data <- readxl::read_excel("ejemplo 4.1.xlsx")
shapiro.test(data$x)
Shapiro-Wilk normality test
data: data$x
W = 0.87622, p-value = 0.1432La inferencia estadística sobre una población hace referencia al conjunto de herramientas que permiten dilucidar aspectos de la población objetivo, a partir de una muestra obtenida de la misma.
En el marco conceptual de la inferencia paramétrica clásica, el comportamiento distribucional de la población objetivo es modelado a través de distribuciones probabilísticas teóricas. Una de las preguntas más básicas que la inferencia estadística ayuda a responder es si la distribución probabilística propuesta es adecuada para modelar el comportamiento distribucional de la población objetivo.
Las técnicas inferenciales que permiten responder esta pregunta se denominan pruebas de bondad de ajuste. Entre las de tipo genérico, es decir, las que permiten evaluar el ajuste de diferentes modelos probabilísticos están ji cuadrado, Kolmogorov-Smirnov, Cramér-von Mises y Anderson-Darling. Entre las específicas para evaluar el ajuste del modelo normal se destaca la prueba de Shapiro-Wilk.
En investigación aplicada, los modelos probabilísticos no representan un fin, sino que se usan como mecanismo para responder preguntas específicas sobre la población de campo que es objeto de investigación. Tales preguntas suelen expresarse mediante juegos de hipótesis sobre los parámetros del modelo.
Para el usuario de los métodos estadísticos son de particular interés las preguntas referidas a los parámetros \(\mu\) y \(\sigma^2\) de la distribución normal, pues constituyen el mecanismo más común para aproximarse al conocimiento de la media y la varianza de las poblaciones de campo. Asimismo, la inferencia sobre el parámetro \(p\) de la binomial permite elucubrar sobre las verdaderas proporciones en las poblaciones objetivo.
En el presente capítulo se presenta inicialmente una prueba de bondad de ajuste a la distribución normal. A continuación, se presentan las técnicas paramétricas clásicas de inferencia estadística sobre la media y la varianza de una población normal y sobre una proporción binomial.
Las exposiciones referidas a inferencia sobre un parámetro (\(\mu,\) \(\sigma^2\) o \(p\)) inician con pruebas de hipótesis. Seguidamente se presenta la contraparte inferencial correspondiente a la estimación por intervalo.
Los ejemplos que se presentan a partir de este capítulo pueden involucrar un número considerable de datos, lo que hace poco práctico digitarlos directamente. Aunque existen muchas formas de importar datos desde R (cf. R paso a paso: Lectura de datos), en este texto se ha optado por usar la importación desde un archivo Excel, mediante la función read_excel{readxl}.
Asimismo, en todos los casos, se suministra el archivo Excel con los datos, el cual puede descargarse haciendo clic en el correspondiente enlace.
Esta prueba de bondad de ajuste, propuesta en 1965 por Samuel Shapiro y Martin Wilk, permite evaluar si la distribución normal constituye un modelo adecuado para describir el comportamiento distribucional de una población de campo.
Esto se plantea mediante un juego de hipótesis, en el que la hipótesis nula postula que una muestra aleatoria de tamaño \(n\) proviene de una población normal, mientras que la alternativa indica que la muestra no proviene de una población normal.
\[
H_0: X_1,X_2,...,X_n \thicksim N
\] \[
H_a: X_1,X_2,...,X_n \nsim N
\]
De nuevo se insiste en el alcance de las conclusiones cuando se rechaza o no se rechaza la hipótesis nula:
Solo el rechazo tiene carácter de prueba estadística.
El no rechazo únicamente indica que no se han encontrado elementos para descartar la hipótesis nula con baja probabilidad de error, pero en ningún caso prueba que la prueba sea verdadera.
Por tanto, la “aceptación” o no rechazo de una prueba de Shapiro-Wilk no debe entenderse como una validación de normalidad.
Lo único que puede probarse estadísticamente mediante esta prueba es la no normalidad.
En general, cuando se realiza una prueba de bondad de ajuste (sea Shapiro-Wilk o cualquier otra), el rechazo de la hipótesis nula indica que el modelo probabilístico propuesto es inadecuado, mientras que el no rechazo simplemente sugiere que la distribución muestral no se aparta significativamente de la distribución teórica.
Aunque suele decirse que Shapiro-Wilk se usa para “probar normalidad”, esto debe entenderse en el sentido restringido de contrastar (cf. advertencia 3.1).
El estadístico de prueba, \(W,\) se calcula con base en la siguiente expresión:
\[
W=\frac{\left( \sum \limits_{i=1}^{n} a_i X_{(i)} \right)^2}
{\sum \limits_{i=1}^{n} \left(X_i-\overline{X} \right)^2 },
\]
donde \(X_{(i)}\) representa el \(i\)-ésimo estadístico de orden, es decir, la observación que ocupa la \(i\)-ésima posición en la muestra organizada ascendentemente (cf. sección 2.1.1.2). Los coeficientes \(a_i\) se obtienen a partir del vector de valores esperados de los estadísticos de orden de la distribución normal estándar y la correspondiente matriz de covarianzas. Aunque su obtención es compleja, no es necesario calcularlos cada vez que se realice la prueba, pues la propuesta de los autores incluye tablas con tales coeficientes, para tamaños muestrales entre 3 y 50 (Shapiro and Wilk, 1965).
En 1982, Royston propone una extensión de esta prueba, que puede usarse con muestras conformadas hasta por 2000 observaciones (Royston, 1982a) y presenta el correspondiente algoritmo computacional (Royston, 1982b), el cual incluye un método para el cálculo de los valores p.
Posteriormente, este mismo autor propone extensiones que permiten trabajar con datos censurados y con muestras de hasta 5000 datos. En 1995 incorpora estas extensiones en un algoritmo computacional (Royston, 1995), el cual constituye la base de la mayoría de las implementaciones actuales para realizar la prueba de Shapiro-Wilk, incluyendo la función shapiro.test{stats} de R.
El usuario no debe preocuparse por los desarrollos históricos que dieron lugar a la versión actual de la prueba de Shapiro-Wilk, puesto que la función shapiro.test{stats} está basada en el algoritmo publicado por Royston en 1995 (Royston, 1995), que incorpora todas sus extensiones y permite trabajar con muestras de hasta 5000 observaciones.
De hecho, la mayoría de implementaciones computacionales de esta prueba —si no todas— están basadas en este mismo algoritmo.
Ejemplo 4.1
Se desea averiguar si es adecuado modelar el comportamiento distribucional de una población mediante la normal, teniendo en cuenta la siguiente información muestral (ejemplo 4.1.xlsx).
\[
x = \{6.1, 2.9, 2.5, 3.6, 4.8, 2.7, 6.0, 6.9, 6.6\}
\]
Se plantea el siguiente juego de hipótesis:
\[
H_0: X_1,X_2,...,X_n \thicksim N
\]
\[
H_a: X_1,X_2,...,X_n \nsim N
\]
Para contrastar el juego de hipótesis, se usan las siguientes instrucciones en R.
data <- readxl::read_excel("ejemplo 4.1.xlsx")
shapiro.test(data$x)
Shapiro-Wilk normality test
data: data$x
W = 0.87622, p-value = 0.1432En la salida anterior, \(W\) es el valor del estadístico de prueba, mientras que “p-value” es el valor p. El criterio de rechazo de la hipótesis nula es igual al que se sigue en cualquier prueba de hipótesis: si el valor p ≤ \(\alpha,\) se rechaza la hipótesis nula.
En muchas de las pruebas de hipótesis que se manejan en investigación, el usuario espera poder rechazar la hipótesis nula, pues con ello logra respaldar la correspondiente hipótesis de investigación (la alternativa). En consecuencia, los investigadores suelen reportar orgullosos los bajos valores p obtenidos en sus ensayos, y no es para menos, pues mientras más bajo sea el valor p de una prueba, se tendrá menor probabilidad de errar al rechazar la hipótesis nula.
Por la forma en que las pruebas de bondad de ajuste —incluyendo Shapiro-Wilk— están planteadas, se sigue otra lógica. En estos casos, los bajos valores p no se exhiben con el mismo entusiasmo, pues la corroboración de que el modelo en el que uno pretendía basar su análisis es inadecuado no suele ser motivo de celebración.
Al concluir sobre una prueba de Shapiro-Wilk, al igual que con cualquier otra prueba de hipótesis, pueden cometerse dos tipos de error. El error tipo I, consiste en declarar no normal una población que sí lo es, y el error tipo II, consiste en declarar normal una población que no lo sea.
En los procesos inferenciales, la distribución normal se usa como modelo teórico del comportamiento distribucional de la población de campo objeto de la investigación (cf. sección 3.9). Por tanto, es necesario tener presente que no existen en campo poblaciones normales como tal. Lo que se contrasta mediante la prueba, más que una pregunta con una respuesta dicotómica que indique si los datos se distribuyen o no se distribuyen normalmente1, es qué tan adecuado resulta el uso de la normal para modelar el comportamiento distribucional de la población de campo.
Ya lo decía George Box, a través de un aforismo que ha llegado a ser muy popular en estadística:
Todos los modelos son incorrectos, pero algunos son útiles.
Teniendo en cuenta lo anterior, la definición concerniente a los dos tipos de error podría matizarse diciendo que el error tipo I consiste en declarar inadecuado el modelo normal en una situación en la que sea adecuado, mientras que el error tipo II consiste en declarar adecuado el modelo normal en una situación en la que no lo sea.
Esta declaración adquiere un matiz aun más profundo si se toma en consideración que los métodos estadísticos más usados en investigación son robustos a desviaciones del supuesto de normalidad (Milliken and Johnson, 2009; Schmider, Ziegler, Danay, Beyer and Bühner, 2010), lo que implica que no se requiere un ajuste cuasi perfecto del modelo normal para tener resultados confiables, bastando con que no se evidencien desviaciones severas.
Luego, si lo que se busca con la prueba de Shapiro-Wilk es detectar desviaciones severas del supuesto de normalidad, un error tipo I resultaría más inconveniente que un error tipo II, siendo recomendable, por tanto, ejercer un control estricto sobre la probabilidad de error tipo I, sin que la consecuente inflación de la probabilidad de error tipo II deba ser motivo de particular preocupación. Esto se logra realizando la prueba con un nivel de significancia \(\alpha = 0.01.\)
Para el presente ejemplo, dado que \(\text{p} > 0.01,\) la prueba de Shapiro-Wilk no evidencia una desviación severa de la normalidad, por lo que esta muestra bien podría usarse en algún proceso inferencial basado en dicho supuesto.
Para evaluar desviaciones severas del supuesto de normalidad, se recomienda usar la prueba de Shapiro-Wilk, con un nivel de significancia \(\alpha = 0.01.\)
Este será el criterio seguido a lo largo de este texto, el cual puede expresarse así:
si \(\text{p}≤0.01,\) se concluye que el modelo normal es particularmente inadecuado, siendo necesario evaluar alternativas2.
si \(\text{p}>0.01,\) se prosigue con el método que tenga como base la distribución normal.
Tal y como se indica en la sección 3.9, la inferencia estadística se basa en dos conjuntos de herramientas: la estimación y las pruebas de hipótesis. A su vez, la estimación puede ser puntual o por intervalos. En esta sección se mostrará que las pruebas de hipótesis y los intervalos de confianza constituyen lo que podría denominarse los dos lados de una misma moneda.
Se presenta inicialmente lo concerniente a la prueba de hipótesis; seguidamente, tomando esta como punto de partida, se desarrolla la estimación por intervalo.
Considérese una muestra aleatoria de tamaño \(n\) de una población normal:
\[
X_1,X_2,...,X_n\: \text{iid}\: N\left(\mu, \sigma^2\right)
\tag{4.1}\]
Para inferir sobre la media poblacional, \(\mu,\) se parte de su estimador insesgado de mínima varianza: la media muestral (cf. sección 3.9.1.1.1), la cual a su vez es una variable aleatoria normalmente distribuida, así:
\[
\overline{X}\thicksim N\left(\mu,\, \sigma^2/n\right)
\]
Al restar la media y dividir por la desviación estándar, se obtiene una variable aleatoria normal estándar:
\[
\frac{\overline{X}-\mu}{\sigma/\sqrt{n}}\thicksim N\left(0,\, 1\right)
\]
Esta variable aleatoria podría usarse como estadístico de prueba para construir una prueba de hipótesis sobre el parámetro \(\mu,\) siempre que la desviación estándar, \(\sigma,\) que aparece en el denominador fuera conocida. De hecho, en muchos textos se presentan diferentes versiones de dicha prueba de hipótesis; una de ellas para los casos en que se conozca la varianza y otra para los casos en que la varianza sea desconocida.
Aunque el asunto de que la varianza poblacional sea conocida no parece desvelar mucho a tales autores, recurriendo a dar el valor de la misma en los ejemplos que así lo requieran, sí sería un aspecto muy preocupante para el investigador, a quien nadie le dará la varianza poblacional, viéndose obligado a realizar un censo poblacional si se le exigiera conocerla, lo cual, a todas luces, estaría fuera de lugar.
En la práctica investigativa, nunca se conoce la varianza poblacional.
Para resolver el problema del parámetro poblacional desconocido, lo lógico es incluir en su lugar su estimador insesgado de mínima varianza (cf. sección 3.9.1.1.2). No obstante, al realizar este cambio, el nuevo estadístico no seguirá necesariamente la distribución normal estándar. Gosset, de quien se habló en la sección 3.7.3, fue el primero en estudiar la distribución del nuevo estadístico.
