letras
A continuación se enumeran los aspectos que es necesario tener en cuenta al nombrar los objetos, así como sus elementos constitutivos.
Todos los nombres deben comenzar con una letra.
Es posible incluir caracteres numéricos como parte de los nombres, pero no en la primera posición.
No se admiten caracteres especiales, es decir, símbolos que tengan un uso específico dentro del lenguaje R, tales como +, -, *, /, ^, \, |, (, ), [, ], {, }, :, ,,", ', #, $, %, &, @, =, ?, !, etc.
No se admiten espacios.
Cuando el nombre que se pretende usar está conformado por varias palabras, suelen usarse el punto (.) y el guion bajo (_) como símbolos de enlace.
Son comunes y válidos nombre como:
Aunque podría usarse punto (.) en la primera posición del nombre de un objeto, el objeto sería invisible1.
Son admisibles los caracteres propios del alfabeto latino, tales como la ñ y las vocales con tilde.
También son admisibles los caracteres correspondientes a los idiomas modernos de Europa Oriental y Asia.
En tal sentido, cualquiera de las siguientes cadenas de caracteres es un nombre válido en R:
R es case-sensitive. Esto quiere decir que se distingue entre mayúsculas y minúsculas.
Un nombre sintácticamente válido en R es el que se ciñe a las restricciones enumeradas anteriormente.
Las anteriores consideraciones son aplicables a los nombres de los objetos, así como a los nombres de sus diferentes componentes.
En adición a los nombres de los objetos, en R es posible —y en ocasiones hasta obligatorio— nombrar los elementos constitutivos de los vectores, matrices, arreglos, data frames o listas, así:
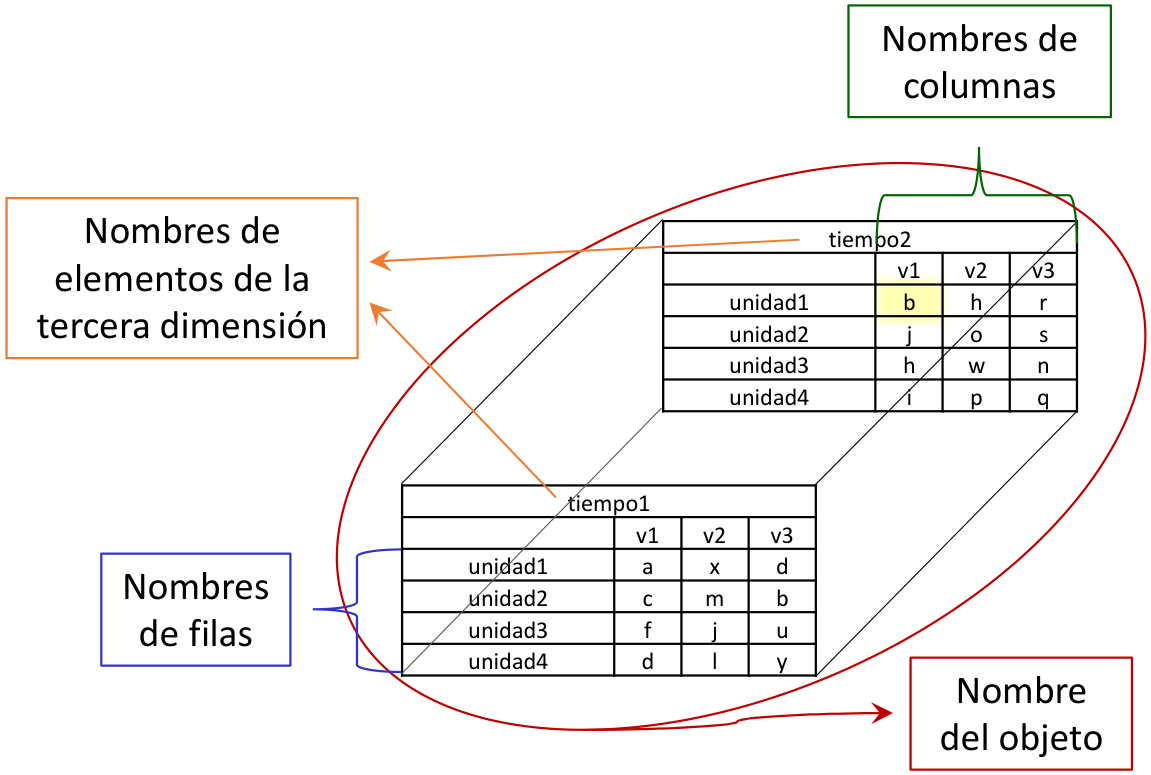
La figura 12.1 se basa en la representación del arreglo letras (cf. sección 8.3) para ilustrar algunos de estos conceptos.
