante lo anterior, es importante resaltar que no existe un referente global de variabilidad esperada o tolerable que pueda aplicarse a todos los ensayos.
Las recomendaciones que surgen de estudios como los reseñados anteriormente deben tomarse con cautela, puesto que corresponden a respuestas específicas, generadas a partir de ensayos realizados en localizaciones y periodos particulares, usando diseños experimentales específicos.
¿¡Y, entonces!?
Más que buscar referentes en libros de texto, cada investigador deberá establecerlos acorde con su área de investigación, teniendo en cuenta que los referentes que en algún momento pudieron ser adecuados podrían no serlo en escenarios de nuevo material biológico, cambio climático u otras condiciones cambiantes.
6.1.17 Etapas de los estudios experimentales
A modo de resumen de la sección de conceptos asociados con el diseño de experimentos, se presentan las tres etapas generales que deben surtirse en todo experimento para realizar inferencias válidas sobre los parámetros de las poblaciones objetivo:
1. Planeación
2. Ejecución
3. Procesamiento y análisis de resultados
En el prefacio de este texto se menciona que el término investigador es de carácter genérico y se resalta la importancia de que los equipos de investigación cuenten con la participación de un asesor estadístico.
En este punto vuelve a traerse a colación este aspecto, por la imperiosa necesidad de que el estadístico participe desde la primera etapa de la investigación, dado que es en esta en la que se definen los aspectos fundamentales que incrementan las posibilidades de obtener inferencias válidas a partir del experimento.
6.1.17.1 Planeación del experimento
La planeación de un experimento comprende decisiones de naturaleza conceptual, estadística y operativa, las cuales pueden organizarse así:
Definición de Objetivos. Precediendo cualquier otra consideración en la planeación, debe estar la definición clara y precisa de los objetivos de la investigación.
En ocasiones, un solo experimento permite satisfacer simultáneamente todos los objetivos, mientras que, en otros casos, se requieren varios experimentos.
Cuando una investigación exige la realización de varios experimentos, debe especificarse cuál o cuáles de los objetivos de la investigación se satisfarán a través de cada uno de ellos.
Es importante señalar que, aunque los objetivos se redactan en prosa, es decir, usando el lenguaje técnico habitual de la correspondiente disciplina, sin incluir simbología estadística, la posterior aplicación de procesos inferenciales para la satisfacción de los objetivos implica la modelación de las poblaciones de campo mediante poblaciones teóricas (cf. sección 3.9).
Esto da lugar a que los objetivos de caracterización se satisfagan mediante técnicas de estimación (cf. sección 3.9.1), mientras que los objetivos que conllevan hipótesis de investigación se satisfagan mediante pruebas de hipótesis estadísticas (cf. sección 3.9.2).
Definición de variables respuesta. Aunque los ejemplos que suelen emplearse con fines ilustrativos en los textos de análisis univariante —incluyendo el presente— consideran una única variable respuesta, en la mayoría de ensayos se evalúan múltiples respuestas.
Durante la planeación de un experimento, es necesario analizar cuáles son exactamente las respuestas que permiten valorar el efecto de los tratamientos sobre el material experimental, acorde con los objetivos planteados, asegurándose de que estas serán registradas adecuadamente durante el desarrollo del experimento.
Puesto que el registro de algunas respuestas puede ser especialmente exigente en cuanto a recursos (tiempo o dinero), la evaluación innecesaria de variables puede ser tan perjudicial para un ensayo como la falta de evaluación.
Conceptualización de la población objetivo. A pesar de que en los experimentos diseñados —a diferencia del muestreo clásico— no se cuente con un marco de muestreo (cf. sección 6.1.4) o que incluso pueda partirse de una población inexistente, es posible y necesario conceptualizar la población objetivo.
Esta es la población sobre la que se pretende inferir, por lo que su definición constituye una guía para la elección de las condiciones experimentales, del material experimental y de los tratamientos, de manera que el experimento goce de adecuada validez externa.
Definición de las condiciones experimentales. Los ensayos deben diseñarse acorde con la variabilidad de las condiciones presentes en la población objetivo. De no ser así, la validez externa del ensayo se vería limitada.
Este aspecto es particularmente relevante cuando se pretende inferir sobre poblaciones de campo que están sometidas a condiciones cambiantes entre localidades, temporadas o estaciones. En tales casos, deben considerarse subensayos en diferentes localidades o temporadas que propicien la replicabilidad (cf. definición 6.12).
Selección del material experimental. El material experimental también debe recoger la variabilidad de la población sobre la cual se desea inferir. Un material demasiado homogéneo disminuiría la validez externa del experimento (cf. sección 6.1.14).
Definición de tratamientos. Para la definición del número y la naturaleza de los tratamientos deben tenerse presentes los objetivos del estudio y los recursos disponibles.
Asimismo, en esta etapa, deberá tomarse en consideración si es del caso incluir tratamientos control (cf. sección 6.1.6.1).
De igual manera, es necesario definir la conveniencia de usar una estructura factorial para aislar efectos (cf. capítulo 10).
Determinación del esquema de aleatorización. Acorde con las características del material experimental y con las condiciones experimentales, se elige el esquema de aleatorización que permita controlar de la mejor manera posible los potenciales factores de confusión (cf. capítulo 7).
Definición del tamaño de la unidad experimental. Para la definición del tamaño de la unidad experimental, debe tenerse en cuenta la distribución de las variables respuesta, la propensión a daños o pérdidas, la capacidad de la unidad experimental para reflejar las dinámicas de la población objetivo, la necesidad de omitir las lecturas de las unidades ubicadas en los bordes de la unidad, el uso de maquinaria, el número de tratamientos y la variabilidad entre unidades, entre otros aspectos.
No obstante, teniendo en cuenta la competencia por recursos que se da entre el tamaño de la unidad experimental y el número de réplicas, el investigador debe elegir unidades experimentales que, con el menor tamaño posible, satisfagan todos los requerimientos específicos de su ensayo, dedicando el resto del material experimental a incrementar el número de réplicas (cf. sección 6.1.15).
Número de réplicas. Uno de los aspectos centrales durante la planeación de un experimento es el relativo a la definición del número de réplicas. Para tal efecto, se sugiere tomar como guía la fórmula de los recursos, propuesta por Mead et al. (2012), la cual se detalla en la sección 7.3.1.
Evaluación presupuestal. Deberán considerarse y cuantificarse todos los recursos necesarios para la conducción del experimento: material experimental, insumos, equipos, jornales, transporte y pruebas de laboratorio, entre otros.
Obtención de permisos y avales necesarios. Estos dependerán del tipo de experimento y de la legislación vigente.
Capacitación de personal. El personal que participa en la ejecución del ensayo o en el registro de información debe recibir un adecuado entrenamiento para tales labores.
Asimismo, es importante que más allá de la capacitación en los aspectos técnicos, todos los colaboradores entiendan la necesidad de respetar la forma aparentemente desordenada (aleatorizada) en que se asignan los tratamientos sobre las unidades experimentales y en que se realizan las labores complementarias.
Elaboración de formatos para recolección de la información. Aunque parezca que este aspecto no requiere planificación, pudiendo dejarse para etapas posteriores, su definición temprana evitará tediosos reprocesos. Para su adecuada proyección, deben tenerse en mente los análisis que se realizarán.
Construcción del cronograma de actividades. La esquematización temporal de las diferentes etapas y actividades del proceso experimental debe entenderse —más que como un requisito que suele aparecer en los formatos de formulación de proyectos— como una guía para dimensionar el estudio.
Asimismo, durante la etapa de ejecución, el cronograma permite contrastar los avances contra lo planeado, y —si es del caso— replantear aspectos del proceso.
6.1.17.2 Ejecución del experimento
Una vez definidos los tratamientos y las unidades experimentales, los tratamientos se asignan a las unidades experimentales, acorde con las restricciones particulares del esquema de aleatorización elegido.
Todas las labores complementarias a los tratamientos se realizan lo más uniformemente posible, con la salvedad que admiten los esquemas de bloques y sus generalizaciones.
De ser necesario, se reforzaría la capacitación al personal.
Para disminuir la probabilidad de fallas en el registro de la información, debe ponerse el máximo esmero en la toma de datos.
La información se consigna en las correspodientes bases de datos.
6.1.17.3 Procesamiento y análisis de resultados
Se contrastan las hipótesis planteadas con un nivel de significancia dado.
Se obtienen intervalos de confianza.
Los resultados se presentan en términos del correspondiente experimento, integrando todo su contexto.
Como paso final del análisis, es importante contrastar con los resultados obtenidos en otros ensayos, así como postular posibles explicaciones.
6.1.18 Componentes de los estudios experimentales
Todo estudio experimental involucra tres aspectos que deben considerarse tanto al momento de su planeación como al realizar una descripción completa del mismo:
La estructura de los tratamientos
El esquema de aleatorización
La secuencialidad en el registro de la información
La figura 6.5 ilustra la relación entre estos componentes.

Mediante la estructura de los tratamientos se indica si estos constan de un único factor (experimento unifactorial o de una vía) o de varios factores (estructura factorial o multivía).
Los experimentos unifactoriales se presentan en capítulo 7, mientras que los factoriales se detallan en el capítulo 10.
Ha sido costumbre que el esquema de aleatorización, es decir, la manera en que se asignan los tratamientos a las unidades experimentales, domine la forma en que se describen los experimentos diseñados; de hecho las denominaciones clásicas de los diseños experimentales a menudo hacen referencia únicamente a este componente (diseño completamente al azar, diseño en bloques completos al azar, etc.).
Algunos de los esquemas de aleatorización básicos se presentan en el capítulo 7, mientras que en el capítulo 10, se presentan esquemas de aleatorización combinados.
Por su parte, la secuencialidad se refiere a si las lecturas se registran en un único momento (estudio transversal) o si se han realizado medidas repetidas a lo largo del tiempo sobre las unidades experimentales (estudio longitudinal).
Todos los estudios que se presentan en este texto, hasta el capítulo 10 son de tipo transversal. En el ?sec-mixed-models se consideran los estudios longitudinales.
Por lo general, se asume que los estudios son transversales, sin hacer mención a ello, resaltando el aspecto de la secuencialidad únicamente cuando se tienen estudios longitudinales.
En general, estos tres aspectos de los diseños experimentales deben considerarse de manera independiente, acorde con los objetivos y las condiciones experimentales, y ninguno de ellos tiene por qué restringir la elección de los otros17.
Antes de cerrar la sección de conceptos asociados con el diseño de experimentos, es importante señalar que, a pesar de las claras ventajas que conllevan los estudios experimentales y de ser viables en muchas áreas de investigación básica y aplicada, no todas las investigaciones se realizan a través de este tipo de estudios.
En muchos casos, particularmente cuando las potenciales unidades experimentales son seres humanos, se presentan limitaciones éticas que no permiten aplicar los tratamientos. En otros casos, los efectos de interés son inherentes a las unidades de evaluación o han surgido a través de procesos naturales que no serían fácilmente reproducibles de manera artificial. En algunos casos más, los objetivos de la investigación no se suplirían mediante un experimento.
Cualquiera que sea la situación por la que se decida no usar un estudio experimental, deberán considerarse otras posibles herramientas estadísticas. Desde luego, sería necesario adaptar el lenguaje al momento de realizar las correspondientes descripciones, teniendo en cuenta que la mayoría de conceptos presentados en esta sección son exclusivos de los experimentos diseñados.
6.2 Análisis de varianza
El análisis de varianza es un método estadístico para comparar las medias de varias poblaciones normales, usando información muestral obtenida de cada una de ellas. El conjunto de réplicas de cada uno de los tratamientos constituye una muestra de la correspondiente población que estos representan.
A pesar de tratarse de un procedimiento de comparación de medias, el análisis de varianza se basa en la partición de la variabilidad total en diferentes fuentes; de ahí su nombre. Tanto en lengua inglesa como española, suele usarse el acrónimo ANOVA (Analysis of Variance) para referirse a este método. Aunque con menor frecuencia, en español también se emplean los acrónimos ANAVA, ANDEVA y AVAR.
Esta técnica, desarrollada por R. A. Fisher entre 1918 y 1925, constituye uno de sus más valiosos legados.
Para no restarle continuidad a la exposición del método, en la presente sección se omite la discusión de los supuestos en los que se basa el ANOVA, postergando su evaluación hasta la sección 6.3.
Las poblaciones teóricas usadas para modelar las poblaciones de campo18 se distribuyen normalmente con igual varianza, pudiendo diferir en su parámetro de localización, la media.
Puesto que, en la distribución normal, la media y la varianza son parámetros independientes, la suposición de varianzas comunes para un conjunto de poblaciones no restringe la eventual existencia de diferentes medias, tal y como se ilustra en la figura 6.6.

Si se obtienen sendas muestras aleatorias19 de tales poblaciones, estas también se distribuirán normalmente, con media \(\mu_i\) y varianza común \(\sigma^2\), lo cual se expresa así :
\[
Y_{ij}\thicksim N(\mu_i,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\tag{6.2}\]
La \(j\)-ésima variable aleatoria de la \(i\)-ésima muestra puede expresarse mediante un modelo estadístico, como la media de la población a la que pertenece, más una desviación aleatoria.
Esta expresión —conocida como modelo de medias— tiene la siguiente forma:
\[
Y_{ij}=\mu_i+\varepsilon_{ij},\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\tag{6.3}\]
Mediante el ANOVA se busca realizar una comparación simultánea de las medias de \(k\) poblaciones, lo cual puede expresarse mediante el siguiente juego de hipótesis:
\[
\begin{align}
H_0&:\mu_1=\mu_2=\dotsb=\mu_k=\mu\\[0.7em]
H_a&: \mu_i\ne\mu_{i'}, \text{ para al menos un par }i\ne i',\text{ con } \ i=1, 2,\dotsc, k;\quad i'=1, 2,\dotsc, k
\end{align}
\tag{6.4}\]
Nótese que si todas las medias son iguales entre sí, serán iguales a una media global, \(\mu\), que, por ser común a todas las poblaciones, no se identifica con ningún subíndice.
Por otra parte, para rechazar la hipótesis nula, no es necesario que todas las medias difieran entre sí; basta con que haya un par de medias diferentes o, en otras palabras, con que al menos una de las medias difiera de la media global, \(\mu\).
Luego, el juego de hipótesis también puede expresarse así:
\[
\begin{align}
H_0&:\mu_1=\mu_2=\dotsb=\mu_k=\mu\\[0.7em]
H_a&: \mu_i\ne\mu, \text{ para al menos un }i=1, 2,\dotsc, k
\end{align}
\tag{6.5}\]
La hipótesis alternativa presentada en la expresión 6.5 plantea que al menos una media \(\mu_i\) se desvía de la media global, \(\mu.\)
A esta desviación se le denomina efecto del \(i\)-ésimo tratamiento y se denota \(\tau_i.\)
\[
\tau_i:=\mu_i-\mu, \text{ siendo } \tau_i \text{ el efecto del } i\text{-ésimo tratamiento}.
\]
Usando la definición de \(\tau_i,\) el juego de hipótesis expresado mediante la expresión 6.5 puede plantearse equivalentemente como:
\[
\begin{align}
H_0&:\tau_i=0\ \forall\ i=1, 2,\dotsc, k\\[0.7em]
H_a&:\tau_i\ne0\ \text{ para al menos un }i=1, 2,\dotsc, k
\end{align}
\tag{6.6}\]
De igual manera, esta notación permite reescribir la expresión 6.3, como un modelo de efectos, así:
\[
Y_{ij}=\mu+\tau_i+\varepsilon_{ij},\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r,
\tag{6.7}\]
donde:
\(Y_{ij}\): Respuesta de la \(j\)-ésima réplica del \(i\)-ésimo tratamiento.
\(\mu\): Media general.
\(\tau_i\): Efecto del \(i\)-ésimo tratamiento \((\mu_i-\mu).\)
\(\varepsilon_{ij}\): Desviación aleatoria de la \(j\)-ésima réplica del \(i\)-ésimo tratamiento respecto a la media, \(\mu_i\), del \(i\)-ésimo tratamiento.
En el modelo 6.7, tanto \(\mu\) como \(\tau_i\) son fijos, siendo los errores, \(\varepsilon_{ij}\), las únicas variables aleatorias del componente derecho de la ecuación.
¿¡Fijos!?
En el modelo 6.7, \(\mu\) no es una variable aleatoria, sino un parámetro.
Por su parte, \(\tau_i=\mu_i-\mu\) es la diferencia entre dos parámetros, por lo que también es fijo.
En el contexto de los modelos, a los términos que representan un cambio en los parámetros se les denomina efectos.
\(\tau_i\) es, por tanto, un efecto fijo.
Teniendo en cuenta que los errores, \(\varepsilon_{ij}\) son las únicas variables aleatorias del componente derecho del modelo, las propiedades distribucionales de las variables aleatorias \(Y_{ij}\) se trasladan a los errores, \(\varepsilon_{ij}.\)
Para su análisis, resulta conveniente despejar los errores, del modelo 6.7:
\[
\varepsilon_{ij}=Y_{ij}-\mu_i
\]
Puesto que cada \(\varepsilon_{ij}\) se obtiene mediante una transformación lineal de la variable aleatoria normal \(Y_{ij},\) su distribución también es normal.
La esperanza se calcula así:
\[
E(\varepsilon_{ij})=E(Y_{ij}-\mu_i)=E(Y_{ij})-E(\mu_i)=\mu_i-\mu_i=0
\] De manera similar, la varianza se calcula así:
\[
V(\varepsilon_{ij})=V(Y_{ij}-\mu_i)=V(Y_{ij})\:(\text{dado que } \mu_i \text{ es constante})=\sigma^2
\]
Luego, las propiedades distribucionales derivadas para los errores, \(\varepsilon_{ij},\) permiten expresar los supuestos del modelo 6.7 en términos de estos, así:
\[
\varepsilon_{ij}\text{ iid } N(0,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\tag{6.8}\]
Al modelo representado por la expresión 6.7, y cuyos supuestos se resumen en la expresión 6.8, se le denomina ANOVA de una vía (one-way ANOVA).
Nota 6.2: ¡ANOVA de una vía!
El modelo de ANOVA de una vía es:
\[
Y_{ij}=\mu+\tau_i+\varepsilon_{ij},\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r,
\] \[
\text{con }\varepsilon_{ij}\text{ iid } N(0,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\]
Se denomina de una vía, porque los tratamientos corresponden a niveles de un solo factor.
En el modelo de ANOVA de una vía, \(\tau_i\) representa el efecto del \(i\)-ésimo nivel del factor. Este modelo asume que cualquier variación que no sea explicada por los tratamientos constituye variación aleatoria dentro de los tratamientos o error experimental.
6.2.1 Notación
La tabla 6.3 presenta la notación básica usada en el contexto del ANOVA. Esta notación irá adaptándose según los requerimientos de modelos más complejos.
En la notación básica de la tabla 6.3, \(Y\) representa la variable aleatoria; sus subíndices indican el grupo al cual pertenece. El subíndice \(i\) —que va desde 1 hasta \(k\)— indica la pertenencia a un tratamiento particular, mientras que el subíndice \(j\) —que va desde 1 hasta \(r\)— identifica la réplica.
