pf(18, 3, 8, lower.tail = FALSE) [1] 0.0006459601En la sección 6.1.18 se desglosaron los componentes de los estudios experimentales: la estructura de los tratamientos, el esquema de aleatorización y la secuencialidad en el registro de la información.
En este capítulo se presentan los esquemas de aleatorización básicos.
Con el fin de mantener una presentación secuencial y ordenada, sin mezclar conceptos, todos los ejemplos de este capítulo están basados en un único factor, es decir, la estructura de los tratamientos es unifactorial o de una vía (one-way).
No obstante, los esquemas de aleatorización que se presentan pueden usarse igualmente en los experimentos con estructura factorial de tratamientos que se desarrollan en el capítulo 10.
Asimismo, aunque todos los ejemplos de este capítulo son de tipo transversal —por cuanto registran la respuesta en un único momento al final de experimento—, los esquemas de aleatorización considerados también son aplicables en estudios longitudinales.
Conviene enfatizar que el esquema de aleatorización es solo uno de los componentes que —junto con la estructura de los tratamientos y la secuencialidad— describe un diseño experimental (cf. sección 6.1.18).
En tal sentido, la denominación tradicional —que se refiere a estos esquemas de aleatorización como diseños (diseño completamente al azar: DCA, diseño en bloques al azar: DBA, diseño cuadro latino: DCL, etc.)— puede no ser la más conveniente para el presente sistema de clasificación.
Consecuentemente, en el presente texto evitamos referirnos a los esquemas de aleatorización como diseños. Sin embargo, no puede desconocerse que tales nombres tienen una larga tradición y que es la denominación que se encuentra en la mayoría de textos.
La denominación diseño, aunque válida en el sistema de clasificación tradicional, no se ajusta a la taxonomía adoptada en este texto.
Al protocolo seguido para asignar los tratamientos a las unidades experimentales lo denominamos esquema de aleatorización.
Reservamos la palabra diseño para referirnos, de manera integral, a los componentes de un experimento.
El esquema de aleatorización, además de tener implicaciones en el ensayo de campo, se refleja en el modelo del ANOVA.
Todos los modelos de una vía tienen un par de elementos comunes: los tratamientos y el término del error. Adicionalmente, pueden incluir términos correspondientes a una o más fuentes de variación aleatoria, sin que por ello dejen de ser modelos de una vía.
En la sección 7.1 se presenta el esquema de aleatorización completamente al azar, cuyo modelo corresponde al presentado en la sección 6.2.
En la sección 7.2 se presenta el esquema de aleatorización en bloques al azar, cuyo modelo incluye una fuente de variación aleatoria.
Y finalmente, en la sección 7.3 se presentan el esquema de aleatorización en cuadro latino —que incluye dos fuentes de variación aleatoria— y sus generalizaciones —que consideran la inclusión de más de dos fuentes de variación aleatoria—.
Los procedimientos de comparación múltiple que se presentan en el capítulo 8 son aplicables a todos los experimentos con un factor que se desarrollan en este capítulo, sin importar su esquema de aleatorización.
Asimismo, tales procedimientos, con algunas adaptaciones, se emplean en los experimentos con estructura factorial que se presentan el capítulo 10.
Este es el más simple de los esquemas de aleatorización. También se le denomina completamente aleatorizado (Completely Randomized Design–CRD). En español suelen emplearse las siglas DCA por su denominación tradicional (diseño completamente al azar).
Bajo este esquema de aleatorización todas las unidades experimentales tienen exactamente la misma probabilidad de que les sea asignado cualquiera de los tratamientos evaluados.
En tal sentido, se dice que se trata de una aleatorización completa o sin restricciones, en concordancia con lo presentado en la sección 6.1.11.
Este esquema de aleatorización es el indicado cuando se tienen unidades experimentales homogéneas y el experimento se realiza bajo condiciones ambientales controladas, por ejemplo, en ensayos de laboratorio, donde las fuentes de variación adicionales a tratamientos son despreciables.
Si bien este esquema de aleatorización exhibe su mejor desempeño cuando se satisfacen las condiciones descritas, también puede ser la mejor alternativa cuando, a pesar de que estas no se satisfagan, el investigador no tiene forma de preverlas, medirlas o controlarlas para incorporarlas en el modelo.
El modelo correspondiente a este esquema de aleatorización es el presentado en la sección 6.2 y condensado en la nota 6.2:
\[
Y_{ij}=\mu+\tau_i+\varepsilon_{ij},\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r,
\]
donde:
\(Y_{ij}\): Respuesta de la \(j\)-ésima réplica del \(i\)-ésimo tratamiento.
\(\mu\): Media general.
\(\tau_i\): Efecto del \(i\)-ésimo tratamiento \((\mu_i-\mu).\)
\(\varepsilon_{ij}\): Desviación aleatoria de la \(j\)-ésima réplica del \(i\)-ésimo tratamiento respecto a la media, \(\mu_i\), del \(i\)-ésimo tratamiento.
Los supuestos del modelo son los que se detallan en la sección 6.3 y se sintetizan en la siguiente expresión, que indica que los errores son independientes y se distribuyen normalmente, con media cero y varianza común \(\sigma^2:\)
\[
\varepsilon_{ij}\text{ iid } N(0,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\]
Ejemplo 7.1
Con el fin de evaluar el efecto de cuatro sistemas de empaque de pulpa de guanábana (Annona muricata) sobre el pH del producto, se usa un esquema de aleatorización completamente al azar (DCA) con tres réplicas por tratamiento.
Las unidades experimentales son sometidas a condiciones de anaquel, a 14 ºC, durante 7 días, tras lo cual se registra el pH.
Cada unidad experimental corresponde a una porción de 250 g de pulpa empacada.
Este ensayo comprende dos pasos de aleatorización. El primero corresponde a la asignación de los tratamientos a las unidades experimentales disponibles (empacar las pulpas). Este paso puede surtirse con apoyo de la instrucción sample(1:12, 12), tal y como se indicó en la sección 6.1.11.
El segundo paso corresponde a una aleatorización de tipo espacial, al ubicar en el anaquel las unidades experimentales ya empacadas. Para ello es recomendable usar un esquema de aleatorización que produzca adecuados niveles de intercalamiento (cf. sección 6.1.11.1).
La figura 7.1, en la que los tratamientos están representados por las letras \(\text{A}\), \(\text{B}\), \(\text{C}\) y \(\text{D},\) muestra un posible esquema de aleatorización que da lugar a una disposición intercalada de las 12 unidades experimentales.
En la tabla 7.1 se presentan las lecturas de pH registradas a los 7 días.
| Tratamiento | pH | \(\overline{Y}_{i\bullet}\) | ||
|---|---|---|---|---|
| \(\text{A}\) | 4.3 | 3.9 | 4.1 | 4.1 |
| \(\text{B}\) | 3.2 | 3.1 | 3.3 | 3.2 |
| \(\text{C}\) | 3.7 | 3.9 | 3.8 | 3.8 |
| \(\text{D}\) | 4.1 | 3.7 | 3.9 | 3.9 |
Antes de proceder con cualquier cálculo, es muy importante tener presente qué pregunta se busca responder y el alcance de la correspondiente respuesta.
En la formulación del ejemplo se dice que se quiere evaluar el efecto de cuatro sistemas de empaque de pulpa de guanábana sobre el pH del producto.
Un usuario poco atento podría verse tentado a responder rápidamente dicha pregunta con base en la información de la última columna de la tabla 7.1, es decir, los promedios de los tratamientos.
Se diría, por ejemplo, que el empaque \(\text{A}\) dio lugar a un pH mayor que el \(\text{B}\) y que los empaques \(\text{C}\) y \(\text{D}\) mantuvieron la pulpa con valores intermedios de pH. Aparentemente, con ello quedaría todo dicho, no siendo necesario ni el ANOVA, ni ninguna otra técnica adicional.
Debe tenerse en cuenta, sin embargo, el alcance de tales respuestas. ¿Deseamos comparar entre sí las tres porciones de pulpa que se almacenaron con cada uno de los tipos de empaques o el efecto de tales empaques sobre futuras porciones de pulpa?
Desde luego, existe muy poco interés en las 12 porciones circunstanciales de pulpa usadas en el presente ensayo, las cuales, aunque suministran información importante, se vuelven prescindibles después del ensayo. El interés del investigador radica en la generalización que pueda hacerse del comportamiento de tales porciones de pulpa cuando son almacenadas con diferentes tipos de empaques.
Cada subconjunto de tres porciones de pulpa que es almacenado con un determinado sistema de empaque representa una muestra. La población es el universo de pulpas almacenadas con un sistema de empaque determinado (cf. secciones 3.9 y 6.2). Las medias muestrales que aparecen en la última columna de la tabla 7.1 suministran información de cada una de las cuatro muestras.
Aunque las afirmaciones que podrían hacerse con respecto a cuáles muestras tuvieron mayor o menor pH medio son válidas para tales muestras, no pueden generalizarse de manera automática a las poblaciones que representan.
Tales afirmaciones tienen un carácter descriptivo. Más allá de que las diferencias observadas puedan parecerle interesantes al usuario del estudio, ello no implica que sean estadísticamente significativas, esto es, que puedan generalizarse con un grado de incertidumbre controlado a las poblaciones que representan (cf. sección 3.9.2.6).
En el ámbito investigativo, los experimentos tienen una intención inferencial, es decir que se busca generalizar los patrones observados en las muestras a las correspondientes poblaciones. Consecuentemente, se requieren herramientas inferenciales, como el análisis de varianza, las cuales brindan el marco teórico para realizar dichas generalizaciones con baja probabilidad de error.
Antes de proceder con la parte operativa del ANOVA, es importante considerar el alcance de las conclusiones que se deriven de este.
Anteriormente se hacía referencia a la población del presente ejemplo, de manera deliberadamente general, como el universo de pulpas almacenadas con un sistema de empaque determinado.
¿Esto cubrirá las pulpas de guanábana de todas las variedades, de cualquier condición de madurez, cultivadas con cualquier sistema de manejo, en cualquier tipo de suelo, en cualquier época y en cualquier lugar del mundo?
Con toda seguridad, sería demasiado ambicioso e ingenuo pretender que tres porciones de pulpa de guanábana lograran representar tal diversidad de condiciones. El investigador deberá tener en cuenta tales aspectos para definir la validez externa de su experimento y, si fuera del caso, tendría que ampliar la cobertura de sus muestras y/o realizar experimentos adicionales (cf. sección 6.1.4).
Este tipo de consideraciones pone de manifiesto la necesidad de emplear procedimientos inferenciales, como el análisis de varianza.
Para la realización manual del ANOVA se siguen una serie de pasos: el cálculo de las sumas de cuadrados, de los grados de libertad, de los cuadrados medios, del estadístico \(F\) y del valor p. Esta información suele presentarse en una tabla resumen.
El modelo del ANOVA de una vía considera que la variabilidad total se particiona en dos únicas fuentes: tratamientos y error. A continuación, se calculan las sumas de cuadrados, usando las fórmulas operacionales presentadas en la sección 6.2.2 (expresiones 6.10, 6.11 y 6.12), empezando por el cálculo del término de corrección.
\[
C=\frac{Y_{\bullet\bullet}^2}{n}=\frac{(4.3+3.9+4.1+\dotsb+3.9)^2}{3\times4}=\frac{45^2}{12}=168.75
\]
Se obtiene a continuación la suma de cuadrados total:
\[
\begin{align}
\text{SCT}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
&=(4.3^2+3.9^2+4.1^2+\dotsb+3.9^2)-C\\[1.4em]
&=170.30-168.75\\[1.4em]
&=1.55\\[1.4em]
\end{align}
\]
La suma de cuadrados de tratamientos se obtiene como: \[
\begin{align}
\text{SCttos}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
&=\frac{12.3^2+9.6^2+11.4^2+11.7^2}{3}-C\\[1.4em]
&=\frac{510.3}{3}-168.75\\[1.4em]
&=1.35
\end{align}
\]
La inclusión en la tabla 7.1 de una columna con los totales de los tratamientos facilitaría su visualización para el cálculo de la \(\text{SCttos}\). De hecho, así suele presentarse cuando se ilustra la realización manual del ANOVA.
En este ejemplo se prefirió omitir dicha columna para no desviar la atención y centrarla en el alcance interpretativo de los promedios muestrales que se discutió anteriormente.
La suma de cuadrados del error se obtiene por diferencia:
\[
\begin{align}
\text{SCE}&=\text{SCT}-\text{SCttos}\\[1.4em]
&=1.55-1.35\\[1.4em]
&=0.20
\end{align}
\]
Los grados de libertad se obtienen con base en las expresiones compiladas en la nota 6.4.
\[
\begin{align}
\text{glT}&=n-1=11\\[1.4em]
\text{glttos}&=k-1=3\\[1.4em]
\text{gle}&=11-3=8
\end{align}
\]
Los cuadrados medios se calculan como la razón entre las sumas de cuadrados y sus correspondientes grados de libertad, usando las expresiones 6.14 y 6.15.
\[
\text{CMttos}=\frac{\text{SCttos}}{k-1}=\frac{1.35}{3}=0.45
\]
\[
\text{CME}=\frac{\text{SCE}}{n-k}=\frac{0.20}{8}=0.025
\]
El estadístico de prueba se calcula como la razón entre el \(\text{CMttos}\) y el \(\text{CME}:\)
\[
F_{\text{c}}=\frac{\text{CMttos}}{\text{CME}}=\frac{0.45}{0.025}=18
\]
Bajo la hipótesis nula, el estadístico de prueba sigue una distribución \(F_{(3, 8)}.\) El valor p se obtiene como el área a la derecha del estadístico calculado en dicha distribución (cf. figura 6.10).
pf(18, 3, 8, lower.tail = FALSE) [1] 0.0006459601La tabla 7.2 condensa la información anterior.
| Fuentes de variación | Grados de libertad | Sumas de cuadrados | Cuadrados medios | Estadístico \(F\) | Valor p |
|---|---|---|---|---|---|
| Tratamientos | 3 | 1.35 | 0.45 | 18.0 | 0.000646 |
| Error | 8 | 0.20 | 0.025 | ||
| Total | 11 | 1.55 |
Usando el código 7.1 en R, se obtiene la tabla resumen del análisis de varianza:
Mediante la línea 1 del código 7.1, se importa la información correspondiente a la tabla 7.1, desde el archivo Excel ejemplo 7.1.xlsx.
La información de la tabla 7.1 es la misma que aparece en el archivo ejemplo 7.1.xlsx; lo único que cambia es la manera en la que se organiza.
La información tabular, como la que se muestra en la tabla 7.1, es adecuada para visualizar los resultados y para realizar cálculos manuales, pues se presta para obtener totales y promedios en los márgenes de la tabla. Este formato es el que suele emplearse en tablas de resumen y en libros de texto.
El formato de base de datos, como el empleado en el archivo ejemplo 7.1.xlsx, en el que la información se organiza con una columna por factor o variable y una observación por fila, es el estándar para análisis de datos mediante algún software.
Aunque el proceso para pasar del formato tabular al de base de datos suele ser relativamente sencillo, puede verse afectado por errores de manipulación. La función personalizada tb2db facilita este proceso.
La línea 2 del código 7.1 define el vector de tratamientos como un factor.
En el presente contexto, los tratamientos son variables de clasificación. Consecuentemente, deben estar definidos en R como objetos de la clase factor (cf. R paso a paso).
Aunque algunas funciones como aov realizan la coerción automática desde character a factor, algunos otras, como plot1, no aplican coerción.
En adición, la coerción automática no se da cuando los tratamientos están identificados con símbolos numéricos, en cuyo caso, se importan como vectores de la clase numeric.
Por lo anterior, se recomienda definir explícitamente los tratamientos como factores.
La línea 3 del código 7.1 es la instrucción central. La función aov{stats} ajusta el modelo de ANOVA y lo guarda en un objeto de las clases aov y lm, desde el cual puede recuperarse la información del modelo. En el presente ejemplo, dicho objeto se llama anova.
El primer argumento de la función aov es una fórmula con el formato general respuesta ~ tratamientos. Mediante el argumento data se especifica el data frame desde el cual se lee la información.
Finalmente, mediante la línea 5 del código 7.1 se ejecuta la función summary, que extrae el resumen del objeto anova, es decir, la tabla resumen del ANOVA.
Esta tabla reproduce la obtenida previamente por cálculo manual, con ligeras variaciones en el formato.
Df Sum Sq Mean Sq F value Pr(>F)
tto 3 1.35 0.450 18 0.000646 ***
Residuals 8 0.20 0.025
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Una de las diferencias más notorias es la omisión de la fila de totales. Aunque esta resulta útil en el procedimiento manual, no aporta información de carácter inferencial.
En la última línea se presentan códigos de significancia, comunes en muchas salidas de R, que se interpretan con base en lo indicado en la tabla 7.3:
| Símbolo | Valor p |
|---|---|
| \(***\) | \(0 < \text{p} \le 0.001\) |
| \(**\) | \(0.001 < \text{p} \le 0.01\) |
| \(*\) | \(0.01 < \text{p} \le 0.05\) |
| \(.\) | \(0.05 < \text{p} \le 0.1\) |
| \(\text{Ningún símbolo}\) | \(\text{p} > 0.1\) |
Aunque en el presente ejemplo —en el que se contrasta un único juego de hipótesis y se obtiene, por tanto, un solo valor p— tales códigos no aportan información adicional, estos pueden llegar a ser útiles en tablas de resultados con múltiples valores p, guiando rápidamente hacia los valores de interés.
En cualquier caso, el usuario puede evitar la aparición de tales códigos mediante la instrucción options(show.signif.stars = FALSE).
Antes de interpretar los resultados de cualquier técnica inferencial y proceder con el análisis, el investigador debe evaluar la solidez de los resultados obtenidos; en otras palabras, debe validar los supuestos del correspondiente modelo estadístico.
Los supuestos susceptibles de validación para el modelo del ANOVA de una vía, con esquema de aleatorización completamente al azar son la normalidad de los errores y la homogeneidad de varianzas dentro de los tratamientos (cf. sección 6.3).
Para evaluar el supuesto de normalidad, se usa la prueba de Shapiro-Wilk sobre los residuales del modelo (cf. secciones 4.1 y 6.3.2), los cuales se extraen en R mediante la función resid.
Se enfatiza que la normalidad se evalúa sobre los residuales del modelo; no sobre la variable respuesta (cf. sección 6.3.2).
shapiro.test(resid(anova))
Shapiro-Wilk normality test
data: resid(anova)
W = 0.92745, p-value = 0.3538Puesto que el valor p de la prueba de Shapiro-Wilk (0.3538) es mayor que \(\alpha=0.01,\) no se rechaza la hipótesis nula. En otras palabras, no se tienen evidencias de desviaciones severas del supuesto de normalidad. Por ende, no se consideran necesarias acciones correctivas ni alternativas.
A continuación, se evalúa el supuesto de homocedasticidad, siguiendo las pautas indicadas en la sección 6.3.3.1. Inicialmente se ilustra el cálculo manual de la prueba de Levene centrada en la mediana, también denominada prueba de Brown-Forsythe2.
