primo <- function(x) {
if (!is.numeric(x))
stop("La función solamente admite valores numéricos")
if (x != floor(x))
stop("La función solamente admite números enteros")
if(x < 2 || x > 100)
stop("La función solo está implementada para valores entre 2 y 100")
residuos <- x%%(2:(x-1))
residuos0 <- residuos == 0
if (x == 2)
cat("2 es un número primo")
else if (sum(residuos0) == 0)
cat(x, "es un número primo")
else
cat(x, "no es un número primo")
}21 FUNCIONES DEFINIDAS POR EL USUARIO
En adición a las funciones que R trae incorporadas en los paquetes que se cargan al inicio o en cualquier otro paquete que se cargue en una sesión específica, el usuario puede crear sus propias funciones para realizar de manera ágil y personalizada labores que ejecute consuetudinariamente.
Tales funciones se denominan funciones definidas por el usuario (user-defined functions) o funciones personalizadas.
¡Créela!
Las funciones definidas por el usuario marcan una gran diferencia entre R y otras aplicaciones para análisis estadístico.
Al ser R un lenguaje de programación, sus posibilidades son prácticamente ilimitadas, no siendo necesario que R “tenga” una función destinada a realizar una tarea particular, puesto que el usuario puede crearla, acorde con sus requerimientos y necesidades.
21.1 Funciones personalizadas y funciones oficiales
A continuación se detallan algunas diferencias entre las funciones personalizadas y las funciones oficiales que se descargan desde la CRAN o desde algún otro sitio.
El usuario no tiene que preocuparse por la escritura de las funciones oficiales. De esta parte ya se ha encargado algún otro usuario de R; muchos de ellos con gran experiencia. Las funciones personalizadas sí exigen un proceso de creación o escritura.
Las funciones oficiales siempre están dentro de algún paquete (cf. capítulo 4). Las funciones personalizadas, aunque también podrían empaquetarse, usualmente se manejan en archivos de scripts de R.
Para tener acceso a una función oficial hay que empezar por descargar el paquete que la contiene (cf. sección 4.1). Por su parte, las funciones personalizadas suelen distribuirse en archivos de scripts de R, con extensión .R.
El uso de cualquier función —sea oficial o personalizada— exige que esté disponible en memoria durante una sesión de trabajo particular. Con excepción de las funciones que forman parte de los paquetes básicos de R —que siempre están disponibles en memoria—, cualquier otra función oficial exige la carga del correspondiente paquete (cf. capítulo 4.2). Esto puede hacerse con alguna de las funciones require o library. Asimismo, puede realizarse una carga temporal (cf. tip 4.1). Las funciones personalizadas se cargan en memoria mediante la función source. En este caso no se carga un paquete sino una función.
Una vez la función esté disponible en memoria, sea porque se haya cargado su paquete contenedor o porque se haya cargado la función con source, el llamado o invocación de cualquiera de estas funciones es exactamente igual.
La tabla 21.1 resume los aspectos diferenciadores de estas dos categorías de funciones.
| Función | Escritura | Empaquetamiento | Distribución | Uso |
|---|---|---|---|---|
| Oficial | Ya ha sido escrita por un tercero | Sí | Se descarga el paquete contenedor | Nombre_función(argumentos) |
| Personalizada | La realiza el usuario | Usualmente no | Archivo de scripts de R | Nombre_función(argumentos) |
21.2 Creación y uso de funciones personalizadas
El ciclo de las funciones personalizadas consta de tres pasos:
Creación
Guardado
Uso
La creación siempre es el paso inicial de cualquier función personalizada. El guardado es optativo. El uso no es obligatorio, pero sí es lo que le otorga sentido práctico a los pasos anteriores.
21.2.1 Creación de funciones personalizadas
La sintaxis general para crear una función personalizada es:
nombre_función <- function (arg1, arg2, argk, ...) {
instrucciones
}La palabra reservada function permite definir funciones personalizadas. El nombre de la función puede ser cualquier identificador sintácticamente válido. Sin embargo, se desaconseja el uso de nombres de funciones ya existentes en R (como mean, sd, sum, etc.), puesto que las funciones personalizadas estarían enmascarando las funciones ya definidas en R.
Al llamar la función, mediante nombre_función y los argumentos necesarios, se ejecuta el contenido del bloque de instrucciones que se hayan especificado entre las llaves.
Para ilustrar lo anterior, consideremos una función que evalúa cualquier número entre 2 y 100, para determinar si es primo.
¿Primo?