Cuando se suma sobre algún subíndice, este se remplaza por un punto. Cuando se toma el promedio sobre un subíndice, además de remplazar el subíndice por un punto, el símbolo principal se corona con una barra. Si se suma o se promedia sobre varios índices, se usan varios puntos y/o varias barras.
| Réplicas | ||||||||
|---|---|---|---|---|---|---|---|---|
| Tratamientos | \(1\) | \(2\) | \(\cdots\) | \(j\) | \(\cdots\) | \(r\) | Total tratamientos | Promedio tratamientos |
| \(1\) | \(Y_{11}\) | \(Y_{12}\) | \(\cdots\) | \(Y_{1j}\) | \(\cdots\) | \(Y_{1r}\) | \(Y_{1\bullet}\) | \(\overline{Y}_{1\bullet}\) |
| \(2\) | \(Y_{21}\) | \(Y_{22}\) | \(\cdots\) | \(Y_{2j}\) | \(\cdots\) | \(Y_{2r}\) | \(Y_{2\bullet}\) | \(\overline{Y}_{2\bullet}\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | ⋱ | \(\vdots\) | ⋰ | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(i\) | \(Y_{i1}\) | \(Y_{i2}\) | \(\cdots\) | \(Y_{ij}\) | \(\cdots\) | \(Y_{ir}\) | \(Y_{i\bullet}\) | \(\overline{Y}_{i\bullet}\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | ⋰ | \(\vdots\) | ⋱ | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(k\) | \(Y_{k1}\) | \(Y_{k2}\) | \(\cdots\) | \(Y_{kj}\) | \(\cdots\) | \(Y_{kr}\) | \(Y_{k\bullet}\) | \(\overline{Y}_{k\bullet}\) |
| Total réplicas | \(Y_{\bullet1}\) | \(Y_{\bullet2}\) | \(\cdots\) | \(Y_{\bullet j}\) | \(\cdots\) | \(Y_{\bullet r}\) | \(Y_{\bullet \bullet}\) | |
| Promedio réplicas | \(\overline{Y}_{\bullet1}\) | \(\overline{Y}_{\bullet2}\) | \(\cdots\) | \(\overline{Y}_{\bullet j}\) | \(\cdots\) | \(\overline{Y}_{\bullet r}\) | \(\overline{Y}_{\bullet\bullet}\equiv\overline{\overline{Y}}\) | |
\(Y_{ij}:\) \(j\)-ésima réplica del \(i\)-ésimo tratamiento, \(i=1, 2,\dotsc, k;\,\,j=1, 2,\dotsc, r\)
\(Y_{i\bullet}=\sum\limits_{j=1}^r{Y_{ij}}:\) Total del \(i\)-ésimo tratamiento, \(i=1, 2,\dotsc, k\)
\(\overline{Y}_{i\bullet}=\frac{\sum\limits_{j=1}^r{Y_{ij}}}{r}:\) Promedio del \(i\)-ésimo tratamiento, \(i=1, 2,\dotsc, k\)
\(Y_{\bullet j}=\sum\limits_{i=1}^k{Y_{ij}}:\) Total de la \(j\)-ésima réplica, \(j=1, 2,\dotsc, r\)
\(\overline{Y}_{\bullet j}=\frac{\sum\limits_{i=1}^k{Y_{ij}}}{k}:\) Promedio de la \(j\)-ésima réplica, \(j=1, 2,\dotsc, r\)
\(Y_{\bullet\bullet}=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}}:\) Gran total
\(\overline{Y}_{\bullet\bullet}\equiv \overline{\overline{Y}}=\frac{\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}}}{rk}=\frac{Y_{\bullet\bullet}}{n}:\) Media general
En el presente contexto, \(n\) representa el número total de observaciones. En ensayos en los que cada tratamiento tiene igual número de réplicas, \(n = rk.\) En un escenario más general, con diferente número de réplicas, \(n=\sum_{i=1}^k{r_i}.\)
6.2.2 Partición de la variabilidad
Como se indicó al inicio de la sección 6.2, el análisis de varianza se basa en la partición de la variabilidad en diferentes fuentes. Para el modelo del ANOVA de una vía (cf. nota 6.2) —que es el más simple— la variabilidad se descompone solo en dos fuentes: la variabilidad debida a los tratamientos y la variabilidad aleatoria o error experimental.
La figura 6.7 ilustra esta partición de la variabilidad.

La línea vertical corresponde a la media general de la variable respuesta. Se ilustran \(k\) tratamientos20. Cada réplica se representa mediante un círculo y la media de cada tratamiento, mediante un triángulo.
El componente de la variabilidad se representa mediante líneas curvas, que —además de evitar la superposición— constituyen un mejor reflejo de las distancias cuadráticas que componen la variabilidad.
Se usan líneas discontinuas negras para denotar las distancias cuadráticas entre cada unidad experimental y la media general.
Las líneas continuas verdes representan las distancias cuadráticas entre la media de cada tratamiento y la media general.
Finalmente, las líneas continuas rojas representan las distancias cuadráticas entre cada unidad experimental y la media de su tratamiento.
6.2.3 Sumas de cuadrados
A las sumas de las distancias cuadráticas representadas en la figura 6.7 se les denomina sumas de cuadrados.
En particular, a la suma de los cuadrados de las desviaciones entre cada respuesta y la media general se le denomina suma de cuadrados total \((\text{SCT}).\)
A la suma de cuadrados de las desviaciones de las medias de los tratamientos respecto a la media general se le denomina suma de cuadrados de tratamientos \((\text{SCttos}).\)
A la suma de cuadrados de las desviaciones entre cada unidad experimental y la media de su correspondiente tratamiento se le denomina suma de cuadrados del error \((\text{SCE}).\)
A continuación, se presentan las correspondientes formas conceptuales:
\[
\begin{align}
\text{SCT}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(Y_{ij}-\overline{Y}_{\bullet\bullet}\right)^2}\\[1.4em]
\text{SCttos}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(\overline{Y}_{i\bullet}-\overline{Y}_{\bullet\bullet}\right)^2}\\[1.4em]
\text{SCE}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(Y_{ij}-\overline{Y}_{i\bullet}\right)^2}
\end{align}
\]
Resulta evidente la similitud entre cada una de las expresiones anteriores y la forma conceptual para el cálculo de la varianza (cf. sección 2.1.2.1). Y es que, efectivamente, cada una de tales sumas de cuadrados, al dividirse por el denominador adecuado, estima la varianza de un grupo dado, respecto a un centro particular.
Así —obviando lo concerniente a la nomenclatura—, la \(\text{SCT}\) es igual al numerador de la varianza total, es decir, la que se obtendría con la expresión presentada en la sección 2.1.2.1.
La \(\text{SCE}\) equivale al numerador de la expresión 6.1, es decir que recoge la variabilidad existente entre unidades experimentales sometidas a un mismo tratamiento, esto es, el error experimental.
Por su parte, la \(\text{SCttos}\) recoge la variabilidad de los diferentes grupos de tratamientos con respecto a la media general.
En términos de las sumas de cuadrados, la partición de la variabilidad total en diferentes fuentes se expresa así:
\[
\text{SCT} = \text{SCttos} + \text{SCE}
\tag{6.9}\]
Para demostrar la validez de esta partición, resulta conveniente trabajar con las formas operacionales de las sumas de cuadrados, que se desarrollan a partir de sus correspondientes formas conceptuales:
\[
\begin{align}
\text{SCT}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(Y_{ij}-\overline{Y}_{\bullet\bullet}\right)^2}\\[1.4em]
&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(Y_{ij}^2-2Y_{ij}\overline{Y}_{\bullet\bullet}+\overline{Y}_{\bullet\bullet}^2\right)}\\[1.4em]
&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-2\overline{Y}_{\bullet\bullet}\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}}+n\left(\frac{\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}}}{n}\right)^2\\[1.4em]
&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-2\left(\frac{\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}}}{n}\right)\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}}+\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-2\frac{Y_{\bullet\bullet}^2}{n}+\frac{Y_{\bullet\bullet}^2}{n}
\end{align}
\]
Por lo tanto,
\[ \text{SCT}=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}\quad\quad\quad\quad\quad\quad\quad\:\;\, \tag{6.10}\]
\[ \begin{align} \text{SCttos}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(\overline{Y}_{i\bullet}-\overline{Y}_{\bullet\bullet}\right)^2}\\[1.4em] &=r\sum\limits_{i=1}^k{\left(\overline{Y}_{i\bullet}-\overline{Y}_{\bullet\bullet}\right)^2}\\[1.4em] &=r\sum\limits_{i=1}^k{\left(\overline{Y}_{i\bullet}^2-2\overline{Y}_{i\bullet}\overline{Y}_{\bullet\bullet}+\overline{Y}_{\bullet\bullet}^2\right)}\\[1.4em] &=r\sum\limits_{i=1}^k{\left(\left(\frac{Y_{i\bullet}}{r}\right)^2-2\frac{Y_{i\bullet}}{r}\frac{Y_{\bullet\bullet}}{rk}+\left(\frac{Y_{\bullet\bullet}}{rk}\right)^2\right)}\\[1.4em] &=r\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r^2}-2r\frac{Y_{\bullet\bullet}}{rk}\frac{\sum\limits_{i=1}^k{Y_{i\bullet}}}{r}+rk\frac{Y_{\bullet\bullet}^2}{(rk)^2}\\[1.4em] &=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{2}{n}Y_{\bullet\bullet}^2+\frac{1}{n}Y_{\bullet\bullet}^2\\[1.4em] \end{align} \]
Luego,
\[ \text{SCttos}=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\:\: \tag{6.11}\]
\[ \begin{align} \text{SCE}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(Y_{ij}-\overline{Y}_{i\bullet}\right)^2}\\[1.4em] &=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\left(Y_{ij}^2-2Y_{ij}\overline{Y}_{i\bullet}+\overline{Y}_{i\bullet}^2\right)}\\[1.4em] &=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2-2\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}\overline{Y}_{i\bullet}}+\sum\limits_{i=1}^k\sum\limits_{j=1}^r{\overline{Y}_{i\bullet}^2}}\\[1.4em] &=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2-2\sum\limits_{i=1}^kY_{i\bullet}\frac{Y_{i\bullet}}{r}+r\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r^2}}\\[1.4em] &=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2-\frac{2}{r}\sum\limits_{i=1}^kY_{i\bullet}^2+\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}}\\[1.4em] \end{align} \]
Por consiguiente,
\[ \text{SCE}=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2-\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}}\quad\quad\quad\quad\quad\quad\quad\:\:\; \tag{6.12}\]
Partiendo de las expresiones 6.10, 6.11 y 6.12, se verifica que la ecuación \(\text{SCT}=\text{SCttos}+\text{SCE}\) constituye una identidad, con lo cual se completa la demostración referente a la partición de la variabilidad postulada en la expresión 6.9:
\[
\begin{align}
\text{SCT}&=\text{SCttos}+\text{SCE}\\[1.4em]
\Rightarrow\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}+\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2-\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}}\\[1.4em]
\Rightarrow\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}
\end{align}
\]
Aunque las fórmulas operacionales anteriores permiten calcular todas las sumas de cuadrados (total, tratamientos y error), lo usual —al realizar procedimientos manuales— es emplear únicamente las correspondientes a la suma de cuadrados total (expresión 6.10) y a la suma de cuadrados de los tratamientos (expresión 6.11), obteniendo por diferencia la suma de cuadrados del error.
Nota 6.3: Fórmulas operacionales para el cálculo de las sumas de cuadrados
Al realizar procedimientos manuales, se utilizan las siguientes fórmulas operacionales para las sumas de cuadrados del modelo del ANOVA de una vía:
\[
\begin{align}
\text{SCT}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
\text{SCttos}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
\text{SCE}&=\text{SCT}-\text{SCttos}
\end{align}
\]
Desde luego, las formas operacionales de las sumas de cuadrados también se asemejan al numerador de la forma operacional de la varianza (cf. expresión 2.2).
El último término de las fórmulas operacionales de \(\text{SCT}\) y \(\text{SCttos}\) —denominado término de corrección— aparece recurrentemente en las formas operacionales de las sumas de cuadrados, por lo que su obtención inicial facilita los cálculos manuales.
6.2.4 Grados de libertad en el ANOVA
Como se indicó en la sección 6.2.3, las sumas de cuadrados son los numeradores de las varianzas de diferentes grupos con respecto a unos centros determinados.
Las varianzas en cuestión se obtienen dividiendo las sumas de cuadrados entre denominadores apropiados. A tales denominadores se les conoce como grados de libertad.
Las sumas de cuadrados son variables aleatorias análogas a las que aparecen en el numerador de la expresión 4.5. Los grados de libertad son los de la correspondiente distribución ji cuadrado.
Las sumas de cuadrados empleadas en el ANOVA tienen asociadas las siguientes distribuciones:
\[
\begin{align}
\frac{\text{SCT}}{\sigma^2}&\thicksim \chi^2_{(n-1)}\\[1.4em]
\frac{\text{SCttos}}{\sigma^2}&\overset{H_0} \thicksim \chi^2_{(k-1)}\\[1.4em]
\frac{\text{SCE}}{\sigma^2} &\thicksim \chi^2_{(n-k)}\\[1.4em]
\end{align}
\tag{6.13}\]
En la nota 4.2 se muestra que la distribución de referencia de la variable aleatoria \(\frac{(n-1)S^2}{\sigma^2}\) —que es equivalente a \(\frac{\text{SCT}}{\sigma^2}\)— tiene \(n-1\) grados de libertad.
Esto es debido a que, los componentes de las sumas de cuadrados (distancias cuadráticas a la media21) no son independientes, lo que implica que debe restarse un grado de libertad en cada caso al número de distancias evaluadas.
Así, el estimador de la varianza total, el cual está basado en \(n\) distancias cuadráticas, tiene \(n−1\) grados de libertad.
La variabilidad entre tratamientos, basada en \(k\) distancias cuadráticas, se estima con base en \(k−1\) grados de libertad.
La variabilidad debida al error experimental se estima dentro de cada uno de los \(k\) grupos, con \(r−1\) grados de libertad, dando lugar, por lo tanto, a un estimador de la variabilidad dentro de tratamientos con \(k(r−1)=n−k\) grados de libertad.
Al igual que las sumas de cuadrados, los grados de libertad son aditivos, satisfaciéndose la siguiente relación:
\[
\text{glT}=\text{glttos}+\text{gle}
\]
En consecuencia, al realizar procedimientos manuales, los grados de libertad del error suelen calcularse por diferencia, de manera análoga al cálculo de la suma de cuadrados.
La nota 6.3 condensa las expresiones operativas empleadas para el cálculo de los grados de libertad en el modelo del ANOVA de una vía con igual número de réplicas por tratamiento.
Nota 6.4: Grados de libertad
En el modelo de ANOVA de una vía con igual número de réplicas por tratamiento, los grados de libertad se obtienen así:
\[
\text{glT}=n-1\] \[
\text{glttos}=k-1\] \[
\text{gle}=\text{glT}-\text{glttos}
\]
6.2.5 Cuadrados medios
Son los estimadores puntuales de la variabilidad:
Cuadrado medio total (\(\text{CMT}\)): variabilidad total.
Cuadrado medio de tratamientos (\(\text{CMttos}\)): variabilidad entre tratamientos.
Cuadrado medio del error (\(\text{CME}\)): variabilidad dentro de tratamientos.
Se calculan como las razones entre las sumas de cuadrados y sus correspondientes grados de libertad.
No obstante, dado que el \(\text{CMT}\) no tiene ninguna utilidad práctica para contrastar el juego de hipótesis del ANOVA, únicamente se obtienen el \(\text{CMttos}\) y el \(\text{CME}:\)
\[
\text{CMttos}=\frac{\text{SCttos}}{k-1}
\tag{6.14}\]
\[
\text{CME}=\frac{\text{SCE}}{n-k}
\tag{6.15}\]
¡No los sume!
Los cuadrados medios no son aditivos, por lo que el \(\text{CME}\) no puede obtenerse como la diferencia entre el \(\text{CMT}\) y el \(\text{CMttos}\).
6.2.6 Prueba de hipótesis en el ANOVA
El ANOVA permite comparar las medias de \(k\) poblaciones, contrastando el juego de hipótesis planteado en la expresión 6.4. La figura 6.7 ilustra un escenario de hipótesis alternativa, es decir, un escenario en el que al menos dos medias poblacionales difieren entre sí y las medias muestrales lo reflejan.
Si la hipótesis nula fuera cierta, es decir, si las medias de todos los tratamientos fueran iguales entre sí, se esperaría que todas las medias muestrales se concentraran alrededor de la media general, de manera similar a lo representado en la figura 6.8.

Las figuras 6.7 y 6.8 facilitan la interpretación gráfica de los cuadrados medios.
El \(\text{CMttos}\) es el cuasipromedio22 de las distancias cuadráticas entre las medias de los tratamientos y la media general (líneas verdes). Por su parte, el \(\text{CME}\) es el cuasipromedio de las distancias cuadráticas entre la respuesta de cada unidad experimental y la media de su correspondiente grupo (líneas rojas).
Teniendo en cuenta lo anterior y que la figura 6.7 ilustra un escenario de hipótesis alternativa, mientras que la figura 6.8 refleja un escenario de hipótesis nula, se hace evidente que bajo la hipótesis nula (figura 6.8), la varianza entre tratamientos (cuasipromedio de la distancia cuadrática de las líneas verdes) es menor o igual que la varianza dentro de tratamientos (cuasipromedio de la distancia cuadrática de las líneas rojas).
Por el contrario, mientras mayor sea la diferencia entre las medias (figura 6.7), mayor será la varianza entre tratamientos con respecto a la varianza dentro de tratamientos.
Existe, por tanto, una relación entre el juego de hipótesis para las medias y un juego de hipótesis para las varianzas, que puede expresarse así:
\(H_0:\mu_1=\mu_2=\dotsb=\mu_k=\mu\Leftrightarrow \sigma^2_{\text{ttos}}\le\sigma^2_{\text{error}}\) (figura 6.8)
\(H_a: \mu_i\ne\mu, \text{ para al menos un }i=1, 2,\dotsc, k\Leftrightarrow \sigma^2_{\text{ttos}}>\sigma^2_{\text{error}}\) (figura 6.7)
La figura 6.9 resume la representación gráfica de los escenarios de hipótesis nula e hipótesis alternativa, así como la equivalencia entre las hipótesis para las medias y para las varianzas.
\[ \begin{align} H_0:&\mu_1=\mu_2=\dotsb=\mu_k=\mu\\[1em] &H_0:\textcolor[RGB]{107, 170, 117}{\sigma^2_{\text{ttos}}}\le\textcolor[RGB]{239, 91, 91}{\sigma^2_{\text{error}}} \end{align} \]
\[ \begin{align} H_a: \mu_i\ne \mu,& \text{ para al menos un }i=1, 2,\dotsc, k\\[1em] &H_a:\textcolor[RGB]{107, 170, 117}{\sigma^2_{\text{ttos}}}>\textcolor[RGB]{239, 91, 91}{\sigma^2_{\text{error}}} \end{align} \]
Aunque la representación del escenario de la hipótesis alternativa podría parecer un tanto extraño, debido a que los cambios en las medias no están acompañados de cambios en las varianzas dentro de los tratamientos, este es justamente el comportamiento que se esperaría, siempre que se satisficieran los supuestos del modelo (cf. sección 6.3).