La tabla 7.4 presenta las desviaciones absolutas entre cada una de las lecturas y la mediana de su correspondiente grupo.
| Tratamiento | \(|Y_{ij}-\widetilde{Y}_{i\bullet}|\) | \(\widetilde{Y}_{i\bullet}\) | ||
|---|---|---|---|---|
| \(\text{A}\) | 0.2 | 0.2 | 0 | 4.1 |
| \(\text{B}\) | 0 | 0.1 | 0.1 | 3.2 |
| \(\text{C}\) | 0.1 | 0.1 | 0.1 | 3.8 |
| \(\text{D}\) | 0.2 | 0.2 | 0 | 3.9 |
La prueba de Levene consiste en realizar un ANOVA sobre las desviaciones absolutas que se presentan en la tabla 7.4. Todos los componentes de dicho análisis se calculan tal y como se ilustró anteriormente para los datos de la tabla 7.1. Los resultados se condensan en la tabla 7.5.
| Fuentes de variación | Grados de libertad | Sumas de cuadrados | Cuadrados medios | Estadístico \(F\) | Valor p |
|---|---|---|---|---|---|
| Tratamientos | 3 | 0.01333 | 0.004444 | 0.533 | 0.672 |
| Error | 8 | 0.06667 | 0.008333 | ||
| Total | 11 | 0.20667 |
Puesto que el valor p (0.672) es mayor que \(\alpha=0.01,\) no se rechaza la hipótesis de homogeneidad de varianzas. En otras palabras, no se tienen elementos que evidencien desviaciones severas del supuesto de homocedasticidad y, consecuentemente, no se consideran necesarias acciones correctivas ni alternativas.
La prueba de Levene puede calcularse automáticamente en R, mediante la función LeveneTest{car}.
library(car)
leveneTest(pH ~ tto, data = data)Se obtiene el siguiente resultado, el cual coincide con el de la tabla 7.5, pero omitiendo la información irrelevante.
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 3 0.5333 0.6722
8 Puesto que no se han detectado desviaciones severas de los supuestos de normalidad y homogeneidad de varianzas, se procede al análisis de los resultados del experimento.
El empleo de \(\alpha=0.01\) en las pruebas de normalidad y homocedasticidad se sustenta en la robustez del ANOVA ante desviaciones leves de estos supuestos.
Este aspecto se discute en el ejemplo 4.1 y las secciones 6.3.2 y 6.3.3.1.
Salvo que se sustente alguna condición especial, el estándar para evaluar la significancia del análisis de varianza es \(\alpha=0.05.\)
En el presente ejemplo, dado que el valor p obtenido (0.000646) es menor que 0.05, se rechaza la hipótesis nula al nivel de significancia del 5 %.
Mediante el ANOVA se contrasta el siguiente juego de hipótesis:
\[
\mu_{\text{A}}=\mu_{\text{B}}=\mu_{\text{C}}=\mu_{\text{D}}=\mu
\] \[
\mu_i \ne \mu_{i'} \text{ para al menos un par } (i,i')
\]
Al estudiar el ANOVA, su lógica y el uso de un estadístico basado en la distribución \(F,\) se hace notar que el mecanismo subyacente es la comparación de la variabilidad entre tratamientos contra variabilidad dentro de tratamientos. Asimismo, se hace notar que el juego de hipótesis para las varianzas es equivalente al juego de hipótesis para la comparación de múltiples medias (cf. sección 6.2.6).
No obstante, para fines prácticos, el ANOVA se presenta e interpreta únicamente en términos de comparación de medias.
Este juego de hipótesis contrasta las medias poblacionales de la respuesta evaluada, es decir, el pH medio de la pulpa de guanábana en los diferentes tipos de empaques.
Así, la hipótesis nula plantea que el pH medio es el mismo, sin importar el tipo de empaque, mientras que la hipótesis alternativa plantea la posibilidad de que el pH medio de la pulpa de guanábana difiera entre al menos dos de los empaques comparados.
La significancia del ANOVA permite concluir que el pH medio de la pulpa de guanábana, evaluado tras 7 días, en condiciones de anaquel, a 14 ºC difiere, a nivel poblacional, entre al menos dos de los sistemas de empaque evaluados.
Esto suele expresarse diciendo que el ANOVA es significativo o que hay efecto significativo de los tratamientos. Esta afirmación puede interpretarse de dos maneras: una más formal, basada en el modelo teórico, y otra más aplicada referida a las poblaciones de campo.
Desde el punto de vista teórico, un efecto significativo de tratamientos quiere decir que al menos uno de los \(\tau_i\) del modelo de efectos difiere de cero (cf. expresión 6.7).
En la práctica esto significa que al menos uno de los sistemas de empaque ejerció un efecto diferencial sobre el pH medio de la pulpa de guanábana, con respecto a los demás.
Para tener una mejor idea de las características de las muestras, puede usarse —como herramienta descriptiva— un diagrama de caja y bigotes con una representación para cada uno de los tratamientos (cf. sección 2.3.6).
En R, la siguiente instrucción3 genera el diagrama de la figura 7.2.
with(data, plot(tto, pH, xlab = "Tratamientos", ylab = "pH"))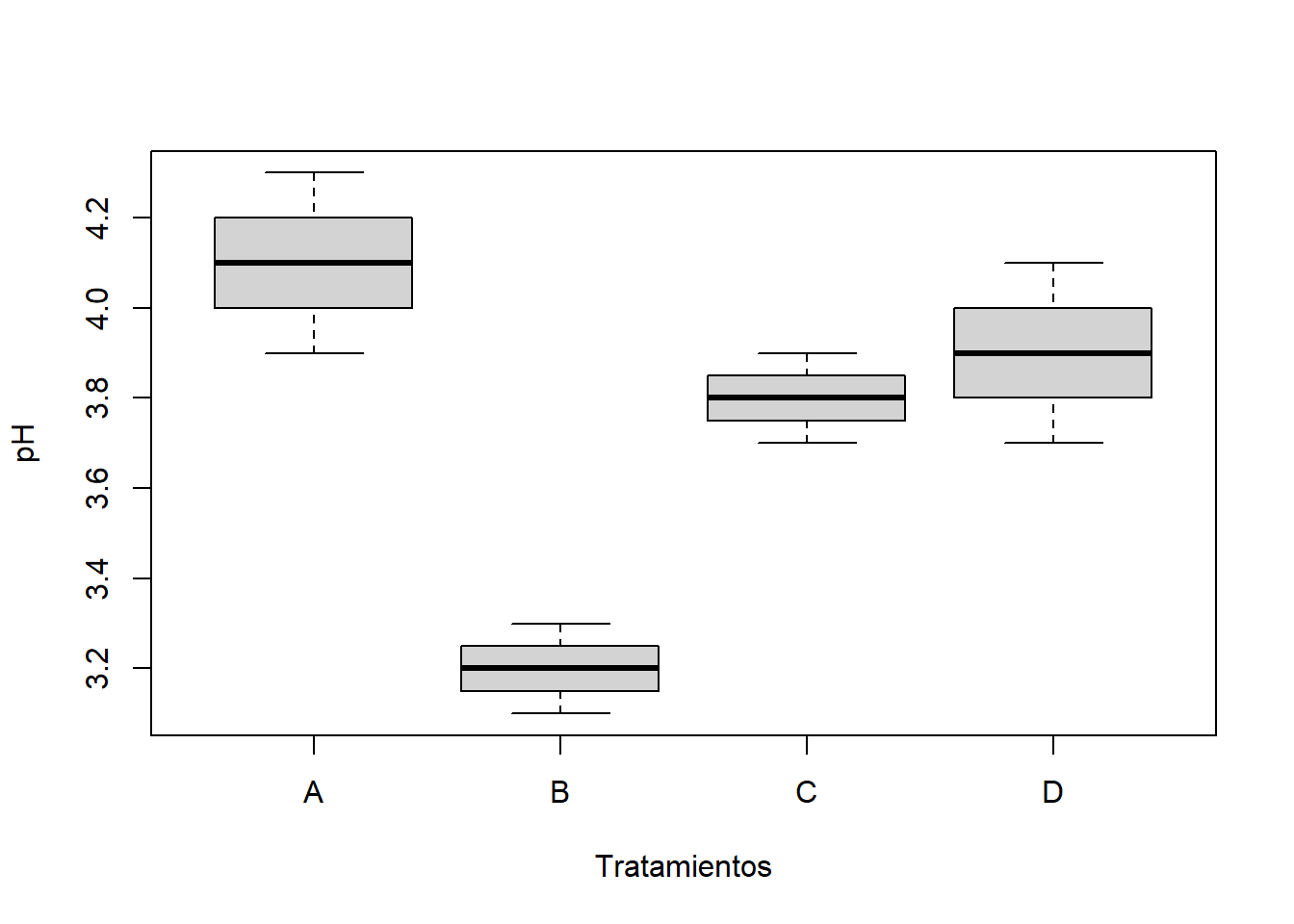
Dada la significancia del ANOVA, ¿el usuario puede estar absolutamente convencido del efecto de los tratamientos a nivel poblacional?
La respuesta corta es no. Ni en este ejemplo ni en ninguna otra situación en la que se haga uso de una técnica inferencial puede tenerse certeza absoluta sobre la validez de los resultados. Siempre existe una probabilidad de errar, sea que se rechace o no la hipótesis nula (cf. tabla 3.4).
No obstante, se ha establecido la convención de destacar aquellos resultados cuya probabilidad de aparición por azar es muy baja. Ya desde la época de Fisher se ha usado un valor probabilístico de 0.05 como referente de baja probabilidad (cf. tip 3.3).
El valor p se calcula como la probabilidad de obtener bajo la hipótesis nula una razón de varianzas igual o más extrema que la observada. Puede interpretarse como la probabilidad —en el contexto del experimento observado— de incurrir en un error al rechazar la hipótesis nula con base en la información de la muestra.
En el contexto del presente ejemplo, el investigador puede interpretar este resultado como una probabilidad de 0.000646 de incurrir en un error al formular sus conclusiones sobre las diferencias de medias o los efectos de los tratamientos. Por tanto, aunque existe una probabilidad de errar mayor que cero —lo que impide avalar la absoluta veracidad de la conclusión—, se considera que dicha probabilidad es baja.
Es necesario tener presente que, además de la significancia estadística, debe valorarse la significancia práctica para la toma de decisiones (cf. sección 3.9.2.6).
Una vez establecido que el ANOVA es significativo —es decir, que existen diferencias entre al menos dos medias— el usuario naturalmente querrá saber entre cuáles medias se presentan dichas diferencias.
Los procedimientos de comparación múltiple permiten responder esta pregunta. Dada su extensión, complejidad y carácter transversal —en cuanto a su aplicación a los distintos esquemas de aleatorización—, se desarrollan en un capítulo aparte, donde se retoma el presente ejemplo para ilustrar su aplicación (cf. capítulo 8).
Este esquema de aleatorización es adecuado cuando —antes de realizar el experimento— se detecta o intuye una fuente de variación adicional a los tratamientos. Dicha fuente de variación se denomina genéricamente factor de bloqueo.
La homogeneidad de los bloques tiene que ver con alguna o algunas características que hipotéticamente podrían determinar parcial o totalmente la respuesta.
La asignación de los tratamientos se realiza de manera aleatoria dentro de cada bloque e independiente entre bloques.
El término bloque, acuñado por Fisher, proviene de la tradición agraria, en referencia a un grupo de parcelas contiguas y esperablemente homogéneas.
En un contexto más amplio, es un término genérico para referirse a cualquier grupo de unidades experimentales con niveles homogéneos del factor de bloqueo.
Al hacer referencia a este esquema de aleatorización, en español suelen emplearse las siglas DBA por su denominación tradicional (diseño de bloques al azar).
Probablemente, el más popular de los esquemas de aleatorización basados en bloques es el que considera bloques conformados por tantas unidades experimentales como tratamientos se estén evaluando. Esto permite asignarle un tratamiento diferente a cada una de las unidades experimentales del bloque, lo que hace que cada bloque contenga el conjunto completo de todos los tratamientos. Por ende, a este esquema de aleatorización se le denomina bloques completos al azar.
Al esquema de aleatorización en bloques completos, frecuentemente se le denomina incorrectamente bloques completamente al azar.
El calificativo completos se usa en contraposición a incompletos, que es el esquema que surge cuando los bloques no alcanzan a alojar todos los tratamientos4.
En contraste, el calificativo completamente se refiere a la aleatorización irrestricta propia del esquema presentado en la sección 7.1, donde todas las unidades experimentales tienen exactamente la misma probabilidad de que les sea asignado cualquiera de los tratamientos evaluados.
Este no es el caso en el esquema de bloques completos al azar, donde la aleatorización sí está sujeta a una restricción: cada bloque debe contener el conjunto total de tratamientos.
Esta sección se enfoca exclusivamente en el esquema de aleatorización en bloques completos al azar, sin considerar sus múltiples variantes.
En experimentos diseñados, la aleatorización en bloques es la estrategia por excelencia para aislar el efecto de factores secundarios reconocibles, evitando que actúen como factores de confusión.
La definición 6.1 destaca que una de las características que configura un efecto secundario como factor de confusión es la falta de control sobre este. Esto impide la separabilidad de efectos.
La figura 7.3 ilustra un hipotético caso en el que se desea comparar el desempeño en crecimiento de dos especies forestales, estableciendo la primera en pendiente alta y la segunda en pendiente baja.
Si se observaran diferencias, no sería posible separar efectos para determinar si estas podrían atribuírsele a la especie, a la pendiente o a una combinación de ambos factores. Lo mismo sucedería si no se observaran diferencias.

La estrategia del bloqueo consiste en conformar grupos de unidades experimentales homogéneas con respecto a los niveles del potencial factor de confusión, de manera que los tratamientos sean comparables dentro de tales grupos.
En el presente ejemplo, en el que el potencial factor de confusión es la pendiente, sería necesario establecer ambas especies forestales en cada uno de los dos niveles de pendiente, como ilustra la figura 7.4. Esto permitiría comparar las especies dentro de cada uno de los niveles de pendiente, sin que las diferencias entre pendientes actúen como factor de confusión.
Mediante esta estrategia, lo que en principio era un potencial factor de confusión se convierte en factor de bloqueo.

Nótese que lo ilustrado en la figura 7.4 es análogo al concepto de pareamiento (cf. sección 5.2.3), consistente en elegir pares de observaciones con la máxima similitud posible en todas aquellas características que pudieran afectar la respuesta, de modo que las unidades dentro de cada par difieran esencialmente en los tratamientos.
En la sección 5.2.3 se discutió el estudio realizado por Márquez, López, Correa, Pareja y Giraldo (2003), en el que se evaluó el efecto de la exposición a agentes potencialmente genotóxicos sobre la integridad del genoma.
En dicho estudio, se eligieron parejas con la mayor homogeneidad posible con respecto a todos los factores secundarios que podrían haber actuado como factores de confusión: edad, género, grupo étnico, consumo de medicamentos y hábitos. En lenguaje de los modelos de ANOVA, cada pareja constituye un bloque.
El bloqueo extiende el concepto de pareamiento. Mientras que el pareamiento es aplicable únicamente a ensayos en los que se comparan dos condiciones o tratamientos, el bloqueo —en teoría— puede usarse en ensayos con cualquier número de tratamientos.
Si en lugar de 2 tratamientos, el ensayo consta de 3, 4, 5 o \(k\) tratamientos, los bloques estarán conformados por ternas, cuádruplas, quíntuplas o \(k\)-tuplas de unidades experimentales homogéneas.
En un ensayo con \(k\) tratamientos, bajo un esquema de aleatorización en bloques completos al azar, cada bloque está conformado por un grupo de \(k\) unidades experimentales homogéneas.
La equivalencia entre el modelo de muestras pareadas y el de bloques completos al azar para el caso de \(k=2\) no es solo conceptual, sino también numérica.
El cuadrado del estadístico de prueba \(t_\text{c}\) es igual al estadístico \(F_\text{c}\) para los tratamientos.
Tanto el valor p como los intervalos de confianza coinciden en ambos modelos.
En la comparación de las dos especies forestales que se ilustra en la figura 7.4, la pendiente es el único criterio de bloqueo.
En contraste, en el estudio de Márquez et al. (2003), el criterio de bloqueo surge de la homogenización de la edad, el género, el grupo étnico, el consumo de medicamentos y los hábitos en cada pareja.
Ambas estrategias son válidas. El uso de una u otra depende del número de factores que se reconozcan como potenciales factores de confusión y del control que pueda ejercerse sobre estos.
A menudo, lo que podría parecer un único factor actúa como consolidador de múltiples factores. Así, tras el simple valor de una pendiente —entendida como el cambio vertical por cada cambio horizontal unitario— puede haber diferencias asociadas con fuerzas mecánicas, compactación, profundidad efectiva, humedad, erosión y lixiviación o acumulación de nutrientes, entre otras.
Esta es la razón por la que en ensayos agronómicos es común utilizar la vecindad espacial como criterio de bloqueo. Se espera que las variaciones entre unidades contiguas sean menores que las exhibidas entre unidades más alejadas entre sí.
La figura 7.5 presenta un posible esquema de aleatorización en bloques completos al azar para un ensayo con cuatro tratamientos y tres réplicas.
La figura 7.5 permite ilustrar los siguientes aspectos comunes a todos los esquemas de aleatorización en bloques completos al azar:
Cada bloque es completo, por cuanto contiene todos los tratamientos.
Cada bloque contiene una réplica de cada uno de los tratamientos. Consecuentemente, el número de bloques coincide con el número de réplicas de cada tratamiento.
Los tratamientos están aleatorizados dentro de cada bloque; de ahí su nombre de bloques al azar.
La aleatorización interna de cada bloque es independiente de la de los demás bloques.
Adicionalmente, un esquema como el de la figura 7.5 a menudo refleja la disposición espacial de los tratamientos en el campo o el laboratorio. Esto es particularmente válido en ensayos en los que la aleatorización es de tipo espacial (cf. sección 6.1.11).
En textos con especial énfasis en ensayos agronómicos, suelen encontrarse recomendaciones aplicables a las situaciones en las que los bloques están conformados por grupos de parcelas contiguas:
Cuando se identifica un gradiente en campo, los bloques deben ubicarse perpendicularmente a dicho gradiente, de manera que el grupo de unidades experimentales que conforman cada bloque esté sometido a una condición homogénea respecto a dicho gradiente.
Las unidades experimentales dentro de cada bloque se ubican con su mayor longitud paralela al gradiente.
Aunque representaciones como la de la figura 7.5 son fiel reflejo de muchos ensayos de campo, no recogen toda la riqueza conceptual del esquema de aleatorización en bloques.
Cuando se presentan como única ilustración, pueden hacer pensar que la estrategia de aleatorización en bloques es bastante limitada, lo cual no es cierto.
La aleatorización en bloques, aunque nació en la experimentación agronómica y sigue utilizándose ampliamente en dicho ámbito, no está limitada a esta. La estrategia de bloqueo resulta útil en prácticamente todas las áreas de aplicación de los diseños experimentales.
En el ámbito pecuario, los bloques pueden conformarse con grupos homogéneos de individuos, considerando las características que pudieran afectar la respuesta: raza, edad, peso, número de partos, tercio de la lactancia, producción histórica y marcadores sanguíneos, entre otras. No necesariamente habrá que homogenizar con base en todas las características secundarias; el investigador deberá evaluar cuál o cuáles son relevantes para la respuesta considerada.
En el área de reproducción animal es común evaluar diferentes técnicas para la criopreservación de semen. La generación excesiva de especies reactivas de oxígeno causa daños físicos y químicos en la estructura del esperma, lo que genera envejecimiento prematuro y reduce la viabilidad y fertilidad de los espermatozoides.
En un estudio realizado por Acosta, Correa, Rojano y Restrepo (2024) se evaluó la incorporación de diferentes antioxidantes para reducir estos efectos adversos. Aunque la composición de cada eyaculado suele ser relativamente homogénea, la variabilidad entre eyaculados suele ser alta. Para evitar que la variabilidad entre eyaculados actuara como factor de confusión, se bloqueó por eyaculado, fraccionando cada eyaculado uno en un número de submuestras correspondiente al número de antioxidantes evaluados.