A continuación se presenta una reformulación moderna, apoyada en resultados sobre las distribuciones normal estándar y ji cuadrado, que permite entender con claridad el origen de la distribución resultante. Para ello, se comienza por reexpresar la variable aleatoria de interés de una manera más conveniente, usando factores comunes en el numerador y el denominador.
\[
\begin{align}
\frac{\overline{X}-\mu}{S/\sqrt{n}}&=\frac{\left(\overline{X}-\mu\right) \Big{/} \sigma}{S\big/\sqrt{n\sigma^2}}\\[1.4em]
&=\frac{\left(\overline{X}-\mu\right) \bigg{/} \sigma\big/\sqrt{n}}{\sqrt{S^2\big/\sigma^2}}\\[1.4em]
&=\frac{\left(\overline{X}-\mu\right) \bigg{/} \sigma\big/\sqrt{n}}
{{\sqrt{\frac{(n-1)S^2}{\sigma^2}\bigg/(n-1)}}}
\end{align}
\]
Desglosando la última expresión obtenida, se observa que la variable aleatoria del numerador es normal estándar (cf. sección 3.7.1), mientras que el denominador consiste en la raíz cuadrada de una variable aleatoria ji cuadrado, dividida entre sus grados de libertad (cf. sección 4.3.1.1).
La razón entre una variable aleatoria normal estándar y la raíz cuadrada de una ji cuadrado dividida entre sus grados de libertad genera una variable aleatoria con distribución \(t\) (cf. sección 3.7.3).
Por tanto, dado que:
\[
\begin{align}
\frac{\left(\overline{X}-\mu\right) }{ \sigma\big/\sqrt{n}} \thicksim N(0, 1)\,\, &\text{y} \,\, {\frac{(n-1)S^2}{\sigma^2}} \thicksim \chi^2_{(n-1)},\\[1.4em]
\frac{\overline{X}-\mu}{S/\sqrt{n}}&\thicksim t_{(n-1)}
\end{align}
\]
Con base en la anterior variable aleatoria se genera el estadístico de prueba. Para ello, se impone una restricción que se satisfaga cuando la hipótesis nula sea cierta.
Considérese el siguiente juego de hipótesis:
\[
H_0: \mu=\mu_0
\] \[
H_a: \mu\ne\mu_0
\]
Si la hipótesis nula es cierta, es decir, si \(\mu = \mu_0,\) la variable aleatoria puede reescribirse intercambiando \(\mu\) por \(\mu_0,\) y su distribución seguirá siendo \(t_{(n−1)},\) lo cual se expresa así:
\[
t\equiv t_\text{c}=\frac{\overline{X}-\mu_0}{S/\sqrt{n}}\overset {H_0}\thicksim t_{(n-1)}
\tag{4.2}\]
Se tiene, pues, una variable aleatoria cuya distribución bajo la hipótesis nula es conocida. Este es precisamente el estadístico de prueba (cf. sección 3.9.2.4).
Puesto que su distribución bajo la hipótesis nula es \(t_{(n−1)},\) dicho estadístico se denomina \(t\) o \(t_\text{c}\) para distinguirlo del valor crítico contra el cual habría de compararse usando el método tradicional de contraste de hipótesis (cf. sección 3.9.2.4).
Sin importar si la prueba es de una o de dos colas, siempre se usa el mismo estadístico de prueba; lo único que cambia es el criterio de rechazo y la forma en que se calcula el valor p.
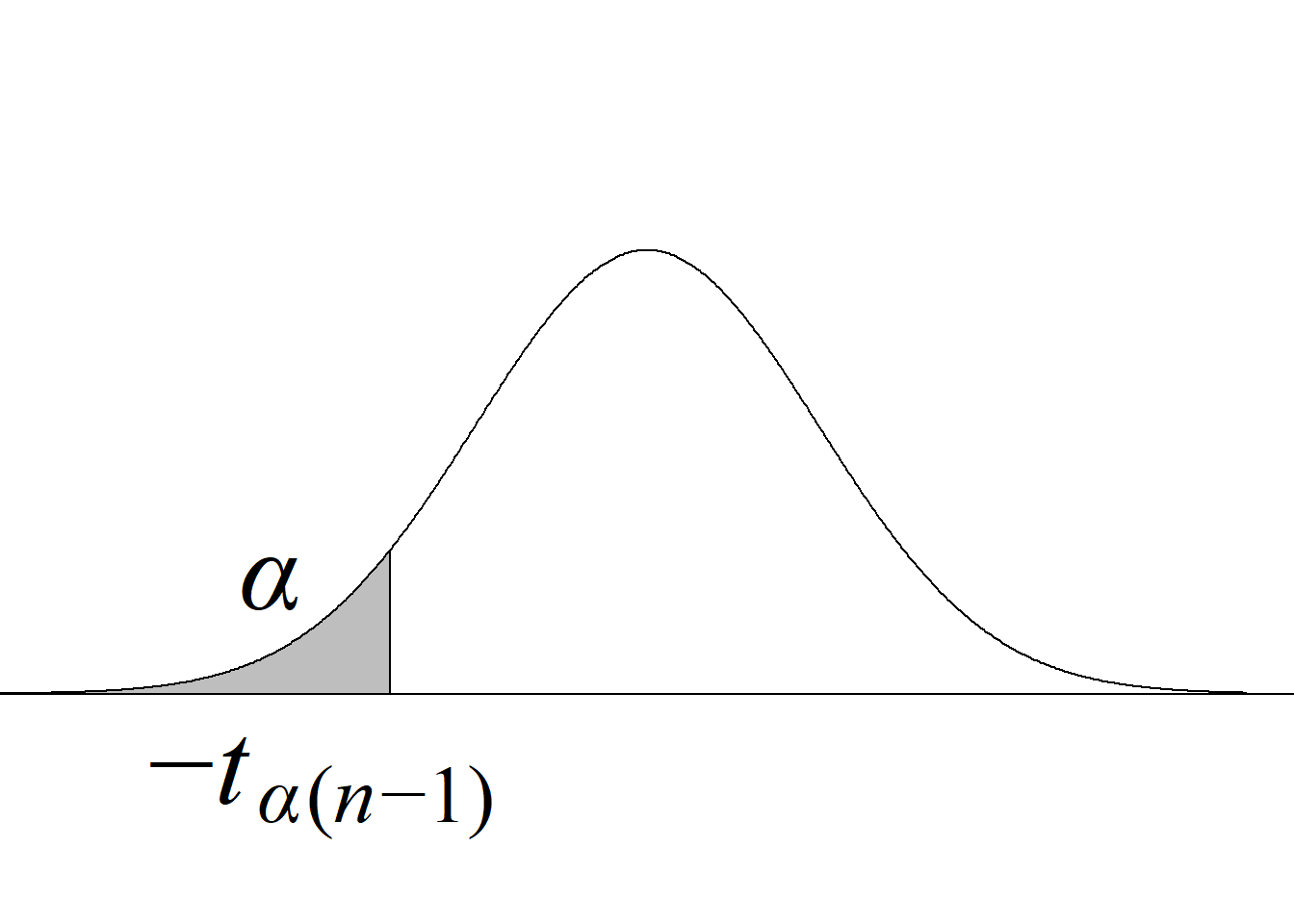
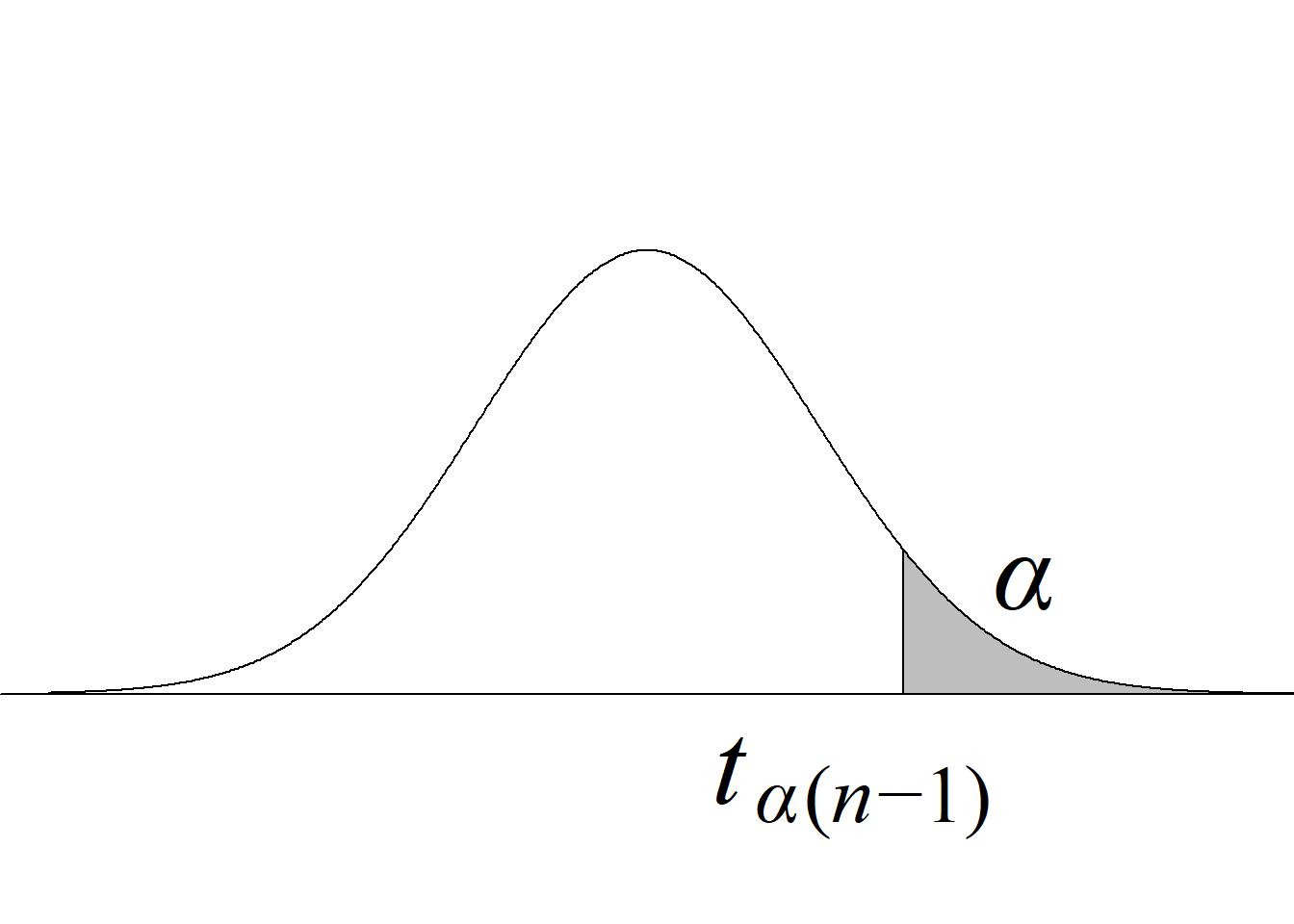
La tabla 4.1 y la figura 4.1 ilustran la forma en que se usa el estadístico de prueba para definir el criterio de rechazo y calcular el valor p.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda \(H_0:\mu\ge\mu_0\) \(H_a:\mu<\mu_0\) |
\(t_\text{c}\le−t_{\alpha(n-1)}\) |
\(P(t_{(n-1)} < t_\text{c})\) |
| Cola derecha \(H_0:\mu\le\mu_0\) \(H_a:\mu>\mu_0\) |
\(t_\text{c}\ge t_{\alpha(n-1)}\) |
\(P(t_{(n-1)} > t_\text{c})\) |
| Dos colas \(H_0:\mu=\mu_0\) \(H_a:\mu\ne\mu_0\) |
\(|t_\text{c}|\ge t_{\alpha/2(n-1)}\) |
\(2 \, P(t_{(n-1)} > |t_\text{c}|)\) |
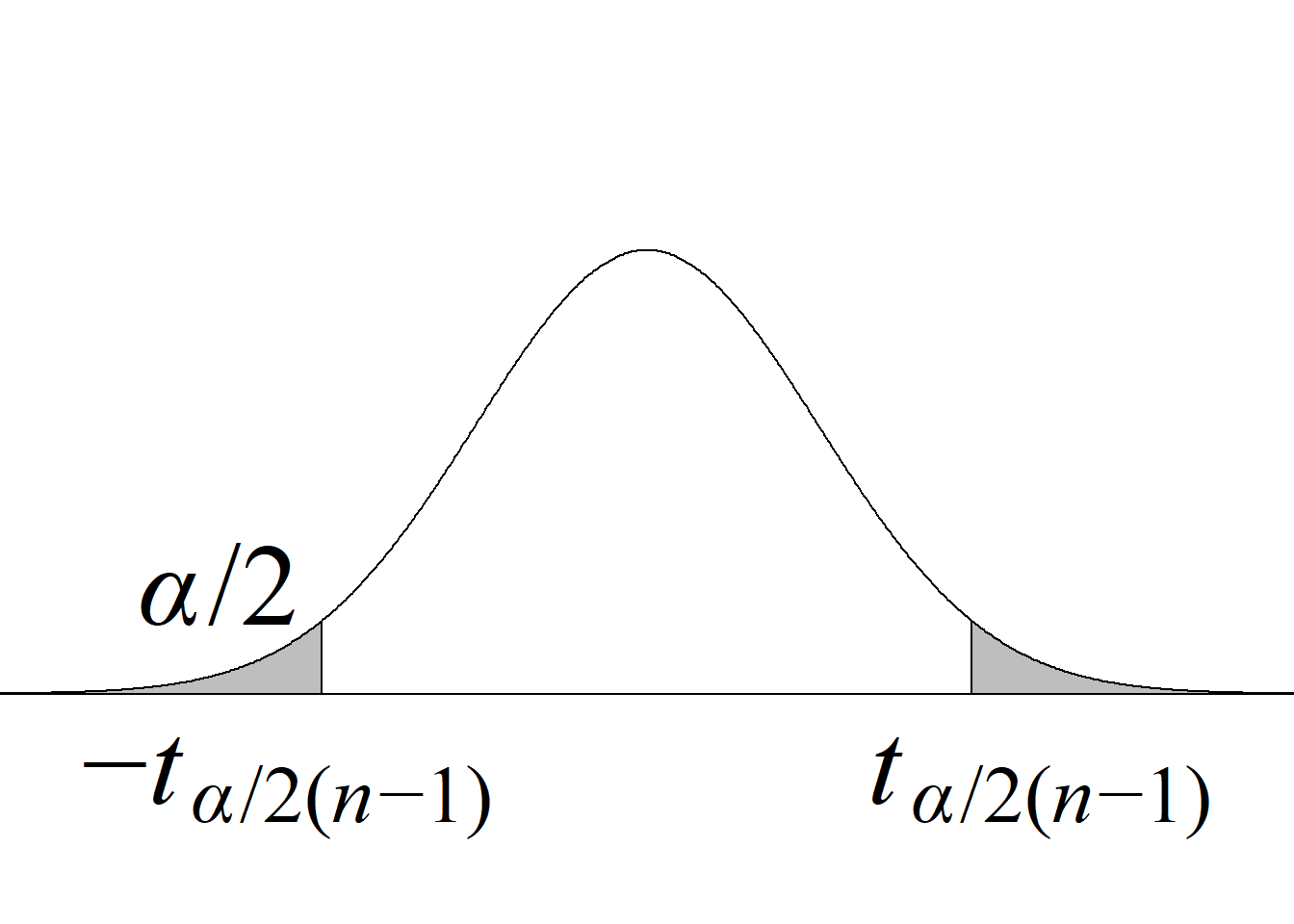
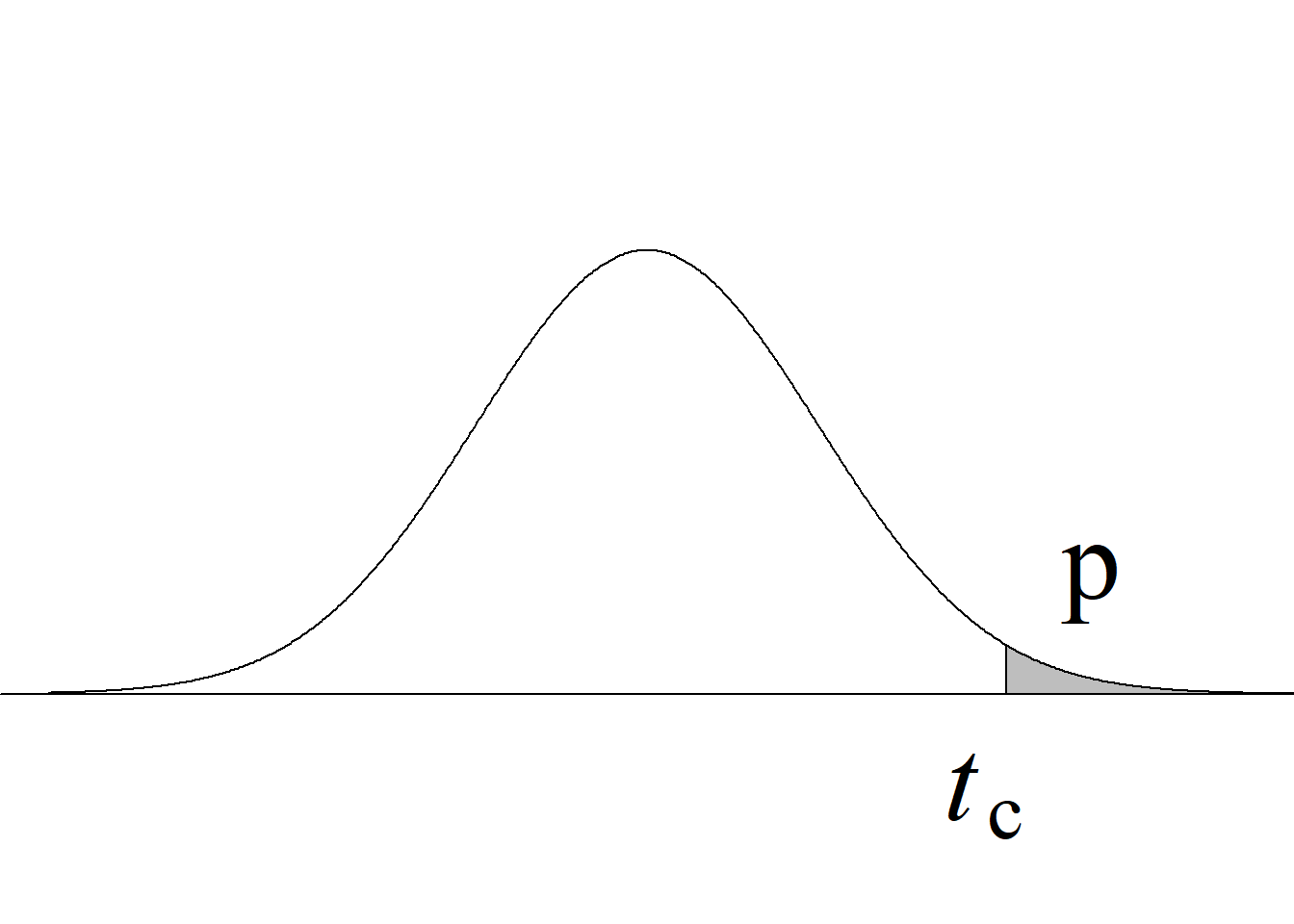
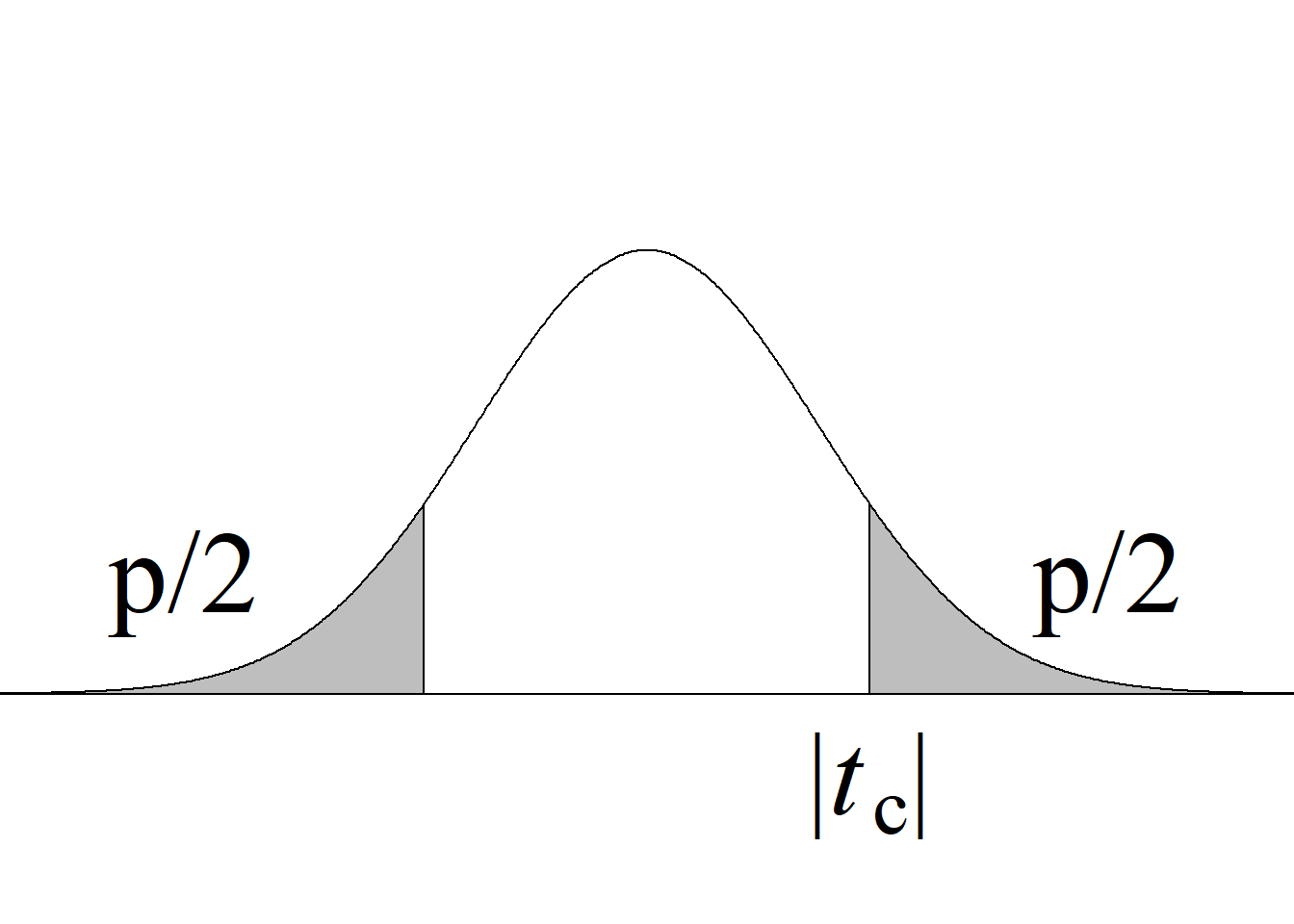
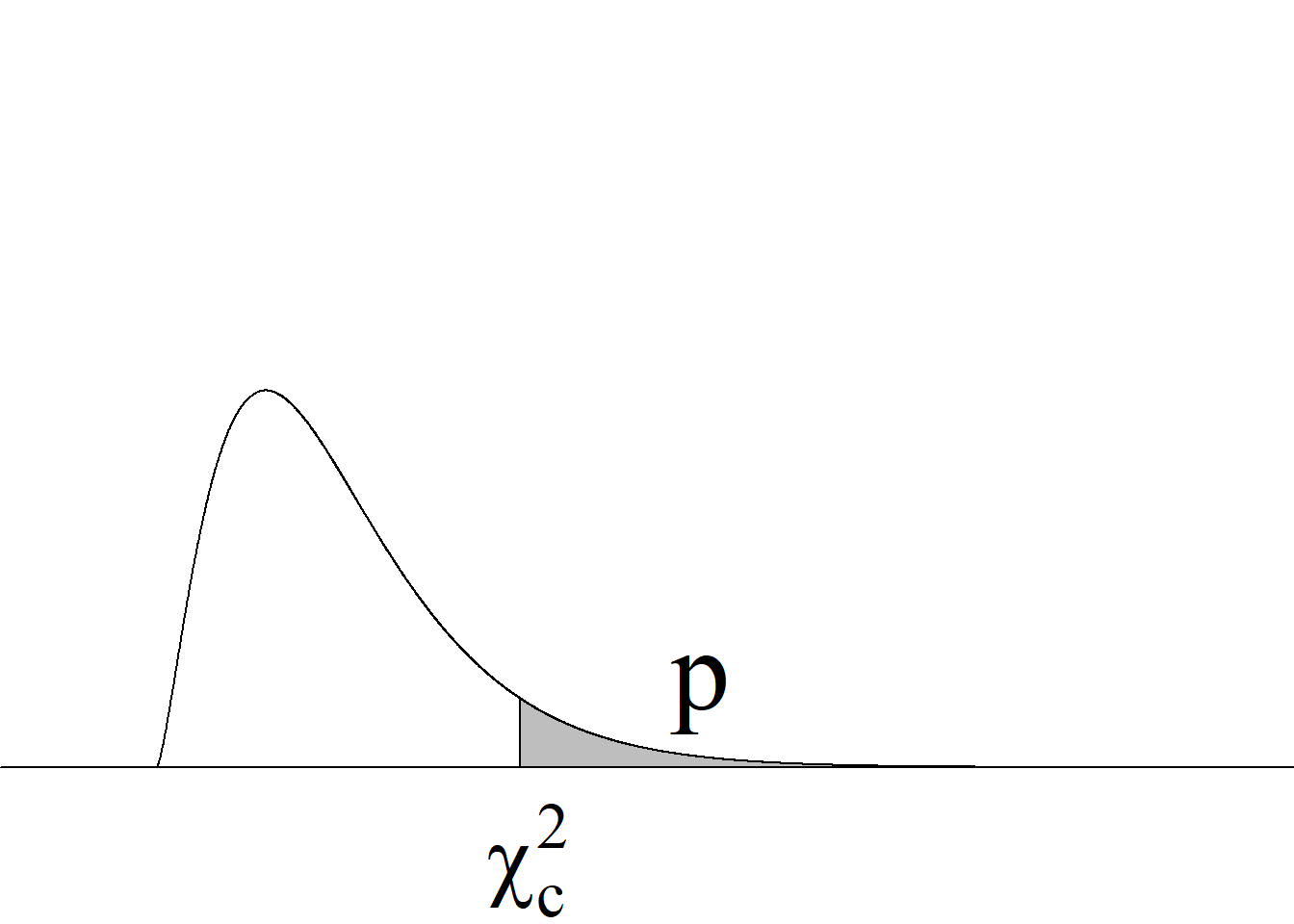
Acorde con la metodología tradicional, el criterio de rechazo de la hipótesis nula para una prueba de dos colas consiste en rechazar \(H_0\) si el estadístico de prueba es menor o igual que el valor que deja un área de \(\alpha/2\) a su izquierda o si es mayor o igual que el valor que deja un área de \(\alpha/2\) a su derecha (figura 4.1 (c)).
Aunque la regla de rechazo para una prueba de dos colas quedaría correctamente expresada, indicando que se rechaza la hipótesis nula si \(t_\text{c} ≤ t_{1−α/2(n−1)}\) o si \(t_\text{c} ≥ t_{α/2(n−1)},\) cuando la prueba de hipótesis está basada en una distribución simétrica y centrada en cero3, se aprovecha la relación existente entre los valores críticos inferior y superior, esto es, que \(-t_{1−α/2(n−1)} = t_{α/2(n−1)},\) para escribir la regla de manera más sucinta, usando la función valor absoluto.
Ejemplo 4.2
Un equipo está programado para empacar 750 g de fertilizante por bolsa. Después de haber sufrido un desperfecto y haber sido reparado por un técnico local, se desea evaluar su calibración. Para ello, se realiza una prueba, consistente en empacar 30 bolsas y pesarlas en una balanza de alta precisión.
Los resultados de dichos pesajes se presentan en la tabla 4.2.
| 748.54 | 729.98 | 761.46 | 765.65 | 769.63 | 763.42 |
| 754.12 | 774.11 | 747.62 | 771.18 | 736.71 | 776.26 |
| 738.07 | 747.93 | 772.95 | 721.84 | 770.14 | 751.91 |
| 770.27 | 759.94 | 734.81 | 771.54 | 774.04 | 739.15 |
| 764.99 | 750.43 | 738.96 | 754.31 | 755.50 | 749.55 |
Aunque una evaluación completa del estado de calibración del equipo implica verificar no solo que esté empacando en promedio la cantidad de fertilizante para la cual ha sido programado, sino también que las cantidades de las diferentes bolsas estén concentradas alrededor de dicha media (baja varianza), en el presente ejemplo verificaremos únicamente lo concerniente a la media; en el ejemplo 4.3 se considera lo relativo a la variabilidad.
Antes de aplicar la estrategia presentada anteriormente, debe verificarse la adecuación del supuesto de normalidad, para cuyo efecto se realiza la prueba de Shapiro-Wilk, con un nivel de significancia \(α = 0.01,\) usando el siguiente script en R.
La información presentada en la tabla 4.2 está contenida en el archivo Excel ejemplo 4.2.xlsx.
data <- readxl::read_excel("ejemplo 4.2.xlsx")
shapiro.test(data$peso)
Shapiro-Wilk normality test
data: data$peso
W = 0.94366, p-value = 0.1142Puesto que \(\text{p}>0.01,\) no se evidencian desviaciones severas del supuesto de normalidad, siendo procedente, por tanto, plantear y contrastar el juego de hipótesis principal sobre la media:
\(H_0: \mu=750\) (equipo calibrado)
\(H_a: \mu\ne750\) (equipo descalibrado)
Por el contexto del presente problema, resulta claro que debe usarse una prueba de dos colas. En este caso, cualquier desviación de la media objetivo (750 g), ya sea por encima o por debajo, indicaría que el equipo está descalibrado.
Bien sea que se pretenda usar la estrategia de evaluación tradicional, basada en la comparación entre el estadístico de prueba y un valor crítico o la que consiste en comparar el valor p contra el nivel de significancia, es necesario definir el correspondiente nivel de significancia de la prueba.
Se ha indicado anteriormente que, aunque no es posible establecer de manera genérica que uno de los dos errores sea más grave que el otro, sí es posible realizar dicho análisis en determinados contextos (cf. secciones 3.9.2.2 y 4.1). Para ampliar este concepto presentaremos a continuación dos escenarios contrastantes que, en caso de presentarse, constituirían una clara guía para la definición del nivel de significancia.
| Escenario A | Escenario B |
|---|---|
| De comprobarse que el técnico local fracasó en su intento de reparación, sería necesario enviar el equipo a Finlandia para la correspondiente calibración. Por otra parte, habría que considerar que el fertilizante es de bajo costo y que no existe ningún tipo de control gubernamental sobre las especificaciones del producto. |
De ser necesario, el técnico local puede realizar a muy bajo costo los ajustes adicionales que sean requeridos, hasta que la calibración sea prácticamente perfecta. Por otra parte, debe considerarse que el fertilizante es de alto costo y que existe un estricto control gubernamental sobre las especificaciones del producto. |
Para el juego de hipótesis que se está considerando, el error tipo I consiste en declarar que el equipo está descalibrado sin ser así, mientras que el error tipo II consiste en concluir que el equipo está calibrado sin ser así.
Tal y como se indica en el tip 3.3, la comunidad científica ha adoptado el valor de 0.05 como estándar para el nivel de significancia; no obstante, el usuario podría moverse alrededor de dicho estándar si existieran condiciones especiales que sustentaran dicha decisión (cf. secciones 3.9.2.2 y 4.1).
En el presente ejemplo, los escenarios planteados brindarían dicho sustento. Sería lógico que el usuario optara por una particular protección contra el error tipo I, si estuviera en el escenario A, y que buscara protegerse del error tipo II, si se encontrara en el escenario B.
Suponiendo que no se tenga posibilidad de incrementar el tamaño de la muestra4, podría elegirse, por ejemplo, un nivel de significancia \(α = 0.01,\) si se estuviera en el escenario A, y un nivel de significancia \(α = 0.1,\) si se estuviera bajo las condiciones del escenario B.
Para continuar con el desarrollo de este ejemplo, supondremos que se detectaron las condiciones del escenario B, eligiéndose, por tanto, un nivel de significancia \(α = 0.1.\)
Nótese lo engañoso que puede ser calificar una prueba, teniendo en cuenta únicamente su nivel de significancia.
Una aproximación desprevenida podría llevarnos a asociar pruebas que tengan un nivel de significancia muy bajo con pruebas estrictas y pruebas con un nivel de significancia alto con pruebas laxas.
En el presente ejemplo, el nivel de significancia elegido es particularmente alto (en relación con el estándar de 0.05), lo que podría hacernos pensar que no estamos siendo lo suficientemente estrictos.
No obstante, si se tiene en cuenta que el error tipo I consiste en declarar descalibrado un equipo que no lo está, la verificación del equipo es en realidad más exigente en este caso que si se hubiera elegido, por ejemplo, un nivel de significancia \(α = 0.01,\) en cuyo caso, el equipo tendría que exhibir desviaciones muy severas para declararse descalibrado.
Para contrastar el juego de hipótesis planteado, se calcula el estadístico de prueba, mediante la expresión 4.2, a partir de la información muestral que aparece en la tabla 4.2:
\[
t_\text{c}=\frac{\overline{X}-\mu_0}{S \big {/} \sqrt{n}}=
\frac{755.5-750}{15\big {/} \sqrt{30}}=2.008
\tag{4.3}\]
Mediante la expresión 4.3 se realiza una simplificación bastante frecuente en los textos de inferencia estadística aplicada.
El punto de partida es la variable aleatoria cuya distribución se conoce bajo la condición impuesta por la hipótesis nula:
\[
t_\text{c} = \frac{\overline{X}-\mu_0}{S/\sqrt{n}}\overset {H_0}\thicksim t_{(n-1)}
\]
Dejando de lado a \(\mu_0\) y \(n,\) que representan constantes para una muestra dada en un ejercicio particular, la media y la varianza son variables aleatorias. Esa es la razón por la que se escriben en mayúsculas, acorde con la convención presentada en la sección 3.5.
Según esta misma convención, una realización o valor observado de dicha variable aleatoria se escribiría así:
\[
t_\text{c} = \frac{\overline{x}-\mu_0}{s/\sqrt{n}}
\]
Luego, la descripción ortodoxa del procedimiento completo sería así:
Puesto que:
\[
T = \frac{\overline{X}-\mu_0}{S/\sqrt{n}}\overset {H_0}\thicksim t_{(n-1)},
\]
el valor observado de dicha variable aleatoria para esta muestra particular es (¡nótense las minúsculas!):
\[
t_\text{c} = \frac{\overline{x}-\mu_0}{s/\sqrt{n}}=\frac{755.5-750}{15\big {/} \sqrt{30}}=2.008
\]
No obstante lo anterior, en la práctica estadística es habitual usar la misma expresión simbólica para definir el estadístico (variable aleatoria) y para evaluar su valor numérico (realizaciones), lo que simplifica los procedimientos y permite concentrarse en los desarrollos.
Esta es la convención que se adopta en el presente texto.
Dado que se está contrastando un juego de hipótesis de dos colas, el valor absoluto del estadístico de prueba se compara contra el valor crítico \(t_{α/2(n−1)},\) esto es, \(t_{0.05(29)},\) acorde con los criterios que se resumen en la tabla 4.1 y en figura 4.1 (c).
Usando la instrucción qt(0.05, 29, lower.tail = F) en R, se obtiene que \(t_{0.05(29)} = 1.6991.\) Por tanto, se rechaza la hipótesis nula con un nivel de significancia del 10 %.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(|t_\text{c}|\) \(2.008\) |
\(>\) \(>\) |
\(t_{0.05(29)}\) \(1.6991\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) se rechaza \(H_0\) con \(α = 0.1\) |
Siempre que se contrasta un juego de hipótesis en algún contexto aplicado es esencial trascender la presentación de las conclusiones más allá del rechazo o no rechazo de la hipótesis nula, integrando dicho contexto a la presentación de los resultados.
Teniendo en cuenta que el juego de hipótesis contrastado se refiere únicamente al parámetro de ubicación, la conclusión podría precisarse así:
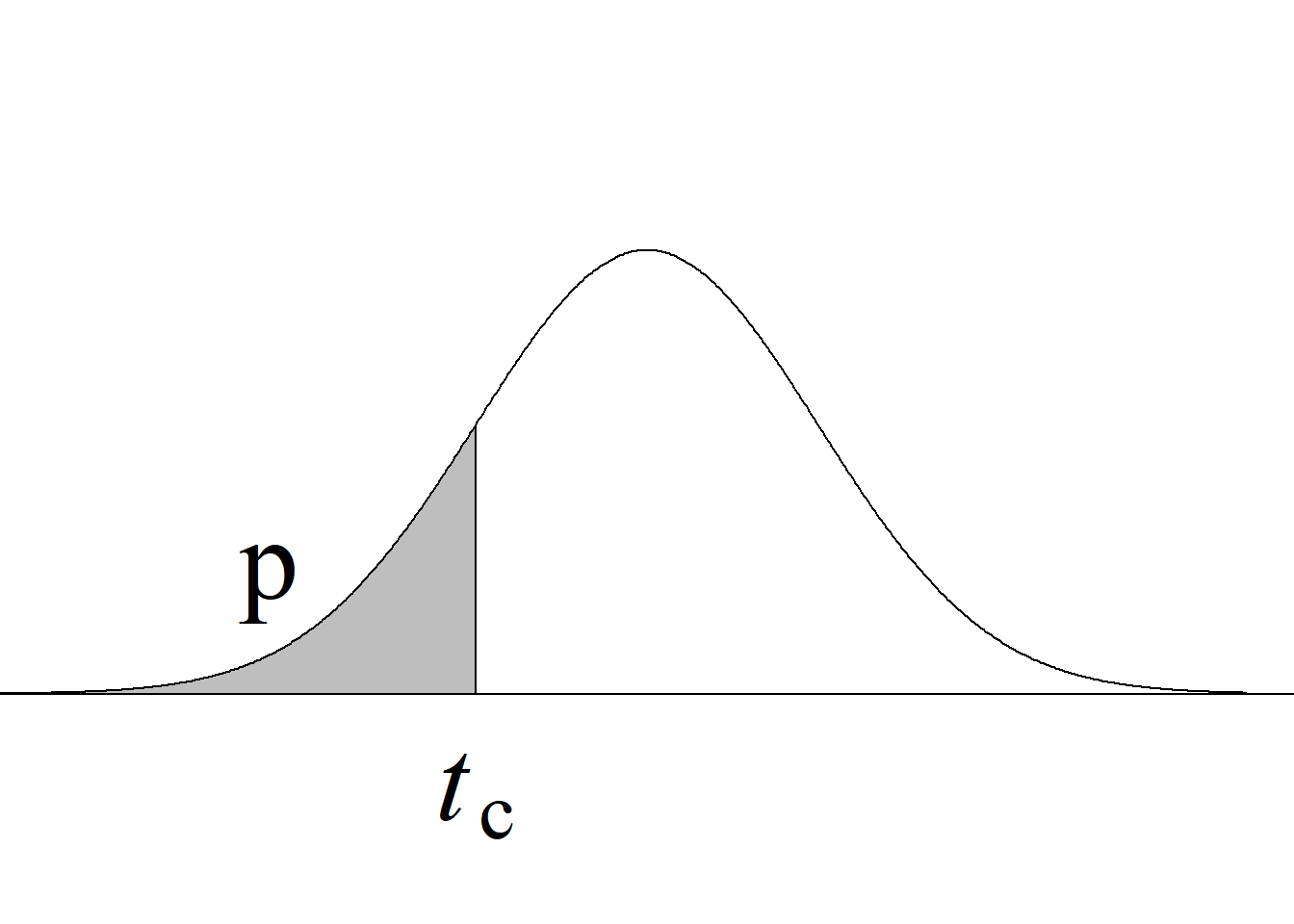
El procedimiento seguido para contrastar el juego de hipótesis, en el que se compara el estadístico de prueba contra un valor crítico, corresponde al denominado método tradicional. En la actualidad es más común e informativo contrastar las hipótesis usando el valor p.
Para el presente caso, en el que se tiene una prueba de dos colas, el valor p se obtiene como \(2\, P(t_{(n−1)} > |t_\text{c}|),\) acorde con los criterios que se resumen en la tabla 4.1 y en figura 4.1 (f). Para obtener dicho valor en R, se usa la instrucción 2 * pt(abs(2.008), 29, lower.tail = F), obteniéndose que p = 0.054.
Para concluir sobre un juego de hipótesis estadísticas a partir del valor p no se requiere ningún valor crítico; basta con definir un nivel de significancia que actúe como referente de comparación.
