x <- c(3, 5, 6, 8, 9)
mean(x)[1] 6.2La estadística descriptiva está conformada por herramientas que se aplican sobre muestras o poblaciones, a fin de describir, representar, resumir y destacar sus características. Los tres conjuntos de herramientas que se usan para tal efecto son las medidas de resumen, las tablas y las representaciones gráficas.
Aunque algunas medidas de resumen cambian cuando se aplican a muestras o a poblaciones, la mayoría coinciden, difiriendo únicamente en la nomenclatura. Teniendo en cuenta lo anterior, aunado al hecho de que en la mayoría de las áreas de investigación básica y aplicada siempre se trabaja con muestras, el uso de todas las herramientas que se presentan en este capítulo está referido a muestras.
Volveremos sobre las poblaciones en la sección 3.9, donde se detalla la forma en que estas se relacionan con las muestras en el contexto investigativo.
Son valores numéricos que, como su nombre lo indica, resumen la información contenida en una muestra. Se dividen en medidas de tendencia central, medidas de dispersión, medidas de forma y medidas de posición. A tales medidas se les llama estadísticos1.
Las medidas de tendencia central caracterizan el centro la muestra. Dicho centro constituye un referente o representante de la muestra.
Es la medida de tendencia central de mayor uso tanto en el ámbito descriptivo como en el inferencial. Se define como la suma de todos los datos, dividida entre el número de datos. A esta medida también se le llama media aritmética o promedio. Se denota con una \(x\) coronada con una barra horizontal, por lo que suele leerse como \(x\) barra.
\[
\bar{x}=\frac{\sum\limits_{i=1}^{n}{x_i}}{n}
\]
Considérese el siguiente conjunto de datos: \(\{3, 5, 6, 8, 9\}\)
\[
\bar{x}=\frac{3+5+6+8+9}{5}=6.2
\]
Aunque la media podría corresponder con alguno de los valores de la muestra, no tiene que ser así; de hecho, la media podría ser un valor muestral imposible.
Tal es el caso cuando se promedian valores de una variable discreta, pudiendo dar como resultado un valor ubicado entre dos niveles adyacentes.
Si se supone, por ejemplo, que los datos presentados anteriormente corresponden al número de huevos ovipositados por la hembra de un insecto, 6.2 sería un número de huevos imposible. A pesar de ello, el valor obtenido se mantiene en representación del centro de la muestra.
La media en R se obtiene con la función mean{base}2:
x <- c(3, 5, 6, 8, 9)
mean(x)[1] 6.2La media puede interpretarse como el centro de gravedad del conjunto de datos, tal y como se ilustra en la figura 2.1.

Considérese ahora el siguiente conjunto de datos: \(\{3, 5, 6, 8, 25\},\) para el cual puede verificarse que el promedio es 9.4.
En la figura 2.2 se aprecia que, aunque la media sigue ocupando el centro de gravedad del conjunto de datos, en este caso no brinda un fiel reflejo de su centro.

Aquellos datos muy altos o muy bajos con respecto al conjunto del cual forman parte se denominan outliers o valores extremos. En el presente ejemplo, 25 es un valor extremo, dado que se encuentra muy alejado de los demás datos del conjunto.
La principal debilidad de la media aritmética como medida de tendencia central es su falta de robustez a la presencia de valores extremos.
Se dice que un método es robusto a una condición cuando la violación de la misma no afecta ostensiblemente el resultado esperado del método.
Se espera que la media represente el centro de un conjunto de datos. No obstante, en presencia de valores extremos, dicho centro no queda bien reflejado. Por consiguiente, la media no es robusta a la presencia de valores extremos.
Supóngase que los datos del presente ejemplo consisten en el salario en millones de pesos de los empleados de una compañía, siendo 25 el salario del gerente. Si la única información con la que contara un aspirante a un cargo en dicha empresa fuera que el salario medio es de 9.4 millones de pesos, eventualmente podría estar motivado a continuar el proceso. Resulta obvio, sin embargo, que la media no constituiría un indicador fidedigno del salario que podría esperar dicho candidato.
Existen alternativas robustas a la presencia de valores extremos, que permiten reflejar de mejor manera el centro de un conjunto de datos. Una de ellas consiste en eliminar un porcentaje determinado de los valores más altos y más bajos de la muestra, dejando únicamente los valores centrales, con base en los cuales se calcula la media.
A esta medida de tendencia central se le denomina media podada o media recortada y puede obtenerse en R, incluyendo el argumento trim en la función mean{base}, mediante el cual se indica una proporción de poda entre 0 y 0.5. El valor por defecto de dicho argumento es 0, con lo cual no se realiza ninguna poda y se obtiene la media aritmética clásica.
Para muestras que no contengan valores extremos se esperaría que los valores de la media podada estuvieran cercanos a los de la media sin podar.
Un caso particular de media podada consiste en eliminar todos los valores que están por encima y por debajo del valor central, dejando únicamente dicho valor como medida de tendencia central; a esta medida se le conoce como mediana y es la alternativa más común a la media cuando existen valores extremos. Puede obtenerse en R, incluyendo el argumento trim = 0.5 en la función mean{base}, aunque en la sección 2.1.1.2 se ilustra una manera más expedita de hacerlo.
Otra situación en la que resultaría cuestionable el papel de la media como medida de tendencia central sería aquella en la que los datos estuvieran constituidos por grupos heterogéneos. Para ejemplificarlo, supónganse dos conjuntos de datos, el primero de ellos correspondiente a la edad de un grupo de niños de la guardería universitaria, y el segundo, a las edades de un grupo de estudiantes de posgrado.
Si —haciendo caso omiso de la clara diferencia existente entre estos dos grupos— se decidiera procesarlos de manera conjunta para calcular su edad promedio, se obtendría un valor de 23.9, el cual no refleja adecuadamente el centro de ninguno de los dos grupos, tal y como lo ilustra la figura 2.3.

Aunque —por la obviedad del presente ejemplo— difícilmente alguien consideraría el manejo integrado de tales grupos concediéndole algún valor al promedio como medida de tendencia central, en la práctica investigativa pueden surgir situaciones similares que no resulten tan obvias.
Por tal motivo, es necesario estar alerta, teniendo presente que, si bien siempre es posible, desde el punto de vista matemático, obtener el promedio de un conjunto (no vacío) de datos numéricos, el valor obtenido no siempre resulta adecuado desde el punto de vista conceptual, como representante del conjunto.
Aunque todo es promediable numéricamente, no todo es conceptualmente promediable.
Es el valor central de un conjunto ordenado de datos.
Así, por ejemplo, para el conjunto \(\{3, 5, 6, 8, 9\},\) la mediana es 6. En caso de que la muestra esté conformada por un número par de datos, la mediana se obtiene como el promedio de los dos valores centrales. Puesto que este conjunto de datos no contiene valores extremos, la mediana es muy similar a la media \(\left(\bar{x}=6.2\right).\)
No obstante, para la muestra de salarios que se usó para ilustrar el bajo desempeño de la media en presencia de valores extremos: \(\{3, 5, 6, 8, 25\},\) se obtiene un valor de 6, el cual le brindaría una mejor guía a un candidato en lo referente a aspiraciones salariales.
La principal ventaja de la mediana en relación con la media es su robustez ante la presencia de valores extremos, no viéndose afectada por estos. La figura 2.4 ilustra este aspecto.

La mediana puede expresarse matemáticamente a partir de los estadísticos de orden de la muestra.
Con base en los estadísticos de orden, se formula la siguiente expresión para el cálculo de la mediana:
\[
\begin{equation}
\tilde{x}=
\begin{cases}
x_{\left(\frac{n+1}{2}\right)} & \text{si $n$ es impar},\\
\\
\frac{x_{\left(\frac{n}{2}\right)}+x_{\left(\frac{n}{2}+1\right)}}{2} & \text{si $n$ es par.}
\end{cases}
\end{equation}
\]
Los estadísticos de orden pueden obtenerse en R, mediante la función sort{base}; la \(i\)-ésima posición del objeto resultante contendrá el \(i\)-ésimo estadístico de orden.
La mediana se obtiene directamente, usando la función median{stats}:
x <- c(3, 5, 6, 8, 25)
median(x)[1] 6A pesar de la clara superioridad que exhibe la mediana sobre la media como representante del centro de un conjunto de datos cuando este contiene valores extremos y de que en otras situaciones su desempeño es bastante similar al de la media, hay varias circunstancias que hacen que sea subutilizada, dejando a la media como la medida de tendencia central predominante.
Por una parte, existen razones teóricas, que se discuten en la sección 3.9.1.1.1, que hacen de la media una “mejor” elección para estimar el correspondiente parámetro poblacional, en el contexto de los métodos inferenciales. Consecuentemente, siempre que se apliquen métodos inferenciales clásicos, es decir, aquellos basados en la distribución normal, se usará la media en lugar de la mediana.
Por otra parte, con la mediana, el usuario tiene la sensación de estar “botando” información, confiándole todo el peso del resumen a un único dato, mientras que con la media siente que está usando toda la información.
Esta apreciación no es correcta. Realmente, en ambos casos hay participación de todas las observaciones. Lo que cambia es su forma de participación.
Así, para obtener el estadístico de orden \((n + 1)/2,\) es necesario contar con una muestra de tamaño \(n.\) La inclusión o exclusión de cualquier observación cambia el estadístico de orden central. El hecho de que la mediana no se vea necesariamente alterada por cambios en algunos de los datos muestrales solo es la expresión de su robustez.
Una situación en la que la mediana estaría claramente llamada a actuar como medida de tendencia central es la que se presenta cuando se realizan pruebas de laboratorio por triplicado. Esta es una práctica común, consistente en realizar una misma prueba sobre submuestras con el fin de disminuir la posibilidad de presentar un resultado alterado. En tales casos, cuando se obtienen resultados similares, suele calcularse el promedio de los mismos; si, por el contrario, se obtienen valores extremos a criterio del laboratorista, estos se descartan, calculándose el promedio de los restantes. En estos casos, bien sea que se obtengan valores extremos o no, la mediana sería la candidata perfecta para reportar los resultados en cuestión; de hecho, sería uno de los resultados obtenidos.
Otra situación en la que la mediana podría prestar un valioso servicio es la que surge cuando se tienen valoraciones que un panel de catadores realiza sobre las características organolépticas de un producto alimentario. En este caso, sin importar el tamaño del panel de catadores, la mediana no se vería afectada por eventuales calificaciones alteradas, emitidas por uno o varios de los panelistas, teniéndose en cuenta, sin embargo, la información de todos ellos para el cálculo del estadístico de orden central.
De igual manera, la mediana podría resultar más adecuada que la media como representante de la tendencia central de una unidad experimental, cuando se haya usado submuestreo para su evaluación (cf. sección 6.1.7); en especial, si se considera que las submuestras pudieran contener valores extremos.
Es una media modificada, donde a cada uno de los valores se le asigna un peso o ponderación específica, de manera que algunos valores pesen más que otros en el promedio. Para su cálculo, se suma cada uno de los valores de la muestra, multiplicado por su peso; este resultado se divide entre la suma de las ponderaciones.
\[
\bar{x}_{\text{w}}=\frac{\sum\limits_{i=1}^{n}{w_ix_i}}{\sum\limits_{i=1}^{n}{w_i}}
\]
Para ejemplificar el uso de la media ponderada, considérese el sistema de créditos académicos utilizado en muchas universidades, como una medida del tiempo que se espera que los estudiantes le dediquen a una asignatura o actividad académica.
En tales casos, si se deseara calcular la calificación media obtenida por un estudiante durante un semestre, lo natural sería valorar diferencialmente cada asignatura, acorde con la exigencia de la misma, esto es, con base en sus créditos académicos. Luego, las asignaturas que exijan mayor dedicación (mayor número de créditos) tendrán una mayor ponderación que las asignaturas de menor exigencia (menor número de créditos).
A continuación, se presentan las notas de cuatro asignaturas con sus correspondientes créditos.
| Asignatura | Créditos | Nota |
|---|---|---|
| Asignatura A | 5 | 3.0 |
| Asignatura B | 3 | 3.5 |
| Asignatura C | 2 | 4.2 |
| Asignatura D | 3 | 3.6 |
La nota media ponderada por el número de créditos se calcula con base en la siguiente expresión:
\[
\text{Nota}=\frac{(5\times3.0)+(3\times3.5)+(2\times4.2)+(3\times3.6)}{5+3+2+3}=3.4
\]
La media ponderada se obtiene en R, mediante la función weighted.mean{stats}:
créditos <- c(5, 3, 2, 3)
nota <- c(3.0, 3.5, 4.2, 3.6)
weighted.mean(nota, créditos)[1] 3.438462Observando el numerador de la expresión para el cálculo manual de la media ponderada, es evidente que, por la conmutatividad del producto, es indiferente cuál sea el primer factor y cuál otro sea el segundo3, pudiendo llevar a la conclusión errónea de que también es indiferente el orden de los argumentos en la función weighted.mean.
Esto, sin embargo, no es así, puesto que el denominador del promedio ponderado es la suma de los ponderadores. En tal sentido, debe respetarse el orden de los argumentos en la función weighted.mean, usando como primer argumento el vector de valores que se desea promediar (las notas en este caso), y como segundo, el vector de ponderadores (los créditos en este caso).
Nótese que, a pesar de que el hipotético estudiante del presente ejemplo haya obtenido una nota alta en la asignatura C, dicha asignatura tiene muy poco peso en relación con la asignatura A (menos de la mitad). Esto explica en parte por qué el promedio ponderado está más cerca de la nota obtenida en la asignatura A que de la nota obtenida en la asignatura C.
También en este caso —teniendo en cuenta el respectivo peso de cada dato— la media ponderada puede interpretarse como el centro de gravedad del conjunto de datos, tal y como se ilustra en la figura 2.5.