Recuérdese que un número primo es un número natural mayor que 1, que solo es divisible por 1 y por sí mismo.
La línea 1 define la función primo, con argumento x.
El cuerpo de la función está comprendido por todas las instrucciones entre llaves, es decir, las que aparecen entre las líneas 2 y 15.
Los condicionales if que aparecen en las líneas 2, 4 y 6 verifican que el argumento sea numérico, entero y que esté entre 2 y 100, respectivamente. En caso de no satisfacerse alguna de estas condiciones, la función se detiene, imprimiendo un mensaje de error.
Las instrucciones de las líneas 8 y 9 habrían podido escribirse de manera condensada en una sola línea. Sin embargo, las desglosamos para analizar los procedimientos internos.
La línea 8 evalúa el residuo de dividir el valor del argumento x entre cada uno de los elementos de un vector de números enteros que va de 2 a x-1 (cf. sección 20.8). Así, si se estuviera evaluando, por ejemplo, x=7, se calcularía el residuo de 7/2, 7/3, 7/4, 7/5 y 7/6; el vector residuos constaría de los elementos 1, 1, 3, 2, 1.
La instrucción de la línea 9 evalúa cuáles de los elementos de residuos son 0, es decir, cuáles dieron lugar a una división exacta sin residuo. El resultado es un vector de valores lógicos, que se almacena en residuos0. Para el caso con x=7, el vector residuos0 constaría de los elementos F, F, F, F, F.
La estructura if...else if...else (líneas 10 a 15) evalúa diferentes posibilidades, para determinar si el argumento es un número primo o si no lo es.
La línea 10 evalúa si el valor del argumento x es 2. De ser así, aparece el aviso especificado mediante la instrucción de la línea 11.
En caso de que x no sea igual a 2 (y haya pasado todos los filtros iniciales), se evalúa si todas las divisiones realizadas mediante la instrucción de la línea 8 dejaron algún residuo, en cuyo caso, el vector residuos0 estaría conformado únicamente por valores FALSE. Y, aprovechando la relación entre las etiquetas lógicos TRUE/FALSE con los valores 0/1 (cf. sección 10.5), basta con averiguar si la suma de las etiquetas lógicas es 0, en cuyo caso, todas las divisiones evaluadas habrían dejado algún residuo, pudiendo clasificarse, por tanto, el número evaluado como primo.
En caso contrario, es decir, si sum(residuos0) no fuera 0 significaría que el vector residuos0 contenía al menos un valor lógico TRUE, lo que significaría que, al menos una de las divisiones evaluadas no dejó residuo. En consecuencia, el número no se considera primo.
Una vez creada y depurada la función, hay dos maneras de cargarla en memoria.
Ejecutando todas las instrucciones que la definen: líneas 1 a 16.
Guardándola en un archivo con extensión
.Ry usando la funciónsource.
Cualquiera que sea el método utilizado, es posible verificar si la función fue cargada correctamente, revisando el Global Environment (usualmente en la ventana superior derecha de RStudio). Si la función se ha cargado con éxito, su nombre aparecerá en el apartado Functions.
21.2.2 Guardado de funciones personalizadas
Aunque las funciones suelen surgir como solución a problemas puntuales, con frecuencia resultan útiles en contextos distintos al que motivó su creación. En tal sentido, lo más recomendable suele ser guardarlas, para facilitar su reutilización posterior.
No obstante, también habrá casos en los que una función solo tenga sentido dentro de un script específico. En tales situaciones, puede dejarse directamente en el cuerpo del script, sin necesidad de crear un archivo adicional.
¿¡Y qué nombre se le pone al archivo!?
Aunque el archivo contenedor de la función puede tener cualquier nombre admisible por el sistema operativo (no está limitado a los nombres sintácticamente válidos en R), se recomienda usar el mismo nombre que se haya usado para la función.
Aunque R no tendría ningún problema en procesar una función llamada primo que esté contenida en un archivo llamado, por ejemplo, números primos.R, esto podría generar confusión en el usuario y aumentar el riesgo de errores.
¡Se recomienda usar el mismo nombre para la función y para su archivo contenedor!
21.2.3 Uso de funciones personalizadas
Suponiendo que función primo se hubiera guardado en un archivo llamado primo.R, se procedería a cargarla en memoria así:
source("primo.R")La anterior instrucción lee el contenido del archivo de scripts primo.R y ejecuta la totalidad de su contenido, dejando disponible en memoria la función primo.
¡Que esté en la ruta!
Para que la carga de una función mediante source se realice adecuadamente, es necesario que el archivo contenedor de la función esté en el directorio de trabajo (cf. capítulo 3).