letras
La figura 12.1 permite comprender por qué son tan poco comunes los nombres de los elementos individuales o celdas. Considérese, por ejemplo, el elemento ubicado en la celda superior izquierda posterior. Si, en adición al nombre del objeto contenedor (letras), se indica que ese elemento corresponde a unidad1, v1, tiempo2, y además se tiene su valor ("b"), el elemento queda completamente especificado, siendo innecesario, redundante y hasta posiblemente conflictivo asignarle algún nombre adicional.
El data frame es una estructura rectangular, con observaciones en filas y variables en columnas.
En los data frames, cada columna (variable) tiene obligatoriamente un nombre. Dos columnas no pueden tener el mismo nombre. Cuando se genera un data frame por importación, el nombre de la columna puede leerse de la información contenida en la primera fila o puede definirse automáticamente como V1, V2, . . . , VK, siendo K el número el número de columnas. Este comportamiento queda definido por la función usada para la importación y sus argumentos (cf. capítulo 6).
Las filas (observaciones) también tienen nombres; por defecto, son los enteros desde 1 hasta n, siendo n el número de observaciones. Dos filas no pueden tener el mismo nombre. Los nombres de las filas se asignan automáticamente al momento de la importación o creación del data frame.
Los data frames no admiten nombres para los elementos individuales o celdas.
Las matrices (que también son arreglos) admiten nombres para las filas y para las columnas, así como para cada uno de los elementos individuales o celdas.
Asimismo, los arreglos de dos o más dimensiones admiten nombres tanto para los componentes de sus diferentes dimensiones, como para cada uno de sus elementos individuales o celdas.
Los vectores, al ser estructuras unidimensionales, únicamente admiten nombres para sus diferentes elementos.
Las listas —que son objetos unidimensionales o vectores genéricos— únicamente admiten nombres para sus elementos o componentes. Estos elementos son equivalentes a los elementos individuales de los vectores atómicos.
No obstante, los subelementos que formen parte los elementos de las listas también podrían admitir nombres, acorde con su naturaleza. Así, por ejemplo, si uno de los elementos de una lista fuera una matriz, las filas, las columnas y las celdas de dicha matriz podrían tener nombres.
Los únicos nombres obligatorios son los de los objetos3 y los de las columnas y las filas de los data frames; todos los demás nombres son optativos.
Las funciones names, rownames, colnames y dimnames permiten recuperar los nombres de los elementos constitutivos de los objetos que se usan como contenedores de datos.
Cuando el argumento de la función names es un data frame, el resultado es el nombre de las columnas.
Este resultado tiene sentido, si se considera que esto es lo que el usuario normalmente quiere saber cuando consulta los nombres en un data frame. El nombre de las filas es secundario. Aunque las filas de los data frames tienen nombres, el usuario no suele estar interesado en su manipulación. Por otra parte, los data frames no admiten nombres para las celdas.
id <- c("a23", "f31", "j33", "m54")
v1 <- c(2.4, 7.9, 1.1, 8.5)
v2 <- c(4+3i, 2-0.8i, 1+1.1i, 3-5i)
df <- data.frame(id, v1, v2)
names(df)[1] "id" "v1" "v2"Cuando se genera un data frame a partir de la concatenación de vectores, el data frame hereda los nombres de los vectores, tal y como se ejemplifica para el data frame df. En los data frames que se surgen de la importación de datos, los nombres suelen leerse de la primera fila del archivo externo o generarse por defecto (cf. capítulo 6).
Puesto que los data frames son objetos bidimensionales, conformados por filas y columnas, también pueden usarse las funciones rownames (alias de row.names) y colnames, para recuperar los nombres de las filas y las columnas respectivamente.