Cuando se promedian valores a los que se les han asignado diferentes porcentajes, el promedio calculado es justamente un promedio ponderado.
Supóngase la nota definitiva de una asignatura cuya evaluación se basa en tres exámenes parciales, acorde con los porcentajes que se muestran a continuación:
| Evaluación | Porcentaje | Nota |
|---|---|---|
| Parcial 1 | 25 % | 2.6 |
| Parcial 2 | 35 % | 3.0 |
| Parcial 3 | 40 % | 4.7 |
La nota definitiva de la asignatura se calcula con base en la siguiente expresión:
\[
\begin{align}
\text{Nota}&=\frac{(0.25\times2.6)+(0.35\times3.0)+(0.40\times4.7)}{0.25+0.35+0.40}\\[1.4em]
&=\frac{0.65+1.05+1.88}{1}\\[1.4em]
&=3.58
\end{align}
\]
Puesto que al realizar un cálculo como el ilustrado anteriormente, el denominador siempre es 1, este se obvia, con lo cual a menudo se pierde la noción de estar calculando una media ponderada. No obstante, esto es justamente lo que se hace siempre que se promedian valores con diferente peso porcentual.
Vale la pena anotar que la media aritmética es un caso particular de media ponderada, con cada uno de los datos recibiendo una ponderación igual a 1; consecuentemente, el denominador (suma de las ponderaciones) es igual a \(n.\)
Los promedios ponderados son bastante utilizados en la práctica estadística. Muchos métodos exigen la obtención de estadísticos a partir de muestras de diferente tamaño. En tales casos, es común usar factores de ponderación asociados con la cantidad de información aportada por cada muestra.
Asimismo, la media ponderada es la base de muchos índices que integran variables a las que se les conceden diferentes grados de importancia, tal y como el índice de condición integral propuesto por Correa-Londoño (2023).
Aunque esta medida de tendencia central no suele ocupar un lugar relevante en la descripción de información proveniente de procesos de investigación, es particularmente útil en contextos donde se requiere promediar tasas construidas a partir de denominadores variables.
La media armónica se calcula como el inverso multiplicativo del promedio de los inversos.
\[
H=\frac{n}{\sum\limits_{i=1}^{n}{\frac{1}{x_i}}}
\]
Esta medida permite consolidar la información de un conjunto de tasas calculadas con diferentes denominadores, generando una tasa global coherente con la estructura del conjunto.
Este sería el caso si se quisiera promediar, por ejemplo, el conjunto de velocidades de un vehículo que cubriera un trayecto compuesto por varios tramos de igual extensión, con velocidad constante dentro de cada uno de ellos, pero con diferentes velocidades entre tramos4.
En este escenario, las velocidades de cada tramo se calcularían con base en el mismo numerador (tramos de igual extensión), pero diferentes denominadores (tiempos variables). La media armónica de tales velocidades representa la velocidad constante a la que tendría que viajar el vehículo para recorrer el trayecto total en el mismo tiempo.
Para ilustrar esta situación, supóngase que el trayecto total está conformado por dos tramos de 60 km cada uno, cubiertos a velocidades de 60 km/h y 90 km/h, respectivamente.
Para recorrer el primer tramo de 60 km, el vehículo requiere 1 h; para el segundo tramo de 60 km, el vehículo requiere 6/9 h. Para cubrir el trayecto total, conformado por los dos tramos (A + B), el vehículo requiere 1 + 6/9 h. Luego, la velocidad promedio del trayecto total se calcula así:
\[
\frac{60+60}{1+6/9}=72\;\text{km/h}
\]
Este resultado, que indica la velocidad constante a la que tendría que viajar el vehículo para cubrir el mismo trayecto en el mismo tiempo, es la media armónica y puede obtenerse de manera directa:
\[
H=\frac{2}{\frac{1}{60}+\frac{1}{90}}=72
\]
En contraste con la situación anterior, cuando las tasas están basadas en un denominador común, debe usarse la media aritmética para su consolidación. Tal sería el caso si en el ejemplo anterior, en lugar de que el vehículo recorriera tramos de igual extensión, los recorridos parciales se realizaran durante un periodo de tiempo determinado.
Así, si el vehículo avanzara, por ejemplo, durante una hora a una velocidad de 60 km/h y seguidamente avanzara durante otra hora a 90 km/h, la media aritmética (75 km/h) representaría la velocidad constante a la que tendría que avanzar el vehículo durante el mismo tiempo (2 horas) para recorrer la misma distancia (150 km).
Cuando ni el numerador ni el denominador permanecen constantes entre observaciones, la media armónica simple deja de ser suficiente, siendo necesario introducir factores de ponderación, lo que da lugar a la media armónica ponderada:
\[
H_{\text{w}}=\frac{\sum\limits_{i=1}^{n}{w_i}}{\sum\limits_{i=1}^{n}{w_i}\frac{1}{x_i}}
\]
Siguiendo con el ejemplo del vehículo, considérese ahora, que tanto las distancias como los tiempos en cada uno de los tramos son variables, tal y como se ilustra a continuación.
| Tramo | A | B |
|---|---|---|
| Extensión (km) | 10 | 40 |
| Velocidad (km/h) | 60 | 90 |
Nótese que cada tramo tiene una extensión diferente y que el tiempo requerido para cubrirlos también varía. Para cubrir el primer tramo se requiere 1/6 h, mientras que el segundo exige 4/9 h. La velocidad constante a la que tendría que realizarse todo el trayecto para cubrirlo en el mismo tiempo se calcula con la media armónica ponderada, usando la distancia (numerador) como factor de ponderación, así:
\[
H_{\text{w}}=\frac{10+40}{10\frac{1}{60}+40\frac{1}{90}}=\frac{50}{\frac{1}{6}+\frac{4}{9}}=81.82
\]
El valor de la media armónica es inferior al de la media aritmética, excepto cuando todos los valores muestrales son iguales, en cuyo caso ambas medidas coinciden con el valor muestral común. La media armónica es robusta a la presencia de valores extremos superiores, mientras que se ve fuertemente afectada por valores extremos inferiores.
Como parte de los métodos estadísticos aplicados a la investigación puede ser útil en expresiones que utilizan ponderadores recíprocos. La media armónica resulta conservadora, acercándose más a los ponderadores bajos.
Considérese un índice basado en dos muestras, que se calcula con base en la expresión \(\text{CME}/r,\) donde \(\text{CME}\) es un valor que de momento no es necesario discutir, bastando con mencionar que es una constante, y \(r\) es el tamaño de las muestras. Supóngase ahora una situación en la que se tengan diferentes tamaños muestrales: \(r_1=3\) y \(r_2=8.\) La media armónica de \(r\) es:
\[
H=\frac{2}{\frac{1}{3}+\frac{1}{8}}=4.36
\]
El índice considerado anteriormente resulta mayor al usar la media armónica \((\text{CME}/4.36)\) que al trabajar con la media aritmética \((\text{CME}/5.5).\) En el contexto de pruebas de medias, en el que se usa el índice en cuestión, un valor alto implica mayor exigencia, siendo mayor para muestras de menor tamaño. Es en este sentido que la media armónica resulta más conservadora en tales contextos5.
Para calcular la media armónica en R, bastaría con obtener el inverso de la media de los inversos, así:
x <- c(3, 8)
1 / mean(1/x)[1] 4.363636No obstante, también puede calcularse directamente con la función Hmean{DescTools}:
x <- c(3, 8)
DescTools::Hmean(x)[1] 4.363636Es una medida netamente descriptiva. Su significado en el ámbito muestral es equivalente al que tiene la palabra moda en la cotidianidad: la moda es lo que más se usa, lo que más se ve, lo que aparece con mayor frecuencia; asimismo, la moda de una muestra es el valor que más se repite en el conjunto de datos.
Una muestra puede tener una única moda (unimodal), varias modas (bimodal para el caso de dos modas; multimodal, para más de una moda, en general) o carecer de moda. En caso de que existan una o más modas, estas corresponderán con alguno o algunos de los valores observados en el conjunto de datos.
Al realizar descripciones, el concepto de moda se usa en sentido amplio, referido a regiones modales, definidas como los sectores con mayor concentración de información. Así, por ejemplo, cuando se afirma que determinada zona tiene un régimen bimodal de lluvias concentradas en abril y octubre, se está afirmando que en dicha zona las lluvias son más frecuentes durante esos dos meses. El concepto de región modal tiene aplicación aun si la moda no existe; e incluso cuando la moda existe, el concepto de región modal puede resultar más informativo.
En la sección 2.1.1.1 se presentó un ejemplo en el que se cuestionaba el uso de la media como medida de tendencia central cuando se tenían dos grupos (niños de guardería y estudiantes de posgrado).
Esta advertencia puede generalizarse a todas las situaciones en las que se tengan distribuciones multimodales. En tales casos, podría resultar más conveniente tratar de identificar los diferentes grupos que conforman la muestra, para proceder a caracterizarlos individualmente.
De las medidas de tendencia central presentadas, la moda es la única que puede usarse sobre variables registradas en escala nominal. Así, puede decirse, por ejemplo, que el color modal de una muestra es el negro. En tal sentido, constituye una excepción a lo expresado anteriormente sobre las medidas de resumen, cuando se decía que eran valores numéricos.
Aunque no existe una función incorporada en R para el cálculo de la moda, esta puede obtenerse a partir del siguiente par de instrucciones, donde x es un vector con los datos:
tabla <- table(x)
names(tabla)[tabla == max(tabla)]Estas instrucciones mostrarían únicamente la moda o modas en su acepción clásica, es decir, aquel o aquellos valores más frecuentes, ignorando regiones modales o valores altamente frecuentes, que no tengan la máxima frecuencia.
Así, por ejemplo, si en un conjunto de datos hay uno de ellos que aparezca 20 veces, otro, 19 y el resto, una sola vez, las instrucciones anteriores únicamente mostrarían aquel valor que aparezca 20 veces, ignorando el que esté presente 19 veces.
La función mode{base} en R no tiene nada que ver con la medida de tendencia central, sino con la forma (modo) en que los objetos son almacenados internamente.
Las medidas de dispersión o variabilidad indican qué tan cercanos o alejados se encuentran los datos entre sí; en otras palabras, indican el grado de homogeneidad o heterogeneidad de la muestra.
Considérense las siguientes muestras: \(\{4, 5, 6, 7, 8\}\) y \(\{1, 3, 6, 9, 11\},\) con sus correspondientes representaciones gráficas (figura 2.6).

Aunque ambos conjuntos de datos están centrados en 6, el primero se encuentra más concentrado que el segundo. Esto pone en evidencia que las medidas de tendencia central no son suficientes para caracterizar una muestra; hacen falta otras medidas para calificar el grado de dispersión.
Las medidas de dispersión suelen obtenerse con base en las distancias entre los diferentes puntos y el referente de centralidad.
Es la medida de dispersión más usada en los métodos clásicos de estadística inferencial. Se obtiene como el cuasi promedio de las distancias cuadráticas entre cada valor y la media.
\[
s^2=\frac{\sum\limits_{i=1}^{n}{\bigl(x_i-\bar{x}\,\bigr)^2}}{n-1}
\tag{2.1}\]
Podría pensarse en omitir la potencia cuadrática en el numerador y trabajar únicamente con las diferencias entre cada valor y la media; sin embargo, la suma lineal de tales diferencias siempre es igual a cero, por lo que no brinda información alguna acerca de la variabilidad de la muestra.
También podría pensarse en tomar las diferencias en valor absoluto, es decir, las distancias. Aunque esta es una alternativa válida como medida de dispersión (en la sección 2.1.2.4 se presenta una versión equivalente), es preferible trabajar con la suma de las distancias cuadráticas —denominada suma de cuadrados— por razones teóricas que se exponen en la sección 3.9.1.1.2.
Las sumas de cuadrados constituyen la base del método de descomposición de la variabilidad desarrollado en el capítulo 6 (cf. secciones 6.2 y 6.2.3).
Puesto que el numerador se ve afectado por el tamaño de la muestra, resultaría insuficiente por sí solo como medida de dispersión: a mayor tamaño muestral, mayor será la suma de distancias cuadráticas, independientemente de que la muestra se haga más dispersa o no.
Por tal motivo, lo natural sería construir un índice de dispersión basado en el promedio de las desviaciones cuadráticas, esto es, dividir dichas desviaciones entre \(n.\) No obstante, al calcular la varianza muestral se utiliza \(n − 1\) en el denominador, en lugar de \(n,\) por razones teóricas que se discuten en la sección 3.9.1.1.2.
Al observar la expresión 2.1 resulta evidente que la varianza de cualquier muestra siempre será mayor o igual a cero, siendo cero únicamente si todos los datos son iguales entre sí y, por tanto, iguales a la media; este sería el caso de una constante o de una variable en la que, por cuestiones del muestreo, todos los registros hubieran resultado iguales.
A mayor varianza, mayor será la dispersión del conjunto de datos. La varianza se expresa en las unidades de la variable original elevadas al cuadrado. Las varianzas solo son comparables entre conjuntos de datos que tengan las mismas unidades.
La fórmula operacional para el cálculo de la varianza es:
\[
s^2=\frac{\sum_{i=1}^{n}{x_i}^2- \frac{\left(\, \sum_{i=1}^{n}{x_i} \right)^2} {n}} {n-1}
\tag{2.2}\]
Muchas expresiones matemáticas pueden escribirse de diferentes maneras, dependiendo de los desarrollos que se realicen sobre las mismas.
En el presente texto, muchas de las expresiones que surgen en la práctica estadística se presentarán bajo dos formas: 1) una fórmula conceptual, que facilita la visualización y comprensión del concepto implícito, la cual, por lo general, es más fácil de recordar (cf. expresión 2.1), y 2) una fórmula operacional, que es la que suele utilizarse para realizar los cálculos (cf. expresión 2.2).
La fórmula operacional surgió como estrategia para facilitar el cálculo y disminuir la acumulación de errores por redondeo, en una época en la que los recursos computacionales eran muy escasos o ausentes.
En la actualidad, aunque las herramientas computacionales permiten obtener los mismos resultados con cualquiera de las dos expresiones, las formas operacionales siguen considerándose más eficientes, siendo estas las que usualmente se programan en los algoritmos computacionales.
La fórmula operacional se deriva de la fórmula conceptual y siempre es equivalente a esta.
A continuación, se muestran los pasos necesarios para llegar a la fórmula operacional de la varianza, partiendo de su fórmula conceptual.
\[
\begin{align}
s^2&=\frac{\sum\limits_{i=1}^{n}{\left(x_i-\bar{x}\right)^2}}{n-1}\\[1.4em]
&=\frac{\sum\limits_{i=1}^{n}{\Bigl(x_i^2-2x_i\bar{x}+\bar{x}^2\Bigr)}}{n-1}\\[1.4em]
&=\frac{\sum_{i=1}^{n}{x_i^2-2\biggl(\frac{\sum_{i=1}^{n}{x_i}}{n}\biggr)\sum_{i=1}^{n}{x_i}+n\biggl(\frac{\sum_{i=1}^{n}{x_i}}{n}\biggr)^2}}{n-1}\\[1.4em]\\[1.4em]
&=\frac{\sum_{i=1}^{n}{x_i^2}-\frac{2}{n} \left(\,\sum_{i=1}^{n}{x_i} \right)^2+\frac{1}{n} \left(\, \sum_{i=1}^{n}{x_i} \right)^2} {n-1}\\[1.4em]
&=\frac{\sum_{i=1}^{n}{x_i}^2- \frac{\left(\, \sum_{i=1}^{n}{x_i} \right)^2} {n}} {n-1}
\end{align}
\]
Considérense nuevamente las muestras utilizadas para ilustrar el concepto de dispersión: \(\{4, 5, 6, 7, 8\}\) y \(\{1, 3, 6, 9, 11\}.\)
A continuación se ilustra el uso de la fórmula operacional para calcular la varianza de la primera muestra, la cual evidenció gráficamente menor dispersión (cf. figura 2.6):
\[
\begin{align}
s^2&=\frac{\sum\limits_{i=1}^{n}{x_i}^2- \frac{\left(\, \sum\limits_{i=1}^{n}{x_i} \right)^2} {n}} {n-1}\\[1.4em]
&= \frac{4^2+5^2+6^2+7^2+8^2- \frac{(4+5+6+7+8)^2} {5}} {4}\\[1.4em]
&=\frac{190-\frac{30^2}{5}}{4}\\[1.4em]
&= 2.5
\end{align}
\]
En contraste, la varianza de la segunda muestra es \(s^2=17.\)
Para calcular la varianza en R, se usa la función var{stats}:
x <- c(4, 5, 6, 7, 8)
var(x)[1] 2.5Es la raíz cuadrada positiva de la varianza.
\[
s=\sqrt{s^2}=\sqrt{\frac{\sum\limits_{i=1}^{n}{x_i}^2- \frac{\left(\, \sum\limits_{i=1}^{n}{x_i} \right)^2} {n}} {n-1}}
\]
Al tratarse de una transformación, la desviación estándar no suministra ninguna información adicional a la que ya está contenida en la varianza. El hecho de usar la varianza o la desviación estándar para describir la dispersión de una muestra es equivalente a presentar una longitud en metros o en centímetros.
Las desviaciones estándar de las dos muestras usadas en la sección 2.1.2.1 para ejemplificar la varianza son \(s=1.58\) y \(s=4.12,\) respectivamente.
Para calcular la desviación estándar en R, se usa la función sd{stats}:
x <- c(4, 5, 6, 7, 8)
sd(x)[1] 1.581139En el contexto descriptivo —como complemento a la media como medida de tendencia central— suele reportarse la desviación estándar como medida de dispersión, dado que se expresa en las mismas unidades de la variable.
Esta medida de dispersión es adecuada para comparar la variabilidad de conjuntos de datos centrados en diferentes puntos.
Por tratarse de una medida adimensional (no tiene unidades de medida), permitiría incluso comparar la variabilidad de conjuntos de datos con diferentes unidades; no obstante, este tipo de comparaciones rara vez tendría utilidad práctica.
Considérense dos muestras, con las medidas de resumen que se relacionan a continuación:
| Muestra | Media | Desviación estándar |
|---|---|---|
| Muestra A | 10 t/ha | 2.5 t/ha |
| Muestra B | 4 t/ha | 2 t/ha |
Al observar los estadísticos de los dos grupos, podría afirmarse que la muestra A es más variable que la muestra B, dado que su desviación estándar es mayor. Aunque esto es cierto en términos absolutos, es importante tener presente que las medidas de dispersión indican qué tan concentrados o dispersos se encuentran los datos respecto a un punto central.
En tal sentido, para comparar la variabilidad de muestras con diferentes centros puede resultar más conveniente el uso de una medida relativa de la dispersión de cada conjunto con respecto a su correspondiente centro.
El coeficiente de variación se expresa como el porcentaje que la desviación estándar representa con respecto a la media (en ocasiones se multiplica por 100).
\[
\text{CV}=100\:\frac{s}{\bar{x}}
\]
El coeficiente de variación de la muestra A es 25 %, mientras que el de la muestra B es 50 %. Esto quiere decir que la variación representada por una desviación estándar de 2.5 t/ha en una muestra centrada en 10 t/ha es menor que la variación representada por una desviación estándar de 2 t/ha en una muestra centrada en 4 t/ha.
Es fácil recordar que el coeficiente de variación se construye como la razón entre estos dos estadísticos; no obstante, a veces se dificulta recordar cuál va en el numerador y cuál otro, en el denominador.
Hay un par de consideraciones que pueden servir de recurso nemotécnico: por una parte, debe tenerse en cuenta que el coeficiente de variación es una medida de variación; luego, el estadístico que expresa la variación, esto es, la desviación estándar, va en el numerador. Por otra parte, debe tenerse presente que el coeficiente de variación expresa la variación relativa a la media; luego, la media va en el denominador.
A pesar de que el coeficiente de variación se expresa porcentualmente, se trata de una razón que no está acotada entre 0 y 100. Bastaría con tener una desviación estándar superior a la media para obtener un coeficiente de variación mayor del 100 %.
Asimismo, es importante tener en cuenta que —puesto que la media va en el denominador— el coeficiente de variación puede verse distorsionado cuando la media exhibe valores muy bajos.
Finalmente, es importante anotar que, como herramienta descriptiva, el coeficiente de variación no tiene más valor que el presentado hasta aquí: indicar la variación porcentual de un conjunto de datos y comparar la variación relativa de datos con diferentes centros. Luego, no tiene sentido realizar ningún juicio de valor acerca de lo “bueno” o “malo” que pueda resultar un coeficiente de variación. En el capítulo 6 se presenta el coeficiente de variación en otro contexto y se discute sobre la valoración del mismo (cf. sección 6.1.16).
Para obtener el coeficiente de variación en R, se combinan las funciones mean y sd.
En situaciones en las que se desestime la media para caracterizar la centralidad de un conjunto de datos, y se utilice en su lugar la mediana, no sería consistente caracterizar la dispersión usando la desviación estándar, dado que esta resume las desviaciones cuadráticas con respecto a la media.
Lo natural al usar la mediana para caracterizar la tendencia central es acompañarla con una medida de dispersión que resuma las desviaciones entre cada observación y la mediana. Una de las medidas más populares para este fin es la desviación mediana absoluta (MAD, por sus siglas en inglés: Median Absolute Deviation), que esta basada en la mediana de las desviaciones absolutas de cada valor con respecto a la mediana:
\[
\text{MAD}_0=\text{mediana}\left({\left| x_i-\tilde{x} \right|,\; i=1, 2,\dots, n }\right)
\]
El resultado de evaluar esta expresión, aunque coherente con la mediana como medida de tendencia central, no es el que suele reportarse como medida de dispersión. En su lugar se prefiere el uso de una versión escalada que tiene la ventaja de quedar en las mismas unidades que la variable original y que además resulta comparable, en términos de magnitud, con la desviación estándar.
\[
\text{MAD}=1.4826\times\text{mediana}\left({\left| x_i-\tilde{x} \right|},\; i=1, 2,\dots, n\right)
\]
Para ilustrar el cálculo de la \(\text{MAD},\) consideremos nuevamente el conjunto de salarios usados en la sección 2.1.1 para ejemplificar la falta de robustez de la media ante la presencia de valores extremos: \(\{3, 5, 6, 8, 25\}.\)
El siguiente conjunto representa las desviaciones de cada valor con respecto a la mediana \(\left(\tilde{x}=6\right)\text{:}\)
\(\{|3-6|, |5-6|, |6-6|, |8-6|, |25-6|\}=\{3, 1, 0, 2, 19\}.\)
La mediana de este conjunto de desviaciones con respecto a la mediana es 2. Luego, \(\text{MAD}=1.4826\times 2=2.9652\).
Esta versión escalada se calcula en R, mediante la función mad{stats}:
x <- c(3, 5, 6, 8, 25)
mad(x) [1] 2.9652Si en un contexto descriptivo utiliza la mediana, en lugar de la media, como medida de tendencia central, complemente el análisis con la \(\text{MAD},\) que es su medida de dispersión natural.
Esta medida de dispersión se calcula como la diferencia entre el máximo y el mínimo valor de la muestra.
\[
\text{recorrido} = \text{máximo} - \text{mínimo}\equiv x_{(n)}-x_{(1)}
\]
Aunque al recorrido también se le conoce como rango, —para evitar confusiones— se recomienda reservar dicho término para aludir al concepto que se detalla en la sección 9.1.
En inglés no se presenta dicha confusión, pues existe un término diferente para cada concepto: a la medida de dispersión se le denomina range; a la aplicación de un ranquin se le denomina rank.
A pesar de tratarse de una medida de dispersión relativamente simple, en comparación con la varianza, el recorrido ofrece información complementaria que no puede obtenerse a partir de aquella.
Asimismo, aunando el concepto del recorrido con el de poda (cf. sección 2.1.1.1) pueden generarse medidas de variabilidad robustas, la más popular de las cuales es el recorrido intercuartil, el cual se presenta en la sección 2.3.6, como parte del gráfico de caja y bigotes.
En R, el recorrido puede calcularse a partir de las funciones max{base} y min{base}, que permiten hallar el máximo y el mínimo muestral, respectivamente:
max(x) - min(x)Equivalentemente, puede obtenerse así:
diff(range(x))Aun cuando las medidas de tendencia central y de dispersión reflejan importantes aspectos de los datos, no alcanzan a cubrir el panorama completo en lo concerniente a su distribución. Las medidas de forma brindan una caracterización adicional de los datos.
Indica el grado de asimetría en la distribución de los datos con respecto a la media, esto es, la manera en que se reparten los valores que se encuentran a la izquierda de la media con respecto a los que se encuentran a su derecha.
Considérense las siguientes muestras, las cuales se representan en la figura 2.7:
| Muestra 1 | 5 | 6.3 | 6.9 | 7.4 | 9.2 | 10 | 12.9 | 18.1 |
| Muestra 2 | 0.85 | 6.05 | 8.95 | 9.75 | 11.55 | 12.05 | 12.65 | 13.95 |