Por una parte, bajo distribución normal (cf. sección 6.3.2), la media y la varianza son independientes23, por lo que los cambios en las medias no tendrían por qué afectar las varianzas. Por otra parte, se espera que, sin importar dónde estén centrados los tratamientos, sus varianzas internas sean similares (cf. sección 6.3.3).
El juego de hipótesis que contrasta la variabilidad entre tratamientos con la variabilidad debida al error experimental es el típico juego de hipótesis para comparar varianzas de dos poblaciones normales, el cual puede evaluarse mediante el procedimiento presentado en la sección 5.1.1.
El estadístico de prueba se construye como la razón entre los estimadores muestrales de las varianzas. En juegos de hipótesis de una cola, este estadístico debe respetar el orden en que se formula el juego de hipótesis (cf. precaución 5.1).
El juego de hipótesis, expresado en términos de razón de las varianzas, se escribe así:
\[
H_0:\sigma^2_{\text{ttos}}\le\sigma^2_{\text{error}}\Leftrightarrow\frac{\sigma^2_{\text{ttos}}}{\sigma^2_{\text{error}}}\le 1
\] \[
H_a: \sigma^2_{\text{ttos}}>\sigma^2_{\text{error}}\Leftrightarrow\frac{\sigma^2_{\text{ttos}}}{\sigma^2_{\text{error}}}> 1
\]
Para una prueba de cola derecha, como la presente, el estadístico se construye como la razón del estimador de la variabilidad entre tratamientos y el estimador de la variabilidad debida al error experimental.
En el contexto del ANOVA, el \(\text{CMttos}\) es el estimador puntual de la variabilidad producida por los tratamientos o variabilidad entre tratamientos, mientras que el \(\text{CME}\) es el estimador puntual del error experimental o variabilidad dentro de tratamientos. Por tanto, el estadístico de prueba siempre se calcula como la razón entre el \(\text{CMttos}\) y el \(\text{CME}\).
Bajo la hipótesis nula, este estadístico de prueba sigue una distribución \(F\), con los grados de libertad de los tratamientos \((k−1)\) y del error \((n−k)\), lo cual se expresa así24:
\[
F_{\text{c}}=\frac{\text{CMttos}}{\text{CME}}\overset{H_0}\thicksim F_{(k-1,\, n-k)}
\]
Por tanto, es posible decidir sobre el juego de hipótesis acerca de las varianzas, ya sea comparando el estadístico de prueba, \(F\text{c},\) con el correspondiente valor crítico de la distribución \(F_{(k−1,\, n−k)}\) u obteniendo el respectivo valor p (cf. tabla 5.1 y figuras 5.3 (b) y 5.3 (e)).
El método clásico se basa en la siguiente regla de decisión:
\(\text{si }F_\text{c}\ge F_{\alpha(k-1,\, n-k)} \Rightarrow\) rechaza \(H_0\) con un nivel de significancia \(\alpha.\)
El valor p se obtiene como el área a la derecha del estadístico de prueba en la distribución de referencia, tal y como se muestra en la figura 6.10.
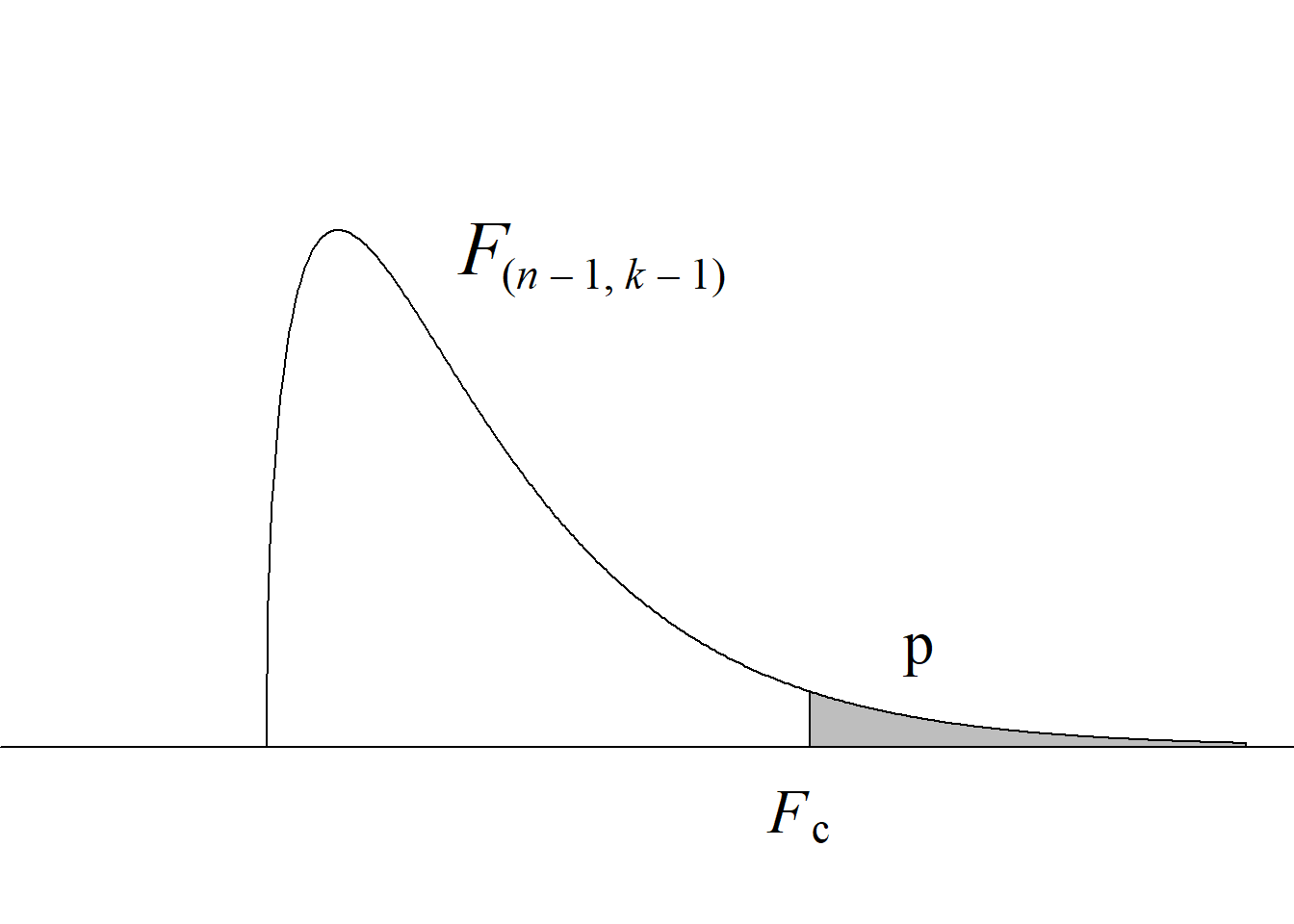
Tal y como se ilustra en la figura 6.9, el contraste del juego de hipótesis que compara la variación entre tratamientos con la variación dentro de tratamientos equivale a contrastar el juego de hipótesis para la comparación de las medias de \(k\) tratamientos.
El hecho de que, para la comparación de \(k\) medias, la prueba que realmente se realice sea una prueba de homogeneidad de varianzas de cola derecha permite entender por qué se usa un estadístico de prueba que, bajo la hipótesis nula, sigue una distribución \(F\) y por qué se calcula el valor p como la probabilidad de obtener un valor mayor que el del estadístico de prueba en la distribución de referencia.
Esta relación, sin embargo, solo suele detallarse para fines didácticos. En la práctica, suele manejarse como una “caja negra”, no siendo común que aparezca ni en la postulación del juego de hipótesis ni en la interpretación de los resultados.
El usuario del ANOVA plantea el juego de hipótesis para las medias (cf. expresión 6.5), evalúa la significancia con base en el estadístico \(F\text{c}\) y concluye sobre las medias, obviando todas las relaciones intermedias.
El juego de hipótesis sobre las varianzas suele permanecer oculto tanto para el investigador como para los receptores de los resultados.
En resumen…
Este es el esquema manejado en la práctica:
\[
H_0:\mu_1=\mu_2=\dotsb=\mu_k=\mu\
\] \[
H_a: \mu_i\ne\mu, \text{ para al menos un }i=1, 2,\dotsc, k
\]
\(\text{si } F_\text{c}\ge F_{\alpha(k-1,\, n-k)},\) rechaza \(H_0\) con un nivel de significancia \(\alpha\)
Si \(\text{valor p}\le\alpha,\) se dice que el ANOVA es significativo y se concluye que existe diferencia entre al menos dos de las medias comparadas.
En caso contrario, se dice que el ANOVA no es significativo, lo que quiere decir que no no se dispone de evidencia suficiente para afirmar que las medias difieren.
Para facilitar la visualización de los principales elementos del ANOVA, estos suelen organizarse de manera similar a lo mostrado en la tabla 6.4, pudiendo existir variaciones en formato entre las salidas generadas por diferentes aplicaciones estadísticas.
| Fuentes de variación | Grados de libertad | Sumas de cuadrados | Cuadrados medios | Estadístico F | Valor p |
|---|---|---|---|---|---|
| Tratamientos | \(k-1\) | \(\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}\) | \(\frac{\text{SCttos}}{k-1}\) | \(\frac{\text{CMttos}}{\text{CME}}\) | \(P(F_{(k-1,\,n-k)}>F_\text{c})\) |
| Error | \(n-k\) | \(\text{SCT}-\text{SCttos}\) | \(\frac{\text{SCE}}{n-k}\) | ||
| Total | \(n-1\) | \(\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}\) |
6.2.7 Relación entre el ANOVA y la prueba de \(t\)
El ANOVA es una generalización de la prueba de \(t\) presentada en la sección 5.2.1.
Mientras que la prueba de \(t\) compara las medias de dos poblaciones normales usando muestras independientes, el ANOVA de una vía presentado en esta sección permite comparar las medias de \(k\) poblaciones normales usando muestras independientes.
En el caso particular de comparación de dos grupos, ambos métodos son equivalentes, tanto conceptual como numéricamente.
Para ilustrarlo, partamos de la definición de una variable aleatoria \(t\) con \(\nu\) grados de libertad a partir de la razón entre una variable aleatoria normal estándar y la raíz cuadrada de una variable aleatoria ji cuadrado dividida entre sus grados de libertad (cf. sección 3.7.3):
Si \(Z\thicksim N(0,\,1)\) y \(U\thicksim\chi_{(\nu)}^2,\) siendo \(Z\) y \(U\) independientes entre sí:
\[
\frac{Z}{\sqrt{U/\nu}}\thicksim t_{(\nu)}:=t_{\nu}
\]
La expresión anterior facilita visualizar la forma que adquiere una variable aleatoria \(t_{(\nu)}\) cuando se eleva al cuadrado:
\[
t_\nu^2=\frac{Z^2}{U/\nu}=\frac{Z^2/1}{U/\nu}
\]
El numerador es una variable aleatoria ji cuadrado25 con un grado de libertad dividida entre sus grados de libertad, mientras que el denominador es una variable aleatoria ji cuadrado independiente dividida entre sus grados de libertad.
Esta razón es una variable aleatoria \(F\) con los grados de libertad del numerador y del denominador, es decir, 1 y \(\nu\) grados de libertad (cf. sección 3.7.4).
\[
t_\nu^2\thicksim F_{(1,\,\nu)}
\]
¿¡Y los grados de libertad!?
Cuando se emplea el ANOVA para comparar dos tratamientos \((k=2),\) con \(r_1\) y \(r_2\) réplicas, se tiene el siguiente desglose de los grados de libertad:
\(\text{glT}=(r_1+r_2)-1\)
\(\text{glttos}=k-1=1\)
\(\text{gle}=((r_1+r_2)-1)-1=r_1+r_2-2\)
Cuando se usa la prueba de \(t,\) los grados de libertad de la distribución de referencia son los utilizados para la estimación de la varianza combinada, es decir, \(n_1+n_2-2\) (cf. expresión 5.3 ), que son los mismos grados de libertad del error, cambiando únicamente la nomenclatura.
En adición a esta equivalencia distribucional, puede verificarse la correspondiente equivalencia en los estadísticos de prueba.
Teniendo presentes las anteriores equivalencias, al comparar dos tratamientos usando muestras independientes, el estadístico de prueba \(F_{\text{c}}\) del ANOVA de una vía es el cuadrado del estadístico de prueba \(t_\text{c}\) de la prueba de \(t\) y —lo que resulta particularmente relevante— los valores p de ambas pruebas son exactamente iguales.
En consecuencia, cuando se comparan únicamente dos tratamientos usando muestras independientes, el ANOVA y la prueba de \(t\) conducen exactamente a la misma decisión inferencial sobre las medias.
¡Use la prueba de Welch!
Se reitera la recomendación presentada en la sección 5.2 concerniente a utilizar la prueba de Welch siempre que se comparen las medias de dos poblaciones normales, usando muestras independientes.
Para la comparación de más de dos medias, se recomienda el ANOVA.
6.3 Supuestos del análisis de varianza
El objetivo último de los procesos inferenciales son las poblaciones de campo a las cuales se busca extender la información obtenida en los ensayos. Este proceso se realiza mediante un modelo estadístico basado en variables aleatorias (cf. sección 3.9).
En consecuencia con lo anterior, es necesario diferenciar dos perspectivas al considerar los supuestos de un modelo:
1. Descripción de los supuestos. Tiene que ver con la forma en que se ha estructurado el modelo. En esta etapa no hay lugar a valoración alguna. Solamente se indica cuáles fueron los insumos teóricos usados en la definición del modelo. En tal sentido, si un modelo considera, por ejemplo, variables aleatorias normalmente distribuidas, no hay lugar a discusión alguna: las variables aleatorias de dicho modelo son normales por definición.
2. Evaluación de supuestos. Esta parte consiste en valorar la consistencia entre las características del modelo y el comportamiento de las muestras, acorde con su naturaleza y con el diseño y ejecución del experimento.
Con frecuencia se argumenta que el comportamiento de las poblaciones de campo no es tan perfecto como el de los modelos teóricos que se usan para describirlas, por lo que deberían relajarse los estándares para su evaluación.
Aunque el argumento pueda ser cierto, la conclusión a la que se llega no necesariamente lo es. No, por el mero hecho de que un modelo resulte inadecuado para describir una situación de campo, ha de relajarse su evaluación.
Lo que es necesario preguntarse es qué tanto se afecta el desempeño de la técnica cuando el comportamiento de la población de campo se aleja del modelo teórico; en otras palabras, cuando la información muestral sugiera desviaciones o violaciones de los supuestos del modelo.
Se dice que un método es robusto a la violación de un supuesto cuando esta no altera notablemente su desempeño (cf. nota 2.1 y sección 4.1). En tal caso, podrían tolerarse desviaciones leves de dicho supuesto.
Por el contrario, si un método no es robusto a la desviación de un supuesto, ello implica que su violación pondría en entredicho los resultados generados por el método. En tal caso, el investigador debería ser estricto en su evaluación.
La manera en la que las muestras exhiban un comportamiento acorde con las condiciones establecidas por el modelo define la validez interna de los procesos inferenciales.
Consideremos nuevamente el modelo del ANOVA de una vía, cuyos supuestos se resumen así (cf. expresión 6.8):
\[
\varepsilon_{ij}\text{ iid } N(0,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\]
Esta expresión establece que los errores son variables aleatorias independientes que están igualmente distribuidas normalmente con media cero y varianza común, \(\sigma^2.\) Ahí quedan sintetizados los supuestos del modelo del ANOVA de una vía.
Independencia entre los errores
Normalidad de los errores
Homogeneidad de las varianzas de los errores
¿¡Y la esperanza!?
Aunque podría parecer que otro de los supuestos del modelo es que la esperanza de los errores sea cero, realmente no es así.
Esta es una condición que —por la forma en que se definen los errores: desviaciones a la media— siempre se satisface.
Expresar los supuestos en términos de los errores permite condensar las condiciones iniciales definidas para las variables aleatorias que modelan la respuesta de campo (cf. expresión 6.2):
\[
Y_{ij}\thicksim N(\mu_i,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\]
¿¡Y la independencia!?
Puesto que la sigla \(\text{iid}\)26 únicamente aparece en la definición de la distribución de los \(\varepsilon_{ij},\) podría pensarse que la independencia no aplica a la definición de las \(Y_{ij}.\) Sin embargo esto no es así.
Puesto que la media de \(Y_{ij}\) es \(\mu_i,\) no sería correcto afirmar que las \(Y_{ij}\) están igualmente distribuidas, por lo que no aplica el uso de la etiqueta \(\text{iid}\). Sin embargo, las \(Y_{ij}\) sí son independientes por definición.
¡Sobre los errores!
Por su sencillez, el modelo de ANOVA de una vía basado en muestras independientes facilita explorar la relación entre la variable respuesta y los errores del modelo. No obstante, en modelos más complejos esta relación no resulta tan directa.
La manera más ortodoxa y general de expresar los supuestos de los modelos inferenciales es a través de los errores del modelo; no sobre la variable respuesta.
6.3.1 Independencia
El modelo del ANOVA establece que los errores \(\varepsilon_{ij}\) son independientes.
Despejando \(\varepsilon_{ij}\) del modelo 6.3, se observa que los \(\varepsilon_{ij}\) corresponden a las desviaciones entre las variables aleatorias y la media poblacional de su correspondiente grupo:
\[
\varepsilon_{ij}=Y_{ij}-\mu_i,\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\]
Puesto que \(\mu_i\) es un valor fijo para cada grupo (no una variable aleatoria), la independencia de los \(\varepsilon_{ij}\) se cumple siempre que las variables aleatorias \(Y_{ij}\) sean independientes.
Acorde con lo discutido anteriormente, las variables aleatorias \(Y_{ij}\) —como entes teóricos— son independientes por definición. La evaluación del supuesto de independencia está basada en la consideración de que las observaciones registradas en diferentes unidades experimentales sean independientes.
Para este análisis resulta conveniente apoyarse en el concepto de eventos independientes. La independencia de dos eventos implica que la probabilidad de que ocurra un evento \(\text{A},\) dada la ocurrencia de un evento \(\text{B},\) es igual a la probabilidad de que ocurra \(\text{A}\) por sí misma. Esto quiere decir que, sin importar cuál sea el resultado del evento \(\text{B}\), la probabilidad de \(\text{A}\) será siempre la misma.
Llevando este concepto a la práctica, la independencia se propicia en los ensayos de campo cuando se rompen las condiciones de cercanía o similitud que puedan hacer que la respuesta de una unidad experimental se vea afectada por la respuesta de otra(s) unidad(es).
Así, al trabajar con animales, por ejemplo, las relaciones filiales entre animales (cercanía genética) pueden producir respuestas más similares que las que se obtendrían de animales no emparentados de la población objetivo.
Algo similar puede presentarse cuando las unidades experimentales están sujetas a cercanía espacial, temporal, idiosincrática o de cualquier otro tipo, dependiendo, desde luego, de la naturaleza de la población objetivo y de la respuesta evaluada.
La falta de independencia puede tener origen en una asignación no aleatoria de los tratamientos a las unidades experimentales (en estudios susceptibles de aleatorización) o por un método de muestreo inadecuado (en estudios que no permitan aleatorizar los tratamientos sobre las unidades experimentales), donde se generen esquemas que hagan caso omiso de posibles relaciones por cualquier tipo de cercanía.