El llamado de una función personalizada se realiza de la misma manera en la que se invocan las funciones oficiales, es decir, usando su nombre y sus argumentos.
Así, por ejemplo, para evaluar si 53 es número primo, se usaría la siguiente instrucción, tras haber cargado la función en memoria:
primo(53)53 es un número primo
Nota 21.1: En resumen…
A continuación se resumen los pasos de la creación, guardado y uso de la función primo:
Escriba la función en el editor de scripts.
Guárdela en un archivo con extensión
.R, idealmente con el mismo nombre de la función (primo.R)Ubique el archivo
primo.Ren el directorio de trabajo y cárguelo en memoria consource("primo.R")Evalue la función sobre cualquier número entre 2 y 100, llamándola por su nombre, por ejemplo:
primo(53).
Esperamos que próximamente usted escriba sus propias funciones personalizadas. De momento lo invitamos a seguir el proceso para la función primo. El paso 1 puede resolverlo copiando el código 21.1 y pegándolo en el editor de scripts.
O, si lo desea, también puede partir del punto 3, descargando el archivo primo.R:
¡Funciones de una línea!
Aunque las funciones pueden alcanzar niveles de complejidad inimaginados, también pueden ser tan simples que pueden presentarse en una sola línea. En tales casos, es posible escribirlas en la misma línea en la que se define la función, sin usar llaves.
Considérese la siguiente función, que calcula la media de un vector omitiendo los valores faltantes.
mean.narm <- function(x) mean(x, na.rm = T)Para ilustrar su uso, calculemos la media de un vector con información faltante:
mean.narm(c(3, NA, 4, NA, 5, NA, NA))[1] 4¡Contrástese este resultado con el que obtiene al usar la función mean —con los valores por defecto de sus argumentos— sobre este mismo vector!
21.3 Personalización adicional de las funciones
¡Las funciones no son funciones!
Por analogía con las funciones matemáticas, en las que cada valor del dominio está asociado con uno y solo uno de los valores del rango, podría creerse que las funciones de R generan un único valor. Y, aunque el ejemplo de la función primo (cf. código 21.1) pareciera reafirmar esta percepción, no es así.
Una función en R puede generar múltiples resultados, tanto en número como en naturaleza, incluyendo resultados cuantitativos, cadenas de texto, vectores, matrices, data frames, listas, tablas, gráficos, etc.
En otras palabras, una función puede generar cualquier objeto o conjunto de objetos de R.
Considérese una función que tome como argumento un vector numérico, le calcule una serie de estadísticos básicos, los cuales reporte con cuatro cifras decimales y con su correspondiente leyenda en español, además de generar un gráfico de caja y bigotes.
statistics <- function (x) {
cat("Media =", round(mean(x), 4), "\n")
cat("Desviación estándar =", round(sd(x), 4), "\n")
q <- quantile(x)
cat("Mínimo =", round(q[1], 4), "\n")
cat("Cuartil 1 (25 %) =", round(q[2], 4), "\n")
cat("Mediana (50 %) =", round(q[3], 4), "\n")
cat("Cuartil 3 (75 %) =", round(q[4], 4), "\n")
cat("Máximo =", round(q[5], 4), "\n")
if (!require(agricolae))
install.packages("agricolae", dependencies = T)
library(agricolae) # Para el cálculo de la asimetría y la curtosis
s <- skewness(x)
k <- kurtosis(x)
cat("Coef. asimetría =", round(s, 4), "\n")
cat("Coef. curtosis =", round(k, 4), "\n")
boxplot(x)
}A continuación se ilustra el uso de función statistics sobre un vector de 100 observaciones seudoaleatorias de la distribución normal estándar usando 47 como semilla, con el fin de que los resultados sean reproducibles.