En el análisis sensorial de alimentos, cada catador recibe una serie de muestras para su valoración. Aunque muchas de estas evaluaciones son efectuadas por panelistas entrenados, buscando unificar criterios y disminuir la subjetividad, es imposible eliminar completamente la percepción subjetiva de cada panelista. No obstante, se espera que las valoraciones emitidas por un panelista particular sobre una serie de productos sean muy consistentes en criterio, variando únicamente por las características de los productos evaluados. Asimismo, por la sensibilidad propia de cada evaluador, es esperable que surjan diferencias entre las valoraciones de distintos panelistas.
En este tipo de estudios, suele incluirse el catador como factor de bloqueo, a fin de evitar que la subjetividad propia de los evaluadores actúe como factor de confusión. Si el número de tratamientos no es muy grande, puede emplearse un esquema de aleatorización en bloques completos al azar, donde cada panelista constituye un bloque y recibe para su valoración las muestras de todos los tratamientos en un orden aleatorio y etiquetadas arbitrariamente para evitar sesgos.
El factor de bloqueo es circunstancial; si bien puede afectar la respuesta, el investigador usualmente no tiene interés en realizar comparaciones entre sus diferentes niveles. Sus niveles no suelen ser fijados por el investigador, sino que se consideran una muestra aleatoria extraída de todos los posibles niveles existentes en la población objetivo.
En el ejemplo anterior, los catadores actúan como factor de bloqueo, puesto que no se trata de un concurso de catadores para comparar sus habilidades5. El bloqueo se emplea con la única intención de controlar las variaciones entre estos, haciendo comparables los tratamientos. Cada panelista se considera un elemento de la muestra de todos los posibles panelistas.
El esquema anterior es análogo al que se utilizaría si se evaluaran una serie de propiedades utilizando diferentes instrumentos, sin el ánimo de comparar instrumentos. Cada instrumento se tomaría como un bloque, con el único fin de controlar la variabilidad entre instrumentos, haciendo comparables las lecturas generadas por estos.
Algunos ensayos relacionados con la industria alimentaria pueden emplear diferentes lotes de materia prima. En estos ensayos, el lote, aunque no suele ser el factor principal6, puede tener algún efecto sobre la respuesta, por lo cual suele manejarse como factor de bloqueo.
En ensayos sobre el control de hormiga arriera (Atta cephalotes) es sabido que el tamaño de los hormigueros es un factor crucial para el control: es más difícil controlar las colonias establecidas en hormigueros grandes que las de hormigueros pequeños.
Un estudio que pretenda evaluar la eficacia de diferentes productos para el control de hormiga arriera deberá bloquear con base en el tamaño del hormiguero. Cada bloque estará conformado por un grupo de hormigueros de tamaño similar, dentro del cual se asignan aleatoriamente los productos (figura 7.6). Esto evita que el tamaño del hormiguero actúe como factor de confusión.

La figura 7.6 ilustra un aspecto que merece señalarse explícitamente: los bloques no tienen que estar conformados por unidades experimentales contiguas espacialmente. Si bien es cierto que en muchos ensayos de campo la vecindad espacial propicia la similitud entre unidades experimentales, en muchos otros casos, el criterio de homogenización puede estar completamente desligado de la ubicación espacial, como en el ejemplo de los hormigueros en el que el criterio de bloqueo es el tamaño del hormiguero, independientemente de su ubicación.
En otros casos, como en ensayos pecuarios con animales sin confinamiento, podría ser que el concepto de ubicación espacial ni siquiera fuera aplicable. De hecho, por manejo, podría resultar más práctico agrupar los individuos durante el ensayo acorde con la dieta suministrada.
La estrategia de bloqueo también encuentra un nicho natural de aplicación en ensayos que deben ejecutarse de manera fraccionada en el tiempo por restricciones de equipos, materiales u operarios.
En tales casos, se hace necesario controlar el efecto del tiempo como potencial factor de confusión. El tiempo actúa como un factor integrador de todas las condiciones que pueden variar entre diferentes momentos de ejecución. Pueden presentarse variaciones en materiales, equipos7, operarios o microclima. Asimismo, pueden surgir errores sistemáticos por descalibración de equipos a lo largo del proceso, así como por cansancio o adquisición de destrezas por parte de los operarios.
El bloqueo constituye una medida preventiva para evitar que las posibles variaciones asociadas con el momento de ejecución se conviertan en factores de confusión. Cada bloque está conformado por el conjunto de ejecuciones realizadas bajo condiciones homogéneas en un momento particular. Todo ensayo fraccionado en el tiempo debe basarse en este esquema de aleatorización.
Nótese que en estos escenarios, el tiempo representa un factor circunstancial que surge de la imposibilidad de realizar todo el ensayo en simultánea. Los diferentes momentos de ejecución se definen con base en la disponibilidad de recursos, sin que se requiera mantener ningún patrón de interespaciamiento. En estos casos, no existe ningún interés en comparar el desempeño del ensayo en los diferentes momentos. En el capítulo 10 se exploran otros escenarios en los que el tiempo sí desempeña un rol activo.
Ante la necesidad de fraccionar un ensayo, resulta muy tentadora la posibilidad de ejecutar todas las réplicas de un tratamiento en un primer momento; las de otro tratamiento en un momento posterior, y así sucesivamente hasta el último tratamiento.
Desde el punto de vista del operador, es entendible que se contemple esta posibilidad, por cuanto facilitaría las labores. No obstante, es la peor estrategia posible desde el punto de vista de control de posibles factores de confusión. Esta estrategia no solamente deja de controlarlos, sino que se convierte en una invitación explícita para su manifestación, afectando gravemente la validez interna del ensayo.
Finalmente es importante señalar que la estrategia de bloqueo facilita la logística de las labores complementarias, evitando que se conviertan en factores de confusión. En ensayos de gran magnitud en los que sería muy complejo o imposible realizar todas las labores complementarias de manera homogénea, basta con garantizar homogeneidad dentro de cada bloque. Las diferencias que puedan surgir en el manejo de diferentes bloques son absorbidas por el factor de bloqueo, sin comprometer ni la validez interna ni la potencia del ensayo para comparar tratamientos.
El esquema de aleatorización en bloques resulta adecuado para controlar una fuente de variación secundaria.
El factor de bloqueo puede conformarse mediante la conglomeración de varios factores secundarios.
Se busca la máxima homogeneidad posible entre las unidades que conforman un bloque, de manera que las diferencias dentro del bloque sean atribuibles esencialmente al efecto de los tratamientos. En contraste, la heterogeneidad entre bloques es esperable.
El factor de bloqueo es de tipo circunstancial o aleatorio. Los ensayos ejecutados bajo este esquema de aleatorización no están diseñados para comparar los diferentes niveles del factor de bloqueo.
En ensayos que deban fraccionarse en diferentes momentos, se hace necesario controlar por medio del bloqueo el posible efecto del tiempo y todos los factores asociados con este.
La estrategia de bloqueo facilita el control de potenciales fuentes de confusión asociadas con el manejo, cuando es poco viable realizar todas las labores complementarias de manera homogénea.
La aleatorización en bloques completos impone una restricción a la aleatorización: cada bloque debe contener el conjunto completo de tratamientos.
El modelo correspondiente a este esquema de aleatorización es:
\[
Y_{ij}=\mu+\tau_i+\beta_j+\varepsilon_{ij},\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r,
\tag{7.1}\]
donde:
\(Y_{ij}\): Respuesta del \(i\)-ésimo tratamiento en el \(j\)-ésimo bloque.
\(\mu\): Media general.
\(\tau_i\): Efecto del \(i\)-ésimo tratamiento.
\(\beta_j\): Efecto del \(j\)-ésimo bloque.
\(\varepsilon_{ij}\): Desviación aleatoria de la respuesta del \(i\)-ésimo tratamiento en el \(j\)-ésimo bloque respecto a su valor esperado.
Este modelo comparte los supuestos del modelo completamente al azar e incluye uno adicional.
Los supuestos comunes se sintetizan en la siguiente expresión, que indica que los errores son independientes y están normalmente distribuidos, con media cero y varianza común \(\sigma^2:\)
\[
\varepsilon_{ij}\text{ iid } N(0,\ \sigma^2),\ i=1, 2,\dotsc, k;\quad j=1, 2,\dotsc, r
\]
Adicionalmente, el modelo de bloques al azar supone aditividad entre los efectos de bloques y tratamientos.
Para el supuesto de independencia aplican las mismas consideraciones que para el modelo completamente al azar. La independencia no se verifica a posteri, sino que se propicia durante la planeación y la ejecución del ensayo (cf. sección 6.3.1).
El supuesto de normalidad se propicia y se evalúa de igual manera que en el modelo completamente al azar. Cuando sea del caso, puede propiciarse empleando unidades experimentales conformadas por múltiples elementos. Para su evaluación se utiliza la prueba de Shapiro-Wilk sobre los residuales del modelo.
Para evaluar homogeneidad de varianzas, se recomienda la prueba generalizada de Levene propuesta por O’Neill y Mathews (2002) y descrita en la sección 7.2.2.
La conceptualización sobre la aditividad entre bloques y tratamientos se discute a continuación. Su evaluación formal se realiza mediante las pruebas descritas en la sección 7.2.3.
En términos simples, la aditividad se refiere al hecho de que la respuesta esperada pueda expresarse como la suma de los efectos de los bloques y los tratamientos, tal y como lo plantea el correspondiente modelo de ANOVA.
Esto implica que la diferencia entre cualquier par de tratamientos sea consistente al ser evaluada en los diferentes bloques. En tal caso, se dice que no existe interacción entre bloques y tratamientos. La figura 7.7 ilustra este escenario.

El comportamiento de los tratamientos —representados en la figura 7.7 mediante líneas de diferentes colores— puede expresarse así: el tratamiento verde supera ligeramente al tratamiento rojo. Tanto el tratamiento verde como el rojo superan visiblemente al tratamiento azul.
Lo resaltable es que esta descripción aplica en cualquiera de los escenarios definidos por los bloques. Sea en el bloque I, en el II o en el III, la descripción es igualmente válida. Las diferencias entre los tratamientos no dependen del bloque.
Desde luego, los bloques pueden aportar. Se observa, por ejemplo, que la respuesta de todos los tratamientos en el bloque II es superior a la que exhiben en el bloque I. Sin embargo, ese cambio se obtiene sumándole una cantidad constante a todos los tratamientos. Algo similar sucede con las respuestas de los tratamientos en el bloque III, con respecto a las del bloque II. Los cambios entre bloques surgen de un proceso aditivo: las medias de los tratamientos al pasar de un bloque a otro se obtienen sumando o restando una constante.
Puesto que las diferencias de los tratamientos no dependen del bloque, se dice que no existe interacción entre bloques y tratamientos.
A la representación de la figura 7.7, en la que se unen mediante líneas o trazas los valores medios que surgen de las diferentes combinaciones de los niveles de dos factores (bloques y tratamientos en el presente caso) se le denomina gráfico de interacción.
En escenarios de no interacción, como el representado mediante la figura 7.7, las trazas son paralelas o cuasi paralelas por segmentos. Este es el reflejo de que las diferencias entre tratamientos sean consistentes entre bloques.
Al evaluar la relación entre dos o más factores, los siguientes términos son conceptualmente equivalentes:
\[ \text{aditividad} \leftrightarrow \text{no interacción} \leftrightarrow \text{independencia de efectos} \]
En contraste, la figura 7.8 ilustra un escenario de no aditividad, interacción entre bloques y tratamientos o dependencia de efectos.
En este caso, las diferencias entre tratamientos no son consistentes entre bloques, sino que dependen del bloque. En consecuencia, no es posible expresar la respuesta mediante la simple adición de efectos, por lo cual el modelo del ANOVA planteado deja de ser válido.

El hecho de que las diferencias entre tratamientos no sean consistentes entre bloques tiene profundas implicaciones conceptuales. ¿Cuál es el mejor tratamiento? ¿Será válido presentar los resultados del ensayo promediando el comportamiento de los tratamientos en los diferentes bloques?
Antes de intentar resolver estas preguntas, es necesario destacar que la interacción entre bloques y tratamientos puede ser de diferente naturaleza, tal y como se ilustra en la figura 7.9.


En el escenario representado mediante la figura 7.9 (a), aunque las trazas no son paralelas por segmentos, es posible extraer un patrón general: el tratamiento verde supera al tratamiento rojo y este a su vez supera al tratamiento azul. Esto es válido para cualquiera de los bloques. Aunque la magnitud de las diferencias cambia entre bloques, el orden se mantiene.
En contraste, la figura 7.9 (b) presenta un escenario en el que no es posible extraer un patrón general, dado que el orden de los tratamientos cambia entre bloques.
La interacción por cambios en magnitud (figura 7.9 (a)) constituye el menos complejo de los escenarios. En estos casos sí sería posible responder cuál es el mejor tratamiento. Sin embargo, aun podría resultar cuestionable presentar los resultados del ensayo promediando el comportamiento de los tratamientos en los diferentes bloques. La interacción por cambios en orden (figura 7.9 (b)) excluye cualquier posibilidad de interpretación global.
En el escenario de interacción por cambios en magnitud (figura 7.9 (a)) los efectos no son aditivos, sino multiplicativos. Esta situación surge, por ejemplo, cuando se evalúan fertilizantes en diferentes suelos como factor de bloqueo. Es común que los suelos no solamente le sumen o resten una constante a la respuesta, sino que algunos de los suelos magnifiquen o atenúen las diferencias entre fertilizantes. Esta condición suele ser corregible mediante la aplicación de transformaciones (cf. sección 6.5).
La interacción por cambios de orden (figura 7.9 (b)) es considerablemente más compleja, tanto conceptualmente como en su manejo. Sin embargo, un análisis juicioso durante la etapa de planeación puede anticipar algunos de tales escenarios.
Supóngase que se desean evaluar diferentes variedades de café en un rango altitudinal entre 1000 y 2500 m s. n. m. Con el fin de evitar que la altitud actúe como factor de confusión, podría considerarse un esquema de aleatorización en el que se tome el piso altitudinal como factor de bloqueo. Podría suceder, sin embargo, que las variedades con mejor desempeño en el margen altitudinal superior fueran las de peor desempeño en el inferior y viceversa.
Esta situación es bastante conocida por ingenieros agrónomos y fitomejoradores; se denomina interacción genotipo-ambiente. Esto significa que la expresión fenotípica está mediada en muchas ocasiones por las condiciones ambientales.
En un escenario como este sería poco pertinente elegir la mejor variedad promedio, puesto que con ello no se estarían recogiendo las particularidades de cada ambiente, pudiendo suceder incluso que dicha variedad no fuera óptima para ninguno de los ambientes considerados (cf. precaución 2.1).
En casos como este, podría resultar preferible un experimento que permita generar recomendaciones específicas por sitio, mediante el reconocimiento del piso altitudinal como efecto fijo, manejado en condiciones análogas a las variedades (cf. capítulo 10).
La experiencia, conjugada con el conocimiento y las expectativas basadas en procesos similares, constituye la mejor guía en la etapa de planeación.
Si la intuición sugiere que las respuestas de los tratamientos no serán consistentes entre bloques, es preferible elegir otro modelo.
Considérese ahora una situación en la que se decide realizar una evaluación sensorial de quesos mediante un panel no entrenado, bloqueando por panelista. Una de las particularidades de esta hipotética situación es la comparación entre quesos maduros y quesos rellenos de arequipe. La otra particularidad es que el panel está conformado por niños y por adultos.
No es difícil prever que en una situación como la descrita, los niños otorgarán las más altas valoraciones a los quesos rellenos de arequipe y las más bajas a los quesos maduros. En contraste, los adultos podrían asignarles las valoraciones más bajas a los quesos rellenos de arequipe —por encontrarlos hostigantes— y las más altas a los quesos maduros, por su complejidad.
Se estaría, pues, ante un claro escenario de interacción entre bloques y tratamientos, en el que las diferencias entre tratamientos no son consistentes entre bloques. Obviamente, no existiría un queso promedio que satisficiera las preferencias de los distintos grupos.
También resulta obvio que ningún profesional de la industria alimentaria diseñaría un ensayo como el descrito, en el que se comparen quesos de líneas completamente diferentes, dirigidos a distintas poblaciones objetivo.
Un estudio razonable compararía quesos de la misma línea o de líneas similares, dirigidos a una población objetivo particular.
Esta reflexión constituye la clave para definir el curso de acción en muchos ensayos en los que surge interacción bloques-tratamientos por cambio de orden: puede ser necesario segmentar la población.
Debe precisarse, sin embargo, que esta estrategia no siempre es viable. En los dos hipotéticos ejemplos desarrollados anteriormente, los niveles del factor de bloqueo no son etrictamente aleatorios.
Si se considera un piso altitudinal particular, por ejemplo, 1500 m s. n. m., podrán obtenerse réplicas del mismo y generar conclusiones válidas para dicho piso altitudinal en otros sitios con condiciones comparables.
Asimismo, en el ejemplo de evaluación sensorial de quesos, los niños representan una subpoblación particular, diferente de la subpoblación de los adultos. Las diferencias en percepción entre niños y adultos son intrínsecas a la edad y van más allá de las diferencias en percepción esperables entre panelistas entrenados.
En contraste, hay situaciones en las que el factor de bloqueo sí es completamente aleatorio y sus niveles son irreplicables. Esto sucede, por ejemplo, cuando se bloquea con base en el tiempo en estudios que deben fraccionarse.
Supóngase que —por la agenda del laboratorio— los niveles de bloqueo son lunes, viernes y sábado de una semana particular. Bien podría suceder que, si el ensayo exigiera un mayor número de réplicas, también se ejecutaran fracciones del ensayo el lunes, viernes y sábado de la siguiente semana. Aunque pareciera que los momentos quedaron replicados, no es así. En casos como este, el nombre del día de la semana es una mera etiqueta; lo que realmente se está bloqueando son las condiciones (insumos, equipos, operarios, condiciones ambientales) de un grupo particular de ejecuciones. En tal sentido, las ejecuciones que se realicen el viernes de la primera semana no estarán más relacionadas con las del viernes de la siguiente semana de lo que podrán estarlo con cualquier otro conjunto de corridas.
Si en un escenario como el descrito, en el que se tenga un factor de bloqueo completamente aleatorio, con niveles irreplicables, se observan resultados inconsistentes entre bloques, la validez interna del ensayo estaría en cuestión. En estos casos, lo más prudente sería repetir el ensayo.
La anterior exposición puede dejar la sensación de que la interacción es algo indeseable, que es necesario evitar a toda costa o corregir si estuviera presente. Y en efecto, así es en el modelo de bloques al azar y sus extensiones.
No obstante, en los modelos que se desarrollan en el capítulo 10, la interacción entre factores es perfectamente esperable, admisible e interpretable, sin que se requiera siquiera “corregirla” si estuviera presente.
La aditividad o no interacción entre bloques y tratamientos implica que las diferencias entre tratamientos sean coherentes entre bloques. En tales casos, el modelo de ANOVA permite extraer el efecto de bloques y realizar comparaciones promedio entre tratamientos.
Las interacciones por cambios en magnitud a menudo pueden corregirse mediante la aplicación de alguna transformación.
Las interacciones por cambios en orden pueden exigir la segmentación de la población o la repetición del ensayo.