Aunque ambos conjuntos de datos están centrados en el mismo punto \(\left( \bar{x}=9.475\right)\) y tienen la misma desviación estándar \(\left(s=4.268\right),\) resulta evidente que difieren en su patrón de asimetría.
El coeficiente de asimetría es una medida que resume la asimetría de los datos alrededor de la media. Se calcula con base en la siguiente expresión:
\[
g_1\equiv a=\frac{n}{(n-1)(n-2)} \frac{\sum\limits_{i=1}^{n}{\bigl(x_i-\bar{x}\,\bigr )^3}}{s^3}
\tag{2.3}\]
Al coeficiente de asimetría que se calcula mediante la expresión 2.3 se le denomina coeficiente de asimetría ajustado de Fisher-Pearson.
Esta es la versión del coeficiente de asimetría que se encuentra implementada en el algoritmo de skewness{agricolae}.
Puesto que las desviaciones entre cada dato y la media de la muestra están elevadas a la tercera potencia, este coeficiente puede ser positivo, negativo o cero. En la figura 2.8 se tipifican tres situaciones, representando la concentración de datos en una región, mediante la acumulación vertical de los correspondientes puntos.
La asimetría es cero cuando los datos se encuentran distribuidos simétricamente alrededor de la media (figura 2.8 (a)); en tal caso, se dice que la distribución de los datos es simétrica. La figura 2.8 (b) representa un conjunto de datos con asimetría a la derecha; en este caso, el coeficiente de asimetría es positivo. En la figura 2.8 (c) se representa un conjunto de datos con asimetría a la izquierda, en cuyo caso, el coeficiente de asimetría es negativo.
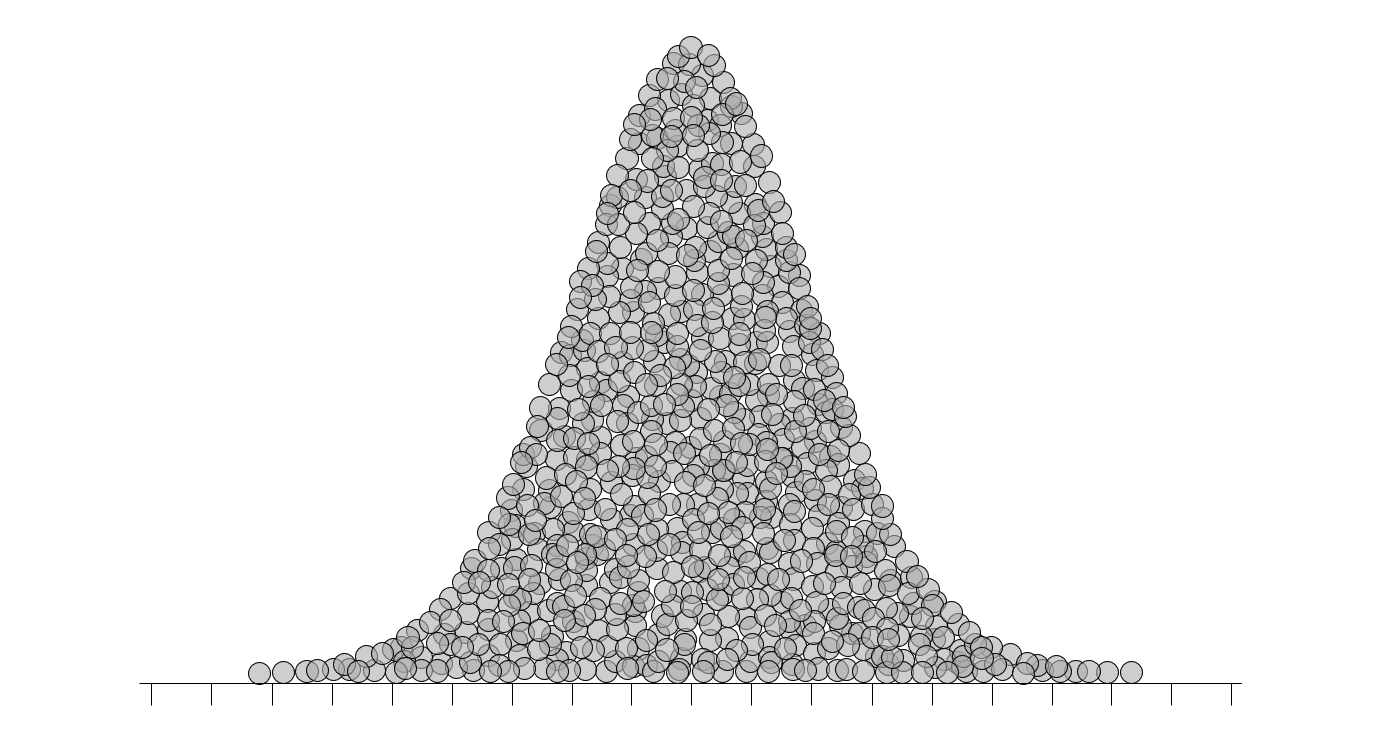
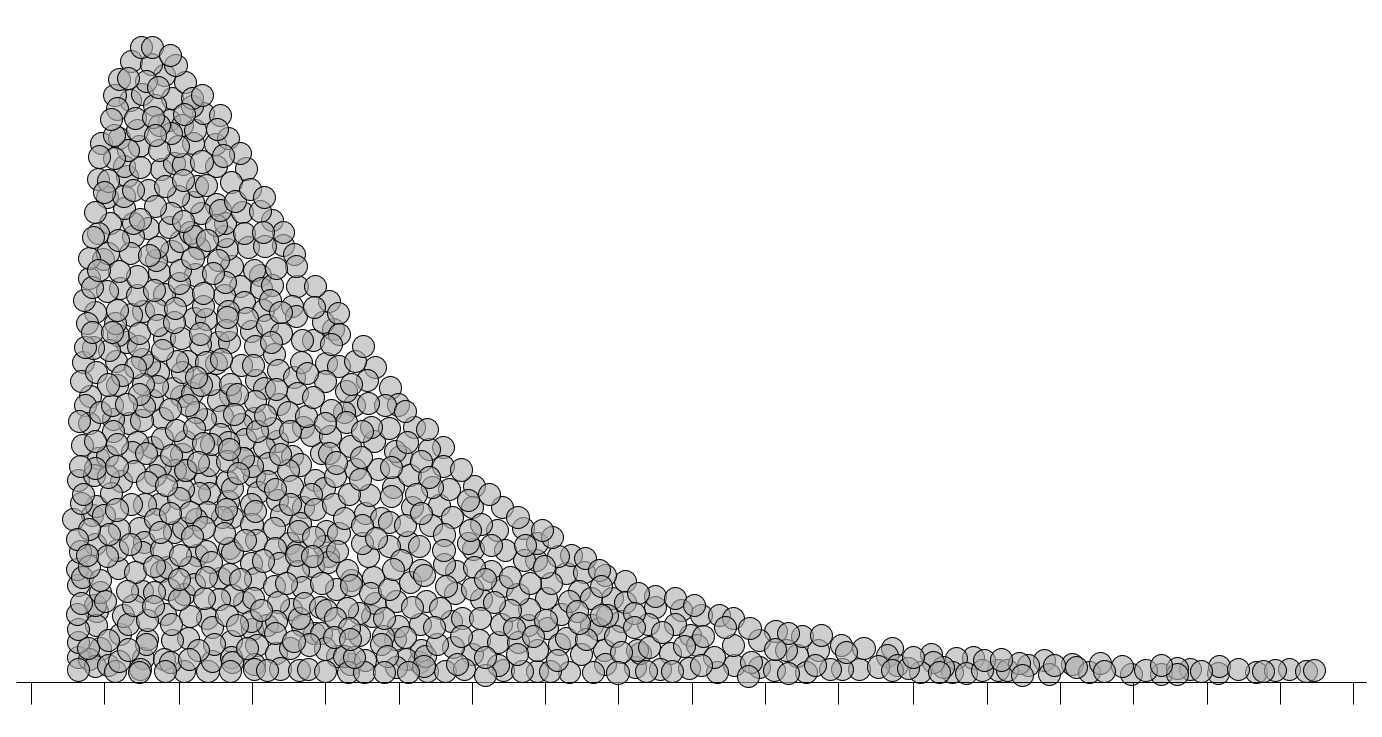
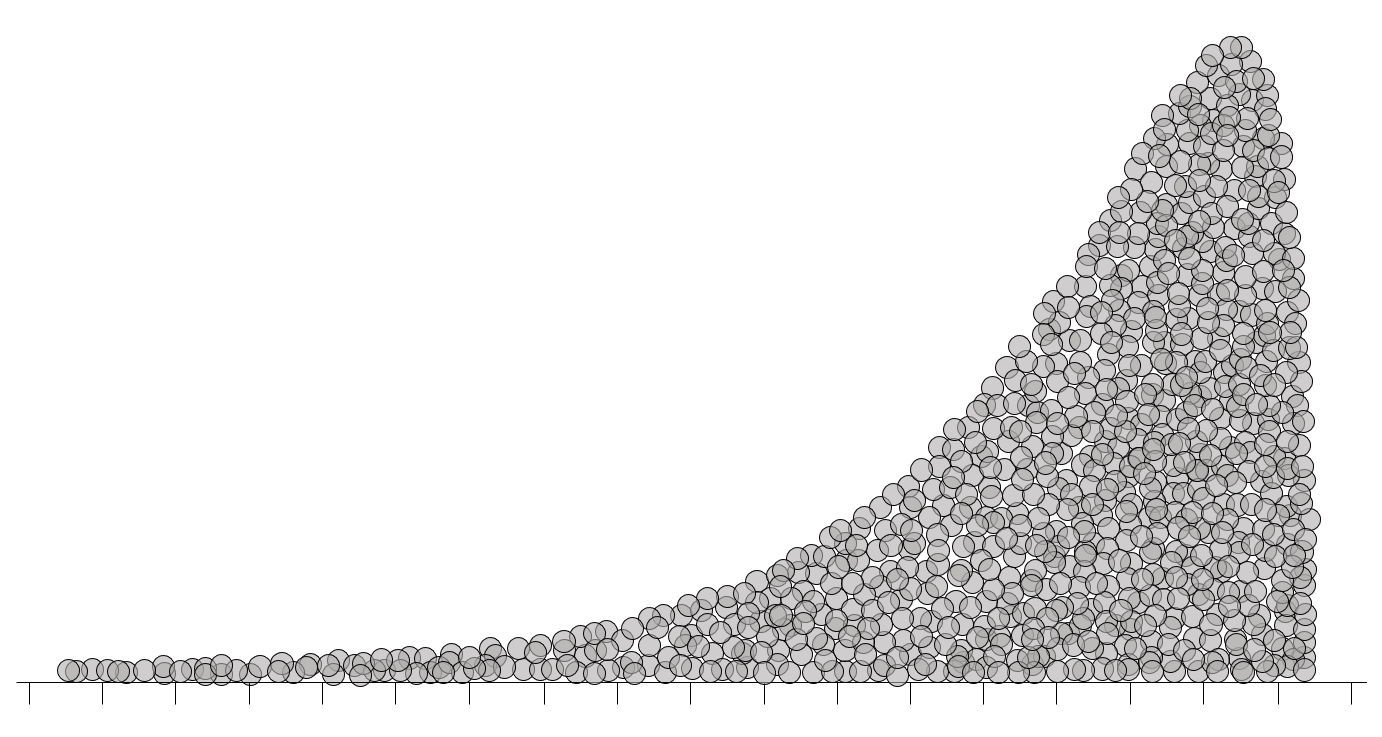
La manera en que se nombran los diferentes patrones de asimetría (izquierda o derecha) tiene que ver con la cola de la distribución, es decir, con la parte más delgada del gráfico (la que acumula menos información). El símbolo de desigualdad mediante el cual se relaciona el coeficiente de asimetría con el cero señala hacia la cola de la distribución, por lo que puede usarse como ayuda nemotécnica: \(a < 0\): asimetría a la izquierda; \(a > 0\): asimetría a la derecha.
En la figura 2.8 se tipifican diferentes patrones de asimetría para conjuntos de datos unimodales. En conjuntos de datos multimodales, los patrones pueden ser más complejos. Para datos con una sola moda, pueden establecerse las siguientes relaciones:
\[
\text{Si } a = 0,\quad \bar{x}=\tilde{x}=\text{moda}
\] \[
\text{Si } a > 0,\quad \bar{x}>\tilde{x}>\text{moda}
\] \[
\text{Si } a < 0,\quad \bar{x}<\tilde{x}<\text{moda}
\]
A la asimetría también se le conoce como sesgo; no obstante, este término también se aplica a un concepto que se detalla en la sección 3.9.1.1 (cf. definición 3.27).
En inglés estos conceptos están claramente diferenciados, correspondiéndole a cada uno un término diferente: a la medida de forma se le denomina skewness; a la propiedad de un estimador puntual de un parámetro poblacional que se detalla en la sección 3.9.1.1 se le denomina bias.
A modo de ilustración, se presenta el cálculo del coeficiente de asimetría para las dos muestras definidas anteriormente y representadas en la figura 2.7.
El coeficiente de asimetría para la primera muestra es:
\[
\begin{multline}
a=\frac{8}{(8-1)(8-2)}\\
\times\frac{(5-9.475)^3+(6.3-9.475)^3+\dotsb+(18.1-9.475)^3}{4.268^3}\\
=1.3089
\end{multline}
\]
El valor positivo indica que dicha muestra tiene asimetría a la derecha, es decir, que existe una mayor concentración de datos a la izquierda, dejando una cola con pocos datos a la derecha (cf. figuras 2.7 y 2.8 (b)). La media es \(\bar{x}= 9.475;\) la mediana, \(\tilde{x}=8.3;\) y aunque no existe la moda, puede apreciarse una región modal alrededor de 7. Se verifica, pues, que \(\bar{x}>\tilde{x}>\text{moda}.\)
El coeficiente de asimetría para la segunda muestra es:
\[
\begin{multline}
a=\frac{8}{(8-1)(8-2)}\\
\times\frac{(0.85-9.475)^3+(6.05-9.475)^3+\dotsb+(13.95-9.475)^3}{4.268^3}\\
=-1.3089
\end{multline}
\]
La razón por la que se ha obtenido un coeficiente de asimetría de igual magnitud que el de la muestra 1, pero de signo contrario, se debe a que cada muestra constituye una imagen espectral de la otra con respecto a la media.
El valor negativo indica que la asimetría de esta muestra es a la izquierda, es decir, que existe una mayor concentración de datos a la derecha, dejando una cola con pocos datos a la izquierda (cf. figuras 2.7 y 2.8 (c)). La media es \(\bar{x}=9.475;\) la mediana, \(\tilde{x}=10.65;\) y aunque no existe la moda, la región modal está alrededor de 12. Se verifica, por tanto, que \(\bar{x}<\tilde{x}<\text{moda}.\)
El coeficiente de asimetría puede obtenerse en R, mediante la función skewness{agricolae}.
m1 <- c(5, 6.3, 6.9, 7.4, 9.2, 10, 12.9, 18.1)
agricolae::skewness(m1)[1] 1.308954m2 <- c(0.85, 6.05, 8.95, 9.75, 11.55, 12.05, 12.65, 13.95)
agricolae::skewness(m2)[1] -1.308954Esta medida de forma caracteriza la concentración de datos en determinados sectores. Aunque tradicionalmente —desde que fue propuesta por Karl Pearson en 1905— se ha descrito como una medida de apuntamiento o puntiagudez, que indica el grado de concentración de datos alrededor de la media, esta interpretación ha sido cuestionada. Westfall (1977) señala que dicha lectura es equívoca y argumenta que la curtosis debe interpretarse exclusivamente en términos de la concentración de datos en las colas de la distribución.
El coeficiente de curtosis es una medida relativa, que toma como referente la distribución normal, una distribución probabilística teórica que se discute en la sección 3.7.1.
\[
k=\frac{n(n+1)}{(n-1)(n-2)(n-3)}\frac{\sum\limits_{i=1}^{n} {\bigl(x_i-\bar{x}\,\bigr)^4}}{s^4}-3\frac{(n-1)^2}{(n-2)(n-3)}
\tag{2.4}\]
El valor esperado del coeficiente de curtosis básico —usualmente denotado como \(g_2\)— para datos normales es 3; no obstante, para facilitar la interpretación, suele utilizarse la versión transformada o corregida que se presenta en la expresión 2.4, cuyo valor esperado para la distribución normal es 0.
En la literatura, \(g_2\) suele referirse a la curtosis excedente, aunque también es común que se mantenga el nombre original.
\[
k=g_2-3
\]
El algoritmo implementado en kurtosis{agricolae} calcula el coeficiente de curtosis excedente de Fisher-Pearson, acorde con la expresión 2.4.
La interpretación del coeficiente de curtosis siempre se realiza en función de lo que se espera de la distribución teórica de referencia: la normal (cf. sección 3.7.1), cuya distribución se denomina mesocúrtica. Una muestra con tanta información en las colas como la esperada bajo normalidad presenta un coeficiente de curtosis igual a 0 (cf. figura 2.9 (a)). Si la muestra tiene más información en las colas (colas pesadas) que la que se esperaría para una distribución normal, se obtiene un valor positivo y se dice que la distribución es leptocúrtica (cf. figura 2.9 (b)). Cuando la muestra tiene menos información en las colas (colas livianas) que la que se esperaría para una distribución normal, se obtiene un coeficiente de curtosis negativo y se dice que la distribución es platicúrtica (cf. figura 2.9 (c)).