Tras cargar la función en memoria (cf. sección 21.2.3), se invoca así:
set.seed(47)
statistics(rnorm(100))Media = 0.0515
Desviación estándar = 0.9826
Mínimo = -2.3224
Cuartil 1 (25 %) = -0.6958
Mediana (50 %) = 0.039
Cuartil 3 (75 %) = 0.8857
Máximo = 2.1879 Coef. asimetría = -0.138
Coef. curtosis = -0.4123 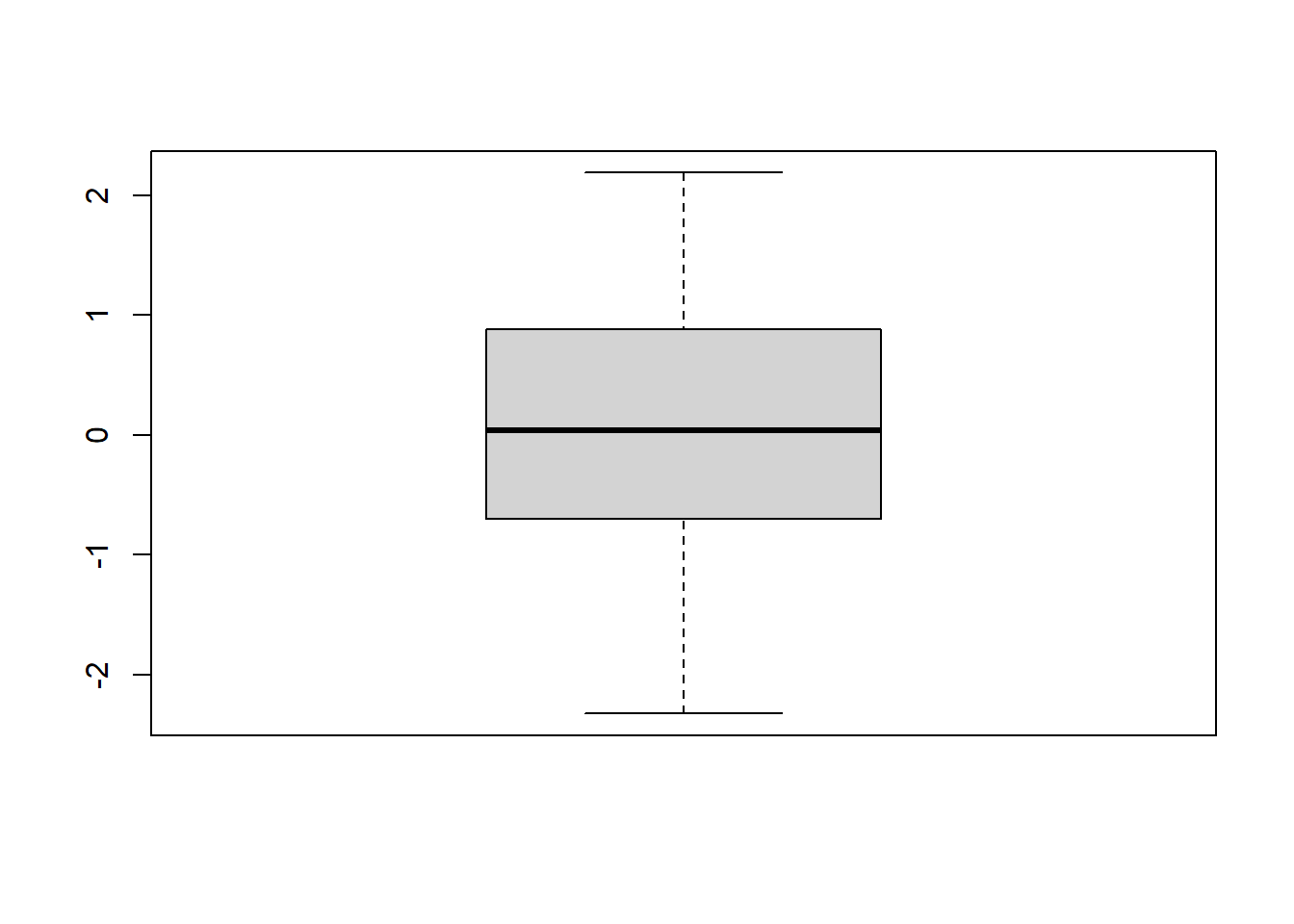
21.3.1 Guardado de salidas en listas
En adición o en remplazo de los resultados por consola, las salidas pueden almacenarse en un objeto para uso posterior. Debe tenerse presente, sin embargo, que aunque una función en R puede generar múltiples resultados durante su ejecución —como imprimir valores por consola o enviar gráficos a un dispositivo gráfico—, esta multiplicidad no se traduce automáticamente en la posibilidad de almacenar cada salida por separado.
Si se desea conservar los resultados en un objeto para su uso posterior, es necesario reunirlos explícitamente en una única estructura. Cuando los elementos son del mismo tipo, pueden almacenarse en un objeto atómico. No obstante, cuando las salidas están conformadas por elementos de diferente naturaleza, se hace necesario el uso de una estructura recursiva (cf. nota 8.1).