La descomposición de la variabilidad total en diferentes fuentes sigue la misma lógica que en el esquema de aleatorización completamente al azar (cf. sección 6.2.2 y ejemplo 7.1).
Pero en el modelo de bloques al azar también se obtiene una suma de cuadrados para los bloques. Este componente permite extraer del error experimental la variabilidad aportada por los bloques, lo que potencialmente incrementa la sensibilidad del ensayo para detectar diferencias entre tratamientos.
A continuación se presentan las fórmulas operacionales de las sumas de cuadrados para el modelo de bloques completos al azar.
\[
\begin{align}
\text{SCT}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
\text{SCttos}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
\text{SCb}&=\frac{\sum\limits_{j=1}^r{Y_{\bullet j}^2}}{k}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
\text{SCE}&=\text{SCT}-\text{SCttos}-\text{SCb}
\end{align}
\tag{7.2}\]
En situaciones de desbalance producidas por tratamientos con diferente número de réplicas, la prueba de Levene es inadecuada para evaluar homogeneidad de varianzas.
O’Neill y Mathews (2000) elaboran un marco teórico basado en mínimos cuadrados ponderados (WLS por sus siglas en inglés: Weighted Least Squares), cuyo desempeño es adecuado, tanto en escenarios desbalanceados como balanceados. Este enfoque permite modelar la estructura de covarianza real de los residuales, que difiere de la matriz identidad impícitamente asumida en la prueba clásica.
Este marco teórico se emplea para construir una propuesta generalizada de la prueba de Levene, extensible a modelos con efectos aleatorios y con estructura factorial de los tratamientos (O’Neill y Mathews 2002).
Aunque en secciones previas se ilustró la prueba de Brown-Forsythe —basada en desviaciones respecto a la mediana— por su simplicidad conceptual y robustez, en adelante se adopta la formulación general propuesta por O’Neill y Mathews, basada en el marco original de Levene y extensible a modelos experimentales más complejos.
La propuesta parte del ajuste de un modelo mediante WLS, usando como respuesta el valor absoluto de los residuales estandarizados y manteniendo las mismas predictoras del modelo original.
El uso de los residuales estandarizados —en lugar de los originales— es lo que permite eliminar la dependencia del diseño en las expectativas de los residuales, asegurando que la prueba se centre exclusivamente en la varianza.
En este caso, la homocedasticidad no se evalúa de manera global, sino sobre cada uno de los efectos del modelo. Esta individualización permite un diagnóstico más acertado, lo que puede sugerir vías de acción específicas.
Los autores ilustran que —para el caso balanceado—, el procedimiento basado en WLS coincide con la aplicación de unas constantes multiplicativas \((m)\) sobre los estadísticos de prueba obtenidos del ajuste de un modelo mediante mínimos cuadrados ordinarios (OLS por sus siglas en inglés: Ordinary Least Squares), tomando como respuesta los valores absolutos de los residuales estandarizados con las mismas predictoras del modelo original.
No obstante, el procedimiento más general —válido tanto para escenarios balanceados como desbalanceados— parte directamente del modelo basado en WLS. Esto exige el uso de álgebra matricial y la obtención de sumas de cuadrados secuenciales.
La heterocedasticidad puede surgir por valores erróneos en la base de datos. Si este fuera el caso, habría que corregir los correspondientes datos o retirarlos.
En muchas ocasiones, los problemas de heterocedasticidad se corrigen mediante la aplicación de transformaciones. En tales casos, pueden aplicarse los procedimientos estándares: ANOVA seguido de procedimientos de comparación múltiple basados en el cuadrado medio del error.
Cuando la heterocedasticidad es causada por algún tratamiento particular o por un nivel específico de algún factor, el usuario podría considerar la segmentación del ensayo omitiendo el tratamiento o el factor problemático del análisis.
Cuando la heterocedasticidad no es causada por datos erróneos, no es corregible mediante transformaciones y no desea segmentarse el ensayo, puede realizarse un ANOVA de Welch (cf. sección 6.4), seguido de algún procedimiento de comparación múltiple específico para escenarios de heterocedasticidad (cf. sección 8.16).
Asimismo podrá considerarse el uso de métodos inferenciales no paramétricos (cf. capítulo 9).
La función personalizada levene_g implementa la prueba generalizada de Levene propuesta por O’Neill y Mathews, que admite modelos balanceados o desbalanceados, con esquema de aleatorización completamente al azar, en bloques o en cualquiera de sus generalizaciones, para tratamientos de una o de múltiples vías.
La evaluación formal de la aditividad se realiza mediante el contraste del siguiente juego de hipótesis:
\[
H_0:\gamma_{ij}=0\quad\text {Aditividad (no interacción)}
\] \[
H_a:\gamma_{ij} \ne 0\quad\text {No aditividad (interacción)}
\]
\(\gamma_{ij}\) representa el término de interacción entre bloques y tratamientos.
Aunque parezca curioso hipotetizar sobre un término que no forma parte del modelo (cf. expresión 7.1), ello cobra sentido si se tiene en cuenta el valor de la hipótesis nula.
El hecho de que el modelo 7.1 no incluya el término de interacción entre bloques y tratamientos es equivalente a exigir que dicho término sea cero.
En escenarios de hipótesis alternativa, el modelo 7.1 estaría inadecuadamente especificado.
Un modelo de una vía con esquema de aleatorización en bloques al azar que incorpora interacción entre bloques y tratamientos tiene la siguiente forma:
\[
Y_{ij}=\mu+\tau_i+\beta_j+\gamma_{ij}+\varepsilon_{ij},\ i=1, \dotsc, k;\quad j=1, \dotsc, r
\tag{7.3}\]
Šimeček y Šimečková (2013) indican que la interacción, representada por el término \(\gamma_{ij},\) puede tener diferentes modalidades de expresión:
A. \(\gamma_{ij}=k \tau_i\beta_j\), donde \(k\) es una constante real.
B. \(\gamma_{ij}=k \tau_i\delta_j\), donde \(\delta_j \thicksim N(0,\, \sigma_\beta^2),\) independientes de \(\beta_j\) y \(\epsilon_{ij},\) siendo \(k\) una constante real.
La modalidad \(\text{A}\) corresponde a interacciones de tipo multiplicativo, como las representadas en la figura 7.9 (a). Las modalidad \(\text{B}\) —al incorporar una variable aleatoria— permite representar un espectro más amplio de interacciones, incluyendo ciertos escenarios de interacción por cambio de orden como los representados en la figura 7.9 (b).
Uno de los procedimientos más utilizados para evaluar interacción entre bloques y tratamientos es la prueba de aditividad con un grado de libertad de Tukey (Tukey 1949).
Esta prueba se basa en la obtención de una suma de cuadrados asociada a la interacción entre bloques y tratamientos:
\[
\text{SCb.ttos}=\frac{\left(\sum\limits_{i=1}^k\sum\limits_{j=1}^r Y_{ij}\left(\overline{Y}_{i\bullet}-\overline{Y}_{\bullet\bullet}\right) \left(\overline{Y}_{\bullet j}-\overline{Y}_{\bullet\bullet}\right)\right)^2}
{\sum\limits_{i=1}^k\left(\overline{Y}_{i\bullet}-\overline{Y}_{\bullet\bullet}\right)^2 \sum\limits_{j=1}^r\left(\overline{Y}_{\bullet j}-\overline{Y}_{\bullet\bullet}\right)^2}
\]
Esta suma de cuadrados —que tiene asociado un grado de libertad— se le descuenta a la \(\text{SCE},\) dando lugar a la denominada suma de cuadrados del error reducida:
\[
\text{SCE}_\text{red}=\text{SCE}-\text{SCb.ttos}
\]
Asimismo, a la \(\text{SCE}\) se le descuenta el grado de libertad transferido a la \(\text{SCb.ttos}.\) Por tanto,
\[
\text{gle}_\text{red}=\text{gle}-1=n-r-k
\]
El estadístico de prueba se construye como la razón entre los cuadrados medios de la interacción y del error reducido. Si el cuadrado medio asociado a la interacción es grande en relación con la variabilidad residual restante, se obtendrán valores elevados del estadístico \(F\), lo que constituye evidencia contra la aditividad:
\[
F_\text{c}=\frac{\text{CMb.ttos}}{\text{CME}_\text{red}}
=\frac{\text{SCb.ttos}/1}{\text{SCE}_\text{red}/(n-r-k)}
\overset{H_0}\thicksim F_{(1,\,n-r-k)}
\]
En un estudio de simulación realizado por Šimeček y Šimečková (2013), en el que se compararon seis pruebas (Tukey, Mandel, Johnson-Graybill, LBI, Tusell y Tukey modificada), la prueba de aditividad de Tukey con un grado de libertad exhibió el mejor desempeño en los escenarios de interacción tipo \(\text{A}\) (interacción multiplicativa). Sin embargo, su desempeño fue bastante pobre en escenarios de interacciones tipo \(\text{B}\) (interacciones complejas), donde las pruebas LBI y Johnson-Graybill exhibieron los mejores desempeños.
El desempeño diferencial de la prueba de Tukey en los escenarios evaluados resulta esperable, si se tiene en cuenta que la \(\text{SCb.ttos}\) se construye a partir de los productos cruzados de las desviaciones de las medias de los tratamientos y de los bloques con respecto a la media general. Esto permite detectar eficientemente las interacciones de tipo multiplicativo, pero no las interacciones más complejas.
Las pruebas LBI (por sus siglas en inglés: Locally Best Invariant) y Johnson-Graybill —que exhibieron los mejores desempeños en los escenarios de interacciones complejas— parten de un marco conceptual diferente.
Las combinaciones entre los diferentes niveles de tratamientos y bloques se organizan en una matriz \(k \times r\). Tras ajustar el modelo del ANOVA, se obtiene una matriz de residuales \(R\) con la misma estructura.
Puesto que los residuales se obtienen eliminando el efecto de los bloques y los tratamientos8, la matriz \(R\) contiene información sobre la variación aleatoria y el efecto de la interacción si estuviera presente. En tal sentido, \(R\) se convierte en una estimación observable de la interacción.
La matriz \(RR'\) —cada uno de cuyos elementos está conformado por el producto interno de los perfiles residuales de los diferentes tratamientos— representa el grado de similitud de los patrones residuales de los tratamientos considerados.
No obstante, bajo aditividad, los residuales deberían representar variación aleatoria, en lugar de variación sistemática, por lo que los patrones residuales no deberían exhibir similitud entre sí.
En escenarios de interacción, la variabilidad residual tiende a concentrarse en unas pocas direcciones dominantes, lo que se refleja en la presencia de uno o varios autovalores considerablemente mayores que los demás.
Tanto la prueba de Johnson-Graybill como la LBI se basan en los autovalores escalados de la matriz \(RR',\) definidos así:
\[
\omega_i=\frac{\lambda_i }{\sum\limits_{i=1}^{\mathrm{mín}(k,\, r)-1}\lambda_i}, \quad i=1, 2,\dotsc , \mathrm{mín}(k,\, r)-1
\]
El estadístico de la prueba de Johnson-Graybill es \(\omega_1,\) definido como el máximo \(\omega_i.\)
El estadístico para la prueba LBI es:
\[
\sum\limits_{i=1}^{\mathrm{mín}(k,\, r)-1}\omega_i^2
\]
Valores elevados de los estadísticos indican que la variabilidad residual presenta estructura sistemática incompatible con el supuesto de aditividad. ***
Buscando una prueba que se desempeñe adecuadamente en los diferentes escenarios de interacción definidos previamente mediante las modalidades \(\text{A}\) y \(\text{B},\) Šimeček y Šimečková (2013) sugieren una modificación de la prueba de aditividad de Tukey.
Los autores argumentan que —dado que la dependencia de los \(Y_{ij}\) con los parámetros del modelo 7.3 no es lineal— los parámetros deben estimarse mediante métodos de regresión no lineal. Seguidamente, comparan el modelo completo (con interacción) contra el modelo reducido (sin interacción) mediante una prueba de razón de verosimilitud.
La probabilidad de rechazo de esta prueba se infla cuando hay pocos tratamiento o bloques (aproximadamente menos de 20). En tales casos, los autores sugieren aplicar una corrección basada en permutaciones o remuestreo.
Los estudios de simulación realizados por estos autores muestran que su propuesta funciona tan bien como la prueba original de Tukey en los escenarios de interacción tipo \(\text{A}\) y supera notablemente su desempeño en los escenarios de interacción tipo \(\text{B}.\)
No obstante, su desempeño sigue siendo inferior al de pruebas como Johnson-Graybill y LBI en los escenarios de interacciones complejas.
Teniendo en cuenta lo anterior, aunado al hecho de que las interacciones tipo \(\text{B}\) evaluadas por los autores no necesariamente recogen toda la complejidad de interacciones de estructura arbitraria, no consideramos conveniente recomendar esta prueba como alternativa general para la evaluación de aditividad.
Kirk (1995) advierte sobre los alcances y limitaciones de la prueba de aditividad de Tukey, señalando que no permite detectar formas de interacción diferentes de la multiplicativa.
Esto ha dado lugar a que se popularicen recomendaciones como la que aparece en la documentación de la función tukey.add.test {asbio} para R, donde se sugiere el uso de un nivel de significancia conservador en el rango entre 0.1 y 0.25.
Teniendo en cuenta que la prueba de Tukey exhibe un adecuado desempeño en escenarios de interacciones multiplicativas y que su limitación no tiene que ver con una baja potencia uniforme, sino con la indetección de interacciones complejas, consideramos inapropiada esta solución.
Aunque sería ideal contar con una prueba universal capaz de detectar cualquier forma de interacción, resulta más razonable reconocer que diferentes estructuras de interacción conducen a diferentes preguntas inferenciales y, por ende, pueden exigir herramientas diagnósticas distintas.
Partiendo de esta consideración y de los resultados de las simulaciones realizadas por Šimeček y Šimečková (2013), se propone emplear la prueba clásica de Tukey para detectar interacción de tipo multiplicativo, y la prueba LBI para interacciones complejas.
La prueba de Tukey busca una estructura dominante de interacción multiplicativa, mientras que pruebas espectrales como Johnson-Graybill y LBI buscan desviaciones más generales respecto a la aditividad.
Aunque las pruebas de Johnson-Graybill y LBI exhibieron un comportamiento comparable en las simulaciones realizadas por Šimeček y Šimečková (2013), la prueba de Johnson-Graybill, al estar basada en el mayor autovalor, puede resultar muy sensible a una única dirección dominante, mientras que la prueba LBI, al emplear un estadístico basado en todos los autovalores, potencialmente podría recoger de mejor manera estructuras de interacción de mayor complejidad.
La tabla 7.6 resume los posibles cursos de acción acorde con las posibles combinaciones de significancia de ambas pruebas.
| Significancia Tukey | Significancia LBI | Interpretación y recomendaciones |
|---|---|---|
| No | No | No hay evidencia detectable de violación del supuesto de aditividad. No se requieren acciones adicionales. |
| Sí | No | Interacción multiplicativa. Evaluar la aplicación de transformaciones. |
| No | Sí | Interacción compleja. Evaluar la naturaleza de la interacción y la posible segmentación de la población. |
| Sí | Sí | Hay evidencia de una interacción multiplicativa dominante. Evaluar la aplicación de transformaciones. |
Puede parecer extraño que la significancia de LBI sin significancia de Tukey se caracterice como una situación más delicada que la significancia de ambas pruebas que se caracteriza de igual manera que el escenario en el que solamente es significativa la prueba de Tukey. Esto, sin embargo, tiene su razón de ser.
La prueba LBI no solamente detecta interacciones complejas, sino también interacciones de tipo multiplicativo, aunque con menor potencia que la prueba de Tukey. Luego, un escenario en el que ambas pruebas exhiban significancia sugiere la presencia de una componente multiplicativa dominante. Posiblemente podrá encontrarse una transformación que permita superar esta situación.
En contraste, los escenarios en los que únicamente resulte significativa la prueba LBI muy probablemente serán evidencia de interacciones complejas que no sean superables mediante transformaciones y que exijan una aproximación diferente, acorde con las consideraciones que surjan de la aleatoriedad o no del factor de bloqueo, tal y como se discutió anteriormente.
Todas las pruebas mencionadas en esta sección están implementadas en el paquete additivityTests (2024). Las funciones de este paquete requieren que el argumento principal sea una matriz organizada por bloques y tratamientos. Este formato no suele formar parte del flujo de trabajo habitual cuando se ajustan modelos de ANOVA en R.
La función personalizada additivity_tests admite como argumento un objeto de las clases aov o lm y ejecuta las pruebas de Tukey y LBI mediante la las funciones additivityTests::tukey.test y additivityTests::lbi.test, respectivamente. Los resultados de ambas pruebas se consolidan en una única tabla de resumen.
Ejemplo 7.2
En un estudio realizado por Palomino (1966), se evaluó el rendimiento en aceites esenciales (kg/ha) de seis especies de menta, utilizando un esquema de aleatorización en bloques completos al azar con tres réplicas.
A continuación se relacionan las especies evaluadas, asignándoles una etiqueta para posterior referencia:
| Especie | Tratamiento |
|---|---|
| Menta arvensis | A |
| Menta sativa | B |
| Menta pulegium | C |
| Menta piperita | D |
| Menta spicata | E |
| Menta rotundifolia | F |
La figura 7.10 presenta un posible esquema de aleatorización espacial para este experimento.
Los datos observados se organizan en la tabla 7.7.
| Tratamiento | Bloque | \(Y_{i\bullet}\) | \(\overline{Y}_{i\bullet}\) | ||
|---|---|---|---|---|---|
| I | II | III | |||
| A | 63.07 | 55.37 | 33.68 | 152.12 | 50.71 |
| B | 51.70 | 57.20 | 33.43 | 142.33 | 47.44 |
| C | 129.39 | 93.78 | 80.46 | 303.63 | 101.21 |
| D | 141.25 | 106.87 | 67.07 | 315.19 | 105.06 |
| E | 52.98 | 40.11 | 29.80 | 122.89 | 40.96 |
| F | 62.69 | 57.68 | 40.32 | 160.69 | 53.56 |
| \(Y_{\bullet j}\) | 501.08 | 411.01 | 284.76 | 1196.85 | |
Las sumas de cuadrados se calculan utilizando las fórmulas operativas relacionadas en las expresiones 7.2.
