3 INFERENCIA ESTADÍSTICA
La inferencia constituye el eje central de las técnicas estadísticas aplicadas a la investigación científica. Son los métodos inferenciales los que hacen posible generalizar la información obtenida a partir de una o más muestras hacia las correspondientes poblaciones de referencia.
Aunque la inferencia estadística se sustenta en constructos matemáticos, estos no constituyen un fin en sí mismos. Su papel es modelar probabilísticamente los datos obtenidos en campo o en el laboratorio y la manera en que dichos datos se vinculan —a través del modelo— con la población de interés, que es, en última instancia, el objetivo central de cualquier investigación aplicada.
En este sentido, y sin entrar aún en los mecanismos internos que la gobiernan, la inferencia estadística puede entenderse como el conjunto de herramientas que permiten extender los hallazgos muestrales a la población de referencia, bajo un control explícito de la incertidumbre asociada a dicho proceso.
Dado que la inferencia estadística está basada en conceptos probabilísticos, se hace necesario realizar algunas elaboraciones previas al respecto. Aunque se trata de una temática amplia, las elaboraciones que aquí se desarrollan se concentran exclusivamente en aquellos aspectos que sirven de fundamento a los métodos inferenciales, dejando deliberadamente de lado otros aspectos que pueden consultarse en textos especializados en probabilidad, como el de Blanco (2010).
Como antesala a la introducción formal de la probabilidad, se presentan algunos elementos básicos que sustentan las construcciones probabilísticas empleadas en la inferencia estadística. Una vez establecido este marco, el capítulo aborda algunas distribuciones de probabilidad frecuentemente utilizadas como base de los métodos inferenciales, para culminar con la presentación de las dos formas fundamentales de la inferencia estadística: la estimación y las pruebas de hipótesis.
3.1 Experimento aleatorio
Experimento 1: Lanzar un dado y anotar el resultado.
Experimento 2: Extraer una carta de la baraja y registrar el palo (símbolo).
Experimento 3: Revisar el envés de una hoja y anotar el número de larvas de un insecto.
Experimento 4: Inocular esporas de un hongo en PDA, usando una caja de Petri de 9 cm de diámetro, y evaluar su crecimiento al sexto día.
Todas las descripciones anteriores corresponden a experimentos aleatorios, por cuanto los resultados que estos generan no pueden determinarse antes de haber ejecutado el experimento.
Los dos primeros ejemplos siguen la línea clásica, en la que la probabilidad suele estar asociada con los juegos de azar. Esto se explica por el hecho de que fueron justamente los juegos de azar los que llevaron a grandes pensadores franceses del siglo xvii como Blaise Pascal y Pierre de Fermat a sentar las bases de la teoría matemática de la probabilidad.
Aunque dicha teoría, alimentada con los desarrollos posteriores, sigue vigente y aún se utiliza para resolver no solo problemas relacionados con juegos de azar, sino también otros fenómenos con igual comportamiento probabilístico, son los dos últimos ejemplos los que mejor reflejan los experimentos que usualmente conciernen a la investigación aplicada.
3.2 Espacio muestral
Al espacio muestral se le denota con la letra \(S\) (sample space).
Considérese el experimento aleatorio consistente en lanzar un dado y registrar el resultado. El correspondiente espacio muestral podría quedar definido de la siguiente manera:
\[ S_{1\text{A}}=\{⚀, ⚁, ⚂, ⚃, ⚄, ⚅\} \]
Este sería el espacio muestral para el más común de los dados, el cual consta de seis caras marcadas con uno, dos, tres, cuatro, cinco o seis puntos. No obstante, existen dados que se apartan de dicho estándar, pudiendo tener cualquier marca en sus caras e incluso un número de caras diferente de seis.
El espacio muestral para un hipotético dado de ocho lados marcado con las primeras ocho letras del alfabeto griego sería el siguiente:
\[ S_{1\text{B}}=\{\alpha, \beta, \gamma, \delta, \varepsilon, \zeta, \eta, \theta\} \]
Al lanzamiento de un dado de seis caras marcado con números del 1 al 6 le correspondería el siguiente espacio muestral:
\[ S_{1\text{C}}=\{1, 2, 3, 4, 5, 6\} \]
Para el experimento que consiste en extraer una carta de la baraja y registrar el palo, el espacio muestral dependerá del tipo de baraja. Suponiendo que se trate de la baraja inglesa, se tendría un espacio muestral conformado por los elementos: pica, corazón, trébol y diamante, ya sea representados a través de sus nombres o de sus símbolos.
\[ S_{2}=\{\spadesuit, \, \large \color{red}♥ \normalsize \color{black} ,\, \clubsuit, \, \large \color{red} ♦\color{black}\normalsize\} \]
El espacio muestral para el experimento aleatorio consistente en revisar el envés de una hoja y anotar el número de larvas de un insecto es:
\[ S_{3}=\{1, 2, 3,...\} \]
Para el experimento consistente en inocular esporas de un hongo en PDA, usando una caja de Petri de 9 cm de diámetro, se tiene el siguiente espacio muestral:
\[ S_{4}=\{x\,|\,0\le x \le9\} \]
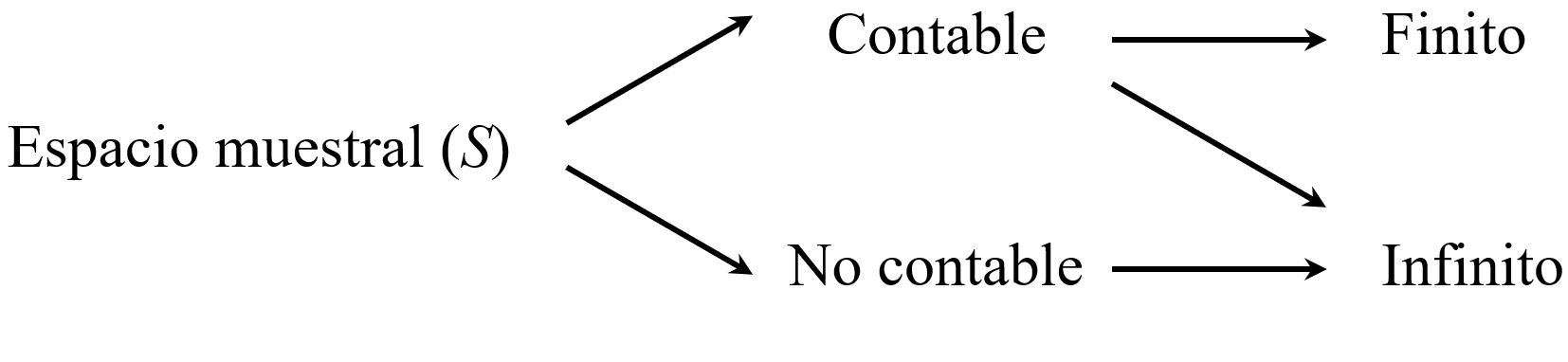
Tal y como se observa en los anteriores ejemplos, los espacios muestrales pueden ser de diferente naturaleza: los hay contables y no contables y también los hay finitos e infinitos.
Los espacios muestrales \(S_{1\text{A}},\) \(S_{1\text{B}},\) \(S_{1\text{C}},\) \(S_{2}\) y \(S_3\) son contables, puesto que es posible enumerar cada uno de sus elementos. El espacio muestral \(S_4\) es no contable; ante la imposibilidad de enumerar todos los elementos, estos se definen mediante una regla. La definición del espacio muestral \(S_4\) se lee como el conjunto de todos los valores de \(x,\) tales que \(x\) sea mayor o igual que cero y menor o igual que 9.
Por otra parte, los primeros cuatro espacios muestrales son finitos: \(S_{1\text{A}}\) tiene \(6\) elementos; \(S_{1\text{B}}, 8;\) \(S_{1\text{C}}, 6\) y \(S_2, 4.\) Los dos últimos espacios muestrales son infinitos.
Conviene detenerse en el espacio muestral \(S_3,\) el cual, aun siendo contable, es infinito. En este caso, los posibles resultados del experimento pueden enumerarse uno a uno, pero no existe un valor máximo que —desde el punto de vista teórico— limite el número de larvas que podrían observarse.
Aunque en la práctica una hoja no pueda albergar un número arbitrariamente grande de larvas, esta restricción es de naturaleza empírica y no define el espacio muestral. No es posible establecer un número \(M\) tal que resulte imposible observar más de \(M\) larvas en todos los casos. En ausencia de un límite superior bien definido, el conjunto de resultados posibles debe considerarse infinito. En situaciones como esta, el espacio muestral se clasifica como contable e infinito.
Por su parte, \(S_4\) ejemplifica un espacio muestral no contable, el cual no consta de una serie de elementos individualizables, sino de todos los posibles valores en un intervalo o segmento de línea. Todos los espacios muestrales no contables son infinitos.
En resumen…
Los espacios muestrales pueden ser contables o no contables. Los espacios muestrales contables pueden ser finitos o infinitos. Todos los espacios muestrales no contables son infinitos (figura 3.1).
3.3 Evento
Para el experimento aleatorio consistente en lanzar un dado de seis caras marcado con números del 1 al 6 y registrar el resultado, cuyo espacio muestral es \(S_{1\text{C}},\) puede definirse, por ejemplo, el evento de obtener un número impar, el cual tendría los siguientes elementos.
\[ E_{1\text{C}.1}=\{1, 3, 5\} \]
A partir del mismo espacio muestral, podría definirse el evento de obtener un número mayor o igual que 3, el cual estaría conformado por los siguientes elementos.
\[ E_{1\text{C}.2}=\{3, 4, 5, 6\} \]
En el contexto del experimento consistente en registrar el crecimiento de un hongo en una caja de Petri de 9 cm de diámetro, cuyo espacio muestral es \(S_4,\) un investigador podría estar interesado en las cepas que presenten un crecimiento superior a 5 cm, durante el periodo de observación. Este evento puede definirse así:
\[ E_{4}=\{x\,|\,5 < x \le9\} \]
Tip 3.1: También es válido…
No es necesario que los eventos sean subconjuntos propios no vacíos del espacio muestral. Un subconjunto vacío o todo el espacio muestral también constituyen eventos válidos.
Si para el experimento con espacio muestral \(S_{1\text{C}}\) se define el evento de obtener un número mayor o igual que 7, el correspondiente conjunto sería vacío. Si, a partir del mismo espacio muestral, se define el evento de obtener un número mayor o igual que 1, el evento queda constituido por todos los elementos del espacio muestral.
Asimismo, es posible definir eventos de tal manera que cada uno de los puntos de un espacio muestral contable constituya un evento.
Nomenclatura
Para evitar confusiones, aclaremos lo concerniente a la nomenclatura:
\(S\) denota el espacio muestral genérico de un experimento.
\(S_1, S_2,..., S_\text{k}\) se usan en este texto para hacer referencia a los espacios muestrales de experimentos particulares: el espacio muestral del experimento 1, \(...,\) el espacio muestral del experimento \(\text{k}.\)
\(S_{1\text{A}},\) \(S_{1\text{B}}\) y \(S_{1\text{C}}\) se usan en este texto para hacer referencia a los espacios muestrales asociados con las diferentes variantes del experimento del dado.
\(E\) denota un evento, en términos genéricos.
\(E_1, E_2,..., E_\text{k}\) se usan en este texto para referirse a eventos particulares dentro de experimentos particulares: un evento particular correspondiente al experimento 1, \(...,\) un evento particular correspondiente al experimento \(\text{k}.\)
\(E_{1\text{C}.1},..., E_{1\text{C}.2}\) se usan cuando se definen diferentes eventos dentro de un experimento particular: el primer subíndice o conjunto de subíndices antes del punto se refiere(n) al experimento; el subíndice después del punto especifica el evento. Así, \(E_{1\text{C}.1}\) se leería como el primer evento del experimento \(1\text{C}.\)
No se usa ninguna nomenclatura especial para referirse a un experimento; simplemente se le denomina experimento y se especifica mediante sus características.
3.4 Probabilidad
La probabilidad puede conceptualizarse como el nivel de certidumbre de que ocurra un evento. Este nivel de certidumbre en muchas ocasiones surge de consideraciones subjetivas y, cuando se usa en la cotidianidad, suele expresarse con un valor porcentual, siendo 0 % la probabilidad de un evento imposible y 100 % la de un evento seguro.
Aunque este acercamiento al concepto de probabilidad pueda bastar para expresar nuestras creencias, en la práctica investigativa se requieren definiciones más formales. A continuación, se presentan dos definiciones, que corresponden a diferentes momentos históricos. La primera de ellas —denominada definición clásica— surge tempranamente, asociada con los comienzos de la teoría probabilística y los juegos de azar. La segunda definición aparece posteriormente, en un marco más amplio, que es el que permite estructurar los métodos de la estadística inferencial.
3.4.1 Probabilidad: Definición clásica
Interesante, pero…
Esta definición tiene varias debilidades; la primera de ellas radica en su circularidad, pues se basa en el concepto que pretende definir: plausibilidad no es más que una forma alternativa de expresar la probabilidad.
Adicionalmente, esta definición solo aplicaría en experimentos con espacios muestrales contables y finitos, constituidos por elementos que tengan exactamente la misma probabilidad.
No obstante las debilidades señaladas, esta definición se mantiene vigente por su formulación intuitiva, que no exige ningún nivel de abstracción, y porque resulta adecuada para resolver preguntas en ámbitos particulares, como el de los juegos de azar.
Probabilidades y frecuencias
Cuando se usa la definición clásica para el cálculo de probabilidades, estas suelen interpretarse en términos frecuentistas, esto es, como la forma límite de la frecuencia relativa del evento en cuestión.
Para el presente ejemplo, se esperaría que, si el experimento se realiza un gran número de veces, la frecuencia relativa del evento planteado sea 0.1667, esto es, que el evento se satisfaga en el 16.67 % de los lanzamientos.
Probabilidades y porcentajes
En lugar de los porcentajes que suelen usarse en la cotidianidad para referirse a la certidumbre de un evento, las probabilidades toman valores en el intervalo \([0, 1],\) siendo esta la manera formal de expresarlas.
Más juegos de azar: el Baloto
Considérese ahora el Baloto, un juego de azar que luego de 16 años cambió el conjunto de condiciones por las que se regía.
Bajo las condiciones iniciales, que estuvieron vigentes hasta el sorteo del 19 de abril de 2017, se ganaba el premio mayor si se acertaban 6 números determinados, elegidos de un conjunto de 45. El tarjetón de apuestas presentaba casillas con los números del 1 al 45, tal y como se muestra en la figura 3.2 (a). El jugador elegía 6 números, como se indica en en la figura 3.2 (b).


Para ganar no se exigía ningún orden entre las cifras que conformaban el conjunto de números por el cual se apostaba. En este caso, si las balotas elegidas el día del sorteo hubieran estado marcadas con los números \(\{2, 6, 12, 29, 32 \text{ y } 43\}\) —sin importar el orden en que hubieran sido extraídas—, el jugador que hubiera llenado el formulario como se muestra en panel de la derecha habría ganado el premio mayor.
Puesto que cualquiera de los posibles conjuntos de 6 números es equiprobable, puede usarse la definición clásica para calcular la probabilidad que habría tenido un jugador de hacerse millonario con el Baloto.
\[
P(\text{ganar})=\frac{\text{Número de conjuntos ganadores}}{\text{Número total de posibles conjuntos}}
\]
El valor del numerador es 1, puesto que, para este hipotético ejemplo, existía un único conjunto ganador: \(\{2, 6, 12, 29, 32, 43\}.\) En el denominador va el número total de posibles conjuntos de seis números: \(\{1, 2, 3, 4, 5, 6\},\) \(\{1, 2, 3, 4, 5, 7\},\) \(\ldotp\ldotp\ldotp,\) \(\{1, 2, 3, 4, 5, 45\},\) \(\ldotp\ldotp\ldotp,\) \(\{40, 41, 42, 43, 44, 45\}.\)
Resulta evidente que el número de posibles grupos de seis números es muy grande. Sería totalmente impráctico tratar de presentarlos en su totalidad para proceder a contarlos. Por fortuna existen técnicas de conteo de puntos muestrales que permiten calcular el número de tales puntos, sin tener que presentarlos explícitamente. Para su estudio puede revisarse el texto de Walpole, Myers, Myers y Ye (2012).
Puesto que, en este caso, resulta indiferente el orden interno de los elementos que conforman los conjuntos, la pregunta que debe resolverse es cuántos conjuntos de 6 elementos pueden construirse a partir de 45 elementos, sin importar el orden interno de los elementos en cada grupo.
En términos de las técnicas de conteo, a este planteamiento se le denomina una combinación y se expresa así: ¿cuántas son las combinaciones de 45 elementos en grupos de 6?
La correspondiente expresión se nota así \({{45}\choose{6}}\) y se resuelve de la siguiente manera:
\[
\begin{align}
{{45}\choose{6}} &= \frac{45!}{6!(45-6)!}\\[1.4em]
&= \frac{45\times44\times43\times42\times41\times40\times39!}{6!\times39!}\\[1.4em]
&= \frac{45\times44\times43\times42\times41\times40}{6!}\\[1.4em]
&= 8\,145\,060
\end{align}
\]
Conocido el denominador y sabiendo que había un único conjunto ganador, puede calcularse la probabilidad que existía de ganar el premio mayor del Baloto, así:
\[ P(\text{ganar})=\frac{1}{8\,145\,060}=0.000000123 \]
A partir del sorteo del 22 de abril de 2017 el juego evolucionó. Acorde con sus directivas: “el nuevo Baloto permitirá que los acumulados sean mayores”.
Ahora el tarjetón está dividido en dos sectores: uno superior con números del 1 al 43 y uno inferior con números de 1 a 16, tal y como se muestra en el panel de la izquierda. El jugador debe elegir 5 números del sector superior y un número del sector inferior, como se muestra en el panel de la derecha.


Si el día del sorteo, las 5 balotas iniciales estuvieran marcadas con los números \(\{1, 3, 16, 19\text{ y } 43\}\) —sin importar el orden de extracción— y la denominada súper balota del sector inferior estuviera marcada con el número \(11,\) el jugador que hubiera llenado el formulario como se muestra en panel de la derecha ganaría el premio mayor.
Para calcular la probabilidad en cuestión deben obtenerse las probabilidades de acertar en el sector superior y en el sector inferior. La probabilidad de acertar en el sector superior es 1 dividido entre el número de combinaciones de 43 números, tomados en grupos de 5, esto es, \(1/962\,598.\) Por otra parte, la probabilidad de acertar en el sector inferior es \(1/16.\)
Y, dado que el acierto del sector superior es un evento independiente del acierto del sector inferior, la probabilidad de que ambos eventos se satisfagan simultáneamente se obtiene como el producto de las probabilidades de cada evento.
Luego, la probabilidad de ganar el premio mayor del Baloto con las nuevas reglas es:
\[
P(\text{ganar})=\frac{1}{962\,598}\times\frac{1}{16}=\frac{1}{15\,401\,568}=0.0000000649
\]
El denominador que aparece en el cálculo de la anterior probabilidad corresponde al número de posibles combinaciones en las que se consideran de manera integrada los conjuntos de 5 números que pueden obtenerse a partir de 43 y los conjuntos de 1 número a partir de 16. Como puede observarse las posibles combinaciones son casi el doble de las que se tenían con las reglas anteriores y, en consecuencia, la probabilidad de ganar el premio mayor es casi la mitad de la que había con las anteriores reglas…
¡Bien dicen las directivas que el nuevo juego permite que los acumulados sean mayores!
3.4.2 Probabilidad: Definición axiomática
Esta definición, formulada por el matemático ruso Andréi Kolmogórov en 1933, además de estar libre de las debilidades anotadas para la definición clásica, cuenta con la solidez suficiente para fundamentar todos los desarrollos basados en probabilidades, incluyendo, desde luego, la inferencia estadística.
Tal y como su nombre lo indica, esta definición se basa en la verificación de una serie de axiomas o postulados que deben satisfacerse para tener una función de probabilidad.
El primer axioma establece que ningún evento tiene probabilidad negativa, por lo que se le denomina axioma de no negatividad. El símbolo \(\subseteq\) indica que \(E\) puede ser cualquier subconjunto de \(S;\) no necesariamente un subconjunto propio, es decir que \(E\) puede ser un evento cualquiera, acorde con la definición presentada anteriormente (cf. tip 3.1).
El segundo axioma establece que la probabilidad del espacio muestral es 1, por lo que se le denomina axioma de normalización.
Como corolario de los axiomas 1 y 2, se desprende que la probabilidad de cualquier evento es un número real en el intervalo \([0,\,1]\).
El tercer axioma se refiere a eventos mutuamente excluyentes, es decir, a eventos que no pueden satisfacerse de manera simultánea.
Este axioma establece que la probabilidad de cualquier conjunto de eventos mutuamente excluyentes se calcula a partir de la suma de las probabilidades de tales eventos. Por tal razón se le denomina axioma de aditividad.
3.5 Variable aleatoria
¡No se confunda!
Las variables aleatorias suelen representarse con letras mayúsculas. A cada uno de los posibles valores, resultados o realizaciones de la variable aleatoria se le denota con la correspondiente letra minúscula.
Así, si la variable aleatoria está representada por \(X,\) sus posibles valores se representan por \(x.\)
El conjunto de todos los posibles valores \(x\) que puede tomar una variable aleatoria \(X\) constituye su rango o recorrido. Dicho conjunto se denota \(\mathcal{X}.\)
Sin importar que un espacio muestral pueda estar conformado por elementos no numéricos, tal y como lo ilustran \(S_{1\text{A}},\) \(S_{1\text{B}}\) y \(S_2,\) las variables aleatorias mapean tales elementos en el espacio de los reales.
Consecuentemente, las variables aleatorias usadas en inferencia estadística siempre son numéricas. Así, por ejemplo, el recorrido de la variable aleatoria \(X\) que contabiliza el número de puntos de cada uno de los elementos del espacio muestral \(S_{1\text{A}}\) es \(\mathcal{X}=\{1, 2, 3, 4, 5, 6\}.\) A los elementos del conjunto \(\mathcal{X}\) se les denota \(x.\)
¡No es lo mismo…!
Contrario a lo que el nombre podría sugerir, las variables aleatorias no son las que registra el investigador en campo o en el laboratorio; son conceptos matemáticos (funciones) que permiten modelar probabilísticamente el comportamiento de aquellas.
Ejemplo 3.1
Considérese a continuación un experimento aleatorio consistente en lanzar 3 monedas. Obviando la gran diversidad de monedas existentes y las marcas que estas tengan, los dos lados de la moneda pueden denominarse genéricamente cara y sello. La figura 3.4 representa la relación entre espacio muestral, variable aleatoria y probabilidad.
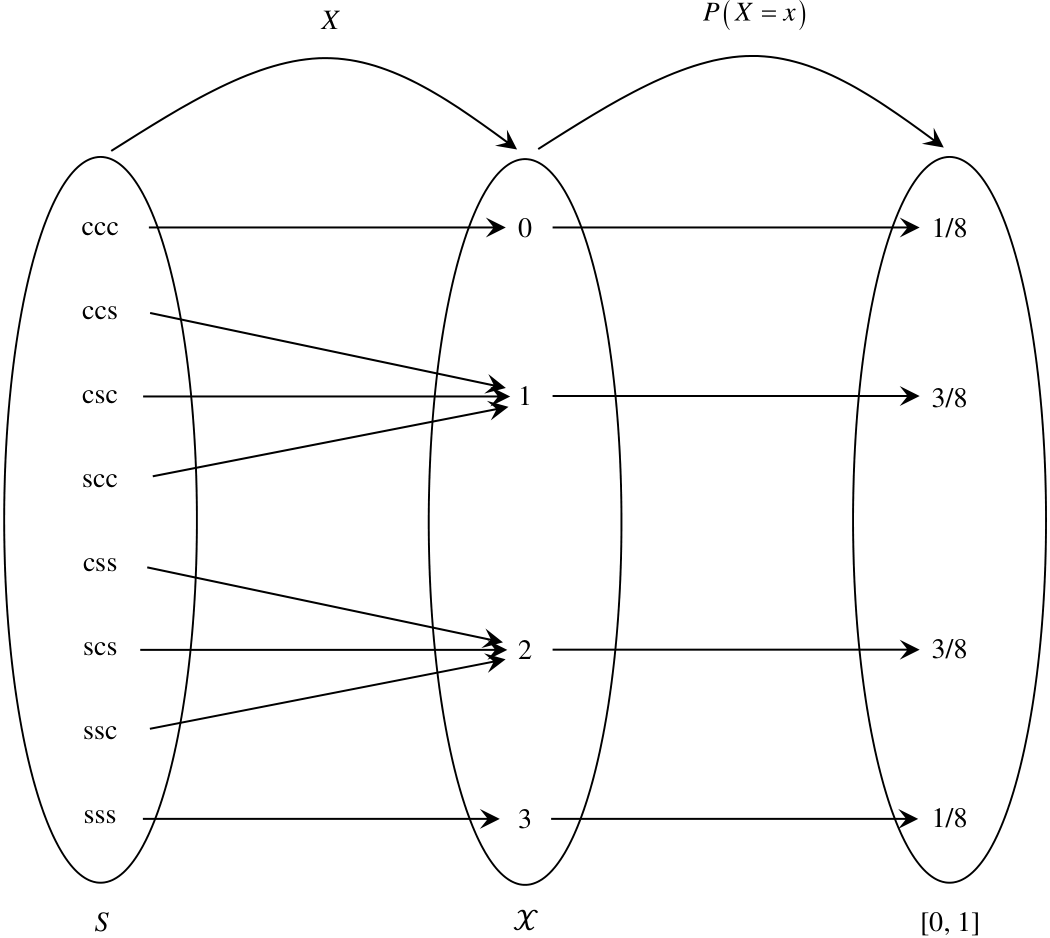
El conjunto de la izquierda es el espacio muestral \(S,\) el cual contiene todos los posibles resultados del experimento, expresados en términos de caras \((\text{c})\) y sellos \((\text{s}).\) Obsérvese que el espacio muestral no tiene que estar conformado por valores numéricos.
Si se supone que las monedas están hechas de un material homogéneo, que han sido fabricadas mediante un proceso estándar, que no han sufrido deformaciones y que las marcas en cada uno de sus lados (la cara y el sello) no generan desbalances significativos, puede considerarse que los eventos definidos por cada uno de los diferentes elementos del espacio muestral son equiprobables. Consecuentemente —por definición clásica— la probabilidad de cada punto muestral es 1/8.
Si se define \(X\) como la variable aleatoria que contabiliza el número de sellos, esta variable aleatoria es una función con dominio en \(S\) y con rango en el subconjunto \(\mathcal{X}= \{0, 1, 2, 3\}\) de los reales. La probabilidad de que la variable aleatoria \(X\) tome determinado valor en su rango \(\mathcal{X},\) que se denota como \(P(X = x),\) se obtiene a partir de las probabilidades de los correspondientes puntos muestrales.
Así, por ejemplo, la probabilidad de que no aparezca ningún sello, \(P(X = 0),\) corresponde a la probabilidad del evento constituido por el punto muestral \(\text{ccc},\) la cual es 1/8. Análogamente, \(P(X = 3) = P(\{\text{sss}\})=1/8.\)
Por otra parte, \(P(X = 1) = P(\{\text{ccs}\}\cup\{\text{csc}\}\cup\{\text{scc}\}),\) que por el tercer axioma de probabilidad es \(P(\{\text{ccs}\}) + P(\{\text{csc}\}) + P(\{\text{scc}\}) = 3/8.\) Análogamente, \(P(X = 2) =3/8.\)
Las variables aleatorias son el vínculo
Las variables aleatorias constituyen un puente entre el espacio muestral y las probabilidades.