Los nombres por defecto de las filas de los data frames son los enteros consecutivos entre 1 y el número de observaciones.
rownames(df)[1] "1" "2" "3" "4"En los data frames la función colnames genera el mismo resultado que names: recupera los nombres de las columnas o variables.
colnames(df)[1] "id" "v1" "v2"En los data frames también puede usarse la función dimnames para obtener de manera simultánea los nombres de los elementos constitutivos de sus dos dimensiones:
dimnames(df)[[1]]
[1] "1" "2" "3" "4"
[[2]]
[1] "id" "v1" "v2"Cuando el argumento de names es una lista, el resultado es el nombre de sus elementos o componentes, en caso de que a estos se les hubiera asignado un nombre (que no es obligatorio). En caso contrario, el resultado sería NULL.
lista2 <- list(c(4.1, -2.7, 7.3), matrix(c("a", "b", "c", "d"), nrow = 2))
names(lista2)NULLEste resultado también tiene sentido, si se tiene en cuenta que las listas son objetos unidimensionales, por lo que no aplicaría ninguna consulta relacionada con nombres de elementos dimensionales. La única pregunta, en términos de nombres, que tiene sentido cuando se hace referencia a una lista, tiene que ver con los nombres de sus elementos.
Al evaluar la función names con objetos atómicos (vectores, matrices o un arreglos) como argumento, se obtendría por resultado el nombre de las celdas o elementos individuales, en caso de que se les hubiera asignado un nombre. Esta situación, además de no ser obligatoria, es poco usual. Si los elementos no tuvieran nombres, el resultado sería NULL.
vocales <- c("a", "e", "i", "o", "u")
names(vocales)NULLEn caso de que los diferentes elementos dimensionales de las matrices o arreglos tuvieran nombres (no son obligatorios), estos podrían recuperarse con las funciones rownames, colnames y dimnames.
Para el caso de matrices es posible recuperar los nombres de las filas usando rownames, y los nombres de las columnas usando colnames. Estas mismas funciones aplican para las dos primera dimensiones de arreglos con mayor dimensionalidad.
Para cualquier objeto atómico de dimensión 2 o mayor, es posible recuperar simultáneamente los nombres de los diferentes elementos dimensionales mediante la función dimnames.
En ocasiones, los nombres de los componentes se generan automáticamente durante la creación de los objetos. En otros casos, es posible indicarlos de manera explícita mediante la introducción de argumentos en las funciones usadas para su creación.
En todos los casos es posible asignar o modificar los nombres de los componentes en objetos ya creados, mediante las funciones names, rownames, colnames y dimnames y el operador de asignación <-. Estas funciones cumplen los mismos roles que se indicaron en la sección 12.2 para recuperación de nombres. Consecuentemente, el uso de las funciones rownames, colnames y dimnames solo aplica para los nombres de los componentes de objetos multidimensionales.
En consonancia con lo indicado en la sección 12.2.1, en cuanto a que la función names en los data frames se refiere a los nombres de las variables, es posible usar esta misma función para modificar los nombres de las variables en un data frame existente.
Consideremos nuevamente el data frame df construido anteriormente, con los nombres heredados al momento de su creación (los nombres de los vectores constitutivos):
id <- c("a23", "f31", "j33", "m54")
v1 <- c(2.4, 7.9, 1.1, 8.5)
v2 <- c(4+3i, 2-0.8i, 1+1.1i, 3-5i)
df <- data.frame(id, v1, v2)
names(df)[1] "id" "v1" "v2"Es posible modificar estos nombres y usar en su lugar algunos nombres personalizados.
[1] "identificador" "lectura1" "lectura2" La línea 1 asigna los nuevos nombres a las variables del data frame df. La línea 2 recupera los nombres actualizados.
Equivalentemente, podría usarse la función colnames en la línea 1, lo cual generaría los mismos cambios. Esto es debido a que la función names aplicada sobre un data frame se refiere los nombres de sus columnas.
Para modificar los nombres de las filas se usa la función rownames
Observemos inicialmente los nombres por defecto de las filas del dataframe df:
rownames(df)[1] "1" "2" "3" "4"Tal y como se indicó en la sección 12.1.1, las filas vienen nombradas por defecto con los números enteros desde 1 hasta el número de observaciones.
Es posible asignar nombres personalizados a las filas:
[1] "primero" "segundo" "tercero" "cuarto" La línea 1 asigna los nuevos nombres a las filas del data frame df. La línea 2 recupera los nombres actualizados.