Asimismo, la independencia falla cuando se toman las lecturas registradas en submuestras (cf. sección 6.1.7.1) para evaluar la variabilidad dentro de tratamientos, incurriendo en la denominada seudoreplicación (cf. sección 6.1.12).
Los esquemas de aleatorización con adecuado intercalamiento (cf. sección 6.1.11.1) constituyen la mejor estrategia para romper las condiciones de cercanía que podrían generar respuestas dependientes. No obstante, es necesario tener presente que lo que realmente se hace es propiciar la independencia, más que garantizarla.
¡Propicie la independencia!
La independencia se propicia rompiendo las condiciones de cercanía o similitud que puedan hacer que la respuesta de una unidad experimental se vea afectada por la respuesta de otra(s) unidad(es) experimental(es).
Los esquemas de aleatorización con adecuado intercalamiento (cuando sea del caso) constituyen la mejor estrategia para romper las condiciones de cercanía que podrían generar respuestas dependientes.
Cuando se viola el supuesto de independencia, la relación entre las sumas de cuadrados y la varianza no sigue una distribución ji cuadrado (cf. expresión 6.13), con lo cual, bajo la hipótesis nula, la razón entre \(\text{CMttos}\) y \(\text{CME}\) tampoco sigue una distribución \(F.\) En consecuencia, la validez interna del estudio se vuelve cuestionable.
Por otra parte, la falta de independencia causada por condiciones de cercanía entre las réplicas de un tratamiento suele dar lugar a respuestas más similares que las que se obtendrían de unidades independientes, lo que hace que se subestime el error experimental, con el consiguiente incremento espurio de la potencia de la prueba. Es decir que los análisis de varianza basados en tales muestras son más proclives a fallar por errores tipo I (declarar diferencias que no existen), tal y como se indica en el estudio realizado por Scariano y Davenport (1987).
En el modelo del ANOVA de una vía, no es posible probar la independencia27, ni realizar ninguna corrección para superar problemas de falta de independencia entre unidades experimentales, en caso de que estos se hubieran presentado durante el desarrollo del experimento.
Todas las acciones para propiciar la satisfacción de esta condición deben realizarse durante la planeación y el desarrollo del experimento y deben quedar debidamente registradas en la sección de materiales y métodos.
Una vez realizado el experimento, no existe transformación o ajuste —dentro del marco del ANOVA— que permita corregir el problema de falta de independencia, en caso de que esté presente.
6.3.2 Normalidad
En el diagnóstico de normalidad es necesario diferenciar entre errores y residuales.
A partir del modelo de medias (expresión 6.3), los errores pueden obtenerse mediante despeje:
\[
\varepsilon_{ij}=Y_{ij}-\mu_i
\tag{6.16}\]
Los errores están conformados por el conjunto de variables aleatorias \(\varepsilon_{ij}\) que representan las desviaciones entre \(Y_{ij}\) y la media poblacional del correspondiente tratamiento.
Puesto que las medias poblacionales son parámetros desconocidos, los errores son variables aleatorias incognoscibles a nivel muestral.
En consecuencia, se hace necesario estimar el parámetro \(\mu_i,\) para lo cual se utiliza su estimador lineal insesgado, \(\overline{Y}_{i\bullet}\) (cf. sección 3.9.1.1.1). Este cambio de referente de centralidad da lugar a los residuales, los cuales quedan definidos así:
\[
r_{ij}=Y_{ij}-\overline{Y}_{i\bullet}
\tag{6.17}\]
Aunque la necesidad de remplazar \(\mu_i\) por su estimador es evidente, no resulta tan evidente la validez de los procedimientos que se basan en los \(r_{ij}\) para responder preguntas sobre los \(\varepsilon_{ij}.\)
Anticipando que el empleo de los \(r_{ij}\) en lugar de \(\varepsilon_{ij}\) es perfectamente válido, hay matices en la relación de estas variables aleatorias, cuya exploración resulta particularmente ilustrativa.
Un error frecuente al evaluar normalidad consiste en realizar el chequeo sobre la variable respuesta, en lugar de hacerlo sobre los residuales del modelo.
¡No evalúe normalidad sobre la respuesta!
Si bien es cierto que los residuales heredan su estructura probabilística de la variable respuesta, cada uno de los grupos puede tener una distribución normal con diferente centro, tal y como se ilustra en la figura 6.6, dando lugar a una mezcla de normales con patrón multimodal, que, al ser evaluada de manera conjunta, puede mostrar fuertes desviaciones de la distribución normal, por el simple hecho de que las muestras tengan diferentes centros.
Considérese la información presentada en la tabla 6.5, donde se muestran las lecturas de la variable respuesta, para un ensayo con 3 tratamientos y 4 réplicas. En la última columna se presentan los residuales, calculados como la diferencia entre cada lectura y la media del correspondiente tratamiento.
| Tratamientos | Y | Media | Residuales |
|---|---|---|---|
| A | 4.8 | \(\\[1.4em]\) 4.425 |
0.375 |
| A | 5.0 | 0.575 | |
| A | 3.5 | -0.925 | |
| A | 4.4 | -0.025 | |
| B | 19.1 | \(\\[1.4em]\) 20.025 |
-0.925 |
| B | 20.3 | 0.275 | |
| B | 19.7 | -0.325 | |
| B | 21.0 | 0.975 | |
| C | 59.5 | \(\\[1.4em]\) 60.550 |
-1.050 |
| C | 60.4 | -0.150 | |
| C | 62.5 | 1.950 | |
| C | 59.8 | -0.750 |
Usando R, puede verificarse que al aplicar la prueba de Shapiro-Wilk sobre la variable respuesta, se rechaza la hipótesis de normalidad \((\text{p-value} = 0.006455),\) mientras que, al aplicarla sobre los residuales del modelo, esta no se rechaza \((\text{p-value} = 0.3969).\)
Este ejemplo muestra claramente que la evaluación de normalidad sobre la variable respuesta no equivale a la evaluación sobre los residuales del modelo, siendo esta última la correcta.
Dejemos de lado, por el momento, las limitaciones inherentes a responder preguntas sobre poblaciones a partir de muestras y analicemos el aspecto central que hace necesaria la normalidad en el contexto del ANOVA.
La normalidad estructura el proceso inferencial del ANOVA. Solamente cuando los errores están normal e independientemente distribuidos puede garantizarse que la razón entre \(\text{SCE}\) y la varianza poblacional siga una distribución ji cuadrado y que —bajo la hipótesis nula— la razón entre \(\text{CMttos}\) y \(\text{CME}\) siga una distribución \(F\).
Para analizar la anterior cadena de afirmaciones, partamos de la expresión inicial de los supuestos del ANOVA:
\[
\varepsilon_{ij}\text{ iid } N(0,\ \sigma^2)
\]
Estandarizando:
\[
\frac{\varepsilon_{ij}-0}{\sigma} \text{ iid } N(0,\ 1)
\]
Al elevar al cuadrado cualquiera de estas variables aleatorias normales estándar, se obtiene una ji cuadrado con un grado de libertad:
\[
\left(\frac{\varepsilon_{ij}}{\sigma}\right)^2=\frac{\varepsilon_{ij}^2}{\sigma^2} \thicksim\chi^2_{(1)}
\]
Sumando todos los \(\varepsilon_{ij}\) se obtiene una variable aleatoria ji cuadrado con \(n\) grados de libertad:
\[
\sum\limits_{i=1}^k\sum\limits_{j=1}^{r_i} \frac{\varepsilon_{ij}^2}{\sigma^2}\thicksim\chi^2_{(n)}
\]
Acorde con lo ilustrado en la expresión 6.16, el cálculo de los errores exigiría conocer los \(k\) parámetros \(\mu_i\) de las poblaciones comparadas. En su lugar, a nivel muestral se utilizan los \(k\) estimadores puntuales correspondientes, \(\overline{Y}_{i\bullet},\) lo que equivale a trabajar con los residuales:
\[
\begin{align}
\frac{\sum\limits_{i=1}^k\sum\limits_{j=1}^{r_i} r_{ij}^2}{{\sigma^2}}
&=\frac{\sum\limits_{j=1}^{r_1} r_{1j}^2}{{\sigma^2}}
+\frac{\sum\limits_{j=1}^{r_2} r_{2j}^2}{{\sigma^2}}+\dotsb
+\frac{\sum\limits_{j=1}^{r_k} r_{kj}^2}{{\sigma^2}}\\[1.4em]
&=\frac{\sum\limits_{j=1}^{r_1} \left(Y_{1j}-\overline{Y}_{1\bullet}\right)^2}{{\sigma^2}}
+\frac{\sum\limits_{j=1}^{r_2} \left(Y_{2j}-\overline{Y}_{2\bullet}\right)^2}{{\sigma^2}}+\dotsb
+\frac{\sum\limits_{j=1}^{r_k} \left(Y_{kj}-\overline{Y}_{k\bullet}\right)^2}{{\sigma^2}}
\end{align}
\]
Cada uno de los términos de la anterior expresión es el numerador de una varianza muestral, dividido entre la varianza poblacional. En la sección 4.3.1 se demostró que una expresión análoga a cualquiera de tales términos sigue una distribución ji cuadrado con \(n-1\) grados de libertad (cf. nota 4.2).
En este caso, cada uno de los términos sigue una distribución ji cuadrado con \(r_i-1\) grados de libertad. Por la propiedad aditiva de las variables aleatorias ji cuadrado, la expresión anterior sigue una distribución ji cuadrado con \((r_1-1)+(r_2-1)+\dotsb+(r_k-1)\) grados de libertad, es decir, \(n-k\) grados de libertad:
\[
\frac{\sum\limits_{i=1}^k\sum\limits_{j=1}^{r_i} \left(Y_{ij}-\overline{Y}_{i\bullet}\right)^2}{{\sigma^2}}
=\frac{\text{SCE}}{\sigma^2}
\thicksim \chi^2_{(n-k)}
\]
Análogamente, bajo la hipótesis nula30 se cumple:
\[
\frac{\text{SCttos}}{\sigma^2}
\thicksim \chi^2_{(k-1)}
\]
Finalmente, la razón entre los cuadrados medios representa la razón entre dos variables aleatorias ji cuadrado divididas por sus grados de libertad, cuya distribución es \(F\) con los grados de libertad del numerador y del denominador (cf. expresión 3.9):
\[
\dfrac{\dfrac{\text{SCttos}}{\sigma^2(k-1)}}{\dfrac{\text{SCE}}{\sigma^2(n-k)}}
=\dfrac{\text{CMttos}}{\text{CME}}
\overset{H_0}\thicksim F_{(k-1,\,n-k)}
\]
La distribución normal subyace asimismo en la construcción de intervalos de confianza y en los procedimientos de comparación de medias.
En muchas áreas de investigación aplicada —entre ellas la agraria y la biológica— se evalúan variables como pesos, longitudes y volúmenes, cuyo comportamiento distribucional puede ser adecuadamente modelado de manera directa con la normal.
En algunos otros casos, en los que no resulta adecuado modelar directamente las variables de interés con la distribución normal, puede incrementarse el tamaño de la unidad experimental, para propiciar que los promedios de las submuestras converjan a la normal, en virtud del teorema central del límite (cf. teorema 3.1 y sección 6.1.7.1).
Existen numerosos procedimientos, tanto genéricos como específicos, para evaluar el ajuste de una muestra a la distribución normal. Entre las pruebas genéricas —es decir, las que permiten evaluar el ajuste no solo a la distribución normal, sino a cualquier otra distribución— se encuentran ji cuadrado, Kolmogorov-Smirnov, Cramér-Von Mises y Anderson-Darling.
Entre las pruebas específicas —diseñadas exclusivamente para evaluar normalidad— se cuentan Shapiro-Wilk, Shapiro-Francia, Lilliefors, D’Agostino y Jarque-Bera.
La prueba de Shapiro-Wilk (cf. sección 4.1) se destaca por elevada potencia frente a muchas alternativas, lo que ha favorecido su amplia adopción en la práctica, convirtiéndola en una de las pruebas más utilizadas para evaluar normalidad (Mendes and Pala, 2003; Yap and Sim, 2011; Mohd Razali and Yap, 2011; Arnastauskaitė, Ruzgas and Bražėnas, 2021; Kamath, Poojari and Varsha, 2025), siendo actualmente la más popular de las pruebas para evaluación de normalidad.
La mayoría de programas estadísticos implementan esta prueba a través del algoritmo desarrollado por Royston (1995), que calcula el estadístico de prueba y su correspondiente valor p para muestras cuyo tamaño oscile entre 3 y 5000 observaciones. En R, se calcula mediante la función shapiro.test{stats} (cf. sección 4.1).
En muestras muy grandes —lo cual no es lo común en experimentos diseñados— la prueba de Shapiro-Wilk puede detectar desviaciones triviales de la distribución normal. En tales casos, una inspección gráfica mediante diagramas de probabilidad normal (QQ-plots) puede ayudar a valorar la relevancia práctica de dichas desviaciones.
Numerosos estudios indican que el análisis de varianza de una vía es razonablemente robusto frente a desviaciones moderadas del supuesto de normalidad (Pearson, 1931; Khan and Rayner, 2003; Schmider, Ziegler, Danay, Beyer and Bühner, 2010; Blanca, Alarcón, Arnau, Bono and Bendayan, 2017; Knief and Forstmeier 2021). Esta robustez se debe a que el procedimiento compara dos estimadores de la misma varianza poblacional. Bajo la hipótesis nula, ambos estimadores tienen esperanza \(\sigma^2,\) aun cuando la distribución subyacente no sea perfectamente normal.
Aunque ello permite relajar en cierta medida el cumplimiento estricto de esta condición, no debe entenderse como un salvoconducto para omitir su verificación. Teniendo en cuenta que las desviaciones leves del supuesto de normalidad no afectan notablemente el desempeño del ANOVA de una vía, y que la prueba de Shapiro-Wilk se emplea principalmente para detectar desviaciones severas de dicho supuesto, resulta suficiente realizar esta prueba con un nivel de significancia \(\alpha=0.01.\)
En consecuencia, si el valor p de la prueba de Shapiro-Wilk es mayor de 0.01, se considerará que no existe evidencia de desviaciones severas del supuesto de normalidad. Por el contrario, cuando \(p≤0.01,\) se considerará que existe evidencia de desviaciones severas y se evaluarán otras alternativas (cf. sección 4.1).
Cuando el supuesto de normalidad no se satisface al 1 %, puede considerarse en primera instancia la transformación de datos (cf. sección 6.5) como acción correctiva. Si con ello no se obtiene la corrección esperada, debería considerarse el uso de métodos no paramétricos (cf. capítulo 9), los cuales no exigen que los errores se distribuyan normalmente.
En resumen…
El modelo del ANOVA de una vía se basa en la distribución normal de los errores, cuya evaluación se realiza sobre los residuales.
La normalidad se hereda de la distribución de la variable respuesta dentro de cada tratamiento. El comportamiento distribucional de muchas variables de campo puede modelarse directamente con esta distribución. En algunos otros casos, como cuando se tienen conteos o evaluaciones de un panel, se incrementa el tamaño de la unidad muestral, como acción preventiva, de manera que los promedios de las mismas exhiban un comportamiento aproximadamente normal, en virtud del teorema central del límite.
Puesto que el análisis de varianza es robusto a desviaciones del supuesto de normalidad, basta con verificar su cumplimiento mediante la prueba de Shapiro-Wilk, usando un nivel de significancia \(\alpha=0.01.\) Cuando no se satisface dicha condición \((p ≤ 0.01),\) puede considerarse en primera instancia una acción correctiva, mediante transformaciones; de no obtenerse la corrección esperada, debería considerarse el uso de métodos no paramétricos, los cuales no exigen que los residuales sigan una distribución normal.
Finalmente, es importante recalcar que la normal se usa en los procesos inferenciales como modelo teórico del comportamiento distribucional de las poblaciones de campo (cf. sección 3.9 y sección 4.1). En tal sentido, no existen en campo poblaciones normales como tal. Lo que se contrasta mediante una prueba de bondad de ajuste, más que una pregunta con una respuesta dicotómica que indique si los datos se distribuyen o no se distribuyen normalmente (en cuyo caso habría que admitir que ninguna población de campo es normal), es qué tan adecuado resulta el uso de la normal para modelar el comportamiento distribucional de la población de campo.
Luego, lo que se busca con la prueba de Shapiro-Wilk es detectar discrepancias severas entre el modelo teórico y el comportamiento de las poblaciones de campo. Si la discrepancia no es grande, el modelo normal puede resultar útil, sin importar las preconcepciones que el investigador pueda tener sobre las variables de campo.
6.3.3 Homogeneidad de varianzas
Uno de los supuestos del modelo del ANOVA de una vía es que las poblaciones que se comparan tienen varianza común (cf. sección 6.2). A este supuesto se le denomina de homogeneidad de varianzas u homocedasticidad.
Si este supuesto es válido, dicha varianza común podrá estimarse con base en el promedio ponderado de las varianzas muestrales dentro de cada uno de los grupos (cf. expresión 6.1). Esta estimación deja de ser apropiada cuando las poblaciones de interés no comparten una varianza común, situación conocida como heterocedasticidad o de varianzas heterogéneas. En consecuencia, la prueba global del análisis de varianza, así como las pruebas de medias que de allí se derivan podrían carecer de validez.
Milliken y Johnson (2009) señalan que, aunque la violación del supuesto de homogeneidad de varianzas representa un problema más grave que la violación del supuesto de normalidad, sus efectos se atenúan cuando los tratamientos tienen el mismo número de réplicas o cuando, en diseños desbalanceados, los grupos más variables son también los de mayor tamaño.
Estos autores agregan que, en tales circunstancias, el desempeño de las pruebas es tan bueno que muchos estadísticos ni siquiera recomiendan evaluar homogeneidad de varianzas; Zar (1984) se encuentra entre quienes sostienen esta postura.
En otras palabras, el efecto de la heterocedasticidad depende no solo de la magnitud de las diferencias entre varianzas, sino también de cómo se relacionan dichas varianzas con los tamaños de muestra. Cuando los grupos más variables tienen mayor número de réplicas, el estimador del error tiende a inflarse y el estadístico \(F\) se vuelve conservador; en cambio, cuando los grupos más variables tienen menor tamaño muestral, el estadístico \(F\) puede inflarse artificialmente, incrementando el riesgo de errores tipo I.
Teniendo en cuenta lo anterior, se recomienda evaluar la homogeneidad de varianzas con un nivel de significancia \(\alpha=0.01\) en experimentos con igual número de réplicas y con \(\alpha=0.05\) cuando el número de réplicas difiera entre tratamientos.
Históricamente se han propuesto numerosas pruebas para evaluar la homogeneidad de varianzas. Entre las más populares se destacan la prueba de la F máxima de Hartley y la prueba de Bartlett, las cuales han ido cayendo en desuso, por depender altamente de la satisfacción del supuesto de normalidad.
En su lugar han ido posicionándose otras pruebas que son robustas a la violación de dicho supuesto, de entre las cuales la de Levene es una de las más usadas en la actualidad.