En el presente ejemplo, en el que se ha supuesto que se está bajo las condiciones del escenario B, se ha establecido \(α = 0.1\) como máxima probabilidad de error tipo I. Puesto que la probabilidad de cometer error tipo I si se rechazara con base en la presente información muestral está por debajo de la máxima probabilidad de error tipo I preestablecida, se rechaza la hipótesis nula.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.054\) |
\(<\) \(<\) |
\(\alpha\) \(0.1\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) se rechaza \(H_0\) |
Aunque las conclusiones a las que se llega por cualquiera de los dos métodos siempre son coincidentes, el valor p brinda información adicional al método tradicional. Así, por ejemplo, puede observarse que si se hubiera elegido un nivel de significancia del 5 %, la presente información muestral no hubiera permitido rechazar la hipótesis nula.
Esto es de gran relevancia, porque, si bien es cierto que el no rechazo (o aceptación) de la hipótesis nula no tiene carácter de prueba, para fines prácticos, el equipo habría pasado como calibrado.
Ya se había mencionado anteriormente lo engañoso que puede resultar calificar una prueba a partir únicamente de su nivel de significancia, sin tener en cuenta la hipótesis que se contrasta. Visto a la ligera, podría parecer que una prueba con un nivel de significancia \(α = 0.05,\) es más exigente que otra en la que se trabaje con \(α = 0.1.\) Resulta claro, sin embargo, que esto no es correcto para el presente ejemplo.
Esto se clarifica al considerar que \(\alpha\) se refiere únicamente al error tipo I. En el presente caso, por el escenario planteado, resulta más preocupante cometer un error tipo II, y puesto que no existe la posibilidad de incrementar el tamaño de la muestra, la única posibilidad que se tiene de controlar el error tipo II consiste en explotar la relación inversa existente entre \(\alpha\) y \(\beta\) (cf. sección 3.9.2.2). Desde luego, una disminución en la probabilidad de error tipo II es equivalente a un incremento en la potencia de la prueba \((1-\beta).\) Esto es justamente lo que se logra al elegir \(\alpha = 0.1.\)
Considérese como punto de partida una prueba de hipótesis de dos colas, con un nivel de significancia \(α,\) para la media, \(\mu,\) de una población normal.
La figura 4.2 muestra la distribución probabilística del estadístico de prueba \(t_\text{c}\) bajo la hipótesis nula, con sus correspondientes regiones de rechazo y aceptación.
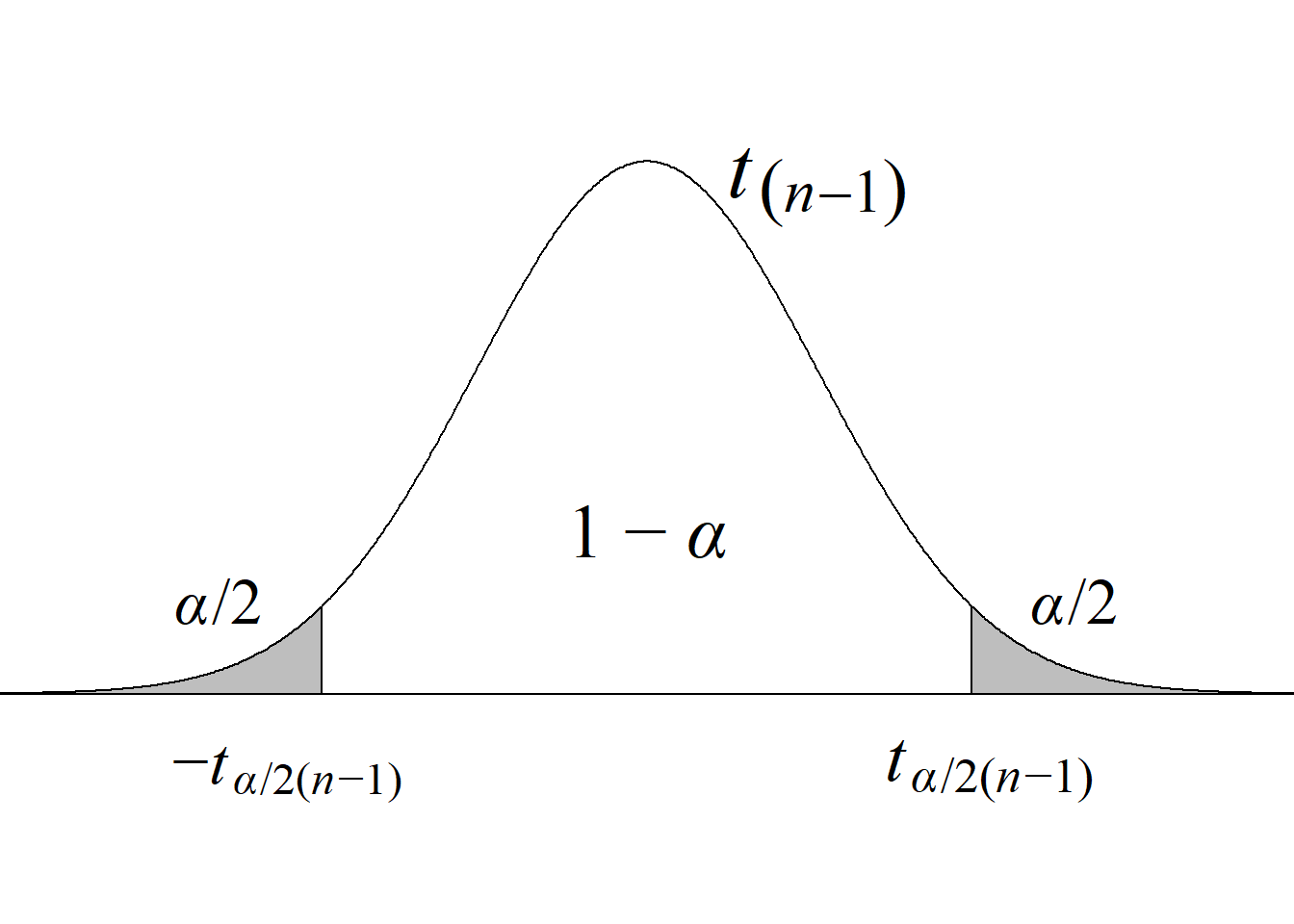
El criterio de rechazo se expresa así:
Si \(|t_\text{c}|\ge t_{\alpha/2(n-1)},\) se rechaza \(H_0\) con un nivel de significancia \(\alpha.\)
En términos probabilísticos, esta condición puede escribirse de la siguiente manera:
\[
P\left(|t_\text{c}|\ge t_{\alpha/2(n-1)}|H_0\right)=\alpha
\]
Consecuentemente,
\[
P\left(|t_\text{c}|< t_{\alpha/2(n-1)}|H_0\right)=1-\alpha
\]
Resolviendo el valor absoluto, se tiene:
\[
P\left(-t_{\alpha/2(n-1)}<t_\text{c}< t_{\alpha/2(n-1)}|H_0\right)=1-\alpha
\]
Remplazando \(t_\text{c}\) con la expresión usada para su cálculo (cf. expresión 4.2):
\[
P\left(-t_{\alpha/2(n-1)}<\frac{\overline{X}-\mu_0}{S \big {/} \sqrt{n}}< t_{\alpha/2(n-1)}\big{|}H_0\right)=1-\alpha
\]
Se multiplican todos los términos de la desigualdad por el error estándar de la media. Por tratarse de un valor positivo, no se altera el sentido de la inecuación:
\[
P\left(-t_{\alpha/2(n-1)}S \big {/} \sqrt{n}<\overline{X}-\mu_0< t_{\alpha/2(n-1)}S \big {/} \sqrt{n}\big{|}H_0\right)=1-\alpha
\]
Se resta la media muestral a todos los términos de la desigualdad:
\[
P\left(-t_{\alpha/2(n-1)}S \big {/} \sqrt{n}-\overline{X}<-\mu_0< t_{\alpha/2(n-1)}S \big {/} \sqrt{n}-\overline{X}\big{|}H_0\right)=1-\alpha
\]
Se multiplican todos los términos de la desigualdad por \(−1,\) lo que cambia el sentido de la misma. Se reescribe la hipótesis nula:
\[
P\left(\overline{X}-t_{\alpha/2(n-1)}S \big {/} \sqrt{n}<\mu_0<\overline{X}+t_{\alpha/2(n-1)}S \big {/} \sqrt{n}\big{|}\mu=\mu_0\right)=1-\alpha
\]
Se incorpora la condición indicada por la hipótesis nula:
\[
P\left(\overline{X}-t_{\alpha/2(n-1)}S \big {/} \sqrt{n}<\mu<\overline{X}+t_{\alpha/2(n-1)}S \big {/} \sqrt{n}\right)=1-\alpha
\]
La expresión anterior está constituida por un par de variables aleatorias, entre las cuales se halla el parámetro \(\mu,\) con probabilidad \(1 − α.\) Esta es justamente la forma en la que se define un intervalo de confianza del \(100(1-\alpha)\,\%\) para el parámetro \(\mu\) (cf. sección 3.9.1.2). A la variable aleatoria que se encuentra a la izquierda se le denomina límite inferior; a la que se ubica a la derecha, límite superior.
Puesto que los límites aleatorios del intervalo se han obtenido invirtiendo la región de aceptación de la prueba de hipótesis para \(\mu,\) a este procedimiento se le denomina de método de inversión. Debe tenerse presente, sin embargo, que este método no siempre es tan expedito como en el presente caso.
El uso del método de inversión permite apreciar que las pruebas de hipótesis y los intervalos de confianza, al estar basados en la misma información, constituyen las dos caras de una misma moneda.
Cuando se utilizan pruebas de hipótesis e intervalos de confianza como herramientas de análisis complementarias, es necesario mantener la consistencia entre estas.
El \(\alpha\) utilizado como nivel de significancia para la prueba de hipótesis debe corresponder con el empleado como complemento de la confianza en la expresión \(100(1−\alpha)\,\%\) del intervalo de confianza.
Un intervalo de confianza para el contenido medio de fertilizante del ejemplo 4.2 deberá estar acorde con las consideraciones realizadas en cuanto al nivel de significancia de la prueba.
Anteriormente se discutió que el escenario B hacía conveniente trabajar con \(α = 0.1.\) En consecuencia, el correspondiente intervalo de confianza para \(\mu\) es del \(100(1 − 0.1)\,\%=90\,\%.\)
Un intervalo de confianza del 90 % para \(\mu\) está dado por:
\[
\begin{align}
\overline{X}\pm t_{\alpha/2(n-1)}\frac{S}{\sqrt{n}}&=755.5\pm 1.6991\frac{15}{\sqrt{30}}\\[1.4em]
&=755.5\pm 4.653
\end{align}
\]
\[
\text{IC:}\quad [750.85,\;\; 760.15]
\]
A partir de este resultado, puede decirse que se tiene una confianza del 90 % en que el contenido medio de fertilizante, \(\mu,\) depositado en las bolsas por el equipo de empaque está entre 750.85 y 760.15 g.
La anterior declaración lleva implícita una afirmación complementaria para la región no comprendida en el intervalo: si la media poblacional fuera inferior a 750.85 g o superior a 760.15 g, la probabilidad de obtener una muestra como la analizada sería 0.1.
Esto implica que mediante un intervalo de confianza es posible responder las preguntas propias de las pruebas de hipótesis. Así, observando el presente intervalo de confianza del 90 % para \(\mu,\) puede establecerse que cualquier prueba de hipótesis al 10 % para \(\mu\) en la que \(\mu_0\) esté dentro del intervalo será aceptada; por el contrario, cualquier prueba hipótesis al 10 % para \(\mu\) en la que \(\mu_0\) esté por fuera del intervalo será rechazada.
En general, si el intervalo de confianza del \(100(1−\alpha)\,\%\) para el parámetro \(θ\) no incluye el valor nulo \(θ_0,\) se rechaza la hipótesis nula con un nivel de significancia \(α.\)
Por el contrario, si el intervalo de confianza del \(100(1−\alpha)\,\%\) para el parámetro \(θ\) sí incluye el valor nulo \(θ_0,\) no se rechaza la hipótesis nula con un nivel de significancia \(α.\)
Teniendo en cuenta la estrecha relación entre estas dos técnicas inferenciales, el investigador podría preguntarse cuándo usar cada una de ellas.
Cada una de estas herramientas suele utilizarse acorde con el avance de la investigación y con el tipo de pregunta que se desee responder. En estados tempranos de la investigación, tales como los estudios de diagnóstico, el intervalo de confianza suministra información acerca del parámetro poblacional, sin que sea necesario tener algún referente preestablecido (\(\mu_0\)).
En ensayos correspondientes a etapas más avanzadas de investigación, en las que se pretende mostrar un cambio con respecto a algún referente, las pruebas de hipótesis permiten establecer conclusiones con mayor contundencia… al menos sicológica.
Anteriormente se hacía notar que si en el ejemplo 4.2 se hubiera elegido un nivel de significancia \(α = 0.05\) para la prueba de hipótesis, esta no habría sido rechazada. En consecuencia, el intervalo de confianza del 95 % para \(\mu\) no contendrá el valor nulo \(\mu_0\) = 750 g.
Un intervalo de confianza del 95 % para el contenido medio de fertilizante se obtiene así:
\[
\begin{align}
\overline{X}\pm t_{0.025(29)}\frac{S}{\sqrt{n}}&=755.5\pm 2.045\frac{15}{\sqrt{30}}\\[1.4em]
&=755.5\pm 5.6
\end{align}
\]
\[
\text{IC:}\quad[749.9,\;\; 761.1]
\]
La comparación de los intervalos de confianza del 90 % y del 95 % para \(\mu\) permite verificar además que a mayor confianza menor precisión (intervalos más amplios) y viceversa.
Todos los resultados anteriores pueden obtenerse de manera directa en R, mediante la función t.test{stats}, la cual contempla, además del argumento obligatorio mediante el cual se especifica el vector contenedor de la información muestral, argumentos opcionales que permiten especificar el tipo de prueba, el valor hipotético y el nivel de confianza para el intervalo.
El correspondiente script para el ejemplo 4.2, sin incluir la prueba de normalidad, la cual ya se presentó anteriormente, consta de las siguientes instrucciones:
data <- readxl::read_excel("ejemplo 4.2.xlsx")
t.test(data$peso, mu = 750, conf.level = 0.9)El argumento mu permite especificar el valor hipotético \(\mu_0.\) Mediante el argumento conf.level se especifica la confianza del intervalo, usando un valor entre 0 y 1. Por defecto, conf.level = 0.95.
Mediante el argumento opcional alternative puede elegirse el tipo de prueba entre 'two.sided', 'greater' y 'less', para pruebas de dos colas, de cola derecha y de cola izquierda, respectivamente. Asimismo, puede usarse solo la primera letra como valor del argumento ('t', 'g' o 'l'). Por defecto se realizan pruebas de dos colas.
Se obtiene el siguiente resultado:
One Sample t-test
data: data$peso
t = 2.0081, df = 29, p-value = 0.05403
alternative hypothesis: true mean is not equal to 750
90 percent confidence interval:
750.8463 760.1543
sample estimates:
mean of x
755.5003 Luego del encabezado de los resultados, la primera línea indica que la información está contenida en un vector denominado peso, dentro del data frame data.
En la segunda línea aparece el valor calculado del estadístico de prueba (t), los grados de libertad (df) de la distribución \(t\) que seguiría el estadístico de prueba bajo la hipótesis nula y el valor p (p-value). Este resultado no da ninguna sugerencia al usuario acerca de si debe rechazar o no la hipótesis nula (en la actualidad casi ningún programa lo hace). El usuario deberá decidir con base en el nivel de significancia que haya preestablecido. Así, en este caso, si se tiene establecido que \(\alpha = 0.1,\) podrá rechazarse la hipótesis nula; si se hubiera elegido \(\alpha = 0.05\) o \(\alpha = 0.01,\) no sería posible rechazar la hipótesis nula con base en la presente información muestral.
La tercera línea de la salida da información acerca del tipo de hipótesis que se está contrastando, mediante la indicación de la hipótesis alternativa. En el presente caso, informa que la hipótesis alternativa plantea que la media verdadera (poblacional) es diferente de 750. Esto significa que se está contrastando una prueba de dos colas.
A continuación, se presenta un intervalo correspondiente a la confianza asignada mediante el argumento conf.level. En el presente caso, se presenta un intervalo de confianza del 90 %. Finalmente, se presenta el estimador puntual de la media, es decir, la media muestral.
Empecemos por recordar que hay dos modalidades de estimación: puntual y por intervalo (cf. sección 3.9.1). Si la pregunta planteada en el título de esta sección estuviera referida al requerimiento matemático, rápidamente podría responderse que se requiere 1 observación para realizar estimación puntual y 2 observaciones para realizar estimación por intervalo.
Desde luego, no es este aspecto trivial el que el investigador tiene en mente cuando consulta por el tamaño de muestra. La pregunta tiene que ver con la calidad de la estimación. Y, puesto que la estimación puntual no lleva asociado ningún indicador de calidad, esto conduce a la estimación por intervalo, que involucra una confianza y una precisión.
La confianza es la probabilidad de que el intervalo aleatorio incluya el parámetro que está estimando (cf. sección 3.9.1.2). La precisión es la semiamplitud del intervalo de confianza.
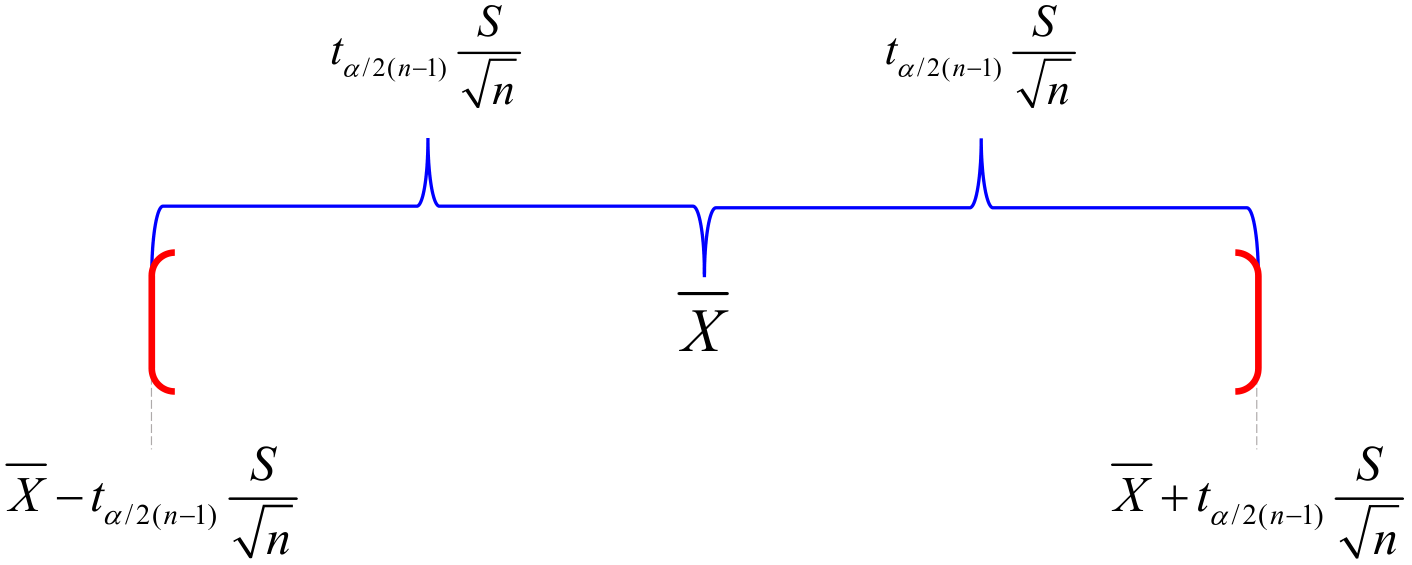
La figura 4.3 ilustra el aspecto de la precisión. El intervalo de confianza para la media se construye con base en la expresión 4.4. El límite inferior está dado por \(\overline{X}- t_{\alpha/2(n-1)}\,S / \sqrt{n},\) mientras que el límite superior está dado por \(\overline{X}+ t_{\alpha/2(n-1)}\,S / \sqrt{n}.\) El estimador puntual \(\overline{X}\) se encuentra en el centro del intervalo. Y, puesto que se tiene una confianza del \(100(1−\alpha)\,\%\) en que el intervalo incluya el parámetro \(\mu,\) puede decirse equivalentemente que se tiene una confianza del \(100(1−\alpha)\,\%\) en que el máximo alejamiento entre el parámetro \(\mu\) y su estimador puntual \(\overline{X}\) es \(t_{\alpha/2(n-1)}\,S / \sqrt{n},\) es decir, la semiamplitud del intervalo. Esta es la precisión de la estimación.
La precisión puede asociarse tanto con un valor numérico como con un concepto, lo que hace que el lenguaje deba adaptarse para cada caso.
Considérense los siguientes intervalos:
Intervalo A: con una semiamplitud de 3.
Intervalo B: con una semiamplitud de 1.
Cuando se hace referencia a intervalos individuales no hay problema en referirse a la precisión a través de sus valores numéricos. Es válido afirmar que el intervalo A tiene una precisión de 3 y que el intervalo B tiene una precisión de 1.
El problema surge cuando se intenta comparar la precisión de estos dos intervalos. Puesto que \(3 > 1,\) uno se vería tentado a afirmar que la precisión del intervalo A es mayor que la del intervalo B. Sin embargo, esta afirmación no es correcta.
Cuando se hace referencia al concepto debe entenderse como “cercanía entre el parámetro y el estimador”. Teniendo esto presente, resulta claro que la precisión del intervalo B es mayor que la del intervalo A.
Puesto que los indicadores de calidad de una estimación por intervalo son la confianza y la precisión, la pregunta que usualmente se quiere responder es: “¿cuál es el tamaño de muestra requerido para estimar la media con una confianza y una precisión dadas?”.
Aunque ambos aspectos son subjetivos, es común usar una confianza del 95 % para los cálculos, lo que se corresponde con un nivel de significancia \(\alpha = 0.05.\) La definición de la precisión depende exclusivamente de las necesidades del investigador.
Para calcular el tamaño de muestra requerido se parte de la precisión, \(\text{pr},\) definida por el investigador:
\[
\text{pr}=t_{\alpha/2(n-1)}\frac{S}{\sqrt{n}}
\]
A partir de la cual se despeja \(n\):
\[
n=\left(t_{\alpha/2(n-1)}\frac{S}{\text{pr}}\right)^2
\]
Hay tres aspectos que determinan el tamaño de la muestra: la confianza, la precisión y la varianza.
La confianza aparece reflejada en el valor crítico superior de la distribución \(t.\) Si consideramos, por ejemplo, una distribución con 30 grados de libertad, el valor crítico para una confianza del 95 % es 2.04, mientras que el valor crítico para una confianza del 99 % es 2.75. Claramente, mientras mayor sea la confianza deseada, mayor será también el tamaño de muestra.
La precisión, que aparece en el denominador de la anterior expresión, también determina el tamaño de la muestra: mientras mayor sea la precisión deseada (mayor cercanía entre el estimador y el parámetro, es decir, menores valores de la semiamplitud), mayor será el tamaño de muestra.
El otro aspecto que determina el tamaño de muestra es la variabilidad. Esta relación es muy intuitiva: a mayor variabilidad, mayor será el tamaño de muestra requerido.
Lo usual, cuando se formulan preguntas relativas al tamaño de muestra es que la muestra no se haya obtenido, con lo cual tampoco se conocerá su variabilidad. Esto conduce a una dependencia circular. La única manera de resolver esta situación es suministrar una estimación de la variabilidad en cuestión. Es posible que, aunque no se haya obtenido la muestra objeto de la pregunta, se tenga información exógena sobre la variabilidad que podría exhibir, bien sea por reportes en la literatura o por muestreos previos que se hubieran realizado. Si así fuera, bien podría usarse tal información.
Si se quisiera una estimación más formal, y los recursos y el tiempo lo permitieran, bien podría realizarse un premuestreo, usando un \(n\) relativamente bajo, que permitiera estimar la varianza. Esta varianza se usaría para calcular el tamaño de la muestra final. Si las condiciones de toma de la muestra piloto satisficieran las condiciones del estudio, bien podría usarse dicha información como parte de la muestra final, con lo cual, tras calcular el \(n\) requerido, bastaría con obtener el número de muestras faltantes, descontando las del premuestreo.
La estrategia del premuestreo podría considerarse como un ideal desde el punto de vista estadístico. Sin embargo, en la práctica investigativa no siempre se cuenta con los recursos para hacerla viable, con lo cual, lo más usual es utilizar alguna estimación exógena.
Finalmente, es necesario anotar que el desconocimiento de la varianza muestral no es el único aspecto que produce una dependencia circular. Los grados de libertad de la distribución \(t\) también dependen del tamaño de muestra. Esta situación, sin embargo, es más fácil de resolver: basta con realizar una estimación iterativa en la que, partiendo de un valor cualquier de los grados de libertad se calcule \(n.\) A continuación se adaptarían los grados de libertad a partir del \(n\) calculado y se seguiría realizando el proceso hasta la estabilización de \(n.\)
Una manera de hacer este proceso más expedito consiste en realizar el cálculo inicial de \(n,\) usando el valor crítico de la normal estándar5. El valor de \(n\) calculado en este primer paso es menor que el que se obtendría usando cualquiera de los miembros de la familia \(t.\) A partir de esta valor inicial de \(n\) se realiza el proceso iterativo de incrementos hasta su estabilización. La función personalizada n_mi automatiza este proceso.
Aunque parezca contradictorio, a menudo surgen preguntas sobre el tamaño de muestra, después de haber obtenido la muestra. En estos casos, la pregunta realmente es ¿cómo sé si la muestra que obtuve sí es del tamaño adecuado?
Para responder esta pregunta basta con calcular el intervalo de confianza para \(\mu\) y verificar si la precisión satisface los requerimientos del estudio. Si no fuera así y se buscara una mayor precisión, bien podría usarse el procedimiento anterior para averiguar en cuánto sería necesario incrementar el tamaño de muestra para satisfacer los requerimientos de precisión. En este caso se tendría la ventaja de poder usar un estimador interno de la variabilidad muestral.
Aunque la inferencia sobre la media de una población normal es mucho más popular que la inferencia sobre su varianza, cada uno de estos parámetros conlleva información única que no está contenida en el otro. Así, la respuesta completa a la pregunta planteada en el ejemplo 4.2 acerca de la calibración del equipo empacador de fertilizante debe considerar tanto lo relativo a su exactitud (inferencia sobre la media) como a su precisión (inferencia sobre la varianza). En esta sección se ejemplifica lo concerniente a la varianza de una población normal con base en dicha información.