Inicialmente se calcula el término de corrección:
\[
C=\frac{Y_{\bullet\bullet}^2}{n}=\frac{1196.85^2}{18}=79580.55125
\]
La suma de cuadrados total es:
\[
\begin{align}
\text{SCT}&=\sum\limits_{i=1}^k\sum\limits_{j=1}^r{Y_{ij}^2}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
&=63.07^2+51.70^2+\dotsb+40.32^2-C\\[1.4em]
&=17727.62\\[1.4em]
\end{align}
\]
La suma de cuadrados de tratamientos es: \[
\begin{align}
\text{SCttos}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet}^2}}{r}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
&=\frac{152.12^2+ \dotsc +160.69^2}{3}-C\\[1.4em]
&=12371.94
\end{align}
\]
La suma de cuadrados de bloques es: \[
\begin{align}
\text{SCb}&=\frac{\sum\limits_{j=1}^r{Y_{\bullet j}^2}}{k}-\frac{Y_{\bullet\bullet}^2}{n}\\[1.4em]
&=\frac{501.08^2+ \dotsc + 284.78^2}{6}-C\\[1.4em]
&=3935.89
\end{align}
\]
La suma de cuadrados del error se obtiene por diferencia:
\[
\begin{align}
\text{SCE}&=\text{SCT}-\text{SCttos}-\text{SCb}\\[1.4em]
&=1419.79
\end{align}
\]
Los grados de libertad se obtienen de manera análoga a los del modelo de ANOVA de una vía completamente al azar:
\[
\begin{align}
\text{glT}&=n-1=17\\[1.4em]
\text{glttos}&=k-1=5\\[1.4em]
\text{glb}&=r-1=2\\[1.4em]
\text{gle}&=17-5-2=10
\end{align}
\]
La tabla 7.8 resume los diferentes componentes del ANOVA:
| Fuentes de variación | Grados de libertad | Sumas de cuadrados | Cuadrados medios | Estadístico \(F\) | Valor p |
|---|---|---|---|---|---|
| Bloques | 2 | 3935.89 | 1967.94 | 13.86 | 0.001309 |
| Tratamientos | 5 | 12371.94 | 2474.39 | 17.43 | 0.0001185 |
| Error | 10 | 1419.79 | 141.98 | ||
| Total | 17 | 17727.62 |
En el modelo de bloques completos al azar, el juego de hipótesis relevante es el que contrasta las medias de los tratamientos. Para el presente caso:
\[
\mu_\text{A}=\mu_\text{B}=\mu_\text{C}=\mu_\text{D}=\mu_\text{E}=\mu_\text{F}
\]
Para la evaluación de este contraste, se emplea el estadístico de prueba construido como la razón entre el \(\text{CMttos}\) y el \(\text{CME}.\) Puesto que el valor p asociado con este estadístico es menor que 0.05 (p = 0.0001185), se rechaza la hipótesis nula, concluyéndose, por tanto, que el rendimiento medio en aceites esenciales no es igual en todas las especies evaluadas.
Resulta tentador realizar un procedimiento análogo para los bloques, empleando la razón entre el \(\text{CMb}\) y el \(\text{CME},\) máxime que ya aparece en las salidas de R (atenuado en la tabla 7.8).
Sin embargo, este procedimiento generalmente no es válido.
El bloqueo se conceptualiza como una estrategia de control de fuentes de variación secundarias, de manera que los tratamientos sean comparables.
En muchas ocasiones, tales fuentes de variación conglomeran condiciones experimentales aleatorias que ni son de interés ni son reproducibles, tales como la variabilidad asociada con material experimental, condiciones ambientales, suelos, equipos, operarios, etc.
El usuario ni siquiera fija los niveles de bloqueo con el propósito de compararlos, sino que estos surgen de condiciones experimentales circunstanciales.
En consecuencia, los bloques, no cuentan con verdaderas réplicas ni son replicables. La replicación exige que cada nivel del factor considerado se evalúe en unidades experimentales independientes (cf. definición 6.10).
La inspección de un esquema de aleatorización como el de la figura 7.10, en el que las unidades experimentales que conforman cada bloque no surgen de un proceso de aleatorización, sino de la vecindad espacial, evidencia condiciones que inducen dependencia entre las unidades experimentales dentro de cada bloque.
Aun cuando el criterio de bloque no se basa en vecindad espacial, el carácter circunstancial o único de los bloques los hace irreplicables.
En un ensayo en el que se bloqueara con base en el lote de leche utilizado para la preparación de un producto lácteo, sería imposible reproducir a futuro alguno de los lotes empleados en el primer ensayo.
Lo mismo sucede cuando se bloquea con base en el tiempo en experimentos que así lo exijan. Cada momento representa el conjunto de condiciones particulares en las que se ejecuta una réplica dada. Por el carácter aleatorio de tales condiciones, se hace imposible replicarlas a futuro.
Podría pensarse que, en los ensayos de evaluación sensorial en los que se bloquea con base en los panelistas, sí es posible obtener réplicas futuras. En tales casos, aun considerando que los futuros ensayos se realizaran con un panel conformado exactamente por los mismos miembros (que no tendría que ser así), las particularidades de cada panelista impiden conceptualizar las futuras evaluaciones de un panelista particular como evaluaciones independientes.
Habrá casos en los que el carácter aleatorio de los bloques no es tan marcado, como en el hipotético ejemplo en el que se evalúan diferentes productos para el control de la hormiga arriera, bloqueando con base en el tamaño del hormiguero.
Aunque la elección inicial de los tamaños pueda resultar un tanto circunstancial, podrían obtenerse futuras réplicas de esos mismos tamaños, además de que no habría limitaciones de dependencia entre los componentes de un bloque por vecindad espacial.
En efecto, en casos como este, el factor de bloqueo estaría actuando prácticamente en las mismas condiciones que los tratamientos, por lo que podría generarse un análisis equivalente.
Si el usuario tuviera particular interés en comparar los niveles de dicho factor, lo más aconsejable sería diseñar el experimento con base en una estructura factorial en la que se crucen los niveles de los diferentes factores y se evalúe la interacción entre estos (cf. capítulo 10).
¿Y, entonces, por qué aparece en las salidas de R?
El procedimiento aov para R, que encapsula modelos lm, no diferencia entre efectos fijos y aleatorios. Todos los factores que se especifican en la parte derecha de la fórmula (~ ...) se procesan de la misma forma.
En las funciones empleadas para el ajuste de modelos mixtos (cf. ?sec-mixed) sí se diferencian explícitamente los efectos fijos de los efectos aleatorios, lo que permite un procesamiento diferenciado.
En R, el modelo del ANOVA se ajusta mediante la función aov{stats}. Aunque el orden de los factores es irrelevante para el ajuste del modelo, no lo es para las funciones personalizadas check_model, levene_g y additivity_tests: el factor de bloqueo se escribe antes que los tratamientos.
En modelos de ANOVA con más de un efecto es necesario escribir inicialmente los factores de bloqueo (o sus extensiones) y luego los tratamientos.
La validez de los resultados generados por las funciones personalizadas check_model, levene_g y additivity_tests depende de este orden.
El siguiente script ajusta el modelo de ANOVA de una vía con esquema de aleatorización en bloques completos al azar para los datos de la tabla 7.7, los cuales están contenidos en el archivo Excel ejemplo 7.2.xlsx:
data <- readxl::read_excel("ejemplo 7.2.xlsx")
data <- transform(data,
bloques = factor(bloques),
ttos = factor(ttos))
anova <- aov(rend ~ bloques + ttos, data = data)
summary(anova) Df Sum Sq Mean Sq F value Pr(>F)
bloques 2 3936 1968 13.86 0.001309 **
ttos 5 12372 2474 17.43 0.000119 ***
Residuals 10 1420 142
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1A continuación se evalúan los supuestos del modelo. La manera más rápida y recomendada de evaluar normalidad y homocedasticidad es mediante el uso de la función personalizada check_model (cf. sección 6.6):
source("check_model.R")
check_model(anova)Resumen de modelos
transformación p (S-W) p (Levene) monótona
tr0: rend 1.0000 0.2184 sí
tr1: log(rend) 0.6386 0.8576 sí
tr2: log(rend + 100) 0.9872 0.5889 sí
tr3: (rend) ^ -0.1 0.8738 0.8534 sí
tr4: (rend + 100) ^ -1.9 0.8534 0.8446 sí
tr5: (rend + 0) ^ -0.19 0.9567 0.8431 síEl diagnóstico del modelo de ANOVA de una vía con esquema de aleatorización en bloques al azar para la variable respuesta en escala original \((\text{tr0})\) no evidencia desviaciones severas del supuesto de normalidad \((\text{p} = 1.0000),\) ni del supuesto de homocedasticidad (el menor de los valores p asociado a los efectos del modelo fue 0.2184).
Aunque en el presente ejemplo, este diagnóstico es suficiente para la evaluación de estos dos supuestos, se presentan los resultados completos de la prueba generalizada de Levene (cf. sección 7.2.2), en la que se incluyen los dos efectos del modelo:
source("levene_g.R")
levene_g(anova)Prueba generalizada de Levene
gl Fc valor p sig.
bloques 2 1.7785 0.2184
ttos 5 0.7477 0.606
Error 10 Para el modelo de bloques al azar es necesario evaluar adicionalmente el supuesto de aditividad. Para ello se emplea la función personalizada additivity_tests (cf. sección 7.2.3):
source("additivity_tests.R")
additivity_tests(anova)Pruebas de aditividad de Tukey y LBI
Estadístico V. crítico Valor p Decisión
Tukey 17.2508844 5.117355 0.0024718 rechaza H0
LBI 0.7638555 0.886827 No rechaza H0Se evidencia una interacción significativa entre bloques y tratamientos. Dado que únicamente la prueba de Tukey resultó significativa, la interacción observada parece corresponder a una estructura predominante multiplicativa, susceptible de corregirse mediante alguna transformación.
Cualquiera de las transformaciones generadas por check_model podría ser viable para continuar el análisis, dado que ninguna induce problemas de normalidad u homocedasticidad. Sin embargo, aún es necesario verificar si alguna logra corregir la interacción entre bloques y tratamientos. Se evalúa inicialmente la más sencilla: la transformación logarítmica:
data$rend.t <- log(data$rend)
anova <- aov(rend.t ~ bloques + ttos, data = data)En general, cada vez que se aplica una transformación se hace necesario evaluar nuevamente todos los supuestos. Sin embargo, en el presente caso, se hace innecesaria la evaluación de normalidad y homocedasticidad.
Lo que sí debe verificarse es el efecto de la transformación sobre la interacción entre bloques y tratamientos:
source("additivity_tests.R")
additivity_tests(anova)Pruebas de aditividad de Tukey y LBI
Estadístico V. crítico Valor p Decisión
Tukey 0.09922948 5.1173550 0.7599372 No rechaza H0
LBI 0.54629105 0.8848958 No rechaza H0Ninguna de las pruebas de aditividad para el modelo ajustado con la variable transformada en escala logarítmica evidencia desviaciones de este supuesto.
A continuación se muestra el resumen del ANOVA ajustado sobre la varible transformada:
summary(anova) Df Sum Sq Mean Sq F value Pr(>F)
bloques 2 0.9557 0.4778 46.46 8.66e-06 ***
ttos 5 2.4341 0.4868 47.33 1.22e-06 ***
Residuals 10 0.1028 0.0103
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1El resultado del ANOVA para el model ajustado sobre la variable transformada, no difiere —en términos de significancia— del obtenido con la variable en la escala original.
A continuación se realizar todas las posibles comparaciones por pares, usando la prueba de Tukey (cf. sección 8.5):
agricolae::HSD.test(anova, "ttos", console = TRUE) rend.t groups
D 4.609294 a
C 4.597181 a
F 3.963320 b
A 3.891729 b
B 3.833822 b
E 3.685350 bFinalmente, se presentan el escenario general, mediante un diagrama de caja y bigotes por tratamiento:
with(data, plot(ttos, rend.t))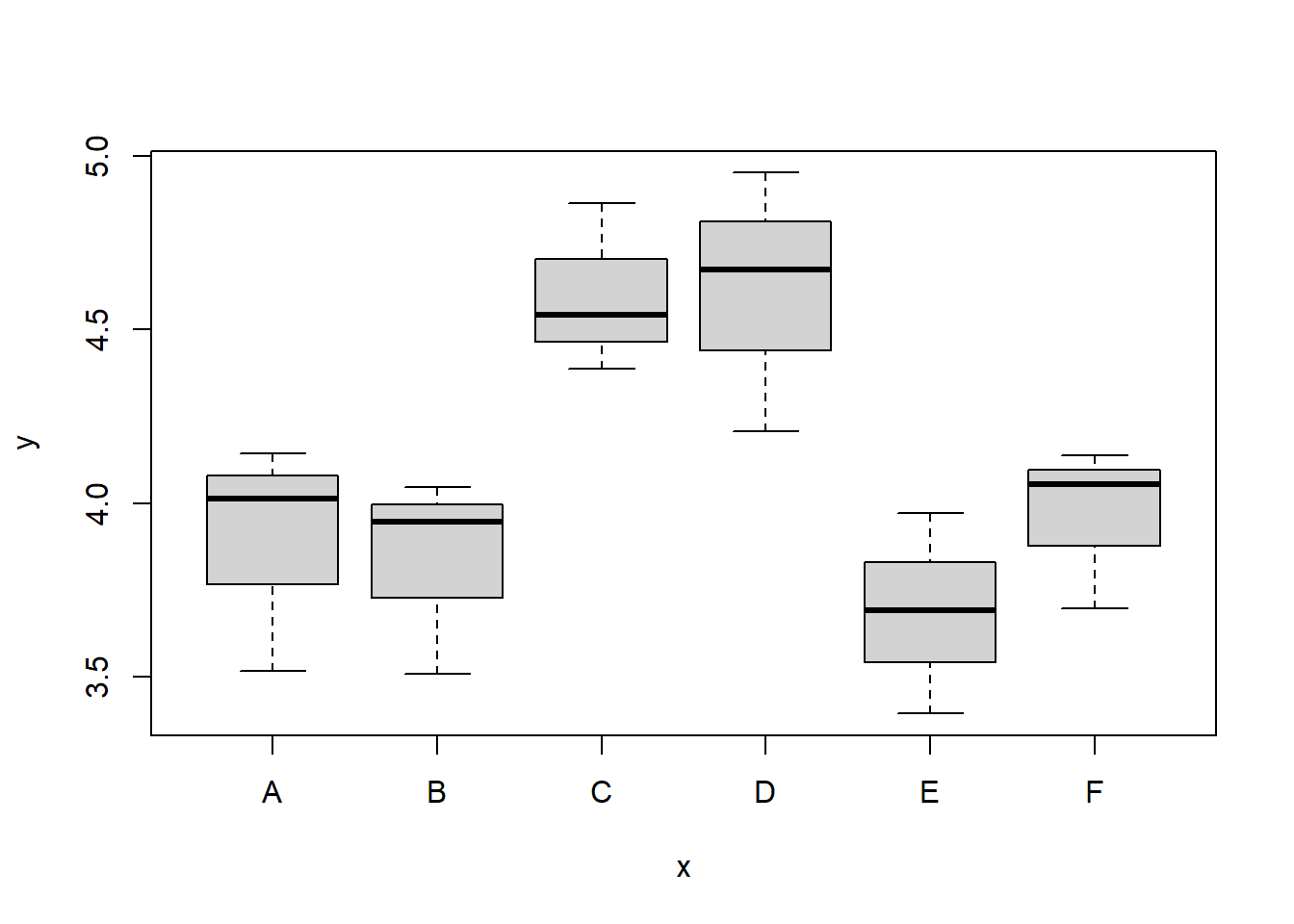
Es notoria la alta correspondencia entre los resultados de la prueba de Tukey y el diagrama de caja y bigotes. Sin embargo, dicha correspondencia no siempre tiene que presentarse con la misma claridad, especialmente cuando las diferencias entre tratamientos son pequeñas o la variabilidad es alta.
Debe tenerse presente, sin embargo, que todas las conclusiones deben basarse en los resultados de la prueba de Tukey, que es la que tiene carácter inferencial. El diagrama de caja y bigotes cumple una función descriptiva y de apoyo a la interpretación.
Este esquema de aleatorización resulta adecuado cuando —antes de realizar el experimento— se detectan o intuyen dos fuentes de variación adicionales a los tratamientos. En tal sentido, constituye una generalización del esquema de aleatorización en bloques.
Aunque podría emplearse cualquier etiqueta genérica para denominar las fuentes de variación circunstanciales —de manera análoga al uso que se hace del término bloques—, por sus orígenes en la experimentación agronómica, donde los niveles de estas fuentes quedaban organizados en las filas y columnas de un cuadro, estos fueron justamente los nombres que se adoptaron: filas y columnas.
Al tratarse de una extensión del esquema de aleatorización en bloques completos al azar, cada fila y cada columna debe contener el conjunto completo de tratamientos exactamente una vez.
El esquema de la figura 7.11 ilustra los conceptos de cuadro, filas, columnas y restricciones a la aleatorización.
Aunque pueden elaborarse variantes rectangulares, los cuadros latinos básicos son cuadrados: el número de filas es igual al número de columnas y de tratamientos. Un cuadro latino de lado \(k\) está conformado por \(k\) filas, \(k\) columnas y \(k\) tratamientos.
Cada una de las filas —etiquetadas en la figura 7.11 como \(F_1, \cdots, F_k\)— contiene el conjunto completo de tratamientos y a su vez se cruza con cada uno de los niveles del factor columna.
Cada una de las columnas —etiquetadas en la figura 7.11 como \(C_1, \cdots, C_k\)— contiene el conjunto completo de tratamientos y a su vez se cruza con cada uno de los niveles del factor fila.
El esquema de aleatorización completamente al azar no impone ninguna restricción para la asignación de los tratamientos a las unidades experimentales: cualquier tratamiento tiene la misma probabilidad de ser asignado a cualquiera de las unidades experimentales.
El esquema de aleatorización en bloques completos al azar impone una restricción: cada bloque debe contener el conjunto completo de tratamientos.
El esquema de aleatorización en cuadro latino debe satisfacer dos restricciones: cada fila y cada columna debe contener el conjunto completo de tratamientos.
Los esquemas de aleatorización basados en extensiones del cuadro latino —que son a su vez extensiones de los bloques completos al azar— imponen más de dos restricciones: cada fuente de variación debe contener el conjunto completo de tratamientos.
Una configuración en la que cualquier nivel de una fuente de variación —sea circunstancial o tratamientos— aparezca con todos los niveles de las demás fuentes, se denomina ortogonal.
La ortogonalidad de los esquemas de aleatorización en bloques completos al azar, cuadro latino y sus extensiones permite separar los diferentes efectos, haciendo comparables los tratamientos.
La aleatorización en cuadro latino y el sudoku comparten una arquitectura idéntica basada en la exclusión mutua y el equilibrio posicional de sus componentes.
En ambos escenarios, el espacio de trabajo se organiza en una matriz bidimensional donde rige la misma restricción fundamental: ningún elemento puede duplicarse dentro de una misma fila o columna.
Lo que en el sudoku funciona como una regla para restringir las opciones del jugador y forzar una solución única, en el cuadro latino actúa como un mecanismo para garantizar la ortogonalidad de las diferentes fuentes de variación.
Aunque la relación entre el cuadro latino y el sudoku pueda resultar fascinante para muchos, podría ser motivo de desasosiego para algunos otros ante la perspectiva de tener que establecer esquemas de aleatorización en cuadros de gran tamaño.
Obviando de momento las implicaciones logísticas derivadas de un experimento con un gran número de tratamientos, la generación de un cuadro latino aleatorizado para cualquier número de tratamientos puede realizarse de manera bastante sencilla.
La siguiente ilustración basada en un cuadro de lado 4 es extensible a cuadros de cualquier tamaño:
Organice alfabéticamente las etiquetas de los tratamientos en la primera fila.
En la segunda fila se empiezan a asignar los tratamientos organizados alfabéticamente a partir de la segunda casilla. Al llegar al final, el tratamiento faltante se asigna en la casilla vacía del comienzo.
Se repite el mismo procedimiento en la tercera fila y sucesivas, dejando \(j-1\) casillas libres al comienzo de la \(j\)-ésima fila, las cuales se llenan al final manteniendo el orden.
Este protocolo da lugar a un esquema como el siguiente:
Esta estrategia es aplicable para generar cuadros latinos ortogonales con cualquier número de tratamientos.
La permutación de filas y columnas modifica la disposición espacial del cuadro, pero conserva las restricciones estructurales que garantizan que cada tratamiento aparezca exactamente una vez en cada fila y en cada columna.
Las exigencias del cuadro latino podrían resultar muy restrictivas en experimentación agronómica, que fue su nicho original de aplicación.