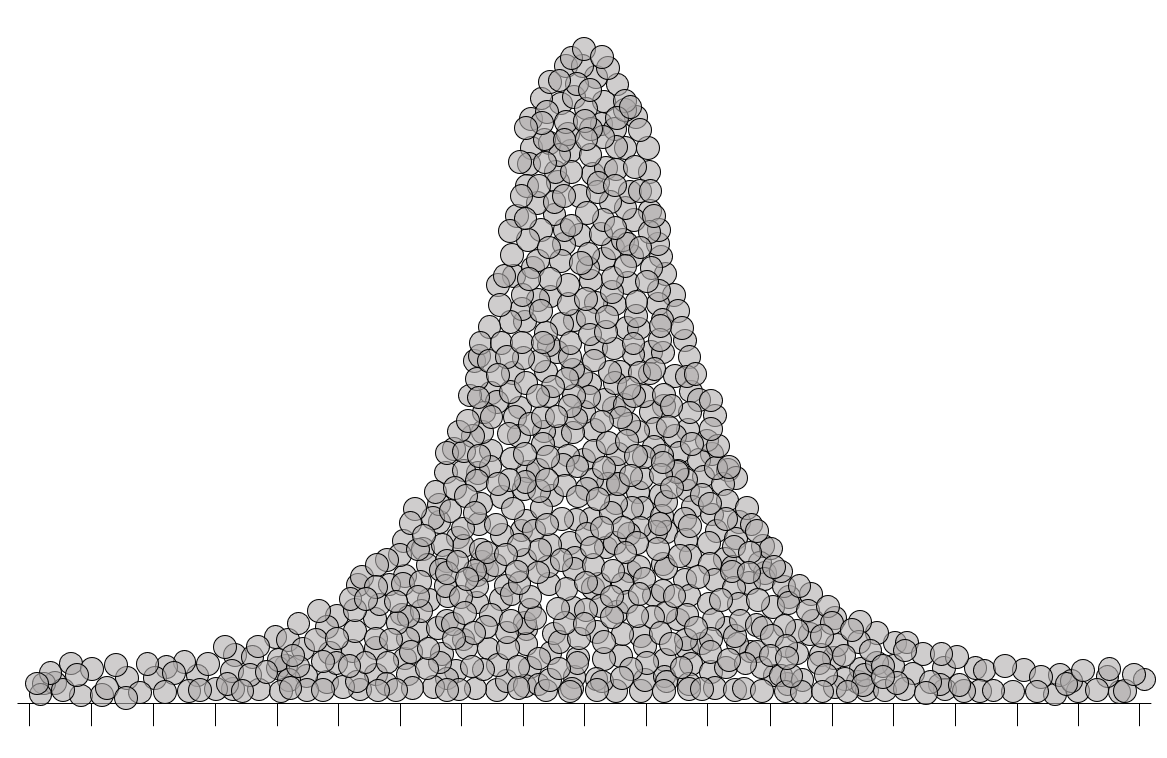

Para ilustrarlo numéricamente, considérense las siguientes muestras:
| Muestra 1 | 0.5 | 4.0 | 6.0 | 6.5 | 7.0 | 7.5 | 8.0 | 10.0 | 13.5 |
| Muestra 2 | 1.5 | 3.5 | 4.0 | 6.0 | 7.0 | 8.0 | 10.0 | 10.5 | 12.5 |
Puede comprobarse que ambas muestras presentan valores coincidentes de media \((\bar{x}=7),\) desviación estándar \((s=3.6228)\) y coeficiente de asimetría \((a=0).\) No obstante, el patrón de concentración de los datos es diferente, tal y como se aprecia en la figura 2.10.

El coeficiente de curtosis para la primera muestra se calcula así:
\[
\begin{multline}
k=\frac{9(9+1)}{(9-1)(9-2)(9-3)}\\
\times\frac{(0.5-7)^4+(4-7)^4+\dotsb+(13.5-7)^4}{3.6228^4}\\
-3\frac{(9-1)^2}{(9-2)(9-3)}=1.235
\end{multline}
\]
El valor positivo indica que dicha muestra tiene una distribución leptocúrtica, es decir, con más información en las colas que la que se esperaría en la distribución normal de referencia (colas pesadas).
El coeficiente de curtosis para la segunda muestra es:
\[
\begin{multline}
k=\frac{9(9+1)}{(9-1)(9-2)(9-3)}\\
\times\frac{(1.5-7)^4+(3.5-7)^4+\dotsb+(12.5-7)^4}{3.6228^4}\\
-3\frac{(9-1)^2}{(9-2)(9-3)}=-1.004
\end{multline}
\]
En este caso, se obtiene un coeficiente de curtosis negativo, lo que significa que la segunda muestra tiene una distribución platicúrtica, esto es, con menos datos en las colas que la distribución normal (colas livianas).
El coeficiente de curtosis puede obtenerse en R, usando la función kurtosis{agricolae}:
m1 <- c(0.5, 4, 6, 6.5, 7, 7.5, 8, 10, 13.5)
agricolae::kurtosis(m1)[1] 1.234985m2 <- c(1.5, 3.5, 4, 6, 7, 8, 10, 10.5, 12.5)
agricolae::kurtosis(m2)[1] -1.004082Es importante resaltar que la información que proporciona la curtosis sobre la distribución de la muestra, y en particular sobre el grado de concentración de datos en las colas, no puede obtenerse a través de ninguno de los otros estadísticos presentados.
La curtosis es independiente de la varianza; el tener más información en las colas no necesariamente incrementa la varianza; de hecho, en el presente ejemplo se ilustra que es posible tener muestras con la misma varianza y diferentes patrones de curtosis.
Existen por lo menos nueve definiciones diferentes de cuantiles muestrales, las cuales son discutidas por Hyndman y Fan (1996), quienes abogan por la unificación.
En tal sentido, tras analizar sus propiedades, Hyndman y Fan (1996) recomiendan obtener los cuantiles muestrales con base en la siguiente definición, en la que \(x_{(i)}\) representa el \(i\)-ésimo estadístico de orden de la muestra (cf. definición 2.1):
\[
\begin{equation}
\small{p\text{-cuantil}=
\begin{cases}
x_{(1)} &\;\; \text{si } p < \frac{2}{3}/\bigl(n+\frac{1}{3}\bigr),\\
\\
x_{\lfloor h \rfloor}+\left(h - \lfloor h \rfloor \right)
\left(x_{\left(\lfloor h\rfloor+1\right)}-x_{\left( \lfloor h\rfloor\right)} \right)\\
\text{donde }h=p\left(n+\frac{1}{3}\right)+\frac{1}{3}
&\;\;\text{si } \frac{2}{3}/\bigl(n+\frac{1}{3}\bigr)\leq p < \bigl(n-\frac{1}{3}\bigr)/\bigl(n+\frac{1}{3}\bigr),\\
\lfloor\cdot\rfloor \text{ es la función parte entera (floor})\\
\\
x_{(n)} &\;\; \text{si } p \geq \bigl(n-\frac{1}{3}\bigr)/\bigl(n+\frac{1}{3}\bigr).\\
\end{cases}}
\end{equation}
\]
La anterior expresión corresponde a una función continua, lo que permite obtener cualquier cuantil. Sin embargo, el uso más frecuente tiene que ver con la obtención de cuantiles especializados que particionan la muestra en intervalos con igual cantidad de información. Tales cuantiles tienen denominaciones particulares, acorde con el número de intervalos; así, por ejemplo, a los cuantiles que particionan la muestra en 4 porciones iguales, cada una con 25 % de la información, se les denomina cuartiles; si la particionan en 10 intervalos iguales, cada uno con 10 % de la información, se les llama deciles; si la partición es en 100 intervalos de 1 % cada uno, percentiles.
En tales casos, siempre se obtiene un cuantil menos que el número de intervalos. Así, por ejemplo, se tienen tres cuartiles: el cuartil 1, \(Q_1,\) es aquel valor tal que al menos el 25 % de los valores muestrales son menores o iguales que él; el segundo cuartil, \(Q_2,\) es un valor tal que al menos el 50 % de los datos muestrales son menores o iguales que él; mientras que el tercer cuartil, \(Q_3,\) es el valor tal que al menos el 75 % de los valores muestrales son menores o iguales que él.
Lógicamente algunos cuantiles coincidirán para diferentes particiones, recibiendo, por tanto, diferentes nombres, dependiendo de la partición a la que se haga referencia. Se tiene, por ejemplo, que la mediana es el segundo cuartil, el quinto decil y el quincuagésimo percentil. Los cuantiles correspondientes a la anterior definición se obtienen en R, usando el argumento type = 8, en la función quantile{stats}.
Considérese la siguiente muestra: \(\{35, 45, 9, 78, 55, 79, 2, 73, 46, 97, 4, 83, 28, 4, 5, 68, 34, 69, 9, 15\}.\) A continuación, se ilustra la obtención del segundo cuartil, es decir, del cuantil 0.5.
Inicialmente, se obtienen los estadísticos de orden:
| \(x_{(1)}\) | \(x_{(2)}\) | \(x_{(3)}\) | \(x_{(4)}\) | \(x_{(5)}\) | \(x_{(6)}\) | \(x_{(7)}\) | \(x_{(8)}\) | \(x_{(9)}\) | \(x_{(10)}\) | \(x_{(11)}\) | \(x_{(12)}\) | \(x_{(13)}\) | \(x_{(14)}\) | \(x_{(15)}\) | \(x_{(16)}\) | \(x_{(17)}\) | \(x_{(18)}\) | \(x_{(19)}\) | \(x_{(20)}\) |
| 2 | 4 | 4 | 5 | 9 | 9 | 15 | 28 | 34 | 35 | 45 | 46 | 55 | 68 | 69 | 73 | 78 | 79 | 83 | 97 |
Se verifican los límites que direccionan a subfunciones específicas:
\[
\begin{align}
(2/3)/(n+1/3)&=(2/3)/(20+1/3)=0.03278689\\[1.4em]
(n-1/3)/(n+1/3)&=(20-1/3)/(20+1/3)=0.96721311
\end{align}
\]
Puesto que \(0.03278689 \le 0.5 < 0.96721311,\) el cuantil 0.5 se calcula con base en la siguiente expresión:
\[
x_{\lfloor h \rfloor}+\left(h - \lfloor h \rfloor \right)
\left(x_{\left(\lfloor h\rfloor+1\right)}-x_{\left( \lfloor h\rfloor\right)} \right)
\]
El valor de \(h\) se obtiene así:
\[
h=p(n+1/3)+1/3=0.5(20+1/3)+1/3=10.5
\]
Luego, el cuantil 0.5 es:
\[
\begin{align}
\text{0.5-cuantil}=&x_{\lfloor h \rfloor}+\left(h - \lfloor h \rfloor \right)\left(x_{\left(\lfloor h\rfloor+1\right)}-x_{\left( \lfloor h\rfloor\right)} \right)\\[0.7em]
=&x_{\lfloor 10.5 \rfloor}+\left(10.5 - \lfloor 10.5 \rfloor \right)\left(x_{\left(\lfloor 10.5\rfloor+1\right)}-x_{\left( \lfloor 10.5\rfloor\right)} \right)\\[0.7em]
=& x_{(10)}+(10.5-10)(x_{(10+1)}-x_{(10)})\\[0.7em]
=&35+0.5(45-35)\\[0.7em]
=&35+5\\[0.7em]
=&40
\end{align}
\]
Utilizando el mismo procedimiento, pueden obtenerse los cuantiles que se relacionan a continuación y que se representan en la figura 2.11.
| \(d_{1}\) | \(d_{2}\) | \(Q_{1}\) | \(d_{3}\) | \(d_{4}\) | \(d_{5}=Q_{2}\) | \(d_{6}\) | \(d_{7}\) | \(Q_{3}\) | \(d_{8}\) | \(d_{9}\) |
| \(10\,\%\) | \(20\,\%\) | \(25\,\%\) | \(30\,\%\) | \(40\,\%\) | \(50\,\%\) | \(60\,\%\) | \(70\,\%\) | \(75\,\%\) | \(80\,\%\) | \(90\,\%\) |
| \(4\) | \(6.6\) | \(9\) | \(11.6\) | \(30.8\) | \(40\) | \(50.8\) | \(68.57\) | \(71.33\) | \(76\) | \(81.53\) |