Considérese una muestra aleatoria de tamaño \(n\) de una población normal:
\[
X_1,X_2,...,X_n\: \text{iid}\: N\left(\mu, \sigma^2\right)
\]
Para inferir sobre la varianza poblacional, \(\sigma^2,\) se calcula la siguiente variable aleatoria, cuya distribución es ji cuadrado con \(n − 1\) grados de libertad.
\[
\frac{(n-1)S^2}{\sigma^2}\thicksim \chi^2_{(n-1)}
\tag{4.5}\]
Para mantener la fluidez de la exposición, esta afirmación se toma como cierta. No obstante, en la sección 4.3.1.1 se presenta una prueba intuitiva, para cuyo seguimiento basta considerar algunos elementos presentados anteriormente. Una demostración más formal, que hace uso de herramientas que exceden el alcance de la presente obra, puede encontrarse en textos que profundizan en los aspectos teóricos de la inferencia estadística, como el de Casella y Berger (2002).
Considérese el siguiente juego de hipótesis:
\[
H_0: \sigma^2=\sigma_0^2
\]
\[
H_a: \sigma^2 \ne \sigma_0^2
\]
Si en la variable aleatoria que se construye con base en la información muestral se remplaza el parámetro \(\sigma^2\) por su valor hipotético \(\sigma_0^2,\) se obtiene una variable aleatoria que mantendrá la misma distribución, siempre que la hipótesis nula sea cierta. Esta variable aleatoria constituye el estadístico de prueba.
\[
\chi_\text{c}^2 = \frac{(n-1)S^2}{\sigma_0^2}\overset {H_0}\thicksim \chi^2_{(n-1)}
\tag{4.6}\]
Al igual que en todas las pruebas de hipótesis, el estadístico de prueba es el mismo, independientemente de si la prueba es de una o de dos colas, cambiando únicamente el criterio de rechazo y la forma en que se calcula el valor p, tal y como se ilustra en la tabla 4.3 y en la figura 4.4.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
Cola izquierda \(H_0:\sigma^2\ge\sigma^2_0\) |
\(\chi_\text{c}^2\le\chi^2_{1- \alpha(n-1)}\) |
\(P\left(\chi_{(n-1)}^2 < \chi_\text{c}^2\right)\) |
Cola derecha \(H_0:\sigma^2\le\sigma^2_0\) |
\(\chi_\text{c}^2\ge \chi^2_ {\alpha(n-1)}\) |
\(P\left(\chi^2_{(n-1)}>\chi^2_\text{c}\right)\) |
Dos colas \(H_0:\sigma^2=\sigma^2_0\) |
\(\chi_\text{c}^2\le\chi^2_{1-
\alpha/2(n-1)}\) o |
\(2\, \text{mín}\Big(P\big(\chi_{(n-1)}^2<
\chi_\text{c}^2\big),\) |
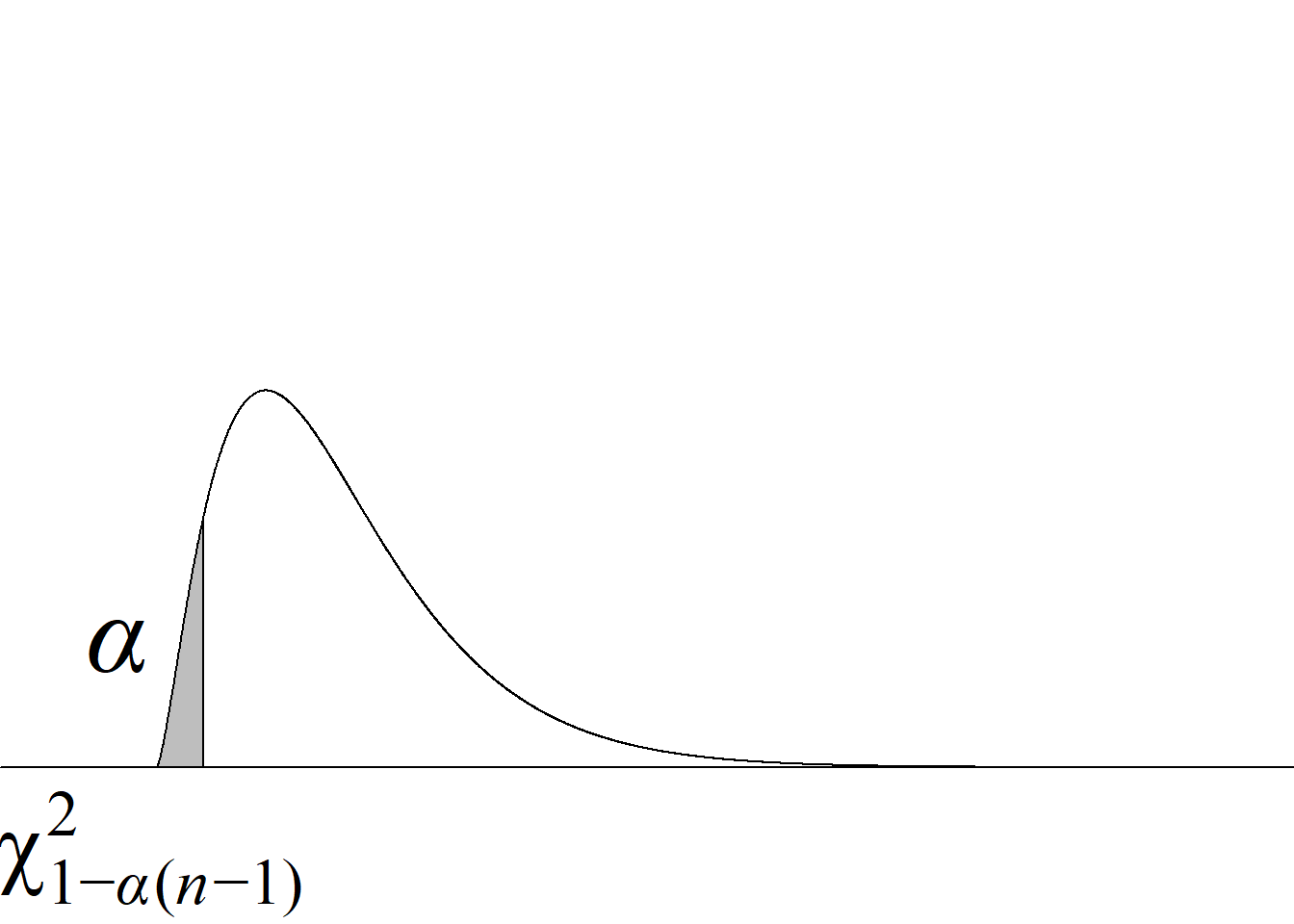
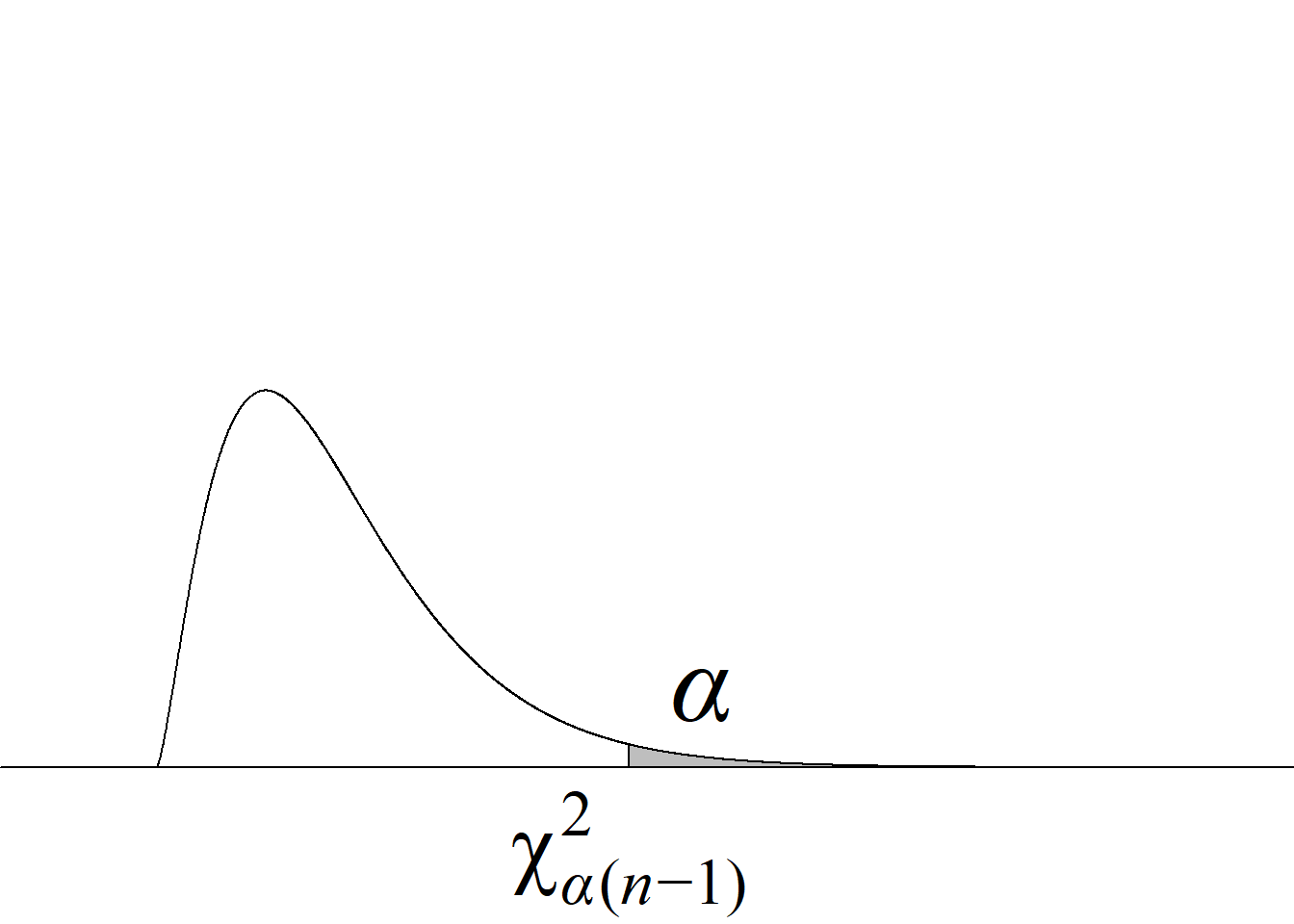
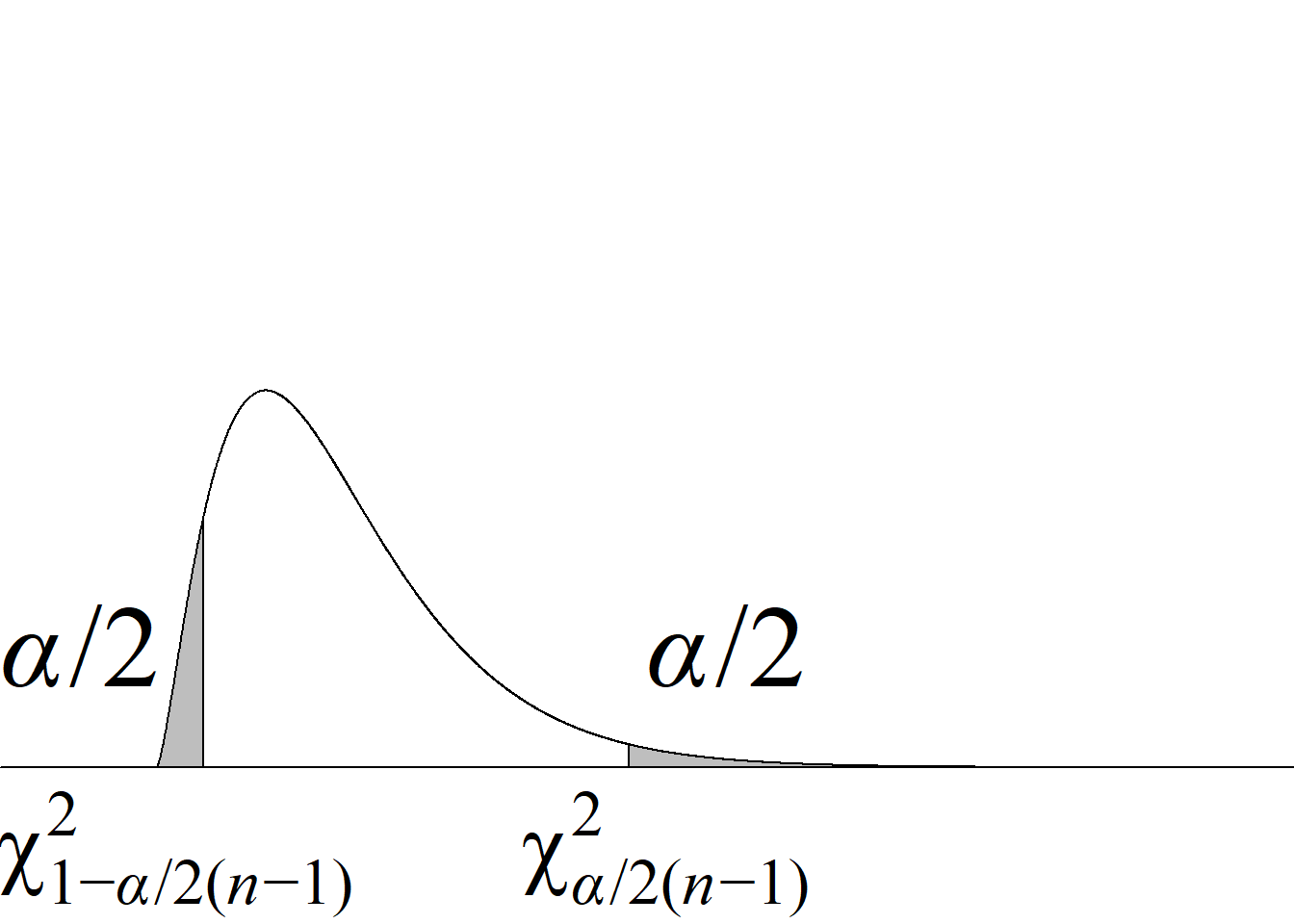
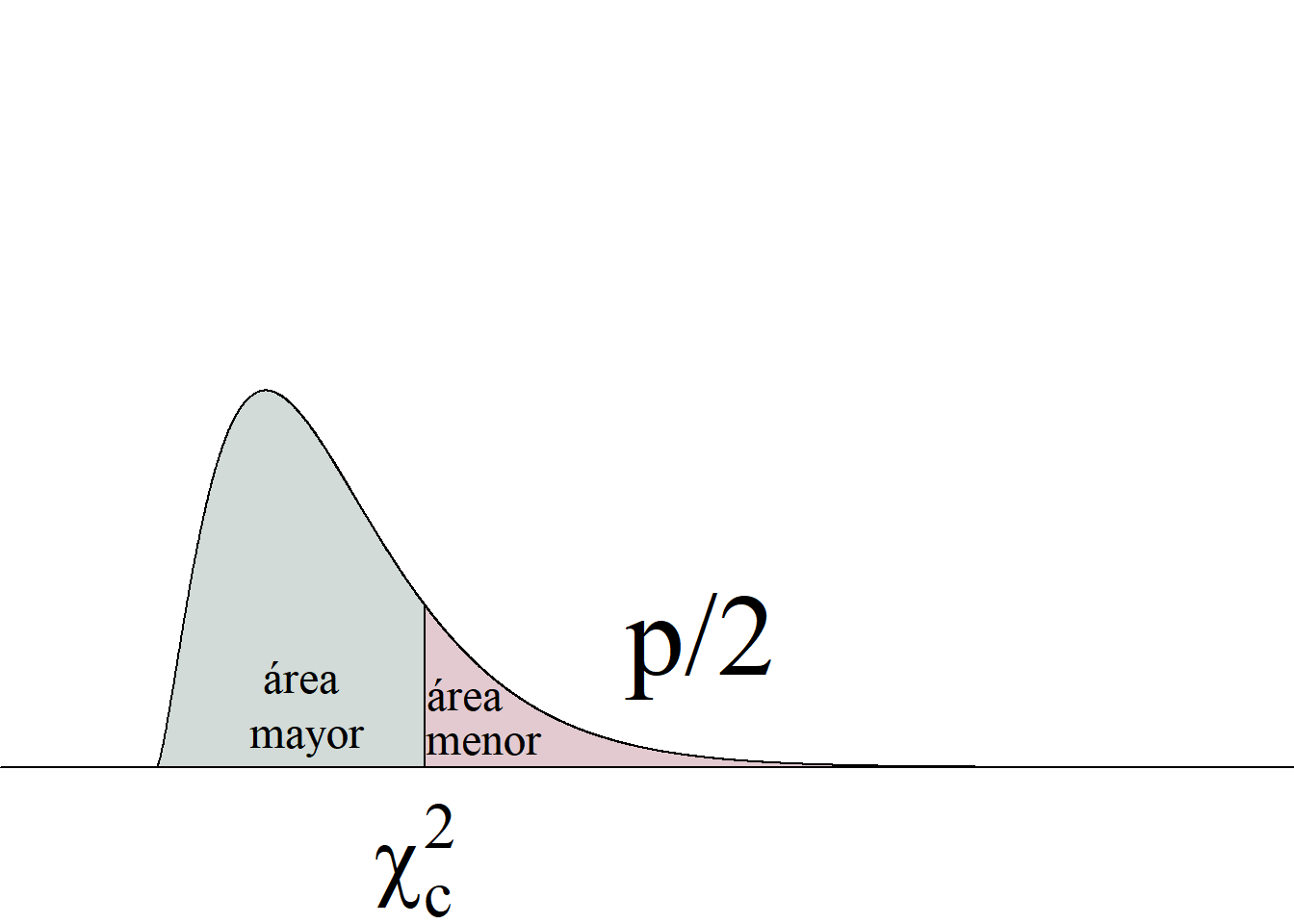
Puesto que la distribución ji cuadrado es asimétrica, no es posible usar la función valor absoluto para escribir de manera sucinta la regla de decisión de rechazo de la hipótesis nula para la prueba de dos colas ni el cálculo del valor p, al estilo de como se hace en la prueba sobre la media (cf. tabla 4.1).
Ejemplo 4.3
Para completar la evaluación del equipo del ejemplo 4.2, es necesario considerar su precisión, es decir, la variabilidad en los pesos de las bolsas de fertilizante. Aun si se aceptara que el peso medio no difiere de 750 g, el equipo podría resultar inadecuado si la variabilidad fuera muy alta (baja precisión).
Las figuras que se usan en la sección 3.9.1.1 para ilustrar los conceptos de insesgamiento y variabilidad de un estimador resultan igualmente útiles para entender los conceptos planteados en este ejemplo:
La figura 3.18 (a) representa los pesos de las bolsas empacadas por un equipo en el que se satisface lo concerniente a la media (equipo exacto), pero no a la varianza (equipo impreciso)
La figura 3.18 (b) corresponde a un equipo en el que no se satisface el requerimiento de la media (equipo inexacto), ni de la varianza (equipo impreciso)
La figura 3.18 (c) corresponde a un equipo en el que no se satisface lo concerniente a la media (equipo inexacto), pero sí lo relativo a la varianza (equipo preciso).
La figura 3.18 (d) representa el equipo ideal, en el que se satisface lo concerniente a la posición (equipo exacto) y a la variabilidad (equipo preciso). Lógicamente solo un equipo exacto y preciso podrá considerarse calibrado.
Supóngase que la norma técnica exige que la desviación estándar de los pesos sea inferior a 12 g. Para verificar esta condición se requiere contrastar un juego de hipótesis en el que se particione el espacio paramétrico de la desviación estándar en dos subconjuntos complementarios: desviaciones estándar por debajo de 12 g (equipo adecuado) y desviaciones estándar por encima de 12 g (equipo inadecuado).
Claramente, se requiere una prueba de hipótesis unilateral o de una cola. ¿Cuál de los dos posibles juegos de hipótesis de una cola resulta más adecuado para esta evaluación?
En el ejemplo 4.2, en donde se usa una prueba de dos colas, los errores tipo I y II quedan automáticamente definidos, siendo la modificación del nivel de significancia la única manera de ejercer control sobre estos, para una muestra dada. Cuando se contrasta un juego de hipótesis mediante pruebas de una cola, el usuario tiene la posibilidad de elegir su dirección (de cola izquierda o de cola derecha), con lo cual puede establecer un tope máximo para la probabilidad de cometer el tipo de error que considere más inconveniente, lo que a su vez le permite presentar sus conclusiones con mayor contundencia.
Puesto que el usuario únicamente puede fijar la probabilidad máxima del error tipo I (cf. sección 3.9.2.1), es recomendable formular el juego de hipótesis, haciendo corresponder el error más delicado con el error tipo I.
Para el presente ejemplo, como quiera que se plantee el juego de hipótesis, los errores que pueden cometerse consisten en:
Declarar que el equipo es adecuado, siendo inadecuado
Declarar que el equipo es inadecuado, siendo adecuado.
Para establecer cuál de estos errores resulta más delicado e inconveniente es necesario considerar el contexto, tal y como se expuso en el ejemplo 4.2, en donde se supusieron dos hipotéticos escenarios, denominados A y B.
En concordancia con el ejemplo 4.2, en el presente ejemplo también supondremos que las condiciones reinantes son las correspondientes al escenario B. Consecuentemente, el error más inconveniente consistiría en concluir que el equipo es adecuado, siendo inadecuado.
Para hacer coincidir este error con el error tipo I, se tiene en cuenta la definición general del error tipo I:
Concluir en favor de la hipótesis alternativa, siendo cierta la hipótesis nula6.
Luego, basta con escribir el juego de hipótesis, de manera que la hipótesis alternativa recoja las condiciones para las cuales el equipo es adecuado, mientras que la nula recoja las condiciones para las que es inadecuado, teniendo presente que la hipótesis nula siempre incluye la condición de igualdad entre el parámetro y el valor hipotético, así:
\(H_0:\sigma\ge 12\) (equipo inadecuado)
\(H_a:\sigma< 12\) (equipo adecuado)
Es muy fácil verificar que, planteando el juego de hipótesis de esta manera, el error tipo I efectivamente consistiría en declarar adecuado un equipo que es inadecuado. Si se tiene en cuenta que, por las condiciones del escenario B, este es el error más indeseable, esta formulación del juego de hipótesis es la que mejor permite expresar las conclusiones con la contundencia requerida.
Si en el escenario planteado resulta altamente inconveniente declarar como adecuado un equipo que no lo sea, se hace necesario probar que el equipo es adecuado; no basta con aceptar que lo es, que sería lo que podría decirse si se hubiera planteado un juego de hipótesis de cola derecha: \(H_0: \sigma \le 12 \text{ vs. } H_a: \sigma > 12.\)
Es necesario tener presente que la aceptación de la hipótesis nula no tiene carácter de prueba; aceptar la hipótesis nula equivale a decir que no se encontraron elementos que permitan diagnosticar el equipo como inadecuado.
Debe tenerse en cuenta que, aunque el juego de hipótesis de cola izquierda presentado anteriormente permitiría responder la cuestión de interés, en esta sección se presenta una metodología para inferencia sobre la varianza; no sobre la desviación estándar. Esto, sin embargo, no representa ningún problema; basta con reescribir el juego de hipótesis en términos de la varianza, así:
\(H_0:\sigma^2\ge 144\) (equipo inadecuado)
\(H_a:\sigma^2< 144\) (equipo adecuado)
Dado que las presentes técnicas inferenciales toman como punto de partida una población normalmente distribuida, es necesario verificar esta condición. No obstante, lo obviamos en el presente ejemplo, puesto que se usan los mismos datos del ejemplo 4.2, donde ya ilustró dicha evaluación \((\text{p}=0.1142).\)
Con base en la información de la tabla 4.2, se calcula el estadístico de prueba:
\[
\chi_\text{c}^2=\frac{(n-1)S^2}{\sigma_0^2}=\frac{29\times 225.07}{144}=45.33
\]
Teniendo en cuenta lo muy indeseable que resultaría cometer el error tipo I, se fija un nivel de significancia del 1 %.
Con base en la metodología de contraste tradicional, se compara el valor del estadístico de prueba con el de una variable aleatoria ji cuadrado con 29 gl que deje un área de 0.01 a su izquierda (valor crítico inferior). Usando la instrucción qchisq(0.01, 29) en R, se obtiene que \(\chi_{0.99}^2 = 14.256.\) Por tanto, no se rechaza la hipótesis nula con un nivel de significancia del 1 %.
Recuerde que el subíndice que aparece en la notación tradicional de los valores críticos no indica el área acumulada, sino el área a la derecha (cf. nota 3.4).
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\chi_\text{c}^2\) \(45.33\) |
\(>\) \(>\) |
\(\chi_{0.99(29)}^2\) \(14.256\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no se rechaza \(H_0\) con \(α = 0.01\) |
Se acepta que el equipo es inadecuado. En este caso, aunque con este resultado no se prueba en sentido estricto que el equipo sea inadecuado, lo que sí es claro es que no se logró probar que fuera adecuado, por lo que deberían aplicarse los correctivos tendientes a lograr su calibración.
Supóngase que, por motivos inescrutables, el dueño del equipo estuviera reticente a someterlo a recalibraciones adicionales y pidiera que se le indiqué qué probabilidad tendría de estar actuando erróneamente si, a la luz de la información muestral, diagnosticara que el equipo cuenta con la precisión requerida.
La respuesta para el dueño del equipo vendría de la mano del valor p, que es justamente la probabilidad de cometer un error tipo I, si se decidiera rechazar la hipótesis nula con base en la presente información muestral. En general, en pruebas de una cola, y muy particularmente en este ejemplo, debe prestarse especial atención a la forma en que se calcula este valor.