Aunque no es obligatorio asignar nombres a los elementos de las listas, sí puede ser muy conveniente, dada la complejidad de estos contenedores. Asignarles nombres a los componentes de las listas facilita la visualización de sus contenidos.
Considérese la lista planilla conformada a partir de la agregación de tres vectores:
nombre <- c("Pablo", "Víctor", "Sandra")
rh <- c("O-", "AB+", "O-")
edad <- c(28, 53, 49)
planilla <- list(nombre, rh, edad)
names(planilla)NULLNótese que —a diferencia de lo que sucede con los data frames— las listas no heredan los nombres a partir de los elementos que se usen para su conformación (los nombres de los vectores en esta caso).
No obstante, es posible definir los nombres de los elementos durante la creación, definiendo los elementos de la lista mediante pares nombre = contenido, así:
nombre <- c("Pablo", "Víctor", "Sandra")
rh <- c("O-", "AB+", "O-")
edad <- c(28, 53, 49)
planilla <- list(id = nombre, rh = rh, edad)
names(planilla)[1] "id" "rh" "" En este ejemplo se ilustran diferentes posibilidades:
Puede asignársele al elemento de la lista un nombre diferente al del elemento usado para su constitución. Así, el argumento id = nombre indica que el primer elemento de la lista tendrá el nombre id y que su contenido será el del objeto nombre.
Puede nombrarse el elemento de la lista de la misma forma que el elemento que lo conforma. Así, el argumento rh = rh indica que el segundo elemento de la lista tendrá el nombre rh y que su contenido será el del objeto rh.
Podría dejarse algún elemento sin nombre. Aunque esto no tendría mucho sentido en un contexto en el que los demás elementos hubieran sido nombrados, sería posible. Así, el argumento edad indica que el contenido del tercer elemento de la lista es el del objeto edad. A dicho elemento no se le asigna ningún nombre.
También es posible asignar o modificar los nombres de los elementos de una lista, mediante la función names.
La línea 1 asigna nombres a los elementos de la lista planilla. La línea 2 recupera los nombres de los elementos de la lista.
Puesto que los vectores son objetos unidimensionales, solo es posible asignarles nombres a sus elementos. Los elementos de los vectores no traen nombres por defecto.
Considérese el siguiente vector:
a <- c(1, 2, 3)
names(a)NULLDurante la creación del vector, es posible asignarles nombres a los diferentes elementos así:
a <- c(uno = 1, dos = 2, tres = 3)
names(a)[1] "uno" "dos" "tres"También podrían asignarse o modificarse los nombres de los elementos de un vector ya creado, mediante la función names, así:
La línea 1 les asigna nombres a los elementos del vector a. La línea 2 recupera los nombres.
Mediante la función names es posible —aunque muy poco común— asignar nombres a los elementos de cada una de las celdas de una matriz o arreglo (cf. sección 12.1).
Los nombres que más a menudo suelen manipularse en objetos atómicos multidimensionales (matrices y arreglos) son los de sus componentes dimensionales, es decir, los de las filas, columnas y demás dimensiones, si hubiera lugar a ello.
Cuando las matrices se generan por concatenación de vectores por columnas, mediante la función cbind, las columnas heredan los nombres de los vectores usados para la conformación. Si se genera por concatenación de vectores por filas, mediante la función rbind, las filas heredan los nombres de los vectores usados para la conformación (cf. sección 8.2).
Para definir o modificar los nombres de las filas de matrices o arreglos ya creados, se usa la función rownames.
Para definir o modificar los nombres de las columnas de matrices o arreglos ya creados, se usa la función colnames.
Para definir de manera simultánea los nombres de los diferentes elementos dimensionales de matrices o arreglos, se usa dimnames, sea como argumento, durante la creación del objeto, o como función cuando el objeto ya existe.