6.3.3.1 Prueba de Levene
Esta prueba fue propuesta en 1960 por Howard Levene, para contrastar el siguiente juego de hipótesis, en el contexto del análisis de varianza.
\[
\begin{align}
H_0&:\sigma^2_1=\sigma^2_2=\dotsb=\sigma^2_k=\sigma^2\text{ (varianzas homogéneas)}\\[0.7em]
H_a&:\sigma^2_i\ne\sigma^2\text{ para al menos un } i=1,2,\dotsc, k\text{ (varianzas heterogéneas)}
\end{align}
\]
Para contrastar este juego de hipótesis, Levene propuso realizar un análisis de varianza, tomando como variable respuesta los valores absolutos de las desviaciones de cada una de las observaciones respecto a la media de su correspondiente grupo:
\[
D_{ij}=\left|Y_{ij}-\overline{Y}_{i\bullet}\right|
\]
El ANOVA compara la media de las desviaciones absolutas dentro de cada grupo, lo cual puede expresarse mediante el siguiente juego de hipótesis:
\[
\begin{align}
H_0&:\mu_{D_1}=\mu_{D_2}=\dotsb=\mu_{D_k}=\mu\\[0.7em]
H_a&:\mu_{D_i}\ne\mu\text{ para al menos un } i=1,2,\dotsc, k
\end{align}
\]
El juego de hipótesis para las medias de la variable \(D\) constituye una forma operacional de contrastar la igualdad de varianzas de la la variable respuesta. Aceptar que las medias de las desviaciones absolutas no difieren entre grupos equivale a aceptar que las varianzas son homogéneas entre grupos. De igual manera, concluir que la media de las desviaciones absolutas difiere entre al menos dos grupos, equivale a concluir que las varianzas son heterogéneas.
Brown y Forsythe (1974) proponen una formulación alternativa de la prueba de Levene, consistente en calcular las desviaciones absolutas respecto a la mediana de cada grupo, en lugar de hacerlo respecto a la media. Estos autores indican que dicha prueba es más robusta a desviaciones del supuesto de normalidad.
Conover, Johnson y Johnson (1981), quienes emplean ensayos de simulación para comparar estas y otras pruebas de homogeneidad de varianzas, ratifican dicha conclusión. A esta prueba se le conoce como prueba de Brown-Forsythe o simplemente como prueba de Levene centrada en la mediana.
En R, la función leveneTest{car} calcula esta prueba por defecto (center = median); también puede calcularse la prueba original de Levene, usando la opción center = mean.
La prueba de Brown-Forsythe resulta adecuada para modelos balanceados simples. En escenarios más generales —como diseños desbalanceados, modelos con bloques o estructuras factoriales complejas— se recomienda la prueba generalizada de Levene propuesta por O’Neill y Mathews (cf. sección 7.2.2).
Cuando la prueba de Brown-Forsythe evidencie desviaciones severas del supuesto de homocedasticidad \((\text{p}≤0.01\) o \(\text{p}≤0.05),\) se recomienda en primera instancia una acción correctiva mediante transformaciones. Si no se obtiene la corrección esperada, puede recurrirse a alternativas paramétricas robustas a varianzas desiguales, como el ANOVA de Welch.
Resumen supuestos del ANOVA
En el contexto del ANOVA de una vía, no existen pruebas para evaluar el supuesto de independencia, ni tampoco existen acciones correctivas para superar los efectos indeseables de su violación.
Todas las acciones en pro de la satisfacción de este supuesto tienen lugar durante el desarrollo del experimento. El investigador debe propender por el uso de estrategias que rompan las condiciones de cercanía o similitud que puedan hacer que la respuesta de una unidad experimental dependa de la respuesta de otras unidades experimentales.
Los esquemas de aleatorización con adecuado intercalamiento constituyen la mejor estrategia para romper las condiciones de cercanía que podrían generar respuestas dependientes.
El supuesto de normalidad se evalúa sobre los residuales del modelo; no sobre la variable respuesta. Para tal efecto, se usa la prueba de Shapiro-Wilk, con un nivel de significancia \(\alpha=0.01.\)
Para evaluar el supuesto de homocedasticidad, se recomienda la prueba de Brown-Forsythe (versión robusta de la prueba de Levene), con un nivel de significancia \(\alpha =0.01\) si todos los tratamientos tienen el mismo número de réplicas o con un nivel de significancia \(α=0.05\) en ensayos con diferente número de réplicas. Cuando se detecten desviaciones severas, pueden considerarse transformaciones de los datos o el uso de métodos robustos a varianzas desiguales, como el ANOVA de Welch.
6.4 ANOVA de Welch
Cuando las varianzas son heterogéneas —especialmente en ensayos con diferente número de réplicas por tratamiento— el modelo clásico del ANOVA puede dejar de ser adecuado (cf. sección 6.3.3). Welch (1951) propuso una variante válida del ANOVA para estas situaciones.
Mediante el ANOVA de Welch —que es una extensión de la prueba de Welch basada en la distribución \(t\) (cf. sección 5.2.2)— se contrasta el siguiente juego de hipótesis:
\[
\begin{align}
H_0&:\mu_1=\mu_2=\dotsb=\mu_k=\mu\\[0.7em]
H_a&: \mu_i\ne\mu_{i'}, \text{ para al menos un par }i\ne i',\text{ con } \ i=1, 2,\dotsc, k;\quad i'=1, 2,\dotsc, k
\end{align}
\]
El modelo de medias se expresa así:
\[
Y_{ij}=\mu_i+\varepsilon_{ij},\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r_i
\]
Los supuestos del modelo son:
\[
\varepsilon_{ij}\text{ independientes, } \varepsilon_{ij}\thicksim N(0,\ \sigma^2_i),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r_i
\]
Nótese que los supuestos de independencia y normalidad coinciden con los del ANOVA clásico, pero —a diferencia de este— el modelo del ANOVA de Welch no postula una varianza común para todos errores, sino una colección de varianzas \(\left(\sigma^2_i\right)\) que pueden diferir entre tratamientos.
La idea clave del ANOVA de Welch consiste en asignar ponderaciones diferenciadas a cada tratamiento, de manera que reflejen la certidumbre o cantidad de información. Esta certidumbre está directamente relacionada con el número de réplicas e inversamente con la variabilidad.
La ponderación de un tratamiento recoge su certidumbre
Los tratamientos con baja variabilidad reciben ponderaciones mayores que los de alta variabilidad.
Asimismo, los tratamientos con mayor número de réplicas reciben ponderaciones más altas que los que cuentan con un número menor de réplicas.
Mientras más información aporte un tratamiento, más alta será su ponderación.
La ponderación del \(i\)-ésimo tratamiento se define así:
\[
w_i=\frac{r_i}{S_i^2}
\]
La media global se calcula como una media ponderada de las medias de los diferentes tratamientos, así:
\[
\overline{Y}_w=\frac{\sum\limits_{i=1}^k{w_i\overline{Y}_{i\bullet}}}{\sum\limits_{i=1}^kw_i}
\]
Nótese que —por la forma en que está construido el factor de ponderación— la media no solamente queda ponderada por el tamaño de muestra (como es usual), sino también por la incertidumbre asociada con la variabilidad, de modo que cada tratamiento participa según la cantidad de información que aporta.
El componente central del estadístico de prueba del ANOVA de Welch se calcula así:
\[
\frac{1}{k-1}\sum\limits_{i=1}^k w_i(\overline{Y}_{i\bullet}-\overline{Y}_w)^2
\]
Aunque parezca —por comparación con el ANOVA clásico— que esta expresión no es más que un \(\text{CMttos}\) con ponderación en el término correspondiente a cada tratamiento, su naturaleza es más rica. La expansión de los términos de la suma y el desglose de los componentes del factor de ponderación facilitan su análisis:
\[
\frac{1}{k-1}\left(\frac{ r_1(\overline{Y}_{1\bullet}-\overline{Y}_w)^2}{S_1^2}+\dotsb+
\frac{ r_k(\overline{Y}_{k\bullet}-\overline{Y}_w)^2}{S_k^2}
\right)
\]
En cada término, el numerador recoge la variabilidad aportada por el tratamiento, mientras que el denominador constituye la variabilidad dentro del tratamiento. En este sentido, cada término adopta la forma de una razón análoga a la del estadístico \(F\) del ANOVA clásico.
En un escenario de varianzas homogéneas, las varianzas dentro de los tratamientos \((S_i^2)\) se promediarían para generar un estimador conjunto del error experimental, es decir, el \(\text{CME}.\) En el presente escenario, sin embargo, —al no existir una varianza común, \(\sigma^2\)— esta estimación deja de tener sentido. Es por esto que, en presencia de heterocedasticidad, el equivalente a la razón \(F\) del ANOVA clásico se construye término a término, incorporando de manera diferenciada la variabilidad de cada tratamiento.
A partir de estos elementos, se construye el estadístico de prueba del ANOVA de Welch:
\[
F_{\text{Welch}}=\dfrac{\dfrac{1}{k-1}\sum\limits_{i=1}^k w_i(\overline{Y}_{i\bullet}-\overline{Y}_w)^2}
{1+\dfrac{2(k-2)}{k^2-1}\sum\limits_{i=1}^k\left(\dfrac{1}{r_i-1}\left(1-\dfrac{w_i}{\sum_{i=1}^k{w_i}} \right)^2\right)}
\]
Por analogía con el ANOVA clásico podría intentarse establecer una similitud entre esta expresión y la razón \(\text{CMttos}/\text{CME}.\) No obstante, dicha similitud ya está recogida en el numerador de \(F_{\text{Welch}}.\) El denominador, por su parte, constituye un factor de ajuste basado en el desequilibrio de la información aportada por los tratamientos.
El factor de ajuste que aparece en el denominador siempre es mayor o igual a 1. En un escenario de varianzas homogéneas e igual número de réplicas, este factor tiende a 1 cuando aumentan los tamaños de muestra, de modo que el estadístico de prueba queda determinado por el numerador, sin ningún tipo de corrección, coincidiendo con el estadístico \(F\) del ANOVA clásico.
Mientras mayor sea el desbalance por heterocedasticidad o por diferencias en el número de réplicas —lo cual queda recogido en la diferenciación de las ponderaciones— mayor será también este factor.
En consecuencia, el denominador actúa como un factor de ajuste por desbalance que tiende a disminuir el valor del estadístico de prueba y, por tanto, a mejorar el control del error tipo I.
¡Desbalance!
La diferenciación de las ponderaciones refleja el desbalance por heterocedasticidad o por diferencias en el número de réplicas.
Milliken y Johnson (2009) señalan que el problema de la heterocedasticidad se atenúa cuando los grupos más variables son también los de mayor tamaño.
Consideremos el ponderador del \(i\)-ésimo tratamiento:
\[
w_i=\frac{r_i}{S_i^2}
\]
Esta expresión permite apreciar que la combinación de altas varianzas con mayor número de réplicas genera factores de ponderación equilibrados, más cercanos entre sí.
En contraste, las combinaciones de tratamientos variables con pocas réplicas o tratamientos poco variables con muchas réplicas dan lugar a ponderadores más extremos, alejados del ponderador promedio, que reflejan tales desbalances.
Estas diferencias en las ponderaciones determinan la magnitud del factor de ajuste en el estadístico de Welch.
Bajo la hipótesis nula, el estadístico de prueba se aproxima a una distribución \(F,\) con \(k-1\) grados de libertad en el numerador y \(\nu\) grados de libertad en el denominador. Esta aproximación mejora a medida que aumentan los tamaños de muestra de los tratamientos.
Los grados de libertad del denominador se estiman mediante la aproximación de Welch-Satterthwaite:
\[
\widehat\nu=\frac{k^2-1}{3\sum\limits_{i=1}^k\dfrac{1}{r_i-1}\left(1-\dfrac{w_i}{\sum_{i=1}^k w_i} \right)^2}\,,
\]
donde \(\widehat\nu\) se utiliza como aproximación de los grados de libertad del denominador en la distribución de referencia. Estos grados de libertad se utilizan sin redondear (cf. advertencia 5.2).
En consecuencia, bajo la hipótesis nula,
\[
F_{\text{Welch}}=\dfrac{\dfrac{1}{k-1}\sum\limits_{i=1}^k w_i(\overline{Y}_{i\bullet}-\overline{Y}_w)^2}
{1+\dfrac{2(k-2)}{k^2-1}\sum\limits_{i=1}^k\left(\dfrac{1}{r_i-1}\left(1-\dfrac{w_i}{\sum_{i=1}^k{w_i}} \right)^2\right)}\overset{\cdot}\thicksim F_{(k-1,\;\nu)}
\]
El valor p del ANOVA de Welch se obtiene como la probabilidad de un valor mayor que el del estadístico de prueba en la distribución de referencia.
En R, la función oneway.test permite realizar esta prueba de manera directa.
Las siguientes recomendaciones orientan la selección del método para la comparación de medias en función del número de tratamientos y del cumplimiento de los supuestos:
Para comparar medias…
Cuando \(k=2\) y se satisfacen los supuestos de independencia y normalidad, utilice la prueba \(t\) de Welch (cf. sección 5.2.2).
Cuando \(k\ge3\) y se satisfacen los supuestos de independencia, normalidad y homocedasticidad, utilice el ANOVA clásico.
Cuando \(k\ge3\) y se satisfacen los supuestos de independencia y normalidad, pero existen combinaciones desfavorables de heterocedasticidad y número de réplicas (cf. sección 6.3.3), utilice el ANOVA de Welch.
Cuando se satisfacen el supuesto de independencia, pero falla el de normalidad, intente corregir mediante una transformación (cf. sección 6.5). Si no se corrige el problema, recurra a técnicas no paramétricas (cf. capítulo 9).
Cuando falla la independencia, repita el ensayo.
6.5 Transformaciones
Cuando —al ajustar un modelo de ANOVA— se evidencian violaciones severas de los supuestos de normalidad u homocedasticidad, es común realizar un reescalamiento o transformación de la variable respuesta, con lo cual, a menudo se logra una mejor adecuación de los datos a los requerimientos del modelo.
Si esta estrategia no resulta efectiva, suele recurrirse a técnicas inferenciales basadas en supuestos menos restrictivos (cf. capítulo 9).
¡La independencia no es negociable!
Cualquiera que sea la estrategia seguida —transformación o uso de otras técnicas—, únicamente se abordan problemas asociados con la distribución de los errores (normalidad) y la homogeneidad de varianzas.
En ningún caso se resuelven ni se evaden problemas de falta de independencia entre las observaciones.
Al referirse a las transformaciones, Sokal y Rohlf (1969) reconocen que el usuario puede experimentar cierto desasosiego al trabajar con una escala artificial, así como ante el hecho de que una prueba estadística que inicialmente no era significativa pueda llegar a serlo después de una transformación, lo cual podría interpretarse como una manipulación indebida.
No obstante, como señalan estos autores, una misma variable puede expresarse en diferentes escalas. Y aunque estamos más acostumbrados a emplear la escala lineal, no existe ninguna razón para considerar que esta sea intrínsecamente superior a otras. Por ejemplo, el pH se expresa en una escala logarítmica31, mientras que la raíz cuadrada de la superficie de un organismo puede constituir una medida más adecuada de su expresión biológica que la superficie misma.
Más allá de la legitimidad de emplear escalas alternativas, el aspecto más relevante de esta estrategia tiene que ver con los cambios en la significancia que pueden presentarse como consecuencia de aplicar las transformaciones.
Debe tenerse presente que se recurre a las transformaciones cuando los supuestos del modelo no se satisfacen en la escala original, pero sí logran cumplirse al modelar la variable transformada.
¿¡Con cuál me quedo!?
El modelo más plausible es aquel que satisface adecuadamente los supuestos, independientemente de lo que ocurra con la significancia de las pruebas antes o después de la transformación.
A continuación, se presentan algunas transformaciones que —por su simplicidad y efectividad— han sido de uso tradicional en la práctica investigativa.
Posteriormente, se introduce una familia paramétrica de transformaciones que incluye varias de estas transformaciones clásicas como casos particulares.
Finalmente, se discute el manejo e interpretación de la información cuando se ha aplicado alguna transformación y se presenta una función personalizada en R que orienta el proceso de elección.
6.5.1 Transformación logarítmica
Es quizá la más popular de las transformaciones y suele ser la primera opción considerada en muchas situaciones de la práctica investigativa.
Resulta particularmente efectiva cuando la distribución de los residuales presenta asimetría a la derecha (cf. figura 2.8 (b)). En estos casos, la transformación logarítmica, además de simetrizar la distribución, tiende a estabilizar las varianzas, puesto que en situaciones como la descrita la variabilidad suele incrementarse con el nivel de la respuesta32.
¿Cuál logaritmo?
Puede emplearse el logaritmo en cualquier base, sin que la significancia de la prueba se vea afectada por la base elegida.
Sin embargo, es habitual el uso del logaritmo natural, por corresponder con un caso particular de la transformación de Box-Cox (cf. sección 6.5.5).
La variable transformada se define como:
\[
Y_\text{t}=\log(Y)
\]
En R, esta transformación se implementa mediante la instrucción Yt <- log(Y).
Cuando los datos incluyen ceros, es necesario sumar una constante a todos los datos antes de aplicar la transformación, con el fin de garantizar que la transformación esté definida33.
Una práctica común consiste en sumar la unidad \(\left(\log(Y+1)\right).\) Sin embargo, Berry (1987) cuestiona este procedimiento por su carácter arbitrario. En su lugar, propone utilizar la constante \(c\) que minimice la función \(G,\) definida como la suma de los valores absolutos del coeficiente de asimetría y del coeficiente de curtosis calculados sobre los residuales del modelo.
La transformación resultante se expresa como:
\[
Y_\text{t}=\log(Y+c),\quad\text{ con }c\text{ tal que minimice }G=|a|+|k|
\]
¡Muy inspiradora!
Aunque la búsqueda de la constante de desplazamiento propuesta por Berry (1987) requiere un procedimiento iterativo, su implementación computacional es sencilla.
Esta idea resulta particularmente sugerente, pues —aunque el autor la desarrolla en el marco de la transformación logarítmica— puede aplicarse en cualquier situación en la que sea posible introducir una constante de desplazamiento, incluso bajo criterios de optimalidad alternativos.
6.5.2 Transformación raíz cuadrada
Esta transformación suele mostrar un buen desempeño cuando la variable respuesta corresponde a conteos, particularmente cuando su valor esperado es pequeño.
En estas situaciones, la distribución de los residuales presenta asimetría a la derecha (cf. figura 2.8 (b)) y la varianza es aproximadamente igual a la media34.
Asimismo, esta transformación puede resultar adecuada para respuestas provenientes de ensayos binomiales en los que la probabilidad de éxito se encuentra muy próxima a alguno de sus límites.
La variable transformada se define como:
\[
Y_\text{t}=\sqrt{Y}
\]
Esta transformación se implementa en R mediante la instrucción Yt <- sqrt(Y).
Cuando las respuestas incluyen ceros, ha sido tradicional desplazar todos los datos en 0.5 unidades antes de extraer la raíz cuadrada:
\[
Y_\text{t}=\sqrt{Y+0.5}
\]
La aplicación de esta transformación en respuestas de ensayos binomiales depende de la región del intervalo \([0, 1]\) en la que se ubiquen las probabilidades de éxito.
Cuando las probabilidades de éxito son cercanas a 0.5, la distribución de los residuales exhibe un comportamiento aproximadamente normal, aun con tamaños de muestra pequeños (cf. figura 3.7 (a)), por lo que la transformación puede ser innecesaria.