Los cuartiles y, en particular, una función derivada de estos (el recorrido intercuartil) desempeñan un importante papel en el contexto descriptivo.
Algunos cuantiles son utilizados para establecer puntos de corte. Así, por ejemplo, si una reglamentación estableciera el otorgamiento de un estímulo a todos aquellos que obtuvieran el 10 % de mejores puntajes en una prueba, esto equivaldría a otorgarle el estímulo a quienes hubieran obtenido un puntaje mayor o igual que el noveno decil.
Si la reglamentación en cuestión estableciera que el estímulo es para quienes estuvieran en el rango del 5 % de los mejores puntajes, aunque podría hablarse del decimonoveno ventil, difícilmente lograríamos hacernos entender; no obstante, usando la expresión presentada anteriormente, no habría ninguna dificultad en obtener el cuantil 0.95.
Durante mucho tiempo las tablas tuvieron un doble propósito: por una parte, resumir la información muestral en un formato que permitiera destacar sus características; por otra, lograr una simplificación inicial de los datos que facilitara el posterior cálculo de los estadísticos.
La estrategia correspondiente al segundo propósito constituía un salvavidas cuando no se contaba con las herramientas computacionales de las que gozamos hoy en día. Resultaba mucho más sencillo obtener las estadísticas de 10 intervalos que las de 1000 datos. Aunque aún se encuentran textos en los que se detallan los procedimientos para obtener estadísticas a partir de datos agrupados, tales procedimientos no tienen mucho sentido en la práctica contemporánea.
En la actualidad, sin importar lo grande que pueda ser una muestra, los estadísticos se calculan directamente a partir de esta, es decir, sobre el conjunto de datos sin agrupar. Así, pues, la función actual de las tablas es netamente la señalada como primer propósito.
A las tablas usadas en el contexto descriptivo se les denomina tablas de frecuencias. Consisten en arreglos tabulares que resumen, de manera estructurada, la información de una o más variables, permitiendo visualizar su distribución.
Cuando en una misma tabla se relacionan dos o más variables, se habla de tablas de contingencia o de tabulación cruzada (cf. sección 5.4). Dependiendo del número de variables tabuladas, se les denomina tablas de una vía, de dos vías, etc. En el presente capítulo restringimos nuestra atención a las tablas de frecuencias de una vía.
Considérese una muestra conformada por 50 lecturas del número de esporas presentes en el cuerpo fructífero de un hongo del género Fusarium (tabla 2.1).
| 540 | 560 | 320 | 410 | 640 | 515 | 160 | 435 | 580 | 225 |
| 130 | 250 | 490 | 440 | 420 | 830 | 520 | 210 | 870 | 240 |
| 480 | 385 | 600 | 1130 | 705 | 800 | 760 | 5 | 800 | 160 |
| 980 | 710 | 720 | 350 | 310 | 820 | 3 | 480 | 445 | 810 |
| 780 | 810 | 850 | 850 | 340 | 310 | 1030 | 380 | 114 | 740 |
Aun en un conjunto de datos tan modesto como este, se hace evidente la dificultad para detectar patrones. Salta a la vista el mínimo y, con un poco más de esfuerzo, puede detectarse el máximo. Poco más puede extraerse de la tabla original.
La forma más básica de resumen consistiría en desplegar de manera ordenada cada uno de los datos de la muestra, indicando el número de veces que se repite. Esto se consigue en R, mediante la función table{base}.
En la gran mayoría de los casos resulta más conveniente agrupar los datos por intervalos, siendo esta la alternativa más utilizada para resumir variables numéricas.
Aunque existen muchas variantes en lo que a tablas de frecuencia se refiere, estas siempre deben estar constituidas por una serie de intervalos contiguos, exhaustivos y mutuamente excluyentes, de manera que cada uno de los datos muestrales quede incluido en uno y solo uno de los intervalos.
Aunque no es obligatorio, sí es muy recomendable que los intervalos tengan la misma amplitud, con la eventual salvedad de los intervalos extremos que en ocasiones se dejan abiertos. Teniendo en cuenta estas restricciones, la tabla de frecuencias puede definirse ya sea por la amplitud de los intervalos o por el número de estos.
Sturges (sturges?) fue el primero en proponer una regla para establecer el número de intervalos en los que debía particionarse una muestra. Esta regla se sintetiza en la siguiente expresión, donde \(n\) es el tamaño de la muestra:
\[
k = 1+\log_2n=1+3.322\,\log_{10}n
\]
Aunque se han desarrollado muchas propuestas alternativas, la regla de Sturges sigue siendo la usada por defecto en muchos programas estadísticos, incluyendo R.
Si se tiene en cuenta que el propósito principal de las tablas de frecuencia es descriptivo, bien puede tomarse la regla de Sturges o cualquier otra como guía.
Es común realizar adaptaciones para que los límites de los intervalos coincidan con valores que tengan algún significado particular o simplemente con valores más fáciles de asimilar a simple vista. En R, a tales puntos de corte se les denomina pretty breakpoints y se obtienen haciéndolos coincidir con valores que sean 1, 2 o 5 veces potencias de 10.
En general, mientras más intervalos se utilicen menos información se pierde, pero el resumen es más pobre, con lo cual la tabla puede resultar menos informativa.
Para la presente muestra, constituida por 50 datos, la regla de Sturges da por resultado 6.64, es decir que bien podrían considerarse en primera instancia tablas de frecuencias con 7 o 6 intervalos, o con algún otro número cercano a estos.
Teniendo en cuenta que el recorrido de la presente muestra es 1127 (1130 − 3), si se eligieran 7 intervalos, el ancho de estos sería 161, mientras que eligiendo 6, el ancho de los mismos sería 187.8.
Tomando en consideración lo expresado anteriormente, en cuanto construir intervalos que sean más asimilables a simple vista (pretty breakpoints), una buena alternativa de resumen puede ser trabajar con base en 6 intervalos de amplitud 200, tal y como se muestra en la tabla 2.2, la cual se obtiene mediante las siguientes instrucciones en R6:
esporas <- c(540, 560, ..., 114, 740)
DescTools::Freq(esporas)| Intervalo | simple | acumulada | simple | acumulada |
|---|---|---|---|---|
| [0, 200] | 6 | 6 | 12.0% | 12.0% |
| (200, 400] | 11 | 17 | 22.0% | 34.0% |
| (400, 600] | 14 | 31 | 28.0% | 62.0% |
| (600, 800] | 9 | 40 | 18.0% | 80.0% |
| (800, 1000] | 8 | 48 | 16.0% | 96.0% |
| (1000, 1200] | 2 | 50 | 4.0% | 100.0% |
Al número de observaciones en cada intervalo se le denomina frecuencia absoluta; a la expresión porcentual de dicha frecuencia en relación con el tamaño de la muestra se le denomina frecuencia relativa. Tales frecuencias pueden presentarse de manera simple o acumulada.
También es posible generar tablas de frecuencia para variables categóricas. No obstante, en tales casos no se construyen intervalos, sino que se trabaja directamente con cada una de las categorías, presentando su correspondiente frecuencia.
En tales casos, puesto que no existe un orden entre las categorías, las frecuencias acumuladas no tendrían sentido.
Para construir en R una tabla de frecuencias para una variable categórica, se usa la función table{base}.
En contraste con los estadísticos, cuya función es describir con gran precisión algún aspecto puntual de la muestra, los gráficos brindan un panorama amplio de los datos, destacando simultáneamente varias de sus características.
Así, por ejemplo, a través de un solo gráfico podría tenerse idea sobre la tendencia central, dispersión y forma de la muestra. Su elaboración y análisis deberían ser una práctica rutinaria previa a cualquier otro análisis.
Los gráficos constituyen una herramienta central del análisis exploratorio de datos, concepto desarrollado por Tukey, quien, en una época en la que los gráficos se construían manualmente por lo incipiente de los recursos computacionales, afirmaba que no existía excusa para dejar de graficar y mirar (Tukey, 1977).
Aunque los programas estadísticos y de graficación, aunados a un poco de estética, permiten crear verdaderas obras de arte en cuanto a colores, texturas y efectos, es importante tener presente que tales variantes no deben reñir con la legibilidad e interpretación, sino que, por el contrario, deben contribuir a estas.
A continuación se describen, en sus versiones básicas, algunos de los gráficos más usados en el contexto descriptivo.
Para su elaboración, se representa cada dato como un punto referenciado en uno o más ejes coordenados, requiriéndose un eje por cada variable considerada. Aunque en términos genéricos se habla de puntos, puede usarse cualquier símbolo.
El gráfico de dispersión más sencillo es el correspondiente a una sola variable. Aunque es poco común como herramienta estándar de la estadística descriptiva, puede resultar práctico para ilustrar aspectos particulares, tales como los que se exhiben en las figuras 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.10 y 2.11.
Los gráficos de dispersión más comunes son los usados para representar dos variables; tanto así que, aunque puede precisarse que tales gráficos son bivariados o bidimensionales, suele obviarse dicha apelación, haciéndose referencia a los mismos simplemente como gráficos de dispersión. La figura 2.12 ilustra varios de estos gráficos, los cuales pueden obtenerse en R, usando la función plot{graphics}.
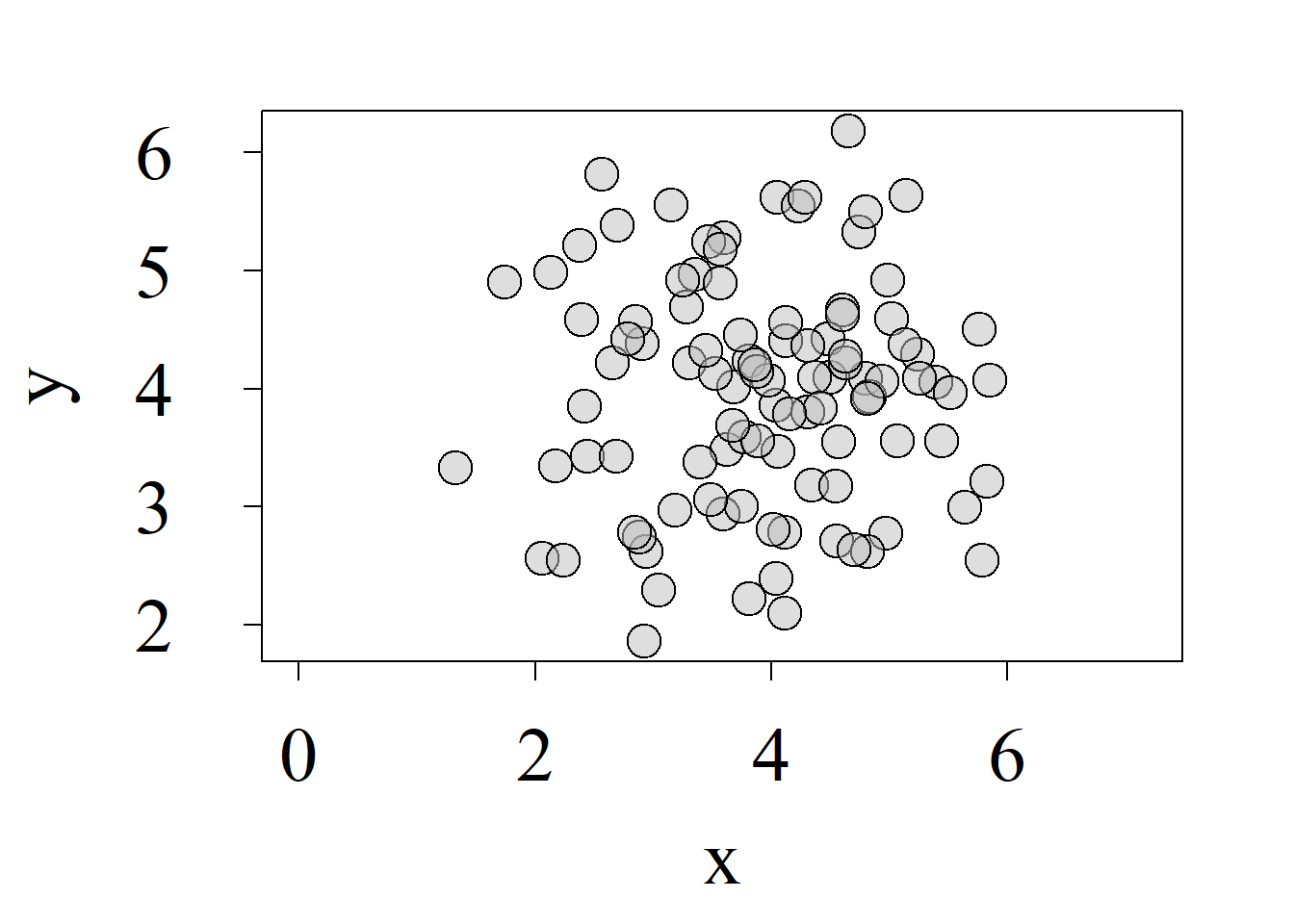
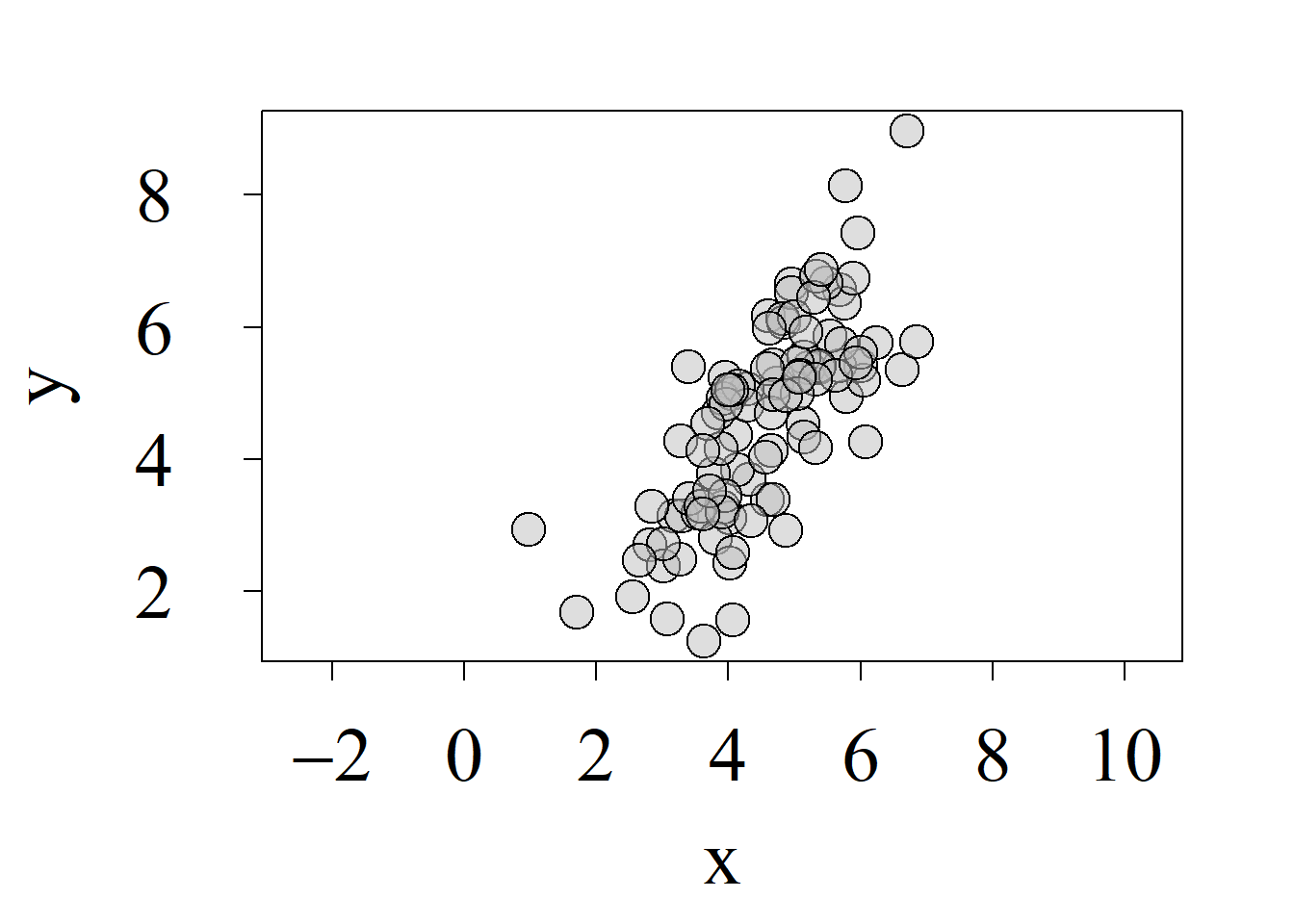
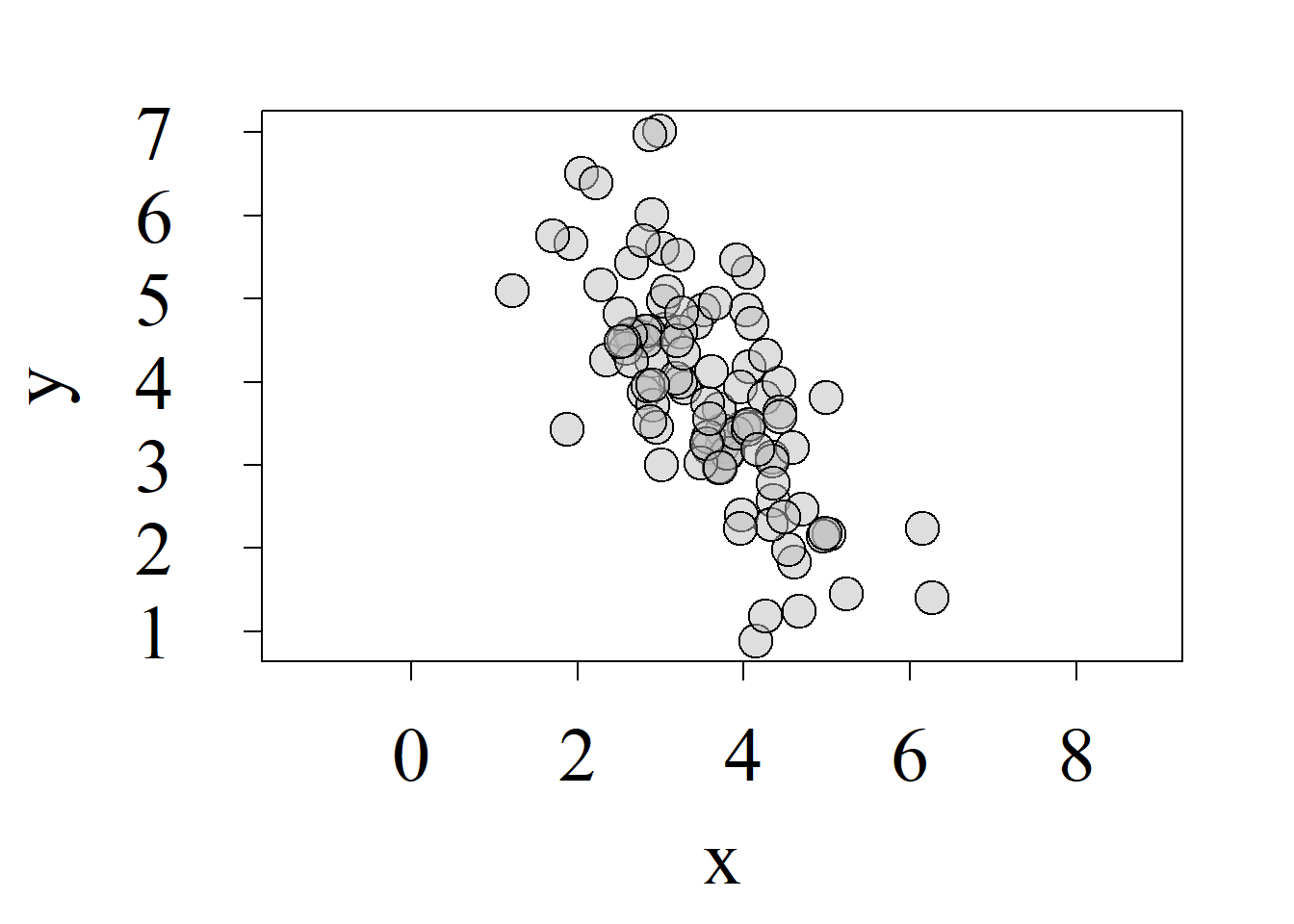
Los gráficos de dispersión constituyen una herramienta gráfica de gran valor para estudiar los patrones de variación conjunta o covariación entre variables numéricas. Así, por ejemplo, la figura 2.12 (a) no sugiere ningún patrón de covariación entre las variables graficadas. La figura 2.12 (b) sugiere un patrón de relación directa, es decir que los valores bajos de una variable suelen asociarse más frecuentemente con valores bajos de la otra variable y viceversa. La figura 2.12 (c) sugiere un patrón de relación inversa, donde los valores bajos de una variable se asocian más frecuentemente con valores altos de la otra variable y viceversa.
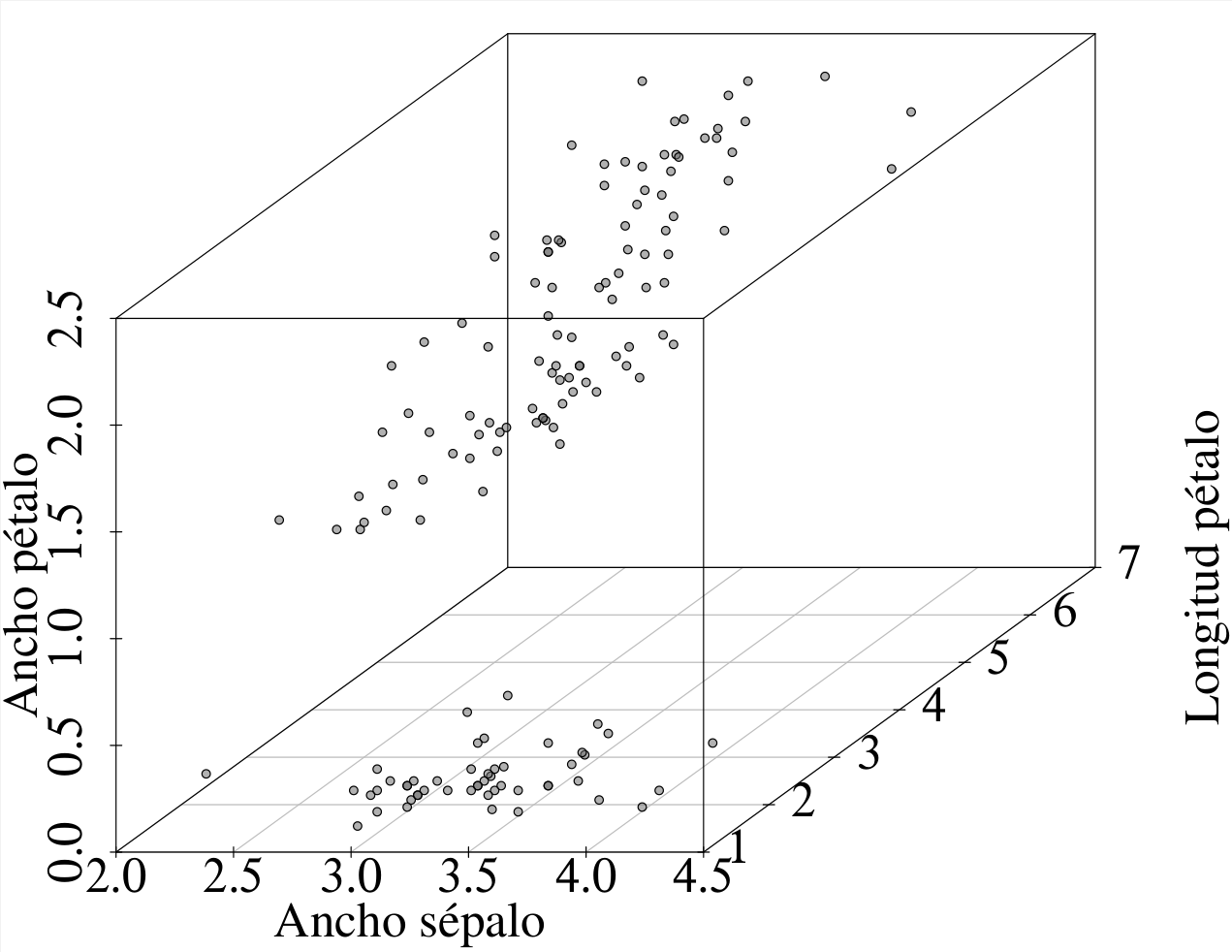
El gráfico de dispersión de tres variables requiere tres ejes ortogonales en un espacio tridimensional. No obstante, con la ayuda de programas estadísticos es posible elaborar en dos dimensiones una representación que tenga el aspecto de un gráfico tridimensional.
Algunas funciones para R, como scatterplot3d{scatterplot3d}, plot3d{rgl} y plot_ly{plotly}, permiten construir gráficos interactivos, particularmente útiles en la exploración visual de los datos, y que además pueden incrustarse en documentos compatibles con esta característica, como los html.
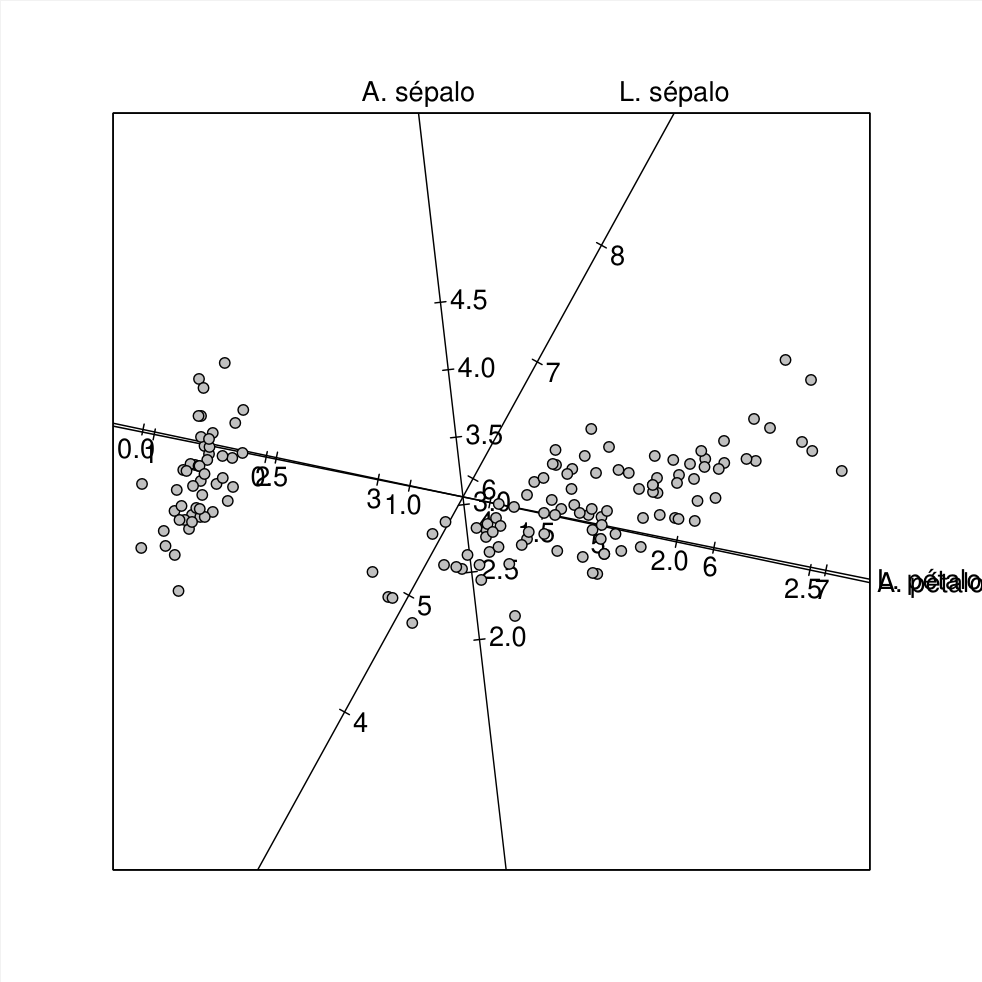
La representación completa de \(n\) variables exigiría \(n\) ejes y, por consiguiente, un espacio de dimensión \(n.\) Gabriel (1971) fue el primero en proponer una representación gráfica bidimensional que resumiera las características del espacio \(n\) dimensional; a dicha representación la denominó biplot, donde el prefijo bi se refiere a la representación simultánea de los datos y los ejes de las variables (en el trabajo original se hace referencia a las filas y las columnas de una matriz). Dicha propuesta ha dado lugar a numerosas extensiones, muchas de las cuales han sido desarrolladas por el grupo de investigación del Departamento de Estadística de la Universidad de Salamanca.
El trabajo de Gower, Lubbe y Le Roux (2011) constituye un excelente compendio sobre este tema, el cual ha trascendido por mucho el concepto de mera generalización de los gráficos de dispersión. En R, es posible generar representaciones biplot, mediante la función Biplots{BiplotGUI}.
La figura 2.13 consta de dos representaciones gráficas generadas a partir de la base de datos iris{datasets}, la cual se usa extensamente en R para fines de ilustración y está constituida por las medidas en centímetros de varios órganos de flores del género Iris (Fisher, 1936). A la izquierda se presenta un gráfico de dispersión “tridimensional”7 para tres variables numéricas (figura 2.13 (a)); a la derecha se presenta un biplot para las cuatro variables numéricas de la base de datos (figura 2.13 (b)).
La figura 2.14 presenta una versión interactiva del mismo conjunto de datos graficado de manera estática en la figura 2.13 (a).
En una primera instancia, la interactividad puede parecer una característica muy deseable. Y, en efecto, bien manejada puede aportar dinamismo a una presentación. No obstante, si se tiene en cuenta que la mayoría de soportes de las publicaciones científicas son de tipo estático, puede resultar preferible optar por una representación fija, cuidadosamente orientada para favorecer su interpretación.
¿Con cuál representación se queda?
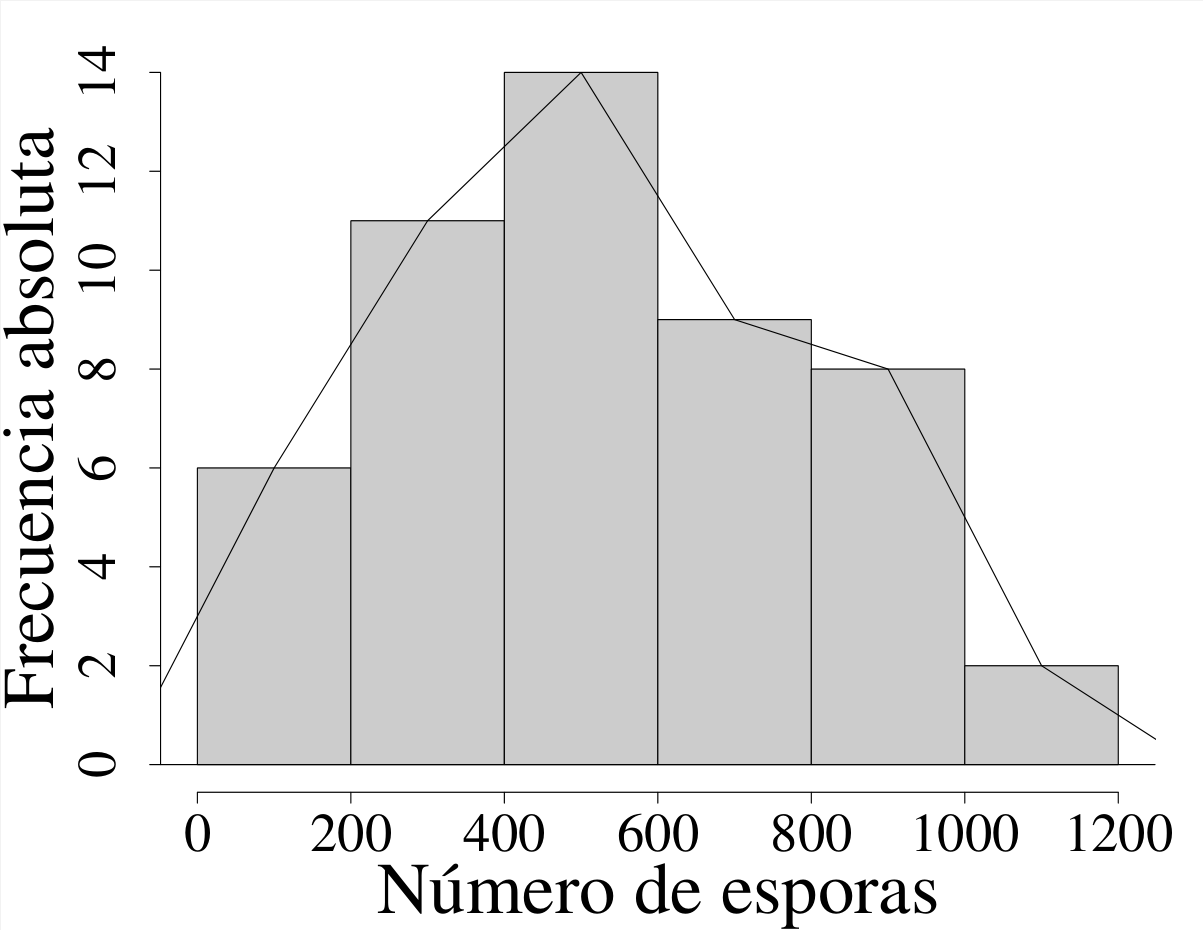
Es la contraparte gráfica de las tablas de frecuencias para variables numéricas. El histograma cuenta con dos ejes coordenados: la abscisa, que corresponde a la variable de interés, y la ordenada, que representa las frecuencias, ya sean absolutas o relativas. En la figura 2.15 se muestra el histograma de frecuencias absolutas correspondiente a los datos de la tabla 2.1. Este gráfico puede generarse en R mediante la función hist{graphics}.