Las funciones de probabilidad —acorde con la definición axiomática— toman los eventos, que son subconjuntos del espacio muestral, como punto de partida. La variable aleatoria, como función que le asigna un número real a los resultados del espacio muestral, determina la forma en la que ciertos subconjuntos del espacio muestral (eventos) se describen en términos numéricos, permitiendo asociarles probabilidades.
Las siguientes relaciones ilustran lo indicado con base en el presente ejemplo:
\[
\begin{align}
P(\text{cero sellos}) &= P(X = 0) = 1/8\\[0.7em]
P(\text{un sello}) &= P(X = 1) = 3/8\\[0.7em]
P(\text{dos sellos}) &= P(X = 2) = 3/8\\[0.7em]
P(\text{tres sellos}) &= P(X = 3) = 1/8
\end{align}
\]
Aunque inicialmente resulta ilustrativo calcular la probabilidad de que una variable aleatoria tome un valor determinado, a través del cálculo de las probabilidades de los correspondientes eventos, en la práctica las probabilidades se calculan de manera directa mediante una función \(f (x),\) que tiene por dominio todos los posibles valores de la variable aleatoria, y una probabilidad entre 0 y 1 por rango.
\[ f(x):\mathcal{X}\rightarrow[0, 1] \]
¿¡Dominio o rango!?
Obsérvese que \(\mathcal{X}\) —el conjunto de todos los posibles valores de la variable aleatoria \(X\)— es el rango o recorrido de la variable aleatoria como función, pero es el dominio o soporte de \(f(x).\)
En las técnicas aplicadas de la estadística inferencial, las variables aleatorias adquieren un rol central, mientras que los espacios muestrales y sus eventos pasan a segundo plano. En la práctica, son las variables aleatorias las que siempre se asocian con el cálculo de probabilidades y con su correspondiente interpretación.
Dualidad indisoluble
Cada variable aleatoria se encuentra asociada con una función \(f(x)\) que define su comportamiento probabilístico. La relación entre \(X\) y \(f(x)\) es tan estrecha que suele hablarse indistintamente de las propiedades de \(X\) o de \(f(x).\)
¿Las variables aleatorias pueden conceptualizarse en términos de naturaleza del espacio muestral?
En la mayoría de ejemplos prácticos, sí.
Las variables aleatorias discretas suelen tener como dominio espacios muestrales contables.
Las variables aleatorias continuas tienen como dominio espacios muestrales no contables.
Es posible, sin embargo, elaborar contraejemplos —aunque sean un tanto artificiales— que hacen inviable definir la naturaleza de las variables aleatorias a partir de la de los espacios muestrales que les sirven como dominio.
No obstante, si le resulta más intuitivo pensar en la naturaleza de las variables aleatorias con base en el espacio muestral que actúa como dominio, no se preocupe: su intuición no lo engaña.
3.6 Distribuciones de probabilidad discretas
Las variables cuyo rango es un conjunto contable de valores reales se denominan variables aleatorias discretas. La función que define el comportamiento probabilístico de tales variables se denomina función masa de probabilidad.
Algunas funciones masa de probabilidad sencillas pueden expresarse en forma tabular, como se muestra a continuación para el experimento consistente en lanzar tres monedas y contabilizar el número de sellos ejemplo 3.1.
| \(x\) | 0 | 1 | 2 | 3 |
| \(P(X=x)=f(x)\) | 1/8 | 3/8 | 3/8 | 1/8 |
Aunque existen infinitas funciones que satisfacen las condiciones descritas anteriormente —siendo, por tanto, funciones de probabilidad—, solo unas cuantas son de particular interés por su aptitud para la modelación de fenómenos naturales y, por ende, para la inferencia estadística aplicada. A continuación, se presentan las distribuciones de probabilidad discretas más utilizadas para dicho fin.
3.6.1 Distribución Bernoulli
La evaluación de cada una de las variables que se describen a continuación constituye un experimento Bernoulli.
Sexo: {macho, hembra}
Estado sanitario: {sano, enfermo}
Estado vital: {vivo, muerto}
Germinación: {germina, no germina}
Mutación genética: {presente, ausente}
Estado de una vaca: {llena, vacía}
Resultado de un examen: {aprobado (resultado ≥ 3.0), reprobado (resultado < 3.0)}
Peso de una semilla: {pesada (peso ≥ 5 g), liviana (peso < 5 g)}
¡Todas las respuestas son dicotomizables!
Tal y como se ilustra en los dos últimos ejemplos, siempre es posible dicotomizar (particionar el espacio muestral en dos) los resultados de un experimento aleatorio, sin importar que en principio este genere una respuesta con más de dos categorías o incluso una respuesta continua.
Éxito y fracaso
El espacio muestral de todo experimento Bernoulli está conformado por dos puntos, los cuales se definen genéricamente como éxito y fracaso.
No se ponga trascedental
Las etiquetas éxito y fracaso están desprovistas de cualquier connotación ética o sicológica; su uso tiene que ver exclusivamente con la forma en que se haya descrito el evento.
Así, por ejemplo, si en una prueba de viabilidad aplicada a una semilla, se define el evento de obtener una semilla no viable, tal resultado tendrá la etiqueta de éxito, mientras que el resultado complementario (viable) será el fracaso.
Es numérica
Sin importar si los elementos del espacio muestral son numéricos o no, la variable aleatoria Bernoulli —al igual que todas las variables aleatorias— siempre toma valores numéricos.
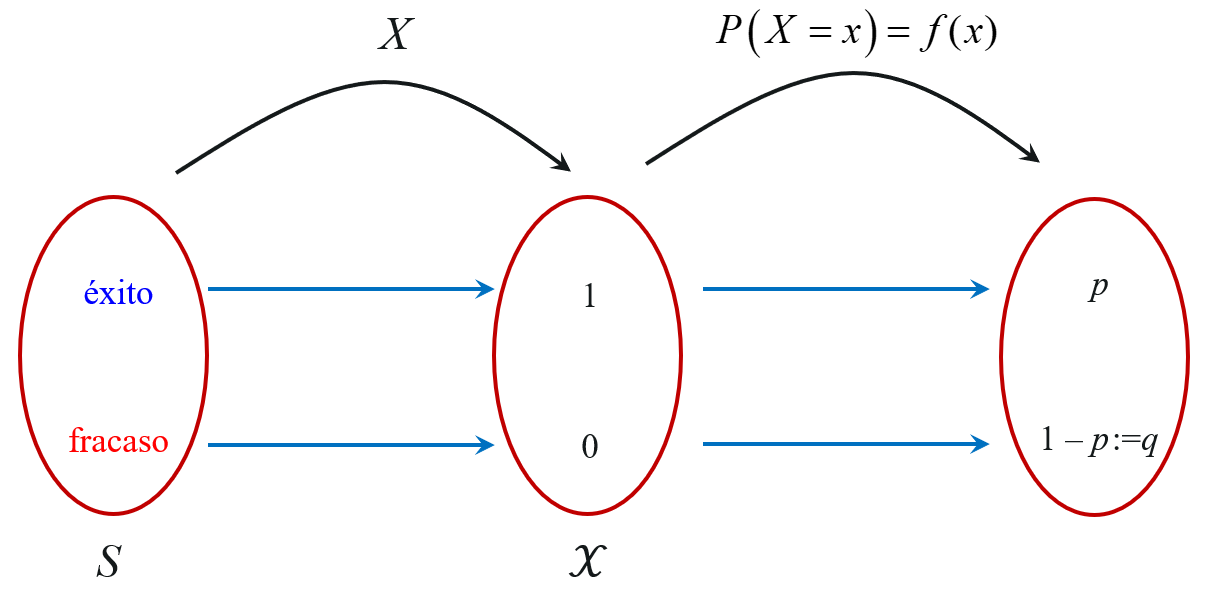
La función masa de probabilidad de una variable aleatoria Bernoulli puede expresarse en forma tabular así:
| \(x\) | 0 | 1 |
| \(P(X=x)=f(x)\) | \(q\) | \(p\) |
Aunque la forma tabular podría bastar para definir la presente distribución, esta modalidad de expresión puede resultar poco práctica, insuficiente o incluso imposible de usar para la mayoría de las demás distribuciones.
En consecuencia, las funciones de probabilidad se expresan mediante una forma funcional, que recoge las particularidades de la tabla (en caso de existir una), tal y como la que se muestra a continuación para la función masa de probabilidad de una variable aleatoria Bernoulli.
\[
f(x)=p^xq^{1-x},\quad x=0, 1
\tag{3.1}\]
La probabilidad de que la variable aleatoria \(X\) tome un valor particular se obtiene evaluando la función masa de probabilidad en dicho valor:
\[
\begin{align}
P(X=0)&=f(0)=p^0q^{1-0}=q\\[0.7em]
P(X=1)&=f(1)=p^1q^{1-1}=p
\end{align}
\]
Se verifica que \(f(x)\ge0 \:\forall\: x\). Asimismo, puede corroborarse que la suma de probabilidades sobre el soporte de \(f(x)\) es 1:
\[
\sum\limits_{\mathcal{X}}f(x)=f(0)+f(1)=q+p=(1-p)+p=1
\]
Para indicar que \(X\) es una variable aleatoria que registra el resultado de un experimento Bernoulli y que, por tanto, su comportamiento probabilístico puede condensarse en la expresión 3.1, se utiliza la siguiente notación:
\[
X \thicksim \text{Bernoulli}(p)
\]
La expresión anterior se lee así: “\(X\) se distribuye Bernoulli con parámetro \(p\)”, o así: “\(X\) sigue una distribución Bernoulli con parámetro \(p\)”, o así: “\(X\) es Bernoulli con parámetro \(p\)”.
Es similar…
De manera análoga a como las estadísticas caracterizan las muestras (cf. sección 2.1), las variables aleatorias con sus correspondientes distribuciones probabilísticas están caracterizadas por uno o más parámetros1.
La distribución Bernoulli tiene un único parámetro: \(p\). Puesto que el parámetro \(p\) pude tomar infinitos valores en el intervalo \([0,\,1]\), existen infinitas distribuciones Bernoulli. Luego, cuando se menciona una distribución probabilística dada sin especificar el valor de su(s) parámetro(s), se hace referencia a uno cualquiera de los miembros de dicha familia.
3.6.2 Distribución binomial
Un experimento binomial surge de la realización independiente de \(n\) experimentos Bernoulli.
Si cualquiera de los experimentos descritos en la sección 3.6.1 se realiza independientemente \(n\) veces, se tiene un experimento binomial. Así, por ejemplo, si en lugar de realizar la prueba de germinación sobre una única semilla, se realizan pruebas independientes sobre 100 semillas, se tiene un experimento binomial con \(n\) = 100.
La independencia entre los diferentes experimentos Bernoulli que conforman el experimento binomial implica que ninguno de los resultados de un experimento Bernoulli particular se vea afectado por el resultado de cualquier otro de los experimentos Bernoulli. En tal sentido la probabilidad de un resultado en cualquiera de los experimentos parciales depende únicamente del parámetro \(p,\) sin que las realizaciones obtenidas en otros experimentos alteren dicha probabilidad.
¡Préstele atención a la independencia!
La independencia es un aspecto que merece particular atención por parte del investigador, pues no siempre se ejecutan todas las acciones necesarias para propiciarla.
Si en el ensayo de germinación al que se hace referencia, las 100 semillas están en contacto entre sí, en un recipiente común, con un sustrato común y sometidas a un protocolo común, difícilmente podrían considerarse los resultados obtenidos como independientes entre sí.
Aunque ajeno al contexto investigativo, el siguiente ejemplo permite ilustrar el concepto de ensayos independientes.
¿Con remplazo o sin remplazo?
En la práctica investigativa los experimentos binomiales suelen realizarse sobre poblaciones infinitas o cuasi infinitas, por lo que el investigador no tendrá que preocuparse por violar la independencia entre ensayos al estar realizando experimentos Bernoulli sin remplazo.
Sin embargo, sí deberá concentrarse en evitar que la respuesta de una unidad experimental esté ligada a la respuesta de otras unidades.
A fin de ilustrar la construcción de la función masa de probabilidad binomial, supóngase que se someten 3 insectos a la acción de un extracto vegetal y se evalúan sus correspondientes estados vitales (vivo, muerto) después de 10 minutos.
Aunque, tal y como se indicó anteriormente, la asignación de las etiquetas de éxito y fracaso está desprovista de cualquier connotación ética o sicológica, esta debe realizarse acorde con el evento de interés. Así, si el investigador desea estimar la efectividad del producto, deberá enfocarse en los insectos que mueren, etiquetando tal resultado como éxito, en cuyo caso, el resultado de un insecto vivo será un fracaso; si, por el contrario, en un estudio de resistencia, el investigador estuviera más interesado en los insectos que viven, debería invertir la asignación de las etiquetas.
En última instancia…
Aunque una adecuada definición del éxito puede facilitar las interpretaciones, al hacerlas más directas, es posible extraer exactamente la misma información sobre el fenómeno subyacente, usando cualquiera de las dos distribuciones resultantes, puesto que estas son complementarias.
Para el presente ejemplo, considérese el resultado de un insecto muerto \((\text{m})\) como éxito y el de un insecto vivo \((\text{v})\) como fracaso.
Este experimento tiene asociado el siguiente espacio muestral:
\[
S = \{\text{vvv, vvm, vmv, mvv, vmm, mvm, mmv, mmm}\}
\]
Por información de la casa productora del extracto, se sabe que la probabilidad de éxito es \(p\); luego, la probabilidad de fracaso será \(q = 1 − p\).
La siguiente tabla presenta cada uno de los puntos del espacio muestral, con su correspondiente probabilidad.
Puesto que cada punto muestral está conformado por tres ensayos independientes, la probabilidad de cada punto muestral puede obtenerse multiplicando las probabilidades de tales ensayos. Seguidamente, las probabilidades se presentan mediante una nomenclatura general, en términos de \(p\) y de \(q\) con un exponente.
| Punto muestral | Probabilidad del punto muestral | ||
|---|---|---|---|
| \(\text{vvv}\) | \(q\cdot q\cdot q\) | \(q^3\) | \(p^0q^3\) |
| \(\text{vvm}\) | \(q\cdot q\cdot p\) | \(pq^2\) | \(p^1q^2\) |
| \(\text{vmv}\) | \(q\cdot p\cdot q\) | \(pq^2\) | \(p^1q^2\) |
| \(\text{mvv}\) | \(p\cdot q\cdot q\) | \(pq^2\) | \(p^1q^2\) |
| \(\text{vmm}\) | \(q\cdot p\cdot p\) | \(p^2q\) | \(p^2q^1\) |
| \(\text{mvm}\) | \(p\cdot q\cdot p\) | \(p^2q\) | \(p^2q^1\) |
| \(\text{mmv}\) | \(p\cdot p\cdot q\) | \(p^2q\) | \(p^2q^1\) |
| \(\text{mmm}\) | \(p\cdot p\cdot p\) | \(p^3\) | \(p^3q^0\) |
Consecuentemente con la definición 3.19, el presente ensayo, con la asignación de etiquetas definida, tendrá asociada una variable aleatoria binomial, \(X,\) que contabiliza el número de insectos muertos.
La probabilidad de observar un número determinado de insectos muertos se obtiene sumando las probabilidades de los puntos muestrales que satisfacen dicha condición.
\[
\begin{align}
P(X=0)&=P(\{\text{vvv}\})=p^0q^3\\[0.7em]
P(X=1)&=P(\{\text{vvm, vmv, mvv}\})=p^1q^2+p^1q^2+p^1q^2=3p^1q^2\\[0.7em]
P(X=2)&=P(\{\text{vmm, mvm, mmv}\})=p^2q^1+p^2q^1+p^2q^1=3p^2q^1\\[0.7em]
P(X=3)&=P(\{\text{mmm}\})=p^3q^0
\end{align}
\]
¡Más sobre los factoriales!
Los factoriales aparecen en las definiciones de combinaciones y de permutaciones, que se usan profusamente en los cursos básicos de estadística. Los ejercicios que se resuelven en tales contextos son bastante entretenidos; puede encontrar una buena muestra de estos en el texto de Walpole et al. (2012).
Aunque en el contexto investigativo, estos conceptos no suelen aparecer de forma aislada3, no está de más saber cómo podrían obtenerse en R.
El factorial de un número en R se calcula mediante la función factorial, así:
factorial(5)[1] 120El resultado del coeficiente binomial, que en el contexto de la combinatoria se expresa como la selección de \(x\) elementos a partir de un grupo de \(n,\) se calcula así:
choose(5, 2)[1] 10El anterior resultado corresponde a este desarrollo:
\[
{{5}\choose{2}}=\frac{5!}{2!\left(5-2\right)!}=
\frac{5\times 4\times 3!}{2!3!}=
\frac{20}{2}=10
\]
La definición presentada anteriormente para \(n!,\) aunque intuitiva, deja algunas preguntas sin respuesta.
¿Cuál es el factorial de de 0?
Respuesta: \(0!=1\)
¿Cuál es el factorial de un entero negativo o de un valor no entero?
Respuesta: No está definido.
Las anteriores respuestas quedan incorporadas en una definición más completa del factorial.
¿Si el factorial únicamente está definido para valores enteros, por qué se obtiene el siguiente resultado en R?
factorial(1.5)[1] 1.32934Esto es debido a que la función factorial de R se basa en la relación existente entre el factorial y la distribución gamma: \(n!=\Gamma(n+1)\) (cf. expresión 3.8). Luego, cuando se pide el resultado de factorial(1.5), R internamente calcula gamma(2.5) (¡compruébelo!).
Para el presente ejemplo se estaría formulando la siguiente pregunta: ¿de cuántas maneras puede presentarse una situación en la que resulten muertos \(x\) insectos de un grupo de \(n\)? Si esta pregunta se formulara, por ejemplo, para \(x=2,\) la respuesta sería que el número de maneras en que puede presentarse un resultado de 2 insectos muertos cuando se evalúan 3 es 3: \(\text{vmm},\) \(\text{mvm}\) y \(\text{mmv}.\) Esto permite escribir cada una de las probabilidades más sucintamente:
\[
\begin{align}
P(X=0)&={{3}\choose{0}}p^0q^3\\[1.4em]
P(X=1)&={{3}\choose{1}}p^1q^2\\[1.4em]
P(X=2)&={{3}\choose{2}}p^2q^1\\[1.4em]
P(X=3)&={{3}\choose{3}}p^3q^0
\end{align}
\]
La expresión general para calcular la probabilidad de que la variable aleatoria \(X\) tome un valor determinado \(x,\) en un ensayo binomial de tamaño \(n,\) con probabilidad de éxito \(p,\) está dada por:
\[
P(X=x)=f(x)=\binom{n}{x} p^x q^{n-x}, \quad x=0,1,2,\dotsc,n
\tag{3.2}\]
Si una variable aleatoria \(X\) tiene una función masa de probabilidad como la de la expresión 3.2, se dice que \(X\) sigue una distribución binomial con parámetros \(n\) y \(p,\) y se denota así:
\[
X \thicksim \text{bin}(n,\,p)
\]
La distribución binomial está caracterizada por dos parámetros: \(n\) y \(p.\) El parámetro \(n\) —que representa el número de ensayos Bernoulli— puede tomar cualquier valor entero mayor o igual que 1. El parámetro \(p\) —que representa la probabilidad de éxito— puede tomar cualquier valor en el intervalo \([0,1].\)
Es lo mismo…
Cuando \(n = 1\), es decir, cuando se realiza un único ensayo Bernoulli, la distribución binomial es equivalente a la distribución Bernoulli.
Aunque las funciones de probabilidad están determinadas por sus parámetros, en ocasiones estos no son interpretables de manera directa.
Para la caracterización de las funciones de probabilidad se utilizan algunas funciones de los parámetros, denominadas genéricamente momentos4. De estos, los más importantes son el primer momento al origen, denominado esperanza matemática, valor esperado o media, y el segundo momento central, denominado varianza.
¡Vienen siendo como la santísima dualidad!
En virtud de la estrecha relación que existe entre las variables aleatorias y sus correspondientes funciones de probabilidad, es equivalente hablar de una u otra cuando se discuten sus propiedades.
Por tanto, es correcto hablar de los momentos de una función de probabilidad o de los momentos de la correspondiente variable aleatoria.
La media de una variable aleatoria es equivalente a la media ponderada de una muestra, usando las probabilidades como factor de ponderación. Refleja el valor medio o esperado de la variable en cuestión si se obtuvieran muchas realizaciones de la misma, es decir, si se realizaran muchos experimentos aleatorios que dieran lugar a valores concretos de la misma.
No obstante, a diferencia de la media aritmética que cambia de muestra a muestra, la esperanza matemática es una constante asociada con cada variable aleatoria, que depende únicamente de los parámetros de su función de probabilidad.
La varianza de una variable aleatoria es el valor esperado de las desviaciones cuadráticas entre cada posible realización de la variable aleatoria y su media. Es equivalente a la varianza de una muestra. Expresa el grado de dispersión de la variable aleatoria, con respecto a su media. Al igual que la esperanza, la varianza de una variable aleatoria es una constante asociada con la misma.
\[
\text{si}\: X \thicksim \text{bin}(n,\, p)\;\;\Rightarrow\;\; E(X)=np,\; V(X)=npq
\]
La interpretación de la esperanza es bastante intuitiva. Así, por ejemplo, para una variable aleatoria \(X\), con distribución \(\text{bin}(10,\,0.7),\) la esperanza es 7. Retomando el experimento de muestreo con remplazo en una tula con 7 fichas blancas y 3 negras, \(X\) representaría el número de fichas blancas cuando se realizan 10 extracciones. Desde luego, el resultado de la variable aleatoria \(X\) en una serie particular puede ser cualquier valor entero entre 0 y 10, con algunos de tales resultados más probables que otros. No obstante, si se repitiera muchas veces el experimento de realizar 10 extracciones y contabilizar el número de fichas blancas, la media de \(X\) sería 7.
¡Compruébelo!
Puede usarse la función de generación de muestras seudoaleatorias (cf. sección 3.8) para constatar, por ejemplo, que el valor esperado de una variable aleatoria \(\text{bin} (10,\,0.7)\) es 7.
Para ello, se genera una muestra de tamaño cien, mil o un millón (cualquier número grande) y se obtiene su promedio, tal y como se ilustra a continuación.
- 1
- Muestra aleatoria de tamaño 1000, basada en una \(\text{bin}(n=10,\,p=0.7)\)
- 2
- Media de las 1000 realizaciones de la variable aleatoria
¿Cómo se ve afectado el desempeño de la simulación por el tamaño de las muestras?
Las funciones masa de probabilidad pueden representarse gráficamente ubicando los posibles valores de \(X\) en la abscisa y la correspondiente probabilidad en la ordenada. Suelen utilizarse barras verticales, cuya altura representa la probabilidad de cada punto. Los parámetros \(n\) y \(p\) determinan el aspecto de la distribución binomial. La figura 3.6, conformada por dos miembros de la familia binomial con un valor común de \(n\) permite visualizar la manera en la que el parámetro \(p\) afecta la forma de la distribución.
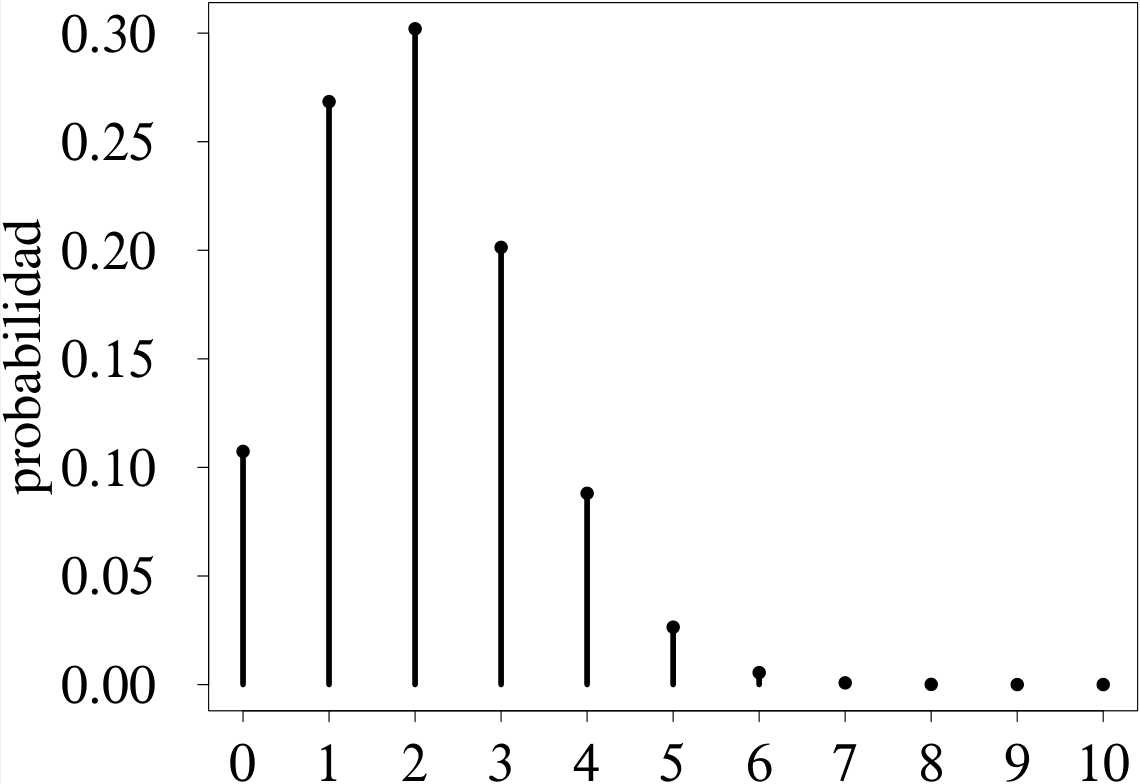
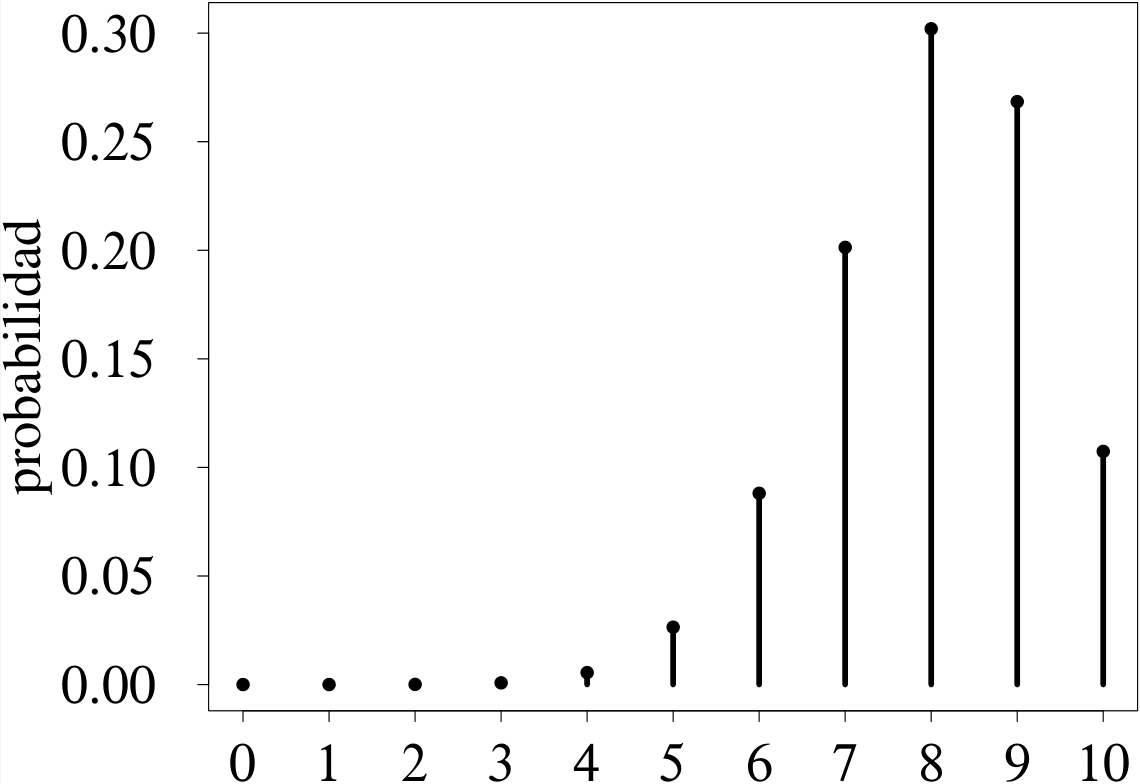
Cuando \(p < 0.5,\) la distribución tiene asimetría a la derecha (figura 3.6 (a)), mientras que \(p > 0.5\) da lugar a distribuciones con asimetría a la izquierda (figura 3.6 (b)) (cf. sección 2.1.3.1). La asimetría es mayor cuanto más cerca esté \(p\) de 0 o de 1.