Por el contrario, valores de \(p\) cercanos a los límites dan lugar a distribuciones bastante asimétricas, en cuyo caso la transformación puede mejorar el comportamiento de los residuales.
Debe tenerse en cuenta, sin embargo, que la dirección de la asimetría depende de si la probabilidad de éxito es baja (cf. figura 3.6 (a)) o alta (cf. figura 3.6 (b)), y que la transformación raíz cuadrada no actúa de manera simétrica en los extremos del intervalo, por lo que su efectividad puede variar según la región en la que se ubiquen las probabilidades.
En ensayos en los que coexistan tratamientos con probabilidades de éxito altas y bajas, la transformación angular —que sí trata de manera simétrica los alejamientos respecto a 0.5— constituye una mejor opción (cf. sección 6.5.4).
La variable respuesta proveniente de ensayos binomiales no debe expresarse como porcentaje, sino como una proporción entre 0 y 1. Cuando la proporción se ubica en el rango superior, es necesario obtener su complemento antes de extraer la raíz cuadrada:
\[
Y_\text{t}=\sqrt{1-Y}
\]
6.5.3 Transformación inversa
Esta transformación suele ser muy efectiva para resolver problemas de falta de normalidad y heterocedasticidad de los residuales en situaciones en las que estos exhiben fuerte asimetría a la derecha, con valores pequeños muy concentrados y valores grandes muy dispersos.
Estas situaciones son comunes cuando la variable respuesta corresponde a tiempos de respuesta, de falla o de mortalidad. Asimismo, pueden presentarse al evaluar concentraciones químicas que varían en órdenes de magnitud, donde la varianza aumenta drásticamente con la media.
Esta transformación tiene un efecto de expansión sobre los valores pequeños y de compresión sobre los grandes, lo que favorece que la distribución final de los residuales se aproxime a la normal.
La variable transformada se define como:
\[
Y_\text{t}=\frac{1}{Y}
\]
Al observar la anterior expresión resulta evidente que esta transformación no está definida cuando las observaciones incluyen ceros.
Esta transformación se implementa en R mediante la instrucción Yt <- 1/Y.
6.5.4 Transformación angular
Esta ha sido tradicionalmente la transformación de referencia para corregir problemas de falta de normalidad y heterocedasticidad en los residuales cuando las respuestas provienen de ensayos binomiales con valores de \(p\) cercanos a 0 o a 1.
La variable respuesta que se somete a transformación no debe estar expresada como porcentaje, sino como una proporción entre 0 y 1.
La variable transformada se define como:
\[
Y_\text{t}=\mathrm{arcseno}\sqrt{Y}
\]
En R, esta transformación se implementa mediante la instrucción Yt <- asin(sqrt(Y)).
¡No es para todos los porcentajes!
Es importante notar que no todas las respuestas expresadas como porcentajes corresponden a resultados de ensayos binomiales.
Únicamente aquellas que representen la proporción de éxitos en un experimento binomial podrían requerir esta transformación (cf. sección 3.6.2).
Esta no es una transformación adecuada cuando se tienen respuestas correspondientes a contenidos porcentuales componentes de un producto (por ejemplo, porcentaje de grasa o de proteína).
Tampoco resulta adecuada para índices porcentuales construidos como razones entre dos cantidades, como \(100\times\frac{\text{peso final}}{\text{peso inicial}}\)
6.5.5 Transformación de Box-Cox
Tukey (1957) propone la familia de transformaciones de potencia (power transformations), en la que los valores transformados son una función monótona de las observaciones.
En su forma básica, la transformación de potencia consiste en elevar cada valor de la variable respuesta a una potencia \(\lambda\) distinta de cero. Cuando \(\lambda=0,\) la transformación consiste en obtener el logaritmo natural.
Esto se expresa mediante una función por partes, donde \(Y^{(\lambda)}\) denota la variable transformada:
\[
\begin{equation}
Y^{(\lambda)}=
\begin{cases}
Y^\lambda & \text{si } \lambda\ne 0,\\
\\
\\
\ln(Y) & \text{si } \lambda=0.
\end{cases}
\end{equation}
\]
La expresión anterior representa una familia de transformaciones en la que cada valor del parámetro \(\lambda\) define una transformación diferente.
Entre los miembros de esta familia quedan incluidas algunas de las transformaciones tradicionales, como la inversa, la raíz cuadrada y la logarítmica, según se ilustra en la tabla 6.6.
| \(\lambda\) | Transformación |
|---|---|
| \(−1\) | \(1/Y\) |
| \(−0.5\) | \(1/\sqrt{Y}\) |
| \(0\) | \(\ln(Y)\) |
| \(0.5\) | \(\sqrt{Y}\) |
| \(1\) | \(\text{Identidad (sin transformación)}\) |
¡Es \(\lambda\), pero nada que ver!
El uso común de la letra griega lambda (\(\lambda\)) para denotar el parámetro de la transformación de potencia y el parámetro de la distribución Poisson es meramente coincidencial.
No existe ninguna otra relación entre estos parámetros.
La figura 6.11 muestra el efecto de algunas transformaciones de potencia con valores de \(\lambda\) entre −2 y 2, al ser aplicadas sobre una variable en el rango entre 0.5 y 2.
En todos los casos, las transformaciones de potencia son funciones monótonas en su dominio. La monotonicidad es condición fundamental en cualquier transformación utilizada para estabilizar el comportamiento distribucional de los residuales.
En el contexto del ANOVA, sería inadmisible una transformación como la ilustrada en la figura 6.12, en la que observaciones distintas en la escala original terminan tomando el mismo valor en la escala transformada, diferenciándose a su vez de observaciones intermedias.
Así, por ejemplo, las observaciones con valores 1.0 y 2.0 en la escala original se transforman en el mismo valor (0.25), mientras que un valor intermedio como 1.5 da lugar a un valor transformado diferente.
Una transformación no monótona implicaría pérdida de información sobre el orden de las observaciones, lo que desvirtuaría la información muestral.
Precaución 6.1: ¡Que sean monótonas!
Las funciones utilizadas para transformar variables en el contexto del ANOVA tienen que ser monótonas.
La figura 6.11 ilustra que las transformaciones de potencia —cuando se aplican sobre el dominio de los números reales positivos— son monótonas.
Las transformaciones de potencia con valores negativos de \(\lambda\) son monótonamente descendentes (cf. figura 6.11 (a)).
Las transformaciones de potencia con valores positivos de \(\lambda\) son monótonamente ascendentes (cf. figura 6.11 (b)).
La figura 6.13 ilustra un aspecto llamativo de las transformaciones de potencia: una discontinuidad en la familia.
Los miembros de la familia con valores negativos de \(\lambda\) son monótonamente descendentes, con pendientes cada vez menores, a medida que \(\lambda\) se aproxima a cero. Análogamente, los miembros de la familia con valores positivos de \(\lambda\) son monótonamente ascendentes, con pendientes cada vez menores, a medida que \(\lambda\) se aproxima a cero.
Si la familia fuera continua en \(\lambda,\) la transformación correspondiente a \(\lambda=0\) debería ser \(Y^0=1\) y su representación gráfica debería ser intermedia entre las correspondientes a \(\lambda=-0.5\) y \(\lambda=0.5,\) es decir, que debería ser una recta con pendiente 0 e intercepto 1, como la línea punteada en tono gris35.
No obstante, cuando \(\lambda=0,\) la transformación de potencia se define de manera especial como \(Y^{(\lambda)}=\ln(Y),\) lo que hace que este miembro de la familia exhiba un comportamiento muy diferente al de los miembros vecinos, tal y como lo evidencia la curva roja de la figura 6.13.
El hecho de que la transformación de potencia para \(\lambda=0\) no conserve el patrón de las transformaciones con lambdas cercanos genera una discontinuidad en la familia.
Box y Cox (1964) introducen una adaptación que permite definir una familia de transformaciones continua respecto al parámetro \(\lambda.\)
La transformación de Box-Cox se calcula con base en la siguiente expresión, en la que \(Y^{(\lambda)}\) denota la variable transformada:
\[
\begin{equation}
Y^{(\lambda)}=
\begin{cases}
\dfrac{Y^\lambda-1}{\lambda} & \text{si } λ\ne0,\\
\\
\\
\ln(Y) & \text{si } \lambda=0.
\end{cases}
\end{equation}
\]
En la figura 6.14 se aprecia que la transformación correspondiente a \(\lambda=0\) exhibe un comportamiento coherente con el de las transformaciones asociadas a valores de \(\lambda\) cercanos, superando así la discontinuidad presente en la familia de transformaciones de potencia.
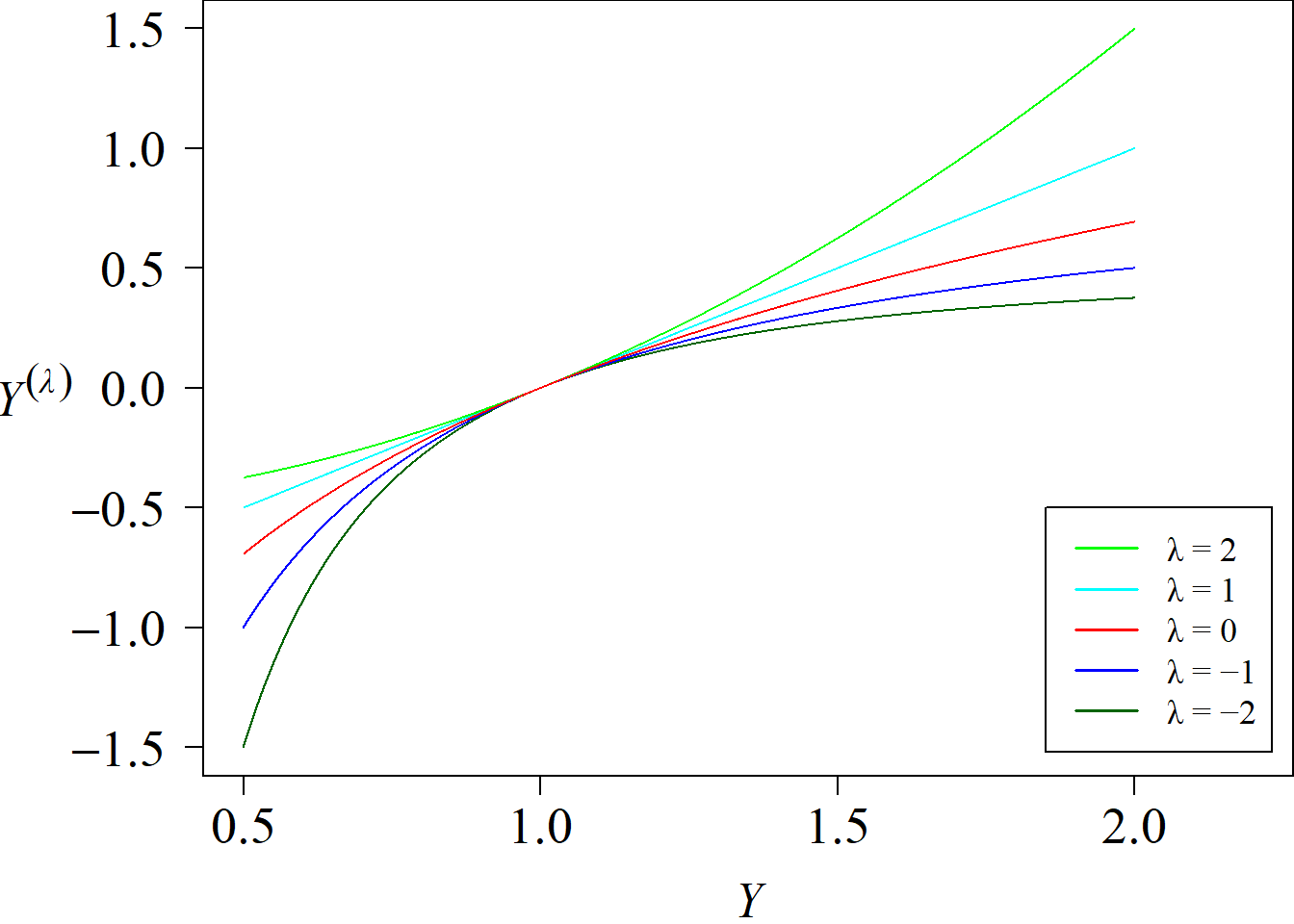
La figura 6.14 también ilustra un aspecto muy relevante: las transformaciones de la familia Box-Cox son monótonamente ascendentes para todos los valores de \(\lambda,\) sin importar su signo.
Esta característica facilita la interpretación de los datos transformados, que —en todos los casos— conservan el mismo orden de las observaciones en la escala original. En muchos casos —aunque no de manera general— este comportamiento también se refleja en las medias, de modo que el orden entre los tratamientos tiende a preservarse tras la transformación.
La propuesta de Box y Cox (1964), al igual que la de Tukey (1957), da lugar a una familia paramétrica de transformaciones, en la que cada valor del parámetro \(\lambda\) define una transformación distinta.
Esta condición le confiere gran flexibilidad a la familia. Su aplicación facilita la corrección de un amplio espectro de desviaciones de la distribución normal y de la condición de heterocedasticidad en modelos de ANOVA.
La gama de opciones que ofrece esta familia conduce naturalmente a plantearse el criterio de optimalidad de una transformación y la manera de encontrar el miembro específico que lo satisfaga.
Uno de los criterios más utilizados —aunque no el único— consiste en seleccionar el valor de \(\lambda\) que haga que los residuales del modelo ajustado con la variable transformada se aproximen lo más posible a una distribución normal.
Cada valor de \(\lambda\) da lugar a un conjunto de residuales. Es posible calcular la probabilidad de que una distribución normal genere una muestra con esos valores. Se selecciona el \(\lambda\) que produce el conjunto de residuales con mayor probabilidad.
La probabilidad que se busca maximizar se calcula con base en una función de probabilidad conjunta, denominada función de verosimilitud o simplemente verosimilitud. Por esta razón, el criterio basado en maximizar la verosimilitud se le denomina de máxima verosimilitud (maximum likelihood).
Aunque realmente…
En la práctica, es más sencillo maximizar el logaritmo de la función de verosimilitud que la función original.
Por la propiedad de los logaritmos que establece que \(\log(A\cdot B)=\log(A)+\log(B),\) el producto de las funciones de probabilidad individuales (la función de verosimilitud) se transforma en una suma, lo que simplifica considerablemente los cálculos.
Dado que el logaritmo es una transformación monótonamente creciente, el valor de \(\lambda\) que maximiza la función de log-verosimilitud es el mismo que maximiza la verosimilitud.
Es por esto que la log-verosimilitud es la que aparece en los procedimientos de cálculo, pero el método se denomina de máxima verosimilitud.
Obtención del \(\lambda\) óptimo
El lambda óptimo para un modelo determinado es el que maximiza la función de verosimilitud normal para los residuales provenientes de un modelo ajustado con base en la variable transformada.
En la búsqueda del \(\lambda\) óptimo, el reescalamiento introducido por la transformación impide comparar directamente los modelos, ya que que cada valor de \(\lambda\) da lugar a una escala diferente de la variable respuesta. No obstante, este inconveniente puede superarse mediante el uso de una versión estandarizada de la transformación de Box-Cox, que incorpora la media geométrica, definida como:
\[
G(Y)=\left(\prod\limits_{i=1}^n{Y_i}\right)^{1/n}
\]
En estas condiciones de escala común, y bajo el supuesto de normalidad, seleccionar el valor óptimo de \(\lambda\) también equivale a elegir el modelo con menor variabilidad residual.
La versión estandarizada de la transformación de Box-Cox queda definida así:
\[
\begin{equation}
Y^{(\lambda)}=
\begin{cases}
\dfrac{Y^\lambda-1}{\lambda\left(G(Y)\right)^{\lambda-1}} & \text{si } λ\ne0,\\
\\
\\
G(Y)\ln(Y) & \text{si } \lambda=0.
\end{cases}
\end{equation}
\]
Puesto que la transformación de Box-Cox para \(\lambda=0\) es el logaritmo natural, es necesario que todos los valores de la variable sean mayores de cero, para evitar indeterminaciones en su evaluación. Si la muestra no satisface esta condición, se introduce un parámetro de desplazamiento, \(\lambda_2,\) que permite trasladar los datos al dominio de los valores positivos.
¡Inclúyalo!
Cuando la muestra contiene ceros o valores negativos, es obligatorio incorporar el parámetro de desplazamiento \(\lambda_2\), aun si el \(\lambda\) óptimo es diferente de cero, puesto que el algoritmo de optimización evalúa el modelo en un rango de valores de \(\lambda\) que incluye el caso \(\lambda=0.\)
Aunque también podría ser…
Yeo y Johnson (2000) proponen un enfoque alternativo —mediante definiciones específicas para los casos que problemáticos— que permite trabajar directamente con variables que incluyen valores cero o negativos sin necesidad de introducir un parámetro de desplazamiento.
No obstante, en este capítulo se ha optado por mantener el uso de la transformación de Box-Cox con desplazamiento, por su mayor simplicidad conceptual y su estrecha conexión con las transformaciones clásicas previamente discutidas.
La versión de la transformación de Box-Cox con parámetro de desplazamiento, \(\lambda_2,\) se define como:
\[
\begin{equation}
Y^{(\lambda)}=
\begin{cases}
\dfrac{(Y+\lambda_2)^\lambda-1}{\lambda} & \text{si } λ\ne0,\\
\\
\\
\ln(Y+\lambda_2) & \text{si } \lambda=0.
\end{cases}
\end{equation}
\]
La forma más general de la transformación de Box-Cox —que incluye la media geométrica y el parámetro de desplazamiento— se expresa así:
\[
\begin{equation}
Y^{(\lambda)}=
\begin{cases}
\dfrac{(Y+\lambda_2)^\lambda-1}{\lambda\left(G(Y+\lambda_2)\right)^{\lambda-1}} & \text{si } λ\ne0,\\
\\
\\
G(Y+\lambda_2)\ln(Y+\lambda_2) & \text{si } \lambda=0.
\end{cases}
\end{equation}
\]
En R, la función boxcox{MASS} facilita obtener el valor de \(\lambda\) que maximiza la verosimilitud normal de los residuales de un modelo dado.
El argumento principal de esta función es un modelo o una fórmula. Por defecto, la función evalúa valores de \(\lambda\) entre −2 y 2, con incrementos de 0.1, y presenta el perfil de las log-verosimilitudes junto con un intervalo de confianza del 95 % para \(\lambda.\)
Supóngase que, tras haber ajustado en R un modelo de ANOVA de una vía y haberlo guardado con el nombre modelo, se detecta que no se satisfacen los supuestos.
La búsqueda del \(\lambda\) óptimo36, mediante la función boxcox se realiza así:
library(MASS)
boxcox(modelo)Al ejecutar la función boxcox con sus valores por defecto, el resultado visible es el gráfico del perfil de las log-verosimilitudes para valores de \(\lambda\) entre −2 y 2, tal y como se ilustra en la figura 6.15.