Las listas son los objetos por excelencia para este fin, pues, al tratarse de los objetos recursivos más generales, permiten empaquetar elementos de distinta naturaleza, facilitando así el retorno organizado de los resultados de una función.
Para ilustrar este aspecto, consideremos nuevamente la función statistics (cf. código 21.2), introduciendo las adaptaciones necesarias para guardar todos los resultados en una lista. Para distinguir esta nueva función de la original, la llamaremos statistics2:
statistics2 <- function (x) {
cat("Media =", round(mean(x), 4), "\n")
cat("Desviación estándar =", round(sd(x), 4), "\n")
q <- quantile(x)
cat("Mínimo =", round(q[1], 4), "\n")
cat("Cuartil 1 (25 %) =", round(q[2], 4), "\n")
cat("Mediana (50 %) =", round(q[3], 4), "\n")
cat("Cuartil 3 (75 %) =", round(q[4], 4), "\n")
cat("Máximo =", round(q[5], 4), "\n")
if (!require(agricolae))
install.packages("agricolae", dependencies = T)
library(agricolae) # Para el cálculo de la asimetría y la curtosis
s <- skewness(x)
k <- kurtosis(x)
cat("Coef. asimetría =", round(s, 4), "\n")
cat("Coef. curtosis =", round(k, 4), "\n")
boxplot(x)
bp <- recordPlot()
invisible(list(media = mean(x),
de = sd(x),
mín = q[1],
q1 = q[2],
mediana = q[3],
q3 = q[4],
máx = q[5],
asimetría = s,
curtosis = k,
boxwhiskers = bp))
}Hasta la línea 17, la función statistics2 coincide con la función statistics. Las instrucciones que se agregan entre las líneas 18 y 28 permiten almacenar todos los resultados en una lista.
En la línea 18 se usa la función recordPlot{grDevices} para guardar el gráfico generado mediante la instrucción de la línea 17 en un objeto susceptible de incluirse en una lista. El objeto en cuestión (bp en el presente ejemplo) es de la clase recordedplot y puede ser almacenado en una lista.
La instrucción que aparece entre las líneas 19 a 28 estructura una lista1, en la cual se guardan todos los resultados. Estos podrían asignarse a un objeto al momento de llamar la función.
Mediante la función list se genera la lista que ha de alojar los resultados generados por la función statistics2. Este proceso no es automático. Es necesario definir explícitamente la lista y cada uno de sus elementos (cf. sección 8.5). Y, aunque no es necesario nombrar sus elementos, sí es muy aconsejable hacerlo, teniendo en cuenta que estas listas estás destinadas a facilitar el acceso posterior a la información generada por la función.
¿Los elementos de la lista tienen que coincidir con los resultados desplegados en consola?
Aunque es muy deseable que haya coincidencia entre lo que se muestra en consola y lo que se guarda en la lista, la coincidencia no tiene que ser total.
Nótese, por ejemplo, que en la lista que alojaría los resultados de la ejecución de statistics2, los valores de los estadísticos no se redondean, mientras que en consola aparecen con cuatro cifras decimales.
Aunque la decisión de los resultados que deben enviarse a consola y los que se guardan en la lista depende del estilo de quien escribe la función, podrían tenerse en cuenta las siguientes recomendaciones.
Presente resultados legibles en consola. Use
catpara encadenar texto con resultados numéricos, de manera que las salidas sean completamente legibles.Al presentar resultados numéricos en consola, considere el uso de
roundpara mejorar la legibilidad.Considere incluir tablas para resumir contenidos en consola.
En procesos complejos no es necesario presentar absolutamente todas las salidas en consola. En tales casos puede ser preferible exhibir un buen resumen, guardando la información anexa en la lista de resultados, desde donde podría recuperarse en caso de ser requerida.
La función invisible{base} evita que el contenido de la lista se despliegue en consola si se ejecuta la función sin asignar su resultado a un objeto. Así, si la función statistics2 se ejecuta sin realizar ninguna asignación al momento de la ejecución, desplegará exactamente los mismos resultados que la función statistics. No obstante, en adición a lo que se presenta en consola y en el dispositivo gráfico, la función statistics2 permite guardar los resultados en una lista.