¿Es lo mismo éxito que fracaso?
Los gráficos que conforman la figura 3.6 ilustran que la definición del éxito y el fracaso, más allá de facilitar la interpretación, es irrelevante en lo que a información se refiere.
Supóngase que se está evaluando el sexo de un organismo, en una población con 20 % de machos y 80 % de hembras. Si se evalúan 10 individuos, la variable aleatoria que contabiliza los machos sigue una distribución binomial con \(n = 10\) y \(p = 0.2\) (figura 3.6 (a)), mientras que la variable aleatoria que contabiliza las hembras sigue una distribución binomial con \(n = 10\) y \(p = 0.8\) (figura 3.6 (b)).
Supóngase, ahora, que se desea calcular la probabilidad del evento consistente en que de los 10 individuos evaluados 3 sean machos y 7 hembras. Si se usa la etiqueta éxito para los machos (y, por tanto, fracaso para las hembras), dicha probabilidad se calcula así:
\[
P(X=3)={{10}\choose{3}}0.2^3\,0.8^7=0.2013266
\]
Si la etiqueta éxito se asigna a las hembras (y, por tanto, fracaso a los machos), la probabilidad del evento indicado se calcula así:
\[
P(X=7)={{10}\choose{7}}0.8^7\,0.2^3=0.2013266
\]
La figura 3.7 ilustra el efecto del parámetro \(n\) en la forma de la distribución.
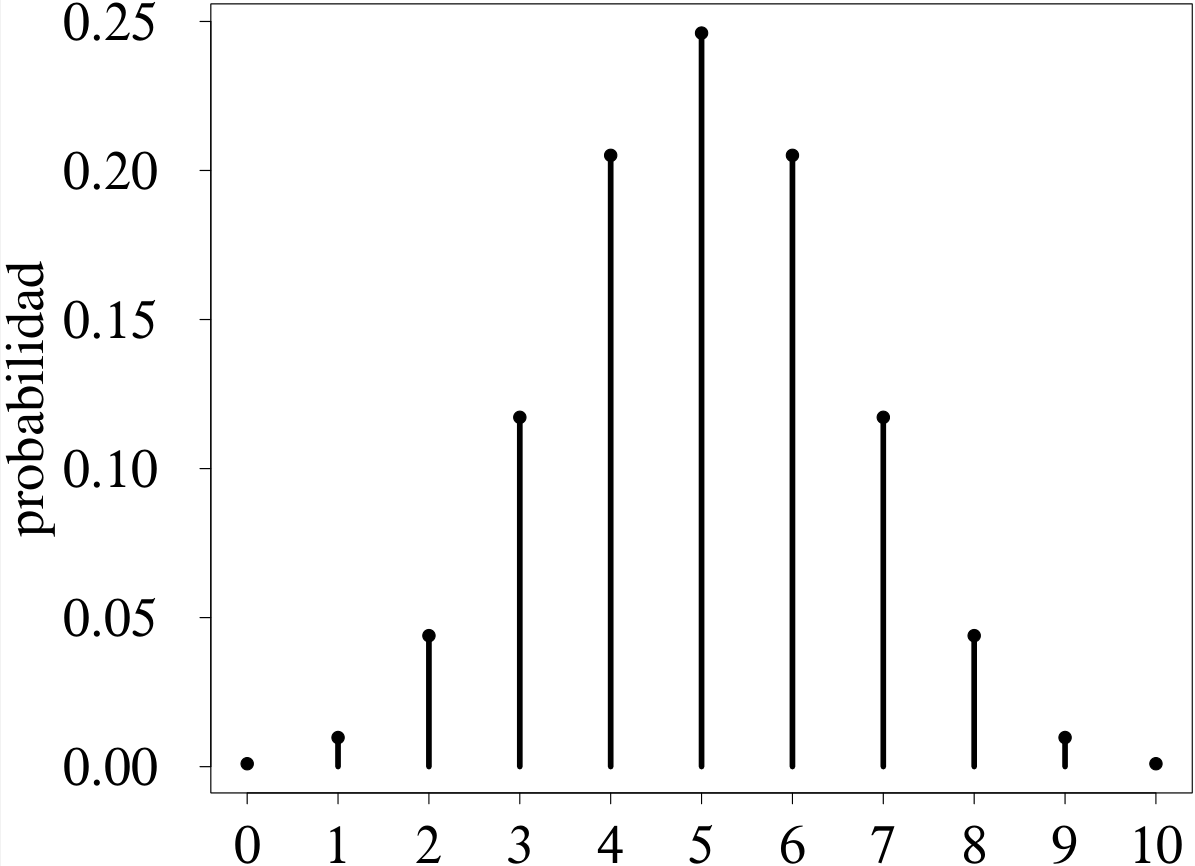
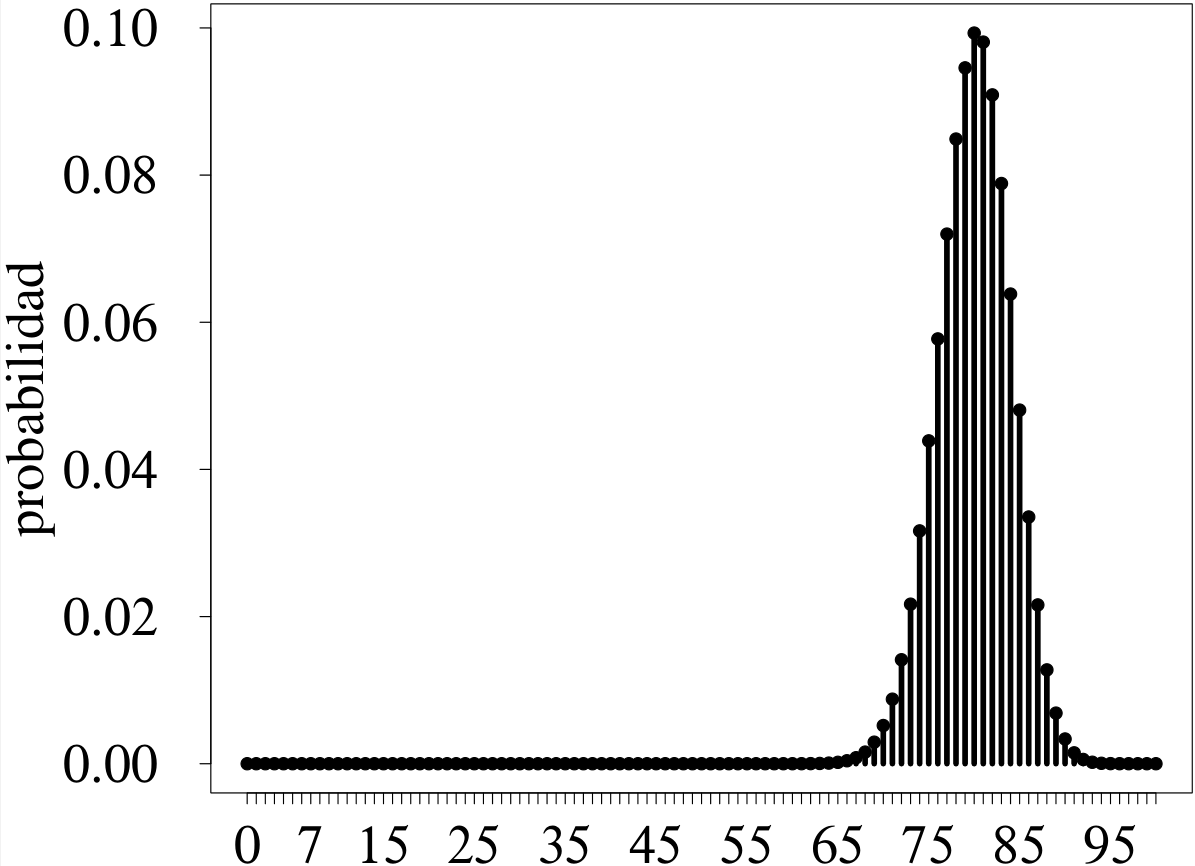
La figura 3.7 (a) muestra la distribución de una variable aleatoria binomial con \(p = 0.5,\) la cual siempre es simétrica, sin importar el tamaño del experimento. Esta distribución se usa para modelar el comportamiento probabilístico de una variable aleatoria que contabiliza el número de éxitos de \(n\) ensayos Bernoulli independientes, cada uno con un espacio muestral conformado por dos puntos muestrales equiprobables, como serían los que corresponden al lanzamiento de una moneda equilibrada.
Para el caso ilustrado, con \(n = 10,\) la esperanza del número de éxitos es 5, valor al que le corresponde la máxima probabilidad. Las probabilidades disminuyen de manera simétrica a medida que se alejan de la esperanza. Así, por ejemplo, \(P(X = 4)\) \(=\) \(P(X = 6).\)
La figura 3.7 (b) muestra cómo se simetriza la distribución para experimentos grandes. Contrástese esta distribución con la presentada en la figura 3.6 (b). Aunque podría pensarse, por la larga cola de la izquierda, que la simetría alcanzada es dudosa, tales valores aportan muy poco a la distribución por ser bastante improbables: \(P(X\le 69) < 0.01.\)
Aunque, usando una hoja de cálculo, no es difícil obtener \(P(X = x)\) mediante la expresión 3.2, puede hacerse de manera más directa usando la función dbinom en R, cuyos argumentos son x, size y prob, siendo x la realización de la variable aleatoria \(X\) cuya probabilidad se desea calcular; size, el tamaño del experimento binomial, es decir, \(n\), y prob, la probabilidad de éxito, es decir, \(p\). Si \(X \thicksim \text{bin}(n,\, p),\) \(P(X = 3)\) se obtiene en R así:
dbinom(3, 10, 0.2)[1] 0.2013266\[ F(x)=P(X\le x)=\sum\limits_{i=0}^{x}{{n}\choose{i}}p^iq^{n-i}, \quad x=0,1,2,\dotsc,n \]
Considérese una variable aleatoria \(X\thicksim \text{bin}(n=15,\,p=0.4).\) La probabilidad de que esta variable tome un valor menor o igual a 5 se expresa así:
\[ F(5)=P(X\le 5)=\sum\limits_{i=0}^{5}{{15}\choose{i}}0.4^i\,0.6^{15-i} \]
Para su obtención, se suman las probabilidades de los correspondientes puntos, así:
\[ \begin{align} P(X=0)&=0.0004702\\[0.7em] P(X=1)&=0.0047019\\[0.7em] P(X=2)&=0.0219420\\[0.7em] P(X=3)&=0.0633879\\[0.7em] P(X=4)&=0.1267758\\[0.7em] P(X=5)&=0.1859378 \end{align} \]
\[
\mathbf{\,\,\,P(X\le5)=0.4032156}
\]
Las funciones de distribución acumuladas constituyen una herramienta muy útil para el cálculo de probabilidades. Las tablas que durante mucho tiempo se utilizaron, y que aún aparecen en muchos textos, están construidas con base en funciones de distribución (cf. sección 3.8). En R, se usa la función pbinom, con los argumentos q, size y prob, siendo q el valor hasta el cual se desea acumular la probabilidad; size, el tamaño del experimento binomial, y prob, la probabilidad de éxito. La probabilidad cuyo cálculo se ilustró anteriormente se obtiene así:
pbinom(5, 15, 0.4)[1] 0.4032156
La figura 3.8, correspondiente a la función de distribución de una variable aleatoria \(\text{bin}(n=5,\,p=0.6)\) facilita la visualización del carácter acumulativo de estas funciones.
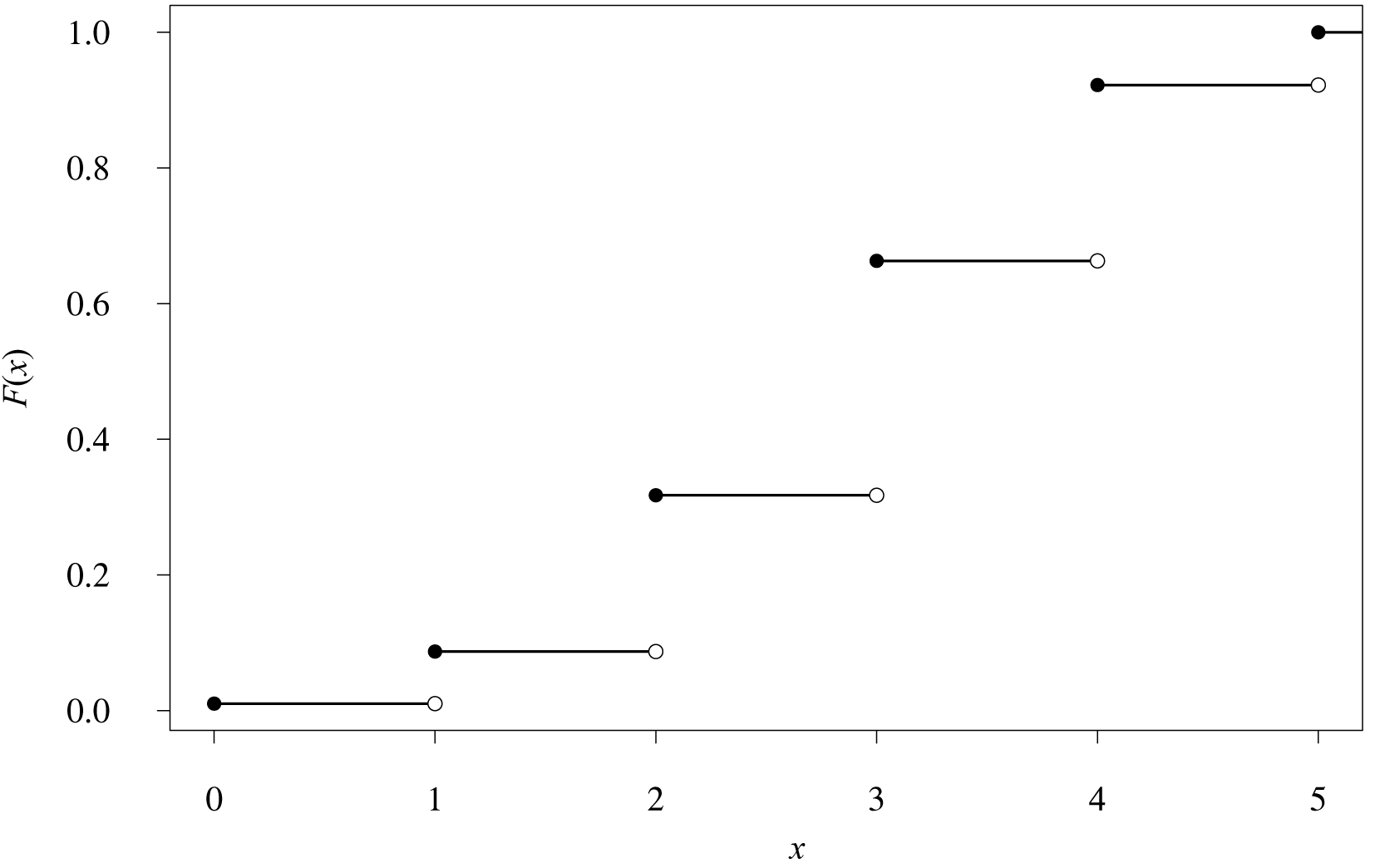
Como consecuencia de que los valores que una variable aleatoria discreta puede tomar estén circunscritos a una serie determinada, sin la posibilidad de que se presente ningún valor intermedio entre pares de valores adyacentes de la serie, sus correspondientes funciones de distribución son funciones escalonadas, tales como la representada en la figura 3.8, correspondiente a una variable aleatoria binomial con \(n = 5\) y \(p = 0.6.\)
Puede observarse, por ejemplo, que el valor de dicha función para cualquier valor en el intervalo \([2,\,3)\) es 0.31744. Esto implica que cualquiera de las siguientes probabilidades es exactamente la misma: \(P(X\le 2)\) \(=\) \(P(X \le 2.5)\) \(=\) \(P(X \le 2.99)\) \(=\) \(0.31744\) (¡compruébelo!). Cuando el valor del argumento llega a 3, la función salta a 0.66304. Nótese que la función de distribución acumulada es el equivalente teórico del polígono de frecuencias acumuladas descrito en la sección 2.3.3.
3.7 Distribuciones de probabilidad continuas
Las variables cuyo rango es un conjunto no contable de valores reales se denominan variables aleatorias continuas. La función que define el comportamiento probabilístico de tales variables se denomina función densidad de probabilidad, función de densidad, densidad de probabilidad o simplemente densidad.
¡No se confunda!
Aunque, en general, las funciones densidad de probabilidad se definen en los reales, esto no implica que el recorrido de cualquier variable aleatoria continua sea el rango completo de los reales. Bien pueden definirse funciones que valgan cero para cualquier valor por fuera de su soporte.
En las funciones masa de probabilidad (variables aleatorias discretas), la segunda condición exige que la suma sobre cada uno de los puntos que conforman el rango de la variable aleatoria sea 1. Para el caso de las variables aleatorias continuas, al no estar conformadas por puntos discretos, sino por un continuo de valores, se usa la integral.
Puesto que las funciones densidad de probabilidad están representadas por curvas, la segunda condición establece que el área total bajo tales curvas es 1. Esto es equivalente a exigir que la probabilidad del espacio muestral sea 1.
¡Diferencia esencial!
La tercera condición representa quizá la diferencia más relevante entre variables aleatorias discretas y continuas. En el caso discreto se calculan probabilidades puntuales. Las funciones de probabilidad están conformadas por el conjunto de tales puntos de probabilidad. En tal sentido puede entenderse su denominación como funciones masa de probabilidad.
En el caso continuo, por la naturaleza misma de las variables, que pueden tomar infinitos valores entre cualquier par de valores por cercanos que se encuentren entre sí, no se calculan probabilidades puntuales; de hecho, la probabilidad de cualquier punto particular es igual a cero.
¿¡Probabilidad cero!?
Para entender el concepto de probabilidad cero para cualquier valor individual también puede resultar útil considerar una variable de campo cualquiera que pueda tomar valores en un continuo.
Considérese, por ejemplo, el diámetro de un tallo y la probabilidad de observar un tallo particular cuyo diámetro sea exactamente igual a 5 centímetros, pudiendo afirmarse que la probabilidad es cero. De nuevo, esta afirmación resulta desconcertante y antintuitiva.
No obstante, si prescindiendo de las limitaciones tecnológicas y prácticas se supone que se cuenta con un instrumento de precisión infinita, sería imposible que dicho instrumento arrojara un valor de 5, seguido de infinitos ceros en todas sus posiciones decimales; una lectura de 5.000… que tuviera cualquier valor diferente de cero en la millonésima posición decimal, sería realmente un valor mayor que 5; de igual manera un valor de 4.999… seguido de infinitas cifras 9, sería realmente un valor menor que 5.
Es por lo anterior que para el caso de variables aleatorias continuas no se calculan probabilidades de valores puntuales, sino la probabilidad de que la variable tome algún valor en un intervalo determinado. Este acercamiento supera las limitaciones expuestas anteriormente.
Así, si para el hipotético caso del tallo de 5 cm de diámetro, en lugar de preguntar por la probabilidad de dicho punto, se reformula la pregunta como la probabilidad de observar un tallo entre 4.9 y 5.1, será perfectamente viable observar tallos que satisfagan dicha condición, sin que un hipotético instrumento de infinita precisión constituya un impedimento para ello.
¿Si todas las probabilidades puntuales son cero, cómo es que la suma de todas la probabilidades es 1?
Aunque resulta paradójico pensar que una suma de infinitos elementos iguales a cero llegue a ser uno, puede ayudar la conceptualización de la integral como una serie infinita de sumas de Riemann. En la sección 2.3.2, al presentar el histograma de frecuencias, se anotó que las frecuencias relativas se asociaban realmente con el área de las barras; no con sus alturas. Adicionalmente, en la sección 3.4.1 se menciona que las probabilidades suelen interpretarse en términos frecuentistas, como la forma límite de las frecuencias relativas de un evento.
En tal sentido, en un histograma de frecuencias con muchísimos intervalos la base de las barras tendería a cero y consecuentemente, el área individual de cada una de las barras —y la probabilidad que representan— tendería también a cero. Sin embargo, la suma de todas las áreas sería 1.
¿¡Densidad!?
La tercera propiedad establece que la probabilidad de que una variable aleatoria continua tome algún valor en un intervalo dado se obtiene mediante la correspondiente integral definida en dicho intervalo. Dicha integral representa, asimismo, el área bajo la curva entre los límites establecidos.
Luego, a diferencia del caso discreto, donde la probabilidad de que la variable aleatoria tome un valor en un intervalo se obtiene sumando puntos de probabilidad, en el caso continuo la probabilidad de que la variable aleatoria tome un valor dentro de un intervalo se obtiene como el área bajo la curva entre los límites definidos por el intervalo.
Esto explica que a las correspondientes funciones de probabilidad se les denomina funciones densidad de probabilidad.
¡Tenga presentes las siguientes equivalencias!
Para el caso continuo todas las siguientes probabilidades son equivalentes:
\[
P(a < X < b) = P(a \le X < b) = P(a < X \le b) = P(a \le X \le b)
\]
Estas identidades surgen del hecho de que la probabilidad de cualquier valor puntual sea igual a cero. En consecuencia, resulta irrelevante incluir o no el punto en el intervalo, lo cual, desde luego, sí marca diferencias en el caso discreto.
Teniendo en cuenta este aspecto y buscando simplicidad, en el caso continuo suelen obviarse los signos de igualdad, expresando siempre las probabilidades en intervalos abiertos.
Puesto que el área bajo cualquier curva de densidad de probabilidad es 1, se satisfacen las siguientes relaciones.
\[
F(x)=1-S(x)
\]
\[
\,S(x)=1-F(x)
\tag{3.5}\]
3.7.1 Distribución normal
Puede afirmarse sin lugar a dudas que la distribución normal es la que juega un papel más importante en los métodos inferenciales clásicos. Su importancia surge del hecho de que puede usarse, ya sea de manera directa o indirecta, para modelar el comportamiento probabilístico de muchas variables de campo y laboratorio.
Aunque esta distribución suele estar ligada con el matemático alemán Carl Friedrich Gauss, no fue este el único pensador en contribuir a la misma. Es necesario acreditar por igual a los matemáticos franceses Abraham de Moivre y Pierre-Simon Laplace. De hecho, fue De Moivre, en 1733, el primero en llegar a su formulación matemática, en búsqueda de una aproximación a la distribución binomial.
En la sección 3.1 se mencionó la contribución realizada por Pascal y Fermat, en el siglo xvii, estimulados por las preguntas que surgían de los juegos de azar. En ese mismo contexto, ya en el siglo xviii, De Moivre buscaba calcular, por ejemplo, la probabilidad de obtener 60 o más sellos al realizar 100 lanzamientos de una moneda.
Aunque la pregunta planteada tiene que ver con un experimento binomial y la expresión matemática mediante la cual podía responderse esta pregunta era conocida, su cálculo no era sencillo usando las herramientas computacionales disponibles en la época.
\[
\sum_{i=60}^{100}{{100}\choose{i}}0.5^i\,0.5^{100-i}=\sum_{i=60}^{100}\frac{100!}{i!(100-i)!}0.5^i\,0.5^{100-i}
\]
De Moivre notó que en experimentos binomiales con \(p = 0.5\) y \(n\) grande, las distribuciones de probabilidad adquirían una forma de curva acampanada como la ilustrada en la figura 3.7 (a). Buscando una expresión matemática de tales curvas, que le permitiera obtener de manera sencilla una aproximación de las probabilidades requeridas, De Moivre desarrolló la distribución normal.
En 1810, Laplace generalizó las ideas de De Moivre, estableciendo las bases de lo que posteriormente daría lugar a uno de los resultados más importantes de la estadística aplicada: el teorema central del límite.
Cuando se mencionaba anteriormente que la distribución normal podía usarse para modelar de manera indirecta el comportamiento de variables de campo, se hacía referencia justamente al teorema central del límite. Usando métodos de simulación Monte Carlo, Correa-Londoño y Castillo-Morales (2000) realizaron un estudio, en el que analizaron la convergencia a la distribución normal de los promedios basados en diferentes tamaños de muestra, a partir de algunas de las distribuciones que más a menudo se suponen en la práctica investigativa.
¿¡Central del límite o del límite central!?
Al hacer referencia a este teorema, algunos autores lo denominan incorrectamente “teorema del límite central”, argumentando que el adjetivo “central” no hace referencia al teorema, sino al límite.
El nombre del teorema en cuestión fue acuñado por George Pólya, en 1920, quien, en su artículo original, escrito en alemán, lo llama zentralen Grenzwertsatz, quedando claro que el adjetivo “central” (zentralen) se refiere al teorema del límite (Grenzwertsatz).
En el resumen de su artículo, Pólya indica que la ocurrencia de la densidad de probabilidad gaussiana que surge en muchas situaciones de experimentación repetida puede explicarse por el teorema límite, el cual juega un rol central en el cálculo de la probabilidad.
Otro tópico que condujo al desarrollo de la distribución normal fue el relacionado con las tempranas mediciones astronómicas realizadas en el siglo xvii y los errores asociados con estas. Galileo había notado que tales errores se distribuían simétricamente y que los errores pequeños eran más frecuentes que los de gran magnitud. Sin embargo, no fue hasta 1809 que Gauss desarrolló la distribución probabilística para describir adecuadamente tales errores. Por tal razón, a la distribución normal suele denominársele gaussiana.
Si \(X\) es una variable aleatoria con función densidad de probabilidad:
\[
f(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{\left(x-\mu\right)^2}{2\sigma^2}},\quad-\infty<x<\infty,
\]
se dice que \(X\) sigue una distribución normal, con parámetros \(\mu\) y \(\sigma^2,\) y se denota así:
\[
X \thicksim N\left(\mu,\,\sigma^2\right)
\]
Aunque los parámetros de las distribuciones no siempre son interpretables de forma directa, en la normal sí lo son.
\[
\text{si}\;X\thicksim N\left(\mu,\,\sigma^2\right)\;\;\Rightarrow\;\;E(X)=\mu,\;V(X)=\sigma^2
\]
¿Y cómo se pronuncia \(\mu\)?
En español, esta letra se llama mi, tal como la registra la Real Academia Española. Esta denominación, además de contar con respaldo normativo, refleja con mayor fidelidad la pronunciación del griego moderno.
Tradicionalmente se ha pronunciado mu, por influencia del inglés, que adoptó la grafía del griego, pero no su sonido.
La forma miu, tomada directamente del inglés (/mjuː/), es ajena tanto al griego como al español, por lo que no debe usarse.
El parámetro \(\mu\) es la media, mientras que \(\sigma^2\) es la varianza. La esperanza, \(\mu,\) puede tomar cualquier valor en los reales, mientras que la varianza, \(\sigma^2,\) toma exclusivamente valores positivos.