En general, en un histograma la frecuencia de cada intervalo se representa mediante el área de su barra. En el caso —más común— de histogramas con intervalos de igual amplitud, la altura de la barra también refleja dicha frecuencia.
Dado que existe una relación de proporcionalidad entre las frecuencias absolutas y relativas, el uso de unas u otras no altera el aspecto del histograma; únicamente cambian los valores representados en el eje vertical.
Los histogramas constituyen una herramienta descriptiva integral, ya que proporcionan información sobre el recorrido de la muestra, su centro o centros, su dispersión, su asimetría y su curtosis.
Es una representación muestral estrechamente asociada con los histogramas de frecuencias; de hecho, en muchas ocasiones aparecen superpuestas en una misma gráfica, tal como se ilustra en la figura 2.16 (a).
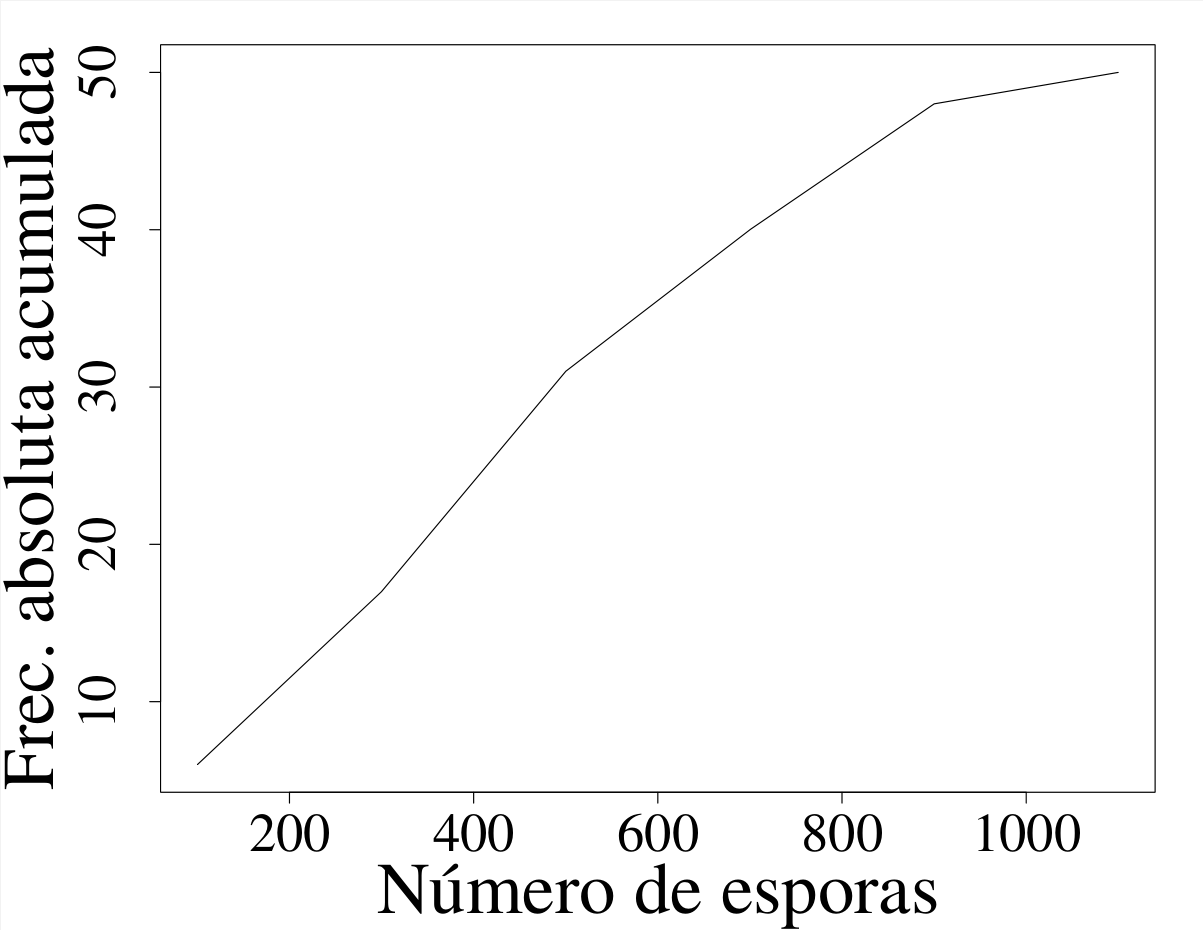
Los polígonos pueden ser de frecuencias simples (absolutas o relativas), como el representado en la figura 2.16 (b), o de frecuencias acumuladas, como el que aparece en la figura 2.16 (c).
Las figuras 2.16 (a) y 2.16 (b) pueden generarse con la función polygon.freq{agricolae}. Para la figura 2.16 (c), se usa la función plot{graphics}, junto con cumsum{base}, para acumular las frecuencias generadas por la función hist{graphics}.
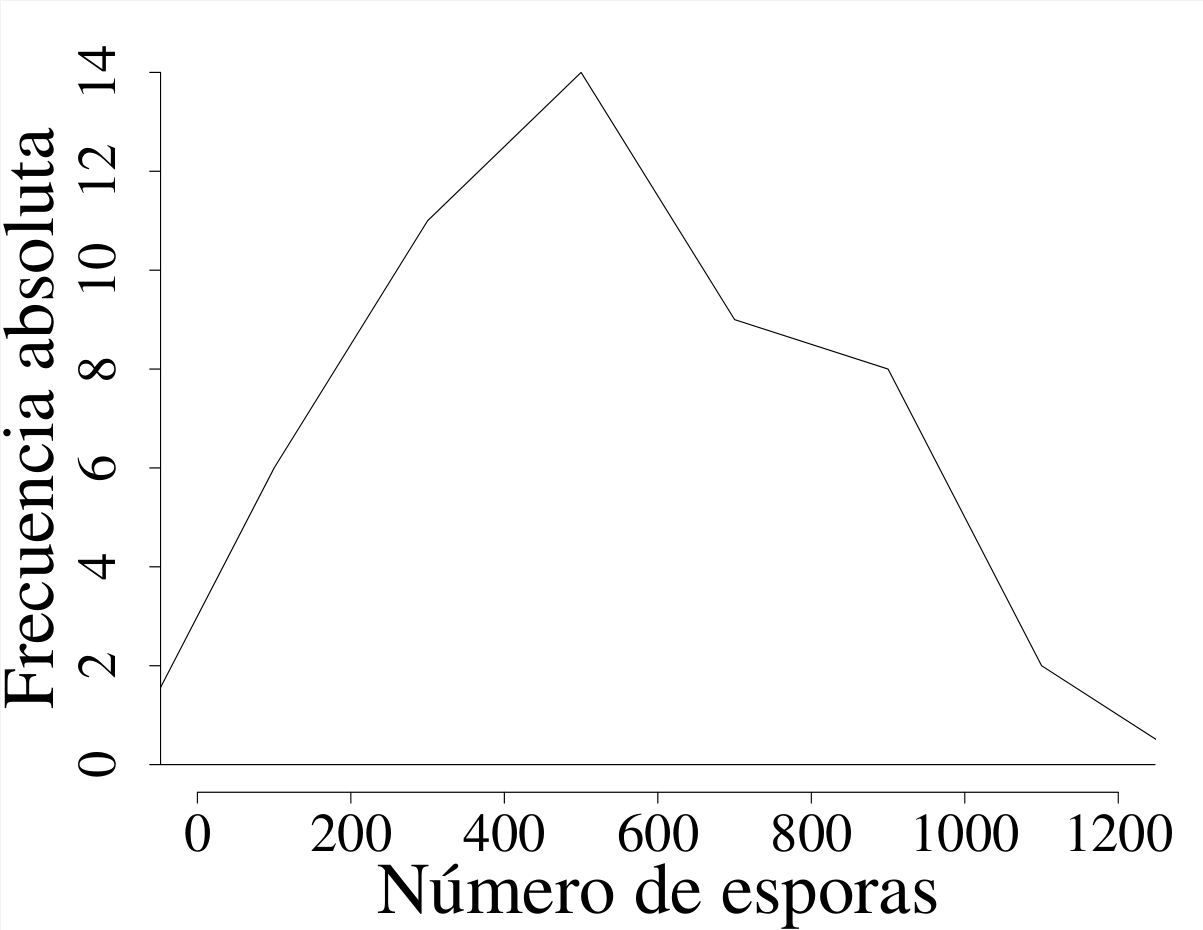
Las coordenadas de los puntos de intersección de las líneas del polígono corresponden a la marca de clase o punto medio del intervalo para la abscisa, mientras que para la ordenada se usa la correspondiente frecuencia.
Cuando el tamaño de muestra es grande y se elige un número elevado de intervalos, el polígono tiende a adquirir un aspecto suavizado, cercano al de una curva.
Los polígonos de frecuencias acumuladas se interpretan exactamente de la misma manera en que se interpretan las frecuencias acumuladas en una tabla de frecuencias: la frecuencia (ya sea absoluta o relativa) que se acumula hasta cierto valor. Así, por ejemplo, para la muestra contenida en la tabla 2.1 y resumida en la tabla 2.2, puede decirse que 40 datos de esporulación (o un 80 %) son menores o iguales que 800.
Se usa para representar gráficamente la tabla de frecuencias de una variable cualitativa. Para cada categoría se usa una barra del mismo ancho, cuya altura representa su frecuencia. Considérese la siguiente información correspondiente a los usos del suelo en una región.
| Uso | Frecuencia relativa |
|---|---|
| Pastoreo | 12 % |
| Forestal | 45 % |
| Agrícola | 18 % |
| Urbano | 22 % |
| Otro | 3 % |
Mediante la función barplot{graphics} se obtiene una representación como la de la figura 2.17.