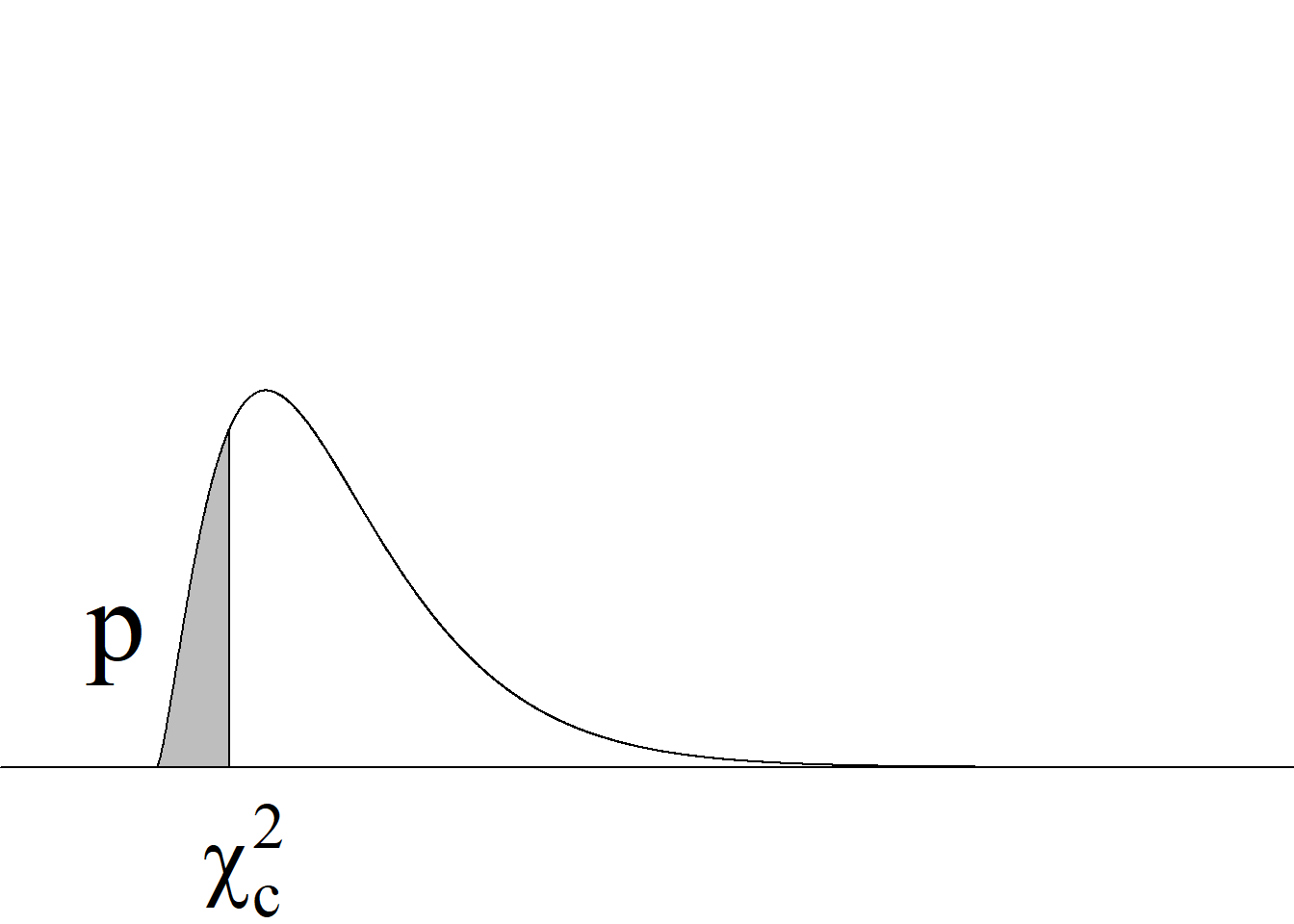
La figura 4.5 muestra la distribución de referencia (ji cuadrado con 29 gl) y la ubicación aproximada del estadístico de prueba en dicha distribución.
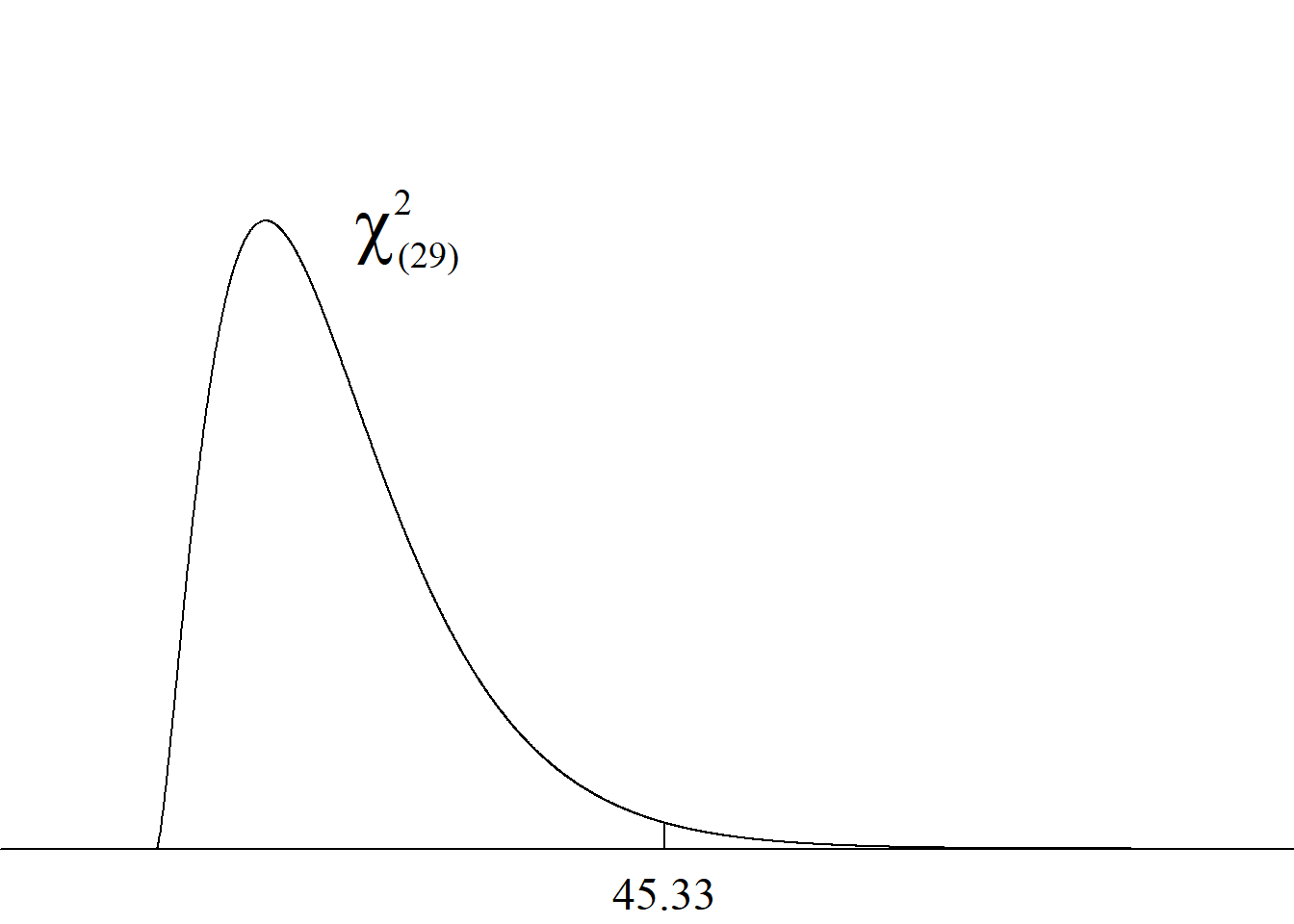
En general, el valor p se calcula como la probabilidad de obtener, bajo la hipótesis nula, un valor igual o más extremo que el del estadístico de prueba. Puesto que bajo la hipótesis nula el estadístico de prueba tendría una distribución ji cuadrado con 29 gl y esta es una distribución continua, puede obviarse lo referente a la igualdad y decirse que para este caso el valor p se calcula como la probabilidad de obtener un valor más extremo que 45.33 en una distribución ji cuadrado con 29 gl.
En este ejemplo, por la ubicación del estadístico de prueba, el usuario podría verse tentado a calcular el valor p como la probabilidad de un valor mayor que 45.33. No obstante el calificativo de extremo no tiene que ver con la ubicación del estadístico de prueba en la distribución de referencia, sino con lo que sería extremo para el tipo de prueba que se esté evaluando. En particular, para una prueba de cola izquierda un valor extremo es un valor bajo (cf. tabla 4.3 y figura 4.4 (d)).
El calificativo de “extremo” no tiene que ver con la ubicación del estadístico de prueba en la distribución de referencia, sino con lo que sería extremo para el tipo de prueba que se esté evaluando.
En pruebas de una cola, el símbolo de desigualdad de la hipótesis alternativa sirve de guía nemotécnica.
En el presente ejemplo, el valor p se calcula como la probabilidad de obtener un valor menor que 45.33 en una distribución ji cuadrado con 29 gl. Esta probabilidad se calcula en R con la instrucción pchisq(45.33, 29), obteniéndose que p = 0.973.
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.973\) |
\(>\) \(>\) |
\(\alpha\) \(0.01\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no se rechaza \(H_0\) |
El primer encuentro de los usuarios con un valor p tan alto suele ser desconcertante.
Puesto que el valor p es una probabilidad de error y las probabilidades de error suelen acotarse con valores bajos, un valor tan alto pareciera fuera de lugar.
No debe olvidarse, sin embargo, que, tratándose de una probabilidad y en particular de una probabilidad exacta (no de una cota máxima), el valor p puede tomar cualquier valor entre 0 y 1.
Si se observa la información muestral no resulta nada sorprendente el alto valor obtenido. Se requiere un equipo cuya varianza sea menor que 144. La varianza muestral en este ensayo fue 225.07. Quien, a pesar de la contundente evidencia muestral en contra, pretendiera hacer pasar el equipo como adecuado tendría una altísima probabilidad de estar cometiendo un error.
La intuición sugiere que deberían usarse \(n\) de libertad para la distribución de la variable aleatoria de la expresión 4.5; sin embargo, se usan \(n-1.\)
Se quiere probar que:
\[
\frac{(n-1)S^2}{\sigma^2}\thicksim \chi^2_{(n-1)}
\]
Considérese una variable aleatoria proveniente de una población normal:
\[
X\thicksim N\left(\mu,\,\sigma^2\right)
\]
Restando la media y dividiendo por la desviación estándar, se obtiene una variable aleatoria normal estándar (cf. expresión 3.6):
\[
\frac{X-\mu}{\sigma}\thicksim N\left(0,\,1\right)
\]
Elevando al cuadrado se genera una variable aleatoria ji cuadrado con un grado de libertad (cf. sección 3.7.2).
\[
\left( \frac{X-\mu}{\sigma}\right)^2\thicksim \chi_{(1)}^2
\]
La suma de los cuadrados de \(n\) normales estándar independientes se distribuye ji cuadrado con \(n\) grados de libertad (cf. sección 3.7.2).
\[
\sum_{i=1}^n\left( \frac{X_i-\mu}{\sigma}\right)^2\thicksim \chi_{(n)}^2
\]
Es posible sumar y restar la media muestral al numerador, sin que esto altere la variable aleatoria:
\[
\sum_{i=1}^n\left( \frac{\left(X_i-\overline{X}\right)+\left(\overline{X}-\mu\right)}{\sigma}\right)^2\thicksim \chi_{(n)}^2
\]
\[
\Rightarrow\sum_{i=1}^n\left(\frac{\left(X_i-\overline{X}\right)^2}{\sigma^2}
+\frac{2\left(X_i-\overline{X}\right)\left(\overline{X}-\mu\right)}{\sigma^2}+
\frac{\left(\overline{X}-\mu\right)^2}{\sigma^2}\right)
\thicksim \chi_{(n)}^2
\]
\[
\Rightarrow\frac{\sum\limits_{i=1}^n\left(X_i-\overline{X}\right)^2}{\sigma^2}
+\frac{2\left(\overline{X}-\mu\right)}{\sigma^2}\sum\limits_{i=1}^n\left(X_i-\overline{X}\right)
+\frac{n\left(\overline{X}-\mu\right)^2}{\sigma^2}
\thicksim \chi_{(n)}^2
\]
\[
\Rightarrow\frac{\sum\limits_{i=1}^n\left(X_i-\overline{X}\right)^2}{\sigma^2}
+\frac{2\left(\overline{X}-\mu\right)}{\sigma^2}
\left(\sum\limits_{i=1}^n X_i-n \frac{\sum\limits_{i=1}^n X_i}{n}\right)
+\frac{n\left(\overline{X}-\mu\right)^2}{\sigma^2}
\thicksim \chi_{(n)}^2
\]
Puesto que el segundo factor del segundo término se anula, se tiene:
\[
\frac{\sum\limits_{i=1}^n\left(X_i-\overline{X}\right)^2}{\sigma^2}
+\frac{\left(\overline{X}-\mu\right)^2}{\sigma^2/n}
\thicksim \chi_{(n)}^2
\]
La suma de cuadrados que aparece en el numerador del primer término es el numerador de la varianza muestral, por lo que la anterior variable aleatoria puede expresarse así:
\[
\frac{(n-1)S^2}{\sigma^2}
+\left(\frac{\overline{X}-\mu}{\sigma/\sqrt{n}}\right)^2
\thicksim \chi_{(n)}^2
\]
Teniendo en cuenta que la suma de los cuadrados de \(n\) variables normales estándar independientes sigue una distribución ji cuadrado con n grados de libertad (cf. sección 3.7.2) y que el segundo término de la expresión anterior es una variable aleatoria ji cuadrado con 1 grado de libertad (es una normal estándar elevada al cuadrado: cf. expresión 3.6), la única forma posible en que la suma de ambos términos se distribuya ji cuadrado con \(n\) grados de libertad es que el primer término se distribuya ji cuadrado con \(n − 1\) grados de libertad.
Esto es lo que se quería probar.
Mediante el método de inversión, es posible deducir un intervalo de confianza para la varianza, de manera análoga a la ilustrada en la construcción del intervalo de confianza para la media (cf. sección 4.2.2). No obstante, en la presente sección se omite dicho desarrollo.
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para el parámetro \(σ^2\) está dado por el siguiente par de límites aleatorios:
\[
\left[\frac{(n-1)S^2}{\chi^2_{\alpha/2(n-1)}},\quad
\frac{(n-1)S^2}{\chi^2_{1-\alpha/2(n-1)}}\right]
\]
Un intervalo de confianza construido con base en la anterior expresión no está centrado en el estimador puntual de la varianza, \(S^2,\) puesto que, a diferencia del intervalo para la media, no se calcula sumándole y restándole una misma cantidad al estimador puntual.
En la sección 4.2.2 se mostró que existe una relación uno a uno entre el intervalo de confianza y la prueba de hipótesis para un parámetro. Es necesario precisar, sin embargo, que esta relación se establece entre pruebas de hipótesis de dos colas e intervalos de confianza bilaterales, es decir, intervalos que tienen un límite inferior y un límite superior.
Las pruebas de hipótesis de una cola, como la del ejemplo 4.3, no se relacionan con intervalos bilaterales, sino con intervalos que constan de un único límite. En concordancia con la denominación de las correspondientes pruebas de hipótesis, a dichos intervalos se les denomina unilaterales.
Las pruebas de cola izquierda se asocian con un intervalo de confianza unilateral superior, mientras que las pruebas de cola derecha se asocian con un intervalo de confianza unilateral inferior.
Los límites de los intervalos unilaterales se obtienen cambiando \(\alpha/2\) por \(\alpha\) en los correspondientes límites del intervalo bilateral.
En la sección 4.5 se presentan los detalles de su construcción y uso.
Así, para el caso de la varianza, se tienen los siguientes intervalos unilaterales del \(100(1 − \alpha)\,\%\) de confianza.
Para \(\left(H_0: \sigma^2 \le \sigma_0^2\quad\text{vs.}\quad \sigma^2 > \sigma_0^2 \right),\quad \text{LI}=\frac{(n-1)S^2}{\chi^2_{\alpha(n-1)}}\)
Para \(\left(H_0: \sigma^2 \ge \sigma_0^2\quad\text{vs.}\quad \sigma^2 < \sigma_0^2 \right),\quad \text{LS}=\frac{(n-1)S^2}{\chi^2_{1-\alpha(n-1)}}\)
Como ayuda nemotécnica, puede asociarse el límite de los intervalos unilaterales con la dirección en la que señala el símbolo de desigualdad de la hipótesis nula.
La lógica de esta relación se presenta en la sección 4.5.
Para el ejemplo 4.3, en el que se ha trabajado una prueba de cola izquierda, puede obtenerse información adicional mediante el correspondiente intervalo de confianza unilateral superior. Dado que la prueba se realizó con un nivel de significancia del 1 %, el correspondiente intervalo sería del 99 % de confianza (cf. advertencia 4.2).
El límite superior de un intervalo de confianza unilateral del 99 % para la varianza poblacional, \(\sigma^2,\) del ejemplo 4.3 está dado por:
\[
\text{LS}=\frac{(n-1)S^2}{\chi^2_{1-\alpha(n-1)}}=\frac{29\times225.07}{\chi^2_{0.99(29)}}=\frac{29\times225.07}{14.256}=457.84
\]
Se tiene una confianza del 99 % en que la varianza del equipo es menor o igual que 457.84. Esto puede expresarse equivalentemente de cualquiera de las siguientes formas:
| \(\sigma^2\le 457.84\) | \(457.84]\) | \([0,\;\; 457.84]\) |
La última notación puede resultar engañosa, pues pareciera que se hubiera calculado un intervalo bilateral.
Sin embargo, el valor 0 que se presenta como límite inferior no se ha calculado como parte de la construcción del intervalo, sino que corresponde un límite natural para la varianza.
En una situación análoga para la media, el límite inferior sería menos infinito.
Para obtener un intervalo de confianza para la desviación estándar, \(\sigma,\) basta con extraer la raíz cuadrada de los correspondientes límites. Para el presente ejemplo, el límite de un intervalo de confianza unilateral superior del 99 % para la desviación estándar es 21.39.
Toda la información calculada anteriormente es coincidente y lleva a la misma conclusión. Si la norma técnica exige que la desviación estándar sea menor que 12 g y el análisis de la información muestral indica que esta es inferior a 21.39, no se cuenta con evidencia suficiente para afirmar que el equipo cumple la norma. Para poder sostener tal afirmación, sería necesario que el límite superior fuera menor de 12.
Muchos de los procedimientos estadísticos más comunes están disponibles en R mediante alguna de las funciones incluidas en el paquete stats (v. gr., median, weighted.mean, var, sd, pbinom, pnorm, pchisq, pf, pt, shapiro.test y t.test). No obstante, el paquete stats no incluye ninguna función que permita realizar los procesos inferenciales descritos en las secciones anteriores7.
En casos como este, es necesario buscar la función en algún otro paquete o crear una función personalizada. Recomendamos la función personalizada inf_var:
En la primera línea se carga la función personalizada inf_var. La segunda línea importa en un data frame los datos presentados en la tabla 4.2, que están contenidos en el archivo Excel ejemplo 4.2.xlsx.
La tercera línea invoca la función inf_var. El valor hipotético del parámetro puede expresarse en términos de la varianza (var0) o de la desviación estándar (sd0), como en el presente caso. El argumento alternative permite especificar el tipo de prueba; en este caso se indica que se trata de una prueba de cola izquierda (less). Finalmente, el argumento conf.level = 0.99 indica que el intervalo de confianza que se construya ha de ser del 99 %.
Se obtienen los siguientes resultados:
Inferencia sobre la desviación estándar de una población normal
Desviación estándar muestral = 15.0025
Desviación estándar hipotética = 12
Ji cuadrado = 45.3273
Grados de libertad = 29
Prueba de cola izquierda (Ha: Desviación estándar poblacional < 12)
Valor p = 0.9727
Intervalo de confianza unilateral superior del 99 %
[0, 21.3971]El resultado anterior puede presentarse en inglés y en el formato propio de los objetos de la clase htest (Hypothesis test), como el de las salidas de la función t.test. Para ello, se usa el argumento lang = "english" en la función inf_var:
source("inf_var.R")
data <- readxl::read_excel("ejemplo 4.2.xlsx")
inf_var(data$peso, sd0 = 12, alternative = "less", conf.level = 0.99,
lang = "english")
Inference on a Normal Standard Deviation
data: data$peso
chi-squared = 45.327, df = 29, p-value = 0.9727
alternative hypothesis: true standard deviation is less than 12
99 percent confidence interval:
0.00000 21.39713
sample estimates:
standard deviation
15.0025 También podría haberse planteado el juego de hipótesis en términos del parámetro \(\sigma^2\). Los resultados aparecen en español (lang = "spanish", por defecto) o en inglés (lang = "english"):
source("inf_var.R")
data <- readxl::read_excel("ejemplo 4.2.xlsx")
inf_var(data$peso, var0 = 144, alternative = "less", conf.level = 0.99)
Inferencia sobre la varianza de una población normal
Varianza muestral = 225.0736
Varianza hipotética = 144
Ji cuadrado = 45.3273
Grados de libertad = 29
Prueba de cola izquierda (Ha: Varianza poblacional < 144)
Valor p = 0.9727
Intervalo de confianza unilateral superior del 99 %
[0, 457.8371]También puede usarse la función varTest{EnvStats}. En este caso, las salidas siempre aparecen en inglés y el juego de hipótesis tiene que plantearse en términos del parámetro \(\sigma^2\):
library(EnvStats)
data <- readxl::read_excel("ejemplo 4.2.xlsx")
varTest(data$peso, alternative = "less", conf.level = 0.99, sigma.squared = 144)$statistic
Chi-Squared
45.32732
$parameters
df
29
$p.value
[1] 0.972661
$estimate
variance
225.0736
$null.value
variance
144
$alternative
[1] "less"
$method
[1] "Chi-Squared Test on Variance"
$data.name
[1] "data$peso"
$conf.int
LCL UCL
0.0000 457.8371
attr(,"conf.level")
[1] 0.99
attr(,"class")
[1] "htestEnvStats"Se insiste sobre el hecho de que las técnicas inferenciales sobre la varianza también están fundamentadas en el supuesto de normalidad, por lo que sería necesario verificar que no se detecten desviaciones severas. En el presente ejemplo se ha obviado, puesto que esta verificación ya se había realizado en el ejemplo 4.2.
Para responder preguntas de investigación concernientes a la proporción en que una característica está presente en una población, se usa el modelo binomial (cf. sección 3.6.2).
Si \(X\) es la variable aleatoria que representa el número de éxitos obtenido al ejecutar \(n\) experimentos independientes Bernoulli con probabilidad de éxito \(p\), se dice que \(X\) tiene distribución binomial, con parámetros \(n\) y \(p,\) y se denota así:
\[
X \thicksim \text{bin}(n,\, p)
\]
El parámetro \(p,\) que representa la probabilidad de éxito en la distribución binomial, sirve como modelo para la proporción de éxitos en la población de campo.
Si se hace referencia al modelo teórico se hablaría de inferencia sobre el parámetro \(p\)8 de una distribución binomial, el cual representa la probabilidad de éxito de los ensayos Bernoulli que definen el modelo.
Teniendo en cuenta la relación que existe entre parámetros teóricos como modelo de parámetros de campo (cf. sección 3.9), la inferencia sobre el parámetro de la binomial puede interpretarse, en el contexto de una población de campo, como la proporción verdadera de unidades que presentan la característica de interés.
En este sentido, puede hablarse de inferencia sobre una proporción cuando se hace referencia a la población de campo.
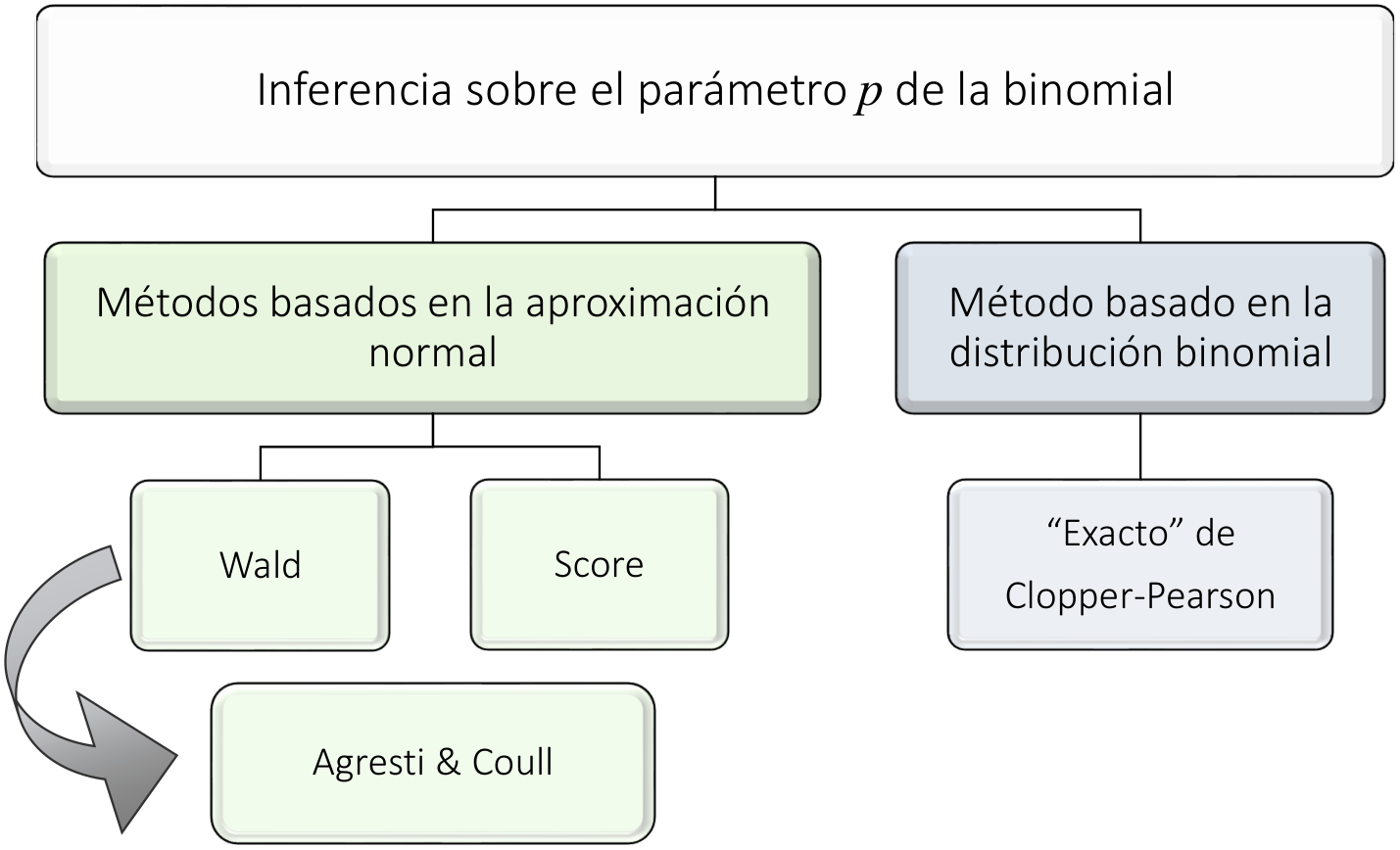
En esta sección se analizan cuatro de las estrategias para realizar inferencia estadística sobre el parámetro \(p.\) Las tres primeras están basadas en una aproximación normal al comportamiento distribucional del número de éxitos. La cuarta estrategia hace uso de la distribución binomial, sin suponer ninguna aproximación.
Los métodos basados en una aproximación mediante la distribución normal son el de Wald, que históricamente ha sido el más popular; el de Agresti y Coull, que consiste en un ajuste al método de Wald, y el del score. Por su parte, el método que no se basa en aproximaciones mediante la distribución normal se conoce como método exacto de Clopper-Pearson. La figura 4.6 esquematiza estos cuatro métodos.
A continuación, se plantea un ejemplo que servirá de referencia para la exposición de los diferentes métodos inferenciales.
Ejemplo 4.4
Un productor de semilla sostiene que la viabilidad de su producto es superior al 90 %, por lo cual cobra un precio superior al de la semilla estándar, la cual tiene una viabilidad certificada del 90 %.
Para verificar la afirmación del productor, se realiza una prueba sobre 200 semillas, de las cuales 185 resultan viables.
Para cada una de las semillas se tiene una respuesta dicotómica (viable, no viable).
En situaciones como la postulada en este ejemplo es necesario verificar que se hayan controlado posibles fuentes de dependencia en las respuestas, de manera que cada una de las semillas exhiba una respuesta independiente (cf. sección 3.6.2).
Si un potencial comprador está dispuesto a asumir un riesgo máximo del 5 % de pagar un sobrecosto innecesario, ¿qué decisión debería tomar en cuanto a comprar la semilla “mejorada” o la estándar?