Los valores de estos parámetros caracterizan a los miembros de la familia normal. En la figura 3.9 se observa que la curva está centrada en \(\mu\), razón por la que se le denomina parámetro de localización o de posición. Por su parte, \(\sigma^2\) determina el ancho y altura de la curva, por lo que suele denominársele parámetro de escala: mientras mayor sea \(\sigma^2\), más dispersa será la distribución.

Nótese que para representar las funciones densidad de probabilidad de la figura 3.9 solo se usa el eje de la abscisa, que corresponde al dominio o soporte de la función, es decir, los posibles valores que puede tomar la variable aleatoria. No suele incluirse el eje para la ordenada, correspondiente a \(f(x)\), dado que puede inducir a una interpretación errónea, pues a diferencia de las funciones masa de probabilidad, en las que \(f(x) = P(X = x),\) en las funciones densidad de probabilidad, \(f(x)\) no tiene una interpretación práctica.
¡No se confunda!
En las funciones masa de probabilidad, \(f(x)=P(X=x),\) pero en las funciones densidad de probabilidad \(f(x)\ne P(X=x).\)
A pesar de que la normal es una familia conformada por infinitos miembros, todos ellos suelen referenciarse a un miembro común. Para comprender este proceso de referenciación, es importante establecer que cualquier transformación de una variable aleatoria da lugar a una nueva variable aleatoria, cuyo comportamiento probabilístico en ocasiones puede describirse de manera explícita y sencilla.
Considérese una variable aleatoria cualquiera —no necesariamente normal— \(X\), tal que \(E(X)=\mu\) y \(V(X)=\sigma^2.\) Si se le resta una constante cualquiera \(m\) a \(X,\) se obtiene una nueva variable aleatoria, con esperanza \(\mu−m;\) la varianza sigue siendo la misma. Esta propiedad puede usarse para centrar en cero cualquier variable aleatoria, es decir, para generar una nueva variable aleatoria con media cero. Para ello, basta con restarle la media, así:
\[
\text{si}\;E(X)=\mu\;\;\Rightarrow\;\;E(X-\mu)=0
\]
Por otra parte, cuando se transforma una variable aleatoria, dividiéndola por una constante, se obtiene una nueva variable aleatoria, cuya varianza es igual a la varianza de la variable original, dividida entre la constante elevada al cuadrado. Al aplicar esta transformación, la esperanza no cambia. Esta propiedad puede usarse para obtener variables aleatorias con varianza 1, dividiendo por la desviación estándar. A este proceso se le denomina estandarización:
\[
\text{si}\;V(X)=\sigma^2\;\;\Rightarrow\;\; V(X/\sigma)=1
\]
Aunando las dos transformaciones anteriores, se tiene la posibilidad de centrar y estandarizar cualquier variable aleatoria, restándole su media y dividiéndola por su desviación estándar, así:
\[
\begin{align}
\text{si}\;E(X)=\mu\quad &\text{y}\quad V(X)=\sigma^2\\[1.4em]
\Rightarrow\;\;E\!\left(\frac{X-\mu}{\sigma}\right)=0
\quad &\text{y}\quad V\!\left(\frac{X-\mu}{\sigma}\right)=1
\end{align}
\]
Aunque las anteriores propiedades de la esperanza y la varianza son generales para cualquier variable aleatoria y no tienen implicaciones distribucionales, para el caso particular de la distribución normal, se cumple que cualquier transformación lineal de una variable aleatoria normal es a su vez una variable aleatoria normal5. Se tiene, por tanto, el siguiente resultado:
\[
\text{si}\;X\thicksim N\left(\mu,\,\sigma^2\right)\;\;\Rightarrow\;\;
Z=\left(\frac{X-\mu}{\sigma}\right)\thicksim N\left(0,\,1\right)
\tag{3.6}\]
Así, pues, a partir de cualquier variable aleatoria con distribución normal, puede generarse una nueva variable aleatoria normalmente distribuida, con media cero y varianza 1. Dicha variable, que sirve como referente de cualquier variable aleatoria normalmente distribuida, se denota por \(Z\) y se le conoce como normal estándar.
La relación existente entre la normal estándar y cualquier otra variable aleatoria normal se utiliza extensamente en los textos básicos para calcular probabilidades asociadas con cualquier variable aleatoria normal. No obstante, más allá de servir de referente para el cálculo de las probabilidades de cualquier distribución normal, lo que convierte a la normal estándar en una poderosa herramienta es el papel que desempeña en muchas técnicas inferenciales.
Hasta hace muy poco, la mayoría de textos de estadística incluían tablas con valores de la función de distribución acumulada de la normal estándar6 (cf. sección 3.8), las cuales facilitaban la obtención de las probabilidades, sin necesidad de realizar en cada ocasión el correspondiente proceso de integración de la función densidad de probabilidad (cf. expresión 3.4). En R, tales probabilidades pueden calcularse fácilmente, usando la función pnorm{stats}, que incluye los argumentos mean, para especificar la media y sd para la desviación estándar.
Tal y como se ha indicado, cuando de normales se trata, la normal estándar es el miembro de la familia que cumple un rol protagónico en los procesos inferenciales. Es por ello que los valores por defecto de los argumentos de la función pnorm corresponden a los parámetros de una normal estándar (mean = 0, sd = 1).
¡Preste atención a la especificación de los parámetros!
El argumento sd de la función pnorm no representa la varianza, sino la desviación estándar.
Aunque este detalle es irrelevante para la normal estándar, en la cual \(\sigma^2 = \sigma = 1,\) debe tenerse presente con otros miembros de la familia normal, para asegurar que se está usando el parámetro correcto.
El primer argumento de la función pnorm es el cuantil (q)7, es decir, el valor hasta el cual se acumula el área o la probabilidad. Por tanto, cuando se usa la función pnorm con un único argumento, se obtiene la probabilidad acumulada hasta dicho valor en una normal estándar. Para obtener, por ejemplo, \(P(Z<1),\) se usa:
pnorm(1)[1] 0.8413447Aprovechando la relación existente entre la función de distribución y la función de supervivencia (cf. expresión 3.5), puede obtenerse por diferencia la probabilidad de obtener un valor de \(Z\) mayor que un valor determinado, lo cual equivale al procedimiento que se usaba cuando se calculaban las probabilidades a partir de tablas.
Las funciones que facilitan el cálculo de probabilidades en R (pnorm y muchas otras con un propósito análogo) incluyen el argumento lógico lower.tail, cuyo valor por defecto es TRUE, mediante el cual se especifica que las probabilidades se calculan desde la cola izquierda, es decir, acumulando. Cuando el valor de este argumento se cambia a FALSE, se está indicando que no es hacia la cola izquierda, sino hacia la derecha que deben calcularse las probabilidades, es decir, función de supervivencia.
La figura 3.10 resume las relaciones expuestas.

En ocasiones se requiere usar las funciones inversas de \(F(X)\) o de \(S(X),\) de manera que, al ingresar una probabilidad como argumento, se obtenga el valor de la variable aleatoria que acumula dicha probabilidad o que deja esa área a la derecha, respectivamente. A las inversas de las funciones de distribución acumuladas se les denomina genéricamente funciones cuantil8. Nótese la similitud entre tales funciones y la definición de los cuantiles muestrales presentada en la sección 2.1.4.
En R, la función cuantil correspondiente a la normal es qnorm; usando el argumento lower.tail = F, se obtiene la inversa de la función de supervivencia. A los valores resultantes de invertir las funciones de distribución y de supervivencia suele denominárseles valores críticos inferiores y valores críticos superiores, respectivamente, por el uso que se hace de los mismos en los procesos inferenciales, tal y como se ilustra en los siguientes capítulos.
Retomando el escenario que se presenta en la figura 3.10, un usuario podría tener interés, por ejemplo, en averiguar cuál es el valor de una variable aleatoria normal estándar que acumula un área de 0.8413 o, en otras palabras, cuál es el valor de una variable aleatoria normal estándar tal que la probabilidad de obtener valores menores sea 0.8413. Para averiguarlo, se escribe qnorm(0.8413), con lo cual se obtiene un resultado que es aproximadamente 1.
Si se desea averiguar cuál es el valor de una variable aleatoria normal estándar que deja un área de 0.1587 a su derecha o, en otras palabras, cuál es el valor de una variable aleatoria normal estándar tal que la probabilidad de obtener valores mayores sea 0.1587, se escribe qnorm(0.1587, lower.tail = F). La figura 3.11, en la que se grafica la función de distribución acumulada de la normal estándar, ilustra las relaciones descritas.

Nótese que, a diferencia de lo indicado para la función densidad de probabilidad —que no suele incluir el eje de la ordenada—, cuando se grafica la función de distribución acumulada sí se incluye un eje en la ordenada, el cual representa la probabilidad acumulada hasta \(z,\) es decir, \(P(Z < z)\) (cf. expresión 3.4).
La figura 3.12 muestra la relación entre la función densidad de probabilidad (figura 3.12 (a)) y la función de distribución acumulada (figura 3.12 (b)) de una variable aleatoria normal estándar.
Mientras que en la función densidad de probabilidad se calcula el área bajo la curva, en la función de distribución se lee directamente en la ordenada el área que se acumula desde \(-\infty\) hasta el valor de la variable, es decir, \(P(Z < z).\)


Muestras seudoaleatorias basadas en la distribución normal
Para obtener en R una muestra seudoaleatoria de tamaño \(k\) a partir de una distribución normal estándar, se usa la instrucción rnorm(k). Si se quiere obtener una muestra basada en una normal con parámetros diferentes de los de la normal estándar, estos pueden indicarse mediante argumentos adicionales.
¿¡Y las otras distribuciones sí tienen algún uso!?
Ya se ha indicado que la importancia de la distribución normal tiene que ver con su papel en los procesos inferenciales. A continuación se presenta una triada de distribuciones de probabilidad continuas estrechamente ligadas con la distribución normal: la ji cuadrado, la \(t\) y la \(F\) (secciones 3.7.2, 3.7.3 y 3.7.4)), que, aunque no se usan —como la normal— para modelar directamente el comportamiento probabilístico de variables de campo, permiten modelar algunos estadísticos que surgen de los procesos muestrales, motivo por el que suele denominárseles distribuciones derivadas del muestreo. Estas tres distribuciones, al igual que la normal estándar, desempeñan roles esenciales en la mayoría de métodos inferenciales clásicos.
3.7.2 Distribución ji cuadrado
La formulación matemática de esta distribución fue desarrollada por el geodesta alemán Friedrich Helmert en 1876, quien describió el comportamiento probabilístico de una suma de variables aleatorias normales estándar elevadas al cuadrado. No obstante, fue el estadístico inglés Karl Pearson quien la popularizó en 1900, al formular una prueba de bondad de ajuste cuyo estadístico seguía esta distribución.
Pearson denota su estadístico de prueba mediante la vigesimosegunda letra del alfabeto griego elevada a la segunda potencia. En consecuencia, la prueba propuesta ha pasado a la posteridad como prueba ji cuadrado de Pearson, y a la distribución del correspondiente estadístico de prueba se le denomina ji cuadrado.
¡No se confunda!
El nombre de esta distribución proviene de la vigesimosegunda letra del alfabeto griego, \(\chi,\) que en español se denomina ji.
Por influencia del inglés, donde la letra \(\chi\) se denomina chi (pronunciada /kai/) y la distribución chi-squared, en muchos textos en español se adoptó la denominación chi-cuadrado.
No obstante, en este libro se utiliza la denominación ji cuadrado, sin guion, por corresponder a la lectura literal en español de \(\chi^2,\) esto es, “ji al cuadrado”.
¡Otros lo precedieron!
Gorroochurn (2016) sugiere que la formulación de Helmert tuvo precedentes. Tanto Irénée-Jules Bienaymé, en 1853, como Ernst Abbe, en 1863, realizaron contribuciones importantes en torno a la distribución de sumas de variables aleatorias elevadas al cuadrado. Estas contribuciones sentaron las bases conceptuales para la formulación exacta de la distribución ji cuadrado que posteriormente presentaría Helmert.
\[
\text{si}\; Z_i\:\text{iid}\:N(0,\,1),\quad i=1, 2, \dotsc,\nu\;\;\Rightarrow\;\;\sum_{i=1}^{\nu}Z_i^2\thicksim\chi_{(\nu)}^2
\tag{3.7}\]
La sigla iid se lee igual e independientemente distribuidas. Esta condición usualmente se satisface cuando se toma una muestra aleatoria de una población normal. La letra griega \(\nu\) (pronunciada ni) es el parámetro único de la distribución ji cuadrado y se le denomina grados de libertad (gl).
Tip 3.2: ¿¡Grados de libertad!?
Suele suceder que no se le preste mucha atención a esta denominación la primera vez que aparece formalmente —aquí, en la distribución ji cuadrado—. Se toma simplemente como lo que se ha anunciado: el parámetro de esta distribución.
Sin embargo, esta no será la última vez aparezca, puesto que las distribuciones \(t\) y \(F,\) derivadas de la ji cuadrado, también incluyen este parámetro (secciones 3.7.3 y 3.7.4)). Asimismo, aparecerá en la mayoría de las técnicas inferenciales que se desarrollan a partir del capítulo 4, cobrando particular relevancia en el contexto del análisis de varianza (cf. sección 6.2). Es en tales contextos en los que el investigador suele preguntarse sobre el significado de los grados de libertad. Y puesto que tales aplicaciones a menudo aparecen alejadas de los contextos básicos, se dificulta trazar el recorrido hasta su origen.
En su aparición inicial, los grados de libertad indican cuántas variables aleatorias normales estándar independientes participan en la definición de la variable aleatoria ji cuadrado. Por ejemplo, si se toma una variable aleatoria normal estándar y se eleva al cuadrado, se obtiene una variable aleatoria ji cuadrado con un grado de libertad, \(\chi_{(1)}^2.\) Si se suman los cuadrados de \(\nu\) variables aleatorias normales estándar independientes, se obtiene una variable aleatoria ji cuadrado con \(\nu\) grados de libertad, \(\chi_{(\nu)}^2.\)
En contextos inferenciales, los grados de libertad representan las piezas o unidades de información independientes. Si bien la cantidad de información está relacionada con el tamaño de la muestra, la estimación de parámetros introduce restricciones que reducen los grados de libertad. Por lo tanto, los procesos inferenciales nunca están basados en \(n\) grados de libertad totales, sino en una cantidad reducida tras ajustar por las estimaciones necesarias.
Tener un alto número de grados de libertad es una condición deseable en los procesos inferenciales. En general, mientras más grados de libertad tenga una prueba, mayor será su precisión y potencia estadística, lo que permite detectar efectos verdaderos con mayor probabilidad.
La función densidad de probabilidad de una variable aleatoria \(\chi_{(\nu)}^2\) es:
\[
\begin{equation}
f(x)=
\begin{cases}
\frac{1}{2^{\nu/2}\Gamma\left(\nu/2\right)}x^{\frac{\nu}{2}-1}e^{-\frac{x}{2}} & \text{si}\:x>0,\\
\\
0 & \text{en los demás casos}.
\end{cases}
\end{equation}
\]
Donde \(\Gamma\) representa la función gamma, la cual está definida así:
\[
\begin{equation}
\Gamma(x)=
\begin{cases}
(x-1)! & \text{si } x \text{ es entero},\\
\\
\int\limits_{0}^{\infty}t^{x-1}e^{-t}\:dt & \text{si } x \text{ no es entero}.
\end{cases}
\end{equation}
\tag{3.8}\]
La esperanza y la varianza de las variables aleatorias ji cuadrado dependen de los grados de libertad:
\[
\text{si}\;X\thicksim\chi_{(\nu)}^2\;\;\Rightarrow\;\; E(X)=\nu,\:V(X)=2\nu
\]
El soporte de las variables aleatorias ji cuadrado son los reales positivos, puesto que están conformadas por la suma cuadrática de una serie de variables aleatorias normales estándar. Aunque la función densidad de probabilidad es asimétrica, dicha asimetría disminuye para valores altos del parámetro \(\nu\), tal y como se ilustra en la figura 3.13.

R incluye funciones que permiten obtener los valores de la correspondiente función de distribución, de la función de supervivencia, así como de sus respectivas inversas.
Para la función de distribución acumulada se usa pchisq(q, df), siendo q el valor hasta el cual se desea acumular la probabilidad en una distribución ji cuadrado con df grados de libertad. Así, por ejemplo, si se tiene una variable aleatoria ji cuadrado con 7 gl y se desea calcular la probabilidad de obtener un valor menor que 3.5, se usa:
pchisq(3.5, 7)[1] 0.1647745Para calcular la probabilidad de obtener un valor mayor (función de supervivencia), se le agrega el argumento lower.tail = F a la función pchisq.
pchisq(3.5, 7, lower.tail = F)[1] 0.8352255Para averiguar cuál es el valor que deja a su izquierda un área de 0.025, en una distribución ji cuadrado con 4 gl, se usa la función cuantil (qchisq):
qchisq(0.025, 4)[1] 0.4844186Para calcular el valor de una variable aleatoria ji cuadrado con 13 gl que deja a su derecha un área de 0.05, se agrega el argumento lower.tail = F en la función cuantil:
qchisq(0.05, 13, lower.tail = F)[1] 22.362033.7.3 Distribución \(t\)
Aunque existen registros que indican que esta distribución fue derivada por Friedrich Helmert y Jacob Lüroth en 1876, su incorporación efectiva a la práctica estadística está marcada por un artículo presentado en 1908 por el estadístico inglés William Sealy Gosset, quien en aquel entonces trabajaba en la cervecería irlandesa Guinness, razón por la cual publicó su trabajo con el seudónimo de Student.
Posteriormente, Ronald Aylmer Fisher contribuyó decisivamente a su formalización y difusión, siendo quien introdujo y consolidó la denominación “\(t\) de Student” en su obra Statistical Methods for Research Workers, publicada en 1925 (Eisenhart, 1979). En la literatura moderna, esta distribución también se conoce simplemente como distribución \(t.\)
La distribución \(t\) está asociada al muestreo de poblaciones normales. Surge como el cociente entre una variable aleatoria normal estándar y la raíz cuadrada de una variable aleatoria ji cuadrado escalada por sus grados de libertad.
Si \(Z\thicksim N(0,\,1)\) y \(U\thicksim\chi_{(\nu)}^2,\) siendo \(Z\) y \(U\) independientes entre sí:
\[
\frac{Z}{\sqrt{U/\nu}}\thicksim t_{(\nu)}
\]
La función densidad de probabilidad de una variable aleatoria \(t_{(\nu)}\) es:
\[
f(t)=\frac{\Gamma\left(\frac{\nu+1}{2}\right)}{\Gamma\left(\frac{\nu}{2}\right)\sqrt{\pi\nu}\left(1+\frac{t^2}{\nu}\right)^{(\nu+1)/2}},\quad -\infty<t<\infty
\]
Donde \(\Gamma\) representa la función gamma (cf. expresión 3.8).
El parámetro \(\nu\) de la distribución \(t\) coincide con el parámetro de la distribución ji cuadrado que le da origen. Dicho parámetro se denomina grados de libertad (gl) y representa el número de variables aleatorias normales estándar independientes involucradas en su definición (cf. tip 3.2).
La esperanza y la varianza de una variable aleatoria \(t\) se definen a partir de su parámetro \(\nu.\)
\[
\text{si}\; t\thicksim t_{(\nu)}\;\;\Rightarrow\;\; E(t) = 0,\: \text{para}\:\nu>1\;\;\text{y}\;\; V(t)=\frac{\nu}{\nu-2}, \:\text{para}\:\nu>2
\]
Al igual que la normal estándar, la distribución \(t\) es simétrica, con forma de campana y centrada en cero, aproximándose asintóticamente al eje horizontal cuando se aleja de la media en cualquier dirección.
Las probabilidades en las colas de la distribución \(t\) son mayores que en la distribución normal estándar; en consecuencia, se dice que la \(t\) es una distribución de colas pesadas o leptocúrtica (cf. sección 2.1.3.2). Esta diferencia se hace más pequeña en la medida en que aumentan sus grados de libertad. En muchos de los textos que incluyen valores tabulares de la distribución \(t,\) estos se presentan únicamente para distribuciones que tengan hasta 30 gl; para valores de \(\nu\) por encima de 30, se aproximan mediante los correspondientes valores de la distribución normal estándar.
La figura 3.14 —en la cual \(\nu=\infty\) equivale a la normal estándar— ilustra este comportamiento.

Usando R es posible obtener valores de la función de distribución, de la función de supervivencia, así como de sus respectivas inversas. Para la función de distribución acumulada se usa pt(q, df), siendo q el valor hasta el cual se desea acumular la probabilidad en una distribución \(t\) con df gl.
Teniendo en cuenta lo anterior, intente definir la instrucción en R para realizar el siguiente cálculo.
Probabilidad de obtener un valor menor que −2 en una distribución \(t\) con 10 gl
pt(-2, 10)Para calcular la probabilidad de obtener un valor mayor (función de supervivencia), se agrega el argumento lower.tail = F.
Intente definir el código R que permite responder la siguiente pregunta:
¿Cuál es el valor que deja a su izquierda un área de 0.025, en una distribución \(t\) con 30 gl?
qt(0.025, 30)Y esta otra:
¿Cuál es el valor de una variable aleatoria \(t\) con 2 gl que deja a su derecha un área de 0.01?
qt(0.01, 2, lower.tail = F)3.7.4 Distribución \(F\)
Como parte de los desarrollos asociados con el análisis de varianza, el estadístico inglés Ronald Aylmer Fisher desarrolló en la década de 1920 un estadístico que hoy se conoce como \(F.\) No obstante, fue Snedecor quien posteriormente consideró que era más conveniente tabular la razón de varianzas; a dicha razón la llamó \(F\) en honor a Fisher. Por tal motivo a esta distribución suele denominársele \(F\) de Snedecor, \(F\) de Fisher o \(F\) de Fisher-Snedecor.
La distribución \(F\) surge de la razón entre dos variables aleatorias ji cuadrado independientes entre sí, dividiendo cada una de ellas entre sus grados de libertad. La variable aleatoria \(F\) hereda los grados de libertad de ambas distribuciones. A tales parámetros se les llama grados de libertad del numerador y grados de libertad del denominador.
\[
\begin{align}
\text{si}\; \chi_{m}^2 \thicksim \chi_{(m)}^2,\: \chi_{n}^2 \thicksim \chi_{(n)}^2\;\;&\text{y}\;\;
\chi_{m}^2 \: \text{y} \: \chi_{n}^2\;\text{son independientes},\\[1.4em]
\frac{\chi_{m}^2/m}{\chi_{n}^2/n} &\thicksim F_{(m,\,n)}
\end{align}
\tag{3.9}\]
La función densidad de probabilidad de una variable aleatoria \(F_{(m,\,n)}\) es:
\[
f(x)=\frac{\left(\frac{m}{n}\right)^{m/2}\:\Gamma\left(\frac{m+n}{2}\right)}{\Gamma\left(\frac{m}{2}\right)\Gamma\left(\frac{n}{2}\right)}
\frac{x^{(m/2)-1}}{\left(1+\frac{m}{n}x\right)^{(m+n)/2}},\quad x>0
\]
Donde \(\Gamma\) representa la función gamma, tal y como se definió en la expresión 3.8.
\[
\begin{align}
&\text{si}\;F \thicksim F_{(m,\,n)}\\[1.4em]
\Rightarrow\;\; E(F)&=\frac{n}{n-2},\;\;\text{para}\; n>2,\\[1.4em]
V(F)&=\frac{2n^2(m+n-2)}{m(n-2)^2(n-4)},\;\; \text{para}\; n>4
\end{align}
\]
Al tratarse de la razón entre dos variables aleatorias cuyo rango es positivo, la variable aleatoria \(F\) solamente toma valores positivos. En la figura 3.15 se aprecia la diversidad de formas que puede asumir esta distribución, en función de sus parámetros.

La obtención de los valores de la correspondiente función de distribución, de la función de supervivencia, así como de sus respectivas inversas es un asunto sencillo, usando R. Para la función de distribución acumulada se usa pf(q, df1, df2), siendo q el valor hasta el cual se desea acumular la probabilidad en una distribución \(F\) con df1 y df2 grados de libertad para el numerador y el denominador, respectivamente.
Intente definir el código R que permite responder la siguiente pregunta:
¿Cuál es probabilidad de obtener un valor menor que 0.5 en una distribución \(F\) con 15 y 10 gl?
pf(0.5, 15, 10)Para calcular la probabilidad de obtener un valor mayor (función de supervivencia), se agrega el argumento lower.tail = F.
Para averiguar cuál es el valor de una variable aleatoria \(F\) que acumula una probabilidad determinada se usa la correspondiente función cuantil: qf.
Intente definir el código R que permite responder la siguiente pregunta:
¿cuál es el valor que deja a su izquierda un área de 0.1, en una distribución \(F\) con 7 y 19 gl?
qf(0.1, 7, 19)Y esta otra:
¿Cuál es el valor de una variable aleatoria \(F\) con 8 y 4 gl que deja a su derecha un área de 0.05?
qf(0.05, 8, 4, lower.tail = F)3.8 Probabilidades y valores críticos en R
¿¡Tablas estadísticas!?
Gracias a las facilidades que ofrecen programas como R, las tablas estadísticas pasaron a ser herramientas del pasado. Y aunque fueron de mucha utilidad en su momento —como también lo fueron las calculadoras y las reglas de cálculo— dejan de tener sentido en la actualidad.
Este cambio de paradigma conlleva cambios incluso en el lenguaje. Durante mucho tiempo se hizo referencia a los valores tabulares, por cuanto eran obtenidos de tablas. Si se tiene en cuenta que en la actualidad tales valores ya no se obtienen de tablas, esta denominación deja de tener sentido.
Las tablas venían esencialmente en dos formatos: función de distribución acumulada (cf. expresiones 3.3 y 3.4) y valores críticos.
Las tablas de la binomial y la normal estándar solían presentarse en el formato de función de distribución acumulada, debido a que los ejercicios relacionados con cálculos de probabilidades a partir de estas dos distribuciones no podían faltar en los cursos básicos de probabilidad y estadística.
Para las distribuciones ji cuadrado, \(t\) y \(F\) —que se usaban principalmente en el contexto inferencial— resultaba más práctico tabular los valores críticos.
Esta diversidad de funciones y formatos obligaba a que los cursos dedicaran mucho tiempo al manejo de las tablas, restándole tiempo a cuestiones más sustanciales.
R cuenta con funciones que permiten obtener probabilidades y valores críticos de un amplio conjunto de distribuciones (todas las de interés en el contexto inferencial clásico y muchas más). El nombre de todas las funciones para calcular probabilidades comienza con la letra p, mientras que el de las funciones para calcular valores críticos o cuantiles (quantiles) comienza con la letra q.
También se cuenta con funciones que permiten calcular el valor \(f(x)\) (density), las cuales comienzan con la letra d. Aunque su resultado no tenga interpretación en las distribuciones continuas, puede resultar útil para graficar la curva de densidad9.
Asimismo, R proporciona funciones para generar muestras seudoaleatorias10 (random numbers), las cuales comienzan con la letra r. Estas muestras son de gran utilidad en estudios de simulación.
Los nombres de todas las funciones relacionadas con distribuciones probabilísticas se construyen agregándole a la letra que determina su uso (p, q, d, r) una cadena de caracteres que identifica la distribución (binom, norm, chisq, t, f). La tabla 3.1 resume las funciones de interés en el contexto inferencial clásico.
| Distribución | Probabilidad acumulada | Cuantiles | \(f(x)\) | Números seudoaleatorios |
|---|---|---|---|---|
| Binomial | pbinom |
qbinom |
dbinom |
rbinom |
| Normal | pnorm |
qnorm |
dnorm |
rnorm |
| Ji cuadrado | pchisq |
qchisq |
dchisq |
rchisq |
| \(t\) | pt |
qt |
dt |
rt |
| \(F\) | pf |
qf |
df |
rf |
Las funciones esenciales en el contexto inferencial son las de probabilidad (p) y las de cuantiles (q). Estas funciones traen por defecto el argumento lower.tail = TRUE, con lo cual la acumulación se realiza desde la cola izquierda. Para obtener áreas a la derecha o calcular valores críticos superiores, se especifica el argumento lower.tail = FALSE.