Aunque la representación de la figura 2.17 guarda cierta similitud con el histograma de frecuencias, ambas son definitivamente diferentes.
En el gráfico de barras se tiene un único eje coordenado, el cual representa las frecuencias, no existiendo un eje coordenado en la abscisa. Aunque los gráficos de barras generados por muchos programas exhiben una línea horizontal en la base, la cual incluso presenta marcas, no se trata de un eje coordenado; es un mero marco o soporte para las barras.
En los gráficos de barras, las categorías no tienen un orden intrínseco que deba respetarse, por lo cual el orden en que estas se presentan es relativamente arbitrario.
Por consiguiente, no tiene sentido buscar patrones de distribución, tales como dispersión, simetría o curtosis. El único estadístico que tiene sentido es la moda (la barra más alta). De igual manera, tampoco tiene sentido calcular frecuencias acumuladas o construir polígonos de frecuencias.
Cuando se indicó que los gráficos de barras se usaban para representar las frecuencias de variables cualitativas, esto incluía también a las variables medidas en escala ordinal (cf. nota 1.1). En estos casos, aunque el orden de los niveles no sea arbitrario, debe evitarse la tentación de interpretar la diferencia entre categorías como una distancia o magnitud.
Existen muchas variantes de los gráficos de barras. Las barras pueden presentarse vertical u horizontalmente. Las etiquetas pueden ponerse en la base de la barra o pueden incluirse en una leyenda; en tal caso, las barras deben diferenciarse por color y/o patrón textural. También pueden conformarse grupos para cada uno de los cuales se represente alguna medida resumen de una característica de interés (la media, por ejemplo), tal y como se muestra en la figura 2.18, donde se presentan los valores medios en centímetros de las medidas de varios órganos florales de tres especies del género Iris (Fisher, 1936).

Al igual que el gráfico de barras, se utiliza para representar las frecuencias de una variable nominal. En este tipo de gráficos el círculo representa la totalidad de la muestra. A cada categoría se le asigna un sector, cuya área es proporcional a su frecuencia. También se le conoce como diagrama de sectores o —de manera más informal— gráfico de torta, en correspondencia con su aspecto y con su nombre en inglés (pie chart). La figura 2.19, elaborada en R con la función pie3D{plotrix} representa las frecuencias relativas de los datos de uso del suelo con base en los cuales se construyó el gráfico de barras de la figura 2.17.
Aunque la información presentada por los gráficos de barras y circular es equivalente, es importante notar que el gráfico de barras facilita la visualización de pequeñas diferencias, mientras que el gráfico circular las enmascara.
Las frecuencias de las categorías Agrícola y Urbano aparecen muy similares en el gráfico circular, no siendo fácil distinguir si son diferentes o no; mientras que en el gráfico de barras (figura 2.17), la diferencia salta a la vista.

Aprovechamos este gráfico circular para analizar lo expresado al inicio de la sección 2.3, en cuanto a que las variantes estéticas que se incorporen en los gráficos deben aportarles, sin reñir con su legibilidad e interpretación.
Habría que evaluar qué se gana con la tridimensionalidad del presente gráfico —cuya función es netamente estética— y si esta pudiera generar confusión en el público hacia el cual va dirigido.
¿Cómo se vería un gráfico bidimensional? Lógicamente, más plano en todos los sentidos. La tridimensionalidad del presente gráfico resulta sin duda más impactante de lo que resultaría la bidimensionalidad de su contraparte clásica. Esto, como bien saben los sicólogos y los especialistas en mercadotecnia, no es un asunto menor.
Teniendo en cuenta el medio en el que publicará, ¿este tipo de gráfico le resta seriedad a la presentación o, por el contrario, le imprime un carácter juvenil y dinámico?
¿Pudiera suceder que los receptores del gráfico se sintieran confundidos, tratando de buscarle una interpretación —que no existe— al espesor de los sectores?
¿El tono oscuro elegido para la categoría Otro es adecuado o deja la impresión de que se hubiera eliminado ese sector?…
Estas y otras cuestiones similares son las que deben evaluarse en cada caso para elegir las mejores opciones gráficas.
Esta herramienta gráfica, propuesta por Tukey (1977), resulta útil para destacar simultáneamente varios aspectos esenciales de la distribución de una o más variables numéricas.
Consta de una caja (box) que se extiende desde el cuartil inferior, \((Q_1),\) hasta el cuartil superior, \((Q_3),\) cubriendo, por tanto, la mitad central de la muestra. La línea que atraviesa la caja en sentido transversal representa la mediana, \((Q_2).\) En ocasiones también se señala la posición de la media con algún otro símbolo, aunque esta no forma parte de la definición original del diagrama. De la caja emergen hacia ambos lados unos segmentos lineales que asemejan bigotes (whiskers).
En ausencia de observaciones muy alejadas de la caja, los bigotes se extienden hasta el mínimo y máximo muestral.
Tukey (1977) define los valores extremos como aquellos que exceden en 1.5 veces el recorrido intercuartil, \((Q_3 − Q_1),\) por encima o por debajo de los extremos de la caja. Asimismo, define los valores muy extremos como aquellos ubicados más allá de 3 veces el recorrido intercuartil con respecto a los límites de la caja.
Aunque podrían sustentarse otros criterios para definir lo que se considera extremo, preferimos respetar la propuesta original de Tukey (1977), que constituye una convención ampliamente difundida.
Debe tenerse presente, sin embargo, que el diagrama de caja y bigotes es una herramienta exploratoria. En tal sentido, sin importar cuál sea la definición usada para los valores extremos o muy extremos, esta no debe usarse como criterio de que haya algo erróneo con tales puntos.
En presencia de valores extremos o muy extremos, estos no determinan la longitud de los bigotes, sino que se representan individualmente más allá de ellos.
En la figura 2.20 se presenta un diagrama de caja y bigotes para los datos de la tabla 2.1. Se mantuvieron los valores por defecto de la función boxplot{graphics}.