Teniendo presente que las filas y las columnas son equivalentes conceptuales de los bloques, deben satisfacerse las mismas condiciones: máxima homogeneidad entre unidades experimentales que conforman un bloque (o una fila o una columna) con posible heterogeneidad entre bloques (o filas o columnas).
En ensayos agronómicos la estrategia de bloqueo es ampliamente utilizada cuando se detecta algún gradiente de variabilidad (pendiente, pedregosidad, suelos, fertilidad, humedad, etc.) para conformar grupos de unidades experimentales homogéneas con respecto a los niveles del gradiente y heterogéneas entre grupos.
Cuando se detecta en campo alguno de tales gradientes, la estrategia del bloqueo queda plenamente justificada y suele facilitar el control de los potenciales factores de confusión.
Un escenario equivalente basado en el cuadro latino exigiría detectar no solo una, sino dos fuentes de variación circunstancial, cuyos gradientes de variabilidad estuvieran configurados perpendicularmente en el terreno, como lo ilustra la figura 7.12.
Aunque la esquematización de una condición como la descrita es relativamente sencilla, no lo es tanto su satisfacción en campo.
Sería necesario partir de la detección de un gradiente —labor que no está exenta de complejidad aun para personal entrenado—. Simultáneamente, sería necesario detectar un segundo gradiente perpendicular al primero.
A la dificultad de la detección —aun para el personal mejor entrenado— hay que sumarle la baja plausibilidad de manifestación de tales patrones en las condiciones requeridas.
Suponiendo que en la figura 7.12 los diferentes tonos de color representaran, por ejemplo, un gradiente de humedad, sería muy poco probable la existencia de un gradiente perpendicular de pedregosidad, de fertilidad, de pendiente o de cualquier otro tipo.
En campo sería mucho más plausible encontrar gradientes que conglomeren una serie de factores asociados, en lugar de gradientes independientes por factor.
No obstante las limitaciones anotadas anteriormente, el esquema de aleatorización en cuadro latino, al ser una extensión de la estrategia de bloqueo, goza de la misma flexibilidad.
La aleatorización en cuadro latino no exige que el ensayo esté conformado por una serie de parcelas vecinas que conformen un cuadro.
La aleatorización en cuadro latino equivale a bloquear con base en dos criterios. Los criterios de bloqueo pueden ser tan amplios y flexibles como los discutidos en la sección 7.2.
Para ilustrar las posibilidades del cuadro latino como estrategia de doble bloqueo, considérese un estudio realizado por el Laboratorio de Osteología Antropológica y Forense de la Universidad de Antioquia, cuyo objetivo era comparar cuatro métodos para remover tejido blando de las piezas óseas, antes de su incorporación al laboratorio.
En adición al método —que constituye el factor principal, cuyos niveles se desean comparar— existen otras fuentes de variación.
La pericia de los operarios para la limpieza de las piezas no es homogénea. Algunos pueden realizar la labor de manera más rápida y preservando mejor las piezas que algunos otros. Es necesario, pues, bloquear, con base en la pericia diferencial de cada operario para evitar que actúe como factor de confusión.
Otra posible fuente de variación tiene que ver las características del donante. En este tipo de laboratorios se incorporan piezas óseas de donantes que han estado sometidos a diferentes condiciones ambientales durante distintos lapsos de tiempo. Por tanto, aunque las piezas óseas de un mismo donante puedan ser relativamente homogéneas, puede existir alta heterogeneidad entre donantes. En consecuencia, se hace necesario bloquear por donante, para evitar que las diferencias entre estos actúen como factor de confusión.
En este escenario se tienen tres fuentes de variación: método, operario y donante. El método es el factor principal, cuyos niveles se desean comparar. Los factores operario y donante son secundarios y se usan como factores de bloqueo. La asignación de las etiquetas filas y columnas a uno u otro de los factores secundarios es irrelevante. De hecho, durante la ejecución del ensayo no habrá ni filas, ni columnas, ni cuadro alguno.
No obstante, si se decidiera dibujar el esquema de aleatorización para su visualización, alguno de los factores secundarios quedará asignado a las filas del cuadro, el otro a las columnas, mientras que los niveles del factor método se aleatorizarán dentro del cuadro, acorde con las restricciones propias de este esquema (figura 7.11).
Aunque la ejecución del experimento en el laboratorio no conlleve filas, ni columnas, ni cuadro alguno, la figura 7.11 resulta útil para visualizar cómo cada uno de los factores secundarios contiene el conjunto completo de tratamientos, desempeñando el mismo papel que los bloques en el esquema de aleatorización en bloques completos al azar.
Nótese que cada donante recibe los cuatro métodos y que cada operario aplica igualmente los cuatro métodos. Esta condición garantiza que los efectos asociados con donantes y operarios puedan separarse del efecto del factor de interés.
El papel del operario es análogo al de los catadores en los estudios sensoriales, en los que se bloquea por catador. Por su parte, el papel del donante es análogo al de los lotes de material experimental que también se utilizan frecuentemente como factor de bloqueo.
Otra situación en la que resulta natural emplear el esquema de aleatorización en cuadro latino surge en los estudios crossover (o ensayos de tratamientos cruzados), en los que a cada individuo se le asignan —de manera consecutiva— los diferentes tratamientos, a lo largo de \(k\) periodos.
Esta alternativa es muy utilizada en ensayos pecuarios con número limitado de animales.
La figura 7.13 ilustra un posible esquema para la evaluación de cuatro tratamientos, utilizando cuatro individuos en cuatro periodos.
Al final del ensayo, cada tratamiento habrá sido evaluado en todos los periodos y sobre todos los individuos, cada individuo habrá realizado evaluaciones en todos los periodos y de todos los tratamientos, en cada periodo habrán participado todos los individuos y se habrán evaluado todos los tratamientos. Esta es la condición de ortogonalidad que permite separar los diferentes efectos.
Los tratamientos son fijados por el investigador y existe interés en comparar sus niveles. En contraste, los individuos y los períodos actúan como factores de bloqueo. Ninguno de ellos constituye el objeto principal de interés del estudio. Los individuos disponibles son circunstanciales y los períodos representan momentos de evaluación necesarios para la aplicación secuencial de los tratamientos, más que tiempos específicos cuyo efecto se desee comparar.
Aunque el esquema de la figura 7.13 es idéntico en apariencia al de la figura 7.11, los ensayos crossover tienen una particularidad que exige consideraciones adicionales.
En estos escenarios, los individuos no son meros instrumentos o aplicadores de tratamientos, sino que constituyen las unidades experimentales sobre las cuales se aplican y evalúan los tratamientos.
Esto obliga a considerar el efecto residual de los tratamientos (carryover effect), es decir, la manifestación remanente que un tratamiento pudiera exhibir en periodos posteriores al de su aplicación.
El efecto residual es inadmisible en los estudios crossover, dado que no permitiría discernir qué parte de la respuesta observada sobre un individuo en un periodo particular es atribuible al tratamiento evaluado en ese periodo y qué otra parte es atribuible al tratamiento o tratamientos administrados en los periodos previos.
El efecto residual puede tener diferentes manifestaciones: por residualidad propiamente dicha del tratamiento en el organismo tras el periodo de evaluación o por cambio de las condiciones del individuo.
Si se utilizara en esquema como el de la figura 7.13 para comparar el efecto cuatro medicamentos sobre el control de la mastitis, los medicamentos suministrados en un periodo determinado podrían permanecer en el organismo, generando confusión con los efectos observados en los periodos posteriores.
Asimismo, si el medicamento que se aplicara en un periodo particular resultara efectivo para el control de la mastitis, ello impediría evaluar el desempeño de los medicamentos suministrados en los periodos posteriores, aunque el medicamento que controló la enfermedad ya no estuviera presente en el organismo.
En un escenario como el descrito, en el que se espere efecto residual de los tratamientos, habría que considerar algún otro diseño experimental en el que cada individuo reciba un único tratamiento, siendo inapropiado el uso de ensayos crossover.
Si en lugar de medicamentos, se estuviera evaluando el efecto de diferentes suplementos alimentarios sobre la producción de leche, la situación podría ser manejable. En estos casos, desde luego, también existe un potencial efecto residual de los suplementos; sin embargo, se esperaría que fuera menos persistente que el de los medicamentos.
En este tipo de ensayos suelen considerarse periodos ampliados, de manera que en la primera parte pueda eliminarse el efecto residual del tratamiento suministrado en el periodo anterior. A este lapso temporal se le conoce como periodo de lavado (washout period). Al final del periodo, se realizan las lecturas que se espera que reflejen únicamente el efecto del tratamiento suministrado en ese periodo.
¿Qué tan amplio debe ser cada periodo y cómo debe distribuirse entre lavado y lectura? No es posible establecer una única respuesta válida para todas las situaciones. Esto debe establecerlo el especialista, teniendo en cuenta la fisiología de la especie estudiada y la naturaleza de los tratamientos.
Podría utilizarse un experimento en crossover para evaluar in vivo la degradabilidad de diferentes pastos, empleando animales fistulados9. En este caso —dado que los pastos no permanecen en el tracto digestivo de los individuos, sino que están en bolsas que se retiran al final del periodo— el riesgo de residualidad asociado al tratamiento es prácticamente inexistente.
Los ensayos crossover constituyen una familia amplia de diseños experimentales, con numerosas variantes y estrategias para el control del efecto residual. Una presentación detallada puede consultarse en Jones y Kenward (2014).
La simetría del cuadro latino hace fácil calcular el tamaño del experimento, así como los grados de libertad del error.
La tabla resumen del ANOVA correspondiente a un cuadro latino de lado \(k\) tiene la siguiente estructura:
| Fuentes de variación | Grados de libertad |
|---|---|
| Filas | \(k-1\) |
| Columnas | \(k-1\) |
| Tratamientos | \(k-1\) |
| Error | \(k^2-3k+2\) |
| Total | \(k^2-1\) |
La tabla 7.9 presenta el tamaño del experimento y los grados de libertad del error para ensayos estructurados con base en cuadros latinos en un rango de tratamientos entre 2 y 10.
| Número de tratamientos | Tamaño del experimento | Grados de libertad del error |
|---|---|---|
| 2 | 4 | 0 |
| 3 | 9 | 2 |
| 4 | 16 | 6 |
| 5 | 25 | 12 |
| 6 | 36 | 20 |
| 7 | 49 | 30 |
| 8 | 64 | 42 |
| 9 | 81 | 56 |
| 10 | 100 | 72 |
La tabla 7.9 evidencia que el cuadro latino resulta limitante cuando se tienen muchos o muy pocos tratamientos.
La evaluación de muchos tratamientos usando este esquema de aleatorización exige experimentos muy grandes, con el consiguiente incremento en costos y complejidad de manejo, lo que puede comprometer la eficiencia del ensayo.
Cuando se usa para evaluar muy pocos tratamientos, el número de grados de libertad de los que se dispone para estimar el error experimental es muy bajo, lo que da lugar a estimaciones con baja precisión y comparaciones con baja potencia (cf. numeral 2 de la nota 8.1).
Esto reduce el ámbito de uso eficiente de los cuadros latinos a un estrecho rango de tratamientos: no muchos para que el experimento no sea muy grande ni muy pocos para que los grados de libertad del error sean insuficientes.
Aunque el compromiso entre el número de réplicas y la eficiencia del ensayo se hace más evidente en el cuadro latino —por las restricciones que exigen que el número de filas sea igual al número de columnas y al número de tratamientos—, no es exclusivo de este esquema de aleatorización.
En general, un escaso número de réplicas implica una potencia limitada; muchas réplicas implican experimentos grandes, costosos y, por ende, ineficientes.
Esta situación es discutida por Mead, Gilmour y Mead (2012), quienes señalan que para obtener un buen estimador del error es necesario contar al menos con 10 grados de libertad.
Esta recomendación se hace tangible al observar la magnitud de los cambios entre los valores críticos superiores de la distribución \(t.\)
En la prueba de la diferencia mínima significativa, uno de los factores de la \(\text{DMS}\) es el valor crítico de la distribución \(t.\) Por tanto, la potencia de la prueba se relaciona de forma directa con su magnitud (cf. sección 8.4).
Para otros procedimientos de comparación múltiple, aunque los valores críticos estén basados en otras distribuciones, se mantiene la misma lógica: pocos grados de libertad dan lugar a valores críticos mayores y, en consecuencia, a pruebas menos potentes.
La tabla 7.10 presenta los valores críticos superiores de la distribución \(t\) para pruebas de dos colas, con \(\alpha=0.05,\) para un rango de grados de libertad entre 1 y 30.
| \(\text{gl}\) | \(t_{0.025(\text{gl})}\) |
|---|---|
| 1 | 12.706 |
| 2 | 4.303 |
| 3 | 3.182 |
| 4 | 2.776 |
| 5 | 2.571 |
| 6 | 2.447 |
| 7 | 2.365 |
| 8 | 2.306 |
| 9 | 2.262 |
| 10 | 2.228 |
| 11 | 2.201 |
| 12 | 2.179 |
| 13 | 2.160 |
| 14 | 2.145 |
| 15 | 2.131 |
| 16 | 2.120 |
| 17 | 2.110 |
| 18 | 2.101 |
| 19 | 2.093 |
| 20 | 2.086 |
| 21 | 2.080 |
| 22 | 2.074 |
| 23 | 2.069 |
| 24 | 2.064 |
| 25 | 2.060 |
| 26 | 2.056 |
| 27 | 2.052 |
| 28 | 2.048 |
| 29 | 2.045 |
| 30 | 2.042 |
El cambio en la magnitud de los valores críticos no es proporcional al cambio en los grados de libertad. El incremento de un grado de libertad entre 1 y 2 produce una disminución de 8.403 en el valor crítico, mientras el incremento de un grado de libertad entre 29 y 30 apenas produce una disminución de 3 milésimas en el valor crítico. La figura 7.14 ilustra esta situación.

Aunque el valor de 10 grados de libertad que sugieren Mead et al. (2012) como tope mínimo es relativamente arbitrario, resulta evidente que la disminución de los grados de libertad del error por debajo de dicho tope tiene efectos cada vez más indeseables sobre la potencia de las pruebas.
Asimismo, la tabla 7.9 y la figura 7.14 evidencian que, a partir de cierto punto, el incremento en los grados de libertad del error se vuelve cada vez más irrelevante en términos del incremento producido sobre la potencia.
Teniendo en cuenta lo anterior, Mead et al. (2012) también sugieren un tope superior de aproximadamente 20 grados de libertad para el error. Estos autores indican que por encima de dicho valor podrían estar desperdiciándose recursos.
Mead et al. (2012) basan su análisis en la partición de los grados de libertad totales entre los diferentes componentes del modelo. A dicha partición la denominan ecuación de los recursos.
Para fines operativos, resulta más práctica una ecuación en la que se calculen los grados de libertad del error, descontándole a los grados de libertad totales los grados de libertad de los tratamientos y los grados de libertad de los componentes de bloqueo si los hubiera.
\[
\text{gle}=\text{glT}-\text{glttos}-\text{gl}\text{(bloques, filas, columnas...)}
\tag{7.4}\]
Teniendo en cuenta las particularidades de cada modelo, esta ecuación puede emplearse de manera iterativa para llevar los grados de libertad del error al rango deseado.
Consideramos muy sana la recomendación de Mead et al. (2012) de buscar que los grados de libertad del error queden aproximadamente entre 10 y 20.
Esta recomendación es particularmente pertinente en la etapa de planeación del experimento. No significa, sin embargo, que un experimento cuyos grados de libertad del error estén por fuera de dicho rango esté malo ni que no deba analizarse.
La potencia de un experimento con menos de 10 grados de libertad para el error será baja; más baja cuanto menos grados de libertad tenga el error. Ante el no rechazo de la hipótesis nula, a la incertidumbre propia de esta decisión habría que añadirle una capa adicional. ¿No se evidenciaron diferencias porque las medias poblacionales son muy similares o por la baja potencia del ensayo?
Ante un número muy alto de grados de libertad solamente se cuestionaría el uso eficiente de los recursos. ¿Podrían haberse obtenido resultados similares empleando menos recursos?
Para ilustrar el uso de la ecuación de los recursos, considérese la planeación de un experimento para comparar tres tratamientos, utilizando un esquema de aleatorización en bloques completos al azar.
Teniendo en cuenta las particularidades del modelo, el uso iterativo de la expresión 7.4 permite calcular los grados de libertad del error a partir del número réplicas (bloque en este caso).
Aunque la búsqueda iterativa del número de réplicas es bastante sencilla, es posible despejar la expresión 7.4 para calcular \(r\) en función del valor objetivo que se fije para los grados de libertad del error.
Para un esquema de aleatorización completamente al azar:
\[
r=\dfrac{\text{gle}}{k}+1
\]
Para un esquema de aleatorización en bloques completos al azar:
\[
r=\dfrac{\text{gle}+k-1}{k-1}
\]
Estas expresiones hacen explícita una idea que se retomará más adelante: para un modelo dado, los grados de libertad del error y el número de réplicas se relacionan linealmente.
Para el ejemplo planteado en el que se buscan las réplicas para un experimento en bloques con \(k=3\), si se toma como referencia un valor objetivo para los grados de libertad del error dentro del rango sugerido por Mead et al. (2012), por ejemplo, \(\text{gle}=15,\) se tiene:
\[
\begin{align}
r&=\dfrac{\text{gle}+k-1}{k-1}\\[1.4em]
r&=\dfrac{15+3-1}{3-1}\\[1.4em]
r&=8.5
\end{align}
\] Aunque la expresión para el cálculo pueda dar lugar a un valor no entero, lógicamente habrá que elegir un valor entero para el número de réplicas. Si \(r\) se redondea por debajo, los grados de libertad del error serán inferiores a los establecidos como objetivo. Si se redondea por encima, se obtendrá un número de grados de libertad para el error superior al valor objetivo (cf. tabla 7.11).
La función personalizada mead facilita la exploración de la ecuación de los recursos, siendo posible calcular el número de réplicas necesario para obtener un número dado de grados de libertad para el error o los grados de libertad que se obtienen a partir de un número dado de réplicas.
La función implementa los cálculos para el esquema de aleatorización completamente al azar (aleat = "ca") y bloques completos al azar (aleat = "ba"). Aunque la función también admite el esquema de aleatorización cuadro latino (aleat = "cl"), en este caso el número de réplicas coincide necesariamente con el número de tratamientos. Por tanto, ni el número de réplicas ni los grados de libertad del error pueden modificarse de manera independiente, pues ambos quedan completamente determinados por \(k.\)
A continuación se ilustra su uso para explorar el escenario de un experimento en bloques completos al azar para comparar tres tratamientos.
Inicialmente puede emplearse para calcular el número de réplicas requerido para obtener al menos un número determinado de grados de libertad. Así, para 15 grados de libertad se escribe el siguiente código10:
source("mead.R")
mead(k = 3, aleat = "ba", gle = 15)Esquema de aleatorización bloques al azar
r = 9
k = 3
gle = 16
n = 27
Distribución de los recursos para esquema
de aleatorización bloques al azar
Grados de libertad
Bloques 8
Tratamientos 2
Error 16
Total 26A partir de este resultado, el usuario puede evaluar el comportamiento de los grados de libertad del error y el tamaño del experimento para cualquier otro número de réplicas. Contrástese el siguiente resultado con el presentado en la tabla 7.11.
mead(k = 3, aleat = "ba", r = 11)Esquema de aleatorización bloques al azar
r = 11
k = 3
gle = 20
n = 33
Distribución de los recursos para esquema
de aleatorización bloques al azar
Grados de libertad
Bloques 10
Tratamientos 2
Error 20
Total 32Considérese la \(\text{DMS}\) para la comparación de medias en un experimento con igual número de réplicas por tratamiento (cf. sección 8.4):
\[
\text{DMS}=t_{\alpha/2(\text{gle})}\sqrt{\dfrac{2\text{CME}}{r}}
\]
Se ha analizado la manera en la que los grados de libertad del error —que definen la magnitud de \(t_{\alpha/2(\text{gle})}\)— influyen en la \(\text{DMS}.\) A partir de esta consideración se han presentado recomendaciones para definir \(r.\) Sin embargo, \(r\) también aparece en el denominador del error estándar, lo que podría sugerir que la \(\text{DMS}\) puede seguir disminuyendo indefinidamente a medida que aumenta el número de réplicas.