Funciones de probabilidad. Inician con la letra
p. Permiten calcular probabilidades acumuladas, bien sea acumulando desde la izquierda (lower.tail = T) o hacia la derecha (lower.tail = F). Tienen como primer argumento un valor de la variable aleatoria que acumula la probabilidad (q); seguidamente aparecen los argumentos correspondientes a los parámetros específicos de la función y finalmente, el argumentolower.tail.Funciones cuantil. Inician con la letra
q. Permiten calcular valores críticos inferiores (lower.tail = T) o superiores (lower.tail = F). Tienen como primer argumento el valor de la probabilidad acumulada (p), luego aparecen los argumentos correspondientes a los parámetros específicos de la función y finalmente, el argumentolower.tail.
La tabla 3.2 presenta los argumentos particulares de cada función.
| Función | Argumentos | Valor por defecto | Significado |
|---|---|---|---|
pbinom |
|
|
|
qbinom |
|
|
|
pnorm |
|
|
|
qnorm |
|
|
|
pchisq |
|
|
|
qchisq |
|
|
|
pt |
|
|
|
qt |
|
|
|
pf |
|
|
|
qf |
|
|
|
¡No están solas!
En adición a los argumentos presentados en la tabla 3.2, las funciones de las familias ji cuadrado, \(t\) y \(F\) incluyen el argumento ncp, que hace referencia al parámetro de no centralidad (cf. Distribuciones no centrales).
Aunque las distribuciones no centrales desempeñan un importante rol en la evaluación de la potencia de las pruebas estadísticas, no están presentes en la aplicación de las técnicas inferenciales. Consecuentemente, cuando se usan las funciones de estas familias, se mantiene el valor por defecto para este argumento (ncp = 0), con lo cual se invocan las distribuciones centrales que son las usadas en las aplicaciones inferenciales.
Debe tenerse presente, sin embargo, que el argumento ncp siempre aparece antes que el argumento lower.tail, por lo cual no es posible omitir el nombre del argumento lower.tail cuando se haga referencia al mismo (cf. R paso a paso: Argumentos de las funciones), a riesgo de que, por posición, el valor ingresado no se le asigne al argumento lower.tail, sino al argumento ncp.
Otro posible factor de confusión surge del hecho de que las funciones mencionadas también incluyen un argumento llamado log.p, lo que exige usar al menos las tres primeras letras del argumento lower.tail (low) para obtener una adecuada coincidencia parcial (cf. R paso a paso: Argumentos de las funciones).
En concreto, para usar el argumento lower.tail es necesario escribir su nombre o al menos sus tres primeras letras (low).
3.9 Inferencia estadística
En sentido amplio, puede decirse que la inferencia estadística comprende el conjunto de técnicas mediante las cuales se generalizan las características muestrales a las correspondientes poblaciones, con una estimación objetiva del nivel de incertidumbre que acompaña dicho proceso.
Aunque sería ideal poder realizar esta generalización de la manera más simple posible, esto es, aprehendiendo la naturaleza de la población, tras la inspección de la muestra, sin pasar por abstrusas conceptualizaciones, la experiencia ha enseñado que esta no es la senda del método científico.
En los procesos inferenciales participan entes reales evaluados en campo o laboratorio, así como constructos matemáticos que permiten modelar los anteriores. Algunos tienen nombres y símbolos iguales o parecidos, siendo necesario diferenciarlos para evitar confusiones. A continuación, se aclaran los conceptos de variable, población, muestra y estadístico en el contexto inferencial.
Variable: Por una parte, están las variables de campo —frecuentemente denominadas variables respuesta en el contexto inferencial— tal y como se definieron en la sección 1.2. Corresponden a las características observadas, medidas o registradas sobre las unidades.
Por otra parte, se tienen las variables aleatorias, las cuales, acorde con la definición 3.11, son funciones que tienen como dominio el espacio muestral de un experimento aleatorio y como rango los números reales.
Población: El concepto de población es quizá el que más acepciones tiene, puesto que aparece en disciplinas tan diversas como la ecología, la demografía, la astronomía y la estadística. En el contexto de la estadística inferencial se manejan dos conceptos de población: por una parte, la población de campo y por otra, la población teórica.
La definición de población de campo parte de la presentada en el contexto descriptivo (cf. sección 1.3), donde se define la población como el conjunto de todas las unidades poseedoras de una o más características comunes; no obstante, para fines inferenciales, tal concepto no se refiere a las unidades o individuos poseedores de la característica de interés, sino a la expresión de una característica particular sobre tales unidades.
Consecuentemente, cuando se plantea el modelo inferencial, no se habla de una población de árboles, sino de una población de diámetros, una población de alturas, una población de densidades de madera, una población de edades, etc.; cada una de tales poblaciones exigirá un manejo particular.
La población teórica está definida como el conjunto de todas las variables aleatorias que tienen una distribución común \(f(x);\) es a tal conjunto al que se hace referencia cuando se menciona, por ejemplo, una población normal con parámetros \(\mu\) y \(\sigma^2.\)
Muestra: Desde el punto de vista de la estadística matemática, una muestra aleatoria de tamaño \(n\) es un conjunto de variables aleatorias \(X_1, X_2,\dotsc, X_n\) de la población \(f(x),\) mutuamente independientes, tales que sus distribuciones marginales sean la misma función \(f(x).\) Esto puede expresarse equivalentemente como un conjunto de variables aleatorias igual e independientemente distribuidas \(f(x).\)
En el contexto de campo, una muestra aleatoria es un subconjunto de una población de campo, elegido al azar; en otras palabras, un conjunto de lecturas de una variable de campo, registradas sobre un conjunto de unidades elegidas al azar.
Estadístico: Los estadísticos de campo, acorde con lo presentado en la sección 2.1, son índices numéricos que resumen la información contenida en una muestra.
En contraste, los estadísticos teóricos son variables aleatorias que a menudo surgen de combinar variables aleatorias elementales. En el contexto inferencial suele denomináreseles estadísticos de prueba (cf. definición 3.41), y constituyen la base de los procesos inferenciales.
La tabla 3.3 sintetiza los conceptos anteriores.
| Concepto | Campo | Teórico |
|---|---|---|
Variable |
Variable de campo Características observadas, medidas o registradas |
Variable aleatoria Función que mapea resultados del espacio muestral en los reales |
Población |
Población de campo Conjunto de todos los resultados de una variable de campo |
Población teórica Universo probabilístico que modela la característica de interés mediante variables aleatorias independientes con distribución común |
Muestra aleatoria |
Muestra aleatoria de campo Subconjunto —elegido al azar— de los resultados una variable de campo |
Muestra aleatoria teórica Conjunto de variables aleatorias igual e independientemente distribuidas, seleccionadas de la población teórica |
Estadístico |
Estadístico de campo Valor numérico que resume la información contenida en la muestra de campo |
Estadístico teórico Variable aleatoria, cuya distribución, bajo ciertas condiciones, es conocida |
La figura 3.16 esquematiza la manera en la que se comunican los diferentes elementos del proceso inferencial entre el mundo teórico y el aplicado.
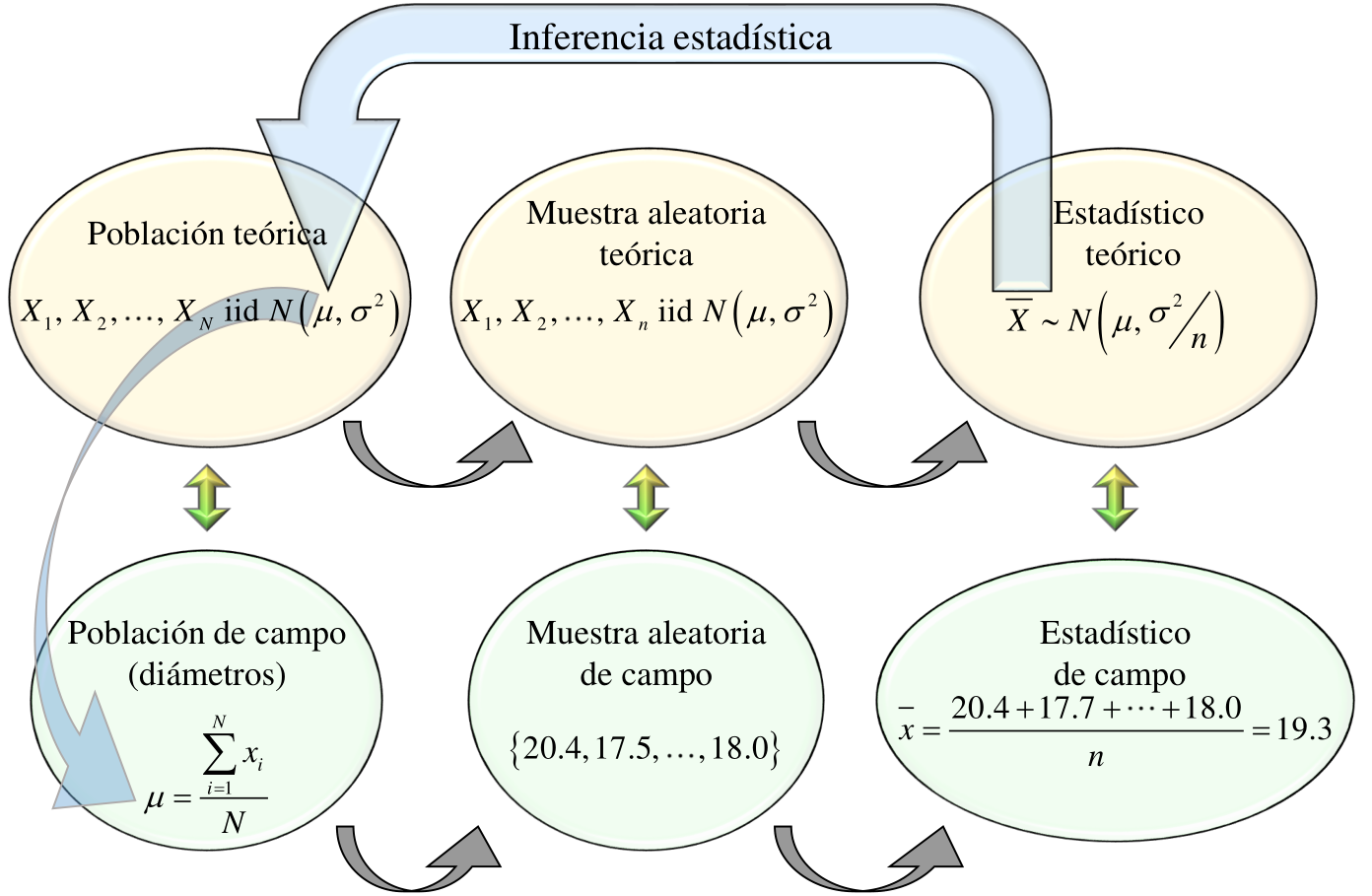
En la parte inferior de la figura 3.16 se presentan tres elipses con los conceptos de campo. En correspondencia con estos, en la parte superior se presenta el mismo número de elipses con los equivalentes conceptos teóricos, los cuales actúan como modelo de los conceptos de campo.
En la elipse inferior izquierda se encuentra la población de campo que constituye el objeto de la inferencia estadística aplicada. Para fines inferenciales, una población de campo está constituida por el conjunto de todas las expresiones de una variable de campo en el grupo de interés. En la figura 3.16 se ejemplifica una población de diámetros.
Aunque es posible definir y conceptualizar las poblaciones de campo, no se tiene certeza sobre el valor de sus parámetros11, los cuales siempre son desconocidos, por lo cual, el investigador se ve en la necesidad de responder las preguntas relacionadas con estos a partir de información muestral. En la elipse inferior izquierda, se usa la media, \(\mu,\) de todos los diámetros para ejemplificarlo.
¿Muestreo o censo?
Los parámetros poblacionales únicamente llegarían a conocerse si se realizara un censo poblacional, lo cual resulta imposible en la mayoría de los casos, puesto que las poblaciones objetivo son infinitas o cuasi infinitas.
Aun en poblaciones finitas, los censos suelen ser ineficientes y poco prácticos para los fines investigativos, representando, por lo general, un gasto innecesario de recursos. En otras áreas, como la tributaria, por ejemplo, los censos están plenamente justificados.
Cuando se realiza un censo en lugar de un muestreo, no hay lugar a la aplicación de técnicas inferenciales; únicamente se aplican técnicas descriptivas12.
El proceso inferencial parte de la modelación del comportamiento distribucional de las poblaciones de campo a través de poblaciones teóricas, especialmente la normal. En el ejemplo que se presenta en la figura 3.16 se supone que el comportamiento distribucional de la población de diámetros puede ser modelado mediante una población normal con parámetros \(\mu\) y \(\sigma^2.\)
Las preguntas planteadas por el investigador acerca de los parámetros de las poblacionales de campo se responden a través de postulados estadísticos sobre los parámetros de las poblaciones teóricas que les sirven de modelo. Si en el presente ejemplo, un investigador tuviera interés en averiguar el valor de la media, \(\mu,\) de la población de diámetros, debería empezar por estimar el valor del correspondiente parámetro en la población normal que le sirve de modelo.
¿Es una variable o son \(N\) variables?
Aunque en lenguaje no inferencial se está ejemplificando una variable (el diámetro), la población teórica que se usa como modelo está conformada por un conjunto de \(N\) variables aleatorias.
Esto se debe a que —para fines de la modelación— cada posible resultado de la variable de interés en campo (cada diámetro) tiene una variable aleatoria como contraparte teórica.
Para responder la pregunta sobre \(\mu,\) se toma una muestra aleatoria en campo (elipse central inferior), la cual aparece ejemplificada en la figura 3.16 mediante un conjunto de lecturas específicas de diámetros. El comportamiento distribucional de la muestra aleatoria de campo se modela con base en una muestra aleatoria teórica (elipse central superior).
Con base en la muestra aleatoria de campo se calcula un estadístico de campo (elipse inferior derecha: para el ejemplo, \(\bar{x} = 19.3\)), el cual tiene como contraparte un estadístico teórico, el cual aparece representado por \(\overline{X}\) en la elipse superior derecha. El estadístico teórico es una variable aleatoria con distribución probabilística conocida.
La estadística inferencial suministra las herramientas para realizar afirmaciones sobre parámetros de una población teórica —v. g., la media, \(\mu,\) de una población normal— a partir de estadísticos obtenidos de muestras aleatorias teóricas. La ilustración de la figura 3.16 sugiere que, el hecho de saber que el estadístico \(\overline{X}\) sigue una distribución \(N(\mu,\,\sigma^2/n)\) puede usarse para responder preguntas sobre la media, \(\mu,\) de la población normal. Este proceso está representado por la flecha que une \(\overline{X}\) con \(\mu.\)
Finalmente, puesto que la población teórica constituye un modelo de la población de campo, se espera que las conclusiones sobre el parámetro \(\mu\) de la distribución normal sean igualmente válidas para el parámetro \(\mu\) de la población de diámetros, lo cual queda representado por la flecha que va desde el parámetro \(\mu\) de la elipse superior izquierda hasta el parámetro \(\mu\) en la elipse inferior izquierda. De esta manera se cierra el ciclo inferencial, presentando todas las conclusiones en términos de la población de campo.
¡Concluya en términos de la población objetivo!
Si bien los modelos teóricos permiten expresar las conclusiones en términos probabilísticos referidos a las poblaciones teóricas, tanto las preguntas de investigación aplicada como sus correspondientes respuestas deben referirse a las poblaciones de campo.
¿¡En qué mundo estoy!?
La inferencia estadística se mueve entre el mundo teórico y el práctico. Al exponer los conceptos de la inferencia estadística suele fallarse en presentar un panorama integrado de estos dos mundos.
Los textos más formales que describen los mecanismos de la inferencia estadística se centran en el mundo teórico (las tres elipses superiores de la figura 3.16), sin que sea fácil visualizar la forma en la que esto pueda vincularse con la investigación aplicada.
Por otra parte, los textos más aplicados a menudo obvian los aspectos intrínsecos de las herramientas inferenciales, lo que impide que el usuario capte los alcances y limitaciones de las mismas, excluyendo la posibilidad de que realice adaptaciones, acorde con sus necesidades.
En el presente texto se ha buscado equilibrar estos dos componentes, presentando los mecanismos intrínsecos de la estadística inferencial, pero teniendo presente que el objetivo último son las poblaciones de campo.
Aun teniendo consciencia de los dos ámbitos involucrados en todo proceso inferencial, resultaría muy recargado presentar en cada caso una descripción tan completa como la realizada sobre el hipotético ejemplo de la figura 3.16.
De hecho, los adjetivos de campo y teórico se han tomado del lenguaje cotidiano y se han usado aquí para diferenciar conceptos que la mayoría de las veces aparecen con el mismo nombre. Esto da lugar a que, en el mejor de los casos, se diferencien por el contexto, y en muchos otros, se confundan.
En este libro usaremos los nombres simplificados siempre que el contexto sea lo suficientemente claro. Así evitaremos recargar innecesariamente las exposiciones. No obstante, se acudirá a las etiquetas diferenciadoras siempre que sea necesaria la precisión conceptual.
Clasificación de técnicas inferenciales
Sea cual sea el marco conceptual, las poblaciones de campo se modelan con base en poblaciones teóricas caracterizadas por uno o más parámetros. El enfoque desarrollado hasta el momento corresponde a la inferencia estadística clásica o frecuentista. En este marco conceptual los parámetros se consideran constantes desconocidas, y cualquier aproximación a los mismos puede lograrse únicamente a través de la información muestral.
En contraste, en el marco conceptual de la inferencia bayesiana los parámetros son considerados variables aleatorias, cuyo comportamiento está regido por una distribución probabilística denominada distribución previa (a priori), la cual es postulada por el investigador a partir del conocimiento o las expectativas que tenga sobre el fenómeno, antes de acceder a la información muestral. Una vez obtenida la muestra, se usa la información contenida en esta para actualizar el modelo probabilístico, dando lugar a la denominada distribución posterior (a posteriori), con base en la cual se realiza la inferencia.
En este libro se considera exclusivamente el enfoque clásico o frecuentista.
La inferencia estadística puede estar dirigida a responder preguntas sobre alguno de los parámetros de la distribución probabilística de una o más poblaciones o sobre la distribución misma. A las pruebas mediante las cuales se evalúa lo adecuado o inadecuado que resulta modelar una población de campo mediante una distribución probabilística específica se les denomina pruebas de bondad de ajuste. El principal uso de estas pruebas en investigación aplicada es el de verificar supuestos distribucionales en las pruebas de interés central (cf. sección 4.1).
Las pruebas centrales suelen enfocarse en algún parámetro específico de la distribución probabilística teórica, motivo por el que suele denominárseles pruebas paramétricas. En contraste, las pruebas no paramétricas o pruebas de libre distribución no parten de la modelación de las poblaciones de campo mediante una distribución probabilística específica.
La figura 3.17 esquematiza la clasificación presentada para las técnicas inferenciales.

En términos generales, la inferencia estadística se basa en dos conjuntos de herramientas: la estimación y las pruebas de hipótesis.
Las herramientas de estimación brindan información en estudios de diagnóstico en los que se conoce poco sobre los parámetros de interés. Estas permiten responder preguntas de tipo general: ¿en qué región es más probable que se encuentre el parámetro? (intervalo de confianza), ¿cuál sería la mejor apuesta que podría hacerse sobre el valor del parámetro poblacional, con base en la información muestral? (estimación puntual). La respuesta a tales preguntas constituye un importante insumo para la caracterización de una población.
Cuando ya se tiene algún conocimiento del fenómeno, se realizan estudios confirmatorios en los que se plantean preguntas dirigidas sobre el valor del parámetro, en forma de juegos de hipótesis que consideran dos regiones complementarias y mutuamente excluyentes para el parámetro en cuestión.
Así, por ejemplo, si se está adelantando un estudio, uno de cuyos objetivos sea evaluar el rendimiento medio de un proceso bioquímico, el investigador podría definir las dos regiones siguientes: rendimiento medio ≤ 55 g/L; rendimiento medio > 55 g/L. El límite de tales regiones se definirá acorde con los conocimientos previos y con los objetivos del estudio. La información muestral puede ayudar a respaldar alguna de las hipótesis y constituir un argumento en contra de la otra.
Asimismo, las pruebas de hipótesis permiten resolver una pregunta especialmente relevante en investigación: ¿existe diferencia entre los parámetros de dos o más poblaciones?
El uso de una u otra herramienta depende de los objetivos específicos de la investigación y, en no pocas ocasiones, estos dos enfoques de la inferencia estadística resultan complementarios.
3.9.1 Estimación
Comprende el conjunto de técnicas inferenciales que permiten, en términos generales, responder cuál podría ser el valor de un parámetro poblacional o en qué región podría estar ubicado. En consonancia con el tipo de respuesta, se habla de estimación puntual o por intervalos.
¿Esto es teórico o práctico?
Sin olvidar que los constructos teóricos actúan como modelos de las correspondientes entidades en campo, de momento nos concentraremos en ilustrar los procesos inferenciales sobre los parámetros de las poblaciones teóricas. En los siguientes capítulos se ejemplifica la relación entre los conceptos teóricos y los de campo.
3.9.1.1 Estimación puntual
La estimación puntual consiste en usar un estadístico muestral13 para representar un parámetro poblacional desconocido.
Aunque —tal y como su nombre lo indica— la estimación puntual se realiza mediante un valor único o puntual, la posible elección de dicho valor no es única.
Existen varios métodos para generar estimadores y varios criterios para evaluar la adecuación de los mismos. El análisis a profundidad de tales métodos y criterios es un aspecto teórico que puede estudiarse en textos dedicados a dicha temática, como el de Casella y Berger (2002).
Los métodos más populares para la generación de estimadores incluyen el método de los momentos y el de máxima verosimilitud. En otros marcos conceptuales, como el bayesiano, se emplean estrategias de estimación basadas en distribuciones posteriores.
Entre los criterios clásicos para evaluar la bondad de un estimador están el insesgamiento y la mínima varianza. Tales criterios conducen a la definición del mejor estimador insesgado.
¿Qué se gana con el insesgamiento?
En el ámbito práctico, si un investigador usara un estimador insesgado un gran número de veces, el promedio de sus estimaciones será igual al parámetro estimado.
¿Y con la varianza mínima?
Cuando se tiene un estimador de mínima varianza, se espera que las estimaciones realizadas a través del mismo se encuentren en promedio más cercanas al valor del parámetro estimado que las realizadas mediante cualquier otro estimador.
En razón de las ventajas de los mejores estimadores insesgados, la práctica más común consiste en elegirlos como estimadores de los parámetros poblacionales de interés.
¿Siempre conviene usar los mejores estimadores insesgados!?
Aunque eventualmente podría considerarse otro grupo de estimadores, tales como aquellos que tienen un sesgo pequeño y alta precisión, en este texto nos ceñiremos a los estimadores clásicos, es decir, a los mejores estimadores insesgados.
La figura 3.18 ilustra los conceptos de insesgamiento y mínima varianza.




Los paneles de la figura 3.18 representan blancos de tiro. El punto central o diana representa el parámetro que se estima. Cada uno de los puntos rojos (o intentos de acertarle a la diana) representa estimaciones del parámetro. Cuando se analizan las propiedades de un estimador, no interesan los aciertos particulares, sino el comportamiento general del estimador.
La figura 3.18 (a) representa un estimador que, a pesar de ser insesgado es muy poco preciso. Si bien es cierto que el promedio de un gran número de estimaciones realizadas a través de este estimador es igual al valor del parámetro, la amplia dispersión del estimador en cuestión hace que su desempeño no sea muy satisfactorio.
La figura 3.18 (b) representa una serie de estimaciones realizadas mediante un estimador sesgado y variable. Este estimador tiene todas las características indeseables de un estimador: además de ser muy poco preciso, su valor esperado no es igual al parámetro que se está estimando.
La figura 3.18 (c) representa las estimaciones realizadas mediante un estimador sesgado y poco variable. A pesar de que las estimaciones realizadas mediante tal estimador están muy concentradas, no lo están alrededor del parámetro que pretenden estimar; la esperanza de tal estimador difiere del parámetro.
La figura 3.18 (d) representa las estimaciones realizadas por un estimador insesgado y poco variable. Este es el estimador ideal. Además de que la esperanza del estimador es igual al parámetro que se estima, es más probable que las estimaciones generadas se encuentren cerca del parámetro.
3.9.1.1.1 Estimación puntual de \(\mu\)
El mejor estimador insesgado de \(\mu\) es \(\overline{X}.\) Esto quiere decir que ningún otro estimador insesgado de \(\mu\) tiene menor varianza que \(\overline{X}.\) Por tal motivo, \(\overline{X}\) desempeña un papel central en las técnicas inferenciales basadas en la distribución normal.
¿Entonces, la media es la mejor opción?
Nótese que \(\mu\) es el parámetro de posición de una población normal. Si la población de campo no puede ser modelada adecuadamente mediante una distribución normal, la media muestral no constituirá necesariamente la mejor elección para estimar la media de la población de campo; en tales casos, la mediana puede cobrar relevancia.
3.9.1.1.2 Estimación puntual de \(\sigma^2\)
A menudo se tiene interés en estimar la varianza \(\sigma^2\) de una población normal, la cual está definida como el segundo momento central, es decir, la esperanza de las desviaciones cuadráticas a la media:
\[
\begin{align}
V(X)&=E\left[\left(X-\mu\right)^2\right]\\[1.4em]
&=\int\limits_{-\infty}^{\infty}\left(x-\mu\right)^2f(x)\,dx\\[1.4em]
&=\int\limits_{-\infty}^{\infty}\left(x-\mu\right)^2\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{\left(x-\mu\right)^2}{2\sigma^2}}\,dx\\[1.4em]
&=\sigma^2
\end{align}
\]
El parámetro equivalente en una población de campo, cuyo valor se infiere a través del parámetro de la normal es:
\[
\sigma^2=\sum\limits_{i=1}^{N}\frac{\left(x_i-\mu\right)^2}{N}
\]
¿Y, por qué no…?
En la sección 2.1.2.1, al presentar la varianza muestral, se sugiere la posibilidad de trabajar con desviaciones en valor absoluto, en lugar de desviaciones cuadráticas.
Se indica que, si bien dicha alternativa resulta válida para la construcción de una medida de dispersión, resulta más práctico trabajar con las desviaciones cuadráticas por razones teóricas.
La razón es que el uso de desviaciones cuadráticas hace posible modelar la varianza de la población de campo, mediante la varianza de una población normal.
Un estimador intuitivo de la varianza es el correspondiente a la siguiente expresión:
\[
\widehat{\sigma}^2=\sum\limits_{i=1}^{n}\frac{\left(X_i-\overline{X}\right)^2}{n}
\tag{3.10}\]
Aunque, en efecto, la expresión 3.10 constituye un estimador válido de \(\sigma^2\) (este es el estimador de máxima verosimilitud), su esperanza es diferente de \(\sigma^2\), lo que lo excluye del grupo de los estimadores insesgados.
El problema del sesgo se corrige remplazando el denominador \(n\) de la expresión 3.10 por \(n-1\), lo que da lugar a la siguiente expresión:
\[
S^2=\frac{\sum\limits_{i=1}^{n}{\bigl(X_i-\overline{X}\,\bigr)^2}}{n-1}
\tag{3.11}\]
\(S^2\) es un estimador insesgado de la varianza. Esto explica el uso del denominador \(n−1,\) en lugar de \(n,\) para el cálculo de la varianza muestral (cf. expresión 2.1).