A continuación se ilustra la ejecución de la función statistics2 sobre el mismo vector de valores seudoaleatorios que se usó para ejemplificar la función statistics, asignando los resultados al objeto estadísticos:
set.seed(47)
estadísticos <- statistics2(rnorm(100))Media = 0.0515
Desviación estándar = 0.9826
Mínimo = -2.3224
Cuartil 1 (25 %) = -0.6958
Mediana (50 %) = 0.039
Cuartil 3 (75 %) = 0.8857
Máximo = 2.1879
Coef. asimetría = -0.138
Coef. curtosis = -0.4123 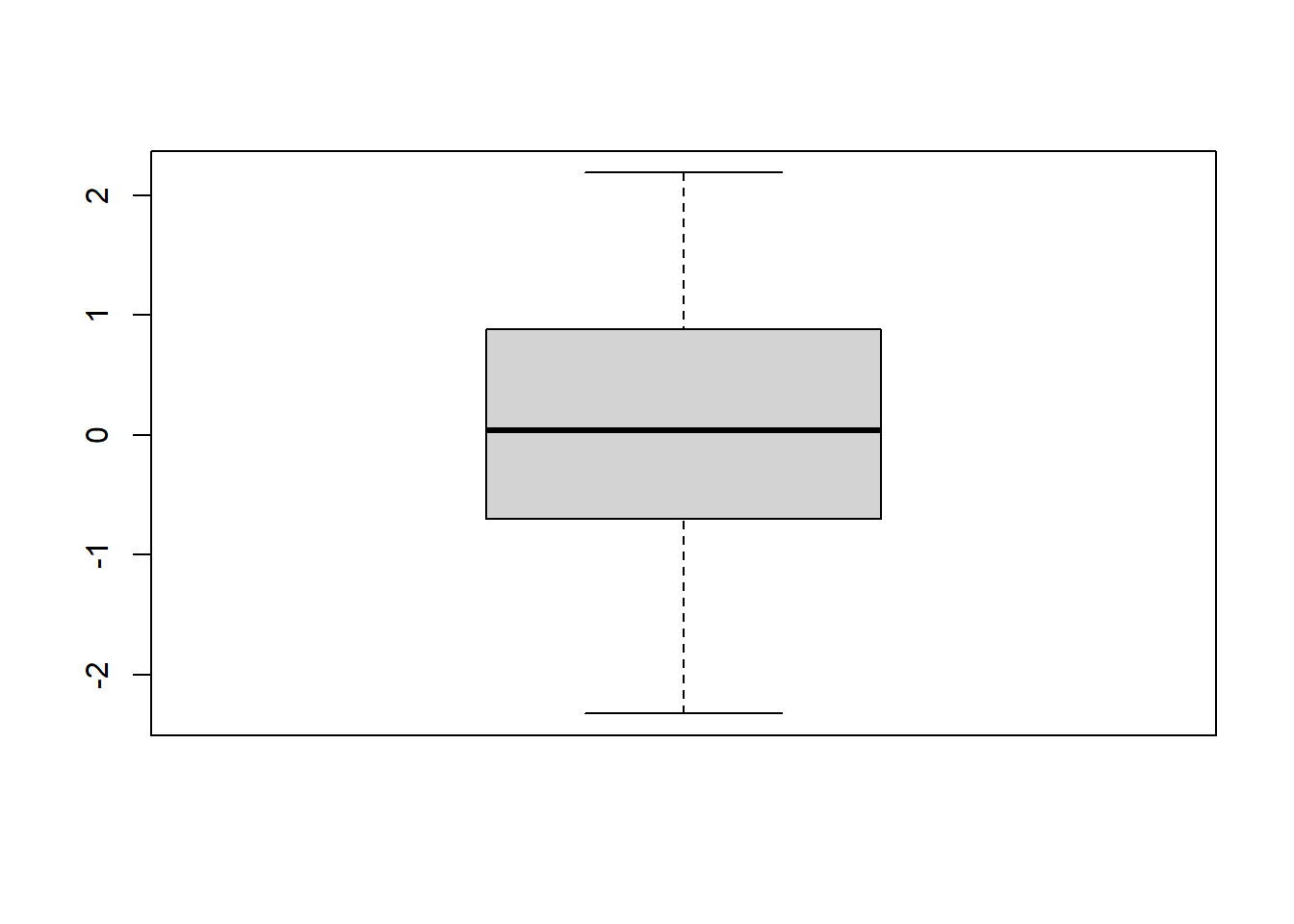
Se observa que los resultados desplegados en consola son exactamente iguales a los obtenidos al ejecutar la función statistics. No obstante, en adición a lo mostrado en consola se ha creado la lista estadísticos, la cual contiene todos los resultados.