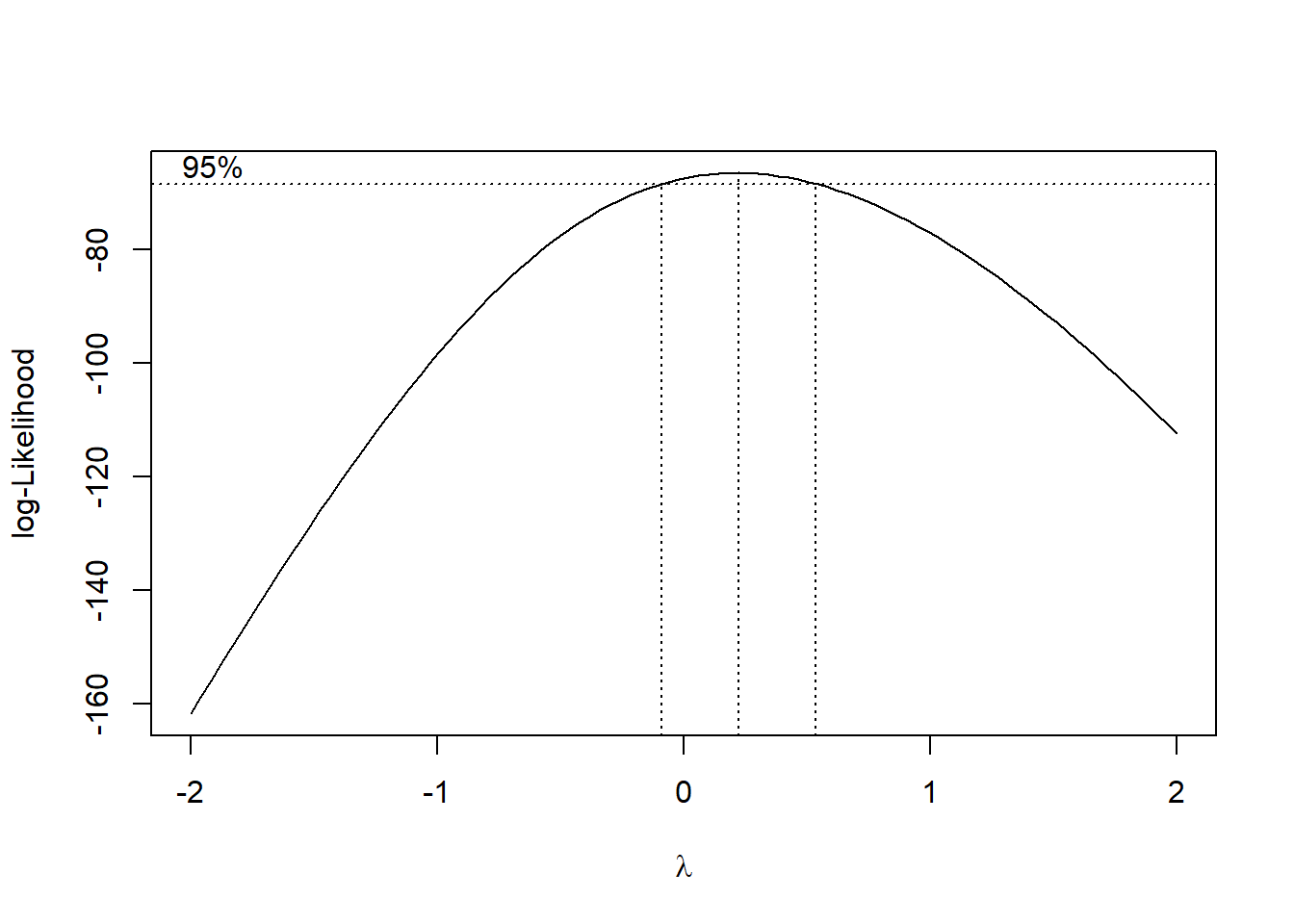
Aunque en muchas ocasiones —como en el presente ejemplo— el valor óptimo de \(\lambda\) se encuentra dentro del intervalo entre −2 y 2, puede ser necesario explorar otras regiones, mediante el argumento lambda37.
La figura 6.15 muestra que el valor de \(\lambda\) que maximiza la log-verosimilitud está cercano a 0.2, con un intervalo de confianza del 95 % entre −0.1 y 0.6 aproximadamente.
A la luz de este resultado, bien podrían ensayarse algunas transformaciones comunes correspondientes a los lambdas en el intervalo de confianza.
En este caso, podría ensayarse la transformación logarítmica \((\lambda = 0),\) así como la transformación raíz cuadrada \((\lambda = 0.5)\) (cf. tabla 6.6).
Igualmente, podrían usarse las siguientes instrucciones para obtener el valor exacto del \(\lambda\) que maximiza la log-verosimilitud.
bc <- boxcox(modelo, lambda = seq(-2, 2, 0.01), plotit = F)
bc$x[which.max(bc$y)][1] 0.21Aunque la transformación de Box-Cox es en apariencia muy diferente de la transformación de potencia, estas se encuentran estrechamente relacionadas.
En su forma básica, la transformación de Box-Cox puede escribirse así:
\[
\frac{Y^\lambda-1}{\lambda}=\frac{1}{\lambda}\;Y^\lambda-\frac{1}{\lambda}
\]
Dado que \(\frac{1}{\lambda}\) es una constante, esta expresión muestra que la transformación de Box-Cox es una transformación lineal de la transformación de potencia, lo cual tiene implicaciones profundas.
Puesto que el análisis de varianza es invariante a transformaciones lineales de la variable respuesta, la transformación de Box-Cox es inferencialmente equivalente a la transformación de potencia.
En términos de significancia, esto implica que se obtienen exactamente los mismos resultados al aplicar una u otra transformación con un \(\lambda\) dado.
Teniendo en cuenta lo anterior, bien podría utilizarse el procedimiento implementado en la función boxcox para estimar el \(\lambda\) óptimo y aplicar posteriormente la correspondiente transformación de potencia, esto es, elevar los valores de la variable respuesta al \(\lambda\) obtenido.
Esto explica por qué en el anterior ejemplo, a pesar de haber obtenido el valor de \(\lambda\) en el marco de la transformación Box-Cox, se mencionó la posibilidad de ensayar las transformaciones logarítmica y raíz cuadrada. Las equivalencias presentadas en la tabla 6.6 también son aplicables para las transformaciones de la familia Box-Cox.
¡Pero cuidado!
Es importante considerar que —para valores positivos de la variable respuesta— la transformación de Box-Cox es monótonamente creciente, sin importar el valor ni el signo de \(\lambda.\) Esto asegura la preservación del orden de las observaciones y en muchas ocasiones de medidas de los diferentes grupos comparados, lo que facilita la interpretación de los resultados.
En contraste, para el mismo rango de valores de \(Y,\) la transformación de potencia es monótonamente decreciente para valores negativos de \(\lambda,\) con lo cual se invierte el orden de las medias transformadas en relación con las medias originales, lo que puede generar confusión en las interpretaciones.
La validez estadística de cualquier transformación monótona —sea creciente o decreciente— es incuestionable. El único riesgo de las transformaciones monótonamente decrecientes es interpretativo. Considerando, sin embargo, que este no es un riesgo menor, se recomienda aplicar en casi todos los casos la transformación de Box-Cox.
En aras de la sencillez, en los casos en los que el \(\lambda\) óptimo sea cercano a 0.5, bien podría ensayarse la transformación raíz cuadrada. Asimismo, cuando el valor óptimo de \(\lambda\) esté cercano a cero, podría ensayarse la transformación logarítmica.
También podría considerarse la aplicación de la transformación inversa, \((1/Y),\) en situaciones en las que los valores transformados puedan interpretarse como tasas de mortalidad, tal y como lo ilustran Box y Cox (1964) en el primero de los dos ejemplos detallados en su artículo.
6.5.6 Transformación de Box-Cox vs. transformaciones predeterminadas
La razón de ser de algunas de las transformaciones clásicas, con sus recomendaciones de uso, estaba asociada con las dificultades operativas que entrañaba la realización de un análisis de varianza y de sus pruebas anexas.
Puesto que la evaluación de una transformación exigía aplicarla, volver a realizar el análisis de varianza, extraer los residuales y realizar las correspondientes verificaciones, el investigador no podía darse el lujo de realizar muchos ensayos.
En dicho contexto, resultaba estratégico tener un conjunto pequeño de transformaciones y empezar aplicando la que solía exhibir un buen desempeño en circunstancias similares. A menudo tales transformaciones se aplicaban incluso antes del primer análisis como medida preventiva.
Hoy en día no existe tal restricción, por lo que resulta poco justificado limitarse a evaluar transformaciones puntuales, cuando es posible analizar simultáneamente el comportamiento de todos los miembros de la familia Box-Cox.
La única excepción, en lo que respecta a las transformaciones clásicas, es la transformación angular, que no forma parte de la familia Box-Cox y que podría resultar útil cuando se evalúan resultados provenientes de experimentos binomiales (cf. sección 6.5.4).
6.5.7 Presentación de datos cuando se ha usado alguna transformación
El investigador suele dudar sobre la manera adecuada de presentar los análisis cuando ha aplicado algún tipo de transformación a sus datos. ¿Debe presentar la información en la escala original, en la escala transformada o en alguna otra escala?
Aunque algunos autores recomiendan transformaciones inversas, o destransformaciones para expresar las medias de los grupos en una escala equivalente a la original, este procedimiento debe interpretarse con cautela, ya que la transformación inicial se aplica sobre cada uno de los datos, mientras que la destransformación se aplica sobre promedios, lo que da lugar a valores que no corresponden ni a la escala original ni a la transformada.
Dejando de lado esta opción, que podría aportar más confusión que información, se consideran únicamente la escala original y la transformada.
El uso de una u otra escala depende del propósito: inferencia o descripción. Todas las técnicas inferenciales —ANOVA, intervalos de confianza y procedimientos de comparación múltiple, entre otras— deben basarse en los datos transformados, que son los que satisfacen los supuestos de las correspondientes técnicas (esto habrá que verificarlo).
Si la información se presenta con fines meramente descriptivos, pueden usarse los datos originales.
Si en los resultados se presenta, por ejemplo, una tabla de medias que incluya letras o símbolos que indiquen diferencias significativas o grupos homogéneos, dichas medias deben calcularse a partir de los datos transformados, de modo que sean coherentes con el procedimiento aplicado.
No obstante, una media basada en datos transformados puede resultar poco informativa para el lector —e incluso para el propio investigador—. Por ello, cuando el objetivo es describir la localización y la magnitud de las diferencias entre grupos, pueden presentarse las medias basadas en la escala original, sin hacer referencia a significancia estadística38.
Los resultados pueden incluir, por tanto, las medias basadas en los datos transformados (para inferencia), las medias basadas en los datos originales (para descripción) o ambas, cada una para el propósito que le corresponde.
Cuando en un estudio en el que se haya aplicado alguna transformación se muestren las medias en escala original, deberá indicarse explícitamente que todas las técnicas inferenciales se basan en los datos transformados y que las medias de los datos originales se presentan únicamente con fines ilustrativos.
Los intervalos de confianza —al ser herramientas netamente inferenciales39— deben construirse con base en los datos transformados.
Puesto que un intervalo de confianza basado en datos transformados puede ser tan poco ilustrativo como lo son las medias que se calculan con los datos transformados y que la función inferencial de tales intervalos podría satisfacerse a través de pruebas de hipótesis, el investigador debería reconsiderar su inclusión.
6.6 Evaluación del modelo en R
En este capítulo se han presentado varias funciones en R para evaluar supuestos y para buscar soluciones mediante transformaciones:
shapiro.test{stats}para la evaluación de la normalidad de los residuales.leveneTest{car}para la evaluación de homocedasticidad.boxcox{MASS}para la obtención del \(\lambda\) óptimo dentro de la familia de transformaciones de Box-Cox, usando el criterio de máxima verosimilitud.
Hasta este punto, se han presentado herramientas para evaluar supuestos y diferentes alternativas de transformación. No obstante, en la práctica resulta deseable integrar estos elementos en un único procedimiento que permita evaluar el modelo y explorar soluciones de manera conjunta.
Mejor use
check_model
Recomendamos el uso de la función personalizada check_model que —además de integrar funciones de diagnóstico y transformación— proporciona una guía para el análisis de una variable particular dentro de un modelo dado de ANOVA.
La función check_model implementa la evaluación de la normalidad de los residuales del modelo mediante la prueba de Shapiro-Wilk (cf. sección 6.3.2). Internamente emplea la función shapiro.test{stats}.
Para el supuesto de homocedasticidad, implementa la prueba generalizada de Levene propuesta por O’Neill y Mathews (2002) (cf. sección 7.2.2).
Aunque esta propuesta calcula un valor p para cada efecto, la tabla resumen generada por check_model presenta el mínimo de tales valores, lo cual constituye una guía adecuada para la toma de decisiones.
6.6.1 Resultados de check_model
La función check_model presenta una tabla resumen en la que aparecen los valores p de las pruebas de normalidad y homocedasticidad para distintos escenarios: el modelo basado en la variable respuesta en su escala original \((\text{tr0})\) y modelos alternativos basados en diferentes transformaciones de la variable respuesta (\(\text{tr1}\) a \(\text{tr6}\)).
La tabla 6.7 resume los escenarios evaluados.
check_model
| Etiqueta | Transformación |
|---|---|
| tr0 | \(Y_\text{t}=Y\) |
| tr1 | \(Y_\text{t}=\ln(Y)\) |
| tr2 | \(Y_\text{t}=\ln(Y+c)\) |
| tr3 | \(Y_\text{t}=\dfrac{Y^{\lambda}-1}{\lambda}\) |
| tr4 | \(Y_\text{t}=\dfrac{(Y+c)^{\lambda}-1}{\lambda}\) |
| tr5 | \(Y_\text{t}=\dfrac{(Y+c)^{\lambda}-1}{\lambda}\) |
| tr6 | \(Y_\text{t}=\mathrm{arcsen}\sqrt{Y}\) |
A continuación se analizan los diferente escenarios resumidos en la tabla 6.7.
tr0: Representa la variable sin transformar40. Los valores p que aparecen en esta fila se emplean para valorar desviaciones de los supuestos en el modelo original.
tr1: Esta es la transformación logarítmica tradicional sin incluir ninguna constante de desplazamiento (cf. sección 6.5.1). Únicamente se aplica cuando todos los valores de la variable respuesta son mayores que cero. De no satisfacerse esta condición, las celdas de la correspondiente fila en la tabla resumen aparecen con NA y se muestra una advertencia.
tr2: La transformación logarítmica incluye una constante de desplazamiento, \(c,\) análoga a la propuesta por Berry (1987). A diferencia del criterio de optimalidad propuesto por este autor, que se basa en la búsqueda de una constante que permita minimizar la suma de los valores absolutos de los coeficientes de asimetría y curtosis (cf. sección 6.5.1), la función check_model define la maximización del estadístico \(W\) de la prueba de Shapiro-Wilk41 como criterio de optimalidad, lo que favorece una búsqueda más integral de la normalidad.
Esta transformación es aplicable en todos los casos, sin importar si la variable contiene valores menores o iguales a cero. La función check_model realiza un desplazamiento inicial —sin intervención del usuario— para asegurar que no se presenten indeterminaciones. El valor de la constante \(c\) que aparece en el resumen recoge el desplazamiento inicial que pudiera haberse requerido. Este es el valor de \(c\) que el usuario debería utilizar si optara por esta transformación.
De manera opcional, la función check_model genera un gráfico con los valores de la constante \(c\) en la abscisa y con dos ordenadas: la de la izquierda con los valores p de la prueba de Shapiro-Wilk, y la de la derecha con sus correspondientes estadísticos \(W.\) Este gráfico permite visualizar el efecto de esta constante de desplazamiento.
Cuando los valores p de 0.01 y 0.05 quedan incluidos en el rango graficado, estos se señalan con líneas punteadas horizontales.
El gráfico siempre incluye un círculo rojo (\(\textcolor{red}{\bullet}\)), mediante el cual se señala el valor p (y el estadístico \(W\)) de la prueba de Shapiro-Wilk para la variable sin transformar.
Asimismo, incluye un cero azul (\(\textcolor{blue}{0}\)), correspondiente a la transformación logarítmica sin suma de constante \((\ln(Y+0)),\) cuando esta transformación sea viable. De igual manera, el gráfico incluye una línea vertical gris que pasa por \(c=0.\)
La curva continua negra muestra el cambio del valor p y del estadístico \(W\) de la prueba Shapiro-Wilk, en función de \(c.\) Un gráfico creciente que alcanza su máximo cuando \(c=100\) estaría indicando que no se requiere esta transformación42.
tr3: En este caso se obtiene el parámetro \(\lambda\) de la transformación de Box-Cox, con base en el criterio de máxima verosimilitud, usando la misma lógica algorítmica de boxcox{MASS}.
Al final de la sección 6.5.5 se mostró que —en términos de significancia— la transformación de Box-Cox para un \(\lambda\) dado es equivalente a la transformación de potencia para el mismo valor de \(\lambda\) (cf. Box-Cox vs. potencia).
Teniendo en cuenta lo anterior, la tabla resumen de check_model presenta la expresión de la transformación de potencia por ser más compacta. Así, por ejemplo, si en la tabla resumen correspondiente \(\text{tr3}\) aparece (Y) ^ -0.7, el usuario debe interpretar que \(\lambda=-0.7\) es el valor óptimo de esta parámetro tanto para la transformación de potencia como para la de Box-Cox.
Para el caso particular de los datos que hubieran dado lugar a esta salida, si el usuario prefiriera una transformación monótonamente creciente, aplicaría Box-Cox:
\[
Y_\text{t}=\frac{\left(Y^{-0.7}-1\right)}{-0.7}
\]
La transformación \(\text{tr3}\) se evalúa siempre que sea viable, es decir, si todos los valores de \(Y\) son mayores que cero.
tr4: Al igual que para \(\text{tr3}\), se obtiene el valor óptimo de \(\lambda\) con base en el criterio de máxima verosimilitud, aplicando la misma lógica algorítmica de boxcox{MASS}. En este caso adicionalmente se incluye un parámetro de desplazamiento.
En la sección 6.5.5 se mencionó el parámetro de desplazamiento \(\lambda_2\) como necesidad operativa para evitar indeterminaciones al evaluar el logaritmo de valores menores o iguales que cero, pero no se discutió cómo elegir su valor ni el efecto que podría tener su inclusión.
Acorde con Berry (1987), la elección de una constante de desplazamiento no es una cuestión trivial: debe elegirse de manera que propicie la mejor convergencia hacia la distribución normal.
¿\(\lambda_2\) o \(c\)?
Podría parece que se están mezclando dos conceptos diferentes. Sin embargo, la diferencia es únicamente de notación.
El parámetro de desplazamiento \(\lambda_2\) de la transformación de Box-Cox es equivalente a la constante de desplazamiento \(c\) de Berry (1987).
La transformación \(\text{tr4}\) incluye el parámetro de desplazamiento óptimo obtenido para \(\text{tr2}\) y genera el \(\lambda\) óptimo por máxima verosimilitud.
Al igual que en \(\text{tr3}\), el \(\lambda\) obtenido es el óptimo para la transformación de potencia y para la transformación de Box-Cox.
tr5: Partiendo de los valores óptimos obtenidos en \(\text{tr4}\) (\(\lambda\) y \(c\)), se realiza un proceso de optimización simultánea, en búsqueda de los valores que maximicen el estadístico \(W\) de la prueba Shapiro-Wilk.
tr6: Esta transformación no se calcula por defecto; únicamente, cuando se establece el argumento ang = TRUE. Para usar esta transformación, la variable respuesta \(Y\) debe ser una proporción en el rango entre 0 y 1.