El estimador \(S^2\), además de ser insesgado es el que exhibe la menor varianza.
3.9.1.1.3 Estimación puntual del parámetro \(p\) de una binomial
El mejor estimador insesgado de \(p\) es \(\widehat{p}=X/n,\) esto es, la proporción observada de éxitos en un experimento binomial de tamaño \(n.\)
En concreto…
Estos son los parámetros más usados en inferencia estadística, con sus correspondientes estimadores insesgados de varianza mínima.
| Parámetro | Mejor estimador insesgado |
|---|---|
| \(\mu\) | \(\overline{X}\) |
| \(\sigma^2\) | \(S^2\) |
| \(p\) | \(\widehat{p}\) |
3.9.1.2 Estimación por intervalos
Cuando se usa esta modalidad de estimación, en lugar de un valor puntual, se usa un intervalo como estimador del parámetro, lo que posibilita asignarle una confianza a la estimación. Consecuentemente, este tipo de estimadores se denominan intervalos de confianza.
¿Es lo mismo confianza que probabilidad?
La confianza a la que se hace mención no es otra cosa que una probabilidad expresada porcentualmente.
Puede afirmarse que un intervalo de confianza del \(100(1−\alpha)\,\%\) para el parámetro \(\theta\) incluirá al parámetro \(\theta\) con probabilidad \((1 − \alpha).\)
¡Cuide la forma!
Desde el punto de vista clásico (no bayesiano), los parámetros son constantes; no variables aleatorias. En consecuencia, resulta un tanto desconcertante hacer referencia a la probabilidad de que el intervalo contenga el parámetro, puesto que el concepto de probabilidad es aplicable solamente a variables aleatorias; no a constantes (cf. sección 3.5).
La interpretación presentada es correcta, sin embargo, si se tiene en cuenta que el intervalo de confianza está definido como un intervalo aleatorio, es decir, un intervalo cuyos límites son variables aleatorias.
Es importante prestar atención la forma de expresarlo, pues una ligera variación puede dar lugar a un sinsentido.
Así, por ejemplo, desde el punto de vista clásico, resulta incorrecto afirmar que “la probabilidad de que el parámetro caiga dentro del intervalo es \((1 − \alpha)\)“, pues ello equivaldría a afirmar que se tiene un intervalo fijo y que el parámetro —como variable aleatoria— puede o no tomar valores dentro de dicho intervalo.
La figura 3.19 ilustra tales conceptos.
La confianza con la que se construyen los estimadores por intervalo es elegida por el usuario, acorde con sus necesidades. Usualmente se trabaja con confianzas altas (por encima del 90%).
¿Mientras más confiable mejor?
Podría pensarse en optar siempre por la mayor confianza posible. Sin embargo, la contraparte de la confianza es la precisión, la cual tiene que ver con la amplitud del intervalo.
Para un intervalo construido mediante una técnica determinada, con base en la información de una muestra dada, a mayor confianza, menor precisión, es decir, intervalos más amplios.
Supóngase que se desea estimar la edad del universo y que, utilizando diferentes métodos, se obtienen las siguientes tres estimaciones por intervalo:
- Estimación 1: [2 mil millones de años, 50 mil millones de años]
- Estimación 2: [13 700 millones de años, 13 800 millones de años]
- Estimación 3: [13 793.45 millones de años y 3 días, 13 793.45 millones de años y 5 días]
La estimación 1 brinda alta confianza, pero baja precisión. Es casi seguro (confianza superior al 99.99%) que dicho intervalo contiene la edad del universo. Sin embargo, el intervalo es tan amplio (poco preciso), que pierde toda utilidad.
La estimación 3 por su parte es altamente precisa; prácticamente determina el momento exacto del big bang. Sin embargo, es muy poco probable (baja confianza) que la edad del universo esté contenida en dicho intervalo.
Por su parte, la estimación 2 constituye un compromiso entre la 1 y la 3: tiene una precisión intermedia y, por consiguiente, una confianza intermedia.
¡Solo puede confiarse en los intervalos!
El concepto de confianza estadística únicamente tiene sentido en la estimación por intervalo.
Si se considera un caso aun más extremo que el del estimador 3, donde la amplitud del intervalo sea cero, se llega a una estimación puntual, a la cual no puede asociársele una confianza objetiva.
¿Qué se gana con la estimación por intervalo?
Los estimadores por intervalo resultan más informativos que los estimadores puntuales: proveen una región en la que probablemente se halle el parámetro y —a través de la precisión— dan un indicio de qué tan variable es la población y qué tanto se conoce sobre la misma.
¿Entonces, qué confianza se usa?
Al usar estimaciones por intervalo, la práctica usual consiste en utilizar intervalos de confianza del 95 %. Eventualmente, dependiendo de circunstancias particulares que se discutirán posteriormente podrían utilizarse otros intervalos, siendo los de 99 y 90 % los más comunes14.
Finalmente, vale la pena anotar que los estimadores por intervalo para un parámetro siempre contienen los correspondientes estimadores puntuales, aunque no necesariamente en el centro.
3.9.2 Pruebas de hipótesis
Las pruebas de hipótesis constituyen una de las herramientas estadísticas más utilizadas en investigación científica, puesto que forman parte de la mayoría de las técnicas inferenciales. Estas permiten tomar decisiones sobre hipótesis estadísticas a partir de la información muestral.
¡Circunscribamos!
Con el fin de desarrollar el marco conceptual de las pruebas de hipótesis, de momento dejaremos de lado las pruebas de hipótesis que involucran dos o más poblaciones, las que se usan en las denominadas pruebas de bondad de ajuste, así como las que se utilizan en el contexto no paramétrico.
Nos enfocaremos en las pruebas de hipótesis que se realizan sobre un parámetro de una población, en el marco inferencial paramétrico.
Las pruebas de hipótesis constituyen la herramienta inferencial que permite dictaminar sobre la plausibilidad de una u otra opción en dicho juego de hipótesis estadísticas, usando la información muestral como guía.
En general, un juego de hipótesis estadísticas para el parámetro poblacional \(\theta\) tiene el siguiente formato:
\[
\begin{align}
H_0&:\theta\in\Theta_0\\[0.7em]
H_a&:\theta\in\Theta_0^c
\end{align}
\tag{3.12}\]
En el anterior juego de hipótesis, \(\Theta\) representa el espacio paramétrico de \(\theta,\) es decir, el conjunto de todos los valores admisibles del parámetro \(\theta,\) mientras que \(\Theta_0\) representa un subconjunto de dicho espacio paramétrico y \(\Theta_0^c\) representa el subconjunto complementario.
En investigación científica, los juegos de hipótesis adquieren una de las siguientes formas:
| \(H_0:\theta\ge\theta_0\) | \(H_0:\theta=\theta_0\) | \(H_0:\theta\le\theta_0\) |
| \(H_a:\theta <\theta_0\) | \(H_a:\theta\ne\theta_0\) | \(H_a:\theta>\theta_0\) |
El juego de hipótesis ubicado en el centro se denomina no direccional, bilateral o de dos colas. Cada uno de los juegos de hipótesis ubicados en los extremos es direccional, unilateral o de una cola; en particular, el ubicado a la izquierda es de cola izquierda, mientras que el ubicado a la derecha es de cola derecha.
¿¡La cola!?
La denominación basada en las colas hace referencia a los extremos de la distribución probabilística usada para contrastar el juego de hipótesis.
El símbolo de desigualdad de la hipótesis alternativa sirve de ayuda nemotécnica, pues señala hacia la correspondiente cola de la distribución.
Tanto el valor hipotético \(\theta_0\) que constituye el referente de comparación15, como el tipo de prueba son elegidos por el investigador acorde con las particularidades del fenómeno estudiado, con el conocimiento que tenga del mismo y muy especialmente con el tipo de pregunta que desee responder.
Es importante notar que la hipótesis nula siempre incluye la posibilidad de igualdad entre el parámetro y el valor hipotético \(\theta_0.\)
¿¡Hipótesis nula!?
El nombre hipótesis nula se refiere a nulidad de efectos, es decir, a lo que está establecido para el parámetro, a lo que se conoce sobre el mismo, a lo estándar: no se mejoró el desempeño de un proceso, no disminuyeron los síntomas de una enfermedad, no se alteró el bienestar de una población animal, etc.
En contraste, la hipótesis alternativa, que consiste en el complemento y negación de la hipótesis nula, plantea la posibilidad de que el valor del parámetro difiera de dicho estándar; por consiguiente, que sí haya efecto.
¡Hipótesis de investigación!
En la mayoría de situaciones en las que se contrasta un juego de hipótesis, el investigador desea cambiar el paradigma (hipótesis nula) y probar que hubo algún efecto (hipótesis alternativa). En consecuencia, a la hipótesis alternativa suele llamársele hipótesis de investigación.
Para ilustrar el método de construcción y contraste de hipótesis estadísticas, considérese el siguiente ejemplo, adaptado del texto de Infante y Zárate (1990).
Ejemplo 3.2
Supóngase que una gitana afirma tener una capacidad extraordinaria para predecir el resultado del lanzamiento de un dado. Con el fin de probar dicha afirmación, se le pide que prediga el resultado del lanzamiento de un dado cúbico no cargado. Tras el lanzamiento, se contrasta el valor predicho con el valor obtenido.
Para el fin que nos concierne, el espacio muestral de este experimento consta de dos puntos: acierta, no acierta. Consecuentemente, se trata de un experimento Bernoulli. Si se define el acierto como éxito y el no acierto como fracaso, la variable aleatoria que modela el resultado del experimento sigue una distribución Bernoulli con parámetro \(p,\) siendo \(p\) la probabilidad de acertar.
\[
X\thicksim\text{Bernoulli}(p)
\]
Para contrastar la afirmación de la gitana, es necesario establecer un referente. ¿Cuál es la probabilidad que tiene cualquier persona de adivinar el resultado en un experimento de este tipo? Aplicando la definición clásica de probabilidad (cf. definición 3.8), se tiene que \(p = 1/6.\)
A continuación, debe expresarse la pretensión de la gitana sobre su capacidad extraordinaria en forma de una hipótesis estadística.
Si se pretendiera probar si la gitana es infalible, habría que probar que \(p = 1.\) No obstante, si nos ceñimos al sentido estricto de la palabra “extraordinaria”, podríamos aceptar como tal cualquier capacidad extra a la ordinaria, es decir, cualquier capacidad que supere a la ordinaria. Por tanto, una capacidad extraordinaria podrá expresarse en términos probabilísticos como \(p > 1/6.\)
El correspondiente juego de hipótesis está compuesto por las dos hipótesis siguientes:
\(H_0:p\le1/6\) (la gitana no tiene capacidad extraordinaria)
\(H_a:p>1/6\) (la gitana sí tiene capacidad extraordinaria)
Una regla de decisión intuitiva para dictaminar sobre las capacidades de la gitana con base en el resultado del experimento planteado sería la siguiente:
Respaldar la hipótesis alternativa si la gitana adivina
Respaldar la hipótesis nula si la gitana no adivina
Aunque esta pueda ser la mejor regla de decisión basada en los resultados del experimento planteado, existe la posibilidad de tomar una decisión errada, cualquiera que sea el resultado.
¡Siempre se puede errar!
Esta es una característica fundamental de la inferencia estadística: ¡siempre se tiene alguna probabilidad de errar al tomar una decisión!
Podría parecer, entonces, que la inferencia estadística no resulta de ninguna utilidad y que da igual hacer una afirmación estadística que una afirmación subjetiva. Esto, sin embargo, no es así: al hacer una afirmación estadística, con base en el seguimiento de ciertos protocolos, si bien existe una probabilidad de error, se establecen reglas que permiten cuantificarla y minimizarla.
Para el presente ejemplo, el cálculo de la probabilidad de error a partir del criterio de decisión descrito es directo. La probabilidad de atribuirle capacidades extraordinarias a la gitana sin que goce de ellas es \(1/6,\) mientras que la probabilidad de dejar pasar desapercibida alguna capacidad extraordinaria es menor de \(5/6.\)
Si un observador estuviera particularmente preocupado por la posibilidad de atribuirle por error una capacidad extraordinaria a la gitana, podría disminuir dicha probabilidad, exigiendo un mayor número de lanzamientos. ¿Sería posible establecer a partir de dos lanzamientos una regla que permitiera tomar una decisión con una probabilidad de error menor de 0.05?
De momento dejaremos de lado este ejemplo para continuar con el desarrollo conceptual de las pruebas de hipótesis; en la sección 3.9.2.2 se retomará para ilustrar algunos aspectos adicionales.
3.9.2.1 Decisiones en pruebas de hipótesis
Cuando la información muestral obtenida para contrastar un juego de hipótesis es incompatible con la hipótesis nula, esta se rechaza; en caso contrario, la hipótesis nula no se rechaza.
En muchas ocasiones, al no rechazo de la hipótesis nula se le llama “aceptación”. No obstante, este término ha sido muy criticado, puesto que, desde el punto de vista de la lógica, resulta inadecuado aceptar un postulado por el solo hecho de no existir argumentos suficientes en su contra: la ausencia de pruebas no es prueba de ausencia16.
Para ilustrar este aspecto, considérese el siguiente juego de hipótesis, que —aunque no sean estadísticas— sirven para nuestro propósito.
Por lo anterior, en lugar de hablar de aceptación de la hipótesis nula, suele hablarse de su no rechazo. Aunque esta forma de expresar los resultados de un juego de hipótesis exige realizar algunas piruetas lingüísticas y de decodificación del significado, tiene la ventaja de evitar contradicciones lógicas.
Los textos más formales manejan el lenguaje de rechazo/no rechazo de la hipótesis nula; mientras que en textos más aplicados es común encontrar esta dicotomía como rechazo/aceptación.
¿Entonces, no se puede “aceptar” la hipótesis nula?
Durante mucho tiempo, los estadísticos han intentado erradicar el término “aceptación de la hipótesis nula” del lenguaje de las pruebas de hipótesis, como si con ello se lograran erradicar las interpretaciones erróneas.
Infortunadamente, esta estrategia no ha sido muy exitosa. Es común encontrar un lenguaje muy cuidado —en el que no aparece por ningún lado la aceptación de la hipótesis nula—, acompañado de interpretaciones que equiparan en su alcance el rechazo y el no rechazo de la hipótesis nula.
Lo esencial es entender que solo el rechazo de la hipótesis nula tiene carácter de prueba. La aceptación de la hipótesis nula —si así se le quiere llamar— no constituye una prueba de que la hipótesis nula sea cierta. Lo único que podría decirse en estos casos es que no es posible probar con baja probabilidad de error que \(H_0\) sea falsa.
Cualquiera que sea la manera en la que se exprese una decisión referente a la hipótesis nula, es necesario tener presente que su no rechazo (o si se quiere, su aceptación) no tiene carácter de prueba; en tales casos, la hipótesis nula se toma como una hipótesis temporal que se mantendrá hasta que surjan elementos que permitan rechazarla.
Aunque el rechazo de la hipótesis nula, con el consiguiente respaldo de la hipótesis alternativa, sí tiene carácter de prueba, esta debe entenderse desde el punto de vista estadístico, es decir, como una afirmación con baja probabilidad de error.
Nota 3.1: ¡Las pruebas estadísticas no son pruebas matemáticas!
En matemáticas, las pruebas tienen carácter irrefutable. Cuando se utiliza una prueba matemática para validar la veracidad de un postulado, este queda demostrado.
En contraste, cuando se prueba estadísticamente, se respalda una conclusión con una baja probabilidad de error, pero no se demuestra con certeza.
La tabla 3.4 presenta los diferentes escenarios que pueden surgir cuando se decide sobre una característica poblacional desconocida a partir de información muestral.
| Situación poblacional desconocida | |||
|
\(H_0\) verdadera \(H_0\) |
\(H_0\) falsa \(H_a\) |
||
|
Decisión basada en información muestral |
Rechazar \(H_0\) |
ERROR TIPO I Probabilidad máxima: \(\alpha\) |
Decisión correcta \(1-\beta\) |
|
No rechazar \(H_0\) |
Decisión correcta \(1-\alpha\) |
ERROR TIPO II \(\beta\) |
|
En la parte superior de la tabla 3.4 se presentan los dos posibles escenarios poblacionales, expresados en términos de la hipótesis nula:
Que la hipótesis nula sea verdadera, en cuyo caso se está en el escenario \(H_0\)
Que la hipótesis nula sea falsa, en cuyo caso se está en el escenario \(H_a\)
¡Hay muchas formas de expresarlo!
Para hacer referencia a que se está en un escenario particular, se utilizan las expresiones dado o bajo.
Las expresiones “dado \(H_0\)” y “bajo \(H_0\)” son equivalentes a “si \(H_0\) es cierta”.
En la parte izquierda de la tabla 3.4 aparecen las dos posibles decisiones que un usuario puede tomar con respecto a una prueba de hipótesis, referidas como el rechazo o el no rechazo de la hipótesis nula. En el contexto clásico, tales decisiones se toman teniendo en cuenta únicamente la información muestral.
Producto de las dos decisiones que pueden tomarse en cada uno de los dos escenarios poblacionales, se tienen cuatro posibles resultados: dos correctos y dos erróneos, cada uno de los cuales aparece caracterizado en la tabla 3.4, con su correspondiente probabilidad.
A continuación se presentan una serie de definiciones asociadas con las decisiones que se toman al contrastar un juego de hipótesis.
Las anteriores definiciones y los conceptos subyacentes constituyen el núcleo de los procesos inferenciales. Las decisiones que finalmente se toman suelen estar basadas en elaboraciones alrededor de estos conceptos. A continuación se presentan algunas consideraciones que van un poco más allá de las definiciones.
Tip 3.3: ¡El nivel de significancia se fija! ¿¡0.05!?
El nivel de significancia puede ser fijado por el investigador. Y puesto que se trata de una probabilidad de error, se busca que esta sea baja. Aunque en principio podría considerarse para este fin cualquier probabilidad cercana a 0, la comunidad científica ha adoptado históricamente el valor de 0.05 como estándar.
Cowles y Davis (1982) describen los antecedentes que, al parecer, llevaron a Fisher a establecerlo formalmente en 1925 en su obra Statistical Methods for Research Workers, mediante el redondeo de la probabilidad de obtener valores que se alejen más de dos desviaciones estándar de la media en una distribución normal (0.0455). Ese redondeo dio lugar a un valor fácil de recordar, de transmitir y de conceptualizar, pues equivale a fijar un criterio con base en el cual —en el peor de los casos— se correría el riesgo de fallar hasta 1 vez de cada 20 al rechazar la hipótesis nula.
No obstante lo anterior, habrá situaciones en las que el investigador podría —e incluso debería— sustentar la elección de algún otro nivel de significancia.
¡La probabilidad \(\beta\) depende del valor de parámetro!
La hipótesis alternativa plantea que el parámetro \(\theta\) que es objeto de la prueba de hipótesis pertenece a una subregión \(\Theta_0^c\) de su espacio paramétrico (cf. expresión 3.12). Consecuentemente, hay muchos posibles valores de \(\theta\) que satisfacen lo postulado por \(H_a.\) Luego, cuando se dice “bajo \(H_a\)” no se está fijando un valor particular de \(\theta,\) sino que se alude a una región de posibles valores de \(\theta.\)
Y puesto que la probabilidad de error tipo II se obtiene para el escenario alternativo (bajo \(H_a\)), \(\beta\) depende del valor particular del parámetro \(\theta\) en la subregión paramétrica definida por la hipótesis alternativa.
En consecuencia, no es posible fijar \(\beta\) como una constante que sea válida para cualquier valor del parámetro; sin embargo, sí es posible analizar su comportamiento definiéndola en función del parámetro. Por tal motivo, en algunos textos se usa la expresión \(\beta(\theta),\) para enfatizar en esta dependencia.
Tip 3.4: ¿¡Y para \(\alpha\) aplica lo mismo!?
Teniendo en cuenta que la hipótesis nula también puede estar constituida por una región paramétrica en lugar de estarlo por un punto17, podría concluirse, por analogía con lo expresado para \(\beta,\) que el valor de \(\alpha\) también depende del valor particular del parámetro. Sin embargo, no es así.
Al revisar la definición de nivel de significancia (cf. definición 3.36), se observa que \(\alpha\) no está definido simplemente como la probabilidad de cometer error tipo I, sino como la máxima probabilidad de cometer error tipo I.
Esta es la razón por la cual la definición de la hipótesis nula siempre debe incluir la igualdad: la máxima probabilidad de error tipo I se calcula haciendo el valor de parámetro igual al postulado por la hipótesis nula; aun si la prueba es de una cola.
En tal sentido, \(\alpha\) no es una variable que dependa del verdadero valor del parámetro, sino una constante que fija el investigador.
¡Mientras más potente, mejor!
Las curvas de potencia, que se construyen en función de los posibles valores del parámetro, permiten analizar las características de una prueba y/o comparar diferentes pruebas.
Mientras más alta sea la potencia,\(1-\beta ,\) de una prueba, más sensible será para detectar la hipótesis alternativa.
3.9.2.2 Relación entre los tipos de error y la potencia de la prueba
Para ilustrar la forma en la que las probabilidades de error tipo I y II se relacionan entre sí y con la potencia de la prueba, retomemos el ejemplo 3.2. La pretensión de la gitana puede contrastarse a través del siguiente juego de hipótesis:
\(H_0:p\le1/6\) (la gitana no tiene capacidad extraordinaria)
\(H_a:p>1/6\) (la gitana sí tiene capacidad extraordinaria)
Anteriormente se insinuaba que podría disminuirse la probabilidad de errar si se le exigía a la gitana realizar un mayor número de lanzamientos.
Considérese a continuación un experimento consistente en realizar 12 lanzamientos independientes, con sus correspondientes predicciones. La variable aleatoria que representa el número de éxitos (aciertos) tendrá distribución binomial con parámetros \(n = 12\) y \(p\) desconocido.
\[
X\thicksim\text{bin}\left(n=12,\quad p\right)
\]
Resulta lógico establecer un criterio de decisión que conduzca al rechazo de la hipótesis nula únicamente si la gitana acierta más veces de lo que se esperaría bajo la hipótesis nula.
En general, el número de aciertos esperado, esto es, la esperanza de la variable aleatoria binomial que contabiliza el número de éxitos es \(np\) (cf. sección 3.6.2). Luego, si la hipótesis nula es cierta \((p = 1/6),\) el número de éxitos esperado sería \(12\times 1/6=2.\) En consecuencia, cualquier criterio de decisión en el que se le reconozcan poderes extraordinarios a la gitana si acierta más de dos veces sería válido…aunque no igual de razonable.
Considérense los siguientes criterios de decisión, cada uno de los cuales configura una prueba de hipótesis:
\(\text{cd}1: \text{rechazar }H_0 \text{ si } X\ge 3\)
\(\text{cd}2: \text{rechazar }H_0 \text{ si } X\ge 5\)
\(\text{cd}3: \text{rechazar }H_0 \text{ si } X\ge 8\)
Dependiendo del criterio que se elija, se tendrá mayor o menor probabilidad de ser timado. Sin embargo, en ningún caso podrá tenerse la certeza de que la decisión tomada sea la correcta, puesto que —aun sin poderes extraordinarios— hay cierta probabilidad de satisfacer cualquiera de los criterios de decisión planteados, tal y como se ilustra a continuación.
\[ \begin{align} P(X\ge 3\:|\:p=1/6)&=0.322574\\[0.7em] P(X\ge 5\:|\:p=1/6)&=0.036350\\[0.7em] P(X\ge 8\:|\: p=1/6)&=0.000156 \end{align} \]
Luego, si un cliente de la gitana aceptara 3 o más aciertos como una prueba de sus capacidades \((\text{cd}1),\) tendría una probabilidad de 0.322574 de ser engañado; mientras que la probabilidad de engañar a un cliente que exigiera 8 o más aciertos \((\text{cd}3)\) sería de una diezmilésima.
¿Y si se realizaran únicamente 2 lanzamientos?
Al final de la exposición del problema de la gitana se dejó planteada una pregunta: ¿sería posible establecer a partir de dos lanzamientos una regla que permitiera tomar una decisión con una probabilidad de error menor de 0.05?
Usando la misma lógica desarrollada anteriormente podemos responder esta pregunta:
Si se realizaran dos lanzamientos, la variable aleatoria que contabilizaría el número de aciertos seguiría una distribución binomial con parámetros \(n = 2\) y \(p\) desconocido.
\[
X\thicksim\text{bin}\left(n=2,\quad p\right)
\]
Es fácil averiguar cuál es la probabilidad de obtener dos aciertos si la hipótesis nula es cierta:
dbinom(2, size = 2, prob = 1/6)[1] 0.02777778Luego, la respuesta a la pregunta que se había dejado planteada es que sí sería posible establecer una regla que permitiera tomar una decisión con una probabilidad de error menor de 0.05. Bastaría con exigirle que acertara en los 2 lanzamientos, con lo cual, la probabilidad de error tipo I sería 0.028.
La figura 3.20 (a) presenta las funciones de potencia correspondientes a las tres pruebas o criterios de decisión considerados.


Para el presente ejemplo, la función de potencia tiene por dominio el espacio paramétrico de \(p,\) esto es, el intervalo \([0,\,1],\) el cual se representa en la abscisa18.
El juego de hipótesis planteado particiona el espacio paramétrico de \(p\) en dos regiones: la de la hipótesis nula, esto es, los valores de \(p \le 1/6\) (valores a la izquierda de la línea punteada vertical) y la de la hipótesis alternativa, es decir, los valores de \(p > 1/6\) (valores a la derecha de la línea punteada vertical) (figura 3.20 (a)).
La función de potencia calcula la probabilidad de rechazar la hipótesis nula para todos los posibles valores del parámetro \(p,\) sin importar si \(H_0\) es cierta o no. Si \(p\) está en el subespacio de la hipótesis alternativa (\(p > 1/6\)), el rechazo de \(H_0\) es una decisión correcta, que ocurre con probabilidad \(1 − \beta;\) si \(p\) está en el subespacio de la hipótesis nula (\(p \le 1/6\)), el rechazo de \(H_0\) es una decisión errónea cuya máxima probabilidad es \(\alpha.\) El rango de la función de potencia es el intervalo \([0,\,1]\) y se representa en la ordenada.
Cualquiera que sea el criterio de decisión, la probabilidad de error tipo I se hace mayor cuanto más cercano se encuentre el parámetro del valor que define la igualdad de la hipótesis nula (en este caso, \(p = 1/6\)), siendo máxima en dicho punto, donde vale \(\alpha.\)
Los niveles de significancia de las pruebas evaluadas aparecen representados en la figura 3.20 (a) con líneas punteadas horizontales y corresponden a las probabilidades calculadas anteriormente de que se satisficiera el criterio, cuando el valor del parámetro coincidía con el que definía la igualdad para la hipótesis nula.
¡Podría ser menor!
Nótese que la probabilidad de error tipo I podría ser menor que \(\alpha.\) El nivel de significancia, que es la máxima probabilidad de error tipo I, se presenta cuando el parámetro se hace igual al planteado en la hipótesis nula.
Para una prueba de cola derecha, como la presente, la probabilidad de cometer error tipo I, si \(p\) fuera estrictamente menor que 1/6, sería inferior a \(\alpha.\)
Por otra parte, el rechazo de la hipótesis nula para valores de \(p\) en \(H_a\) (valores a la derecha de la línea punteada vertical) constituye una decisión correcta.
Cualquiera que sea el criterio de decisión, la probabilidad de rechazar una hipótesis nula falsa se incrementa en la medida en que \(p\) se aleja del valor que define la igualdad para la hipótesis nula. Lógicamente, sería mucho más probable detectar una capacidad extraordinaria altamente cultivada (un \(p\) muy alto) que una capacidad extraordinaria que se diferenciara muy poco de la ordinaria (un \(p\) ligeramente superior a 1/6).