Luego, la elección de \(r\) con base en el tope superior de 20 grados de libertad del error resultaría razonable si se considera el control ejercido desde el valor crítico de \(t,\) pero no tendría razón de ser si se considera la disminución producida a través del error estándar.
Esta percepción, sin embargo, es engañosa. Como se ilustró anteriormente, los grados de libertad son una combinación lineal del número de réplicas. Esto implica que, para un modelo dado, no es posible modificar las réplicas sin que se afecten los grados de libertad. Por tanto —para un modelo determinado— basta cualquiera de estos elementos para explicar el comportamiento de la \(\text{DMS}.\)
La figura 7.15 ilustra esta relación para un experimento en esquema de aleatorización en bloques completos al azar, en el que se comparan cinco tratamientos, suponiendo un \(\text{CME}=7.\)


La figura 7.15 revela que, aunque la recomendación de Mead et al. (2012) se formula en términos de los grados de libertad del error, la elección del número de réplicas que de allí se deriva también afecta el error estándar. Por tanto, al definir el número de réplicas para un modelo determinado, se incide simultáneamente sobre ambos componentes de la \(\text{DMS}\): el valor crítico y el error estándar.
En ocasiones se hace necesario emplear variantes del cuadro latino para incrementar los grados de libertad del error, para ejercer un mejor control sobre posibles fuentes de variación secundarias o por una combinación de estas razones.
La tabla 7.9 muestra que los cuadros latinos básicos para comparar 4 o 3 tratamientos tienen muy baja potencia, siendo crítica la situación en la que se pretendiera emplearlos para la comparación de 2 tratamientos, donde no quedan grados de libertad disponibles para estimar el error.
Considérese un escenario en el que se busque comparar el efecto de tres dietas sobre la producción de leche en bovinos.
Suponiendo inicialmente que se contara únicamente con tres vacas, la opción de asignarle al azar una dieta a cada una de las vacas disponibles sería inviable, dado que, al no contar con réplicas de los tratamientos, no habría grados de libertad disponibles para estimar el error.
| Fuente de variación | Grados de libertad |
|---|---|
| Dieta | 2 |
| Error | 0 |
| Total | 2 |
Avanzando en complejidad, podría considerarse un crossover, asignándole de manera secuencial las diferentes dietas a cada una de las vacas, con secuencias diferentes para cada vaca. Este diseño, aunque viable, solamente deja 2 grados de libertad disponibles para la estimación del error, lo que se traduce en muy baja potencia.
| Fuente de variación | Grados de libertad |
|---|---|
| Periodo | 2 |
| Vaca | 2 |
| Dieta | 2 |
| Error | 2 |
| Total | 8 |
Supóngase ahora que se cuenta con nueve vacas, lo que permitiría realizar tres ensayos independientes en crossover, cada uno de los cuales tendría la estructura indicada anteriormente. Esta estrategia, sin embargo, no sería la más eficiente.
Una mejor estrategia consistiría en realizar todas las evaluaciones en los mismos tres periodos de tiempo, lo que permitiría extraer la variabilidad asociada con los periodos empleando únicamente dos grados de libertad:
| Fuente de variación | Grados de libertad |
|---|---|
| Periodo | 2 |
| Vaca | 8 |
| Dieta | 2 |
| Error | 14 |
| Total | 26 |
Desde luego, en este caso no se tiene un cuadro latino, sino un rectángulo latino. Sin embargo, siguen siendo aplicables los conceptos de doble bloqueo y ortogonalidad subyacentes al cuadro latino.
La distribución homogénea de las tres posibles secuencias entre las vacas disponibles evita que las diferencias observadas entre tratamientos puedan atribuirse sistemáticamente a una secuencia particular.
La secuencia es particularmente relevante en estudios de producción de leche, dado que la producción no es homogénea durante todo el periodo de lactancia.
Una curva típica de lactancia inicia con un incremento que alcanza su pico máximo aproximadamente entre los 45 y 90 días después del parto, tras lo cual sigue en descenso hasta concluir el periodo de lactancia, que dura en promedio 305 días, tal y como lo ilustran las dos curvas de la figura 7.17.

En la figura 7.17 aparecen dos curvas típicas de lactancia. En la curva roja, correspondiente a la primera lactancia, el pico no es tan alto como en la curva azul, correspondiente a la tercera lactancia.
Los principales factores que afectan la forma de la curva son la dieta, las condiciones ambientales, el número de lactancias y el potencial genético.
En un ensayo como el planteado, la dieta es justamente el factor que se evalúa. El efecto de las condiciones ambientales queda controlado mediante el factor periodo. Se esperaría que el factor vaca controlara lo concerniente al número de lactancias y el potencial genético. Sin embargo, este control podría ser ineficiente si se deja al azar.
Supóngase que los periodos usados como factor fila en el esquema representado en la figura 7.16 corresponden de manera aproximada con los tercios de lactancia separados con líneas punteadas en la figura 7.17. Supóngase además que —por azar— las vacas 2, 5 y 8, a las que se les asignó la secuencia \(\text{A}\), \(\text{C}\), \(\text{B},\) fueran de primera lactancia (curva roja), mientras que las vacas 3, 6 y 9, a las que se les asignó la secuencia \(\text{B}\), \(\text{A}\), \(\text{C},\) fueran de tercera lactancia (curva azul).
Esto pondría en ventaja al tratamiento \(\text{B}\) con respecto al tratamiento \(\text{A}\), por las diferencias esperables en el primer periodo entre vacas con diferente número de lactancias.
Cochran, Autrey y Cannon (1941) sugieren controlar este posible efecto indeseable mediante la conformación previa de grupos homogéneos de animales.
En el escenario considerado se conformarían inicialmente tres grupos de tres vacas, cada uno con vacas que exhiban la máxima homogeneidad posible en términos de número de lactancias y potencial genético. Posteriormente, se asignaría al azar una vaca de cada grupo a cada una de las tres secuencias de tratamientos evaluada. Esto da permite equilibrar las secuencias dentro de cada uno de los grupos.
Mediante esta práctica se controlan posibles factores de confusión sin sacrificar grados de libertad para la estimación del error. La variabilidad correspondiente a las vacas se descompone en variabilidad entre grupos —con 2 gl— y variabilidad de vacas dentro de cada grupo, con \(2+2+2=6 \text{ gl}\) (figura 7.18):

Esta descomposición se presenta así en la tabla resumen del ANOVA (tabla 7.13):
| Fuente de variación | Grados de libertad |
|---|---|
| Periodo | 2 |
| Grupo | 2 |
| Vaca dentro de grupo | 6 |
| Dieta | 2 |
| Error | 14 |
| Total | 26 |
Aunque la partición de la variabilidad de las vacas en los componentes “Grupo” y “Vaca dentro de grupo” constituye una forma elegante de presentación, equivale numéricamente a la variabilidad total entre vacas sin agrupación (¡Compruébelo!).
El verdadero control se ejerce mediante la adecuada conformación de los grupos. En la medida en que se logren establecer grupos más homogéneos, se controlará mejor la variabilidad entre vacas como posible factor de confusión.
La comparación entre la tabla 7.12 y la tabla 7.13 permite apreciar que los grados de libertad para el error son los mismos, sea que se agrupe o que no.
Luego, en escenarios como el planteado, vale la pena intentar un agrupamiento. Nada se pierde en términos de grados de libertad para el error y podría ganarse mucho en términos de control de posibles factores de confusión.
El cuadro latino generaliza el concepto de bloqueo a dos fuentes de variación secundarias: filas y columnas. Esta idea de bloquear con base en más de una fuente de variación circunstancial puede extenderse a tres o más fuentes.
El cuadro grecolatino generaliza la idea de bloqueo a tres fuentes de variación secundarias. Geométricamente, suele representarse como un cuadro con filas y columnas, al que se le agregan letras griegas para representar la tercera fuente de variación circunstancial. Los tratamientos suelen representarse mediante letras latinas.
Este esquema de aleatorización recibe su nombre de las letras griegas que suelen usarse para representar la tercera fuente de variación circunstancial y las letras latinas usadas para representar los tratamientos.
Esto también explica el nombre del cuadro latino, donde el único alfabeto que interviene es el de las letras latinas que se usan para representar los tratamientos.
No está de más insistir en el hecho de que, tanto el cuadro latino como sus extensiones constituyen esquemas de aleatorización con más de una fuente de bloqueo. Las etiquetas genéricas que se utilicen para la identificación de las fuentes de bloqueo, así como su orden y representación (si hubiera lugar a ello) son irrelevantes.
El cuadro grecolatino impone tres restricciones a la aleatorización de los tratamientos:
Todos los tratamientos tienen que aparecer en cada nivel del factor fila.
Todos los tratamientos tienen que aparecer en cada nivel del factor columna.
Todos los tratamientos tienen que aparecer combinados con cada una de las letras griegas.
Estas restricciones implican ortogonalidad entre filas, columnas, letras griegas y tratamientos. Culquier nivel de un factor se combina con todos los niveles de los demás factores, tal y como se ilustra en la figura 7.19.
Aunque la representación geométrica de la figura 7.19 rara vez tendría una correspondencia física directa, en la que se crucen tres fuentes de variación secundarias (pero relevantes) con los tratamientos, es necesario tener presente que, más allá de su representación gráfica, el cuadro grecolatino es un esquema de aleatorización que bloquea con base en tres fuentes. En tal sentido, existen escenarios en los que su aplicación es pertinente.
Considérese nuevamente el hipotético ejemplo de limpieza de piezas óseas. Anteriormente se identificaron tres posibles fuentes de variabilidad: dos secundarias que se asignaron a filas y columnas y una primaria, que se asignó a los tratamientos, así:
Método: tratamientos
Donante: filas
Operario: columnas
¿El tipo de pieza tendrá alguna relevancia? ¿En términos de las respuestas evaluadas, será igual limpiar la tibia, el peroné, el cúbito o el radio?
Si la eficiencia y la calidad de limpieza de una pieza ósea depende del tipo de pieza, sería totalmente relevante incluir el factor “pieza” como factor de bloqueo.
Luego, este hipotético ensayo ampliado manejaría tres fuentes de variación secundarias y una primaria, así:
Método: tratamientos (letras latinas)
Donante: filas
Operario: columnas
Pieza: letras griegas
Si se revisa nuevamente la figura 7.19, teniendo en cuenta las anteriores correspondencias, podrá observarse que cada método es evaluado sobre cada una de las cuatro piezas consideradas, sobre cada uno de los cuatro donantes disponibles y por parte de cada uno de los cuatro operarios. Esto evita que las fuentes de variación secundarias actúen como factor de confusión en la comparación de los tratamientos.
La idea de bloquear con base en más de una fuente puede generalizarse —en teoría— a cualquier número de fuentes.
A las generalizaciones del cuadro grecolatino se les denomina cuadros hipergrecolatinos.
Aunque la representación gráfica pueda complejizarse o volverse irrealizable, esto no constituye impedimento para su realización.
Tampoco habría restricciones relacionadas con los alfabetos o símbolos que fueran requeridos para representar las fuentes de variación adicionales.
No obstante, en la práctica es poco común encontrar este tipo de situaciones. Esto no es debido a que el número de fuentes de variabilidad sea reducido, sino a la dificultad para aislarlas y al buen desempeño que suele lograrse mediante los bloques como factor conglomerador de múltiples fuentes de variación.
Dejando de lado las variantes y extensiones del cuadro latino, el modelo correspondiente a este esquema de aleatorización es:
\[
Y_{ijk}=\mu+\tau_i+F_j+C_k+\varepsilon_{ijk},\ i, j, k=1, 2,\dotsc, k,
\]
donde:
\(Y_{ijk}\): Respuesta del \(i\)-ésimo tratamiento en la \(j\)-ésima fila y la \(k\)-ésima columna.
\(\mu\): Media general.
\(\tau_i\): Efecto del \(i\)-ésimo tratamiento.
\(F_j\): Efecto de la \(j\)-ésima fila.
\(C_k\): Efecto de la \(k\)-ésima columna.
\(\varepsilon_{ijk}\): Desviación aleatoria de la respuesta del \(i\)-ésimo tratamiento en la \(j\)-ésima fila y la \(k\)-ésima columna respecto a su valor esperado.
Al tratarse de una extensión del modelo en bloques completos al azar, este modelo comparte sus supuestos.
Los errores son independientes y están normalmente distribuidos, con media cero y varianza común \(\sigma^2:\)
\[
\varepsilon_{ijk}\text{ iid } N(0,\ \sigma^2),\ i, j, k=1, 2,\dotsc, k,
\]
En este caso el supuesto de aditividad o no interacción incluye todos los componentes del modelo. Se supone que no existe ningún tipo de interacción entre filas, columnas y tratamientos.
Para la independencia se tienen en cuenta las mismas consideraciones que para los modelos anteriores. La independencia no se verifica a posteri, sino que se propicia durante la planeación y la ejecución del ensayo (cf. sección 6.3.1).
El supuesto de normalidad se propicia y se evalúa de igual manera que en el modelo completamente al azar y el de bloques. Cuando sea del caso, puede propiciarse empleando unidades experimentales conformadas por múltiples elementos. Para su evaluación se utiliza la prueba de Shapiro-Wilk sobre los residuales del modelo.
Para evaluar homogeneidad de varianzas, se recomienda la prueba generalizada de Levene propuesta por O’Neill y Mathews (2002), descrita en la sección 7.2.2, que puede ejecutarse mediante la función personalizada levene_g. Esta función permite evaluar homocedasticidad tanto en modelos de cuadro latino como en sus variantes y extensiones.
La discusión sobre aditividad en el cuadro latino y sus extensiones incluye los mismos elementos que en el modelo de bloques completos al azar.
La aditividad se refiere al hecho de que la respuesta esperada pueda expresarse como la suma de los efectos de los tratamientos y de todos los factores circunstanciales: filas, columnas, letras griegas, etc., tal y como lo plantea el correspondiente modelo de ANOVA.
Esto implica que la diferencia entre cualquier par de tratamientos sea consistente en cualquiera de las condiciones definidas por la combinación de niveles de los factores secundarios.
Goedhart (1990) discute las limitaciones del cuadro latino cuando se utiliza en su modalidad crossover para evaluar digestibilidad en cerdos con rango de peso entre 40 y 100 kg. El autor reporta fuerte evidencia de interacción entre periodo y animal, probablemente debida al incremento de la capacidad digestiva de los cerdos a medida que avanzan por los diferentes periodos del crossover y ganan peso.
Aunque Goedhart (1990) reporta esta limitación para una situación muy particular, se trata de un hallazgo especialmente relevante. Si la duración de un ensayo crossover es suficientemente larga, pueden presentarse cambios fisiológicos en los individuos que modifican la manera en que estos responden a lo largo del tiempo. En tales circunstancias, el supuesto de aditividad puede dejar de ser válido.
El conocimiento que se tenga sobre el comportamiento de la respuesta en diferentes escenarios es clave desde la etapa de planeación. El ejemplo discutido por Goedhart (1990) ilustra precisamente la importancia de este conocimiento previo. Un investigador familiarizado con la fisiología digestiva de los animales probablemente evitaría plantear un ensayo en el que individuos pertenecientes a etapas fisiológicas muy diferentes fueran tratados como si constituyeran una población homogénea.
Más allá de sus implicaciones estadísticas, esta situación invita a reflexionar sobre la propia pregunta experimental. Si individuos que se encuentran en etapas fisiológicas muy diferentes responden de manera distinta a los tratamientos, quizá no resulte apropiado resumir su comportamiento mediante una única respuesta promedio.
Desde esta perspectiva, el problema no necesariamente radica en la elección del modelo estadístico, sino en la definición de la población sobre la cual se pretende realizar la inferencia.
Cuando las diferencias fisiológicas son suficientemente marcadas, puede resultar cuestionable considerar todos los individuos como pertenecientes a una misma población de interés. En estos casos podría ser más apropiado analizar por separado grupos de individuos con características fisiológicas comparables o recurrir a diseños y modelos que incorporen explícitamente esta fuente de variación adicional.
La prueba de aditividad para modelos de cuadro latino y sus extensiones parte de la idea de Tukey (1949) de aislar un grado de libertad del error para evidenciar no aditividad asociada a una estructura multiplicativa.
Aunque Tukey (1949) toma como punto de partida una tabla de doble entrada (bloques y tratamientos), declara explícitamente la posibilidad de generalización a modelos que involucren más de un factor de bloqueo. Posteriormente, en respuesta a una consulta sobre la aplicación de esta prueba a ensayo crossover, Tukey (1955) ilustra la adaptación de esta prueba a la geometría particular del cuadro latino.
Federer, Robson y Tukey (1971) formalizaron la idea subyacente a la prueba de Tukey, según la cual una estructura multiplicativa de interacción puede representarse mediante una relación funcional (regresión) entre los efectos principales y los residuos. En este manuscrito se demostró que la independencia entre los residuos de mínimos cuadrados y los estimadores de las constantes garantiza que el grado de libertad extraído sea estadísticamente válido y que, bajo la hipótesis de aditividad, el estadístico asociado siga una distribución \(F.\)
Kohli (1988) reescribe esta lógica utilizando notación matricial y la extiende sistemáticamente a cuadros latinos y afines.
La prueba de Tukey-Kohli parte de la obtención de la suma de cuadrados de no aditividad, que puede verse como una extensión de la empleada para evaluar no aditividad entre bloques y tratamientos en el modelo de bloques completos al azar.
Si se define \(X_{ijk}=\widehat{Y}_{ijk}^2,\) la suma de cuadrados de no aditividad se expresa así:
\[
\text{SCnoad}=\frac{\sum\limits_{ijk} \left[ \left(X_{ijk}-\widehat{X}_{ijk}\right) \left(Y_{ijk}-\widehat{Y}_{ijk}\right)\right]^2}
{\sum\limits_{ijk} \left(X_{ijk}-\widehat{X}_{ijk}\right)^2}
\]
Esta suma de cuadrados representa el componente de variación atribuible a una estructura multiplicativa de no aditividad y tiene asociado un único grado de libertad.
Esta suma de cuadrados se le descuenta a la \(\text{SCE},\) dando lugar a la denominada suma de cuadrados del error reducida:
\[
\text{SCE}_\text{red}=\text{SCE}-\text{SCnoad}
\]
Asimismo, a la \(\text{SCE}\) se le descuenta el grado de libertad transferido a la \(\text{SCnoad}.\) Por tanto:
\[
\text{gle}_\text{red}=\text{gle}-1
\]
Para el cuadro latino estándar:
\[
\text{gle}_\text{red}=n-3k+1
\]
El estadístico de prueba se construye como la razón entre los cuadrados medios de no aditividad y del error reducido. Si el cuadrado medio asociado a la no aditividad es grande en relación con la variabilidad residual restante, se obtendrán valores elevados del estadístico \(F\), lo que constituye evidencia de una posible estructura multiplicativa de no aditividad.