La situación planteada conlleva una partición del espacio paramétrico de \(p,\) en dos regiones: una correspondiente a valores del parámetro menores o iguales que 0.9, en cuyo caso no se cumplirían las especificaciones anunciadas por el vendedor, y otra para valores del parámetro mayores que 0.9, caso en el que sí se satisfarían las especificaciones del producto. Esto implica el contraste de un juego de hipótesis de una cola.
Al concluir sobre el juego de hipótesis puede errarse por dos vías:
Concluir que el producto es mejorado, sin que lo sea.
Concluir que el producto no es mejorado, cuando sí lo es.
Tal y como se indica en el ejemplo 4.3, es necesario valorar los posibles errores y hacer coincidir el que se considere más grave con el error tipo I.
El presente ejemplo indica que el potencial comprador desea ponerle tope a la probabilidad de pagar un sobrecosto innecesario, es decir, a la probabilidad de concluir que el producto es mejorado, sin que lo sea. Consecuentemente, este es el error que debe hacerse coincidir con el error tipo I, el cual, en su definición general, consiste en concluir en favor de la hipótesis alternativa cuando la hipótesis nula es verdadera.
En consideración de lo anterior, basta con escribir el juego de hipótesis de manera que la hipótesis alternativa recoja las condiciones correspondientes a un producto mejorado, mientras que la nula coincida con las que tendría un producto no mejorado, teniendo presente incluir en la hipótesis nula la condición de igualdad entre el parámetro y el punto de corte:
\(H_0: p \le 0.9\) (la semilla no es mejorada)
\(H_a: p > 0.9\) (la semilla sí es mejorada)
La forma escrita del juego de hipótesis permite verificar de manera directa cuál es el error tipo I y cuál es el error tipo II.
A continuación, se desarrollan las cuatro técnicas inferenciales esquematizadas en la figura 4.6. En todos los casos se usa un nivel de significancia del 5 %, acorde con lo especificado en el planteamiento9.
Inicialmente se establece un marco común para las tres técnicas basadas en la aproximación normal.
Inferencia para una Proporción con base en la Aproximación Normal
Sea \(X\) la variable que representa el número de éxitos en un ensayo binomial.
\[
X \thicksim \text{bin}(n,\, p), \text{ con }E(X)=np\,\,\text{y}\,\, V(X)=npq,
\]
siendo \(n\) el número de ensayos Bernoulli; \(p,\) la probabilidad de éxito, y \(q,\) la probabilidad complementaria de \(p,\) es decir, la probabilidad de fracaso \((1 − p).\)
El teorema central del límite establece que cuando \(n\) es grande, la distribución de \(X\) es aproximadamente normal (cf. teorema 3.1)10:
\[
X \overset {{\cdot}}\thicksim N(np,\, npq)
\]
El estimador insesgado de mínima varianza del parámetro \(p\) es la proporción observada de éxitos (cf. sección 3.9.1.1.3), la cual, al ser una transformación lineal de una variable que sigue una distribución aproximadamente normal, se distribuye asimismo de forma aproximadamente normal.
\[
\hat{p}=\frac{X}{n} \overset {{\cdot}}\thicksim N\left(p,\,\frac{pq}{n}\right)
\]
Estandarizando,
\[
\dfrac{\hat{p}-p}{\sqrt{\dfrac{pq}{n}}} \overset {{\cdot}}\thicksim N\left(0,\,1\right)
\tag{4.7}\]
La expresión 4.7 constituye el punto de partida de los métodos basados en un estadístico de prueba que sigue una distribución aproximadamente normal, tal y como se ilustra en las siguientes tres secciones (4.4.1, 4.4.2 y 4.4.3).
Partiendo de la expresión 4.7 y remplazando la varianza de \(\hat{p}\) con su correspondiente estimador puntual11, se llega a una variable aleatoria que sigue teniendo distribución aproximadamente normal estándar.
\[
\dfrac{\hat{p}-p}{\sqrt{\dfrac{\hat{p}\widehat{q}}{n}}} \overset {{\cdot}}\thicksim N\left(0,\,1\right)
\]
Incorporando la condición de la hipótesis nula (se remplaza \(p\) por \(p_0\) en el numerador), se obtiene el estadístico de prueba usado en por el método de Wald:
\[
\text{Bajo }H_0,\quad Z_\text{W}=\dfrac{\hat{p}-p_0}{\sqrt{\dfrac{\hat{p}\widehat{q}}{n}}} \overset {{\cdot}}\thicksim N\left(0,\,1\right)
\]
La tabla 4.4 y la figura 4.7 resumen los criterios de rechazo de la hipótesis nula para los diferentes tipos de pruebas.
| Tipo de prueba | Criterio de rechazo de \(H_0\) para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda \(H_0:p\ge p_0\) \(H_a:p<p_0\) |
\(Z_\text{W}\le−z_{\alpha}\) |
\(P(Z < Z_\text{W})\) |
| Cola derecha \(H_0:p\le p_0\) \(H_a:p>p_0\) |
\(Z_\text{W}\ge z_{\alpha}\) |
\(P(Z > Z_\text{W})\) |
| Dos colas \(H_0:p=p_0\) \(H_a:p\ne p_0\) |
\(|Z_\text{W}|\ge z_{\alpha/2}\) |
\(2 \, P(Z > |Z_\text{W}|)\) |
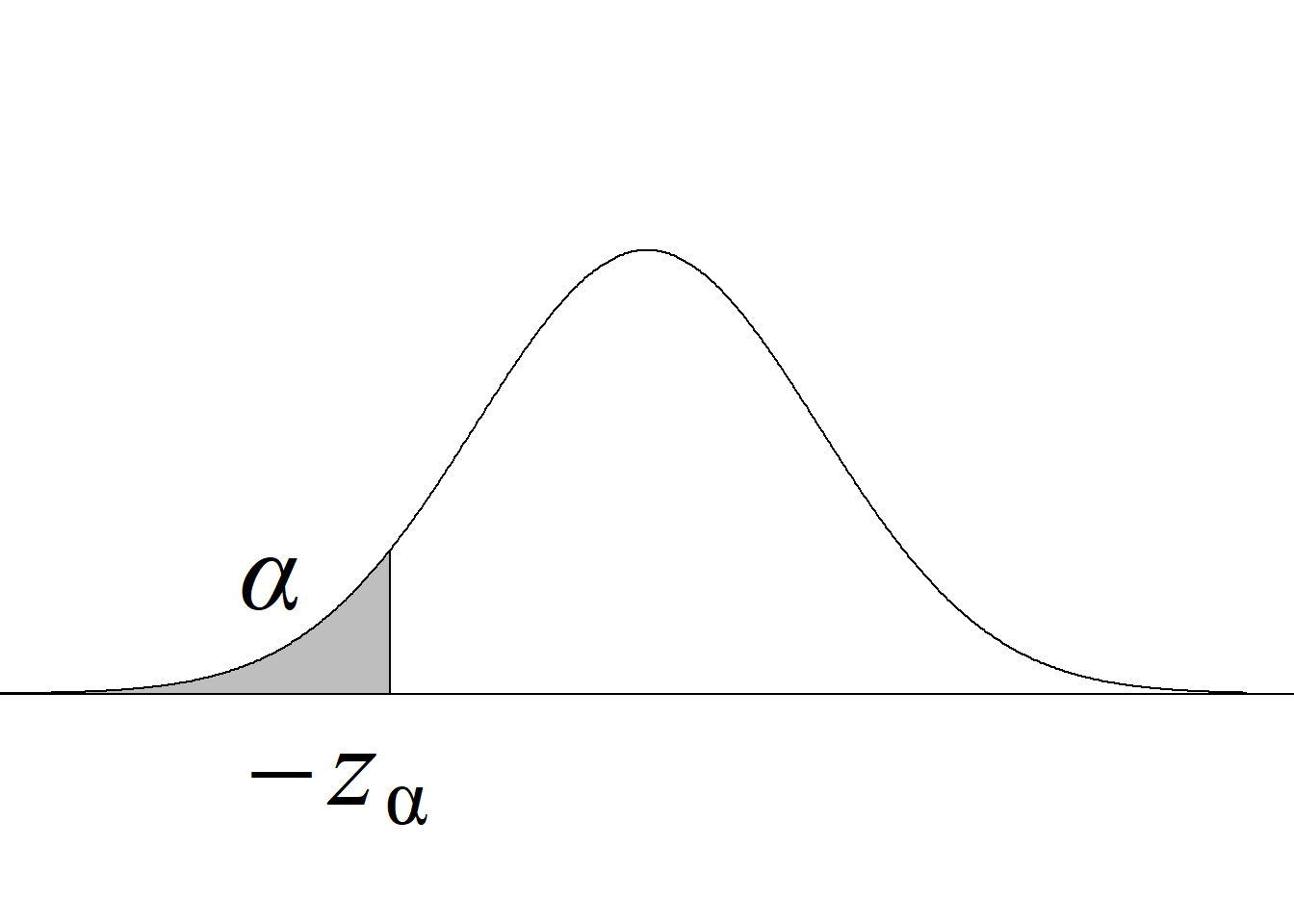
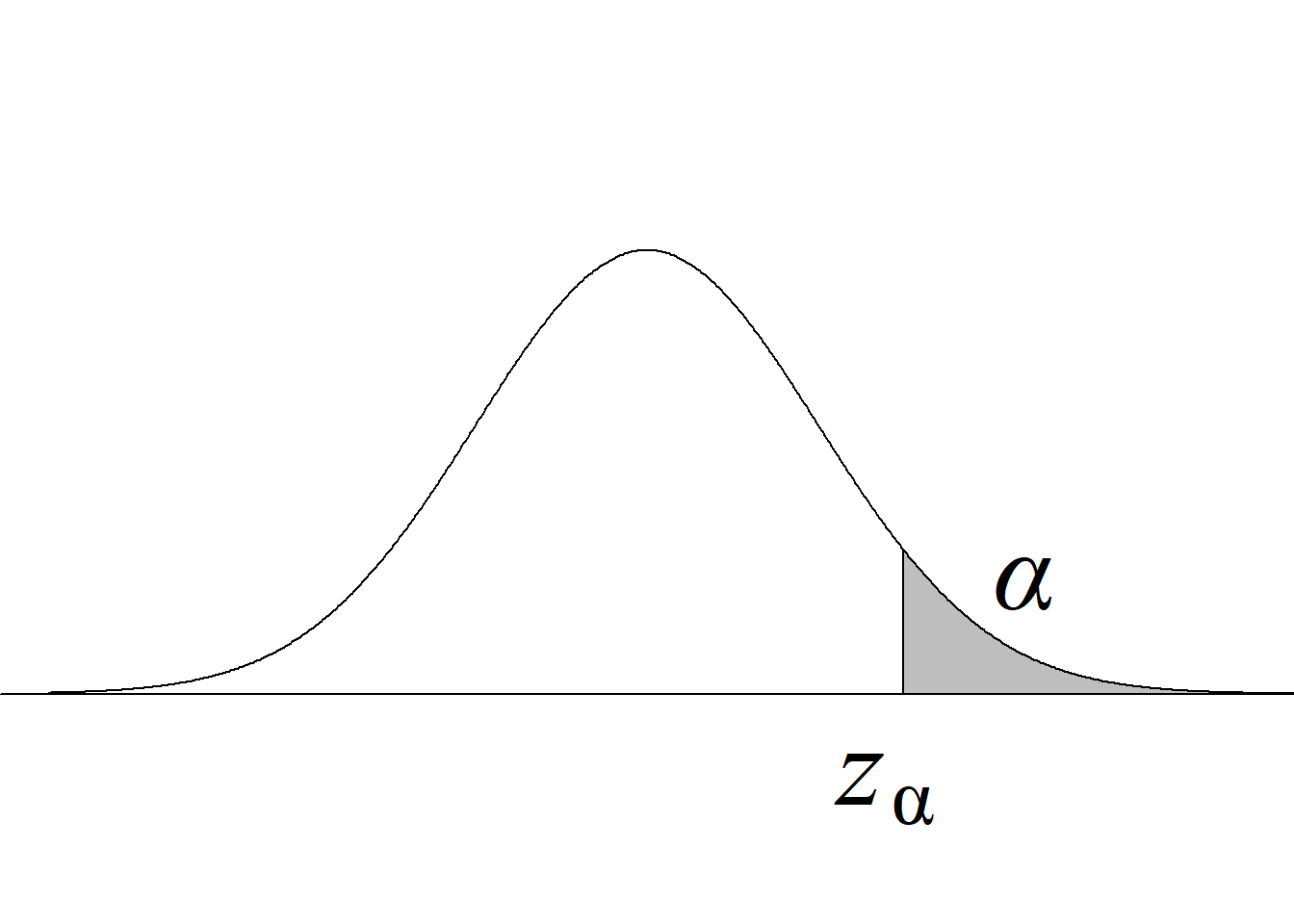
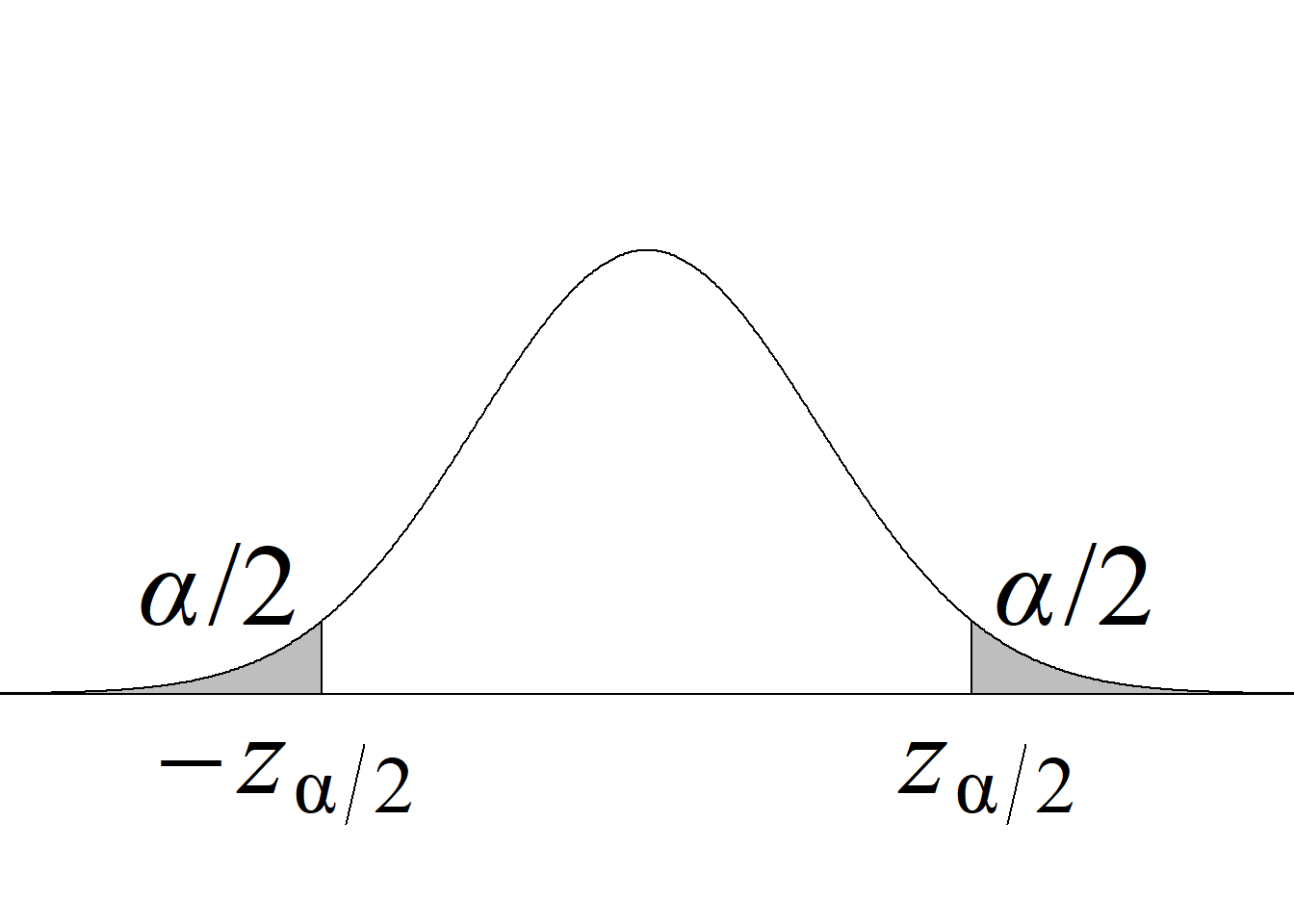
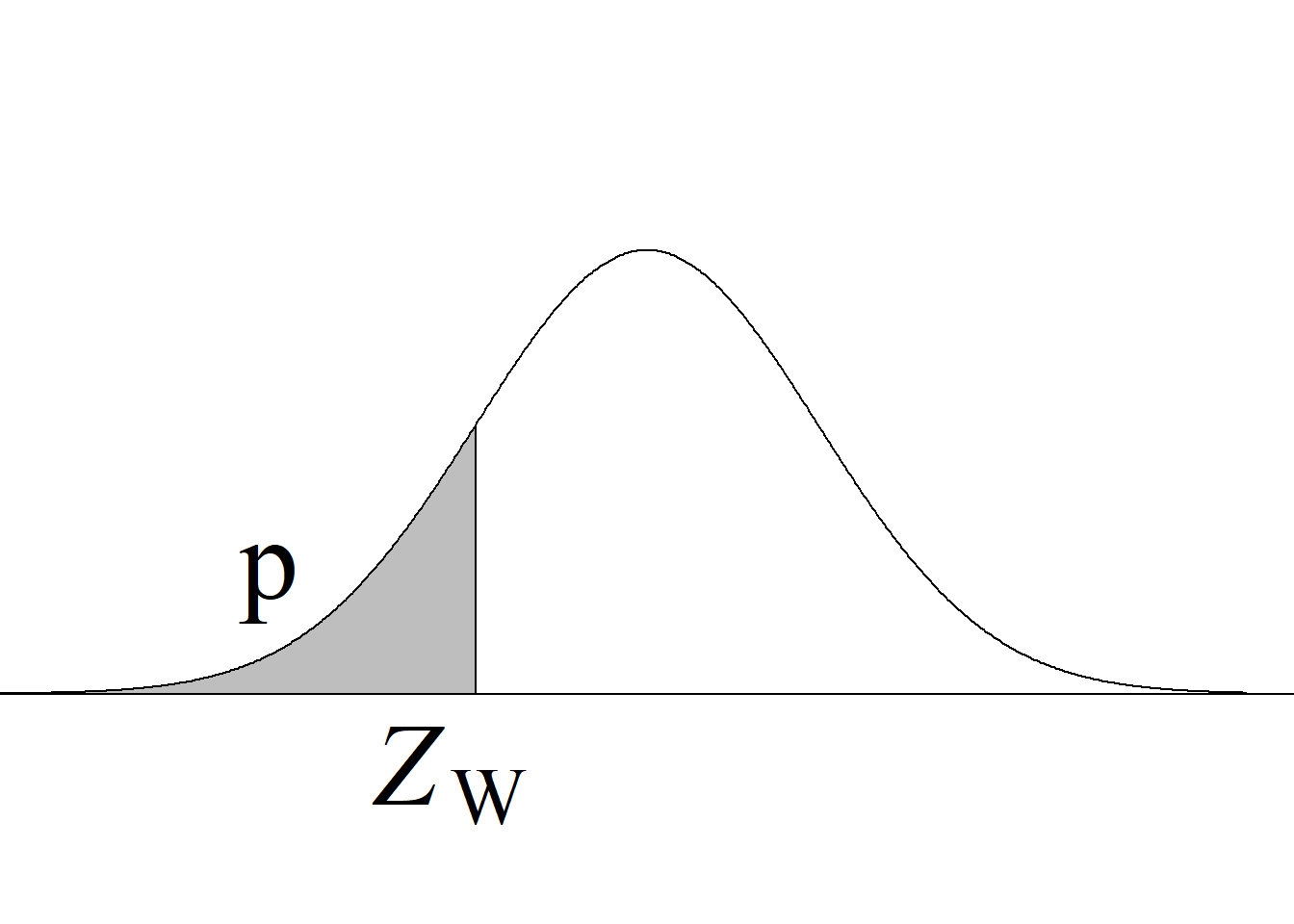
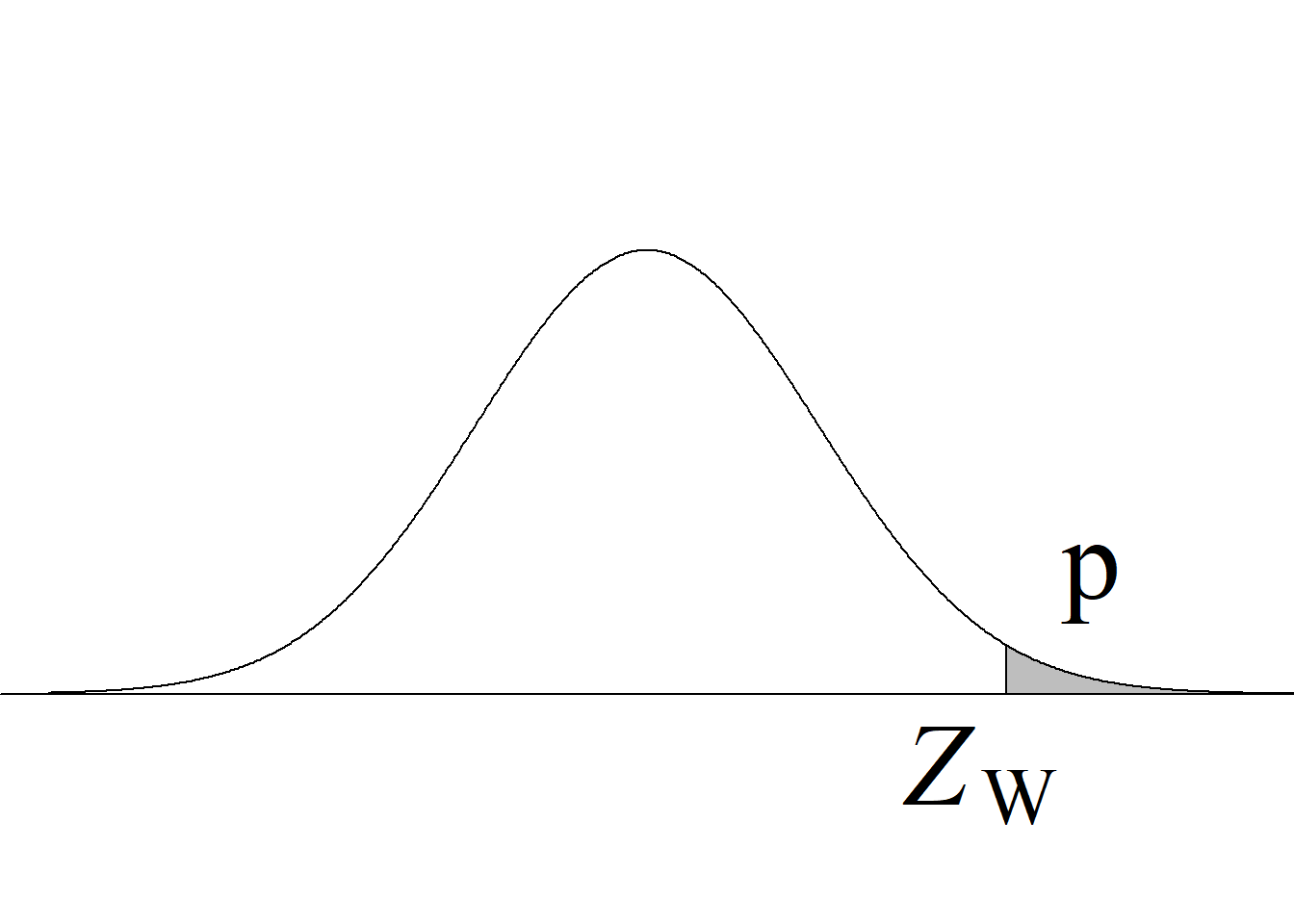
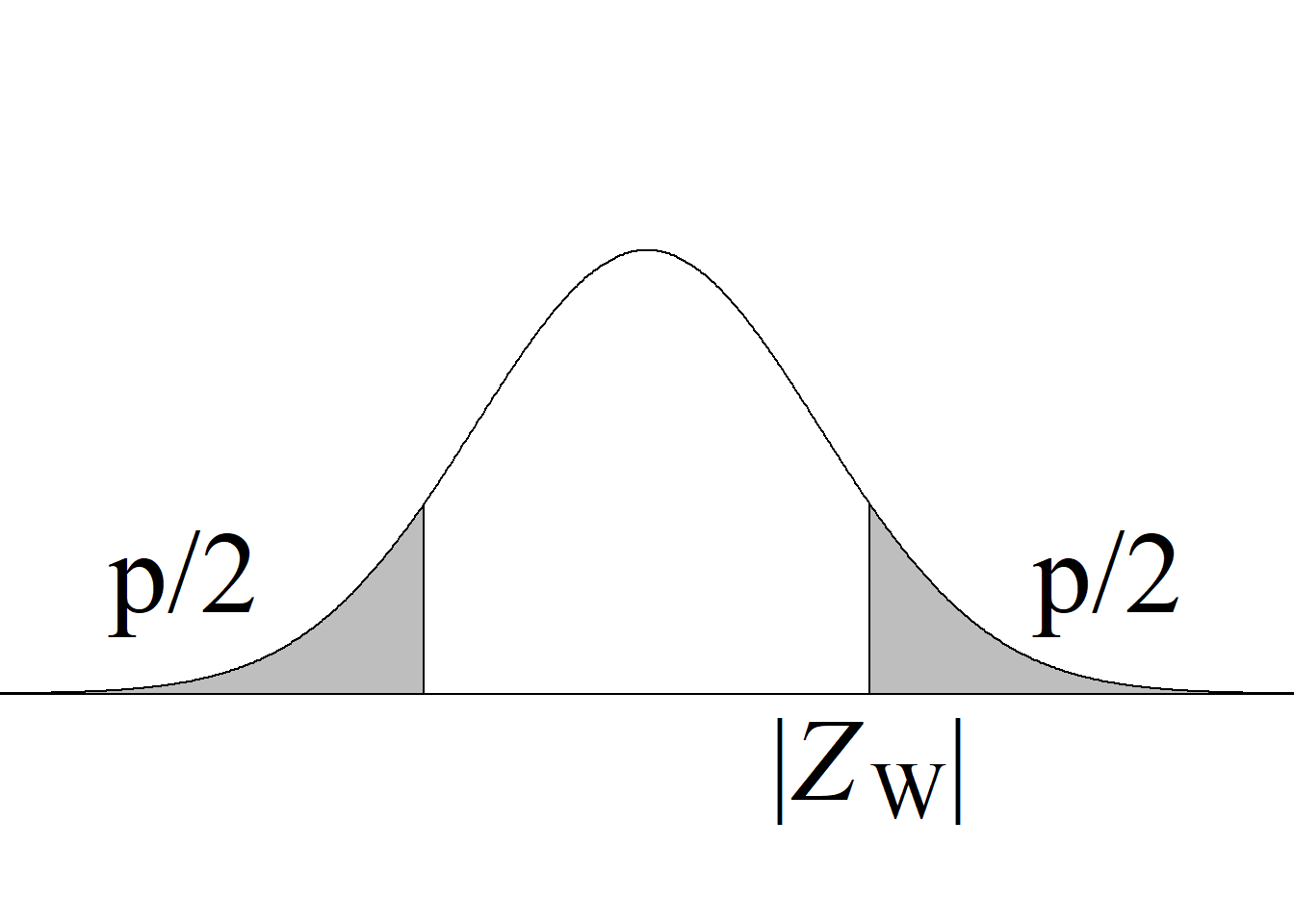
Para el ejemplo 4.4:
\[
\hat{p}=\frac{x}{n}=\frac{185}{200}=0.925,\quad\quad \widehat{q}=1-\hat{p}=1-0.925=0.075
\]
\[
Z_\text{W}=\frac{0.925-0.9}{\sqrt{\dfrac{0.925\times0.075}{200}}}=1.3423
\]
En el presente ejemplo, se está contrastando una prueba de cola derecha al 5 %. Luego, por el método tradicional, se compara el valor del estadístico de prueba contra el valor de la variable aleatoria normal estándar que deja a su derecha un área de 0.05, esto es, el valor crítico superior \(z_{0.05}.\) Usando en R la instrucción qnorm(0.05, lower.tail = F), se obtiene que \(z_{0.05} = 1.645.\)
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(Z_\text{W}\) \(1.3423\) |
\(<\) \(<\) |
\(z_{0.05}\) \(1.645\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no se rechaza \(H_0\) con \(α = 0.05\) |
El ensayo no aporta elementos que permitan concluir, con una probabilidad de error menor o igual que 0.05, que las semillas sean mejoradas, es decir, que su viabilidad sea superior al 90 %. Teniendo en cuenta que el comprador está dispuesto a asumir un riesgo máximo del 5 % de pagar un sobrecosto innecesario, debería optar por la semilla estándar.