La función escalonada representada en la figura 3.20 (b) corresponde a la prueba de hipótesis ideal. Bajo dicho criterio, la probabilidad de rechazar la hipótesis nula, siendo cierta es cero, es decir, que nunca se cometería error tipo I. Por otra parte, la probabilidad de rechazar la hipótesis nula siendo falsa es 1, con lo cual \(\beta\) es igual a cero, es decir que tampoco se cometería nunca un error tipo II. Por tanto, una prueba ideal permitiría tomar una decisión correcta con probabilidad 1, cualquiera que fuera el escenario.
¿¡Y para qué sirve!?
Aunque en la práctica investigativa no se cuenta con pruebas que gocen de las bondades de una prueba ideal, estas constituyen un referente para la evaluación de pruebas reales.
Una prueba será mejor cuanto más se parezca a la prueba ideal.
Se observa que el comportamiento de la prueba \(\text{cd}3\) (figura 3.20 (a)) es bastante similar al de la prueba ideal cuando la hipótesis nula es cierta, lo que significa que ejerce un excelente control sobre el error tipo I. No obstante, esta prueba es la que más se aleja del referente de idealidad cuando se está en el escenario de la hipótesis alternativa (mayor probabilidad de error tipo II).
En el otro extremo se encuentra la prueba \(\text{cd}1\) (figura 3.20 (a)), cuyo comportamiento bajo \(H_a\) es el que más se acerca al ideal (es la prueba más potente), pero es el que exhibe el peor desempeño cuando la hipótesis nula es cierta (mayor probabilidad de error tipo I).
Consecuentemente, \(\text{cd}1\) sería una mejor prueba que \(\text{cd}2\) y esta que \(\text{cd}3\), si la hipótesis nula fuera falsa. No obstante, la valoración se invertiría si la hipótesis nula fuera cierta.
¡No puedes taparte los pies sin descubrirte la cabeza!
Dentro de una familia de pruebas de hipótesis, las probabilidades de los errores tipo I y II se relacionan inversamente.
En consecuencia, excepto en casos triviales, fuera del ámbito investigativo, no existe ninguna prueba real que permita minimizar simultáneamente la probabilidad de los dos tipos de errores.
Cuando, usando un modelo determinado sobre una muestra dada, el usuario varía el criterio para decidir sobre un juego de hipótesis, buscando disminuir la probabilidad de alguno de los dos tipos de errores, siempre lo hace a expensas de incrementar la probabilidad del otro tipo de error.
Si un potencial cliente de la gitana estuviera muy preocupado por ser timado, trataría de protegerse del error tipo I, es decir, de atribuirle poderes extraordinarios a la gitana sin que los tuviera; en consecuencia, desestimaría el \(\text{cd}1\), eligiendo el \(\text{cd}2\) o mejor aun el \(\text{cd}3\) (figura 3.20 (a)). No obstante, siguiendo tal estrategia tendría mayor probabilidad de cometer un error tipo II, es decir, fallar en la detección de una eventual capacidad extraordinaria.
Si, por el contrario, el potencial cliente considerara que es poco lo que tiene que perder y que resultaría más inconveniente prescindir de los servicios de una persona con capacidades extraordinarias, tomaría su decisión basado en el \(\text{cd}2\) o en el \(\text{cd}1\) (figura 3.20 (a)). Sin embargo, al seguir tal estrategia estaría más propenso a cometer un error tipo I, esto es, atribuirle a la gitana una capacidad extraordinaria que no tiene.
Aunque no es posible definir de manera general que uno de los dos errores sea más grave que el otro, de manera que el investigador deba centrar todos sus esfuerzos en protegerse contra el mismo, ignorando el otro, en determinados contextos sí es posible realizar una valoración diferenciada de los mismos.
Considérese, por ejemplo, el resultado de una prueba diagnóstica de cáncer. La hipótesis nula sería que el paciente no está enfermo, mientras que la alternativa sería que sí lo está.
\(H_0:\) El paciente no está enfermo
\(H_a:\) El paciente sí está enfermo
En dicho contexto, un error tipo I se denomina falso positivo, esto es, diagnosticar como enfermo a un paciente sano, mientras que un error tipo II se denomina falso negativo, es decir, diagnosticar como sano a un paciente enfermo.
Es común que las pruebas alteradas (diagnóstico positivo) impliquen pruebas adicionales, mediante las cuales probablemente podrán depurarse los resultados erróneos. Por tanto, un error tipo I (falso positivo) no tendría consecuencias tan graves en este caso. Por su parte, un falso negativo sería sumamente delicado, pues privaría a un paciente de la posibilidad de iniciar un tratamiento oportunamente.
Resulta claro que, en este contexto, por el protocolo seguido y las implicaciones de cada tipo de error, es necesario adoptar un criterio de evaluación que permita manejar probabilidades muy bajas para el error tipo II.
Supóngase ahora que un centro de investigación, preocupado por la susceptibilidad del plátano hartón a la sigatoka negra, desea introducir una nueva variedad que sea resistente a esta enfermedad.
En este caso la hipótesis nula es que la nueva variedad no es resistente a la enfermedad, mientras que la hipótesis alternativa plantea que la nueva variedad sí es resistente a la enfermedad.
\(H_0:\) La nueva variedad no es resistente a la enfermedad
\(H_a:\) La nueva variedad sí es resistente a la enfermedad
Un error tipo I implicaría concluir que la nueva variedad es resistente a la enfermedad sin ser así, mientras que el error tipo II consistiría en no concluir en favor de la nueva variedad, siendo esta resistente.
Suponiendo que el centro de investigación goce de suficiente prestigio, una conclusión en favor de la nueva variedad podría dar lugar a políticas de sustitución. Obviamente, adelantar un programa de sustitución en un escenario de hipótesis nula (que la nueva variedad no fuera realmente resistente) sería bastante indeseable.
Teniendo presentes estas consideraciones, el centro de investigación debe procurar mantener la probabilidad de error tipo I en niveles muy bajos. Por otra parte, un error tipo II no sería tan grave, pues aunque privaría temporalmente a los productores de una variedad resistente, esta tendría oportunidad de exhibir su potencial en una etapa posterior del programa de mejoramiento.
En muchas otras situaciones experimentales, el contexto no queda tan claramente definido como en los dos escenarios expuestos anteriormente. La práctica corriente consiste en fijar un tope máximo para la probabilidad de error tipo I: usualmente 0.05 (cf. tip 3.3).
Nota 3.2: En resumen
La potencia de la prueba, que es el complemento del error tipo II, es una característica deseable. Una mayor potencia quiere decir que es más probable rechazar la hipótesis nula o, en otras palabras, que la prueba es más sensible para detectar pequeños efectos o pequeñas diferencias.
Al aplicar una prueba de hipótesis, usando un protocolo experimental dado, con una muestra determinada y con un nivel de significancia fijado, solo es posible aumentar la potencia, incrementando el tamaño de la muestra.
3.9.2.3 Tamaño de la muestra
Volviendo al ejemplo 3.2, se habrá notado que exigirle dos lanzamientos a la gitana en lugar de uno permite ejercer un mejor control sobre la prueba, cuyo desempeño global mejora aun más cuando se exigen 12 lanzamientos.
Incrementar el tamaño de la muestra es la estrategia más directa para mejorar el desempeño de una prueba de hipótesis. De esta manera se logra disminuir simultáneamente la probabilidad de ambos tipos de error. Lógicamente, en la medida en que se cuente con mayor información, se tendrán mayores posibilidades de tomar una decisión correcta.
Para situaciones sencillas, existen expresiones que permiten calcular el tamaño de muestra requerido para realizar una prueba de hipótesis sobre un parámetro, con un nivel de significancia y una potencia determinadas.
Algunas otras expresiones se construyen a partir del nivel de confianza y de la precisión deseada para la estimación por intervalo de un parámetro. En el capítulo 4 se presentan algunas de estas.
En resumen
Para una muestra dada, las probabilidades de los dos tipos de errores se relacionan de manera inversa.
Al tomar una decisión con base de una muestra dada, solo es posible disminuir una de dichas probabilidades, si se permite un incremento de la otra.
No obstante, es posible disminuir simultáneamente ambas probabilidades, aumentando el tamaño de la muestra.
3.9.2.4 Lógica de las pruebas de hipótesis
Advertencia 3.1: ¡Las pruebas no prueban!
Aun teniendo presente que probar estadísticamente no equivale a probar matemáticamente (cf. nota 3.1), la traducción de hypothesis test como “prueba de hipótesis” puede prestarse a interpretaciones incorrectas.
En la expresión original, testing conlleva la idea de contrastar, comparar o examinar, pero no la de demostrar o probar en su acepción matemática.
En español, el verbo probar tiene un rango de significados más amplio. Por una parte, puede referirse a aspectos procedimentales (ensayar, contrastar), coincidiendo con la acepción de testing, pero también puede entenderse desde lo demostrativo (validar, comprobar). Estas últimas ideas no están contenidas en testing y es justamente esta extensión semántica la que genera conflictos interpretativos.
Para evitar esta situación, algunos autores sugieren traducir hypothesis tests como “contrastes de hipótesis”. Efectivamente, esta traducción disminuiría el riesgo de que se amplíe el rango interpretativo hacia ideas no contenidas en la expresión original.
No obstante, la expresión “prueba de hipótesis” está tan arraigada en la práctica estadística que muy probablemente seguirá siendo la más usada. Lo importante es recordar que el término “prueba” debe entenderse en su sentido restringido: el de contrastar, no el de demostrar.
¿Y cómo son?
En el contexto inferencial paramétrico clásico la mayoría de los estadísticos de prueba se modelan con base en las distribuciones normal estándar, \(t,\) ji cuadrado y \(F.\) Los estadísticos de prueba que aparecen en este contexto suelen identificarse con el subíndice \(\text{c}\)19: \(Z_\text{c},\) \(t_\text{c},\) \(\chi_\text{c}^2,\) \(F_\text{c}\)…
Sin embargo, hay otros estadísticos de prueba válidos, como el número de aciertos, usado en el ejemplo 3.2. En efecto, el número de aciertos es un estadístico de prueba, pues se trata de una variable aleatoria, cuya distribución bajo la hipótesis nula es conocida. Cuando la hipótesis nula es cierta, es decir, si la gitana no tiene capacidades extraordinarias, la distribución del número de aciertos es \(\text{bin}(n,\: p=1/6),\) con \(n\) correspondiendo a cualquiera de las variantes consideradas (\(n=1,\) \(n=2,\) \(n=12\)).
Aunque el número de éxitos de un ensayo binomial parezca un estadístico de prueba un tanto rebuscado, que solo habría de servir para ilustrar conceptos básicos, también aparece en pruebas formales sobre el parámetro \(p\) de la binomial (cf. sección 4.4.4) y en el contexto no paramétrico (cf. ?sec-sign-test).
Para ilustrar la lógica subyacente a las pruebas de hipótesis, considérese el siguiente juego de hipótesis, acerca \(\mu,\) el parámetro de posición de una población normal, donde \(\mu_0\) representa una constante real cualquiera.
\[
\begin{align}
H_0&: \mu=\mu_0\\[0.7em]
Ha&: \mu\ne\mu_0
\end{align}
\]
Considérese ahora el siguiente estadístico de prueba, sobre cuya obtención y ámbito de aplicación se discute en la sección 4.2.
\[
Z=\frac{\overline{X}-\mu_0}{\sigma/\sqrt{n}} \overset {H_0}{\thicksim} N(0,\,1)
\]
El estadístico de prueba que se utiliza para contrastar el juego de hipótesis es una variable aleatoria denominada \(Z,\) cuya distribución —cuando la hipótesis nula es cierta— es normal estándar.
¡Hay varias formas de expresarlo!
La distribución del estadístico de prueba condicionada al cumplimiento de la hipótesis nula, puede denotarse, como en el presente caso, escribiendo \(H_0\) encima de la virgulilla, lo que se lee: “\(Z\) se distribuye bajo \(H_0\) (o cuando \(H_0\) es cierta) normal estándar”.
Equivalentemente, puede anteponerse la condición de que la hipótesis nula sea cierta, en cuyo caso se expresaría así: “Si la hipótesis nula es cierta (o bajo \(H_0\)), \(Z\) sigue una distribución normal estándar”; en este caso, no se usaría el símbolo \(H_0\) encima de la virgulilla.
Puesto que la distribución probabilística del estadístico de prueba está condicionada al cumplimiento de la hipótesis nula, este hecho se usa para para decidir sobre la misma.
Si el comportamiento probabilístico del estadístico de prueba es el que se esperaría bajo la hipótesis nula, no habría razón para dudar de su veracidad; consecuentemente, no se rechazaría.
No obstante, si el comportamiento del estadístico de prueba fuera inusual para la distribución que este tendría bajo la hipótesis nula, sería razonable dudar del cumplimiento de la condición necesaria para que este tuviera dicha distribución y, en consecuencia, se rechazaría la hipótesis nula.
Cuando se conoce la distribución que rige el comportamiento probabilístico de una variable aleatoria, es posible definir una región en la que con mayor probabilidad se ubiquen las realizaciones (valores concretos) de la variable en cuestión. Para el ejemplo planteado, si la hipótesis nula fuera cierta, se esperaría que las realizaciones de la variable aleatoria \(Z\) se dieran en regiones de alta plausibilidad para la distribución normal estándar.
La figura 3.21 muestra que el 95 % de las realizaciones de una variable aleatoria normal estándar se presentan entre −1.96 y 1.96. Por tanto, la probabilidad de que una variable aleatoria normal estándar tome valores por fuera de dicho rango es 0.05.

La obtención de un valor de \(Z\) en la región sombreada de la figura 3.21 —al ser un hecho inusual o poco probable para una variable aleatoria con distribución normal estándar— pondría en duda la distribución probabilística de \(Z\) y, por ende, la veracidad de la hipótesis nula que la sustenta, conduciendo, por tanto, a su rechazo.
Debe destacarse que, aunque las realizaciones de una variable aleatoria normal estándar en la región sombreada de la figura 3.21 son poco probables, no son imposibles. De hecho, el rango de una variable aleatoria normal estándar son los reales y \(P(|Z| > 1.96) = 0.05.\) Por tanto, si se establece un criterio de decisión según el cual se rechace la hipótesis nula siempre que \(|Z| > 1.96,\) la probabilidad de rechazar hipótesis nulas verdaderas20 será 0.05.
La anterior regla de decisión, con la correspondiente probabilidad de error asociada, se expresa de la siguiente manera:
El contraste de los juegos de hipótesis tradicionalmente se realizaba fijando el nivel de significancia y comparando el valor del estadístico de prueba con el del los valores críticos que definen la región de rechazo.
¡Lenguaje!
Puesto que los valores críticos solían obtenerse de tablas, a estos también se les denominaba valores tabulares.
Por su parte, al estadístico de prueba, el cual usualmente se representa con la misma letra que se utiliza para la distribución probabilística que este tendría bajo la hipótesis nula, suele llamársele valor calculado.
En el lenguaje tradicional, la regla de decisión presentada anteriormente solía expresarse así:
En adición al tradicional nivel de significancia del 5 %, también ha sido común el uso del nivel de significancia del 1 %, en situaciones en las que se tenga particular interés en ejercer control sobre la probabilidad de error tipo I.
Cuando una prueba de hipótesis se rechaza con un nivel de significancia del 5 %, se dice que la prueba es “estadísticamente significativa” o simplemente “significativa”, mientras que al rechazo con un nivel de significancia del 1 % suele calificársele con “altamente significativo”. Asimismo, en el uso tradicional, se ha utilizado un asterisco para denotar la significancia al 5 % y dos asteriscos para la significancia al 1 %.
Por su parte, las pruebas en las que no se rechaza la hipótesis nula al usar un nivel de significancia del 5 %, se dice que “no son estadísticamente significativas” o simplemente que “no son significativas”, tal y como se resume en la tabla 3.5.
| Decisión | Expresión | Notación |
|---|---|---|
| Rechazar \(H_0\) con \(\alpha = 0.05\) | Estadísticamente significativa | * |
| Rechazar \(H_0\) con \(\alpha = 0.01\) | Altamente significativa | ** |
| Rechazar \(H_0\) con \(\alpha = 0.05\) | No significativa | n. s. |
Desde el punto de vista tradicional, cualquier valoración relacionada con una prueba de hipótesis corresponde a una de las tres categorías relacionadas en la tabla 3.5, lo que implica la discretización de un proceso que es continuo por naturaleza.
Para ilustrar las limitaciones de este enfoque, considérese el siguiente juego de hipótesis de cola derecha, para la media de una población normal:
\[
H_0: \mu\le\mu_0
\] \[
Ha: \mu>\mu_0
\]
Si se fija un nivel de significancia \(\alpha = 0.01,\) el correspondiente valor crítico superior es 2.3 y el criterio de rechazo se expresa así:
Si el \(Z_\text{c}\ge 2.3,\) rechaza \(H_0\) con un nivel de significancia del 1 %; en caso contrario, no se rechaza \(H_0.\)
La figura 3.22, correspondiente a la cola derecha de una distribución normal estándar, presenta en sombreado la región de rechazo. Cualquier valor del estadístico de prueba en la región de rechazo, es decir, mayor o igual que 2.3 conduciría al rechazo de la hipótesis nula con un nivel de significancia del 1 %. En tal sentido, la declaración frente a una prueba cuyo estadístico sea 2.5 o 4.0 será exactamente la misma: la prueba es altamente significativa.

Este ejemplo pone en evidencia lo básico que resulta el sistema de clasificación tradicional. Aunque, bajo la hipótesis nula, un valor de 4.0 es mucho menos probable que un valor de 2.5, el sistema tradicional basado en la comparación entre un valor calculado y un valor tabular no discrimina tales situaciones.
Se intuye que una valoración de lo poco probable que sea obtener un valor tan extremo como 2.5 o 4.0 permitiría discriminar entre los escenarios comparados. Esta idea da lugar a un concepto central en estadística inferencial: el valor p.
3.9.2.5 Valor p
Nota 3.3: ¿Cómo se calcula el valor p?
El valor p se calcula como la probabilidad de obtener —bajo la hipótesis nula— un estadístico de prueba igual o más extremo que el observado.
¡No se confunda!
Resulta notoria la similitud entre el valor p y el nivel de significancia, pues ambos conceptos hacen referencia a la probabilidad de error tipo I.
No obstante, el nivel de significancia es la máxima probabilidad de error tipo I que el investigador está dispuesto a tolerar. Es un valor obtenido a priori que se fija sin necesidad de considerar la información muestral. Su determinación se basa únicamente en lo grave que pueda resultar cometer un error tipo I.
En contraste, el valor p se obtiene a posteriori, con base en una muestra, y se interpreta como la probabilidad de cometer un error tipo I si se rechaza la hipótesis nula con base en la información de esa muestra particular.
A diferencia del nivel de significancia, que es una probabilidad máxima de error, el valor p es una probabilidad exacta de cometer un error tipo I. Esto permite plantear de manera natural la siguiente regla de decisión:
Recibe diferentes denominaciones
Al valor p también se le denomina “valor-p”, “p-valor” “p valor” o simplemente “p” o “P”.
Aunque el concepto del valor p no es nuevo, su cálculo resultaba dispendioso antes de la era computacional. En la actualidad, casi todas las pruebas de hipótesis que se realizan mediante algún programa estadístico llevan asociado el correspondiente valor p.
La condición “bajo la hipótesis nula” que aparece en la definición del valor p implica que su cálculo se realiza utilizando la distribución que tendría el estadístico de prueba si la hipótesis nula fuera cierta. Esta es la distribución con base en la cual se calculan las probabilidades de obtener valores extremos.
Así, al contrastar una prueba de hipótesis basada en un estadístico de prueba que siga una distribución normal estándar cuando la hipótesis nula sea cierta, esta es la distribución que se usa para calcular los valores p.
Lo tocante a la probabilidad de un valor igual o más extremo, se precisa en función del tipo de prueba, así:
En pruebas de cola derecha, se trata de valores mayores o iguales que el del estadístico de prueba.
En pruebas de cola izquierda, se trata de valores menores o iguales que el del estadístico de prueba.
En pruebas de dos colas, se calcula como el doble del mínimo entre las dos probabilidades descritas anteriormente.
La tabla 3.6 y la figura 3.23 ilustran las regiones de rechazo y el cálculo de los correspondientes valores p, suponiendo un juego de hipótesis tal que bajo la hipótesis nula el estadístico de prueba siga una distribución normal estándar.