En este caso, los cuartiles son \(Q_1= 325,\) \(Q_2=502.5\) y \(Q_3=775.\) Estos valores definen la caja. El recorrido intercuartil, que para esta muestra es \(Q_3-Q_1=450,\) se usa para definir los valores extremos o muy extremos.
En la implementación del diagrama de caja y bigotes en R, mediante la función boxplot{graphics}, la definición de los bigotes se controla a través del argumento range. Por defecto, range = 1.5, lo que reproduce la convención propuesta por Tukey para la identificación de valores extremos, extendiendo los bigotes hasta el dato más alejado que no exceda 1.5 veces el recorrido intercuartil con respecto a los límites de la caja. Los valores que quedan fuera de ese intervalo se representan individualmente.
La función boxplot{graphics} no distingue, sin embargo, entre valores extremos y valores muy extremos; todos los puntos que exceden el umbral definido por range se grafican de manera uniforme. La identificación explícita de valores muy extremos, con símbolos diferentes a los usados para identificar los valores extremos, requeriría, por tanto, un tratamiento adicional por parte del usuario.
Para el presente ejemplo, los valores extremos, acorde con la convención de Tukey (1977), implementada en boxplot{graphics}, serían aquellos que se alejaran de los bordes de la caja más de 1.5 veces el recorrido intercuartil, esto es, \(1.5\times 450=675.\) Luego, los valores extremos inferiores serían aquellos menores de \(325 − 675 = −350,\) mientras que los superiores serían los mayores de \(775 + 675 = 1450.\)
Puesto que el mínimo y el máximo muestral son 3 y 1130, respectivamente, esta muestra no contiene valores extremos, por lo que los límites de los bigotes coinciden con los valores mínimo y máximo.
El lector atento podrá haber notado que los cuartiles reportados no coinciden con los generados por la función quantile, con el argumento type = 8, en consonancia con lo recomendado para su obtención (cf. sección 2.1.4). En contraste, la función boxplot utiliza la definición clásica que aparece en la formulación de Tukey (1977), la cual se obtiene en R, mediante la función quantile con su valor por defecto (type = 7).
Esta aparente discrepancia no debe interpretarse como una inconsistencia metodológica. El uso de cuantiles tipo 8 responde a una recomendación general para la estimación numérica de posiciones muestrales, mientras que el diagrama de caja y bigotes conserva, por razones históricas y de estandarización gráfica, la definición original propuesta por Tukey. En la práctica, esta diferencia rara vez tiene un impacto apreciable sobre la interpretación visual del diagrama.
Por esta razón, no se recomienda modificar el criterio de cálculo de los cuartiles al construir diagramas de caja y bigotes.
Estos diagramas permiten inspeccionar de manera rápida la simetría de un conjunto de datos. En muestras asimétricamente distribuidas, el bigote más largo señala hacia la cola de la distribución, mientras que las representaciones de muestras simétricas exhiben bigotes más o menos de la misma longitud.
En la figura 2.20 se nota que el bigote derecho es ligeramente más largo que el izquierdo, lo que es reflejo de una muestra con ligera asimetría a la derecha (cf. figura 2.15).
La figura 2.21, conformada por dos conjuntos de datos contrastantes, permite ampliar este concepto. En la parte superior, se muestran sus histogramas de frecuencias; en la parte inferior, se representan los mismos conjuntos de datos mediante diagramas de caja y bigotes.
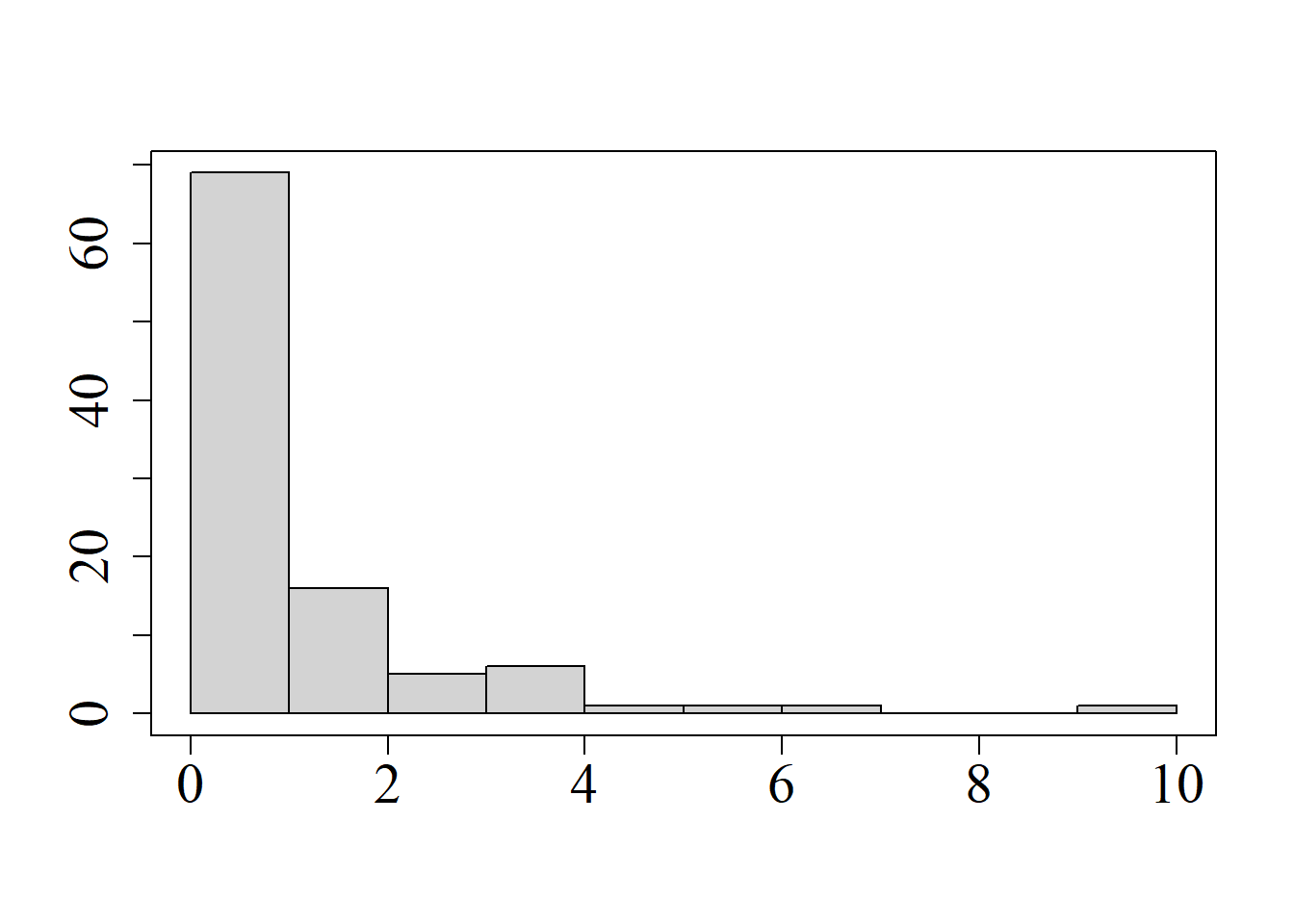
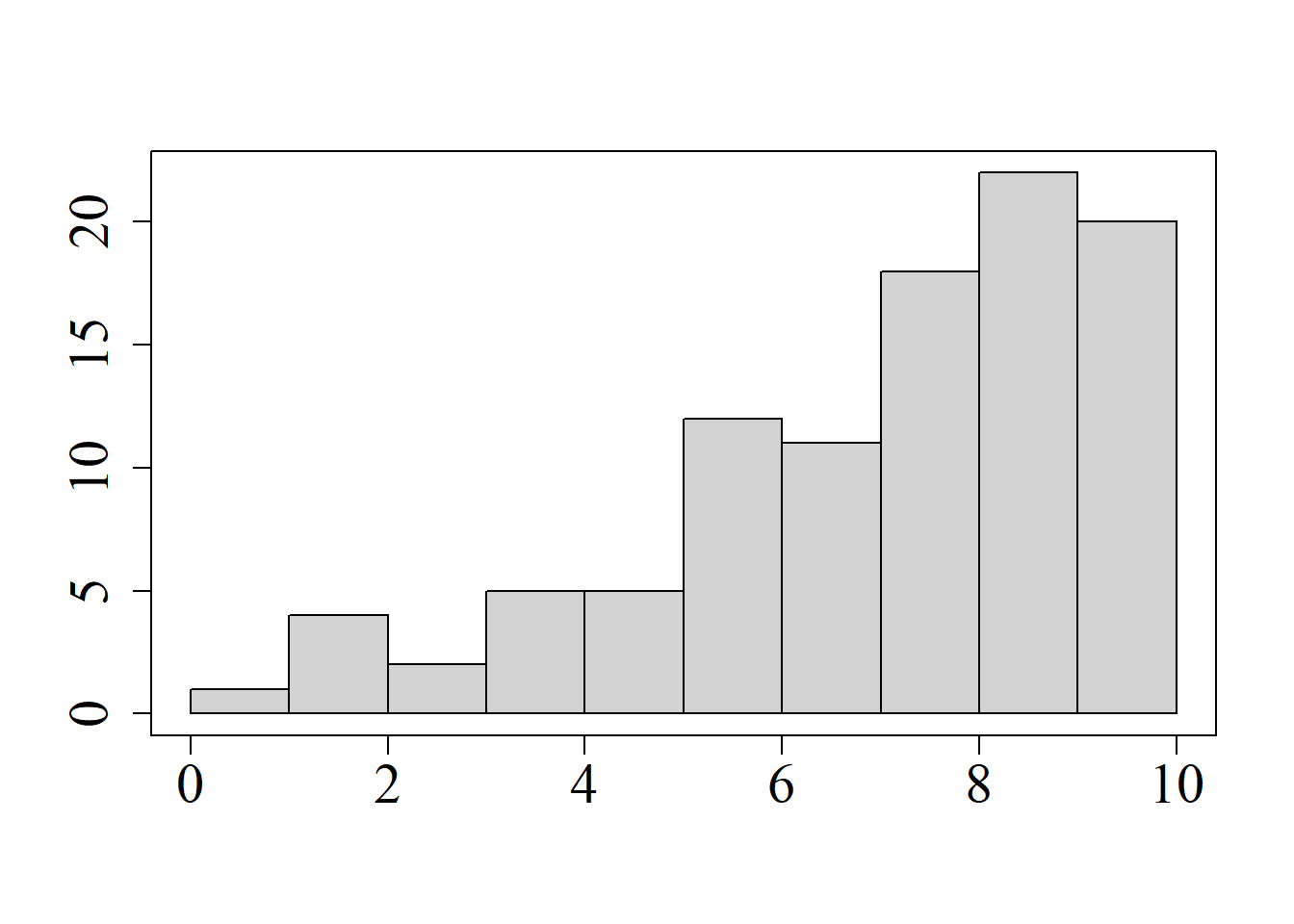
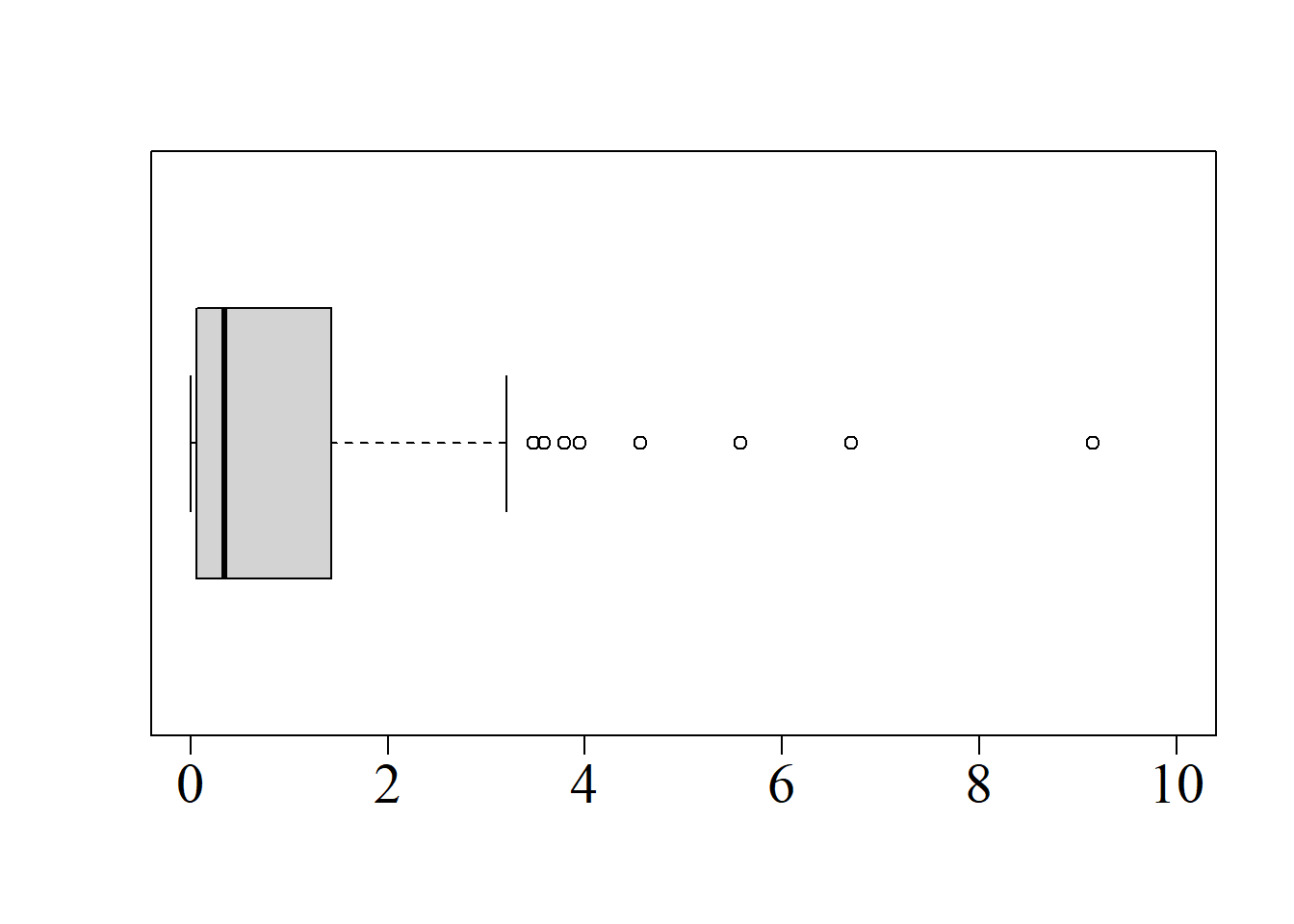
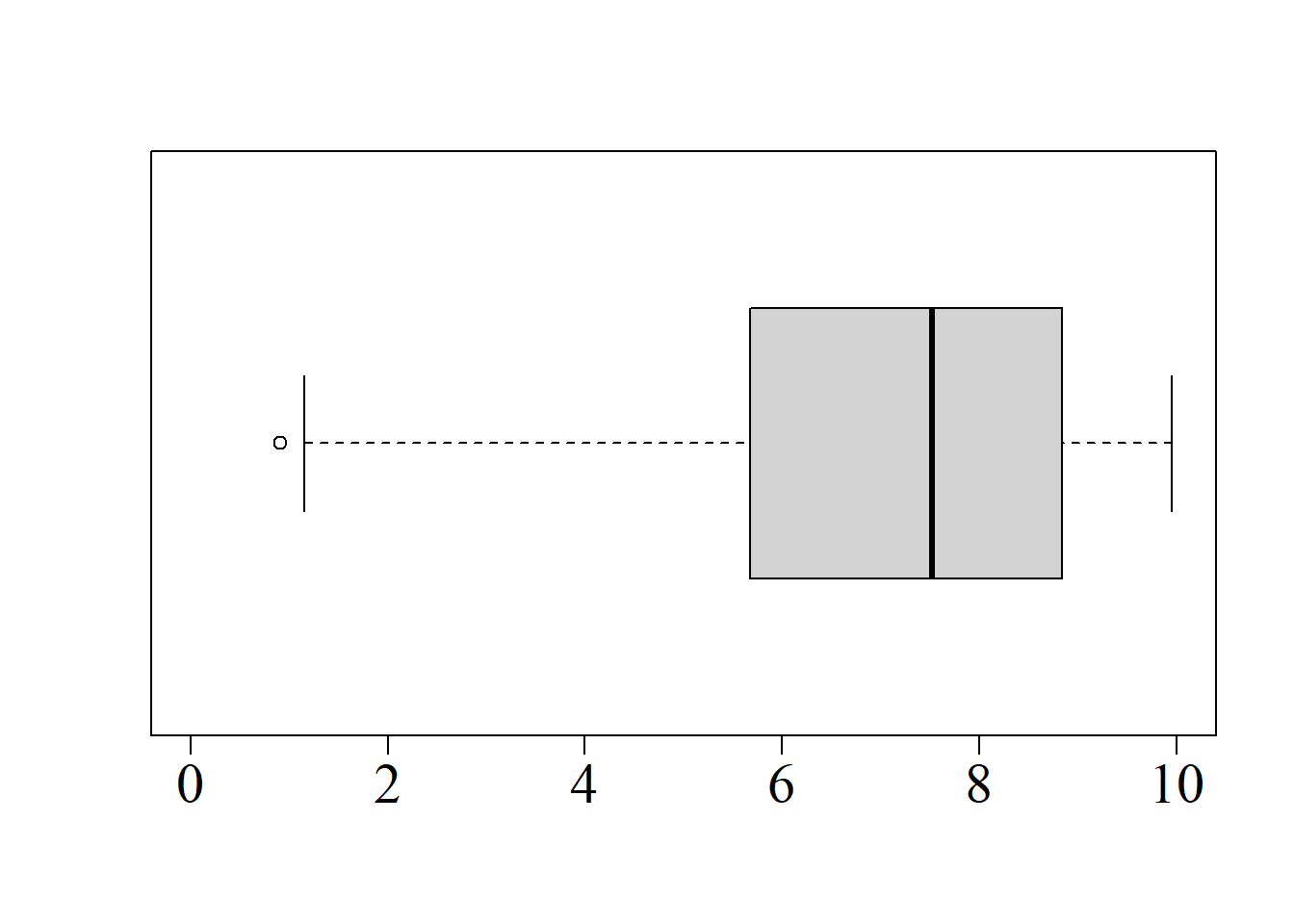
Rousseeuw, Ruts y Tukey (1999) proponen el gráfico de bolsa (bagplot) como una generalización del gráfico de caja y bigotes para la representación conjunta de dos variables numéricas.
Aunque no se trata de un gráfico ampliamente popularizado, se presenta justamente para resaltar cómo las herramientas estadísticas pueden mutar y adaptarse a nuevas exigencias —o a la disponibilidad de recursos—, dando incluso lugar a desarrollos metodológicos adicionales.
En este caso, partiendo del concepto de profundidad de localización o profundidad de Tukey (halfspace depth) (Tukey, 1975), se ubica el punto de mayor profundidad en el gráfico de dispersión, el cual es equivalente a la mediana y se representa con un asterisco. A continuación, como equivalente de la caja, se define una bolsa (bag) que contiene la mitad de las observaciones con mayor profundidad en el gráfico de dispersión. Magnificando la bolsa por un factor de 3 se obtiene la cerca (fence), que sería equivalente, por analogía, a los bigotes. Los autores proponen graficar la región entre la bolsa y la cerca en otro tono. Los valores por fuera de la cerca se marcan como valores extremos.
La figura 2.22 ilustra un gráfico de bolsa para los datos de la figura 2.12 (b), construido mediante la función bagplot{aplpack}.
Registered S3 method overwritten by 'aplpack':
method from
plot.bagplot DescTools
Este, que es el término más común en la actualidad, es el que se usa en este libro. En el pasado también fueron comunes términos como “estadísticas” o “estadígrafos”.↩︎
En este texto, las funciones de R se referencian acompañadas del nombre del paquete al que pertenecen, encerrado entre llaves. Así, mean{base} se lee como la función mean del paquete base.↩︎
Es indiferente si se escribe \(5\times3.0\) o \(3.0\times5.\)↩︎
\(\text{velocidad}=\frac{\text{distancia}}{\text{tiempo}}\)↩︎
La media armónica es la que aparece en la solución de Kramer para resolver el problema de diferente número de réplicas en la prueba de Tukey (cf. sección 8.5).↩︎
Las salidas numéricas son las generadas por R; lo único que se ha editado es el formato de la tabla.↩︎
Proyectado en dos dimensiones↩︎