Supóngase que, tras sostener una larga conversación con el vendedor acerca del proceso de mejoramiento, y considerando que \(\hat{p}=0.925,\) el comprador decide seguir su intuición y comprar la semilla, sin condicionar su decisión al resultado del ensayo.
La obtención de un intervalo de confianza para \(p\) es directa, mediante el método de inversión (cf. sección 4.2.2). Para ello se parte de la siguiente expresión:
\[
\dfrac{\hat{p}-p}{\sqrt{\dfrac{\hat{p}\widehat{q}}{n}}} \overset {{\cdot}}\thicksim N\left(0,\,1\right)
\]
\[
\Rightarrow P\left(\left|\dfrac{\hat{p}-p}{\sqrt{\dfrac {\hat{p}\widehat{q}}{n}}}\right|>z_{\alpha/2}\right)\approx\alpha
\]
Por tanto, la probabilidad aproximada del complemento es:
\[
P\left(\left|\dfrac{\hat{p}-p}{\sqrt{\dfrac {\hat{p}\widehat{q}}{n}}}\right|<z_{\alpha/2}\right)\approx 1-\alpha
\]
Despejando el valor absoluto, se tiene:
\[
P \left(-z_{\alpha/2} < \dfrac{\hat{p} - p}{\sqrt{\dfrac {\hat{p}\widehat{q}}{n}}} < z_{\alpha/2}\right)\approx 1-\alpha
\]
A continuación se multiplican todos los miembros de la desigualdad por \(\sqrt{\hat{p}\widehat{q}/n}\,\):
\[
P \left(-z_{\alpha/2} \sqrt{\dfrac {\hat{p}\widehat{q}}{n}}
< \hat{p} - p <
z_{\alpha/2}\sqrt{\dfrac {\hat{p}\widehat{q}}{n}}\right)\approx 1-\alpha
\]
Se resta \(\hat{p}\) a cada miembro de la desigualdad:
\[
P \left(-z_{\alpha/2} \sqrt{\dfrac {\hat{p}\widehat{q}}{n}}-\hat{p}
<- p <
z_{\alpha/2}\sqrt{\dfrac {\hat{p}\widehat{q}}{n}} - \hat{p} \right)\approx 1-\alpha
\]
Se multiplica por \(-1\) (cambia el sentido de la inecuación):
\[
P \left(\hat{p}-z_{\alpha/2} \sqrt{\dfrac {\hat{p}\widehat{q}}{n}}
< p <
\hat{p}+z_{\alpha/2}\sqrt{\dfrac {\hat{p}\widehat{q}}{n}}\right)\approx 1-\alpha
\]
Luego, un intervalo de confianza aproximado del \(100(1 − \alpha)\,\%\) para \(p\) está dado por:
\[
\hat{p}\pm z_{\alpha/2} \sqrt{\dfrac {\hat{p}\widehat{q}}{n}}
\]
A este intervalo de confianza para \(p\) se le denomina intervalo de confianza de Wald. Aunque en algunos textos lo denominan simplemente intervalo de confianza mediante la aproximación normal, desaconsejamos este nombre por su ambigüedad, dado que hay otros intervalos de confianza que también están basados en la aproximación normal.
Para el presente ejemplo, en el que se está contrastando una prueba de cola derecha, se obtiene un intervalo de confianza unilateral inferior del 95 % (cf. nota 4.3):
\[
\text{LI}: \hat{p}- z_{\alpha} \sqrt{\frac {\hat{p}\widehat{q}}{n}}=0.925-1.645 \sqrt{\frac {0.925\times 0.075}{200}}
=0.8943
\]
Puede decirse que se tiene una confianza del 95 % en que la viabilidad de las semillas es superior a 0.8943.
Como siempre, el intervalo ratifica la conclusión de la prueba de hipótesis. No es posible afirmar con baja probabilidad de error (menor de 0.05) que la viabilidad de la semilla sea superior al 90 %.
Nótese, sin embargo, que el estimador por intervalo (unilateral en este caso) resulta más informativo que la correspondiente prueba de hipótesis. Un potencial comprador bien podría considerar que la presente información le es suficiente para adquirir el lote de semillas, con lo cual, desde luego, la probabilidad de estar pagando un sobrecosto innecesario ya no sería 0.05, sino 0.0897, tal como informó el valor p.
El intervalo de confianza unilateral obtenido para el parámetro \(p\) del ejemplo 4.4 puede presentarse así:
\[
[0.8943,\quad 1]
\]
Aunque esta presentación dé la sensación de que se trata de un intervalo bilateral, no es así. El intervalo de confianza que guarda correspondencia con una prueba de cola derecha es unilateral inferior. El \(1\) que aparece en el intervalo anterior no se calcula con base en la información muestral, sino que constituye la cota natural del parámetro \(p,\) que no puede tomar valores por encima de 1.
De manera análoga, si se estuviera calculando un intervalo de confianza unilateral superior para el parámetro \(p,\) correspondiente a una prueba de cola izquierda, podría escribirse así:
\[
[0,\quad \text{LS}]
\]
En este caso, lo único que se habría calculado sería el límite superior \(\text{LS};\) por su parte, el \(0\) correspondería a la cota natural inferior del parámetro \(p.\)
Una situación análoga se discutió al presentar un intervalo de confianza unilateral superior para el parámetro \(\sigma^2,\) en el ejemplo 4.3 (cf. sección 4.3.2).
La inferencia sobre \(p\) basada en la aproximación a la distribución normal de la variable que representa el número de éxitos se fundamenta en el teorema central del límite, que establece que cuando se tienen tamaños de muestra suficientemente grandes, los promedios —y también las sumas, como la representada por \(X\)— de cualquier variable aleatoria convergen a la distribución normal (cf. teorema 3.1). Así, pues, el uso de tal aproximación es viable cuando el tamaño de muestra, \(n,\) es grande (cf. figura 3.7 (b)).
Como regla de oro, algunos autores mencionan que dicha aproximación no debe usarse a menos que \(n > 30\) y los productos \(np\) y \(nq\) sean ambos mayores a 5 (o a 10). Otros consideran necesario que \(n > 100;\) otros más prefieren verificar que el producto \(npq > 5\) o que se obtengan como mínimo 15 éxitos y 15 fracasos.
Sin embargo, autores como Brown, Cai y DasGupta (2001, 2002) muestran, mediante extensos estudios de simulación, que ninguna de estas prescripciones es suficiente para corregir el comportamiento errático del método de Wald. Su conclusión es categórica:
El método de Wald nunca debería usarse.
La conclusión de los autores que han realizado los estudios de simulación para evaluar el desempeño de los intervalos de confianza para la estimación del parámetro \(p\) es contundente:
“No utilice el método de Wald si tiene una mejor alternativa”.
Tal y como lo expresa el profesor George Casella en uno de los comentarios que aparecen al final del artículo de Brown, Cai y DasGupta (2001), llegó el momento de cantarle Bye-bye, so long, farewell al intervalo de Wald.
La buena noticia es que sí se tienen mejores alternativas. En las secciones 4.4.2 y 4.4.3 se presentan un par de opciones.
Es importante aclarar que no es posible evaluar una prueba de bondad de ajuste, tipo Shapiro-Wilk (cf. sección 4.1) para dictaminar lo adecuado o inadecuado que pueda resultar el uso de la aproximación normal en un ensayo particular. Todas las recomendaciones anotadas anteriormente provienen de ensayos de simulación en los que se analiza el comportamiento de diferentes pruebas bajo diversas condiciones.
Si al leer el título de esta sección usted se encuentra desconcertado, pensando que es un sinsentido calcular el tamaño de muestra mediante un método desaconsejado, tiene toda la razón. No obstante, hay una explicación para ello.
Si bien es cierto que el método de Wald se desaconseja para todos sus usos inferenciales (intervalos de confianza, pruebas de hipótesis y cálculo del tamaño de muestra), lo que sí hay que abonarle es su sencillez. Esta es la razón por la que en esta sección se usa el método de Wald para ilustrar la lógica del cálculo del tamaño de muestra. Si, tras entender la lógica en cuestión se desea calcular un tamaño de muestra para una situación particular, se recomienda remitirse a la sección 4.4.5.
Antes de entrar en el desarrollo, vale la pena revisar los conceptos de confianza y precisión que se discuten en la sección 4.2.4; en particular, la precisión de una estimación por intervalo, la cual está dada por el máximo alejamiento tolerable entre el estimador puntual y el parámetro que se está estimando.
En intervalos de confianza simétricos, como el que se obtiene para la estimación de \(p\) mediante el método de Wald, la precisión está dada por la semiamplitud del intervalo, tal y como lo ilustra la figura 4.8.
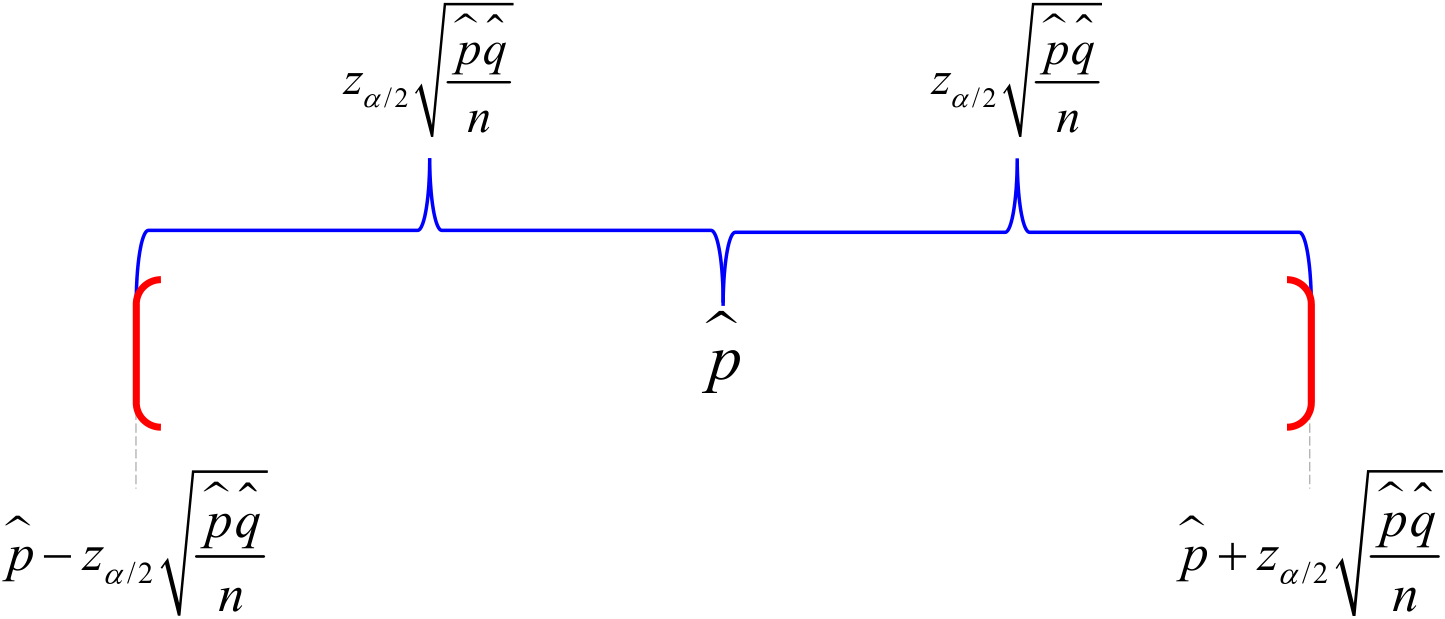
Para calcular el tamaño de muestra requerido se parte de la precisión deseada, \(\text{pr}:\)
\[
\text{pr}=z_{\alpha/2} \sqrt{\dfrac {\hat{p}\widehat{q}}{n}}
\]
El despeje de \(n\) a partir de la expresión anterior es inmediato:
\[
n=\left(\dfrac{z_{\alpha/2}}{\text{pr}}\right)^2 \hat{p}\widehat{q}
\]
Hay tres aspectos que determinan el tamaño de la muestra: la confianza, la precisión y la varianza.
La confianza aparece reflejada en el valor crítico superior de la normal estándar. Si consideramos, por ejemplo, una confianza del 95 %, el valor crítico es 1.96, mientras que el valor crítico para una confianza del 99 % es 2.576. Claramente, mientras mayor sea la confianza deseada, mayor será también el tamaño de muestra requerido.
La precisión —que aparece en el denominador de la anterior expresión— también determina el tamaño de la muestra: mientras mayor sea la precisión deseada (mayor cercanía entre el estimador y el parámetro, es decir, menores valores de la semiamplitud), mayor será el tamaño de muestra.
El otro factor que determina el tamaño de muestra es la variabilidad. Recuérdese que la varianza de una variable aleatoria binomial es \(npq,\) por lo que la varianza de una proporción \(pq/n.\) El factor \(\hat{p}\hat{q}\) recoge la esencia de la variabilidad.
En este caso es aun más evidente la dependencia circular que se discutió al presentar una propuesta para calcular el tamaño de muestra necesario para estimar la media de una población normal (cf. sección 4.2.4): se quiere averiguar el tamaño de muestra requerido para estimar \(p,\) pero la fórmula para el cálculo depende del estimador de \(p.\)
No obstante, a diferencia del escenario en el que se pretendía calcular el tamaño de muestra para estimar la media de una población normal, donde la varianza no tenía tope, lo que hacía necesario realizar un premuestreo o utilizar información exógena, en el presente caso, el producto \(\hat{p}\hat{q}\) sí tiene un tope máximo, tal y como puede verificarse derivando \(\hat{p}\hat{q}\) con respecto a \(\hat{p}:\)
\[
\frac{\mathrm{d}(\hat{p}\hat{q})}{\mathrm{d}\hat{p}}=
\frac{\mathrm{d}(\hat{p}\,(1-\hat{p}))}{\mathrm{d}\hat{p}}=
\frac{\mathrm{d}(\hat{p}-\hat{p}^2)}{\mathrm{d}\hat{p}}=
1-2\hat{p}
\]
Igualando a cero se tiene:
\[
1-2\hat{p}=0\;\; \Rightarrow\;\; 2\hat{p}= 1\;\; \Rightarrow\;\;\hat{p} = 0.5
\]
Luego, el máximo valor del producto \(\hat{p}\widehat{q}\) se obtiene cuando \(\hat{p}=0.5.\) Este valor máximo es \(\hat{p}\widehat{q}=0.25.\) La figura 4.9 ilustra el comportamiento del producto \(\hat{p}\widehat{q}\) para el rango de posibles valores de \(\hat{p}.\)
Aunque sigue siendo válido realizar un premuestreo o usar información exógena para obtener una preestimación de \(p\) que permita calcular el tamaño de muestra, esto no es obligatorio. Si el usuario no tuviera absolutamente ninguna información sobre el posible valor de \(p,\) usaría el valor \(\hat{p}=0.5,\) con lo cual estaría realizando el cálculo más conservador de \(n,\) es decir, el tamaño de muestra que permitiría estimar \(p\) bajo el escenario de máxima variabilidad, que es cuando \(p=0.5.\)
Si entendió la lógica tras el cálculo del tamaño de muestra para estimar \(p,\) siéntase satisfecho. Ese es el único objetivo de esta sección.
Si desea calcular el tamaño de muestra para estimar \(p,\) remítase a la sección 4.4.5.
A fin de suplir las carencias del método de Wald, sin renunciar a su simplicidad, Agresti y Coull (1998) proponen una modificación a este, la cual —para el caso de intervalos de confianza del 95 %— se resume en adicionar 2 éxitos y 2 fracasos y aplicar seguidamente el método de Wald tal y como se expuso en la sección 4.4.1.
Los 2 éxitos y 2 fracasos considerados en esta propuesta no hacen parte de la muestra; son meros artificios utilizados para mejorar el desempeño del método de Wald. En tal sentido, se trata de 2 seudoéxitos y 2 seudofracasos.
El tamaño muestral usado para esta prueba se incrementa artificialmente en 4 unidades.
Para diferenciar los estimadores utilizados en este método de los del método de Wald, usaremos una virgulilla en lugar del acento circunflejo, así:
\[
\widetilde{p}=\frac{X+2}{n+4}
\]
\[
\widetilde{q}=1-\widetilde{p}
\]
Y consecuentemente con esta notación, al tamaño de muestra adicionado con los dos seudoéxitos y los dos seudofracasos lo denotamos también con virgulilla:
\[
\widetilde{n}=n+4
\]
El estadístico de prueba de Agresti y Coull adquiere la siguiente forma:
\[
Z_{\text{AC}}=\frac{\widetilde{p}-p_0}{\sqrt{\frac{\widetilde{p}\widetilde{q}}{\widetilde{n}}}}
\]
Puesto que bajo la hipótesis nula \(Z_{\text{AC}}\overset {{\cdot}}\thicksim N\left(0,\,1\right),\) pueden usarse los mismos criterios presentados en la tabla 4.4 y la figura 4.7, cambiando el estadístico de prueba \(Z_\text{W}\) por \(Z_{\text{AC}}.\)
Para el ejemplo 4.4 se realizan los siguientes cálculos:
\[
\begin{align}
\widetilde{p}&=\frac{185+2}{200+4}=0.91667\\[1.4em]
\widetilde{q}&=1-0.91667=0.08333\\[1.4em]
\widetilde{n}&=200+4=204
\end{align}
\]
Por tanto:
\[
Z_{\text{AC}}=\frac{0.91667-0.9}{\sqrt{\dfrac{0.91667\times 0.08333}{204}}}=0.8615
\]
Valor p : pnorm(0.8615, lower.tail = FALSE) = 0.1945
Aunque la conclusión, en términos de no rechazo, es la misma que se obtuvo con base en la prueba sin ajustar de Wald, el ajuste pone de manifiesto que el riesgo de incurrir en un sobrecosto innecesario es sustancialmente mayor que el calculado mediante el método de Wald.
Un intervalo de confianza aproximado del \(100(1 − \alpha)\,\%\) para \(p\) se obtiene con base en la expresión:
\[
\widetilde{p}\pm z_{\alpha/2} \sqrt{\frac {\widetilde{p}\widetilde{q}}{\widetilde{n}}}
\]
Un intervalo de confianza unilateral inferior del 95 % para el ejemplo 4.4 se calcula así:
\[
\text{LI}: \widetilde{p}- z_{\alpha} \sqrt{\frac {\widetilde{p}\widetilde{q}}{\widetilde{n}}}=0.91667-1.645 \sqrt{\frac {0.91667\times 0.08333}{204}}
=0.8848
\]
El ajuste del método de Wald presentado como la adición de 2 éxitos y 2 fracasos es una forma nemotécnica, reducida y aproximada de mostrar el ajuste en cuestión, cuando se desean obtener intervalos de confianza del 95 %.
La forma completa del ajuste propuesto por Agresti y Coull (1998) —válida para cualquier confianza— consiste en adicionarle \(z_{\alpha/2}^2/2\) a \(X\) y sumarle \(z_{\alpha/2}^2\) a \(n,\) así:
\[
\begin{align}
\widetilde{X}&=X+\frac{z_{\alpha/2}^2}{2}\\[1.4em]
\widetilde{n}&=n+z_{\alpha/2}^2
\end{align}
\]
A partir de estas cantidades ajustadas se definen los estimadores:
\[
\begin{align}
\widetilde{p}&=\frac{\widetilde{X}}{\widetilde{n}}\\[1.4em]
\widetilde{q}&=1-\widetilde{p}
\end{align}
\]
La recomendación de sumar 2 éxitos y 2 fracasos surge del hecho de que al trabajar con una confianza del 95 %, el valor crítico superior de la distribución normal es 1.96, que se aproxima a 2.
Consecuentemente, a \(n\) se le suma aproximadamente 2 elevado al cuadrado, que es 4.
\[
\widetilde{n}=n+z_{\alpha/2}^2=n+1.96^2=n+(\approx 2)^2 \approx n+4
\]
Por su parte, a \(X\) se le adiciona aproximadamente 2 elevado al cuadrado, que es 4, dividido entre 2, que da 2:
\[
\widetilde{X}=X+\frac{z_{\alpha/2}^2}{2}=X+\frac{1.96^2}{2}=X+\frac{(\approx 2)^2}{2}\approx X+\frac{4}{2}\approx X+2
\]
Finalmente, si a la muestra total se le suman 4 observaciones, 2 de las cuales corresponden a éxitos, las otras 2 corresponden a fracasos.
Aunque la adición de 2 éxitos y 2 fracasos constituye una forma ingeniosa y nemotécnica de implementar el ajuste de Agresti y Coull, debe tenerse presente que esta estrategia únicamente aplicaría para el cálculo de intervalos de confianza del 95 %.
Al igual que el método de Wald, este método también está basado en la aproximación normal; sin embargo, difiere de aquel en la forma en la que trata la varianza del estimador.
Retomemos la expresión 4.7, que formaliza la aproximación normal para el estimador puntual de \(p:\)
\[
\frac{\hat{p}-p}{\sqrt{\frac{pq}{n}}} \overset {{\cdot}}\thicksim N\left(0,\,1\right)
\]
Ya se había indicado la necesidad de remplazar el valor de la varianza de \(\hat{p}\) —el cociente dentro del radical— para poder usar la expresión anterior como estadístico de prueba.
En este caso, se remplazan \(p\) y \(q\) con sus correspondientes valores hipotéticos, lo que conduce a la siguiente expresión:
\[
\dfrac{\hat{p}-p}{\sqrt{\dfrac{p_0q_0}{n}}}\overset {{\cdot}}\thicksim N\left(0,\,1\right)
\]
El estadístico de prueba del método del score se construye incorporando en el numerador la condición establecida por la hipótesis nula, es decir, remplazando \(p\) por \(p_0,\) así:
\[
Z_\text{s}=\dfrac{\hat{p}-p_0}{\sqrt{\dfrac{p_0q_0}{n}}}\overset {{\cdot}}\thicksim N\left(0,\,1\right)
\]
A la prueba basada en este estadístico se le denomina prueba del score. Y, dado que, bajo la hipótesis nula, \(Z_\text{s}\) sigue una distribución normal estándar, es posible utilizar los mismos criterios que se resumen en la tabla 4.4 y la figura 4.7, remplazando \(Z_\text{W}\) por \(Z_\text{s}\).
Para el ejemplo 4.4:
\[
Z_\text{s}=\frac{0.925-0.9}{\sqrt{\dfrac{0.9\times 0.1}{200}}}=1.1785
\]
Valor p : pnorm(1.1785, lower.tail = FALSE) = 0.1193
| \(\,\) Puesto que \(\hspace{-1.5em}\) |
\(\text{p}\) \(0.1193\) |
\(>\) \(>\) |
\(\alpha\) \(0.05\) |
\(\,\) \(\hspace{-1.5em}\Rightarrow\) no se rechaza \(H_0\) |
Wilson (1927) mostró cómo invertir la prueba del score para generar un intervalo de confianza. Al intervalo que se obtiene a través de dicha inversión se le denomina intervalo del score, intervalo de Wilson o intervalo de confianza Wilson-score y puede calcularse mediante la siguiente expresión:
\[
\text{IC:}\quad\frac{1}{1+\frac{z_{\alpha/2}^2}{n}}\left(\hat{p}+\frac{z_{\alpha/2}^2}{2n}\pm z_{\alpha/2}\sqrt{\frac{\hat{p}\widehat{q}}{n}+\frac{z_{\alpha/2}^2}{4n^2}}\right)
\tag{4.8}\]
Obsérvese que —a diferencia de los intervalos de Wald y de Agresti y Coull— este intervalo no es simétrico alrededor de \(\hat{p}.\)
Un intervalo de confianza unilateral inferior del 95 % para el ejemplo 4.4 se obtiene así:
\[
\text{LI}=\frac{1}{1+\frac{z_{0.05}^2}{n}}\left(\hat{p}+\frac{z_{0.05}^2}{2n}- z_{0.05}\sqrt{\frac{\hat{p}\widehat{q}}{n}+\frac{z_{0.05}^2}{4n^2}}\right)
\]
\[
\begin{multline}
\text{LI}=\frac{1}{1+\dfrac{(1.645)^2}{200}}\\
\times\left(0.925+\frac{(1.645)^2}{400}- 1.645\sqrt{\frac{0.925\times 0.075}{200}+\frac{(1.645)^2}{4(200)^2}}\right)\\
=0.888
\end{multline}
\]
Es posible obtener los anteriores resultados (prueba de hipótesis e intervalo de confianza, basados en la prueba del score) de manera directa en R, usando la función prop.test{stats}. A continuación se ilustra su uso, usando los datos del ejemplo 4.4:
prop.test(x = 185, n = 200, p = 0.9, alternative = "greater", correct = F)En el código anterior, x representa el número de éxitos; n, el tamaño del ensayo binomial; p es el valor hipotético del parámetro \(p.\) El argumento alternative, cuyo valor por defecto es two.sided, puede modificarse para realizar pruebas de cola derecha (greater) o izquierda (less); el argumento correct, cuyo valor por defecto es TRUE, indica si debe aplicarse o no la corrección de Yates por continuidad.
Se obtienen los siguientes resultados:
1-sample proportions test without continuity correction
data: 185 out of 200, null probability 0.9
X-squared = 1.3889, df = 1, p-value = 0.1193
alternative hypothesis: true p is greater than 0.9
95 percent confidence interval:
0.8883737 1.0000000
sample estimates:
p
0.925 Los resultados obtenidos mediante la función prop.test coinciden con los de los cálculos manuales, excepto por el valor del estadístico de prueba.