| Tipo de prueba | Criterio de rechazo para un nivel de significancia \(\alpha\) | Valor p |
|---|---|---|
| Cola izquierda | Si \(Z_\text{c}\le−z_\alpha\) |
\(P(Z < Z_\text{c})\) |
| Cola derecha | Si \(Z_\text{c}\ge z_\alpha\) |
\(P(Z > Z_\text{c})\) |
| Dos colas | Si \(|Z_\text{c}|\ge z_{\alpha/2}\) |
\(2 \, P(Z > |Z_\text{c}|)\) |
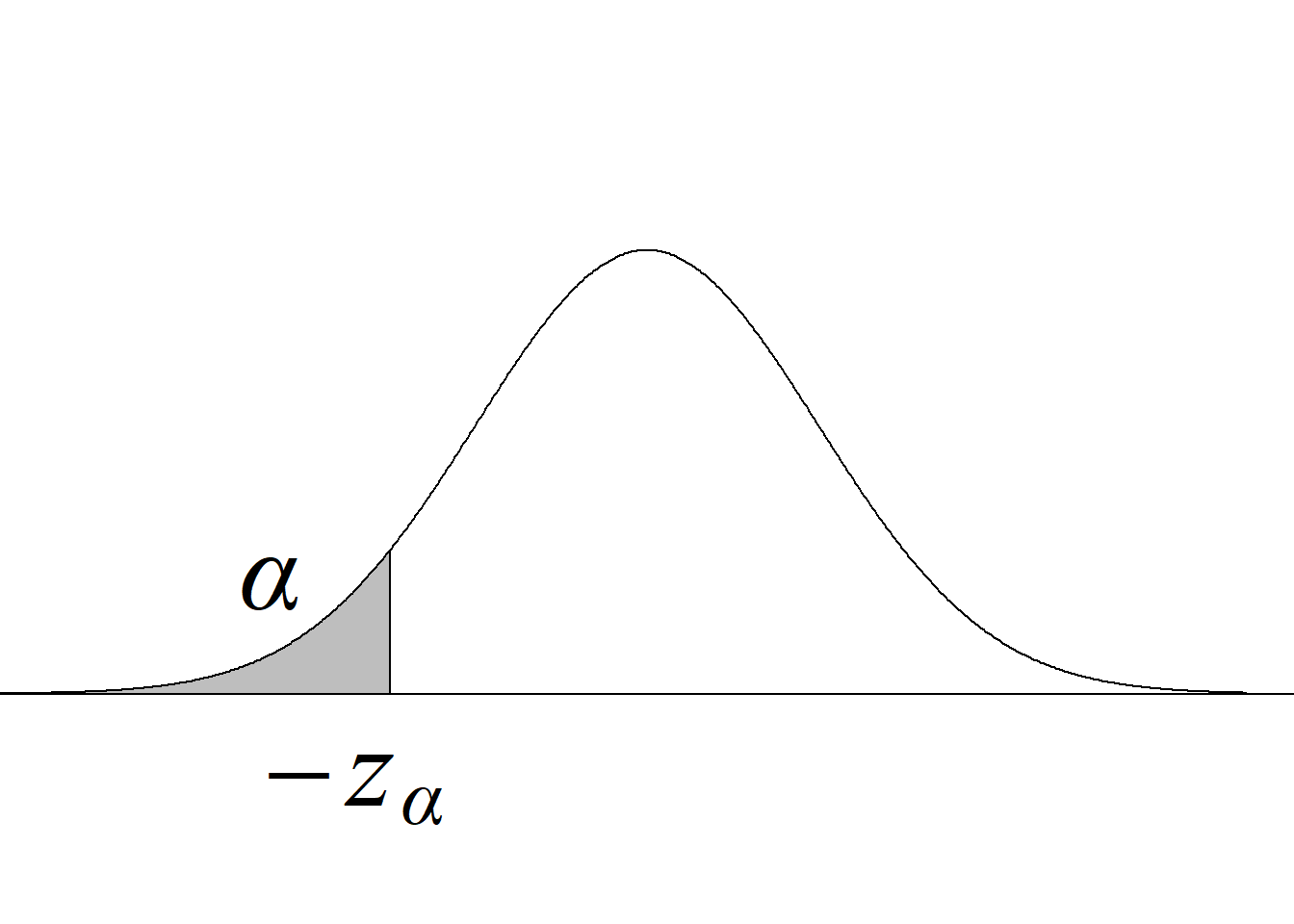
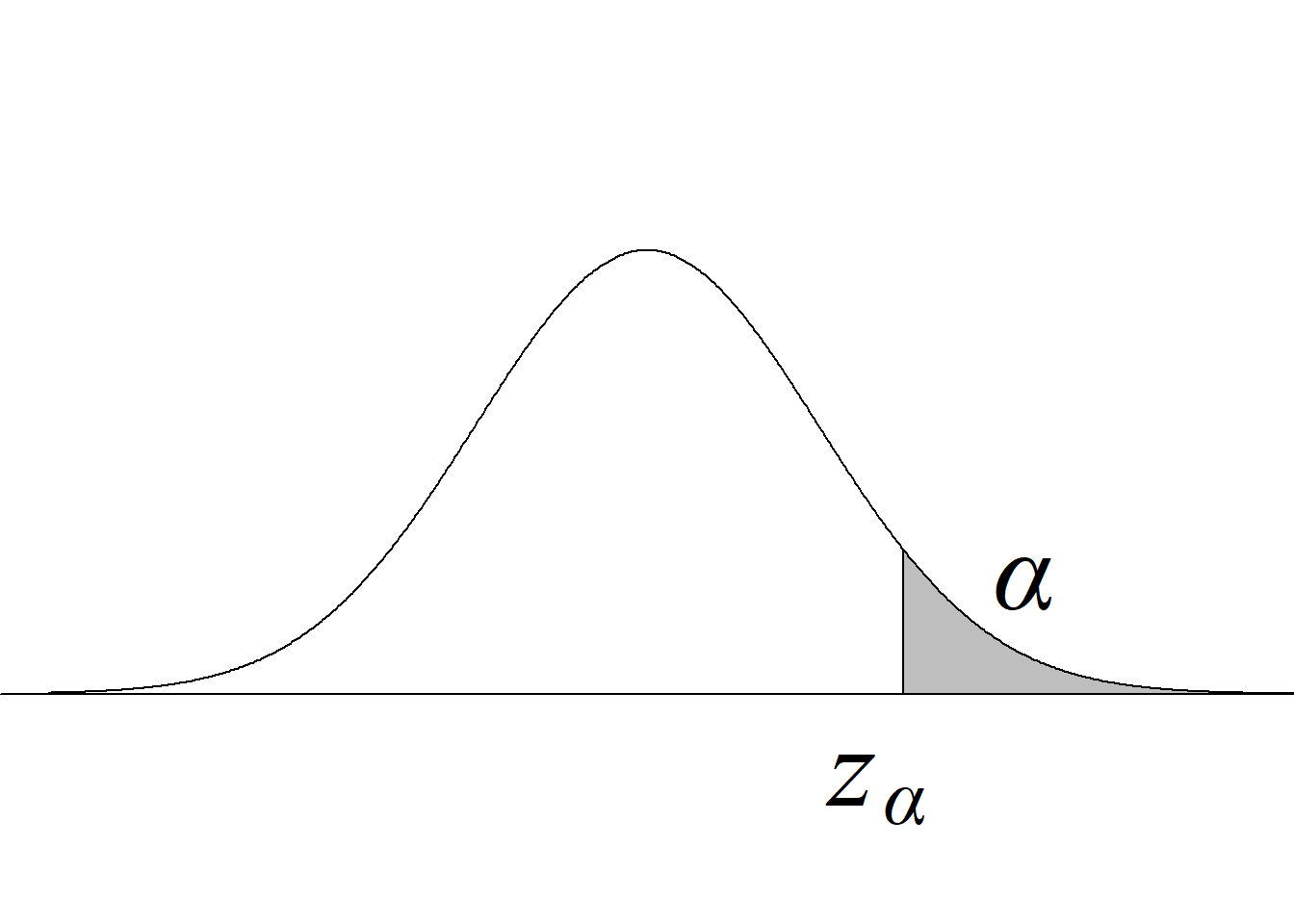
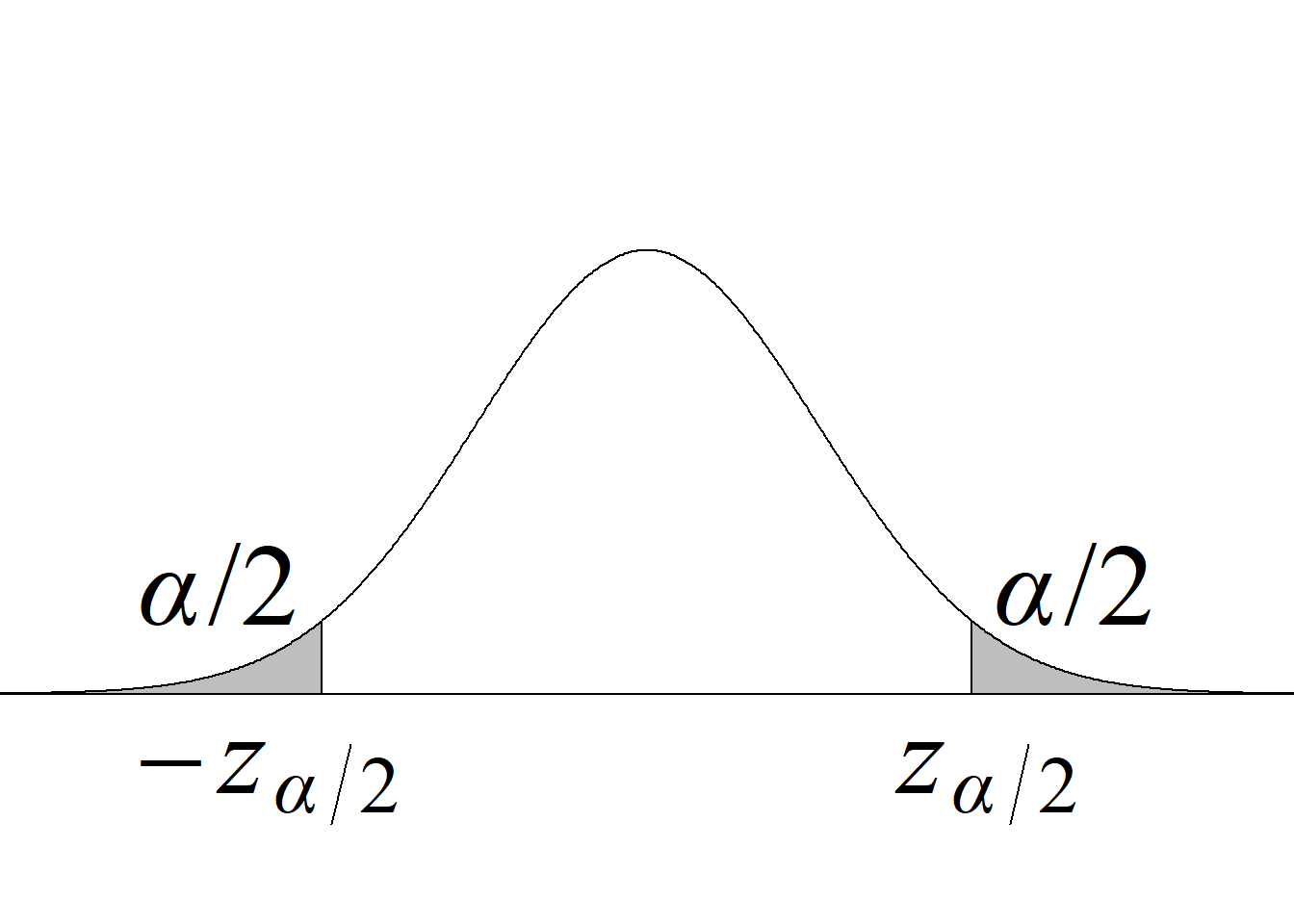
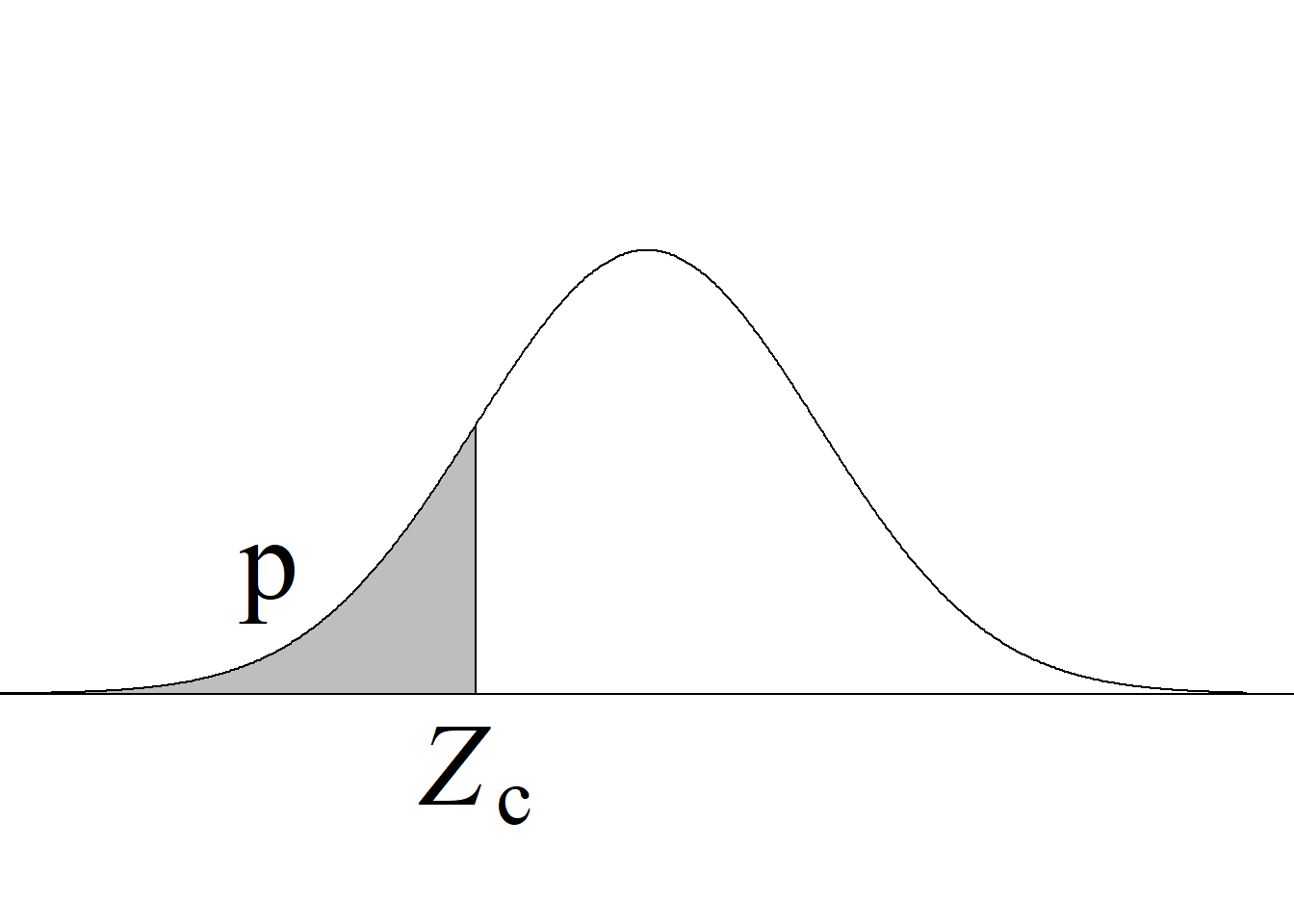
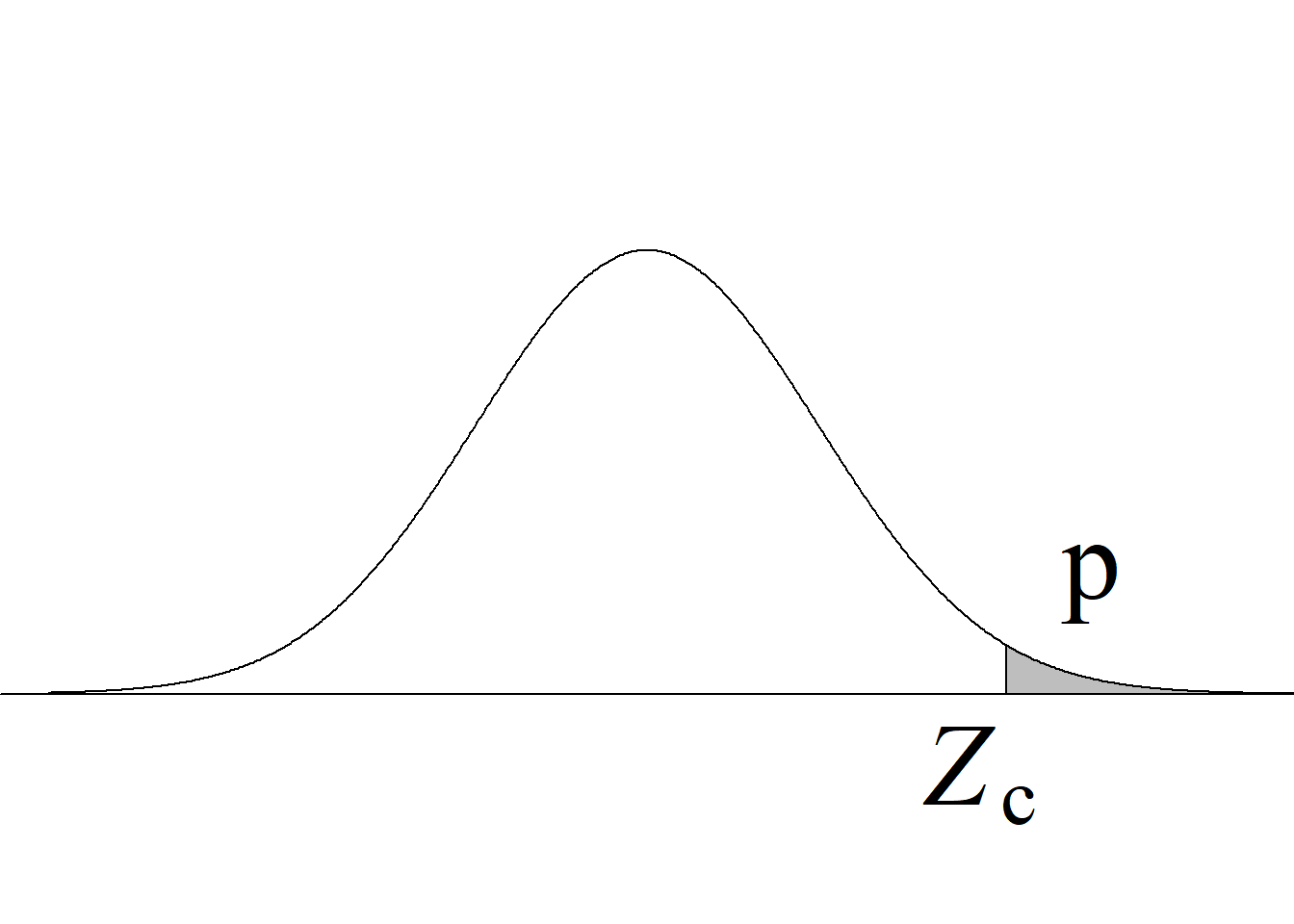
Nota 3.4: ¡Notación!
En adelante, se usará la notación \(x_α\) para representar el valor de una variable aleatoria \(X,\) tal que \(P(X > x_α) = α\) (cf. figura 3.23 (b)).
Consecuentemente, al valor de una variable aleatoria que deja a su izquierda un área \(\alpha,\) se le denomina \(x_{1-\alpha},\) pues deja a su derecha un área \(1-\alpha.\)
En el contexto de una prueba de hipótesis en la que la región de rechazo esté dada por los valores mayores que \(x_α,\) a este se le denomina valor crítico superior (cf. figura 3.23 (b)).
En el contexto de una prueba de hipótesis en la que la región de rechazo esté dada por los valores menores que \(x_{1-α},\) a este se le denomina valor crítico inferior (cf. figura 3.23 (a)).
¡Valores críticos inferiores en distribuciones simétricas!
Para el caso particular de distribuciones simétricas y centradas en cero, como la normal estándar y la \(t,\) se satisface que el valor crítico inferior para un \(\alpha\) dado es igual al valor crítico superior para dicho \(\alpha,\) con signo contrario (cf. figura 3.23 (b) y figura 3.23 (a)).
\[
x_{1-α} = -x_{α}
\]
La segunda columna de la tabla 3.6 y las figuras 3.23 (a), 3.23 (b) y 3.23 (c) ilustran los criterios de rechazo tradicionales, consistentes en comparar el estadístico de prueba con un valor crítico.
Los valores críticos definen el límite entre las regiones de rechazo y de no rechazo de la hipótesis nula. En las representaciones gráficas, las regiones de rechazo suelen sombrearse, dejando sin sombrear la región de no rechazo (o aceptación), la cual siempre está en el centro de la distribución.
Si el estadístico de prueba se ubica en la región de rechazo, se rechaza la hipótesis nula; en caso contrario, es decir, si se ubica en la zona de no rechazo, no se rechaza.
¡Las colas no mienten!
Las figuras 3.23 (a), 3.23 (b) y 3.23 (c) ilustran el origen del nombre genérico de estas pruebas.
Las pruebas de cola izquierda tienen su región de rechazo en la cola izquierda de la distribución de referencia (cf. figura 3.23 (a)).
Las pruebas de cola derecha tienen su región de rechazo en la cola derecha de la distribución de referencia (cf. figura 3.23 (b)).
Las pruebas de dos colas tienen su región de rechazo distribuida en ambas colas de la distribución de referencia (cf. figura 3.23 (c)).
En inglés, a las pruebas de una sola cola (izquierda o derecha) y de dos colas se les denomina one-tailed y two-tailed tests, respectivamente. En particular, se les denomina lower-tailed tests a las de cola izquierda y upper-tailed tests a la de cola derecha.
La tercera columna de la tabla 3.6 y las figuras 3.23 (d), 3.23 (e) y 3.23 (f) ilustran la forma general en que se calcula el valor p.
¡Los métodos coinciden!
Las conclusiones a las que se llega mediante cualquiera de los dos métodos de decisión (tradicional y valor p) siempre son coincidentes.
Si una hipótesis es significativa al 1 %, quiere decir que \(\text{p} \le 0.01\) y viceversa.
El valor p de una hipótesis que alcance la categoría de significancia, pero no de alta significancia, será tal que \(0.01 < \text{p} \le 0.05\) y viceversa.
Las pruebas no significativas exhibirán valores \(\text{p} > 0.05.\)
El enfoque basado en el valor p tiene la ventaja de expresar de manera continua la probabilidad de error tipo I, la cual, por limitaciones computacionales, se manejó durante mucho tiempo de forma discretizada a través de tres categorías: altamente significativo, significativo y no significativo.
¡Siempre hay un juego de hipótesis!
En la actualidad es bastante común encontrarse con salidas de programas estadísticos que contienen valores p. Mucho menos común es encontrarse con descripciones explícitas del juego de hipótesis contrastado.
Si se tiene en cuenta que el valor p es la probabilidad de cometer un error tipo I, es decir, de rechazar una hipótesis nula que es verdadera, siempre que aparezca un valor p, habrá un juego de hipótesis subyacente.
Si aparece más de un valor p es porque se están contrastando múltiples juegos de hipótesis: tantos como valores p se presenten.
3.9.2.6 Significancia estadística
Es necesario precisar el alcance de la significancia estadística, sea cual sea la vía usada para concluir sobre la misma: la tradicional o la basada en el valor p.
Tal y como se indicó anteriormente, se dice que una prueba es significativa (o muy significativa) si se rechaza la hipótesis nula. En contraste, una prueba no significativa será aquella para la cual no se rechace la hipótesis nula con un nivel de significancia dado.
Aunque en el marco teórico usado para modelar las poblaciones de campo se habla en términos generales de rechazar o no rechazar una hipótesis nula, el concepto de la significancia estadística se hace más comprensible presentándolo como una afirmación con baja probabilidad de error acerca de un cambio en la población objetivo. Si, a partir de la muestra, el investigador puede afirmar con baja probabilidad de error que hay un efecto o diferencia en la población objetivo, este se cataloga como significativo.
Puesto que en la cotidianidad el término significativo es sinónimo de importante, es común la tendencia a trasladar dicha acepción al contexto inferencial. Esta interpretación, sin embargo, no es correcta. A la valoración subjetiva, aunque no por ello carente de criterio, otorgada por el usuario se le denomina significancia práctica, y se define como el cambio mínimo necesario para motivar una elección por parte del usuario. El establecimiento de la significancia práctica involucra un análisis integral, estando mediado casi siempre por consideraciones de tipo económico.
Un error frecuente consiste en ignorar la falta de significancia estadística de una prueba, argumentando la significancia práctica de las diferencias muestrales. Se cree que la significancia estadística no es más que la misma significancia práctica con un mayor nivel de exigencia. El usuario suele decir que aunque el resultado no sea estadísticamente significativo, para él sí lo es, por sus implicaciones económicas, y reclama vía libre para implementar los cambios. Esta forma de actuar sería equivalente a tomar una decisión basada únicamente en estadísticos muestrales descriptivos, sin tener en cuenta ningún tipo de proceso inferencial, creyendo ingenuamente que lo observado en la muestra tiene que reproducirse en la población.
Cuando se pretende, por ejemplo, comparar dos poblaciones, la pregunta de fondo no es cuál muestra tuvo mejor desempeño, sino si las diferencias observadas a nivel muestral pueden atribuirse a diferencias reales a nivel poblacional. Lo que indica un resultado no significativo es que, por halagüeño que pueda parecer el resultado muestral, no es posible afirmar con baja probabilidad de error que dicho resultado se reproducirá a nivel poblacional. En ausencia de significancia estadística, los métodos inferenciales advierten que los efectos observados a nivel muestral pudieron presentarse por azar.
Otro error, quizá más frecuente que el anterior y que suele pasar inadvertido, es dejar todo el peso de las decisiones a la significancia estadística, sin valorar la significancia práctica del resultado. El hecho de que pueda afirmarse con baja probabilidad de error, por ejemplo, que existe diferencia entre los parámetros de dos poblaciones no implica necesariamente que haya que tomar una decisión en favor de la población con parámetro más deseable.
En muchas ocasiones se tienen resultados que, aunque estadísticamente significativos (puede afirmarse con baja probabilidad de error que existen tales efectos o diferencias en la población o poblaciones objetivo), carecen de significancia práctica, pudiendo resultar más oneroso el cambio de paradigma que mantener la situación existente.
Las significancias estadísticas irrelevantes pueden surgir de considerar únicamente el valor p del juego de hipótesis. Un valor p menor que el nivel de significancia únicamente indica que es posible afirmar con baja probabilidad de error que las medias poblacionales comparadas nos son exactamente iguales. Esto, sin embargo, no suele recoger las necesidades del usuario. Lo que realmente debe valorarse es la magnitud de la diferencia y muy particularmente el rango probables de esta, es decir, el intervalo de confianza para la diferencia.
Asimismo, es necesario tener en cuenta que la potencia de cualquier prueba de hipótesis (capacidad de rechazo) se incrementa con el tamaño de la muestra; consecuentemente, mientras más grandes sean los tamaños de muestra, más probable será obtener resultados significativos para pequeños efectos.
Aunque resulta obvio, cabe mencionar que no debe tomarse ninguna acción basada en los resultados que no tengan significancia estadística ni práctica. Únicamente los resultados que presenten significancia estadística y significancia práctica de manera simultánea constituyen verdaderos puntales de avance en el ámbito investigativo.
A fin de complementar el presente análisis, se destacan nuevamente las implicaciones del rechazo (significancia) y el no rechazo (no significancia) de la hipótesis nula.
El no rechazo de la hipótesis nula no conlleva su respaldo ni tiene carácter de prueba. Cuando el resultado es no significativo, se mantiene la hipótesis nula con carácter temporal, hasta que surjan argumentos que permitan rechazarla. Si se está en uno de esos casos en que se combina la falta de significancia estadística, con significancia práctica, el usuario debería evaluar los motivos de la no significancia estadística. ¿Qué tan variable es la muestra?, ¿cómo es el tamaño de la muestra?, ¿cómo es la potencia de la prueba?, ¿valdrá la pena realizar un nuevo ensayo bajo condiciones mejor controladas?
De igual manera, en todos los casos en que se tenga significancia estadística, es necesario realizar una valoración integral en la que se tomen en consideración todos los pros y los contras de un eventual cambio de paradigma. Justamente en esto consiste el análisis de la significancia práctica.
Se insiste en la recomendación de presentar los resultados significativos acompañados de la estimación por intervalo de las correspondientes diferencias o efectos. Esta estimación brinda mejores elementos para la toma de una decisión que la correspondiente estimación puntual, la cual puede resultar engañosa. La percepción y valoración del usuario puede cambiar drásticamente si se le dice, por ejemplo, que la diferencia media entre dos tratamientos es de 2 unidades o si se le dice que se tiene una confianza del 95 % en que la diferencia media entre dos tratamientos está entre 0.1 y 3.9 unidades.
La tabla 3.7 resume los cuatro posibles resultados que surgen de combinar la significancia estadística y la significancia práctica, con sus correspondientes recomendaciones.
| Significancia estadística | Significancia práctica | Recomendaciones |
|---|---|---|
| Sí | Sí |
|
| No | Sí |
|
| Sí | No |
|
| No | No |
|
¡No es solo la significancia!
La significancia estadística es solo uno de los requisitos para generalizar los hallazgos muestrales a la población objetivo.
La significancia no brinda, sin embargo, información sobre la satisfacción de otros requisitos tales como replicabilidad, validez interna, validez externa, uso de un modelo probabilístico adecuado y satisfacción de requerimientos particulares del modelo utilizado.
Tales aspectos no se discuten en este capítulo, el cual constituye un marco general para los procesos inferenciales; sin embargo, serán tenidos en cuenta cuando se describan técnicas específicas, muy particularmente en el capítulo 6.
3.9.2.7 Consideraciones adicionales sobre pruebas de hipótesis
A lo largo de esta sección se han presentado algunos elementos concernientes a la formulación y análisis de las pruebas de hipótesis; no obstante, algunos otros se desarrollan a través de los ejemplos que se presentan en los dos capítulos siguientes. En la sección 5.7 se presenta, a manera de compendio, un decálogo sobre pruebas de hipótesis. Allí se amplían y precisan algunos conceptos o se redirige a la discusión in extenso desarrollada en algún otro lugar del texto.
Referencias bibliográficas
Blanco Castañeda, L. (2010). Probabilidad. Universidad Nacional de Colombia.
Casella, G. and Berger, R. L. (2002). Statistical Inference. Duxbury.
Correa-Londoño, G. A. y Castillo-Morales, A. (2000). Tamaño de muestra para aproximación de un estadístico a la distribución normal. Agrociencia, 34(4), 467-476.
Cowles, M. and Davis, C. (1982). On the origins of the .05 level of statistical significance. American Psychologist, 37(5), 553-558. http://dx.doi.org/10.1037/0003-066X.37.5.553
Eisenhart, C. (1979). On the transition from "Student’s" z to "Student’s" t. The American Statistician, 33(1), 6-10. https://doi.org/10.2307/2683058
Gorroochurn, P. (2016). Classic topics on the history of modern mathematical statistics: from Laplace to more recent times. John Wiley.
Infante Gil, S. y Zárate de Lara, G. P. (1990). Métodos estadísticos: un enfoque interdisciplinario. Trillas.
Walpole, R. E., Myers, R. H., Myers, S. L. y Ye, K. (2012). Probabilidad y estadística para ingeniería y ciencias. Pearson Educación.
Los análogos de las estadísticas son realmente los momentos de la distribución, v. gr., esperanza y varianza, los cuales dependen de sus parámetros cf. sección 3.6.2.↩︎
Los muestreos sin remplazo son comunes en control de calidad. Estos ensayos se modelan mediante la distribución hipergeométrica.↩︎
Eventualmente, para definir el número de posibles comparaciones por pares en los procedimientos de comparación múltiple (cf. sección 8.5)↩︎
Casi siempre, los momentos pueden obtenerse mediante la denominada función generadora de momentos asociada con la correspondiente función de probabilidad. No obstante, en algunos casos dicha función no existe (no converge). En general, sea que la función generadora de momentos exista o no, podrá usarse la denominada función característica, la cual siempre existe y se asocia de manera unívoca con cada función de probabilidad, permitiendo generar sus correspondientes momentos.↩︎
Una transformación lineal de \(X\) es cualquier expresión de la forma \(a+bX.\) Puede constatarse que la transformación \((X-\mu)/\sigma\) es lineal con \(a=-\mu/\sigma\) y \(b=1/\sigma.\)↩︎
\(F(z)=P(Z<z)\)↩︎
en inglés quantile↩︎
En particular, la función cuantil correspondiente a la normal estándar se denomina función probit.↩︎
Las figuras 3.9, 3.10, 3.12 (a), 3.13, 3.14 y 3.15 se construyeron de esta manera.↩︎
Las muestras seudoaleatorias son conjuntos de números generados mediante algún algoritmo computacional, que aunque reflejan el comportamiento probabilístico de la variable en la que se basan, no son verdaderamente aleatorias o imprevisibles. El usuario no suele percatarse de ello, puesto que cada vez que genera una muestra con tales características, obtiene un conjunto diferente. No obstante, si lo requiriera también podría obtener siempre el mismo conjunto, fijando la semilla generadora, mediante la función
set.seed(m), dondemes un valor entero (que nada tiene que ver con la variable aleatoria de referencia). A menudo se obvia este tecnicismo y a tales muestras se les denomina aleatorias.↩︎En las poblaciones de campo, los parámetros son constantes que caracterizan las poblaciones, de manera equivalente a como los estadísticos de resumen caracterizan las muestras (cf. sección 2.1).↩︎
Si esta afirmación lo desconcierta, revise la definición de inferencia estadística.↩︎
En sentido amplio, un estadístico muestral o simplemente estadístico es cualquier variable aleatoria generada con base en una muestra aleatoria, sin que sea admisible la participación de ningún parámetro desconocido.↩︎
Los intervalos de confianza del 95, 99 y 90 % están ligados con pruebas de hipótesis con niveles de significancia de 0.05, 0.01 y 0.1, respectivamente.↩︎
\(\theta_0\) es una constante cualquiera que forma parte del espacio paramétrico de \(\theta.\)↩︎
A la falacia lógica consistente en tomar la ausencia de pruebas como prueba de la ausencia se le denomina argumento de la ignorancia.↩︎
Solo en pruebas de dos colas está constituida por un punto.↩︎
En otros casos, el dominio será el espacio paramétrico del parámetro sobre el que se esté hipotetizando.↩︎
que se lee “calculado”↩︎
Error tipo I.↩︎