Para recuperar por consola el contenido de la lista estadísticos se usa la siguiente instrucción:
print(estadísticos)
$media
[1] 0.05148905
$de
[1] 0.9826215
$mín
0%
-2.322372
$q1
25%
-0.6957751
$mediana
50%
0.03899234
$q3
75%
0.8856567
$máx
100%
2.187918
$asimetría
[1] -0.1380486
$curtosis
[1] -0.4122769
$boxwhiskers21.3.2 Retorno de resultados
Tal y como se ha ilustrado en las secciones anteriores, una función puede generar múltiples resultados. Estos pueden ir enviándose a consola a medida que se generan o pueden organizarse y enviarse a consola al final de la función. La manera en que se realice este procedimiento depende de la necesidad de unificar información al final —en una tabla, por ejemplo— y de consideraciones de legibilidad.
En contraste, cuando se desea guardar los resultados en un objeto, es necesario condensarlos en una única instrucción.
Cuando se realiza una asignación como la ilustrada en el código 21.3, la información que se asigna al objeto corresponde a la generada en la última instrucción de la función. En este ejemplo, corresponde a la lista que se define mediante la siguiente instrucción:
invisible(list(media = mean(x),
de = sd(x),
mín = q[1],
q1 = q[2],
q2 = q[3],
q3 = q[4],
máx = q[5],
asimetría = s,
curtosis = k,
boxwhiskers = bp))Este tipo de retorno se denomina automático o implícito. El usuario solo debe preocuparse por posicionar al final de la función lo que desee retornar en el objeto de resultados.
También es posible definir un retorno explícito, mediante la función return: cualquier contenido que se use como argumento de la función return es usado si se realiza una asignación al invocar la función, sin importar la posición que ocupe la instrucción con el retorno explícito.
¿Implícito o explícito?
No hay una respuesta única para esta pregunta, máxime si se tiene en cuenta que la literatura especializada puede ofrecer recomendaciones contrarias.
La guía Google de estilo R, por ejemplo, recomienda el uso de return explícito siempre, para hacer más claro lo que devuelve la función. En contraste, el equipo tidyverse (The tidyverse team, s. f.) favorece el retorno implícito, para evitar ruido visual innecesario.
Dejando de lado los aspectos estilísticos, es necesario señalar una diferencia esencial entre los dos tipos de retornos. Esta diferencia sí pueden balancear la decisión en uno u otro sentido: cuando se usa retorno explícito, mediante return, la instrucción de retorno se convierte en la última instrucción ejecutada. Ninguna de las instrucciones que pudieran aparecer después de esta sería evaluada.
Este comportamiento puede ser útil si se usa de manera consciente, por ejemplo, dentro de un condicional que de lugar a un resultado particular, que haga innecesario, inconveniente o hasta erróneo evaluar el resto de instrucciones.
Deben evitarse, sin embargo, los retornos tempranos si se requiere que las instrucciones posteriores sean evaluadas.
Cuando la instrucción cuyos resultados se desean retornar es la última instrucción de la función, el uso de return tiene exactamente el mismo efecto que el retorno automático, quedando a criterio del autor de la función usar una u otra estrategia.
Para ilustrar lo concerniente a las dos modalidades de retorno, considérese el siguiente código:
raíz <- function (x) {
if (x < 0) {
return(complex(real = sqrt(-x), imaginary = 1))
}
sqrt(x)
}Obsérvese el resultado de la función raíz cuando se invoca usando un real negativo como argumento.
raíz(-2)[1] 1.414214+1iEn este caso, no alcanza a evaluarse la instrucción sqrt(x), puesto que la función finaliza una vez se retorna el resultado de evaluar complex(real = sqrt(-x), imaginary = 1).
21.4 El arte de la programación
La escritura de funciones definidas por el usuario es un arte que va de la mano con la programación. El texto de Santana y Mateos (2014) constituye una muy buena referencia en español sobre este tema, manteniéndose en un nivel relativamente básico.
Si se desea profundizar, puede consultar textos más especializados como The R Inferno de Burns (2011), quien —mediante un sentido del humor muy particular— establece un paralelo con la Divina Comedia de Dante (¡a quien le agradece por sus útiles comentarios!), elabora un mapa para moverse en el ‘infierno’ que R puede representar para muchos usuarios.
También es recomendable consultar la definición del lenguaje R, la cual es escrita y actualizada por el equipo nuclear de R (2022).
Un excelente recurso para captar la lógica y el estilo de las funciones consiste en revisar funciones existentes en R. Para ver el contenido de una función, en muchas ocasiones basta con escribir el nombre de dicha función y presionar Enter.