El estadístico de prueba para el modelo de cuadro latino es:
\[
F_\text{c}=\frac{\text{CMnoad}}{\text{CME}_\text{red}}
=\frac{\text{SCnoad}/1}{\text{SCE}_\text{red}/(n-3k+1)}
\overset{H_0}\thicksim F_{(1,\,n-3k+1)}
\]
La función personalizada tukey_g implementa esta prueba para el cuadro latino, sus variantes y sus extensiones.
En el modelo de cuadro latino, la variabilidad total se descompone en diferentes fuentes: filas, columnas, tratamientos y error experimental, siguiendo la misma lógica que en el esquema de bloques completos al azar (cf. sección 7.2.1).
La ortogonalidad propia de este esquema de aleatorización permite extraer del error experimental la variabilidad asociada con filas y columnas, lo que puede aumentar la sensibilidad del ensayo para detectar diferencias entre tratamientos.
A continuación se presentan las fórmulas operacionales de las sumas de cuadrados para el modelo de cuadro latino.
\[
\begin{align}
\text{SCT}&=\sum{Y_{ijk}^2}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
\text{SCttos}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet\bullet}^2}}{k}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
\text{SCF}&=\frac{\sum\limits_{j=1}^k{Y_{\bullet j \bullet}^2}}{k}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
\text{SCC}&=\frac{\sum\limits_{k=1}^k{Y_{\bullet\bullet k}^2}}{k}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
\text{SCE}&=\text{SCT}-\text{SCttos}-\text{SCF}-\text{SCC}
\end{align}
\tag{7.5}\]
Ejemplo 7.3
Martínez (1988) presenta los resultados de un experimento realizado en el campo experimental de Papaloapan, en el estado de Veracruz, México.
Se empleó un cuadro latino \(6 \times 6\) para ensayar algunas combinaciones de elementos menores con nutrientes mayores, sobre el rendimiento de caña de azúcar.
A continuación se relacionan los tratamientos evaluados, asignándoles una etiqueta para posterior referencia:
| Descripción | Tratamiento |
|---|---|
| Control (N0–P0–K0) | A |
| (N6–P8–K6) + B + Mn + Zn | B |
| (N6–P8–K6) + B + Mn | C |
| (N6–P8–K6) + B + Zn | D |
| (N6–P8–K6) + B | E |
| (N6–P8–K6) | F |
La figura 7.20 presenta el esquema de aleatorización empleado para este experimento junto con los datos de rendimiento.
La información de la figura 7.20 puede parecer un tanto caótica si se compara con la presentada en la tabla 7.7, en la que se organiza la información con la que se ejemplifica el esquema de aleatorización en bloques al azar.
Esto es debido a que en el esquema de aleatorización en bloques completos al azar intervienen únicamente dos factores, lo que permite cruzar sus niveles de forma limpia en una tabla bidimensional.
En contraste, en el cuadro latino, donde intervienen tres factors, únicamente pueden cruzarse de manera ordenada dos de ellos en la tabla bidimensional (filas y columnas). Los niveles del tercer criterio (tratamientos) deben ubicarse en las celdas internas, acorde con las restricciones de este esquema de aleatorización.
Para los cálculos manuales, es conveniente contar con los totales de filas, columnas y tratamientos. Los totales de filas y columnas se calculan de manera sencilla y suelen ubicarse en los márgenes de la tabla cuando se realizan ejercicios manuales. El cálculo de los totales de los tratamientos exige identificar las observaciones correspondientes a cada tratamiento, las cuales se encuentran dispersas dentro del cuadro.
La siguiente tabla presenta los totales de las filas, las columnas y los tratamientos:
| Fila | Total | Columna | Total | Tratamiento | Total |
|---|---|---|---|---|---|
| 1 | 9272 | 1 | 10174 | A | 6152 |
| 2 | 10017 | 2 | 10899 | B | 10771 |
| 3 | 10250 | 3 | 10766 | C | 11435 |
| 4 | 10233 | 4 | 10845 | D | 10936 |
| 5 | 11840 | 5 | 9105 | E | 10798 |
| 6 | 9065 | 6 | 8888 | F | 10585 |
Las sumas de cuadrados se calculan utilizando las fórmulas operativas relacionadas en 7.5.
Inicialmente se calcula el término de corrección:
\[
C=\frac{Y_{\bullet\bullet\bullet}^2}{k^2}=\frac{60\,677^2}{6^2}=102\,269\,398
\]
La suma de cuadrados total es:
\[
\begin{align}
\text{SCT}&=\sum{Y_{ijk}^2}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
&=(1626^2+ \dotsb+1245^2)-C\\[1.4em]
&=5\,048\,552.973\\[1.4em]
\end{align}
\]
La suma de cuadrados de tratamientos es: \[
\begin{align}
\text{SCttos}&=\frac{\sum\limits_{i=1}^k{Y_{i\bullet\bullet}^2}}{k}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
&=\frac{6152^2+ \dotsc +10585^2}{6}-C\\[1.4em]
&=3\,206\,584.473
\end{align}
\]
La suma de cuadrados de filas es: \[
\begin{align}
\text{SCF}&=\frac{\sum\limits_{j=1}^k{Y_{\bullet j\bullet}^2}}{k}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
&=\frac{9272^2+ \dotsc + 9065^2}{6}-C\\[1.4em]
&=805\,083.139
\end{align}
\]
La suma de cuadrados de columnas es: \[
\begin{align}
\text{SCC}&=\frac{\sum\limits_{k=1}^k{Y_{\bullet \bullet k}^2}}{k}-\frac{Y_{\bullet\bullet\bullet}^2}{k^2}\\[1.4em]
&=\frac{10174^2+ \dotsc + 8888^2}{6}-C\\[1.4em]
&=683\,406.473
\end{align}
\]
La suma de cuadrados del error se obtiene por diferencia:
\[
\begin{align}
\text{SCE}&=\text{SCT}-\text{SCttos}-\text{SCF}-\text{SCC}\\[1.4em]
&=353\,478.89
\end{align}
\]
Los grados de libertad se obtienen de manera análoga a los de los demás modelos de ANOVA de una vía:
\[
\begin{align}
\text{glT}&=k^2-1=35\\[1.4em]
\text{glttos}&=k-1=5\\[1.4em]
\text{glF}&=k-1=5\\[1.4em]
\text{glC}&=k-1=5\\[1.4em]
\text{gle}&=35-5-5-5=20
\end{align}
\]
La tabla 7.14 resume los diferentes componentes del ANOVA:
| Fuentes de variación | Grados de libertad | Sumas de cuadrados | Cuadrados medios | Estadístico \(F\) | Valor p |
|---|---|---|---|---|---|
| Filas | 5 | 805083.14 | |||
| Columnas | 5 | 683406.47 | |||
| Tratamientos | 5 | 3206584.47 | 641316.89 | 36.29 | 2.29e-09 |
| Error | 20 | 353478 | 17673.94 | ||
| Total | 35 | 5048552.97 |
En el modelo de cuadro latino, el juego de hipótesis relevante es el que contrasta las medias de los tratamientos. Para el presente caso:
\[
\mu_\text{A}=\mu_\text{B}=\mu_\text{C}=\mu_\text{D}=\mu_\text{E}=\mu_\text{F}
\]
Para la evaluación de este contraste, se emplea el estadístico de prueba construido como la razón entre el \(\text{CMttos}\) y el \(\text{CME}.\) Puesto que el valor p asociado con este estadístico es menor que 0.05 \((\text{p}=2.29\text{e}\!-\!09),\) se rechaza la hipótesis nula, concluyéndose, por tanto, que el rendimiento medio no es igual bajo todos los tratamientos de fertilización.
En el cuadro latino, las filas y las columnas juegan el mismo rol que los bloques en el esquema de aletorización en bloques completos al azar.
Su carácter es circunstancial o secundario y en la mayoría de los casos aleatorio.
El objetivo de su consideración en el esquema de aleatorización y su inclusión en el modelo es disminuir la variabilidad que aportan, a la vez que se evita que actúen como factores de confusión.
Aunque las salidas de aov y de otros paquetes estadísticos presenten filas y columnas en igualdad de condiciones con los tratamientos, su interpretación es diferente (cf. advertencia 7.1).
Si existe interés científico en comparar los niveles asociados a filas, columnas u otras fuentes de variación secundarias, estas dejan de desempeñar un papel de bloqueo. En tal caso deberá considerarse una estructura factorial de los tratamientos que permita evaluar formalmente dichos efectos y sus interacciones (cf. capítulo 10).
A continuación se ilustra el uso de la prueba de Tukey para la comparación entre todos los posibles pares de medias.
En la práctica, tras ajustar el modelo de ANOVA, debe evaluarse la satisfacción de supuestos —y aplicarse medidas correctivas si fuera del caso— antes de realizar procedimientos de comparación múltiple.
No obstante, dado que, en modelos complejos, la evaluación manual de supuestos resulta poco práctica y actualmente se realiza casi exclusivamente mediante aplicaciones especializadas, pasamos directamente a ilustrar el uso de la prueba de Tukey, para cerrar este bloque manual.
Posteriormente, cuando se ilustre su implementación en R, se seguirá el orden estándar: ajuste del modelo → evaluación de supuestos → procedimientos de comparación múltiple.
El valor crítico superior del recorrido estudentizado con \(\alpha=0.05\) es:
qtukey(p = 0.05, nmeans = 6, df = 20, lower.tail = FALSE)[1] 4.445237
La \(\text{DSH}\) es:
\[
\begin{align}
\text{DSH}&=q_{\alpha(k,\,\text{gle})}\sqrt{\dfrac{\text{CME}}{r}}\\[1.4em]
&=4.445237\sqrt{\dfrac{17673.94}{6}}\\[1.4em]
&=241.25
\end{align}
\]
El resultado de las 15 posibles comparaciones entre pares de medias se resume así:
| Tratamiento | Media | Grupo |
|---|---|---|
| C | 1905.83 | a |
| D | 1822.67 | a |
| E | 1799.67 | a |
| B | 1795.17 | a |
| F | 1764.17 | a |
| A | 1025.33 | b |
El resumen de grupos homogéneos evidencia que el tratamiento \(\text{A}\) presenta un rendimiento significativamente inferior al de los demás tratamientos. Entre los tratamientos \(\text{B},\) \(\text{C},\) \(\text{D},\) \(\text{E}\) y \(\text{A}\) no se detectan diferencias estadísticamente significativas.
El punto de partida del análisis es la organización de la información de la figura 7.20 en una base de datos, respetando las combinaciones, fila-columna-tratamiento que caracterizan esa aleatorización particular.
Este aspecto —aunque relativamente trivial— es fundamental para asegurar la validez de los análisis. El archivo Excel Ejemplo 7.3.xlsx compila la información de manera organizada.
Mediante las siguientes instrucciones se importa y adecúa la base de datos. Seguidamente, se ajusta el modelo de ANOVA:
1data <- readxl::read_excel("Ejemplo 7.3.xlsx")
2data <- transform(data,
filas = factor(filas),
columnas = factor(columnas),
ttos = factor(ttos))
3anova <- aov(rend ~ filas + columnas + ttos, data = data)factor a las filas, las columnas y los tratamientos.
El objeto anova contiene la información del modelo ajustado. Este es el objeto que se utiliza como argumento de entrada para las funciones que se presentan a continuación.
Inicialmente se evalúan los supuestos de normalidad y homocedasticidad, mediante la función check_model:
source("check_model.R")
check_model(anova)Resumen de modelos
transformación p (S-W) p (Levene) monótona
tr0: rend 0.8216 0.6568 sí
tr1: log(rend) 0.9354 0.3368 sí
tr2: log(rend + 8.8) 0.9356 0.3395 sí
tr3: (rend) ^ 1 0.8216 0.6568 sí
tr4: (rend + 8.8) ^ 1 0.8216 0.6568 sí
tr5: (rend + 8.8) ^ 1.46 0.9420 0.7174 síAl evaluar los supuestos del modelo sobre la variable en escala original \((\text{tr0}),\) no se evidencian desviaciones severas de los supuestos de normalidad \((\text{p}=0.8216)\) ni de homocedasticidad \((\text{mínimo p}=0.6568).\)
A continuación se emplea la función tukey_g para evaluar aditividad:
source("tukey_g.R")
tukey_g(anova)Tukey-Kohli's one df test for additivity
F = 0.2388878 Denom df = 19 p-value = 0.6306044Puesto que \(p=0.63,\) no se detecta evidencia de no aditividad de tipo multiplicativo.
Dado que no se detectaron violaciones de los supuestos, se revisa la tabla resumen del ANOVA:
summary(anova) Df Sum Sq Mean Sq F value Pr(>F)
filas 5 805083 161017 9.110 0.000122 ***
columnas 5 683406 136681 7.733 0.000345 ***
ttos 5 3206584 641317 36.286 2.29e-09 ***
Residuals 20 353479 17674
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1A continuación se utiliza la prueba de Tukey para realizar todas las posibles comparaciones por pares:
agricolae::HSD.test(anova, "ttos", console = TRUE) rend groups
C 1905.833 a
D 1822.667 a
E 1799.667 a
B 1795.167 a
F 1764.167 a
A 1025.333 bFinalmente, se presentan el escenario general, mediante un diagrama de caja y bigotes por tratamiento:
with(data, plot(ttos, rend))
Salta a la vista la alta correspondencia entre los resultados de la prueba de Tukey y el diagrama de caja y bigotes.
Debe tenerse presente, sin embargo, que todas las conclusiones deben basarse en los resultados de la prueba de Tukey, que es la que tiene carácter inferencial. El diagrama de caja y bigotes cumple una función descriptiva y de apoyo a la interpretación.
En este capítulo se han presentado varios esquemas de aleatorización, siguiendo una gradación acorde con el conocimiento que se tenga sobre posibles fuentes de variación secundarias y con el control que pueda ejercerse sobre estas.
El esquema de aleatorización completamente al azar es el adecuado cuando no es posible identificar o separar fuentes de variación adicionales a tratamientos.
Este esquema no impone ninguna restricción sobre la aleatorización. Cualquier tratamiento tiene la misma probabilidad de ser asignado a cualquiera de las unidades experimentales disponibles. No obstante, debe tenerse presente la recomendación de intercalar los tratamientos espacial o temporalmente cuando haya lugar a ello (cf. sección 6.1.11.1 ).
El esquema de aleatorización en bloques completos al azar resulta adecuado cuando se identifica o intuye una fuente de variabilidad adicional a tratamientos y es viable conformar grupos de unidades experimentales homogéneos con respecto a los niveles de dicha fuente.
Esta estrategia, además de evitar que la fuente de variación secundaria actúe como factor de confusión, puede incrementar la potencia de las pruebas.
Bajo este esquema se impone una restricción sobre la aleatorización: cada bloque debe contener el conjunto completo de tratamientos. Esto genera una condición de ortogonalidad entre bloques y tratamientos que permite separar sus efectos.
El esquema de aleatorización en cuadro latino permite controlar dos fuentes de variabilidad adicionales a tratamientos, aplicando un doble bloqueo.
Esto evita que las fuentes de variación secundarias actúen como factores de confusión, a la vez que puede incrementar la potencia de las pruebas.
Bajo este esquema se imponen dos restricciones sobre la aleatorización: cada tratamiento debe aparecer en cada uno de los niveles del factor fila y del factor columna, de manera que tanto las filas como las columnas hagan las veces de bloques completos.
Esto genera una condición de ortogonalidad entre filas, columnas y tratamientos que permite separar sus efectos.
Los esquemas de aleatorización en cuadro grecolatino y cuadro hipergrecolatino generalizan la lógica del cuadro latino para tres o más fuentes de variación secundarias. Cada fuente adicional introduce una nueva restricción de ortogonalidad que permite separar su efecto del efecto de los tratamientos.
En todos los casos, el objetivo es el mismo: lograr que los tratamientos sean comparables, evitando que fuentes de variación secundarias actúen como factores de confusión y mejorando, cuando sea posible, la precisión de las comparaciones.
En este capítulo y el precedente se han presentado varias funciones personalizadas que permiten planear el experimento y evaluar la adecuación de los modelos.
mead: Permite explorar diferentes escenarios de número de réplicas, grados de libertad del error y tamaño total del experimento, a partir de la ecuación de los recursos propuesta por Mead et al. (2012).
check_model: Evalúa normalidad de residuales (internamente utiliza stats::shapiro.test) y homocedasticidad mediante la prueba generalizada de Levene (cf. sección 7.2.2), tanto para el modelo ajustado sobre la respuesta en esclala original, como para modelos alternativos basados en diferentes transformaciones.
Estas evaluaciones son aplicables a cualquiera de los modelos considerados en este capítulo.
levene_g: Realiza la prueba generalizada de Levene (cf. sección 7.2.2). A diferencia de check_model, cuyas salidas presentan únicamente el mínimo de los valores p de esta prueba —que suele ser suficiente para fines de diagnóstico— la función levene_g presenta los valores p de la prueba generalizada de Levene para cada uno de los efectos del modelo, lo que permite realizar una valoración más integral sobre posibles problemas de heterocedasticidad, en caso de que estén presentes.
La prueba generalizada de Levene es aplicable a cualquiera de los modelos considerados en este capítulo.
additivity_tests. Implementa las pruebas de aditividad de Tukey y LBI para el modelo de bloques completos al azar, las cuales usadas de manera conjunta, permiten un diagnóstico más completo sobre la naturaleza de las posibles interacciones entre bloques y tratamientos (cf. sección 7.2.3).
Esta implementación únicamente es aplicable al modelo de bloques completos al azar.
tukey_g. Implementa la prueba de aditividad de Tukey-Kohli para los modelos de cuadro latino, cuadro grecolatino y sus extensiones.
La tabla 7.15 resume las funciones disponibles para la validación de supuestos en los modelos considerados en este capítulo.
| Esquema de aleatorización | Normalidad | Homocedasticidad | Aditividad |
|---|---|---|---|
| Completamente al azar | check_model |
check_model |
No aplica |
| Bloques completos al azar | check_model |
check_model |
additivity_tests |
| Cuadro latino y extensiones | check_model |
check_model |
tukey_g |
Para la obtención del diagrama de caja y bigotes de la figura 7.2.↩︎
Dado que todos los tratamientos tienen igual número de réplicas, esta prueba resulta adecuada. En la sección 7.2.2 se presenta una formulación generalizada de la prueba de Levene válida para escenarios balanceados y desbalanceados.↩︎
Es necesario que los tratamientos (tto) estén definidos como factor.↩︎
Por ejemplo, un esquema con bloques conformados por 3 unidades experimentales en un ensayo con 5 tratamientos.↩︎
Eventualmente, podría existir interés en ello, pero no en el ámbito investigativo, sino durante la etapa de entrenamiento. En investigación aplicada, cuando se le asigna a un panel de catación la tarea de evaluar una serie de productos, se parte del supuesto de que todos los panelistas son igualmente competentes.↩︎
Estos ensayos suelen enfocarse en comparar diferentes procesos, matrices, temperaturas, fermentaciones, aditivos, etc.↩︎
Bien sea en los equipos mismos o en sus condiciones de ejecución.↩︎
\(Y_{ij}-\overline{Y}_{i\bullet}-\overline{Y}_{\bullet j} +\overline{Y}_{\bullet\bullet}\).↩︎
Desde luego, un ensayo con estas características tendría que ser avalado por el comité de bioética.↩︎
Aunque la función maneja por defecto gle = 15, en este caso lo escribimos para presentarlo explícitamente como un argumento que el usuario puede modificar.↩︎