La función prop.test utiliza un estadístico ji cuadrado en lugar de un estadístico normal estándar. El estadístico ji cuadrado es el estadístico \(Z_\text{s}\) elevado al cuadrado. Para el ejemplo 4.4, \((1.1785)^2=1.3889.\)
Y, dado que una variable aleatoria normal estándar elevada al cuadrado sigue una distribución ji cuadrado con 1 grado de libertad (cf. sección 3.7.2), el resultado es equivalente en lo que a significancia se refiere.
Al usar el método del score, Agresti y Coull (1998) desaconsejan aplicar la corrección por continuidad de Yates, puesto que genera intervalos de confianza tan conservadores como los del método exacto de Clopper-Pearson (cf. sección 4.4.4).
Puesto que la función prop.test aplica esta corrección por defecto (correct = TRUE), es necesario indicar lo contrario de manera explícita: correct = FALSE.
Al realizar inferencia sobre el parámetro \(p\) de la distribución binomial, es posible prescindir de la aproximación normal, usando el número de éxitos como estadístico de prueba.
Esta prueba, propuesta por Clopper y Pearson (1934), está basada en la distribución del número de éxitos.
\[
X \thicksim \text{bin}(n,\, p)
\]
Puesto que la variable aleatoria \(X\) siempre se distribuye binomialmente, sin importar el tamaño de la muestra ni el valor de \(p,\) a este método se le denomina exacto.
Puesto que el método de Clopper-Pearson no se basa en la aproximación normal, suele denominársele método “exacto”. Esta apelación, sin embargo, puede ser engañosa, pues el hecho de que la inferencia no esté basada en una aproximación no implica que esta sea exacta ni que sus propiedades inferenciales sean mejores.
Agresti y Coull (1998) lo resaltan en su artículo titulado «Aproximado es mejor que “exacto” para la estimación por intervalo de proporciones binomiales».
Para la aplicación del método de Clopper-Pearson, se parte de la definición del valor p como la probabilidad de obtener un valor igual o más extremo que el del estadístico de prueba, si la hipótesis nula es cierta (cf. nota 3.3). En este caso, puesto que la distribución del estadístico de prueba es discreta (binomial), hay que hacer énfasis en incluir la probabilidad correspondiente al estadístico de prueba (el valor de la igualdad).
La definición de extremo se basa en los resultados menos probables bajo la hipótesis nula.
Como ayuda nemotécnica, los valores extremos se encuentran en la región hacia la que señala la hipótesis alternativa: valores bajos en pruebas de cola izquierda; valores altos en pruebas de cola derecha.
Para el ejemplo 4.4, en el que se ha planteado una prueba de cola derecha, los valores extremos del estadístico de prueba \(X\) serán aquellos iguales o mayores que el número observado de éxitos. Un número alto de éxitos constituye un resultado extremo bajo la hipótesis nula y respalda la hipótesis alternativa (cf. sección 3.9.2.5).
Bajo la hipótesis nula, esto es, cuando \(p = p_0,\) dicha probabilidad se calcula así:
\[
P(X\ge x)=\sum\limits_{i=x}^n {{n}\choose{i}}p_0^iq_0^{n-i}
\]
Esta probabilidad se calcula de la siguiente manera en R:
x <- 185
n <- 200
p0 <- 0.9
pbinom(x - 1, n, p0, lower.tail = FALSE)[1] 0.1430754Hay que tener en cuenta que la función pbinom acumula la probabilidad desde cero hasta el valor del argumento. Por tanto, si se usa x como argumento, calcula \(P(X\le x).\) Y cuando se usa la opción lower.tail = FALSE, se calcula la probabilidad complementaria, esto es, \(P(X > x),\) que es equivalente a \(P(X \ge x+1 ).\)
Luego, para obtener \(P(X \ge x),\) es necesario usar x - 1 como valor del primer argumento, junto con la opción lower.tail = FALSE.
A quien esté acostumbrado a trabajar con las tablas de la distribución binomial, puede resultarle más intuitivo un acercamiento a través del complemento de la probabilidad:
\(P(X < 185)+P(X \ge 185)=1\)
\(P(X \ge 185)=1- P(X < 185)\)
\(P(X \ge 185)=1- P(X \le 184)\)
Luego, también sería posible calcular el valor p de esta manera:
x <- 185
n <- 200
p0 <- 0.9
1 - pbinom (x - 1, n, p0)Análogamente, si se tratara de una prueba de cola izquierda, se calcularía la probabilidad de un valor menor o igual que el observado, así:
\[
P(X\le x)=\sum\limits_{i=0}^x {{n}\choose{i}}p_0^iq_0^{n-i}
\]
Dado que se trata de una probabilidad acumulada, en R se obtendría de manera directa así:
pbinom(x, n, p0)[1] 0.9070538Si la prueba fuera de dos colas, se obtendrían los valores correspondientes a las dos expresiones anteriores y se multiplicaría el menor de ellos por 2.
Si usando la información muestral del ejemplo 4.4 se estuviera contrastando una prueba de cola derecha, valor p = 0.1430754; si fuera de cola izquierda, valor p = 0.9070538; si se tratara de una prueba de dos colas, valor p = 0.2861508.
En pruebas de dos colas es común calcular el valor p mediante la duplicación de la más pequeña de las probabilidades de valores más extremos que el observado, calculando, desde el valor observado, las probabilidades acumuladas hacia cada una de las colas de la distribución. Todo este proceso se resume elegantemente en inglés como twice the smaller tail.
Aunque este procedimiento es perfectamente válido cuando la distribución de referencia es continua, solo es aproximada en distribuciones discretas, en las que el valor p exacto se obtendría en sumando las probabilidades de todos los puntos con probabilidad menor o igual que la del punto observado, bajo la hipótesis nula, sin importar si se encuentra a la izquierda o a la derecha.
A los intervalos de confianza para \(p\) basados en la distribución binomial se les denomina intervalos de confianza “exactos” de Clopper-Pearson.
Un intervalo de confianza del \(100(1−\alpha)\,\%\) para \(p\) está conformado por un par de variables aleatorias \(\text{LI}\) y \(\text{LS},\) tales que \(P(\text{LI}<p<\text{LS})=1-\alpha.\)
Esto significa que la probabilidad de que el límite inferior \(\text{LI}\) esté por encima de \(p\) no excede \(\alpha/2\) y que la probabilidad de que el límite superior \(\text{LS}\) esté por debajo de \(p\) no excede \(\alpha/2.\)
\[
P(\text{LI}>p)=\alpha/2
\]
\[
P(\text{LS}<p)=\alpha/2
\]
Es posible construir un intervalo con estas características si eligen \(\text{LI}\) y \(\text{LS}\) como los parámetros que darían lugar a un número de éxitos igual o más extremo que el observado, con probabilidad \(\alpha/2,\) en cada caso.
Para el caso de \(\text{LI},\) extremo significa muchos éxitos; para el caso de \(\text{LS},\) extremo significa pocos éxitos. Luego, las expresiones tendrían la siguiente forma:
\[
\text{LI}:P(X \ge x|p=\text{LI})=\alpha/2
\]
\[
\text{LS}:P(X \le x|p=\text{LS})=\alpha/2
\]
Para obtener los valores de \(\text{LI}\) y \(\text{LS}\) sería necesario realizar procesos iterativos, evaluando diferentes valores de \(p,\) hasta llegar a la probabilidad de \(\alpha/2.\) No obstante, haciendo uso de la relación existente entre las distribuciones binomial y \(F,\) es posible calcular \(\text{LI}\) y \(\text{LS}\) de manera directa, con base en las siguientes expresiones, donde, qf es la función cuantil de la distribución \(F\) (cf. tabla 3.1).
\[
\begin{align}
\text{LI}&=\frac{x}{x+(n-x+1)\text{qf}_{1-\frac{\alpha}{2}\bigl(2(n-x+1),\,2x\bigr)}}\\[1.4em]
\text{LS}&=\frac{x+1}{x+1+\frac{n-x}{\text{qf}_{1-\frac{\alpha}{2}\bigl(2(x+1),\,2(n-x)\bigr)}}}
\end{align}
\]
Un intervalo de confianza unilateral inferior del 95 % para la proporción binomial del ejemplo 4.4 se calcula así:
(185/((185 + (200 - 185 + 1) * qf(1 - (0.05), 2 * (200 - 185 + 1), 2 * 185))))[1] 0.8868616Es necesario insistir en que el epíteto exacto no informa sobre el desempeño del intervalo de confianza de Clopper-Pearson.
Los estudios realizados por Agresti y Coull (1998) y Brown, Cai y DasGupta (2001, 2002) muestran que los intervalos obtenidos mediante este método son excesivamente conservadores, por lo que desaconsejan su uso.
Usando la función binom.test{stats}, es posible obtener los resultados de la inferencia —pruebas de hipótesis e intervalos de confianza— para el parámetro \(p,\) con base en el método “exacto” de Clopper-Pearson.
binom.test(x = 185, n = 200, p = 0.9, alternative = "greater")
Exact binomial test
data: 185 and 200
number of successes = 185, number of trials = 200, p-value = 0.1431
alternative hypothesis: true probability of success is greater than 0.9
95 percent confidence interval:
0.8868616 1.0000000
sample estimates:
probability of success
0.925 Aunque en este caso se calcula un intervalo de confianza unilateral inferior, suele incluirse el 1 como límite superior por constituir una cota natural del parámetro \(p.\)
Las funciones prop.test y binom.test, que forman parte del paquete stats, permiten realizar inferencia sobre el parámetro \(p,\) mediante los métodos del score y de Clopper-Pearson, respectivamente.
No está de más insistir en la recomendación de incluir la opción correct = FALSE cuando se use la función prop.test, a fin de evitar la corrección que se aplica por defecto y que da lugar a intervalos tan conservadores como los del método Clopper-Pearson.
La función personalizada inf_p permite aplicar todos los métodos ilustrados anteriormente, realizando por defecto una prueba de dos colas, mediante el método del score (sin corrección), con una confianza del 95 %.
Para el ejemplo 4.4 se usaría el siguiente script:
source("inf_p.R")
inf_p(x = 185, n = 200, p0 = 0.9, alternative = "greater")Inferencia sobre el parámetro p de la binomial
Método Score-Wilson
Prueba de cola derecha (Ha: p > 0.9)
Proporción estimada = 0.925
Estadístico de Prueba: Zs = 1.1785
Valor p = 0.1193
Límite de confianza inferior del 95 %
[0.8884, 1]Por otra parte, la función personalizada n_p permite calcular el tamaño de muestra requerido para la estimación de \(p\) con una precisión y una confianza determinadas, siguiendo la lógica ilustrada en la sección 4.4.1.2, pero usando el método del score en lugar del método de Wald.
El siguiente script ilustra el cálculo de \(n\) usando todos los valores de la función por defecto, es decir, con una confianza del 95 % (conf = 0.95), una precisión de 0.05 (desv = 0.05) y una preestimación de 0.5 para el parámetro \(p\) (p = 0.5).
source("n_p.R")
n_p()El tamaño de muestra requerido para estimar p (para p = 0.5),
con una confianza del 95 %y una precisión de 0.05 es n = 381También es posible usar un tamaño de muestra (n) como argumento de esta función, en lugar de la precisión (desv), con lo cual se obtiene la precisión.
source("n_p.R")
n_p(n = 200)La precisión en la estimación de p (para p = 0.5),
con una confianza del 95 %y una muestra de n = 200 es 0.06863914Los intervalos de confianza simétricos, como el que se genera para \(p,\) mediante el método de Wald (cf. sección 4.4.1.1) o el de \(\mu\) (cf. sección 4.2.2) permiten expresar la definición general de precisión en términos de semiamplitud del intervalo.
En estos casos, la precisión —definida como el máximo alejamiento tolerable entre el estimador puntual y el parámetro que se está estimando— es igual a la semiamplitud del intervalo de confianza.
En intervalos asimétricos, con respecto al estimador puntual, esta relación no se mantiene:
Para ilustrarlo, consideremos un intervalo de confianza bilateral del 95 % calculado mediante el método del score para una muestra en la que \(x=93\) y \(n=100.\)
Usando inf_p o prop.test, puede verificarse que el correspondiente intervalo de confianza es:
\[
[0.8625,\,\,0.9657]
\]
La semiamplitud del intervalo es:
\[
\frac{0.9657-0.8625}{2}=0.0516
\]
El alejamiento entre el estimador puntual \((\hat{p}=0.93)\) y el límite inferior es \(|0.93-0.8625|=0.0675.\)
El alejamiento entre el estimador puntual y el límite superior es \(|0.93-0.9657|=0.0357.\)
Resulta evidente que el máximo alejamiento entre el estimador puntual y el parámetro estimado que implica el intervalo de confianza del score (\(0.0675\)) no coincide con la semiamplitud del intervalo (\(0.0516\)).
No obstante lo anterior, la idea de precisión como semiamplitud del intervalo sigue siendo más intuitiva. Si un usuario pide un intervalo con una precisión de \(0.01\), tiene en mente un intervalo con un formato similar a \([0.44,\,0.46]\), aunque, por la manera en que se construya, este intervalo pudiera estar admitiendo una diferencia mayor de \(0.01\) entre el estimador puntual y alguno de los límites del intervalo.
Para mantener esta idea intuitiva, la función n_p, aunque está basada en el intervalo del score, calcula la precisión como la semiamplitud del intervalo.
El método de Wald presenta falencias cuando el valor del parámetro está cerca de los extremos, dando lugar a intervalos de longitud cero cuando el estimador del parámetro es 0 o 1. Por mucho tiempo fue el único método presentado en los libros de texto, lo que podría explicarse por lo intuitiva que resulta su construcción y por la facilidad computacional. Actualmente existe consenso en cuanto a que este método no debe ser utilizado.
El método de Agresti y Coull, aunque se presenta como un ajuste al método de Wald, está derivado conceptualmente del método del score, por lo que, manteniendo la simplicidad del método de Wald, tiene un mejor comportamiento que este bajo un amplio rango de circunstancias.
El método “exacto” de Clopper-Pearson no es recomendable, por ser demasiado conservador. Los intervalos de confianza que se construyen a partir de este método suelen ser más amplios de lo necesario. Viene implementado en R, mediante la función binom.test.
El método score-Wilson ha sido el que ha exhibido un mejor comportamiento en estudios de simulación realizados por múltiples autores. Tiene un comportamiento bastante bueno, bajo un amplio rango de circunstancias. Por mucho tiempo se prescindió de presentarlo por lo poco intuitiva que podía resultar la construcción del intervalo de confianza. En la actualidad puede considerarse el método estándar, siendo la opción por defecto de muchos paquetes estadísticos. En R, viene implementado, mediante la función prop.test.
El hecho de usar o no usar una aproximación basada en la distribución normal es solo uno de los aspectos involucrados en los procesos inferenciales sobre el parámetro \(p.\)
El método de Wald —basado en la aproximación normal— tiene un desempeño muy pobre. Sin embargo, el método del score —que también se basa en la aproximación normal— tiene un desempeño mejor que el del método de Clopper-Pearson, que no está basado en la aproximación normal.
Incluso el método de Agresti-Coull —que, siendo un híbrido entre el método de Wald y el método del score, está igualmente basado en la aproximación normal— exhibe un mejor desempeño que el denominado método “exacto”.
Todos los métodos expuestos en esta sección están implementados en la función personalizada inf_p. Por otra parte, la función personalizada n_p permite calcular el tamaño de muestra requerido para la estimación de \(p\) con una precisión y una confianza determinadas, usando el método del score.
En las secciones anteriores se ilustró la relación entre estas dos herramientas, presentándolas como las dos caras del proceso inferencial. Se hizo notar que cada una de ellas se enfoca en aspectos particulares. Las pruebas de hipótesis evalúan la plausibilidad de un valor paramétrico de referencia, mientras que los intervalos de confianza definen una región de alta plausibilidad para el parámetro.
Las pruebas de hipótesis responden preguntas dirigidas, mientras que los intervalos de confianza ofrecen respuesta a preguntas no dirigidas sobre el valor del parámetro.
Habrá contextos en los que, por simplicidad o conveniencia, únicamente se use alguna de estas herramientas para responder las preguntas de investigación. No obstante, en muchos otros casos podrá y deberá valorarse la información complementaria que estas suministran, la cual siempre es consistente.
En la sección 4.2.2, al presentar por primera vez los intervalos de confianza en un contexto aplicado, se estableció la siguiente relación:
En el caso de pruebas de hipótesis de dos colas —que se asocian con intervalos de confianza bilaterales— esta relación es bastante intuitiva. En la sección 4.2.2 se dedujo un intervalo de confianza para la media, a partir de la correspondiente prueba de hipótesis de dos colas, y se discutió la relación entre estas dos herramientas en el contexto del ejemplo 4.2.
En la sección 4.3.2 se indicó —sin la mediación de ningún desarrollo, para no romper la continuidad del ejemplo— que las pruebas de cola izquierda se asociaban con un intervalo de confianza unilateral superior, mientras que las pruebas de cola derecha se asociaban con un intervalo de confianza unilateral inferior.
A la luz del criterio enunciado, puede resultar desconcertante el hecho de que una prueba de cola izquierda se asocie con un intervalo de confianza cuya “región de rechazo” se ubica a la derecha, mientras que una de cola derecha se asocie con un intervalo de confianza cuya “región de rechazo” se ubica a la izquierda.
Con el fin de evidenciar la validez de esta relación y aclarar los conceptos subyacentes, se presenta el desarrollo que conduce a la construcción del intervalo unilateral superior asociado con la prueba de cola izquierda del ejemplo 4.3.
Se plantea el siguiente juego de hipótesis:
\[
H_0: \sigma^2 \ge \sigma^2_0
\]
\[
H_a: \sigma^2 < \sigma^2_0
\]
El estadístico de prueba que se utiliza para contrastar este juego de hipótesis es:
\[
\chi^2_\text{c}=\frac{(n-1)S^2}{\sigma^2_0}
\]
La figura 4.4 (a) muestra la distribución probabilística del estadístico de prueba bajo la hipótesis nula, con sus correspondientes regiones de rechazo (sombreada) y aceptación (no sombreada).
El criterio de rechazo se expresa así:
Si \(\chi^2_\text{c} \le \chi^2_{1-\alpha(n-1)},\) se rechaza \(H_0\) con un nivel de significancia \(\alpha\) (cf. tabla 4.3).
Puesto que el nivel de significancia es la máxima probabilidad de cometer error tipo I, la anterior expresión puede escribirse así:
\[
\text{máx}\left(P\left(\chi^2_\text{c} \le \chi^2_{1-\alpha(n-1)}|H_0\right)\right)=\alpha
\]
Aunque, en el contexto de pruebas de una cola, existen infinitas maneras en las que puede satisfacerse la hipótesis nula (dado que el subespacio paramétrico definido por \(H_0\) está constituido por una región), la máxima probabilidad de cometer error tipo I, esto es, \(\alpha,\) surge cuando el valor del parámetro es el establecido por la igualdad, es decir, cuando \(σ^2 = \sigma_0^2\) (cuando \(σ^2 = 144\) para el ejemplo 4.3).
La figura 3.20 (a) ilustra este concepto para el ejemplo 3.2: la hipótesis nula comprende la región paramétrica \(p \le 1/6;\) el rechazo de la hipótesis nula para cualquier valor en dicha región constituye un error tipo I. No obstante, la máxima probabilidad de cometer dicho error —para cualquiera de los criterios de decisión ilustrados— se da cuando \(p = 1/6.\)
La razón por la que se exige que la hipótesis nula siempre incluya la igualdad es que solo así puede fijarse el nivel de significancia.
Con base en esta consideración, podemos escribir la anterior expresión así:
\[
P\left(\chi^2_\text{c} \le \chi^2_{1-\alpha(n-1)}|\sigma^2=\sigma^2_0\right)=\alpha
\]
Consecuentemente,
\[
P\left(\chi^2_\text{c} > \chi^2_{1-\alpha(n-1)}|\sigma^2=\sigma^2_0\right)=1-\alpha
\]
Remplazando el estadístico de prueba por la expresión usada para su cálculo, se tiene:
\[
P\left(\frac{(n-1)S^2}{\sigma^2_0} > \chi^2_{1-\alpha(n-1)}|\sigma^2=\sigma^2_0\right)=1-\alpha
\]
Se multiplican ambos miembros de la desigualdad por la razón entre el hipotético valor del parámetro y el valor crítico. Puesto que esta razón es positiva, el sentido de la desigualdad se mantiene:
\[
P\left(\frac{(n-1)S^2}{\chi^2_{1-\alpha(n-1)}} > \sigma^2_0|\sigma^2=\sigma^2_0\right)=1-\alpha
\]
Se incorpora en la ecuación la condición indicada por la hipótesis nula:
\[
P\left(\frac{(n-1)S^2}{\chi^2_{1-\alpha(n-1)}} > \sigma^2\right)=1-\alpha
\]
Para facilitar su visualización, escribimos esta expresión reordenando los miembros de la desigualdad:
\[
P \left(\sigma^2 < \frac{(n-1)S^2}{\chi^2_{1-\alpha(n-1)}}\right)=1-\alpha
\]
Puede observarse que la variable aleatoria del lado derecho de la inecuación constituye el límite superior del intervalo de confianza unilateral para \(\sigma^2,\) coincidiendo con el utilizado en el ejemplo 4.3, en el que se contrasta una prueba de cola izquierda.
Siguiendo el mismo procedimiento, sería fácil verificar que, partiendo de una prueba de cola derecha se habría llegado a un intervalo de confianza unilateral inferior. De la misma manera podría adaptarse el procedimiento ilustrado en la sección 4.2.2 para obtener intervalos de confianza unilaterales para la media: de límite superior para pruebas de cola izquierda, y de límite inferior para pruebas de cola derecha.
El anterior desarrollo, aunque muestra la validez de las asociaciones entre pruebas de una cola e intervalos unilaterales, no ofrece un anclaje intuitivo que permita mitigar el desasosiego que se genera por el hecho de que una prueba de cola izquierda se asocie con un intervalo de confianza cuya “región de rechazo” se ubica a la derecha, mientras que una de cola derecha se asocie con un intervalo de confianza cuya “región de rechazo” se ubica a la izquierda.
Esta aparente contradicción surge de un uso relajado del lenguaje, en el que se aplica una misma etiqueta a dos conceptos diferentes.
En el contexto de pruebas de hipótesis, la distribución que tendría el estadístico de prueba cuando la hipótesis nula es cierta (o más precisamente, cuando se satisface la igualdad) permite definir un par de regiones —de alta y de baja probabilidad— para las realizaciones de esta variable aleatoria. A la región de alta probabilidad se le denomina región de no rechazo (o de aceptación), mientras que a la región de baja probabilidad se le conoce como región de rechazo.
La región de rechazo siempre se ubica en las colas de la distribución: ya sea en una de ellas (pruebas de una cola) o en ambas (pruebas de dos colas). En el caso particular de pruebas de una cola, el lado en el que se ubique la región de rechazo se usa para darles un nombre genérico a tales pruebas: si la región de rechazo se ubica en la cola izquierda, se habla de una prueba de cola izquierda; si la región de rechazo se ubica en la cola derecha, se trata de una prueba de cola derecha.
En el contexto de intervalos de confianza no se parte de algún hipotético valor del parámetro, por lo que no se construye ningún estadístico de prueba, ni tampoco se define alguna región de baja probabilidad para las realizaciones del inexistente estadístico de prueba. Por tanto, los intervalos de confianza no llevan asociada una región de rechazo acorde con lo definido para pruebas de hipótesis.
Mediante los intervalos de confianza se particiona el espacio paramétrico en dos regiones: una en la que se tiene alta confianza en que esté el parámetro (al interior del intervalo) y otra en la que se tiene poca confianza de encontrar al parámetro (por fuera del intervalo). Estas regiones pueden usarse para decidir sobre hipótesis relacionadas con valores específicos del parámetro, rechazando con un nivel de significancia \(\alpha\) cualquier planteamiento que se realice con respecto a la ubicación del parámetro por fuera de un intervalo de confianza del \(100(1−\alpha)\,\%.\)
El hecho de que, tanto en pruebas de hipótesis como en intervalos de confianza aparezcan regiones que el usuario debe valorar para decidir sobre el rechazo de una hipótesis es lo que lleva a pensar erróneamente que se trata de la misma región y es lo que genera desconcierto cuando se nota que dicha región se ubica a la derecha en los intervalos asociados con pruebas de cola izquierda y viceversa.
No obstante, por lo expuesto anteriormente, se evidencia que las regiones en cuestión son diferentes. Aunque el verbo rechazar aparece en ambos contextos, el objeto sobre el cual se ejerce es radicalmente distinto. En consecuencia, debe evitarse el uso de una etiqueta común.
La región de rechazo es la región de la distribución de referencia de un juego de hipótesis en la que sería poco probable que se dieran valores del estadístico de prueba si la hipótesis nula fuera cierta.
En contraste, al usar intervalos de confianza para decidir sobre el rechazo/no rechazo de una hipótesis específica, se consideran dos regiones del espacio paramétrico: una región paramétrica de no rechazo (al interior del intervalo) y otra región paramétrica de rechazo (por fuera del intervalo).
La separación de estos conceptos —dejando clara la diferencia entre región de rechazo y región paramétrica de rechazo— resuelve el conflicto señalado.
Las pruebas de cola izquierda que, tal y como su nombre lo indica, tienen su región de rechazo en la cola izquierda de la distribución de referencia, se asocian con intervalos unilaterales cuya región paramétrica de rechazo está a la derecha.
En contraste, las pruebas de cola derecha que, acorde con su nombre, tienen su región de rechazo en la cola derecha de la distribución, se asocian con intervalos unilaterales cuya región paramétrica de rechazo está a la izquierda.
Si así fuera, sería necesario reconocer que en ningún caso las poblaciones de campo son normales.↩︎
Las alternativas consisten en usar alguna transformación (cf. sección 6.5) o utilizar una técnica que no exija normalidad (cf. capítulo 9).↩︎
La normal estándar o la \(t.\)↩︎
Es posible disminuir simultáneamente ambos errores, aumentando el tamaño de la muestra.↩︎
Que equivale al de una distribución \(t\) con infinitos grados de libertad.↩︎
Esta forma de expresar el error tipo I, que es equivalente a “rechazar la hipótesis nula, siendo cierta”, facilita el proceso de hacer coincidir el error más grave con el error tipo I.↩︎
Para revisar la lista de funciones, se usa la instrucción library(help = "stats").↩︎
Algunos autores lo denominan \(\pi.\)↩︎
El potencial comprador está dispuesto a asumir un riesgo máximo del 5 % de pagar un sobrecosto innecesario.↩︎
Para denotar una distribución aproximada se usa la virgulilla con un punto encima, lo cual se lee: “se distribuye aproximadamente”.↩︎
La varianza de \(\hat{p}\) es \(\frac{pq}{n};\) su estimador puntual es \(\frac{\hat{p}\widehat{q}}{n}.\)↩︎
La normal estándar es la distribución que seguiría el estadístico de prueba si la hipótesis nula fuera verdadera.↩︎