De esta manera puede obtenerse, por ejemplo, el código de la función factor:
factorfunction (x = character(), levels, labels = levels, exclude = NA,
ordered = is.ordered(x), nmax = NA)
{
if (is.null(x))
x <- character()
nx <- names(x)
matchAsChar <- is.object(x) || !(is.character(x) || is.integer(x) ||
is.logical(x))
if (missing(levels)) {
y <- unique(x, nmax = nmax)
ind <- order(y)
if (matchAsChar)
y <- as.character(y)
levels <- unique(y[ind])
}
force(ordered)
if (matchAsChar)
x <- as.character(x)
levels <- levels[is.na(match(levels, exclude))]
f <- match(x, levels)
if (!is.null(nx))
names(f) <- nx
if (missing(labels)) {
levels(f) <- as.character(levels)
}
else {
nlab <- length(labels)
if (nlab == length(levels)) {
nlevs <- unique(xlevs <- as.character(labels))
at <- attributes(f)
at$levels <- nlevs
f <- match(xlevs, nlevs)[f]
attributes(f) <- at
}
else if (nlab == 1L)
levels(f) <- paste0(labels, seq_along(levels))
else stop(gettextf("invalid 'labels'; length %d should be 1 or %d",
nlab, length(levels)), domain = NA)
}
class(f) <- c(if (ordered) "ordered", "factor")
f
}
<bytecode: 0x00000233bdd88120>
<environment: namespace:base>En otros casos resulta un tanto más complejo obtener el código de una función determinada.
Considérese la función t.test:
t.testfunction (x, ...)
UseMethod("t.test")
<bytecode: 0x00000233bdea3850>
<environment: namespace:stats>Este resultado indica que la función t.test es genérica y que usa métodos o subfunciones diferenciadas, dependiendo la clase del primer argumento. Para buscar los métodos disponibles, debe usarse la función methods:
methods(t.test)[1] t.test.default* t.test.formula*
see '?methods' for accessing help and source codeEn muchos casos, como el presente, hay un método por defecto (default), cuyo código es el que se quiere visualizar. Para ello se usa la siguiente instrucción:
getAnywhere(t.test.default) En otros casos, no existe un método por defecto, al que pueda accederse agregando el sufijo default al nombre de la función.
Considérese la función TukeyHSD:
TukeyHSDfunction (x, which, ordered = FALSE, conf.level = 0.95, ...)
UseMethod("TukeyHSD")
<bytecode: 0x00000233bdebd188>
<environment: namespace:stats>Al igual que para el caso de la función t.test, el resultado indica que la función TukeyHSD deriva a métodos particulares, los cuales se obtienen mediante la función methods:
methods(TukeyHSD)[1] TukeyHSD.aov*
see '?methods' for accessing help and source codeUna vez ubicado el método de interés (solo hay uno en este caso: TukeyHSD.aov), se obtiene su código mediante la función getAnywhere:
getAnywhere(TukeyHSD.aov)
¿¡Qué sentido tiene la derivación por métodos cuando existe un solo método!?
Resulta llamativo que la función TukeyHSD, que únicamente considera un método (TukeyHSD.aov) utilice este sistema.
Esto tiene sentido, sin embargo, en pro de la extensibilidad de la función. Aunque actualmente la función TukeyHSD implementa un único método, a futuro sería posible implementar métodos adicionales, sin necesidad de cambiar el nombre de la función principal.
¿¡Y si no aparece nada!?
No todas las funciones permiten ver su código en lenguaje R simplemente escribiendo su nombre y presionando Enter. Algunas funciones, como sum, +, [[, length y c forman parte del núcleo de R y están implementadas directamente en C o C++.
En tales casos, lo que se muestra en consola no es el código fuente en R, sino un aviso indicando que se trata de una función primitiva:
lengthfunction (x) .Primitive("length")El acceso al código fuente de estas funciones —al no estar escrito en lenguaje R— queda fuera del alcance del usuario promedio.
Referencias Bibliográficas
Burns, P. 2011. «The R inferno». https://www.burns-stat.com/pages/Tutor/R_inferno.pdf.
R Core Team. 2022. R Language Definition. Vienna, Austria: R Foundation for Statistical Computing. https://cran.r-project.org/doc/manuals/r-release/R-lang.pdf.
Santana, E., J. S. y Mateos. 2014. El arte de programar en R: un lenguaje para la estadística. 1st ed. México: Instituto Mexicano de Tecnología del Agua.
The tidyverse team. s. f. «The tidyverse style guide». https://style.tidyverse.org/.
Aunque se desglosa en 10 líneas para facilitar su lectura, se trata de una sola instrucción.↩︎