A continuación se ilustra el uso de las funciones rownames y colnames para definir los nombres de las filas y las columnas de una matriz.
m <- matrix(c(2, 0, 5, -1, 9, 1), nrow = 2, ncol = 3, byrow = TRUE)
rownames(m) <- c("fila1", "fila2")
colnames(m) <- c("col1", "col2", "col3")
dimnames(m)[[1]]
[1] "fila1" "fila2"
[[2]]
[1] "col1" "col2" "col3"La línea 1 crea la matriz. Puesto que no se crea por concatenación de vectores, ninguna de sus elementos tiene nombre. La línea 2 les asigna nombres a las filas. La línea 3 les asigna nombres a las columnas. La línea 4 recupera los nombres de todas las dimensiones de m.
A continuación se ilustra el uso de dimnames como argumento para la definición de los nombres de los diferentes elementos dimensionales de una matriz o un arreglo. El valor de dimnames debe ser una lista, en la que cada uno sus elementos corresponde a una dimensión. Los nombres de los encabezados en cada dimensión se organizan en un vector.
Considérese el arreglo tridimensional letras esquematizado en la figura 12.1. A continuación se ilustra el uso de dimnames como argumento de la función array.
letras <- array(c('a', 'c', 'f', 'd',
'x', 'm', 'j', 'l',
'd', 'b', 'u', 'y',
'b', 'j', 'h', 'i',
'h', 'o', 'w', 'p',
'r', 's', 'n', 'q'), dim = c(4, 3, 2),
dimnames = list(
1 c("unidad1", "unidad2", "unidad3", "unidad4"),
2 c("v1", "v2", "v3"),
3 c("tiempo1", "tiempo2")))
dimnames(letras)[[1]]
[1] "unidad1" "unidad2" "unidad3" "unidad4"
[[2]]
[1] "v1" "v2" "v3"
[[3]]
[1] "tiempo1" "tiempo2"Igualmente podría usarse dimnames como función para asignar o modificar los nombres de un objeto ya creado, así:
dimnames(letras) <- list(c("unidad1", "unidad2", "unidad3", "unidad4"),
c("v1", "v2", "v3"),
c("tiempo1", "tiempo2"))
Las funciones names, colnames, rownames y dimnames permiten gestionar los nombres de los componentes de los objetos que se usan como contenedores de datos, tal y como se resumen en la tabla 12.1.
| data frames | listas | vectores | matrices | arreglos | |
names |
variables | elementos | elementos | celdas | celdas |
colnames |
variables | no aplica | no aplica | columnas | columnas |
rownames |
observaciones | no aplica | no aplica | filas | filas |
dimnames |
observaciones y variables | no aplica | no aplica | filas y columnas | todas las dimensiones |
Cuando se importan datos desde fuente externas, estas pueden contener variables cuyos nombres no sean sintácticamente válidos para R4. Lo que sucede con tales nombres durante la importación depende de la función que se use.
Cuando se usa alguna de las funciones read.table, read.delim, read.delim2, read.csv o read.csv2 (cf. sección 6.1), los caracteres no estándar (espacios o símbolos especiales) se remplazan por puntos, con lo cual, todos los nombres del data frame resultante son sintácticamente válidos.
En contraste, cuando se usa la función read_excel{readxl} para importar datos desde archivos Excel, los nombres no se modifican, sin importar si se trata de nombres sintácticamente válidos o no. Esto puede dar lugar a nombres no estándar para algunas de las variables del data frame resultante.
Es posible, sin embargo, forzar el reconocimiento de nombres no estándar, encerrándolos entre comillas invertidas (` `).
Así, por ejemplo, nombres como `log (UFC)` o `3a lectura %` son reconocidos por la mayoría de funciones en R.
Se desaconseja el uso de nombres no estándar por las siguientes razones:
Se recomienda evitar los nombres no estándar, a fin de mantener el código limpio y portable.
Lo más directo para evitar la aparición de nombres no estándar en los data frames que se importen mediante la función read_excel{readxl} consiste en usar nombres sintácticamente válidos en el archivo fuente de Excel.
Si esto resultara muy dispendioso, poco práctico o irrealizable, podría realizarse una adaptación de los nombres resultantes, mediante la función make.names{stats}
names(df) <- make.names(names(df)) Esto aplica únicamente a los objetos; no, a sus elementos constitutivos.↩︎
No obstante, podrían manejarse objetos efímeros, a los que no se les asigna ningún nombre, pero que tampoco podrían invocarse posteriormente.↩︎
Si se pretende invocarlos posterirmente.↩︎
Aunque sí podrían serlo en el archivo fuente original.↩︎