A continuación se muestra una salida típica de la función check_model:
Resumen de modelos
transformación p (S-W) p (Levene) monótona
tr0: Brix 0.0110593 1.800e-03 sí
tr1: log(Brix) 0.0004862 2.398e-10 sí
tr2: log(Brix + 10.68) 0.2166309 2.456e-04 sí
tr3: (Brix) ^ 0.8 0.0621825 7.900e-04 sí
tr4: (Brix + 10.68) ^ 0.4 0.0870375 5.250e-04 sí
tr5: (Brix + 93.9) ^ -5 0.2297384 1.642e-04 síEn la primera columna aparece la etiqueta que identifica cada transformación.
En la segunda columna aparecen los valores de los parámetros \(c\) y \(\lambda\) que correspondan a las transformaciones evaluadas. Así, por ejemplo, el \(c\) para \(\text{tr2}\) es 10.68; el \(\lambda\) para la transformación de potencia o de Box-Cox, sin parámetro de desplazamiento es 0.8.
En la columna p (S-W) se presenta el valor p de la prueba de Shapiro-Wilk sobre los residuales del modelo.
En la columna p (Levene) se presenta el valor p de la correspondiente prueba de Levene.
La última columna muestra una etiqueta que indica si la transformación es monótona para el conjunto de datos evaluado.
Cualquier transformación que pretenda usarse deberá satisfacer el criterio de monotonicidad. De no ser así, deberá dejarse fuera de consideración (cf. precuación 6.1).
La figura 6.16 ilustra el comportamiento de la transformación logarítmica para valores de \(c\) en el rango entre 0 y 100.
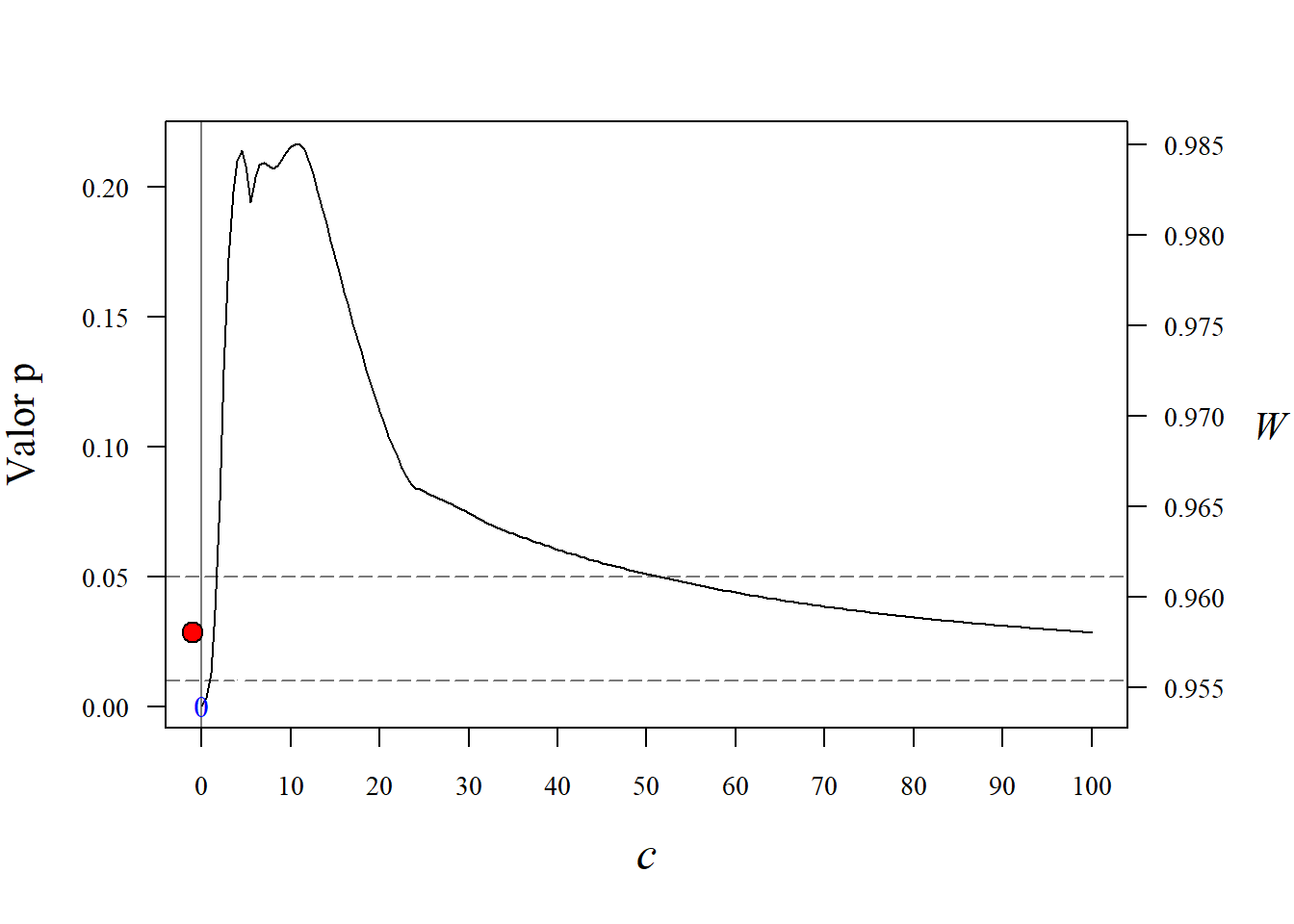
Criterios
La búsqueda de los parámetros óptimos está basada en diferentes criterios:
En \(\text{tr2}\) se busca la constante \(c\) que maximice el estadístico \(W\) de la prueba de Shapiro-Wilk.
En \(\text{tr3}\) se obtiene el parámetro \(\lambda\) con base en el criterio de máxima verosimilitud.
En \(\text{tr4}\) se maneja un criterio híbrido: se incorpora la constante \(c\) que se obtuvo con base en la maximización del estadístico \(W\) de la prueba de Shapiro-Wilk y luego se obtiene el parámetro \(\lambda\) con base en el criterio de máxima verosimilitud.
En \(\text{tr5}\) se realiza la búsqueda simultánea de los parámetros con base en la maximización del estadístico \(W\) de la prueba de Shapiro-Wilk.
Es importante resaltar que, aunque el criterio de optimización está enfocado en todos los casos en la convergencia hacia la distribución normal, estas transformaciones también suelen contribuir a corregir problemas de heterocedasticidad.
6.6.2 Uso de check_model
Se recomienda emplear la función check_model de manera rutinaria para evaluar supuestos en modelos de ANOVA.
Si los valores p de las pruebas de Shapiro-Wilk y Levene en \(\text{tr0}\) no sugieren desviaciones severas de los supuestos, es preferible mantener la escala original, por facilitar la interpretación de los resultados.
Si se detectan desviaciones severas en uno o ambos los supuestos, las demás entradas de la tabla proporcionan una guía de posibles transformaciones.
¡Tómelas como guía!
Teniendo presente que no existe una mejor transformación en términos absolutos, no necesariamente debe elegirse aquella que proporcione los valores p más altos.
Una transformación sencilla que permita corregir desviaciones fuertes de los supuestos puede ser preferible a una más compleja, especialmente cuando facilita la interpretación de los resultados.
En este sentido, la función check_model no debe entenderse como un mecanismo automático de selección de transformaciones, sino como una herramienta de apoyo para la toma de decisiones informadas.
Su uso permite evaluar de manera integrada los supuestos del modelo y explorar alternativas, sin perder de vista que la elección final debe equilibrar el cumplimiento de los supuestos, la simplicidad de la transformación y la interpretabilidad de los resultados.
En última instancia, el propósito de las transformaciones no es optimizar valores p, sino facilitar un análisis válido y comprensible de los datos.
Referencias bibliográficas
Arnastauskaitė, J., Ruzgas, T. and Bražėnas, M. (2021). An Exhaustive Power Comparison of Normality Tests. Mathematics, 9(7), 788. https://doi.org/10.3390/math9070788
Berry, D. A. (1987). Logarithmic transformation in ANOVA. Biometrics, 43(2), 439-456.
Blanca, M. J., Alarcón R., Arnau J., Bono R. and Bendayan R. (2017). Non-normal data: Is ANOVA still a valid option? Psicothema, 29(4), 552-557. https://doi.org/10.7334/psicothema2016.383
Box, G. E. P. y Cox, D. R. (1964). An analysis of transformations. Journal of the Royal Statistical Society. Series B (Methodological), 26(2), 211-252.
Brown, M. B. and Forsythe, A. B. (1974). Robust tests for the equality of variances. Journal of The American Statistical Association, 69(346), 364-367.
Conover, W. J., Johnson, M. E. and Johnson, M. M. (1981). A comparative study of tests for homogeneity of variances, with applications to the outer continental shelf bidding data. Technometrics, 23(4), 351-361.
Faria Filho, D. E., Dias, A. N., Veloso, A. L. C., Bueno, C. F. D., Couto, F. A. P., Matos Júnior, J. B., Barreto, K. Z. O., Rodrigues, P. A., Carneiro, W. A. (2010). Classification of coefficients of variation in experiments with commercial layers. Brazilian Journal of Poultry Science, 12(4), 255-257.
Hurlbert, S. H. (1984). Pseudoreplication and the design of ecological field experiments. Ecological Monographs, 54(2), 187-211. https://doi.org/10.2307/1942661
Kamath, A., Poojari, S. and Varsha, K. (2025). Assessing the robustness of normality tests under varying skewness and kurtosis: a practical checklist for public health researcherss. BMC Medical Research Methodology, 25(1), 206. https://doi.org/10.1186/s12874-025-02641-y
Khan, A. and Rayner, G. D. (2003). Robustness to non-normality of common tests for the many-sample location problem. Journal of Applied Mathematics and Decision Sciences, 7(4), 187-206.
Knief, U. and Forstmeier, W. (2021). Violating the normality assumption may be the lesser of two evils. Behavior Research Methods, 53(6), 2576-2590. https://doi.org/10.3758/s13428-021-01587-5
Letelier S., L. M., Manríquez M., J. J. y Claro G., J. C. (2004). El ciego en los ensayos clínicos ¿Importa? Revista Médica de Chile, 132(9), 1137-1139. https://dx.doi.org/10.4067/S0034-98872004000900016
Mead, R., Gilmour, S. G. y Mead, A. (2012). Statistical principles for the design of experiments. Cambridge.
Mendes, M. and Pala, A. (2003). Type I error rate and power of three normality tests. Pakistan Journal of Information and Technology, 2(2), 135-139.
Milliken, G. A. and Johnson, D. E. (2009). Analysis of messy data. Volume 1: Designed experiments. Chapman; Hall/CRC.
Mohd Razali, N. and Yap, B. (2011). Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. Journal of Statistical Modeling and Analytics, 2(1), 21-33.
Muñoz Duque, S. E., García González, J. J., Correa Londoño, G., Atencio García V. J., Pardo Carrasco, S. C. (2012). Efectos del perifiton sobre los parámetros fisicoquímicos del agua en estanques con policultivo de tilapia Oreochromis niloticus y Bocachico Prochilodus magdalenae. Revista Lasallista de Investigación, 9(1), 41-52.
O’Neill, M. E. and Mathews, K. L. (2002). Levene Tests of Homogeneity of Variance for General Block and Treatment Designs. Biometrics, 58(1), 216-224. https://doi.org/10.1111/j.0006-341X.2002.00216.x
Patel, J. K., Patel, N. M. y Shiyani, R. L. (2001). Coefficient of variation in field experiments and yardstick thereof - An empirical study. Current Science, 81(9), 1163-1164.
Pearson, E. S. (1931). The analysis of variance in cases of non-normal variation. Biometrika, 23(1/2), 114-133.
Petersen, R. G. (1994). Agricultural Field Experiments: Design and analysis. Marcel Dekker.
Royston, J. P. (1995). Remark AS R94: A remark on algorithm AS 181: the W-test for normality. Journal of the Royal Statistical Society: Series C (Applied Statistics), 44(4), 547-551. https://doi.org/10.2307/2986146
Scariano, S. M. and Davenport, J. M. (1987). The effects of violations of independence assumptions in the One-Way ANOVA. The American Statistician, 41(2), 123-129.
Schmider, E., Ziegler, M., Danay, E., Beyer, L. and Bühner, M. (2010). Is it really robust? Methodology, 6(4), 147-151. https://doi.org/10.1027/1614-2241/a000016
Shadish, W. R., Cook, T. D. and Campbell, D. T. (2002). Experimental and Quasi-Experimental Designs for Generalized Causal Inference. Houghton Mifflin.
Sokal, R. R. y Rohlf, F. J. (1969). Biometría: Principios y Métodos Estadísticos en la Investigación Biológica. Blume.
Suescún, D., Villegas, J. C., León, J. D., Flórez, C. P., García-Leoz, V., Correa-Londoño, G. A. (2017). Vegetation cover and rainfall seasonality impact nutrient loss via runoff and erosion in the Colombian Andes. Regional Environmental Change, 17(3), 827-839. https://doi.org/10.1007/s10113-016-1071-7
Tukey, J. W. (1957). On the comparative anatomy of transformations. The Annals of Mathematical Statistics, 28(3), 602-632. https://doi.org/10.1214/aoms/1177706875
Welch, B. L. (1951). On the comparison of several mean values: an alternative approach. Biometrika, 38(3/4), 330-336. https://doi.org/10.1093/biomet/38.3-4.330
Yap, B. W. and Sim, C. H. (2011). Comparison of various types of normality tests. Journal of Statistical Computation and Simulation, 81(12), 2141-2155. https://doi.org/10.1080/00949655.2010.520163
Yeo, In-Kwon and Johnson, R. A. (2000). A new family of power transformations to improve normality or symmetry. Biometrika, 87(4), 954-959. https://doi.org/10.1093/biomet/87.4.954
Zar, J. H. (1984). Biostatistical Analysis. Prentice Hall.
En sentido amplio, es decir, simple ciego, doble ciego o triple ciego.↩︎
Para el caso de poblaciones finitas suele contarse incluso con un marco muestral, es decir, con una lista completa de las unidades que conforman la población objetivo.↩︎
El tipo de conglomeración de efectos al que aquí se hace referencia difiere del obtenido mediante la combinación de niveles de varios factores que se describe en el capítulo 10, donde sí es posible separar los efectos de cada factor.↩︎
En ocasiones se le denomina “control del agricultor”.↩︎
Si \(X \thicksim\text{Poisson} (λ)\), \(E(X) = λ\), \(Var(X) = λ.\)↩︎
También suele describirse como muestreo de las unidades experimentales.↩︎
Lógicamente, cuando se usa esta estrategia para propiciar la convergencia de la respuesta a la distribución normal, en virtud del teorema central del límite, deberán evaluarse todos los elementos.↩︎
El gradiente podría ir en cualquier otra dirección.↩︎
Una variación sistemática, en contraste con una variación aleatoria, es la que sigue un patrón determinado. Por ejemplo, que todos los errores sean por exceso y que estos sean cada vez mayores con el paso del tiempo.↩︎
Algunos autores los denominan experimentos naturales o experimentos con factores no manipulables.↩︎
Un arreglo sistemático consiste en intercalar los tratamientos ordenadamente, siguiendo siempre el mismo patrón, de manera análoga al intercalamiento de las casillas negras y blancas en un tablero de ajedrez.↩︎
Desde un punto de vista práctico, es más útil saber que el alfa nominal elegido representa un límite superior probable para el nivel de significancia del ensayo. Esto es lo que se logra al elegir arreglos intercalados.↩︎
se recomienda la mediana.↩︎
En ocasiones también debe considerarse en camas de cultivo, en bandejas, etc.↩︎
En los contextos de inferencia básica que involucran uno o dos parámetros, se habla de tamaño de la muestra (cf. secciones 4.2.4, 4.4.5 y 5.3.1.4.1).↩︎
El error experimental estima la varianza dentro de los tratamientos; su raíz cuadrada estima la desviación estándar.↩︎
Excepto en el análisis de medidas repetidas, donde el tiempo entra como un factor adicional a tratamientos, generando una estructura factorial.↩︎
Acorde con las definiciones de población de campo y población teórica que se presentaron en la sección 3.9.↩︎
Conjunto de variables aleatorias igual e independientemente distribuidas (cf. sección 3.9).↩︎
Aunque en el presente esquema se ilustran tres tratamientos, este es válido para cualquier número, \(k\), de tratamientos.↩︎
Que se obtiene como una combinación lineal de las variables.↩︎
Los grados de libertad que se utilizan en el denominador no corresponden al número de distancias.↩︎
Hay distribuciones, como la Poisson y la ji cuadrado, donde la media y la varianza no son independientes.↩︎
Si la hipótesis nula es cierta, el estadístico de prueba es la razón entre dos variables aleatorias ji cuadrado, dividiendo cada una de ellas entre sus grados de libertad, lo cual da lugar a una distribución \(F\) (cf. expresión 3.9).↩︎
Una normal estándar elevada al cuadrado (cf. sección 3.7.2).↩︎
Igual e independientemente distribuida.↩︎
Aunque existen varias denominadas “pruebas de independencia”, siendo la basada en la ji cuadrado la más popular de ellas (cf. sección 5.4.1), estas no aplican al presente contexto.↩︎
Aunque a nivel poblacional sí serían cognoscibles.↩︎
\(n-1\) es el denominador requerido para que \(S^2\) sea un estimador insesgado de \(\sigma^2\) (cf. sección 3.9.1.1.2).↩︎
La hipótesis nula plantea que la variabilidad entre tratamientos, \(\sigma^2_{\text{ttos}},\) es menor o igual que la variabilidad dentro de tratamientos, \(\sigma^2_{\text{error}}.\) Para la situación de igualdad —que es la que define el nivel de significancia de la prueba— \(\sigma^2_{\text{ttos}}=\sigma^2_{\text{error}}=\sigma^2.\)↩︎
Logaritmo negativo de la concentración de iones de hidrógeno.↩︎
\(V(Y) \propto \mu^2\)↩︎
\(\log(0)=-\infty\).↩︎
A nivel teórico, se trata de realizaciones de una distribución Poisson, en la que \(V(Y)=E(Y)=\lambda.\)↩︎
Aunque esto sería necesario para la continuidad de la familia, no sería deseable para los fines buscados, dado que —sin importar el valor en la escala original— cualquier valor transformado sería igual a uno.↩︎
El que maximiza la verosimilitud normal.↩︎
Para evaluar, por ejemplo, valores de \(\lambda\) en la región entre −1 y 5, se usaría la instrucción
boxcox(modelo, lambda = seq(-1, 5, 0.1)).↩︎Sin incluir letras, ni asteriscos.↩︎
Los intervalos de confianza no cumplen la función descriptiva que sí pueden cumplir las medias,↩︎
En el contexto de la familia de transformaciones de potencia se denomina transformación identidad. Es la que se obtiene cuando \(\lambda=1,\) es decir, \(Y_\text{t}=Y^1\).↩︎
Y, por tanto, la maximización del valor p de esta prueba.↩︎
Esta es una reinterpretación de la indicación de Berry (1987), quien al manejar un criterio basado en \(G\) se refiere a la minimización de esta función cuando \(c\) tiende al infinito.↩︎